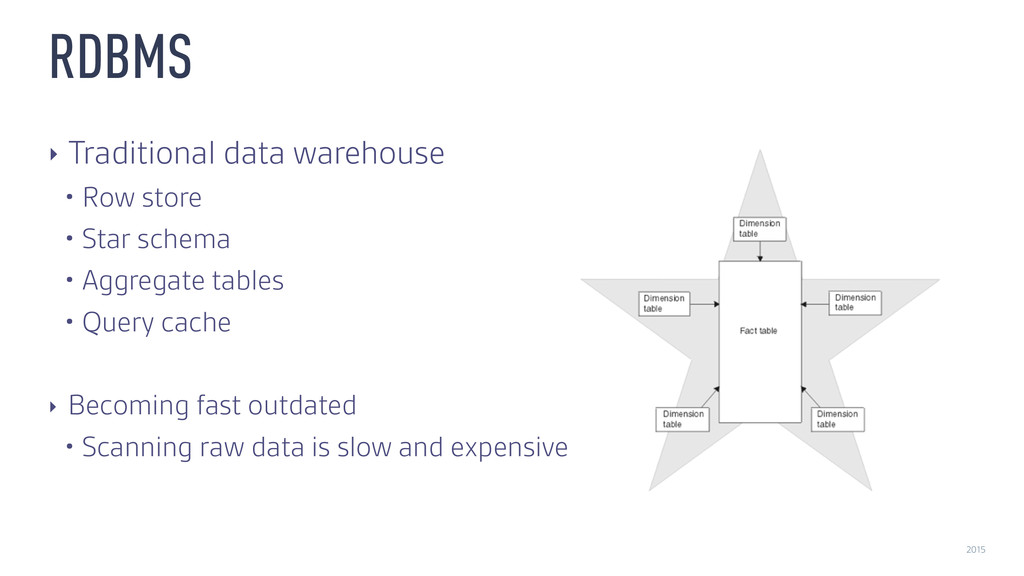
is complex! • Data manipulations/ETL, machine learning, IoT, etc. • Building data systems for business intelligence applications ‣ Dozens of solutions, projects, and methodologies ‣ How to choose the right tools for the job?
adopted, its limitations also become more well known ‣ General computing frameworks can handle many different distributed computing problems ‣ They are also sub-optimal for many use cases ‣ Analytic queries are inefficient ‣ Specialized technologies are adopted to address these inefficiencies
• Aggregate measures over time, broken down by dimensions • Revenue over time broken down by product type • Top selling products by volume in San Francisco • Number of unique visitors broken down by age • Not dumping the entire dataset • Not examining individual events
a subset of queries • Exponential scaling costs ‣ Range scans • Primary key: dimensions/attributes • Value: measures/metrics (things to aggregate) • Still too slow! KEY/VALUE STORES
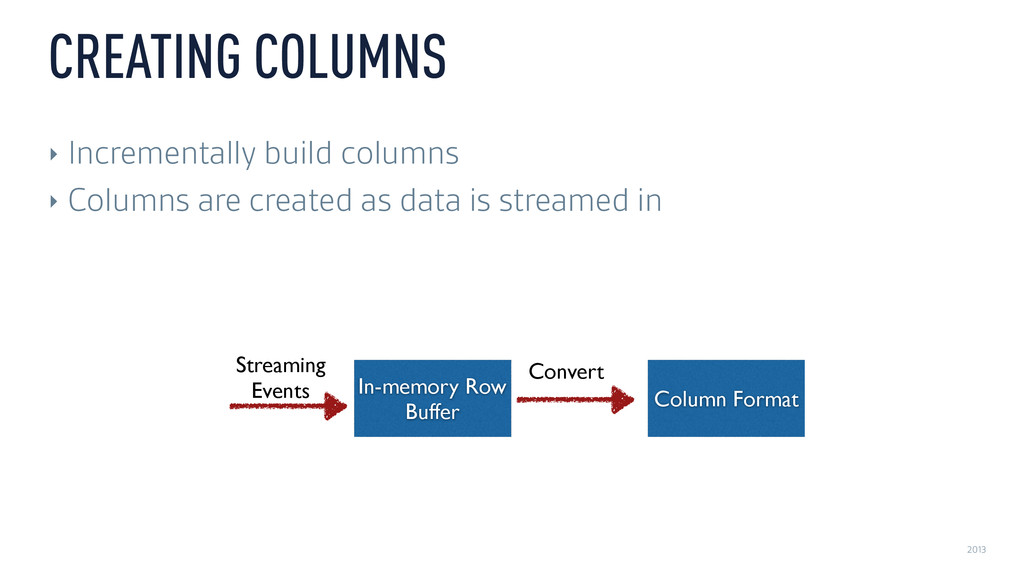
