Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【輪講資料】Inferring the Demographics of Search User...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Yuichiro SEKIGUCHI
June 12, 2013
Research
230
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【輪講資料】Inferring the Demographics of Search Users【WWW2013】
2013-06-12に職場で実施した輪講資料を代理アップロードしました.
Yuichiro SEKIGUCHI
June 12, 2013
More Decks by Yuichiro SEKIGUCHI
See All by Yuichiro SEKIGUCHI
【輪講資料】Destination Prediction by Sub-Trajectory Synthesis and Privacy Protection Against Such Prediction【ICDE2013】
dreamedge
0
560
【輪講資料】Time-aware Point-of-Interest Recommendation【SIGIR2013】
dreamedge
1
710
【輪講資料】Exploring and Exploiting User Search Behavior on Mobile and Tablet Devices to Improve Search Relevance【WWW2013】
dreamedge
1
220
【輪講資料】Fast Candidate Generation for Two-Phase Document【CIKM2012】
dreamedge
1
170
【輪講資料】Optimal Hashing Schemes for Entity Matching【WWW2013】
dreamedge
2
1.1k
【輪講資料】From Query to Question in One Click: Suggesting Synthetic Questions to Searchers【WWW2013】
dreamedge
1
170
【輪講資料】Are Web Users Really Markovian?【WWW2012】
dreamedge
1
190
【輪講資料】Learning to Rank for Spatiotemporal Search【WSDM2013】
dreamedge
1
970
【輪講資料】Mining the Web for Points of Interest【SIGIR2012】
dreamedge
1
1.2k
Other Decks in Research
See All in Research
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
220
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
140
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
PGDM: Physically Guided Diffusion Model for L Downscaling
satai
3
350
コーディングエージェントとABNを再考
hf149
2
760
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
550
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
110
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
360
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
150
