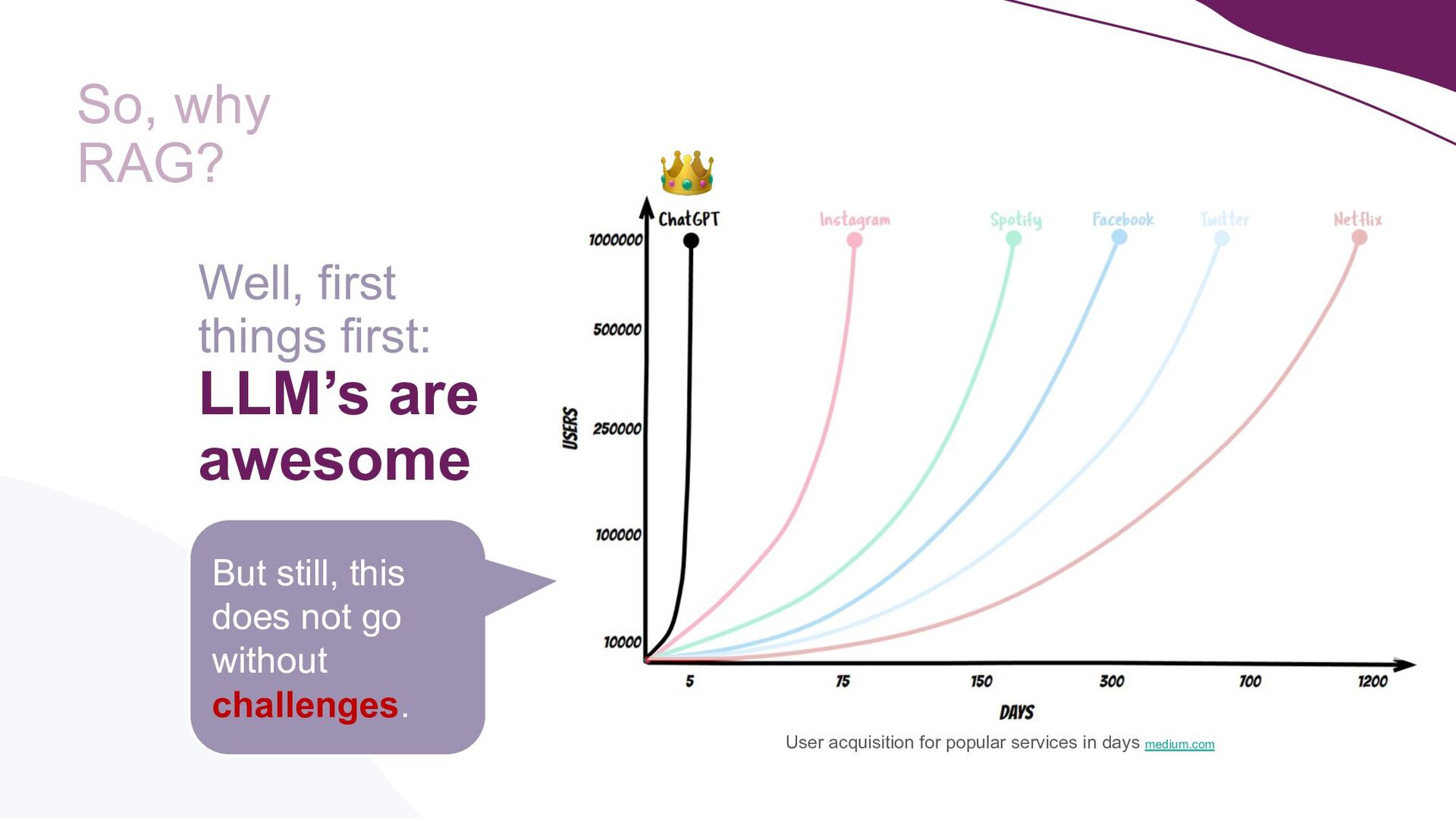
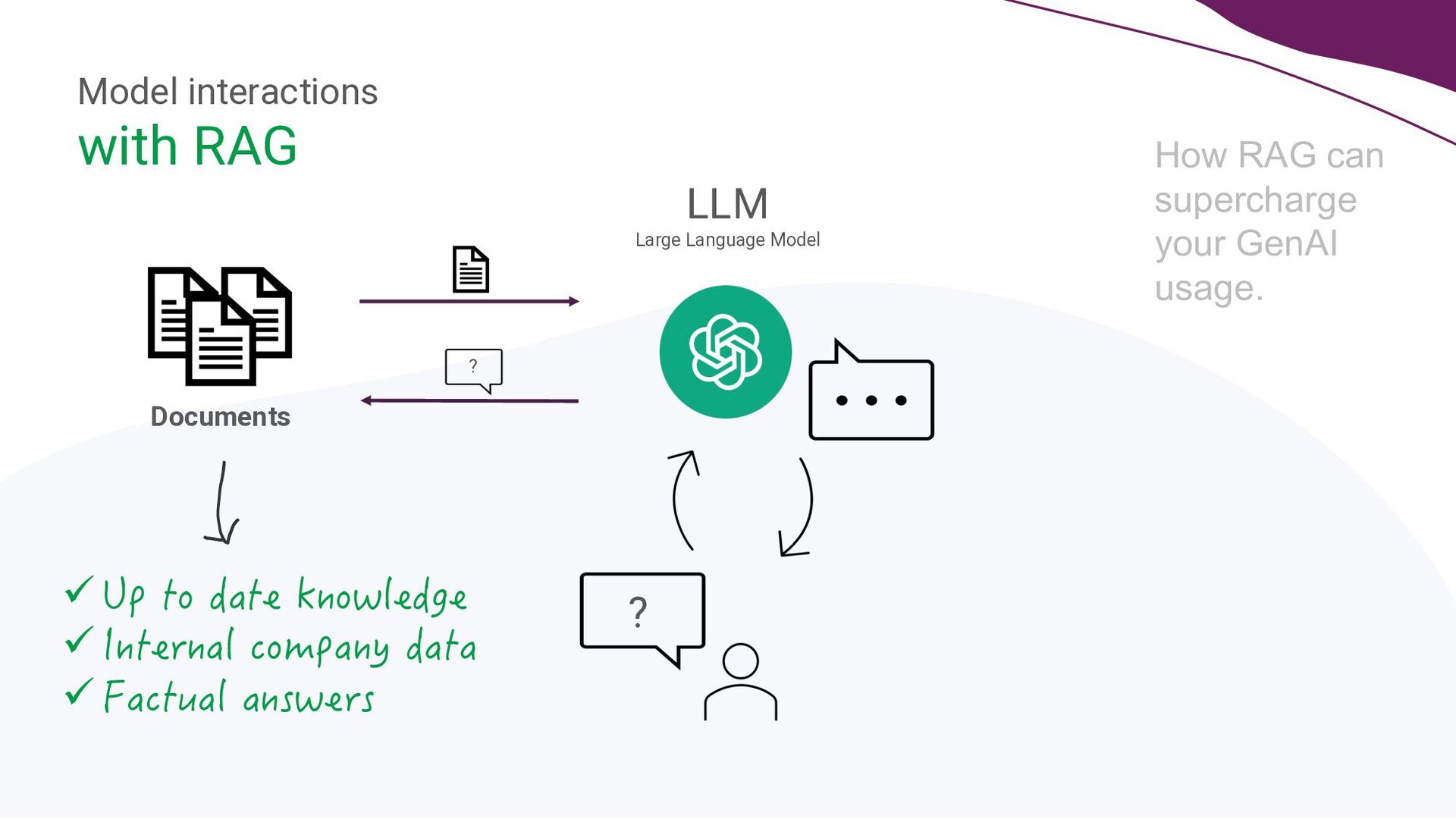
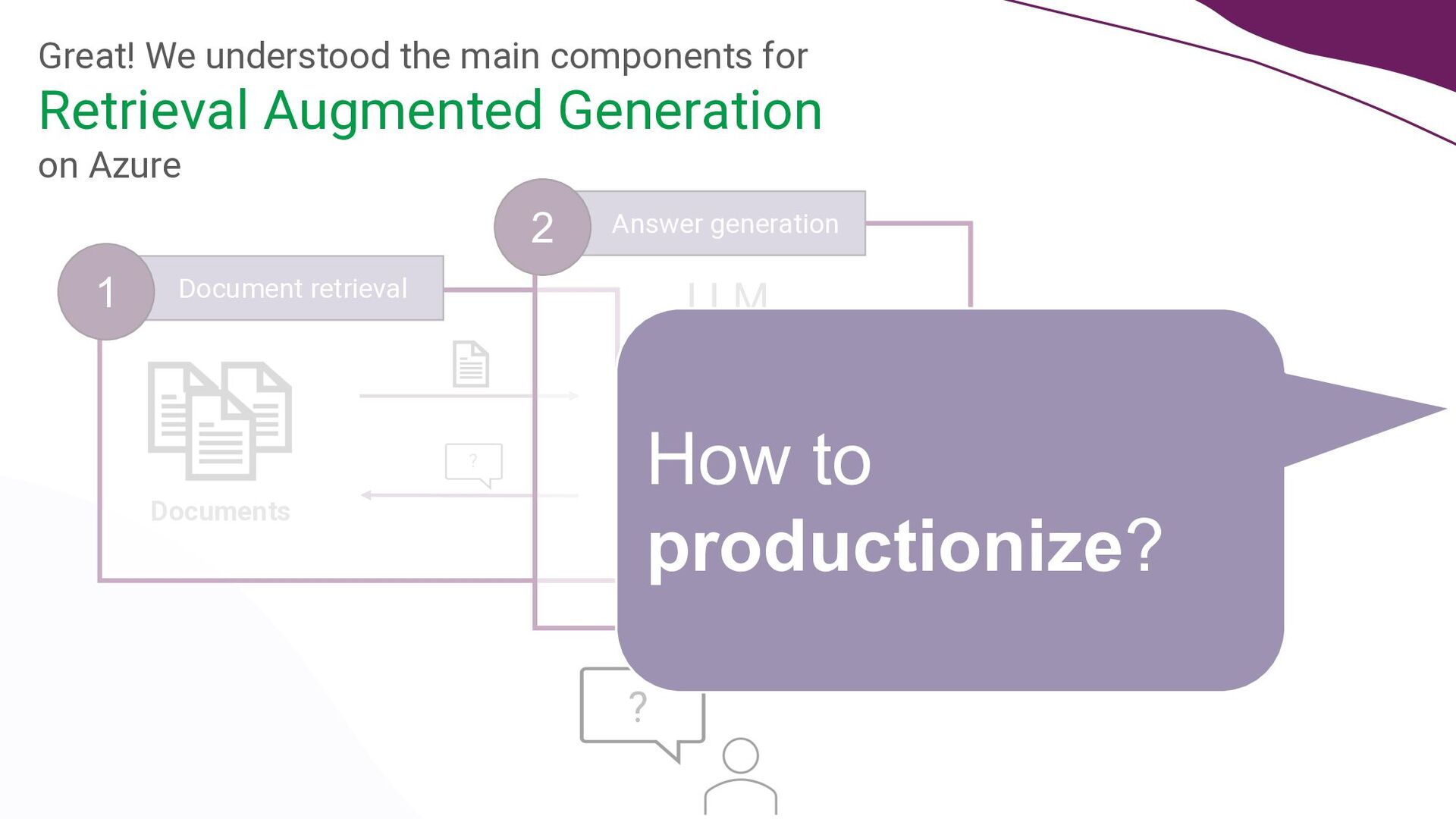