‣ Different compression algorithms for different columns ‣ Encoding for string columns ‣ Compression for measure columns ‣ Different indexes for different columns COLUMN STORES
event data and BI queries ‣ Supports lots of concurrent reads ‣ Streaming data ingestion ‣ Supports extremely fast filters ‣ Ideal for powering user-facing analytic applications
events • Over 3M events/s • 90% of queries < 1 second ‣ Growing Community • 120+ contributors • Many client libraries and UIs: R, Python, Perl, Node.js, Grafana, etc. • Used in production at numerous large and small organizations
[/foo, /bar, /bar] [2, 1, 1] [145e10] [carol] [/baz] [1] [144e10, 144e10, 144e10, 145e10] [alice, alice, bob, carol] [/foo, /bar, /bar, /baz] [2, 1, 1, 1] Merge all data in a single segment queried along with all existing data target size 500MB–1GB
bob, carol] [/foo, /bar, /bar, /baz] [2, 1, 1, 1] [144e10, 145e10] [carol, dave] [/qux, /baz] [1, 3] DeterminePartitionsJob IndexGeneratorJob Events Hadoop M/R Loader create a set of segments, each 500MB–1GB one reducer creates one segment can replace or append to existing data
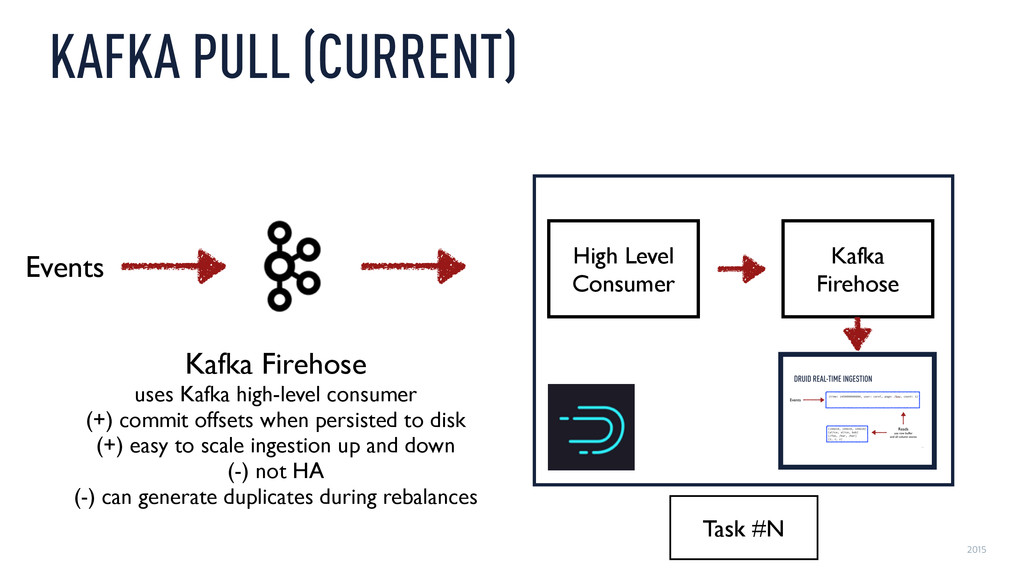
(+) commit offsets when persisted to disk (+) easy to scale ingestion up and down (-) not HA (-) can generate duplicates during rebalances High Level Consumer Kafka Firehose Events Task #N
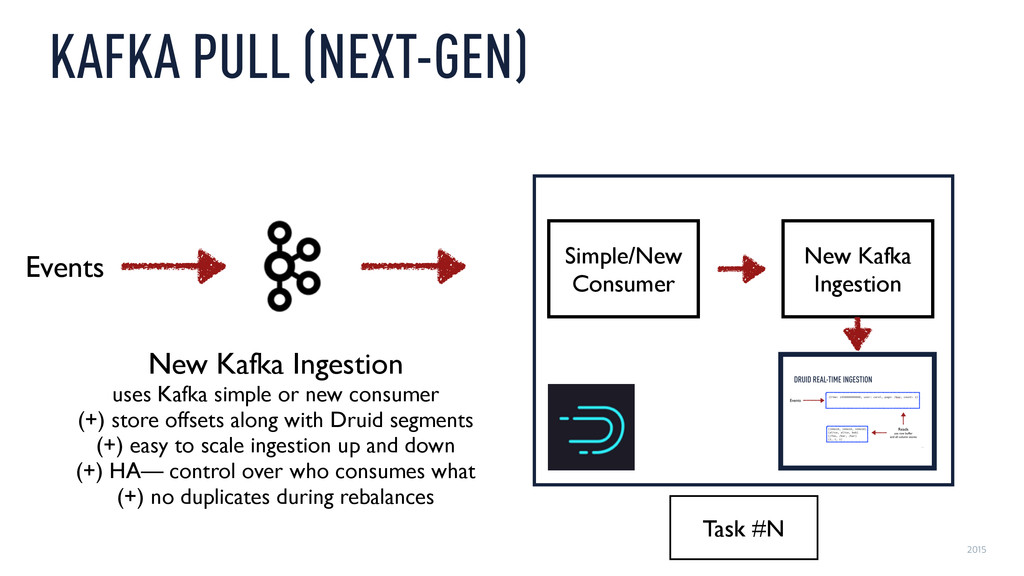
or new consumer (+) store offsets along with Druid segments (+) easy to scale ingestion up and down (+) HA— control over who consumes what (+) no duplicates during rebalances Simple/New Consumer New Kafka Ingestion Events Task #N
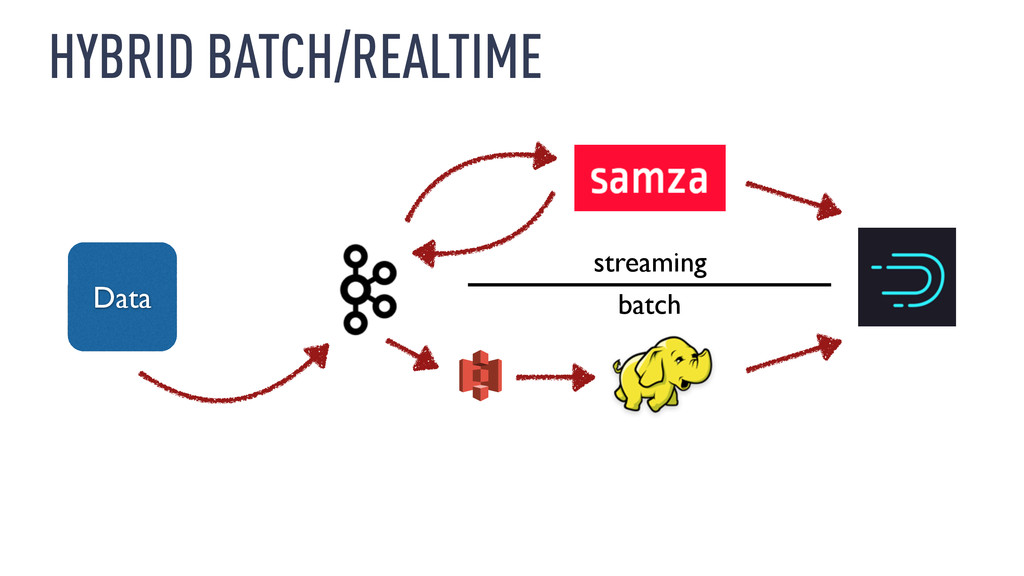
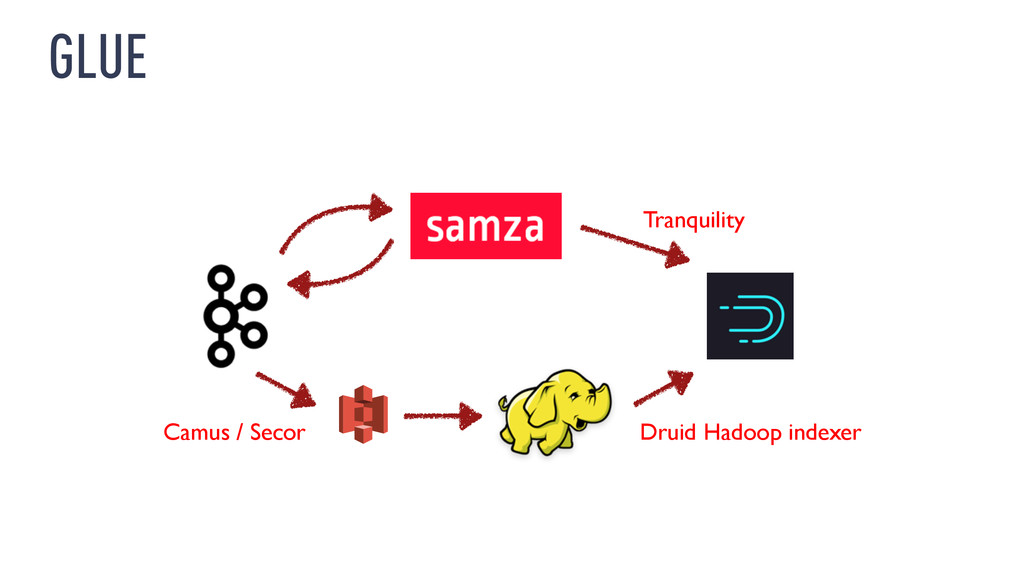
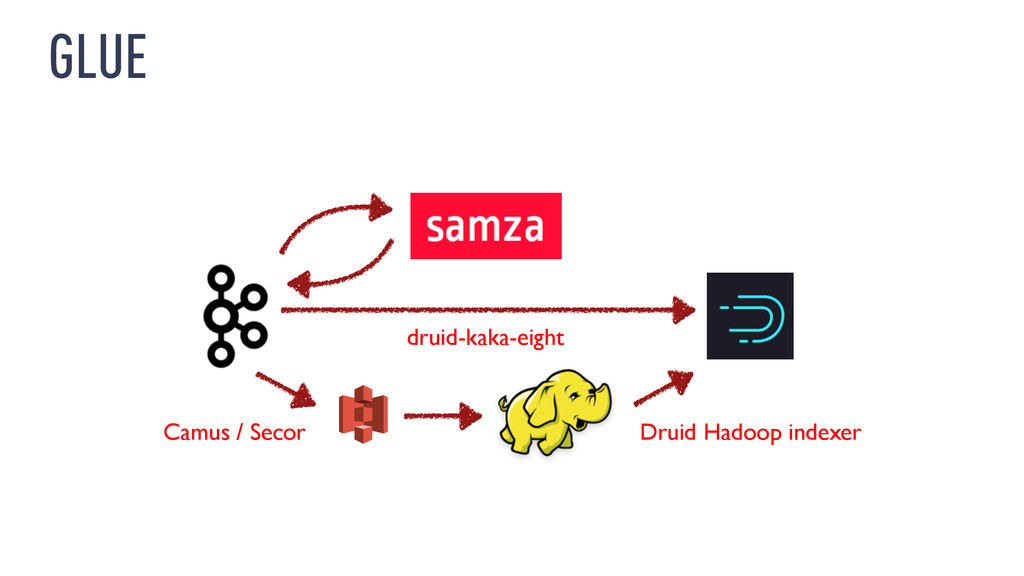
to restate existing data ‣ Limitations of current software ‣ …Kafka 0.8.x, Samza 0.9.x can generate duplicate messages ‣ …Druid 0.7.x streaming ingestion is best-effort
the input stream from the start ‣ Doesn’t require operating two systems ‣ I don’t have much experience with this ‣ http://radar.oreilly.com/2014/07/questioning-the-lambda- architecture.html