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
Ankylosing Spondylitis
ankh2054
0
180
Featured
See All Featured
The Curious Case for Waylosing
cassininazir
1
430
Test your architecture with Archunit
thirion
1
2.3k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
230
Context Engineering - Making Every Token Count
addyosmani
9
1k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
630
Building an army of robots
kneath
306
46k
We Have a Design System, Now What?
morganepeng
55
8.2k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
890
Transcript
1 輪講資料 2013-06-12 Inferring the Demographics of Search Users Bin
Bi*, Milad Shokouhi, Michal Kosinski, Thore Graepel *Bin’s internship at Microsoft Research Cambridge WWW’13, May 13-17, 2013, Rio de Janeiro, Brazil.
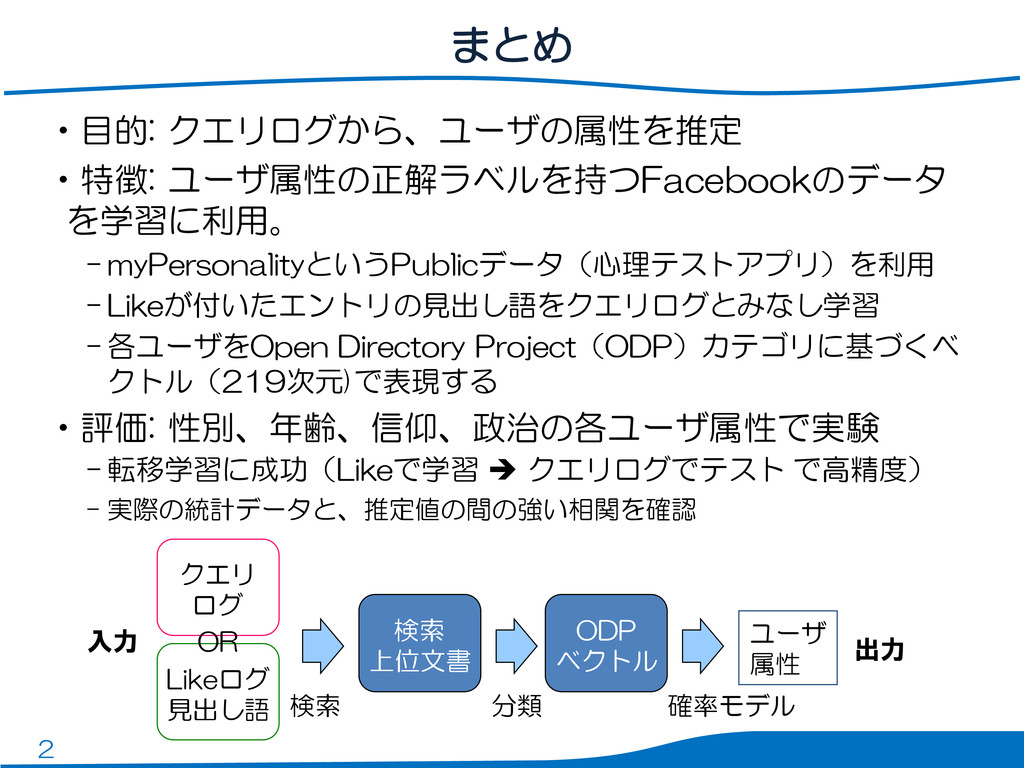
2 まとめ •目的: クエリログから、ユーザの属性を推定 •特徴: ユーザ属性の正解ラベルを持つFacebookのデータ を学習に利用。 – myPersonalityというPublicデータ(心理テストアプリ)を利用 –
Likeが付いたエントリの見出し語をクエリログとみなし学習 – 各ユーザをOpen Directory Project(ODP)カテゴリに基づくベ クトル(219次元)で表現する •評価: 性別、年齢、信仰、政治の各ユーザ属性で実験 – 転移学習に成功(Likeで学習 クエリログでテスト で高精度) – 実際の統計データと、推定値の間の強い相関を確認 Likeログ 見出し語 検索 上位文書 ODP ベクトル クエリ ログ ユーザ 属性 入力 出力 OR 確率モデル 分類 検索
3 はじめに •検索クエリの履歴から、ユーザ属性を知ることが出来れば 、検索結果の改善などに役立てることが出来る •ユーザ属性には大きく分けて2種類ある –デモグラフィック属性とは、人口統計学的な属性データ 。具体的には、性別、年齢、居住地域、所得、職業、学 歴、家族構成など。 –サイコグラフィック属性とは、心理学的属性。具体的に は、ライフスタイル、好み、価値観、信念(宗教)、購
買意向・動機など。 •タイトルはデモグラフィック属性の推定だが,実験ではサ イコグラフィック属性の推定もしている
4 はじめに •Bingのユーザが、Facebookにログインしながら 検索するのは、全体の22% •Microsoftのユーザアカウントでは、政治観や信 仰などの属性は取得できない。また、正解属性が 分かるユーザ数も少ない。 クエリログから学習するのは困難 •属性が明らかなFacebookのLike(いいね!)を
、クエリログからの推定のために利用する: –「ドメイン適応」や「転移学習」と呼ばれる –2つの情報源(Facebookとクエリログ)を、Open Directory Project(ODP)カテゴリでブリッジする
5 目次 •はじめに •ユーザ属性モデリング •データセット •実験 •まとめ
6 ユーザ属性のモデリング • 2つのチャレンジに取り組む 1. 検索クエリとFacebookのLikeの間に、有効な共通表 現はあるか? 2. 2つのデータセット(検索、Facebook)におけるユ ーザ属性の分布の違いをどう扱って転移学習するか?
