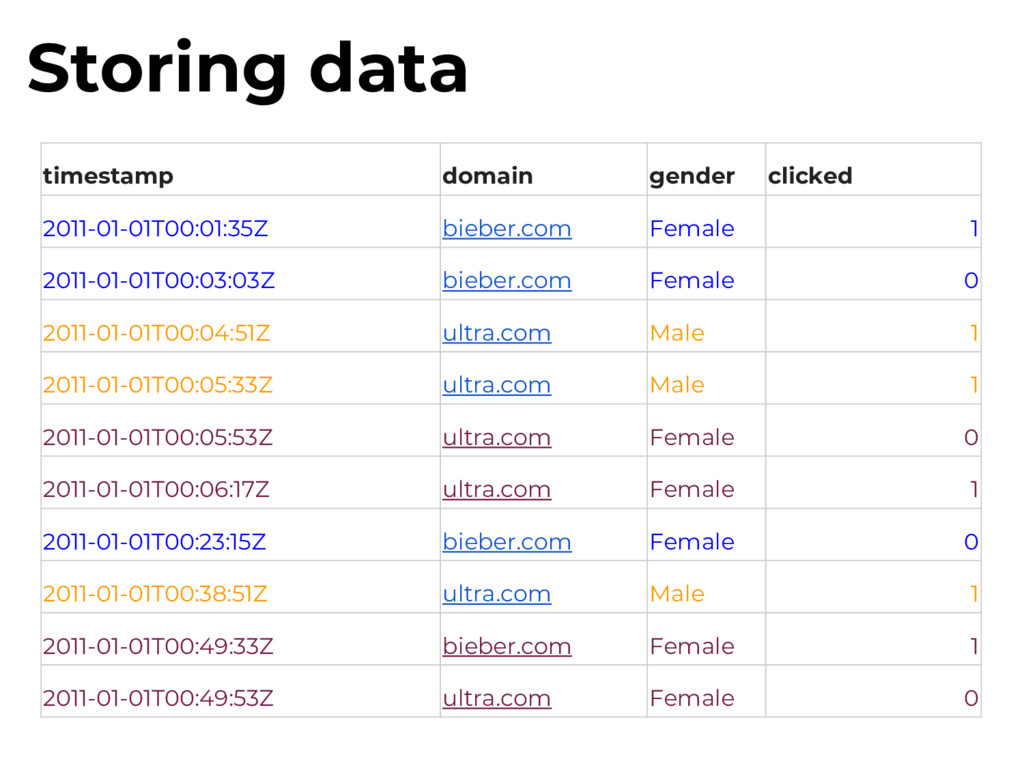
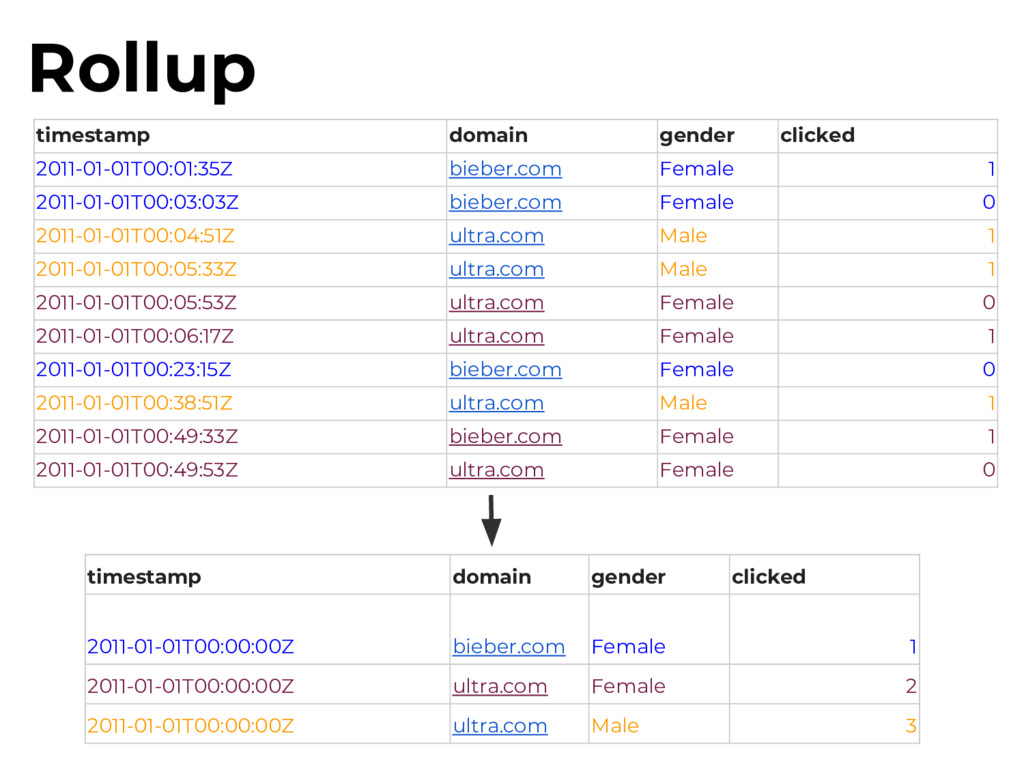
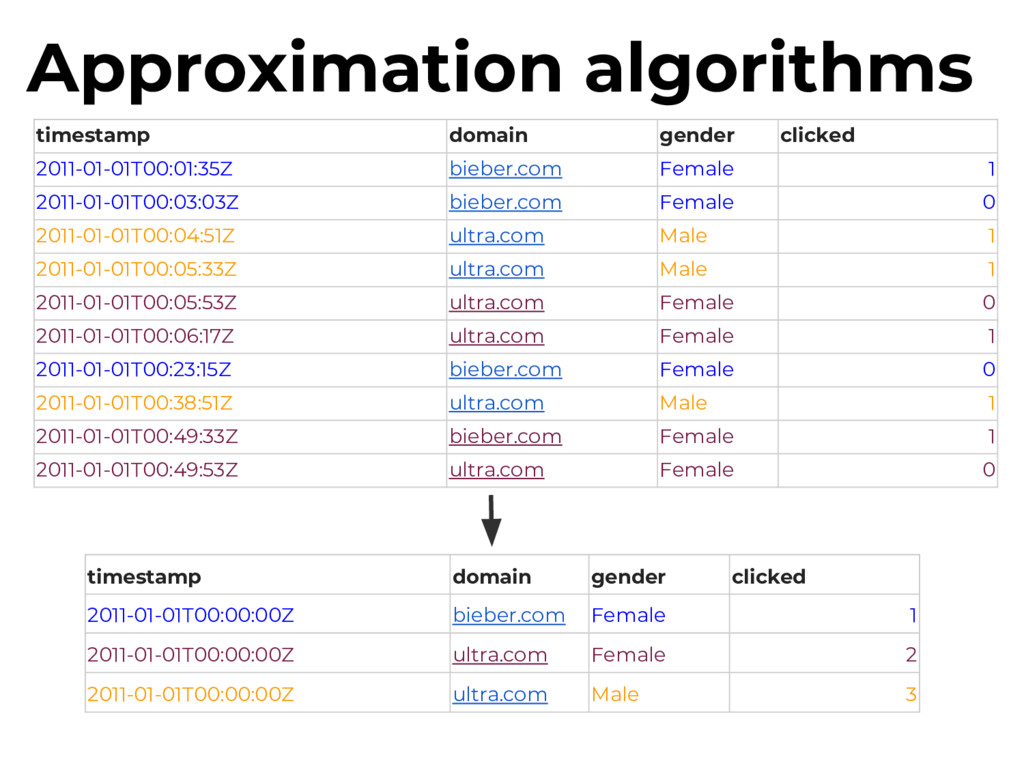
as little private data as possible: - No IPs - Only sanitized user agents - Historical data (older than 90 days) must be fully cleansed of sensitive information - Should not be able to reconstruct browsing sessions
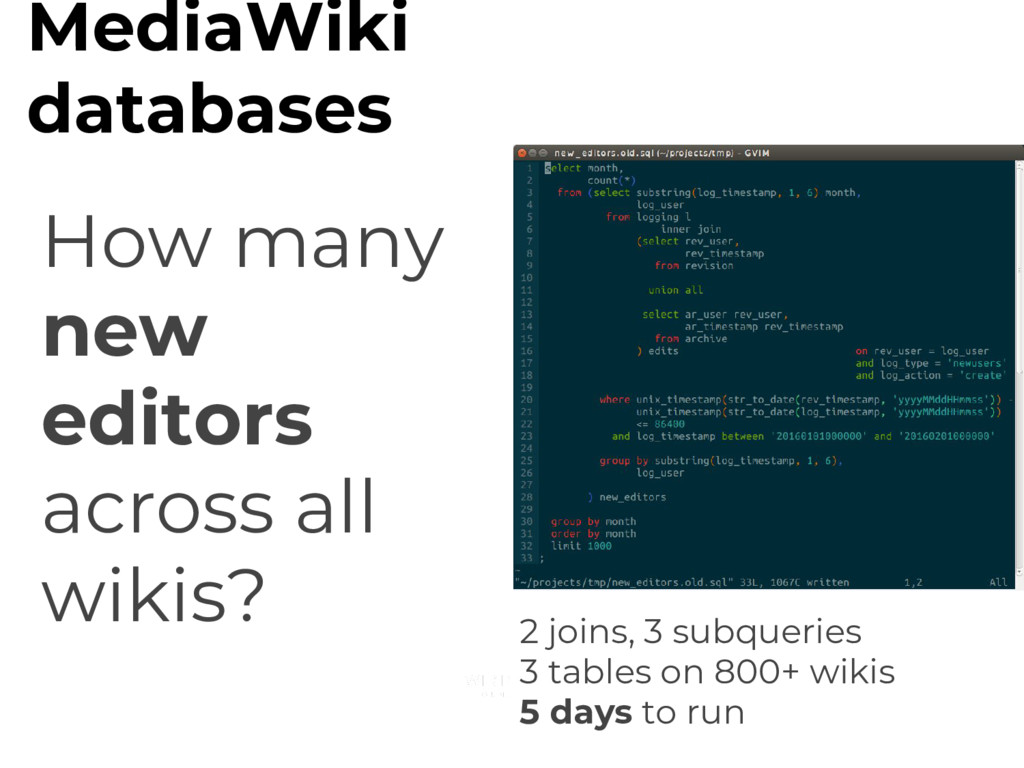
How many new users over time? - How many edits over time? - How many edits do new users make? - How do editors stay active? - How many edits are made by bots? - Etc. etc. etc. MediaWiki databases