‣ Consider Samza for streaming data integration ‣ Consider Druid for interactive exploration of streams ‣ Have a reprocessing strategy if you’re interested in historical data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![2015 DRUID REAL-TIME INGESTION Events [144e10, 144e10, 144e10] [alice, alice,](https://files.speakerdeck.com/presentations/c2c5c695036d44ab8b55a7f8fed2dac0/slide_29.jpg){kind=link}
![2015 DRUID REAL-TIME INGESTION Events [144e10, 144e10, 144e10] [alice, alice,](https://files.speakerdeck.com/presentations/c2c5c695036d44ab8b55a7f8fed2dac0/slide_30.jpg){kind=link}
![2015 DRUID REAL-TIME INGESTION [144e10, 144e10, 144e10] [alice, alice, bob]](https://files.speakerdeck.com/presentations/c2c5c695036d44ab8b55a7f8fed2dac0/slide_31.jpg){kind=link}
![2015 DRUID REAL-TIME INGESTION [144e10, 144e10, 144e10] [alice, alice, bob]](https://files.speakerdeck.com/presentations/c2c5c695036d44ab8b55a7f8fed2dac0/slide_32.jpg){kind=link}
![2015 LOAD FROM HADOOP [144e10, 144e10, 144e10, 145e10] [alice, alice,](https://files.speakerdeck.com/presentations/c2c5c695036d44ab8b55a7f8fed2dac0/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}