7 チャレンジ1: LikeとQueryの共通表現 (1) •Open Directory Project(ODP)を利用する –ボランティア運営による世界最大のウェブディレクトリ –全世界で約500万サイトが登録。英語が320万、日本語 が18万弱(Wikipediaより、2012年12月)
http://www.dmoz.org/
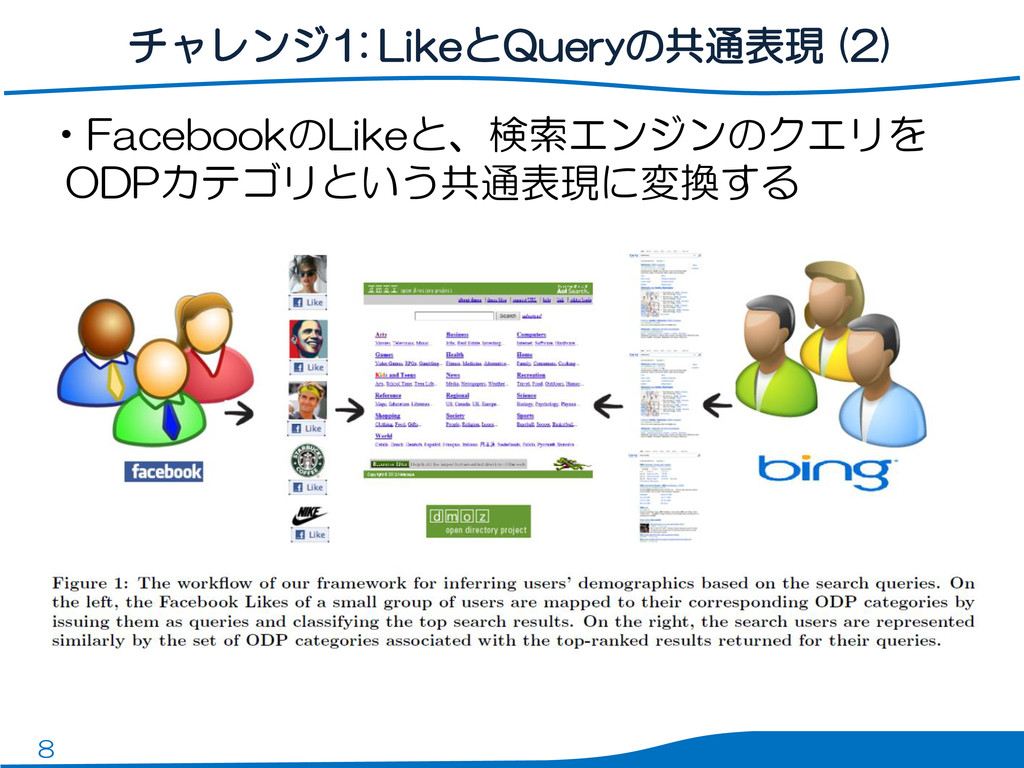
8 •FacebookのLikeと、検索エンジンのクエリを ODPカテゴリという共通表現に変換する チャレンジ1: LikeとQueryの共通表現 (2)
9 チャレンジ1: LikeとQueryの共通表現 (2) •FacebookのLikeを「Likeされたエンティティの タイトル」をクエリとした検索と解釈 –Lady gagaへのLike = “lady
gaga”という検索 •検索結果(Bing)の上位10件の各Webページを 、ODPカテゴリ(219種)に分類する – ODPにリンクされたページを学習データとして、ロジ スティック回帰による分類器を構築 –例) Arts/Movies、Business/Jobs 1つのLikeが219次元のベクトルに変換される –各カテゴリについて検索結果に含まれる文書数が要素
10 チャレンジ1: LikeとQueryの共通表現 (2) •クエリログも同様に219次元ベクトルに変換可能 –ユーザの各クエリについて、検索結果を取得し、上位1 件の文書をODPに分類する –分類結果を集約して、ODPベクトルを作成 Likeとクエリを共通表現に変換可能
= Likeからでも、クエリからでもユーザ属性を推定可能 = Likeデータで学習した結果を、クエリでのテストに転移 できる
11 ユーザ属性のモデリング • 2つのチャレンジに取り組む 1. 検索クエリとFacebookのLikeの間に、有効な共通表 現はあるか? 2. 2つのデータセット(検索、Facebook)におけるユ ーザ属性の分布の違いをどう扱って転移学習するか?
