Many exact queries require computation and storage that scale linearly or superlinearly in the data. There exist many classes of problems for which exact results are not necessary. Druid has long provided support for various approximate algorithms and sketches, and recently Yahoo has been doing some work to integrate new sketch algorithms directly into Druid. We will talk about the theta sketch algorithm that Yahoo has developed and how it can be leveraged for analytics in Druid.
{kind=link}
{kind=link}
{kind=link}
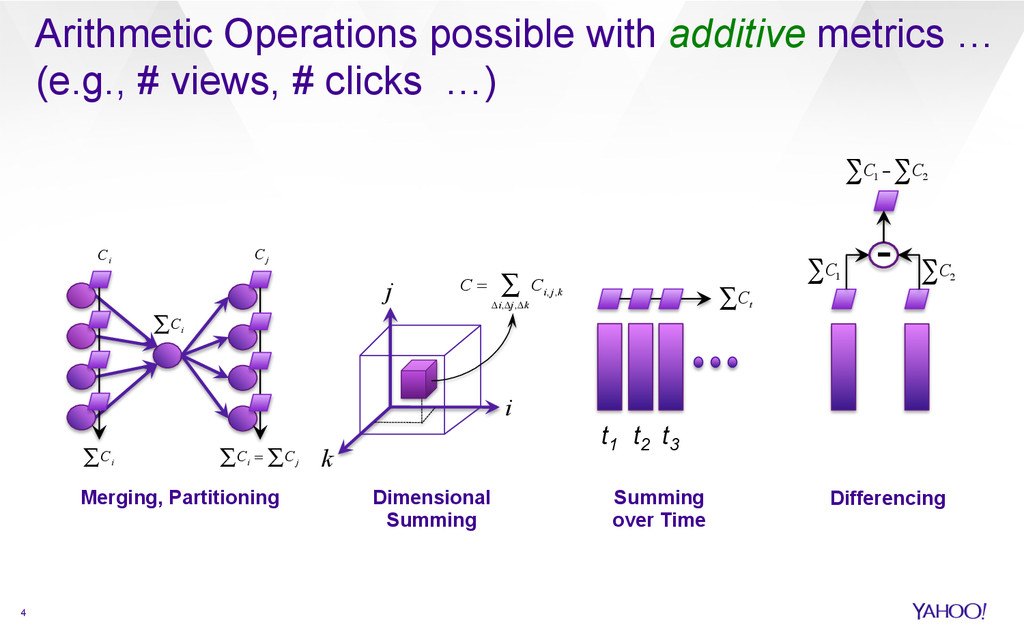{kind=link}
{kind=link}
{kind=link}
{kind=link}
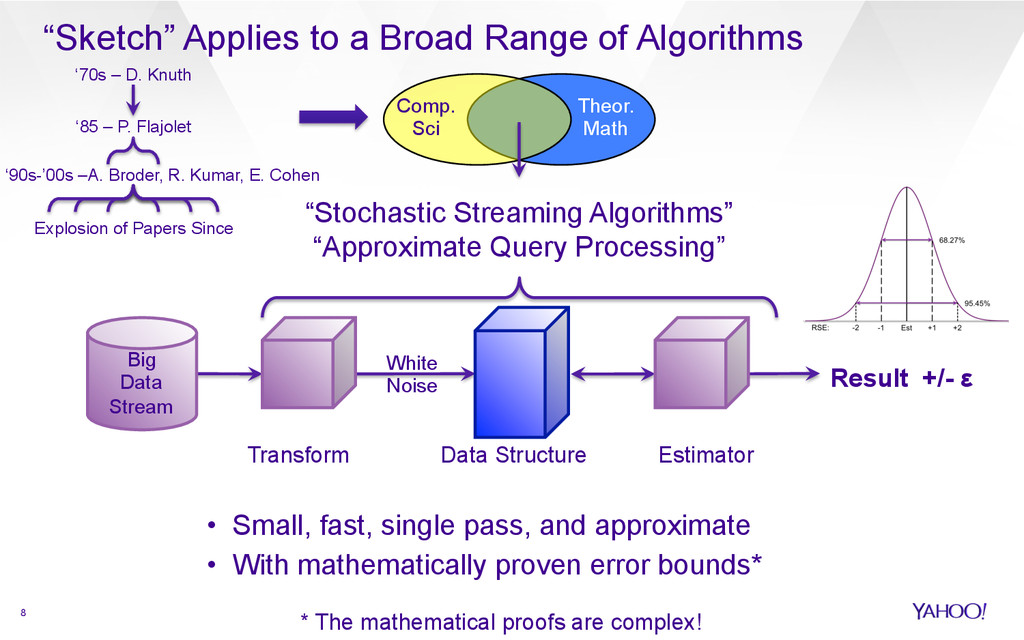{kind=link}
