Intersection with Bloom Filters Dept. of Computer Science, Institute for Advanced Computer Studies, The iSchool University of Maryland, College Park 2013-06-12 輪講資料
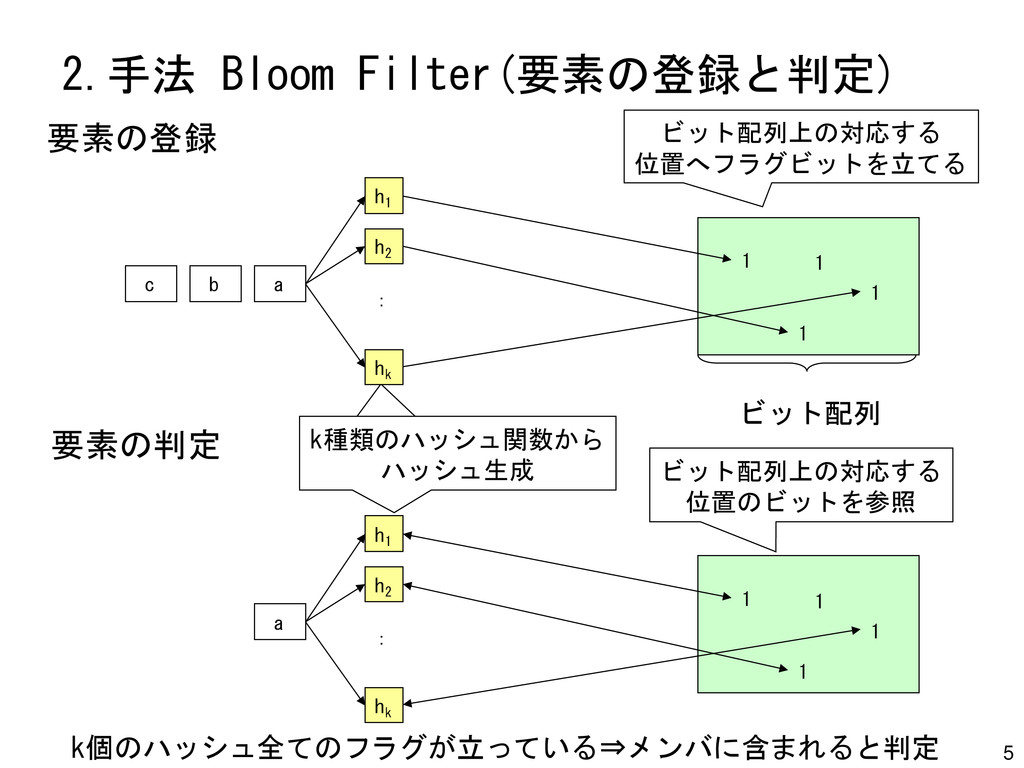
a h1 hk : 要素の登録 h2 ビット配列上の対応する 位置へフラグビットを立てる 1 1 1 1 a h1 hk : h2 ビット配列上の対応する 位置のビットを参照 要素の判定 k個のハッシュ全てのフラグが立っている⇒メンバに含まれると判定 ビット配列 k種類のハッシュ関数から ハッシュ生成 b c
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}