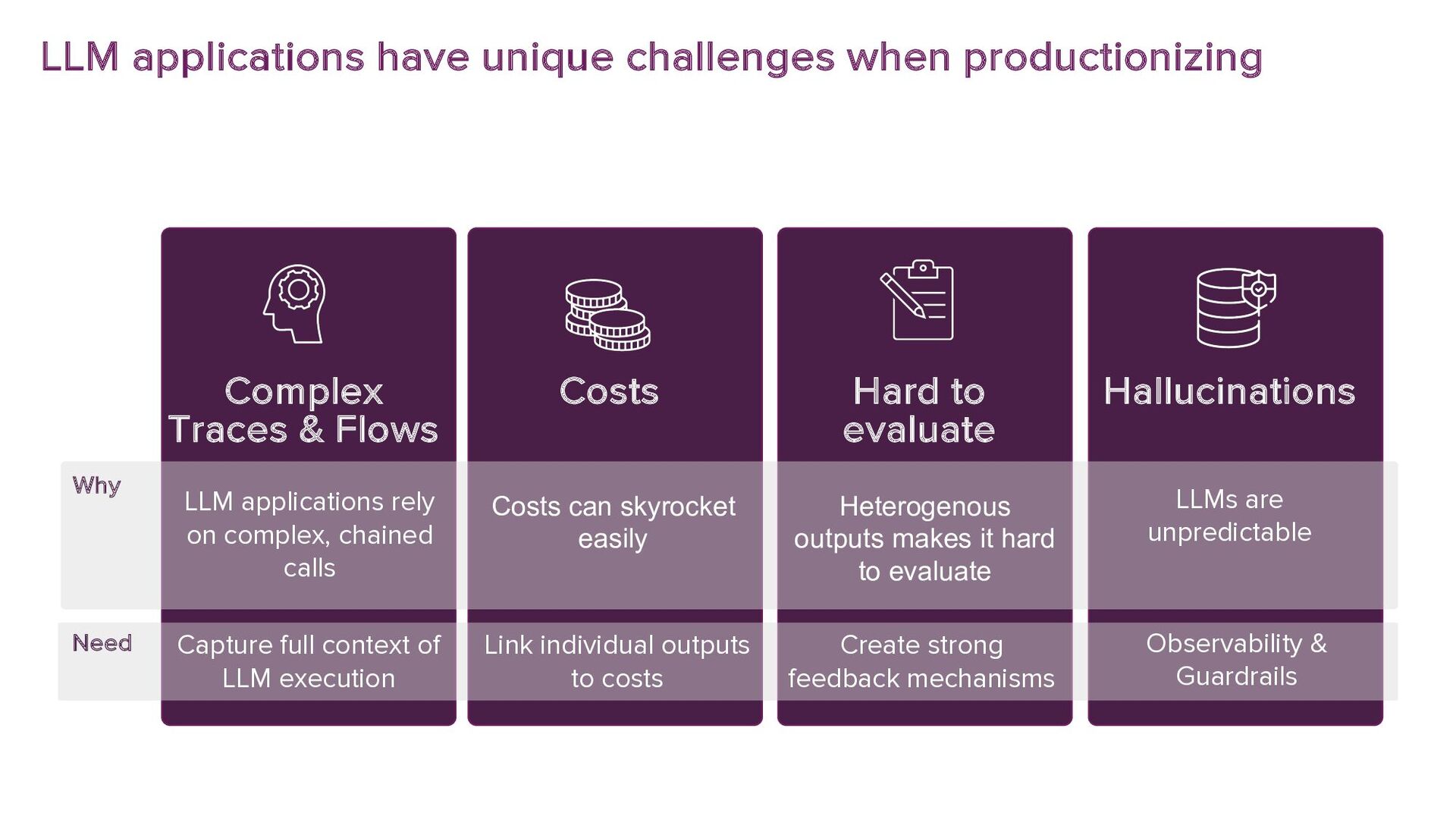
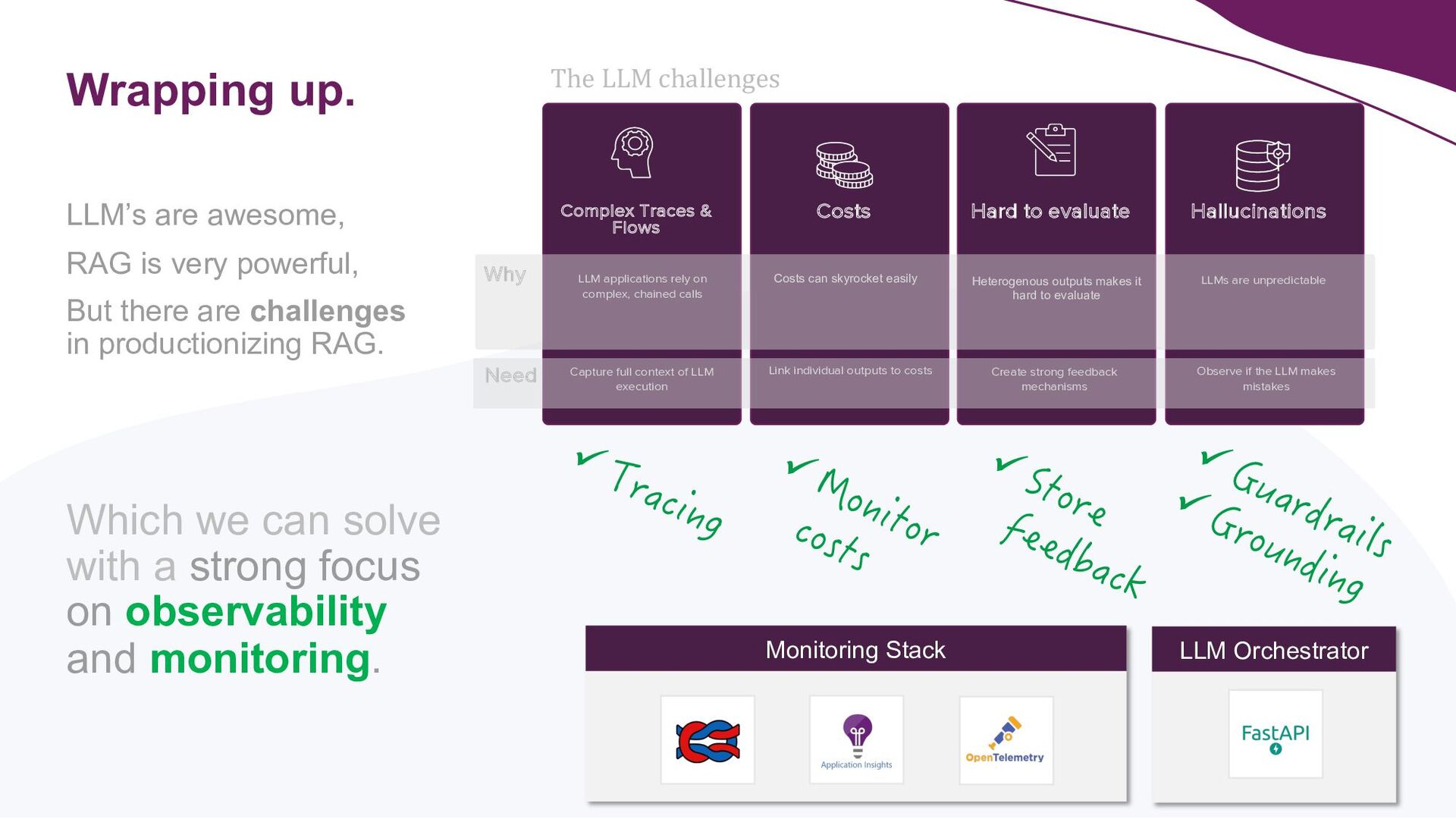
