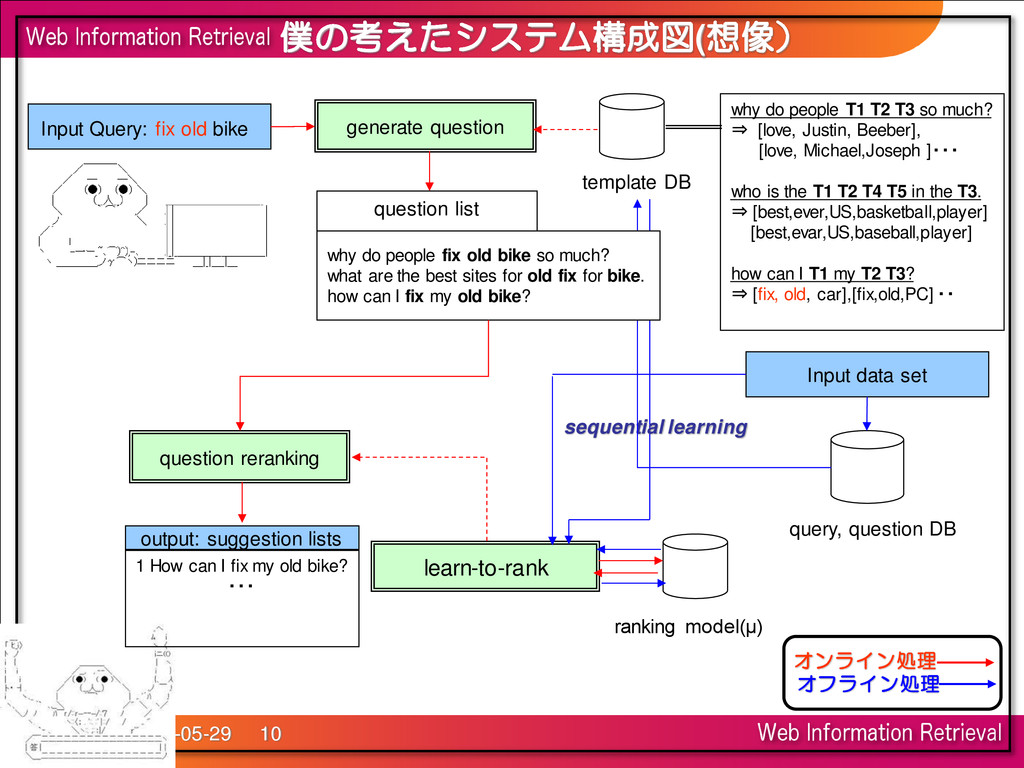
people T1 T2 T3 so much? ⇒ [love, Justin, Beeber], [love, Michael,Joseph ]・・・ who is the T1 T2 T4 T5 in the T3. ⇒ [best,ever,US,basketball,player] [best,evar,US,baseball,player] how can I T1 my T2 T3? ⇒ [fix, old, car],[fix,old,PC] ・・ sequential learning generate question query, question DB template DB question list question reranking output: suggestion lists learn-to-rank ranking model(μ) 1 How can I fix my old bike? ・・・ Input data set why do people fix old bike so much? what are the best sites for old fix for bike. how can I fix my old bike? オンライン処理 オフライン処理
i k i q q sim q q sim ) , ( ) , ( k i k q q , はそれぞれk番目のクエリ ) , ( * ) , ( * ) , ( ]) , , [ ], , , ([ car bike sim old old sim fixed fixed sim car old fixed bike old fixed sim ・類似度はcontext vector をtfidf で重み付けしたものでcosine類似度
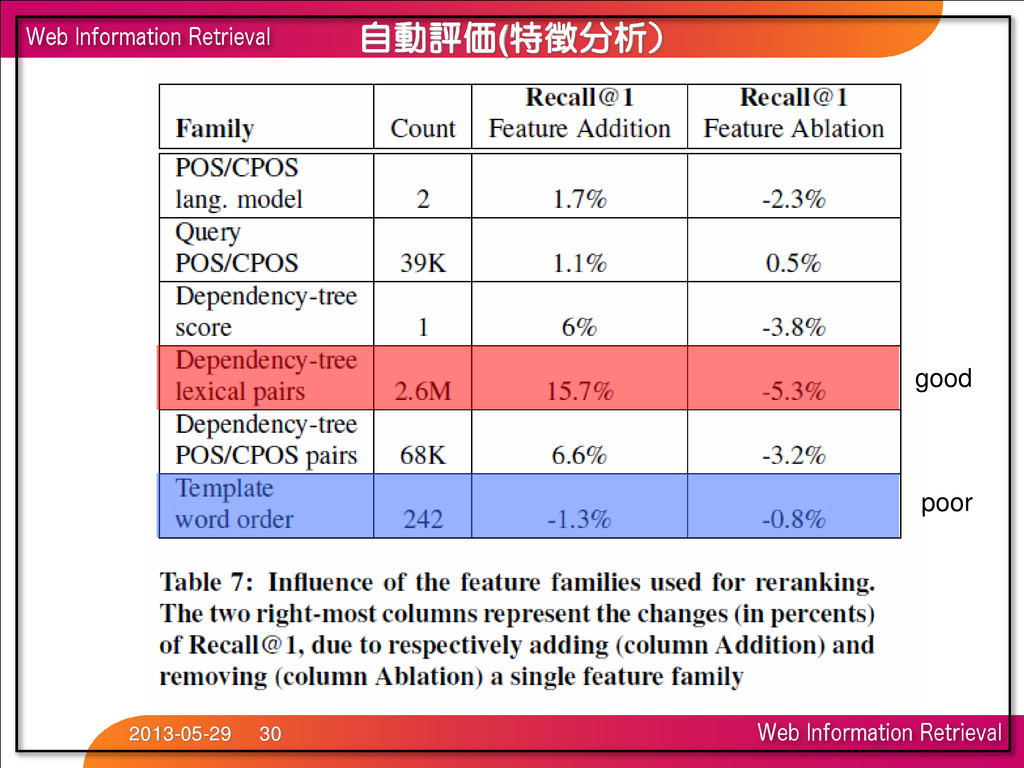