{kind=link}
{kind=link}
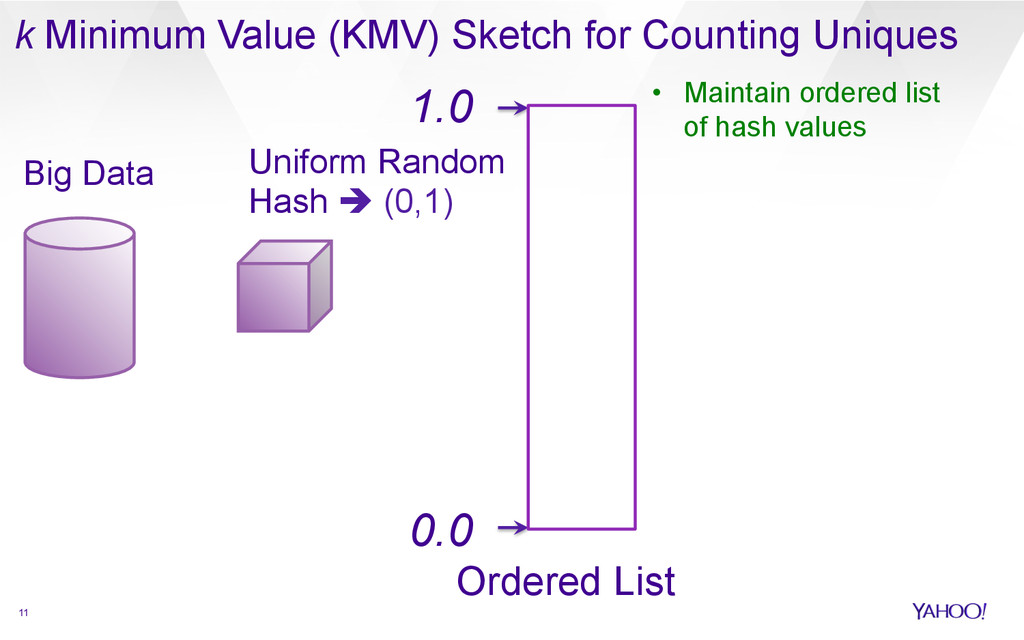{kind=link}
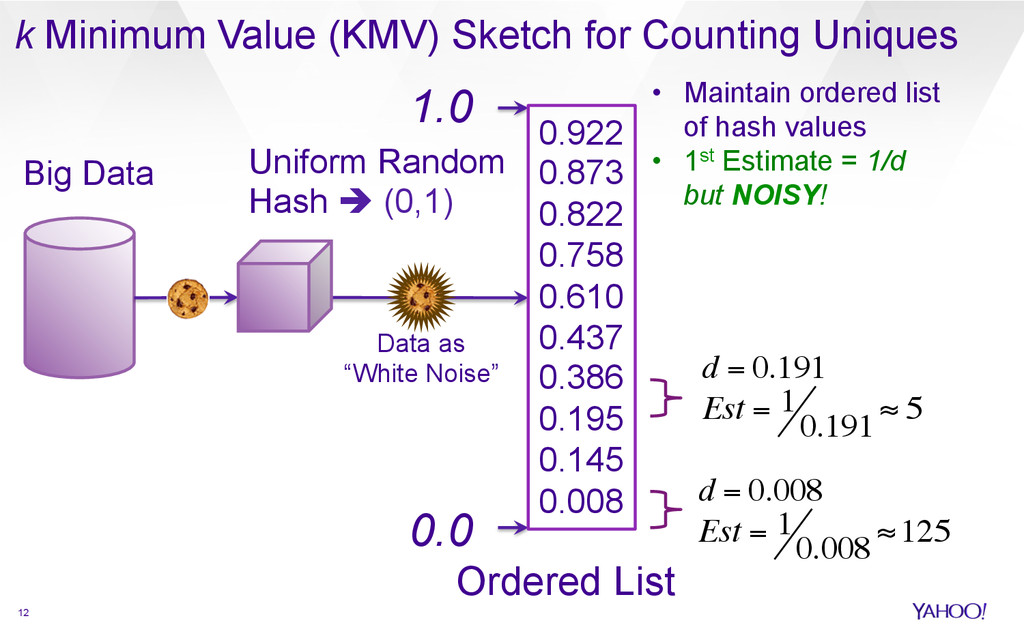{kind=link}
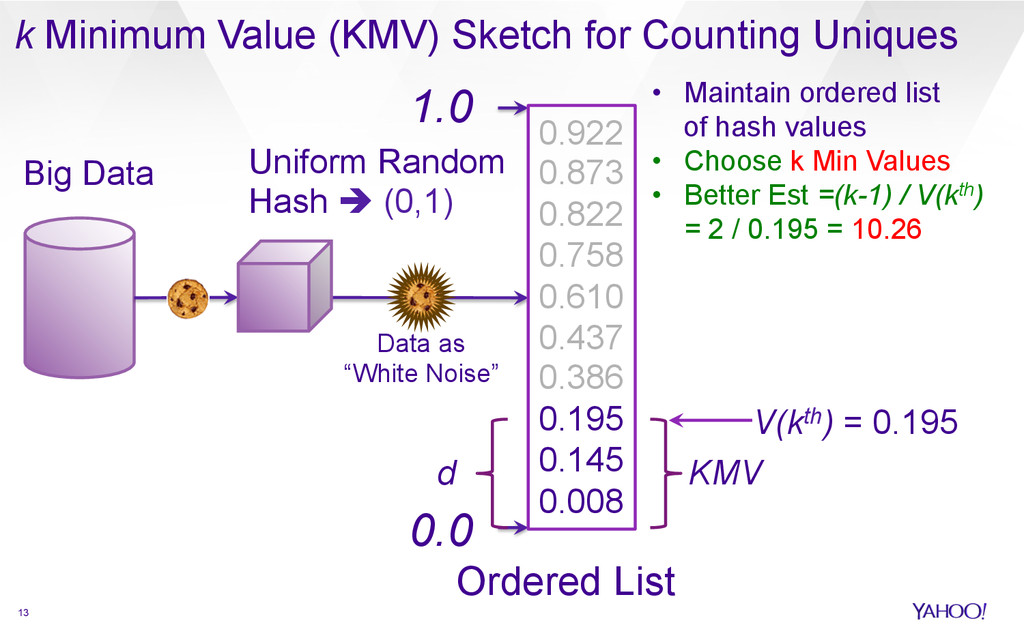{kind=link}