GenAI is hot. Companies are showing increasing interest and are recognising its business value. Specifically, by supercharging LLM’s using a technique called RAG, LLM weaknesses like hallucination and out-of-date knowledge can be overcome. But how to bring such applications into production? What extra complexities should be taken into account when productionising LLM applications? What makes LLMOps different from MLOps?
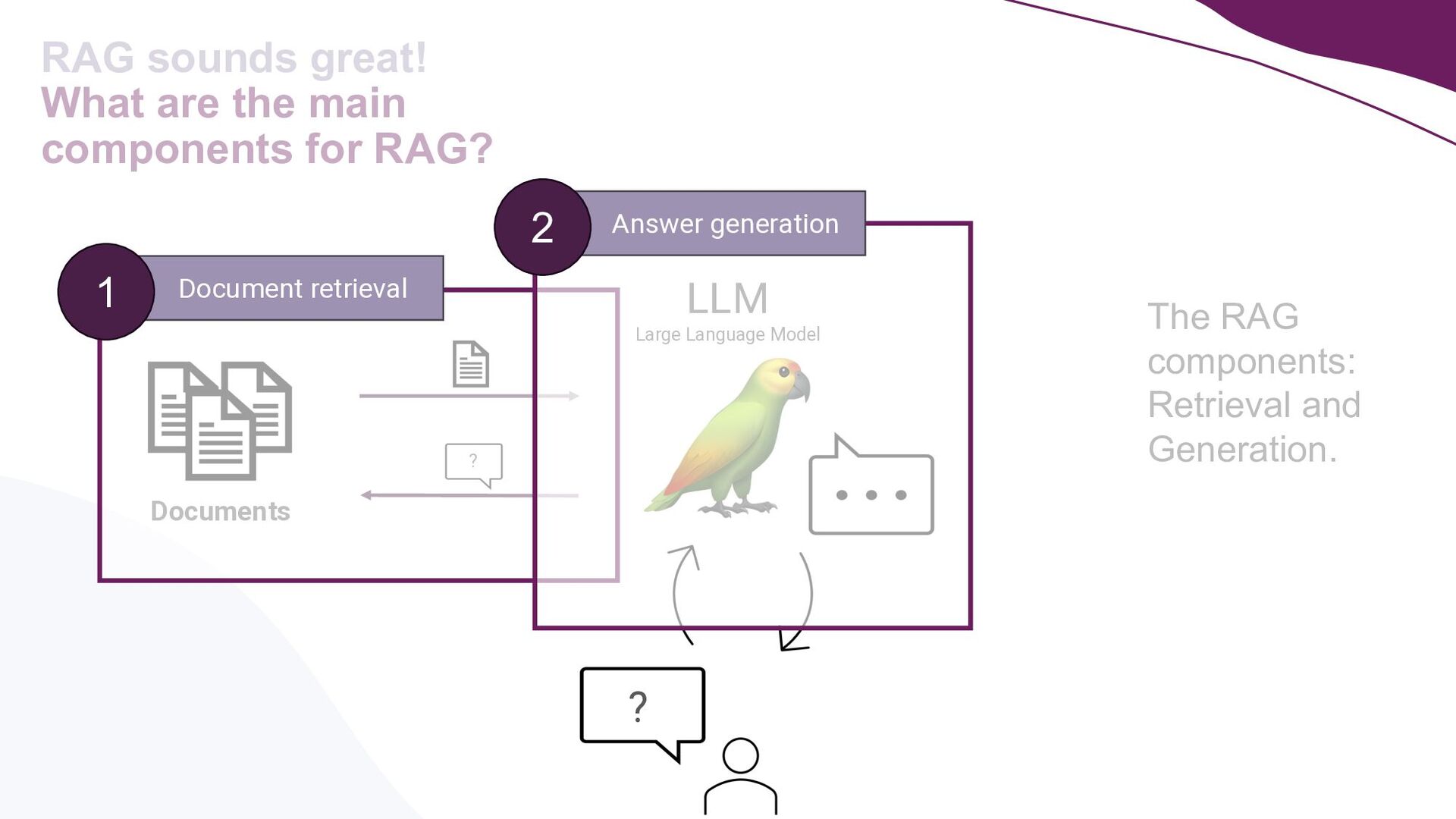
