Using MySQL Server and Percona XtraDB Cluster we will take a look at several possible replication configurations for MySQL high-availability, disaster recovery and load-balancing. After comparing them for administration ease, scalability of reads and writes, robustness of the system for errors and time for data recovery as well as looking at how they impact your code-layer we will discuss the ins-and-outs of each setup, looking at the pros and cons, and what trade-offs you will need to make depending on your needs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
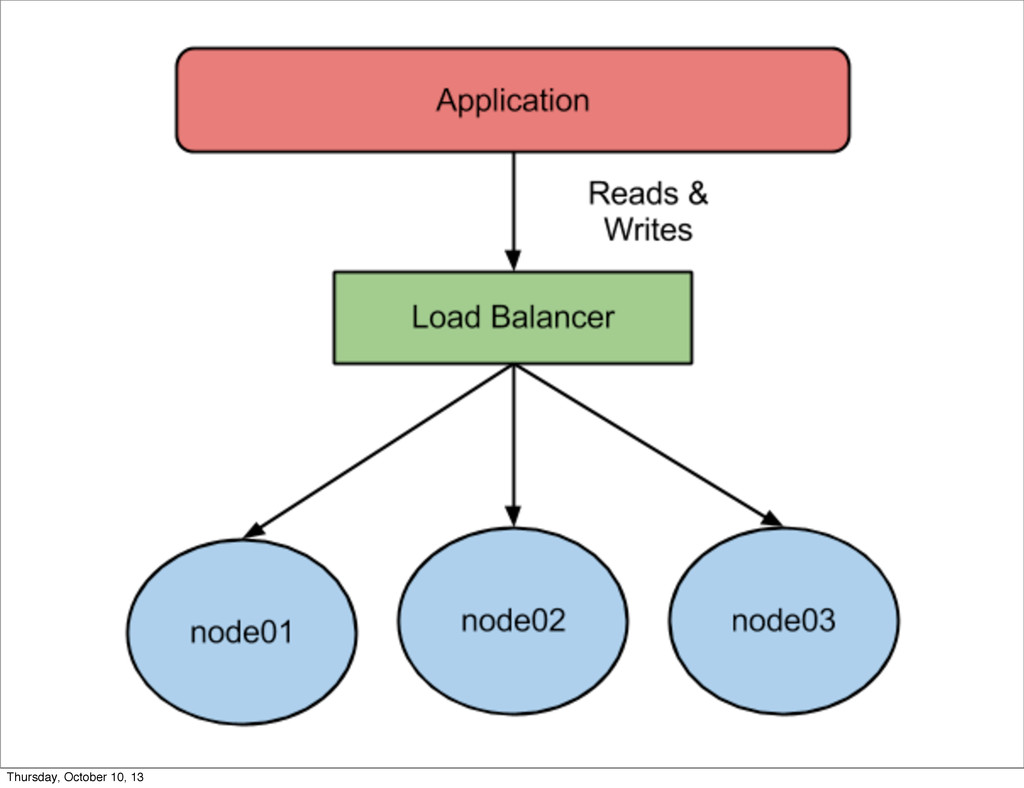{kind=link}
![Primary Server Setup [mysqld] wsrep_cluster_address=gcomm:// datadir=/var/lib/mysql user=mysql binlog_format=ROW wsrep_provider=/usr/lib/libgalera_smm.so wsrep_slave_threads=2](https://files.speakerdeck.com/presentations/67d6a00013b20131f9fe3aacfc01551e/slide_38.jpg){kind=link}