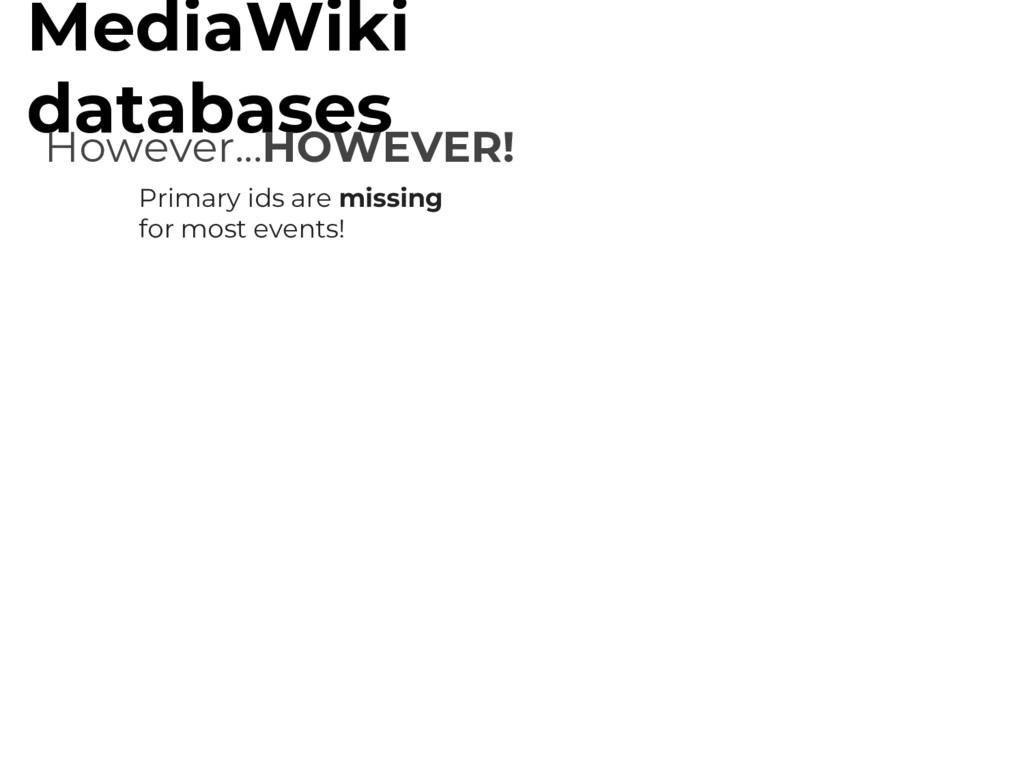
(rename, block, rights) ...which both go back to the almost beginning of wiki-time MediaWiki databases However... Historical events are saved in a ‘log’ table. Log has juicy information about:
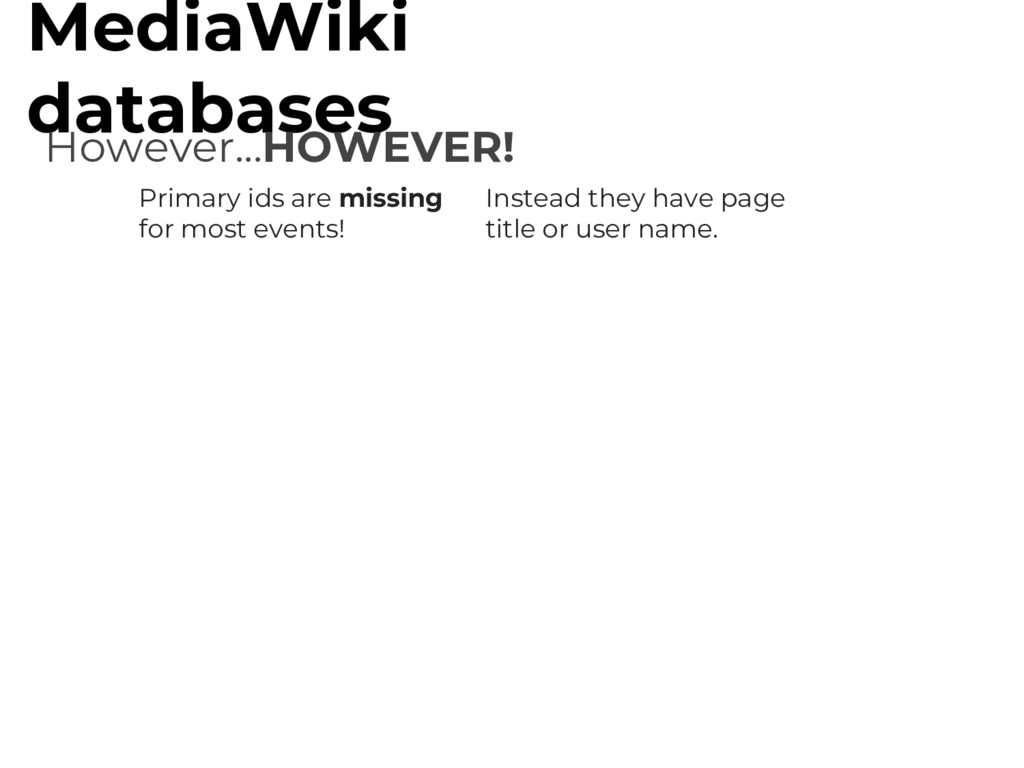
Instead they have page title or user name. Pages and users are renamed all the time! Data is stored in different formats depending on MediaWiki version that created the log record
Instead they have page title or user name. Pages and users are renamed all the