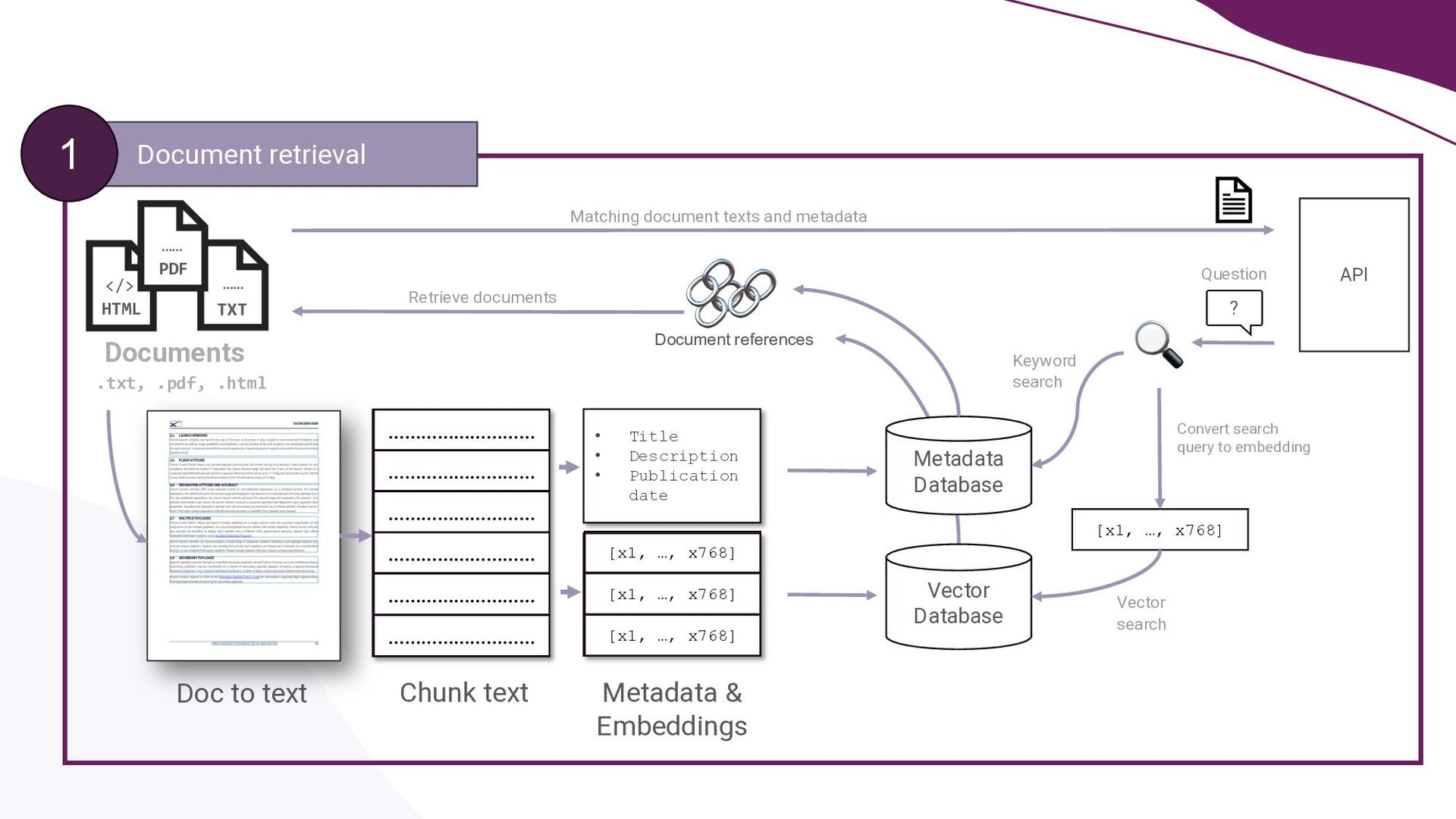
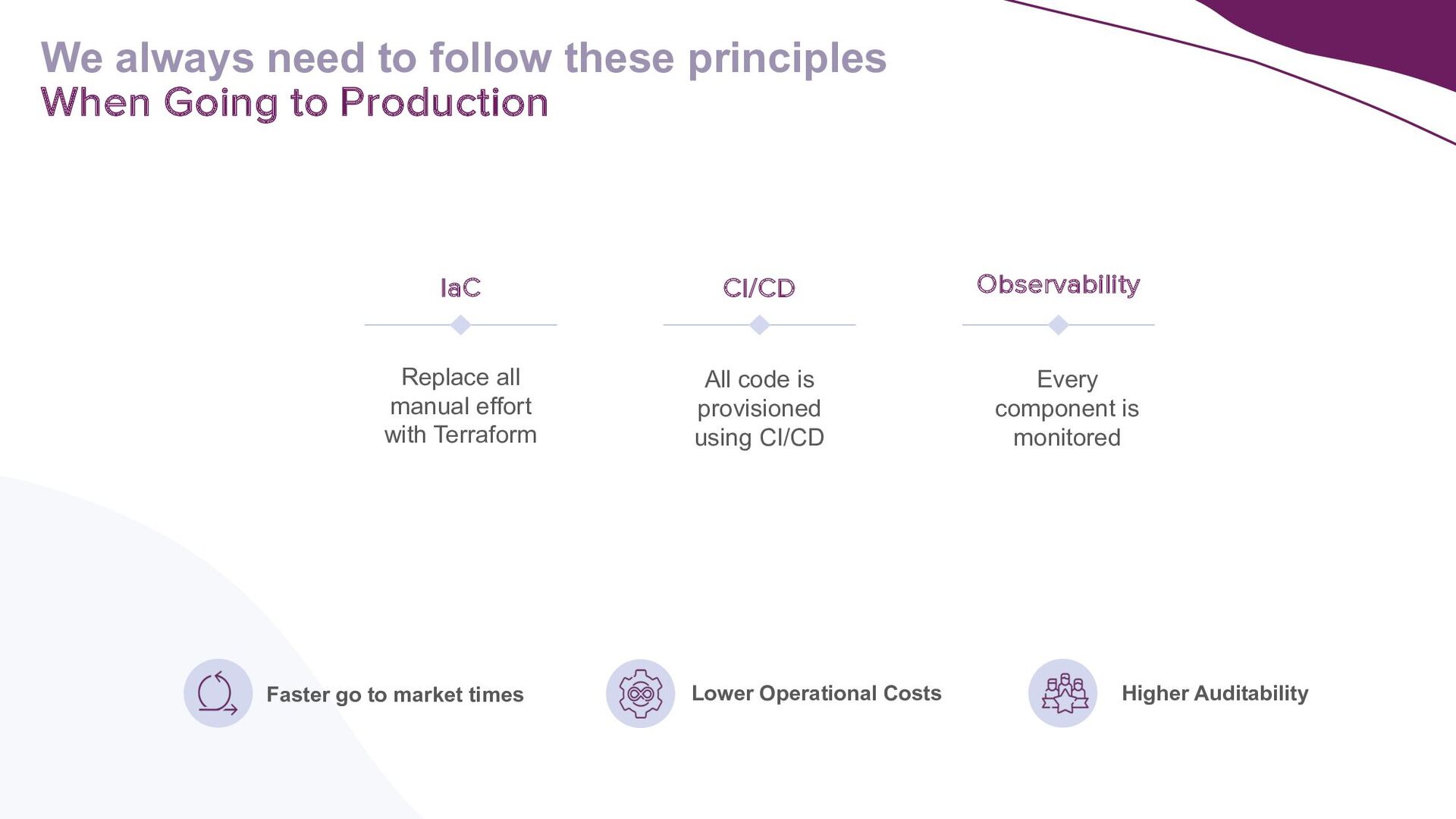