12 チャレンジ2: どう転移学習するか? (1) •最終的に推定したい確率 –Y: ユーザ属性クラス –Q: クエリ –Dq:
クエリログ全体 •ODPカテゴリCで周辺化されていると考えると、 推定したいユーザの クエリQを、ODP共通表現 に変換して推定可能 ここをどのように 推定するか?が この論文のポイント
13 チャレンジ2: どう転移学習するか? (2) •ベイズルールより、 •P(Y|Dq)は、検索エンジンにおけるユーザ属性分布と考え て良い(既知とする) •P(C|Dq)は、ODPカテゴリのエントリ数の分布と考えて良 い(既知とする)
P(C|Y,Dq)が推定出来ればOK!しかし、クエリログDq には、ユーザ属性の正解ラベルが付いていない
14 •P(C|Y,Dq)は、ユーザ属性Yが、カテゴリCに興味 のある確率である 検索エンジンの利用にも、Facebookの利用にも依存し ないので、以下の様に考えて良い Facebookには正解のユーザ属性データがあるので、こ れを学習に利用する チャレンジ2: どう転移学習するか? (3)
queryログ facebookログ
15 •P(C|Y)=θYをMAP(最大事後確率)推定する •MAP推定値は以下の通り得られる チャレンジ2: どう転移学習するか? (4) 尤度(多項分布)事前分布(ディ リクレ分布) • K:
ODPカテゴリ数(=219) • k: カテゴリインデクス • Nk Y: クラスYのユーザのLikeによる検索結果 に含まれる、ODPカテゴリkのWebページ数 • NY:クラスYのユーザのLikeによる検索結果 のWebページ数
16 チャレンジ2: どう転移学習するか? (5) •最初に戻ると、 •P(C)は、ODPカテゴリ分布。 •P(C|Q,Dq)は、各ユーザのクエリQから得られる正規化さ れたODPベクトルと考えて良い – 共通表現なので、Likeからでも推定可能