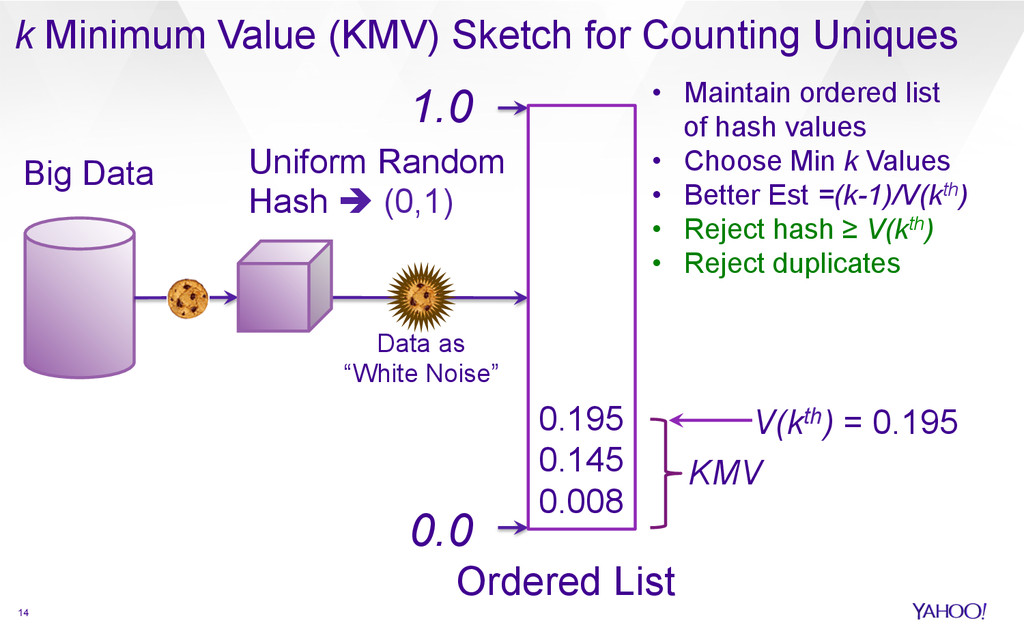{kind=link}
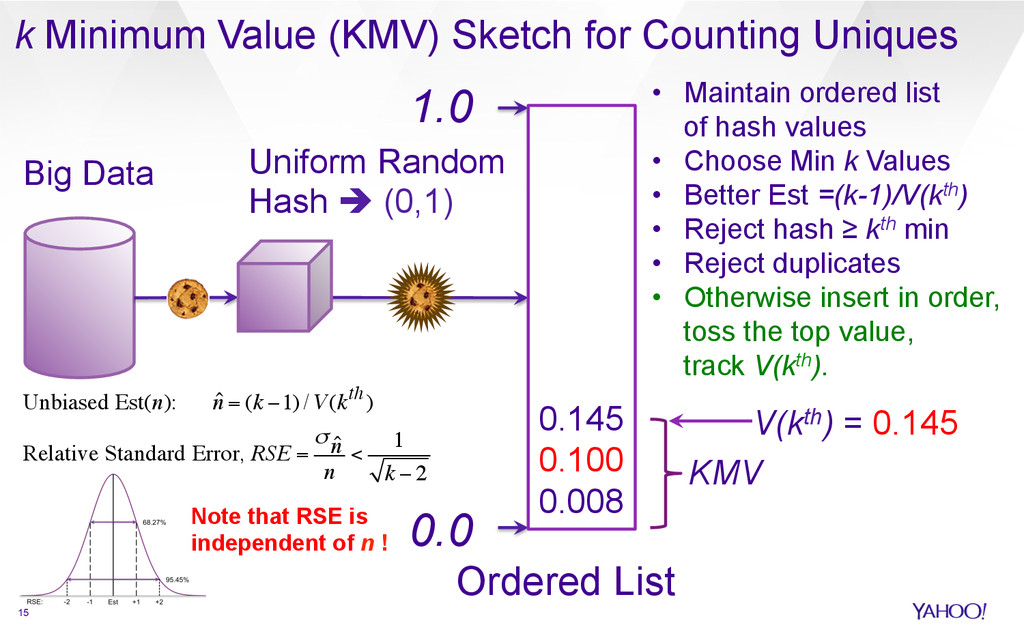{kind=link}
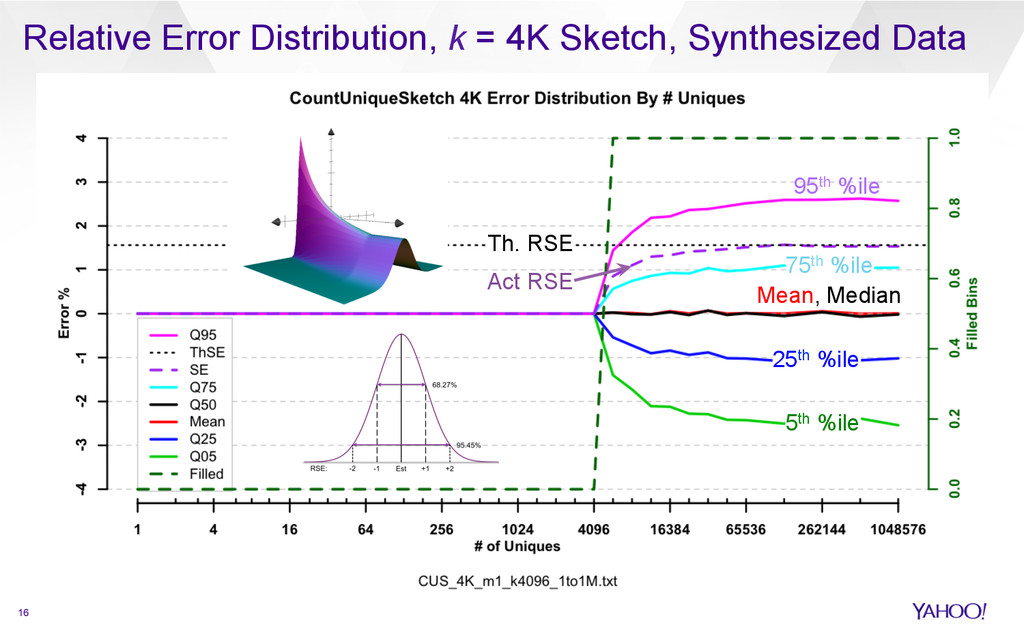{kind=link}
{kind=link}
{kind=link}
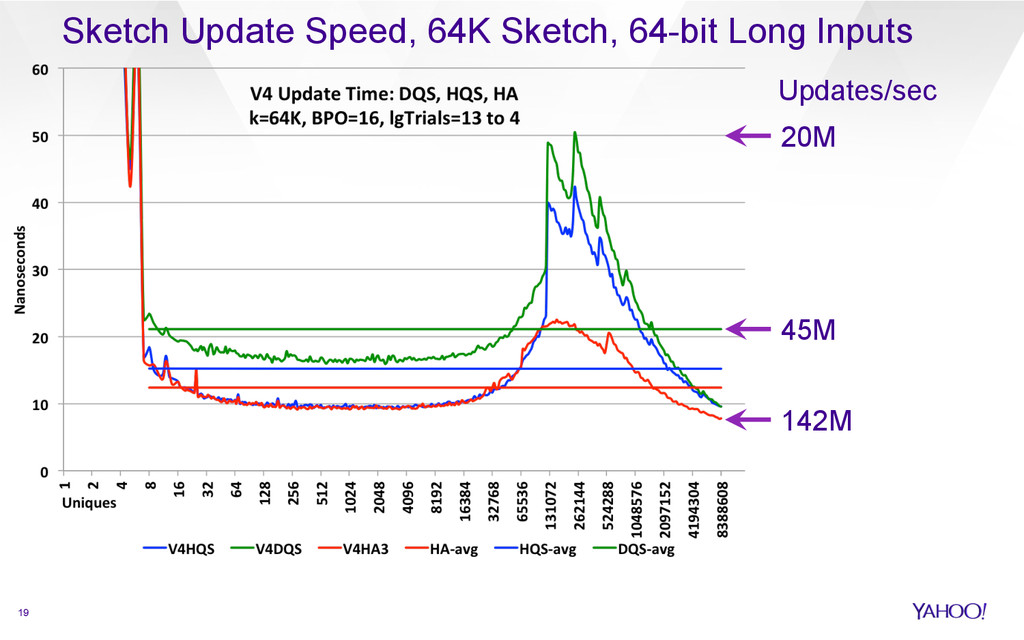{kind=link}