score for Question POS tags (Coarse-POS※) ※簡略化した品詞 名詞は Nでまとめられる (NN,NNS,NP,NPS) 素性の効果としては高度な文法上の流暢性を考慮する。 – 学習データ •1500万の質問データ(3-gram)で学習 ex) How can I fix my old car? Questions POS language models How can I fix my # Adverb-Verb-Determiner-Verb-eterminer can I fix my old # Verb-Determiner-Verb-eterminer-Adjective I fix my old car # Determiner-Verb-eterminer-Adjective-Noun fix my old car ? # Verb-eterminer-Adjective-Noun-Punctuation
do I fix my old car? how can I fix an old car? how could you fix your old car? ex2) where can I {find/buy/get} a TV for a good price?. ⇒ 5つを推薦した場合、リスト中の2~3個は 質問意図が重複している • 後処理でフィルタリングを実施する – 2種のフィルタリング方法を提案
method 異なる疑問表現(interrogative word※)で始まる 質問文を優先して出す ※what,when,where,.. ex) where can I fix a wii game console? where can I buy a wii game console? ⇒ 削除 • Eliminating Redundant Questions - 冗長性の削除 word-base edit-distance を計算し、閾値(K<=3)以内であれば削除す る。ただし、interchangeble pair※の交換はcost=0で交換可能。 ※interchageble pair はDBの共起情報などから生成(5oo pair) ex) what are the {main/major} characteristics of a pigs? ⇒ {main/major}は非交換可能ペア。⇒非削除 フィルタリング方法
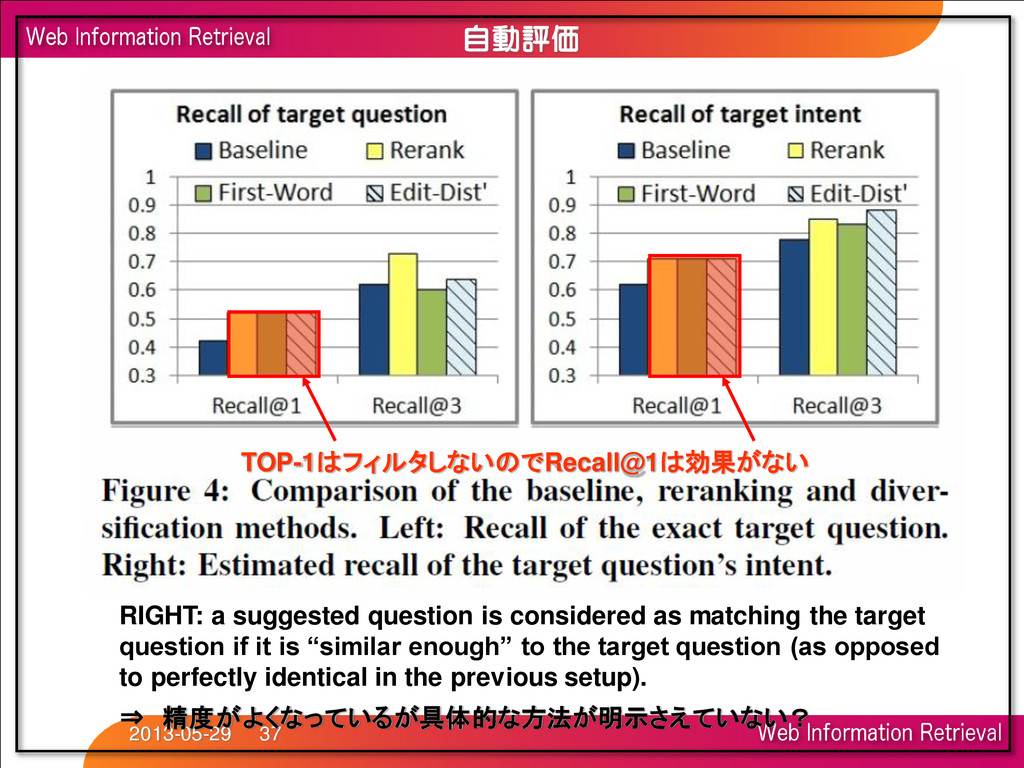