Facebookデータから学習できた! 残り: ユーザのクエリQに 依存する部分 Likeログ 見出し語 検索 上位文書 ODP ベクトル クエリ ログ ユーザ 属性 入力 出力 OR モデル 分類 検索 をLikeで学習!
17 目次 •はじめに •ユーザ属性モデリング •データセット •実験 •まとめ
18 myPersonalityデータセット(Facebook) •Facebookの心理テストアプリ –オプトインで研究目的にプロフィール記録 –http://mypersonality.org/wiki からデータをDL可能 •600万ユニークユーザのうち、本研究では、年齢 、性別、政治観、信仰、Facebookのいいねリス トがあるUSユーザのみ利用 –10ユーザ未満のLikeエンティティは削除
–457,000ユーザ、122,000ユニークLike、1100万以 上の(ユーザ, Like)の組 –信仰と政治観は自由記述 正規表現でマッチング
19 Bingデータセット(Search) •2012年10月14日~10月28日のBingのデータ •検索時にMicrosoft Live アカウントにログイン 中のデータ1.33億クエリ、3.3百万ユーザ –Microsoft Liveプロフィールに性別と年齢のデータあり ※
本研究では、クエリログに関するユーザ属性の正 解データは得られない想定で、ユーザ属性推定を 行う。Liveアカウントのプロフィールデータはテ スト時のみ用いる
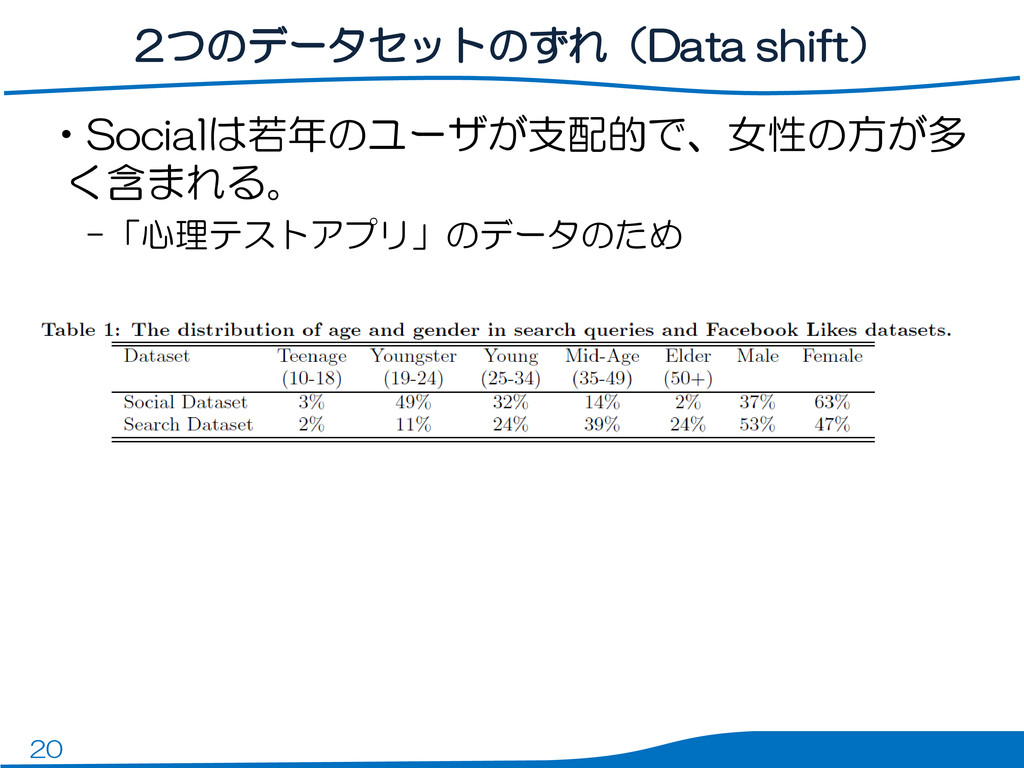
