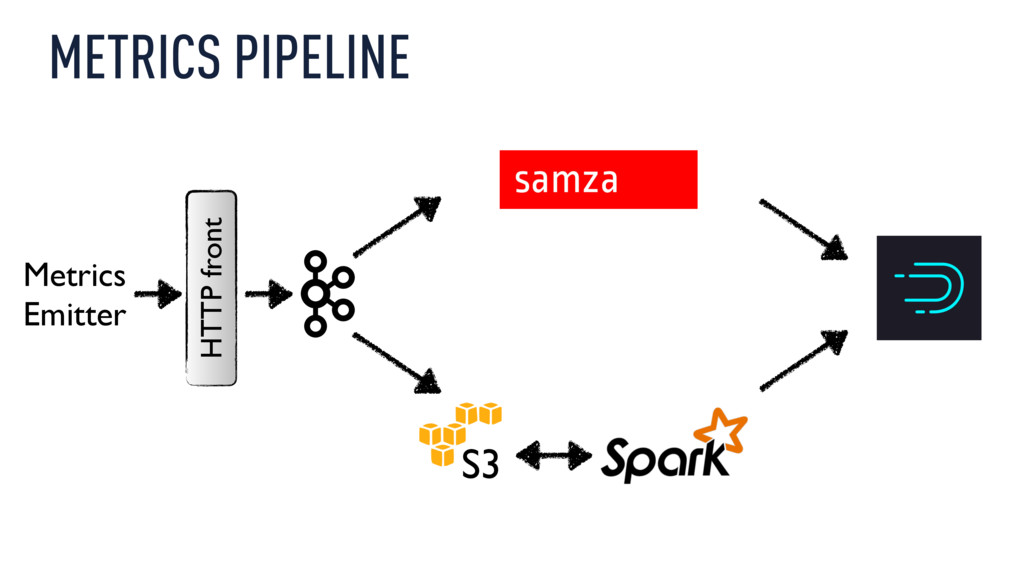
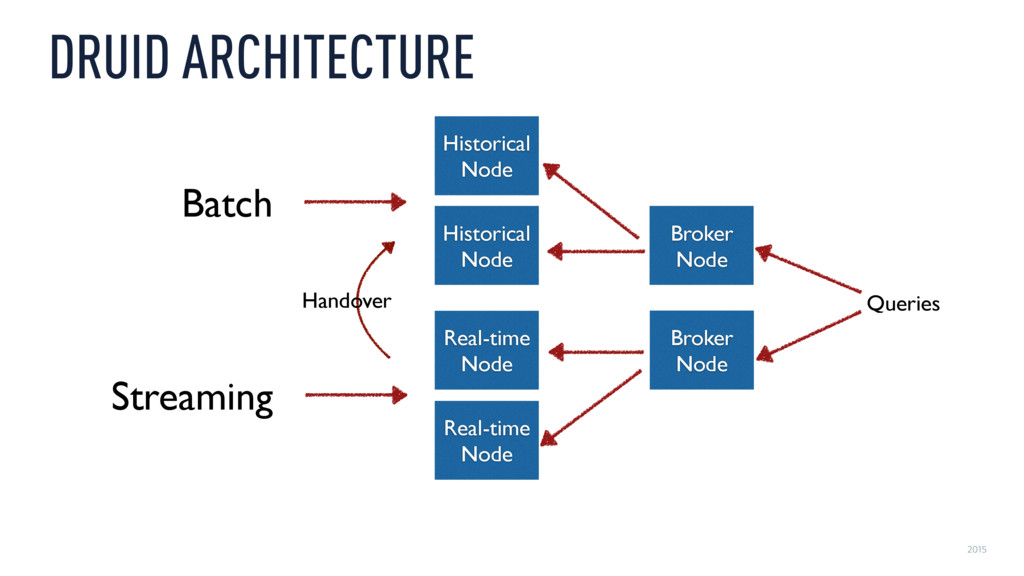
Today, Metamarkets processes over 300 billion events per day—over 100 TB going through a single pipeline built entirely on open source technologies such as Druid, Kafka, and Samza. Working at such a scale presents engineering challenges on many levels, not just in terms of design but also in terms of operations, especially when downtime is not an option.