time! Data is stored in different formats depending on MediaWiki version that created the log record sometimes in PHP encoded blobs!
Instead they have page title or user name. Pages and users are renamed all the time! Data is stored in different formats depending on MediaWiki version that created the log record page and user properties might be in different fields depending on age of event! sometimes in PHP encoded blobs!
Instead they have page title or user name. Pages and users are renamed all the time! Data is stored in different formats depending on MediaWiki version that created the log record Durations of user blocks is stored in 7 different date formats! page and user properties might be in different fields depending on age of event! sometimes in PHP encoded blobs!
Instead they have page title or user name. Pages and users are renamed all the time! Data is stored in different formats depending on MediaWiki version that created the log record Durations of user blocks is stored in 7 different date formats! page and user properties might be in different fields depending on age of event! Some revisions are historically orphaned (no existent page IDs!) sometimes in PHP encoded blobs!
Instead they have page title or user name. Pages and users are renamed all the time! Data is stored in different formats depending on MediaWiki version that created the log record Durations of user blocks is stored in 7 different date formats! page and user properties might be in different fields depending on age of event! Some revisions are historically orphaned (no existent page IDs!) Some page IDs were reused for different pages! (I guess IDs were a scarce commodity in 2006?) sometimes in PHP encoded blobs!
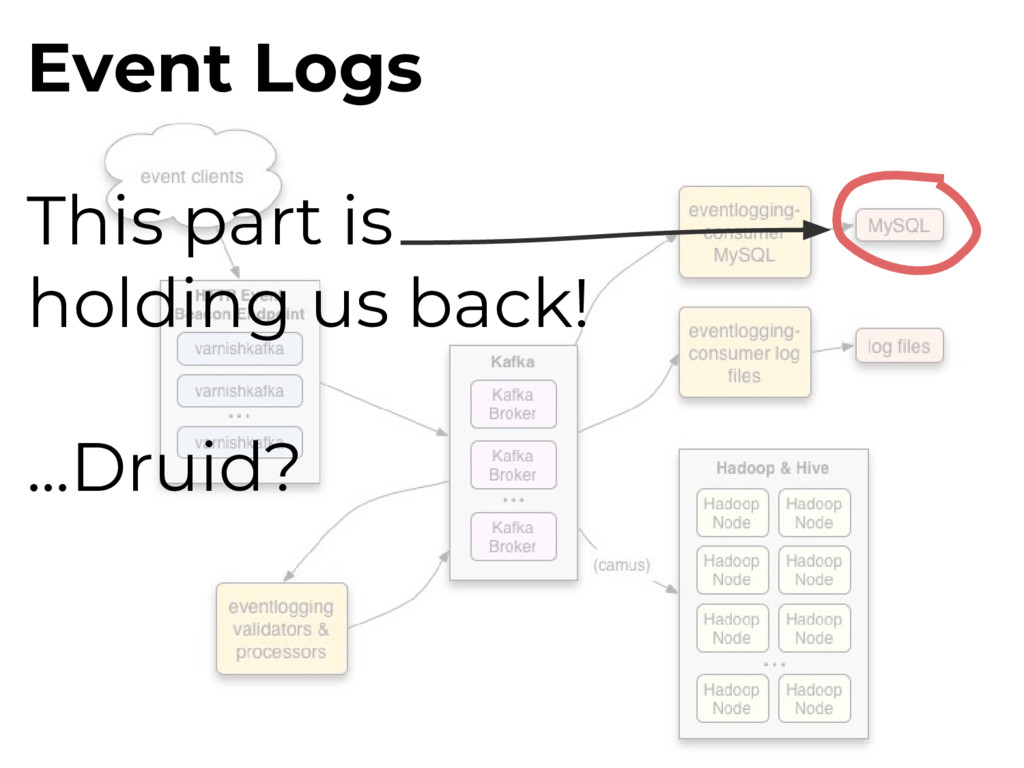
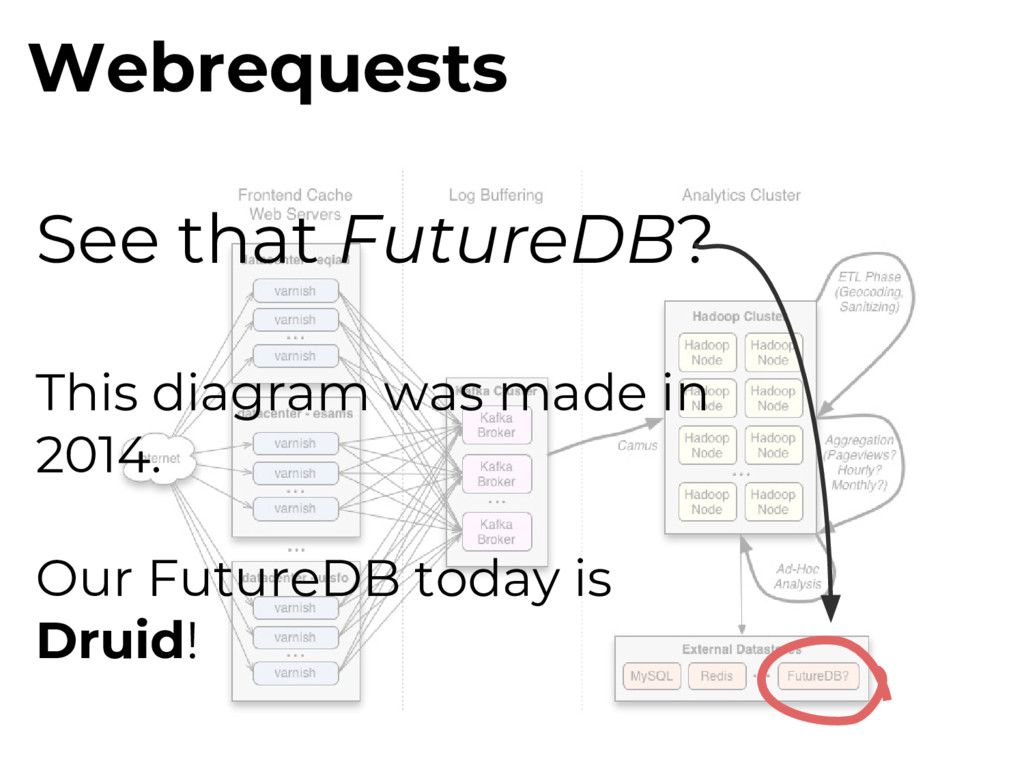
that iterate over imported snapshot of all MediaWiki databases. Final output: large denormalized history Hive table of all MediaWiki events across all Wikimedia sites
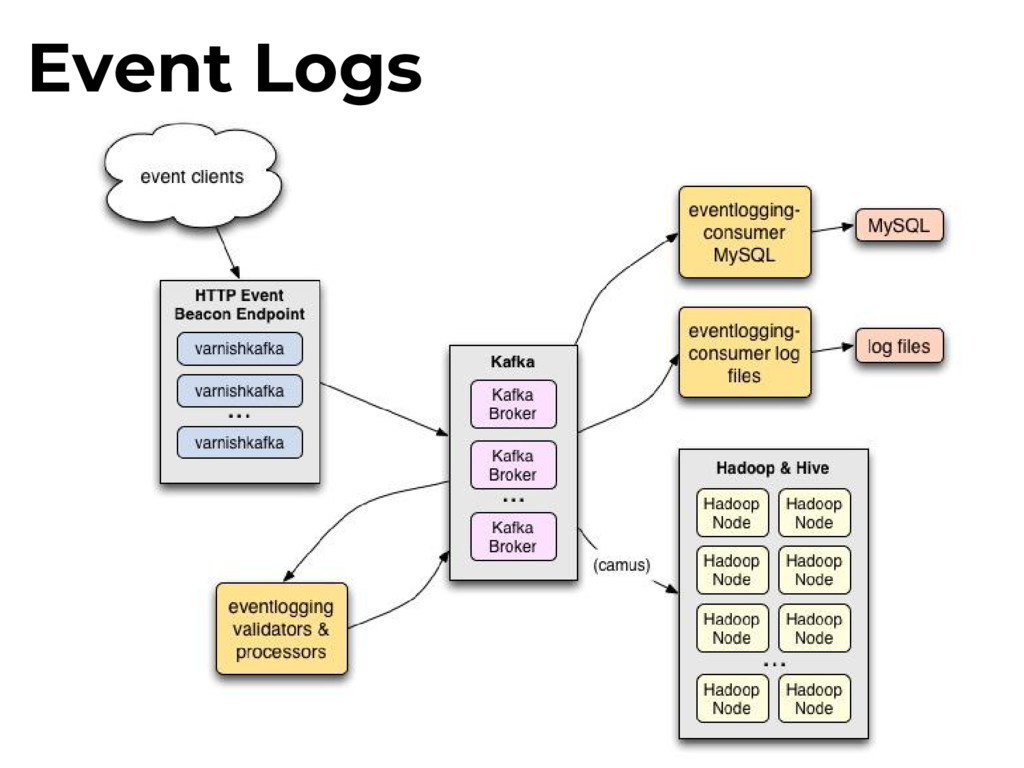
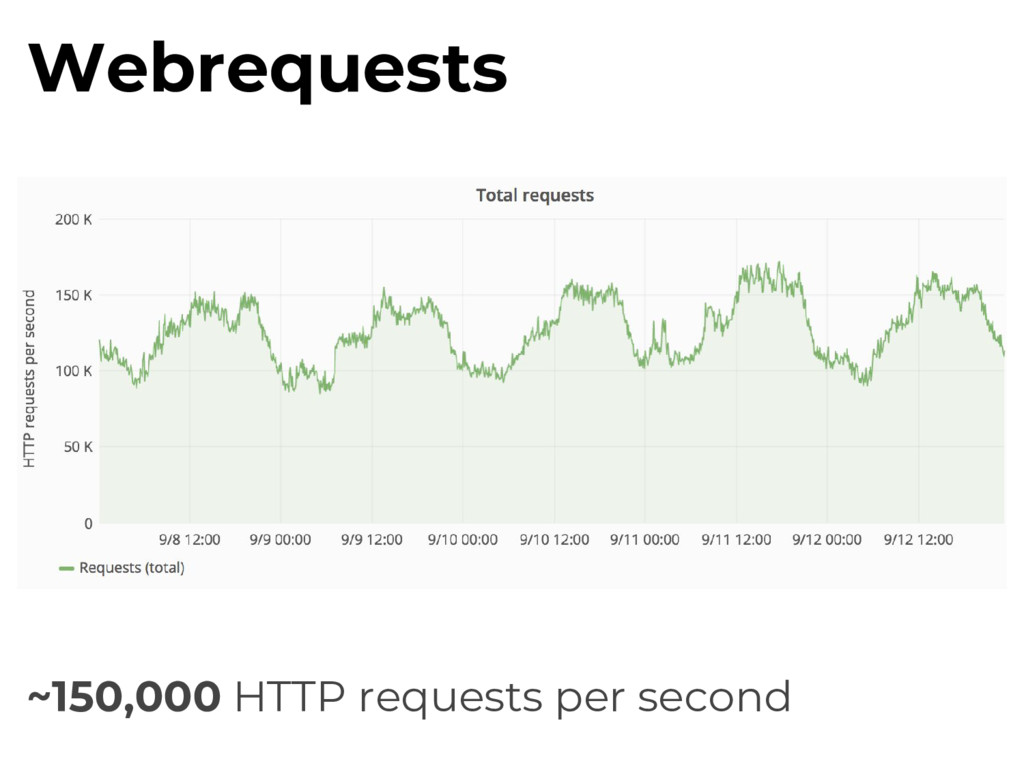
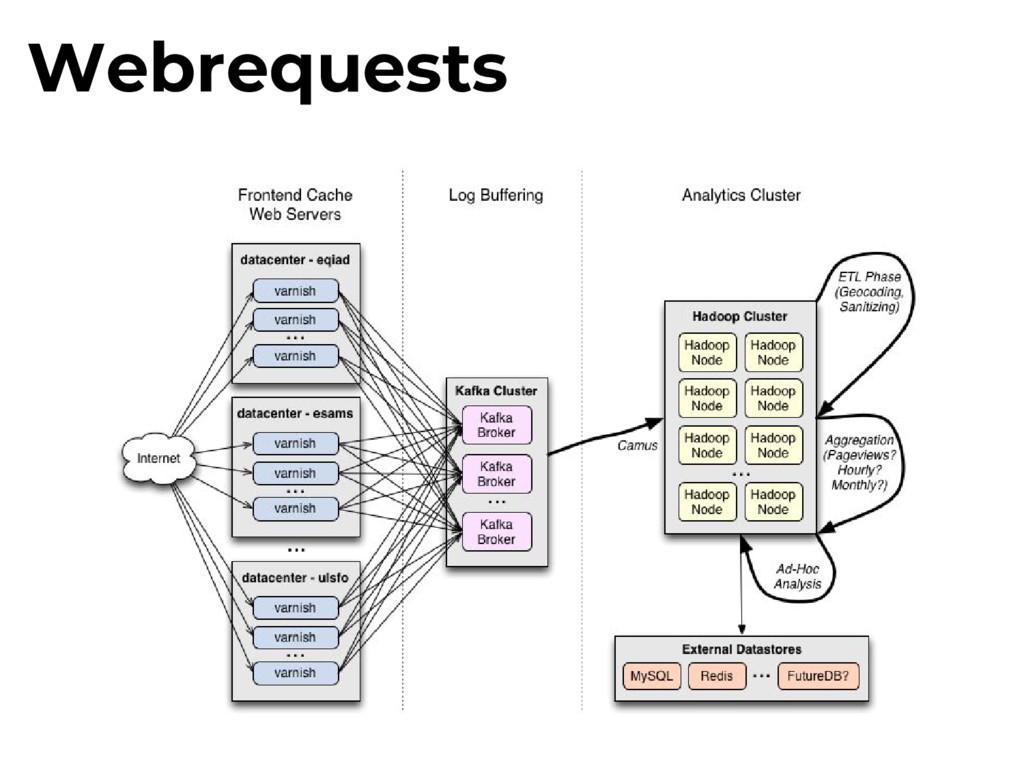
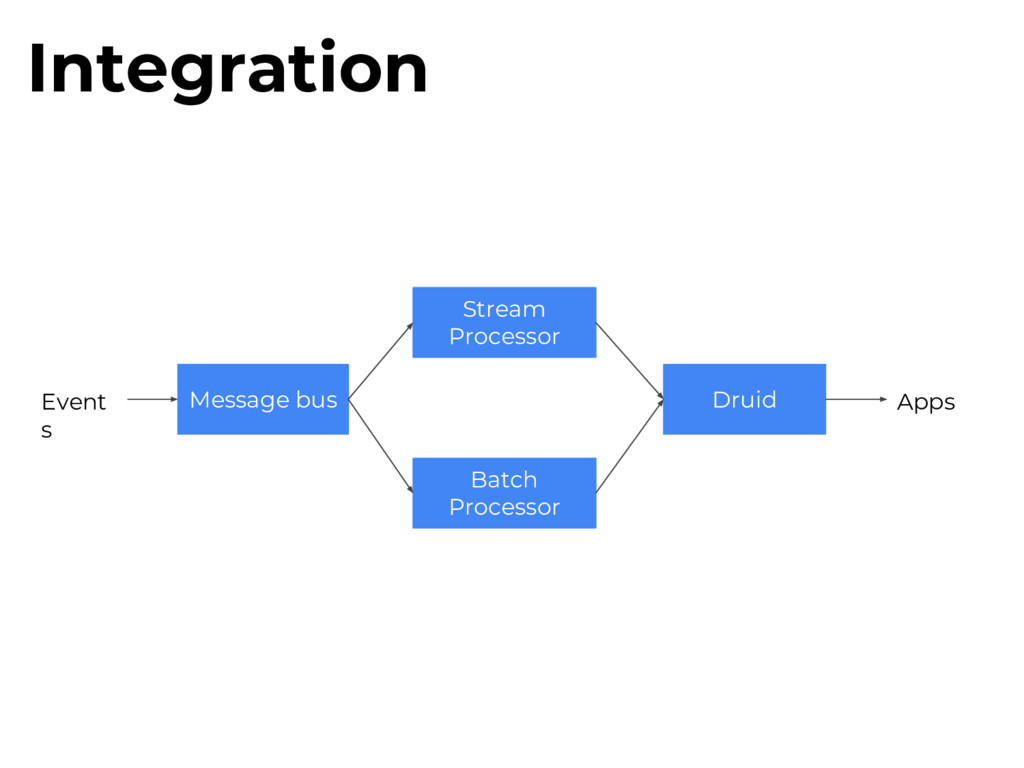
log varnishlog apps can access in Varnish’s logs in memory. Varnishncsa Varnishlog -> stdout formatter Wikimedia patched this to send logs over UDP. Webrequests