20 2つのデータセットのずれ(Data shift) •Socialは若年のユーザが支配的で、女性の方が多 く含まれる。 –「心理テストアプリ」のデータのため
21 目次 •はじめに •ユーザ属性モデリング •データセット •実験 •まとめ
22 評価実験 •学習: – Facebookデータの66%で学習 •テスト: – Facebookデータの残り34%(性別、年齢、政治観、信仰) – Searchデータ100%(性別、年齢)
•指標: – AUC(Area Under the ROC Curve)の平均値 •False Positive vs. True Positiveの曲線の面積 – 1.0のとき最も良い。0.0のとき最も悪い •ユーザ属性の正解ラベルを使った評価 – Pearson相関係数 •オフィシャルの統計と、推定値の相関 •ユーザ属性の正解ラベルを用いていない
23 転移学習の結果 •Facebookで学習,Searchでテスト(クエリロ グからユーザ属性推定)しても高い推定精度を維 持している 転移学習成功 Facebookで学習、 Facebookでテスト Facebookで学習、
Searchでテスト 性別(2クラス) 年齢(5クラス) 信仰(4クラス) 政治観(2クラス)
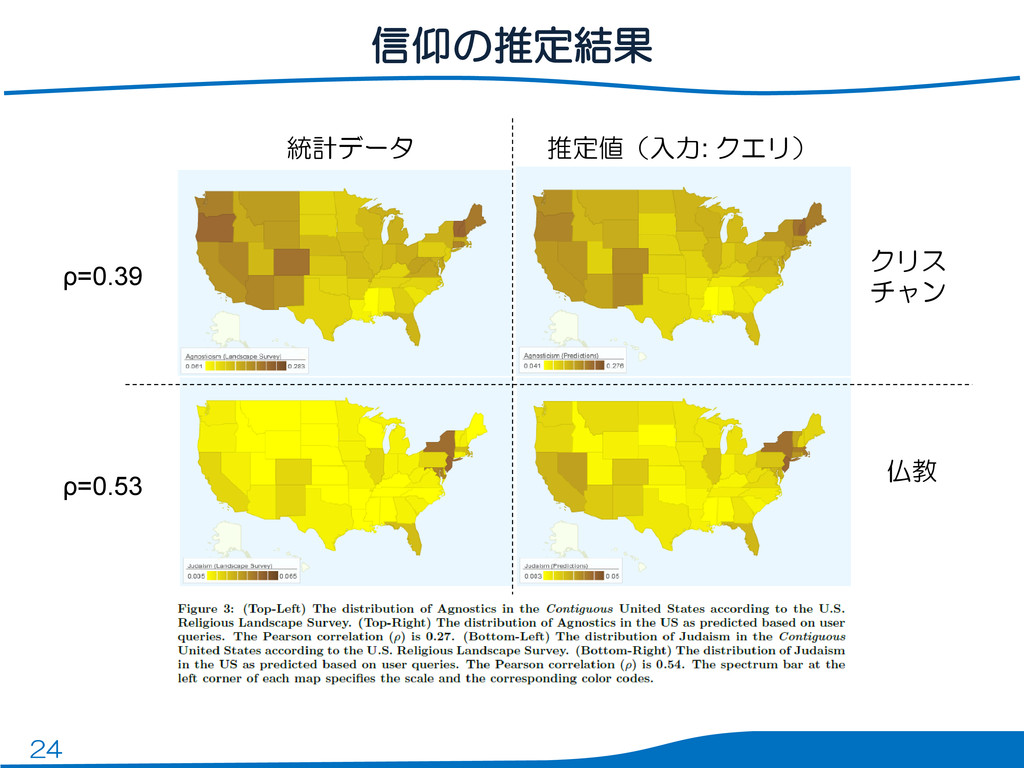
24 信仰の推定結果 統計データ 推定値(入力: クエリ) クリス チャン 仏教 ρ=0.39 ρ=0.53
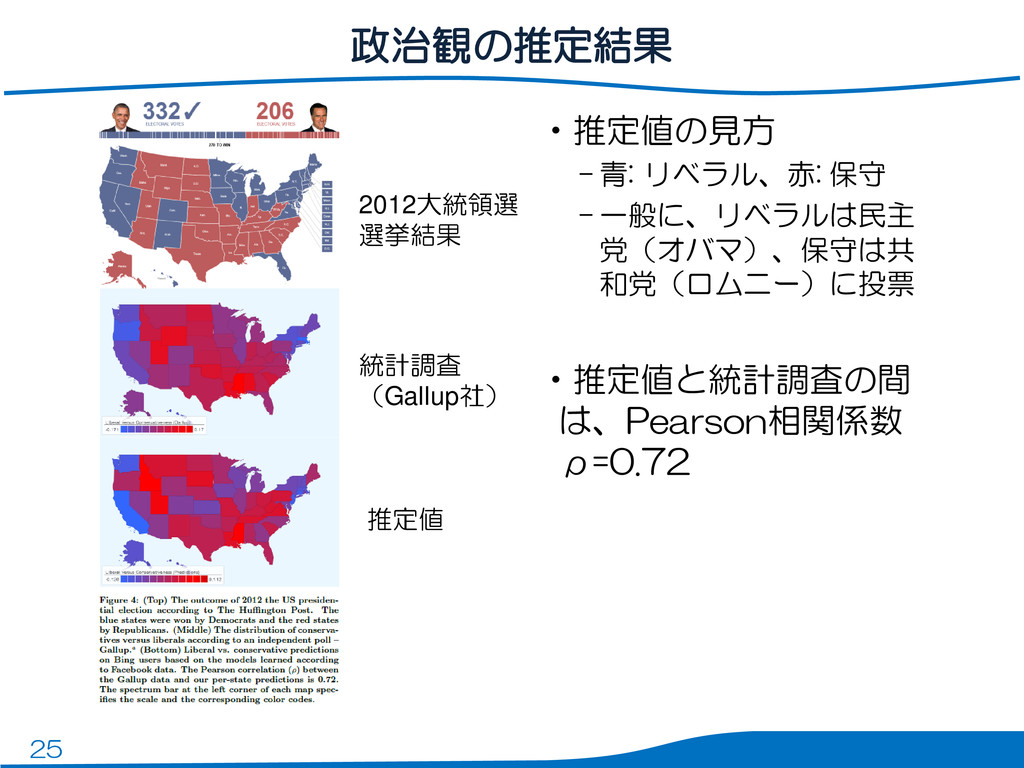
25 政治観の推定結果 •推定値の見方 – 青: リベラル、赤: 保守 – 一般に、リベラルは民主 党(オバマ)、保守は共
和党(ロムニー)に投票 •推定値と統計調査の間 は、Pearson相関係数 ρ=0.72 2012大統領選 選挙結果 統計調査 (Gallup社) 推定値