as matching the target question if it is “similar enough” to the target question (as opposed to perfectly identical in the previous setup). ⇒ 精度がよくなっているが具体的な方法が明示さえていない?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![9 2013-05-29 • オフライン処理 (モデル学習) 1. 質問文テンプレート抽出 2. 質問文表示順位モデル学習[ランキング学習] 3.](https://files.speakerdeck.com/presentations/f4785d50abfc013071af5a1918864baf/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![27 2013-05-29 • アルゴリズム別の人手評価の結果 – Relevant は両手法とも概ね高精度(94[%]~96[%]) ※全てのクエリが質問文に出てくるので、判定者がよく見えるためだと思われる。 – Grammar](https://files.speakerdeck.com/presentations/f4785d50abfc013071af5a1918864baf/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![34 2013-05-29 • フィルタテスト – development データ(140,000クエリ)に対して 2種のフィルタでどれぐらいフィルタされるか調査 ⇒ 少なくとも50[%]の最上位の質問は2種のフィルタに](https://files.speakerdeck.com/presentations/f4785d50abfc013071af5a1918864baf/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![40 2013-05-29 [1] S. Zhao, H. Wang, C. Li, T.](https://files.speakerdeck.com/presentations/f4785d50abfc013071af5a1918864baf/slide_39.jpg){kind=link}
{kind=link}