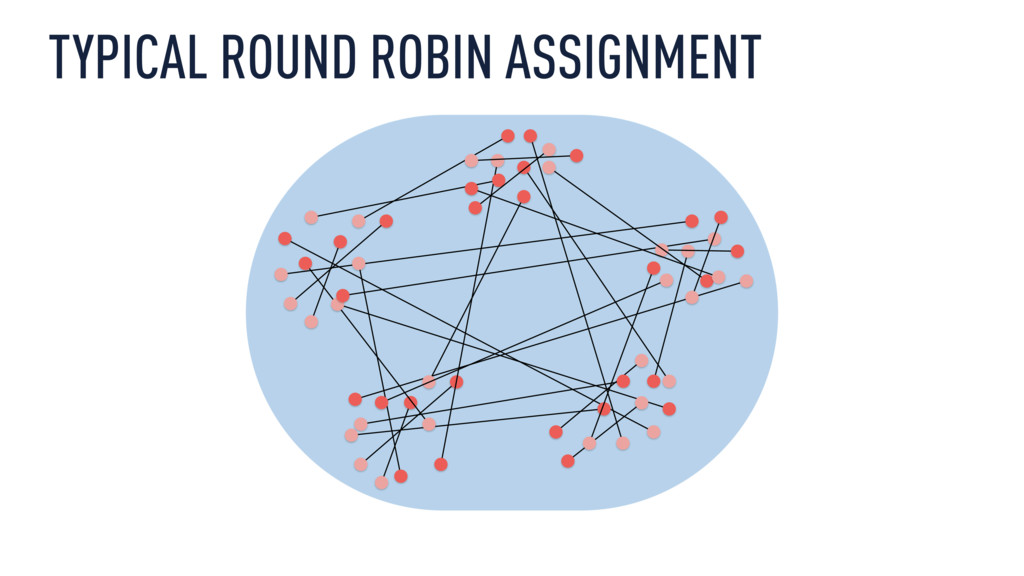
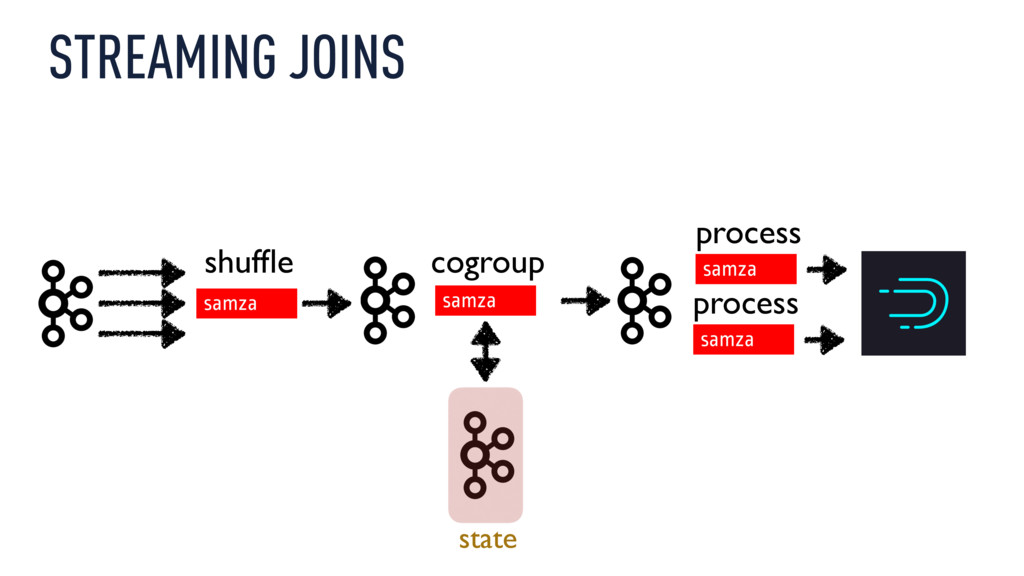
Xavier Léauté explores how Metamarkets used Kafka and Samza to build a multitenant pipeline to perform streaming joins and transformations of varying degrees of complexity and then push data into Druid to make it available for immediate, interactive analysis at a rate of several hundreds of concurrent queries per second. But as data grew an order of magnitude in the span of a few months, all systems involved started to show their limits. Xavier describes the challenges around scaling this stack and explains how the team overcame them, using extensive metric collection to manage both performance and costs and how they handle very heterogeneous processing workloads while keeping down operational complexity.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}