26 ユーザ属性と関連が強いODPカテゴリの発見(1) •どのODPカテゴリがユーザ属性に寄与しているかを Information Gainにより計算 •「Sports/Basketballは、性別の判定に役立つ」など
27 ユーザ属性と関連が強いODPカテゴリの発見(2) •特定の属性に影響するODPカテゴリをInfluence(β)ス コアにより計算 •例えば、Shopping/JewelleryやBusiness/Hospitalityは Mid-age(35-49歳)に影響、などが分かる
28 目次 •はじめに •ユーザ属性モデリング •データセット •実験 •まとめ
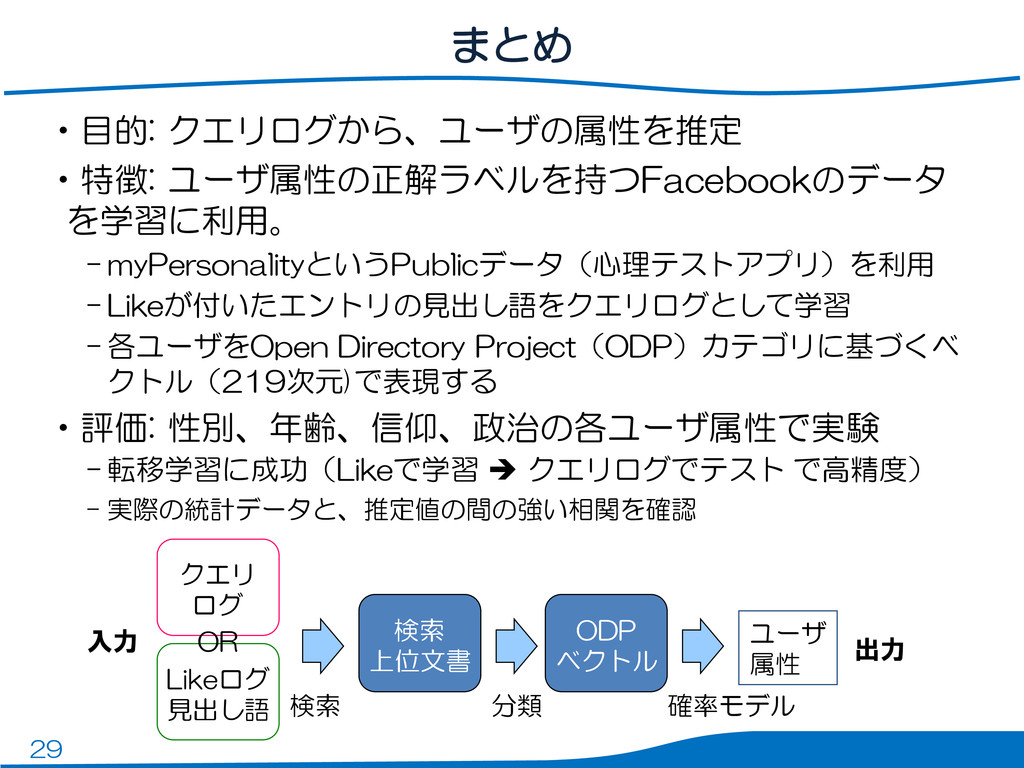
29 まとめ •目的: クエリログから、ユーザの属性を推定 •特徴: ユーザ属性の正解ラベルを持つFacebookのデータ を学習に利用。 – myPersonalityというPublicデータ(心理テストアプリ)を利用 –
Likeが付いたエントリの見出し語をクエリログとして学習 – 各ユーザをOpen Directory Project(ODP)カテゴリに基づくベ クトル(219次元)で表現する •評価: 性別、年齢、信仰、政治の各ユーザ属性で実験 – 転移学習に成功(Likeで学習 クエリログでテスト で高精度) – 実際の統計データと、推定値の間の強い相関を確認 Likeログ 見出し語 検索 上位文書 ODP ベクトル クエリ ログ ユーザ 属性 入力 出力 OR 確率モデル 分類 検索
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}