Initial problem: visually explore data - online advertising data - SQL requires expertise - Writing queries is time consuming - Dynamic visualizations not static reports
- GPL license initially - Part-time development until early 2014 - Apache v2 licensed in early 2015 Requirements? - “Interactive” (sub-second queries) - “Real-time” (low latency data ingestion) - Scalable (trillions of events/day, petabytes of data) - Multi-tenant (thousands of current users)
focus on BI Business intelligence/OLAP queries - Time, dimensions, measures - Filtering, grouping, and aggregating data - Not dumping entire data set - Not examining single events - Result set < input set (aggregations)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
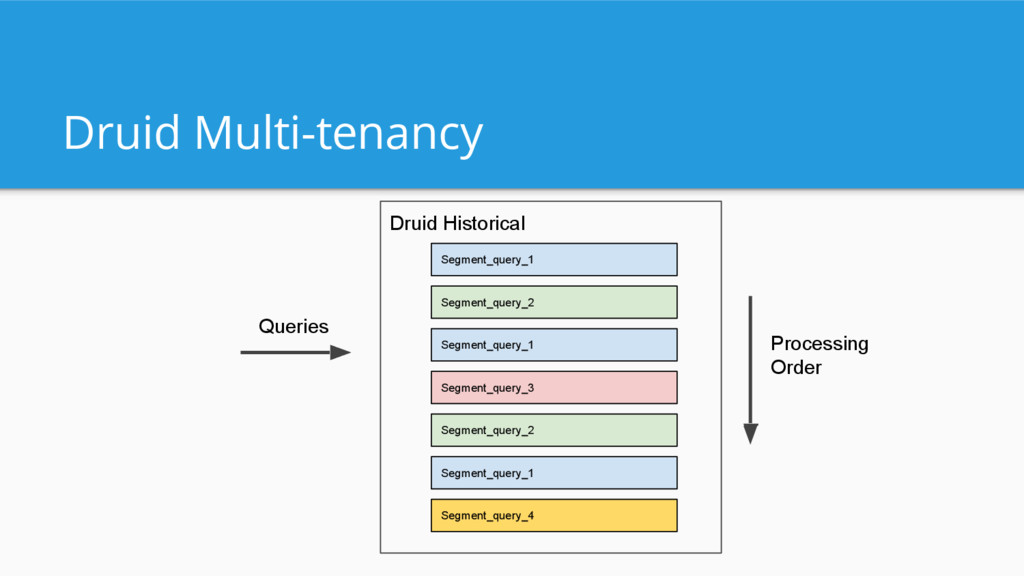{kind=link}
{kind=link}
![Columnar Storage Justin Bieber → [0, 1, 2] → [111000]](https://files.speakerdeck.com/presentations/ec5a787115724303878e178c29055e6d/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
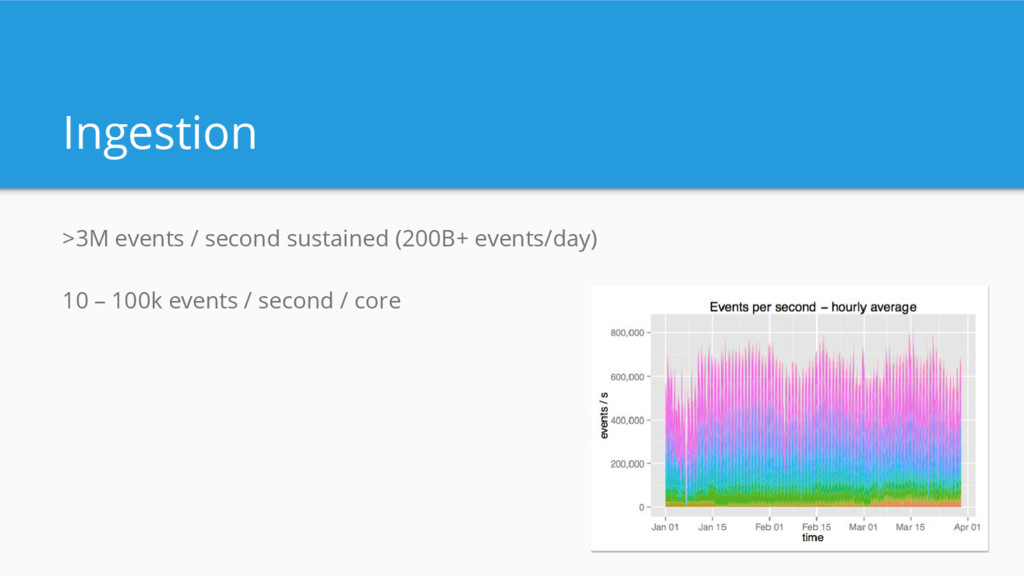{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}