Tees out and samples traffic to custom filters. multicast relay socat relay sends varnishncsa traffic to a multicast group, allowing for multiple udp2log consumers. Webrequests
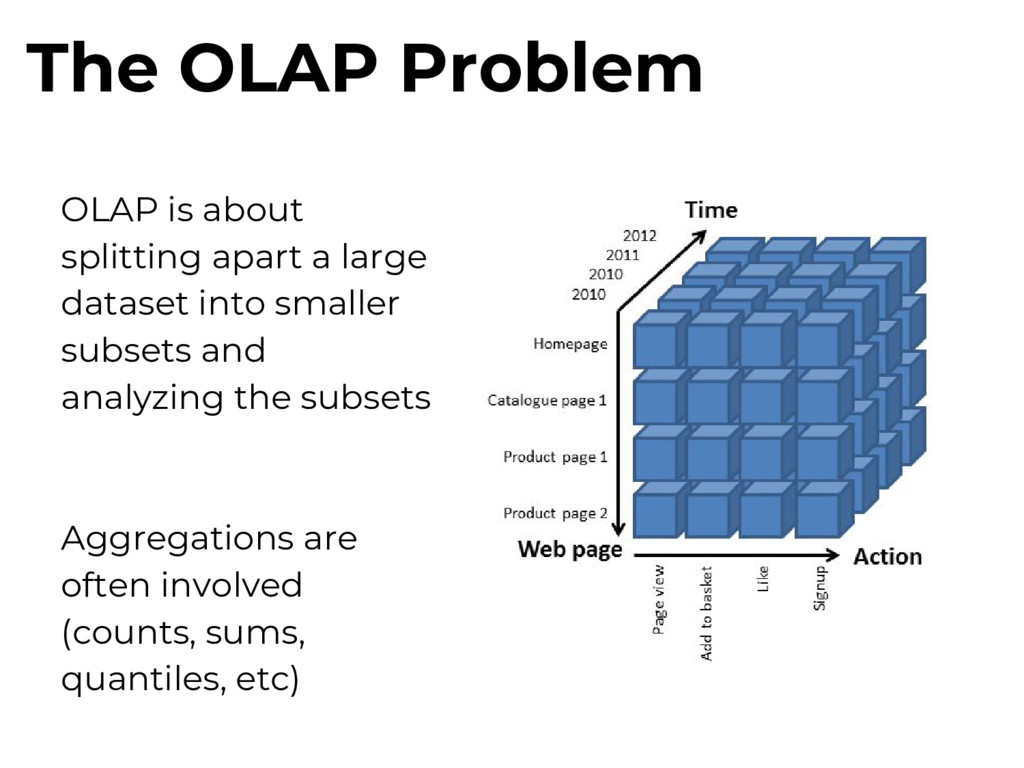
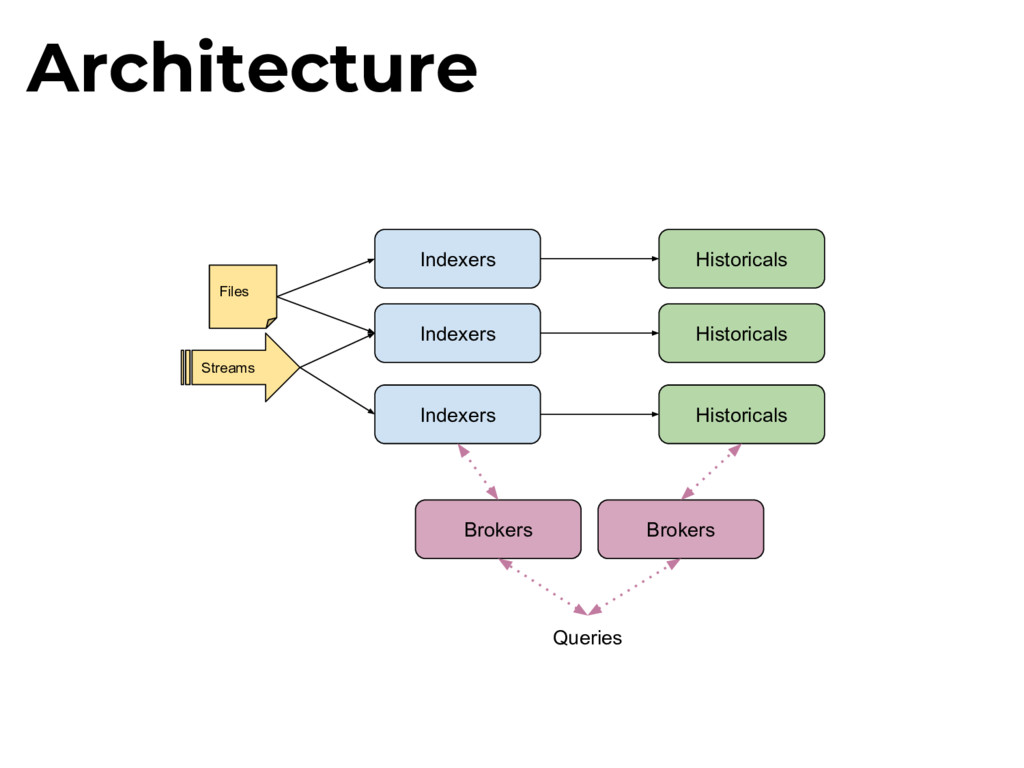
with some really nice GUIs (Pivot, Superset, etc.), which provides a lot of value for us. and we get a fast scalable OLAP database, with realtime support
cardinality: each column may have millions of unique values Multi-tenancy: many concurrent users Freshness: load from streams, not batch files OLAP at scale is hard
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Justin Bieber → [0, 1, 2] → [111000] Ke$ha →](https://files.speakerdeck.com/presentations/ddc90de36358458fb24e04d8e83ee96d/slide_99.jpg){kind=link}
{kind=link}
{kind=link}
![timestamp domain gender clicked unique_users 2011-01-01T00:00:00Z bieber.com Female 1 [approximate_sketch]](https://files.speakerdeck.com/presentations/ddc90de36358458fb24e04d8e83ee96d/slide_102.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}