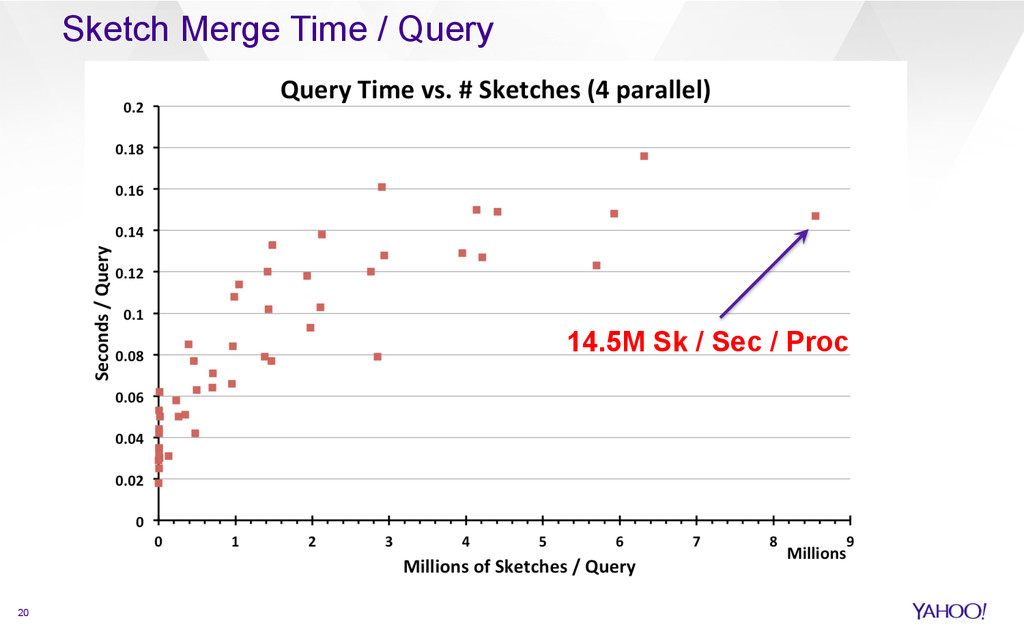{kind=link}
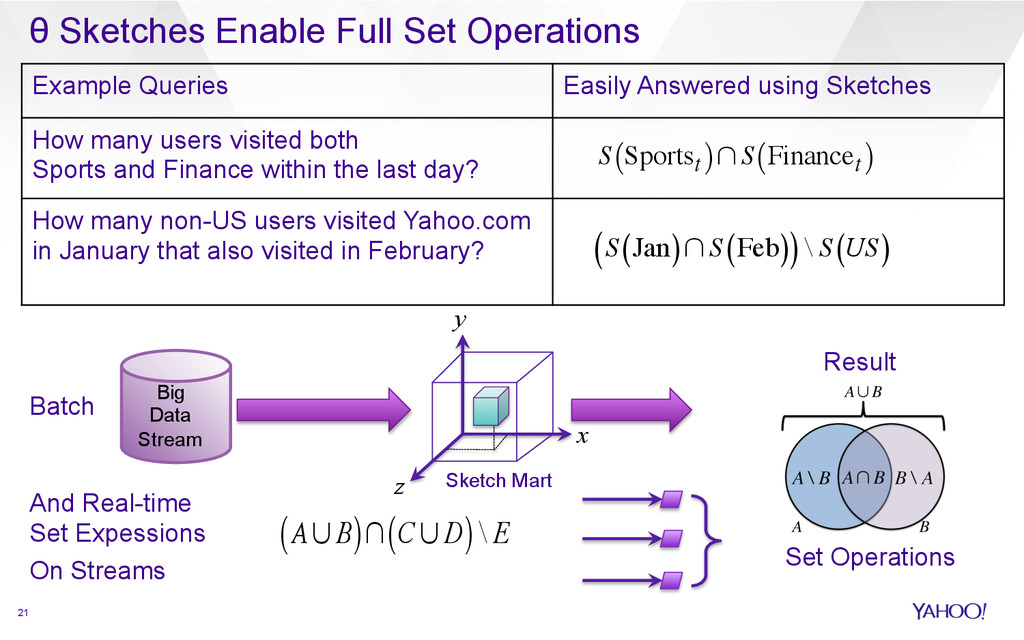{kind=link}
{kind=link}
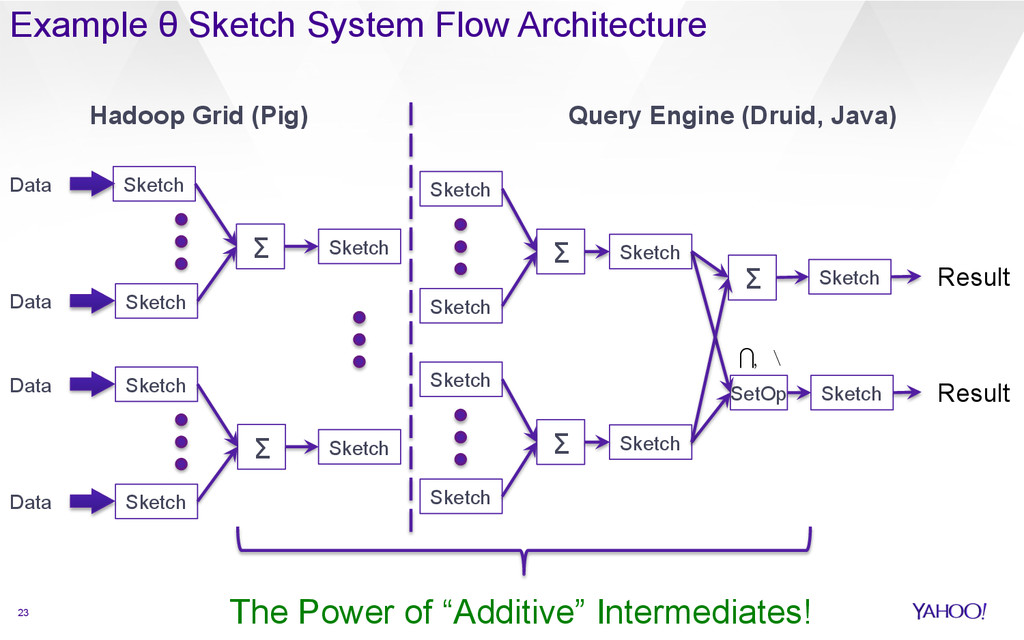{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}