![Other Server Setup [mysqld] wsrep_cluster_address=gcomm://<ip> datadir=/var/lib/mysql user=mysql binlog_format=ROW wsrep_provider=/usr/lib/libgalera_smm.so wsrep_slave_threads=2](https://files.speakerdeck.com/presentations/67d6a00013b20131f9fe3aacfc01551e/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
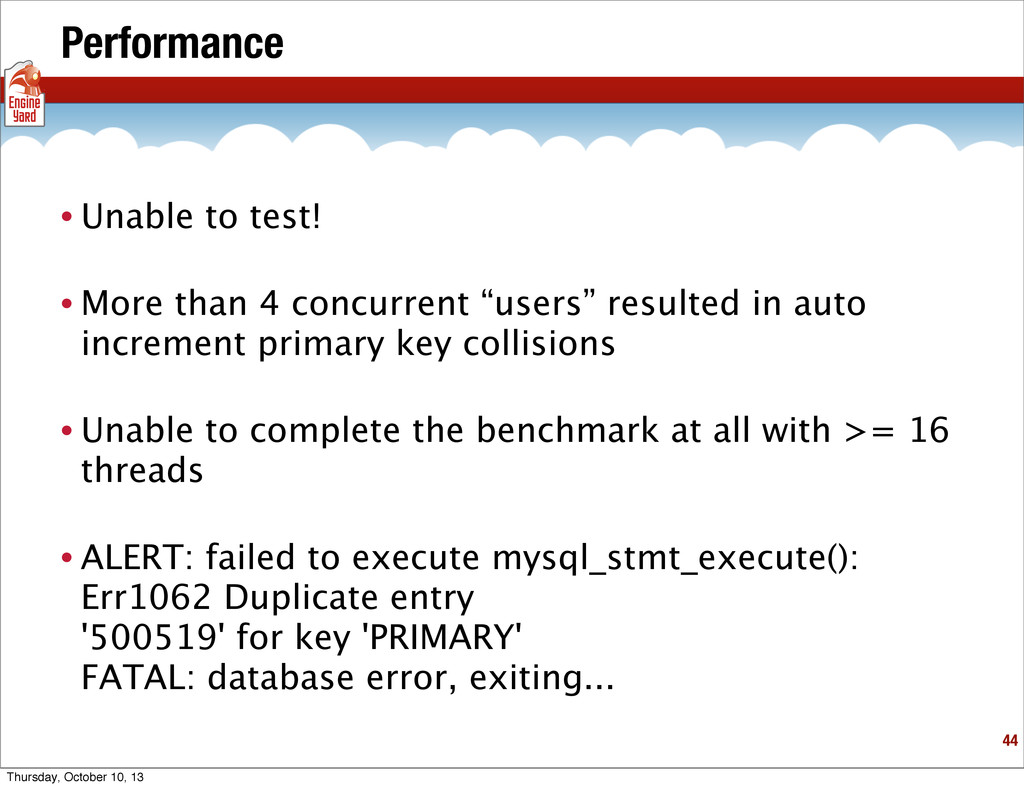{kind=link}
{kind=link}
{kind=link}
{kind=link}
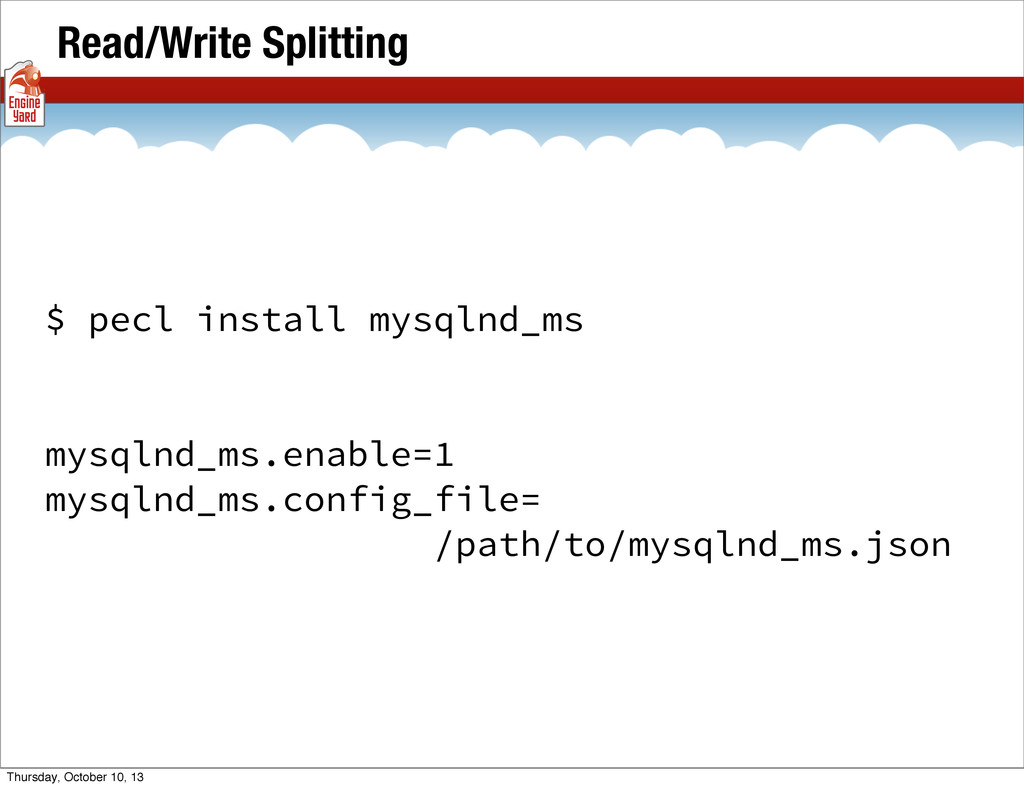{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Feedback & Questions: Feedback: https://joind.in/9093 Twitter: @dshafik Email: [email protected] http://ey.io/zc13-mysql](https://files.speakerdeck.com/presentations/67d6a00013b20131f9fe3aacfc01551e/slide_51.jpg){kind=link}