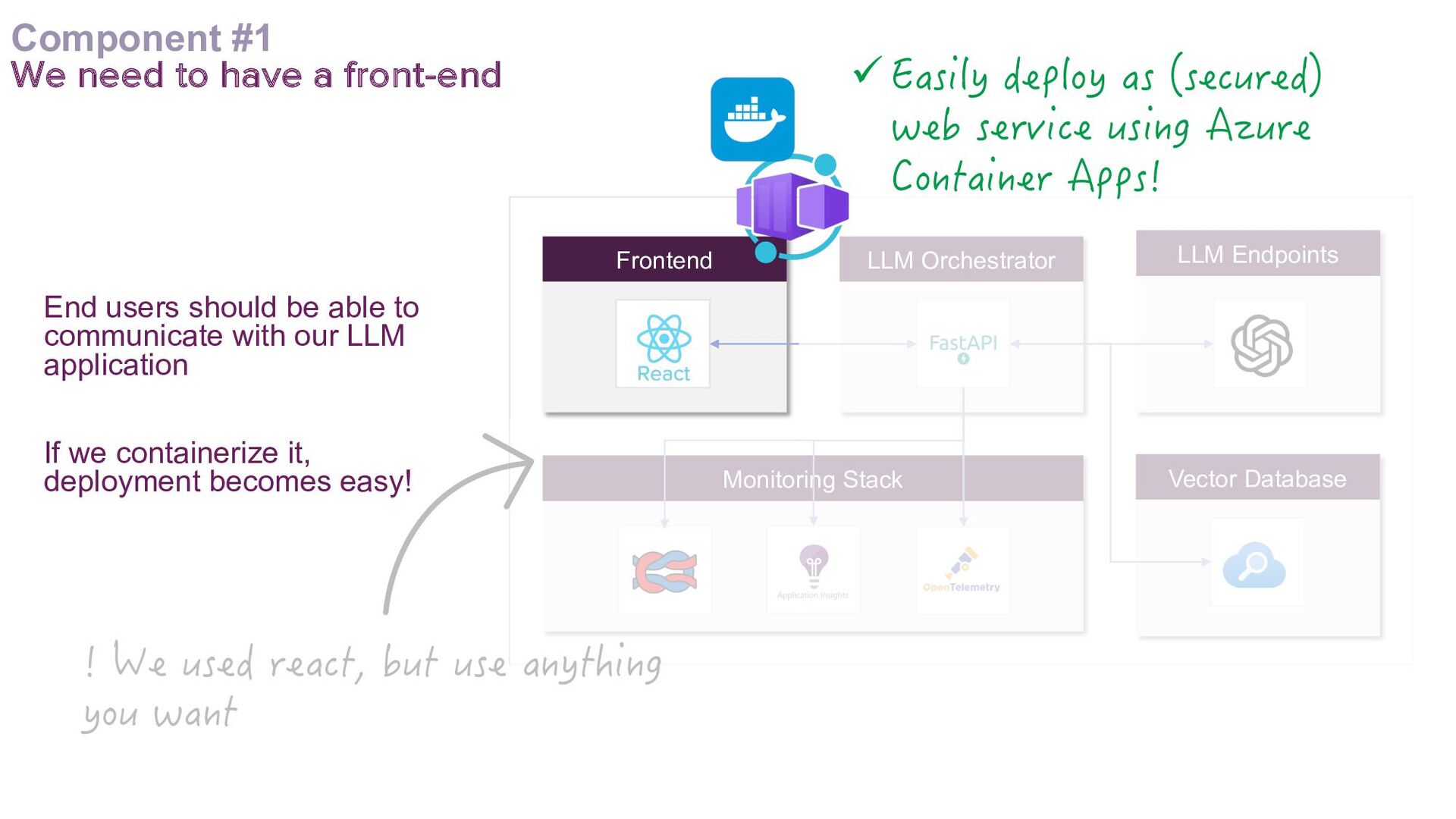
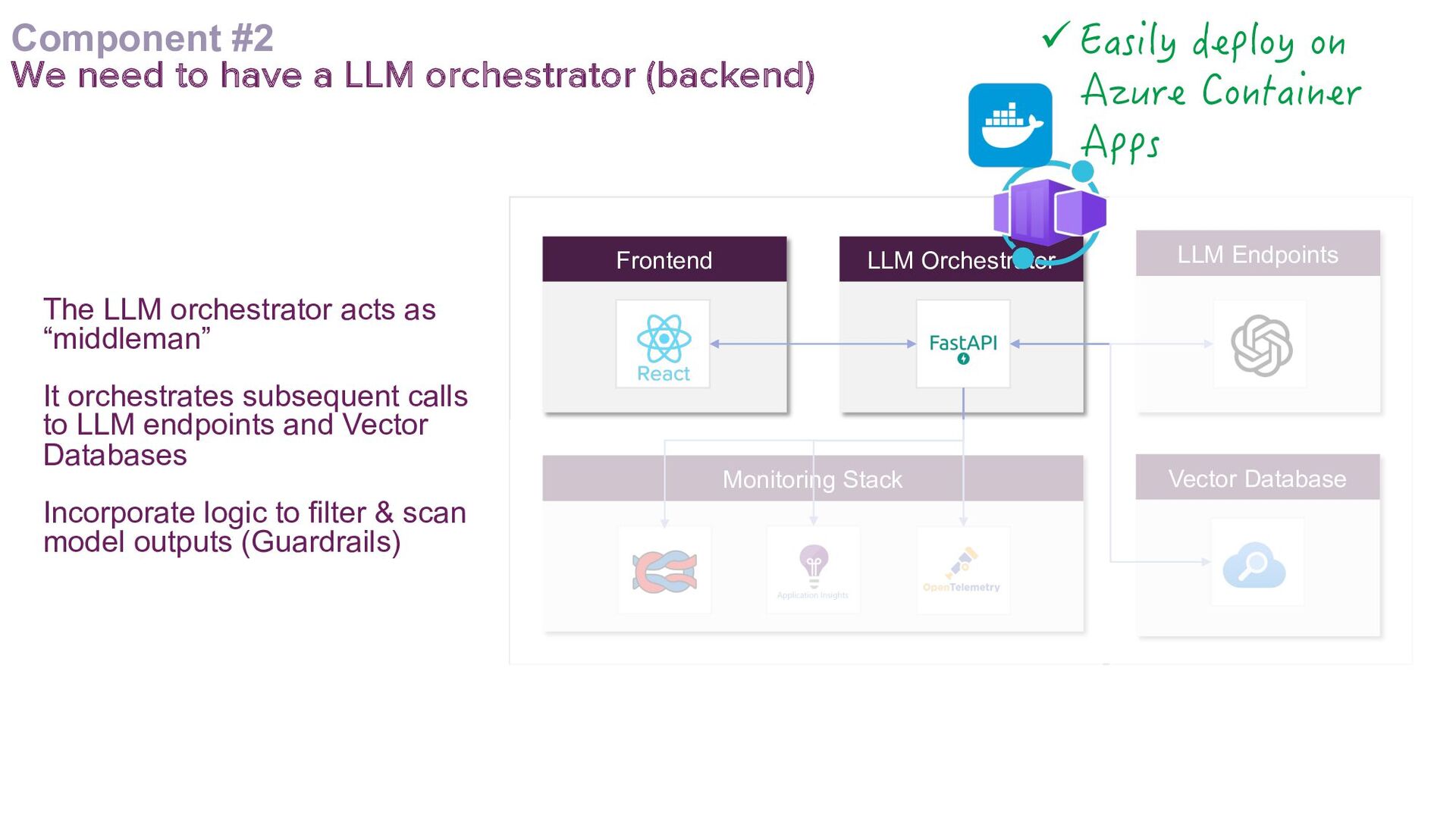
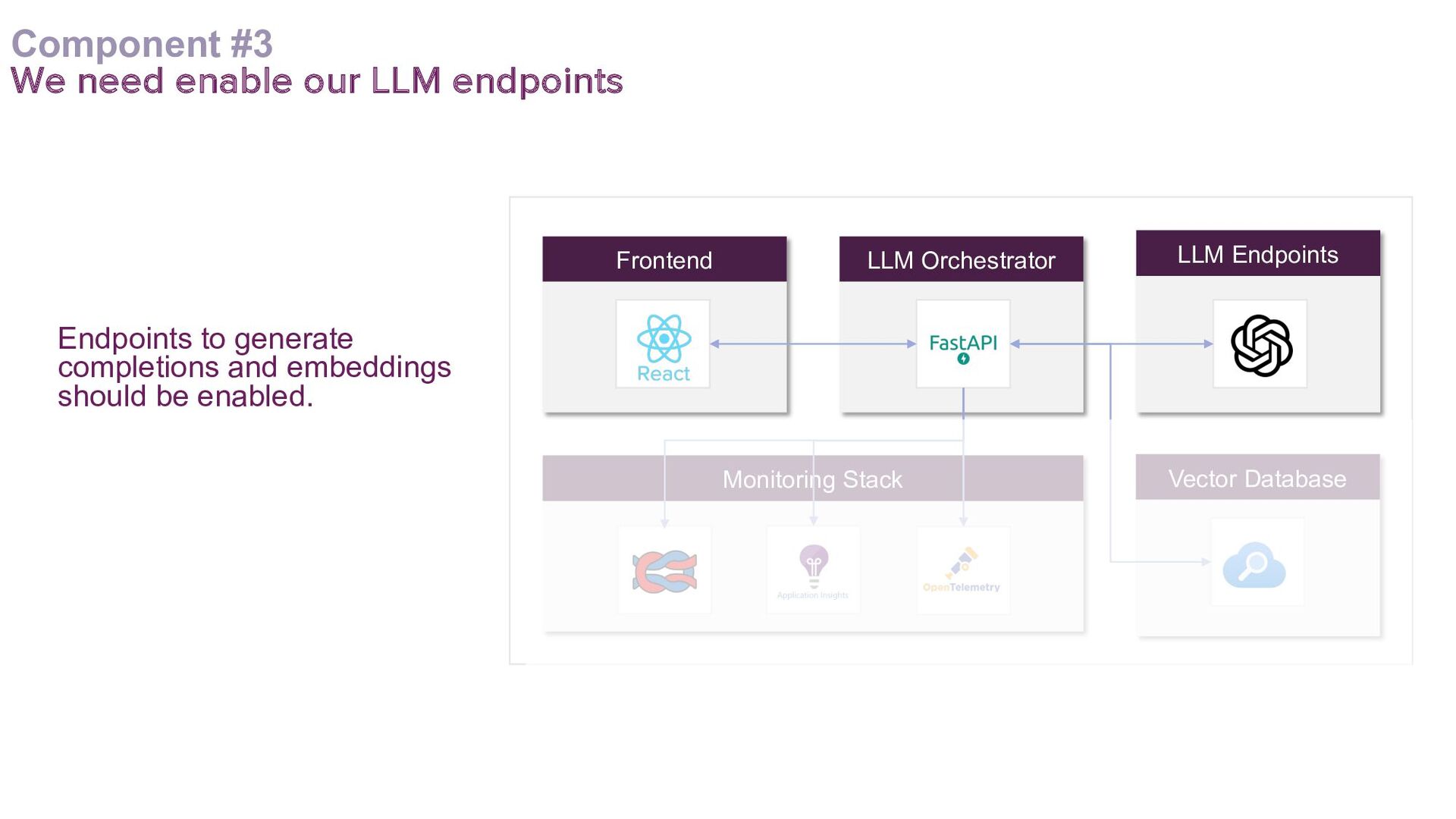
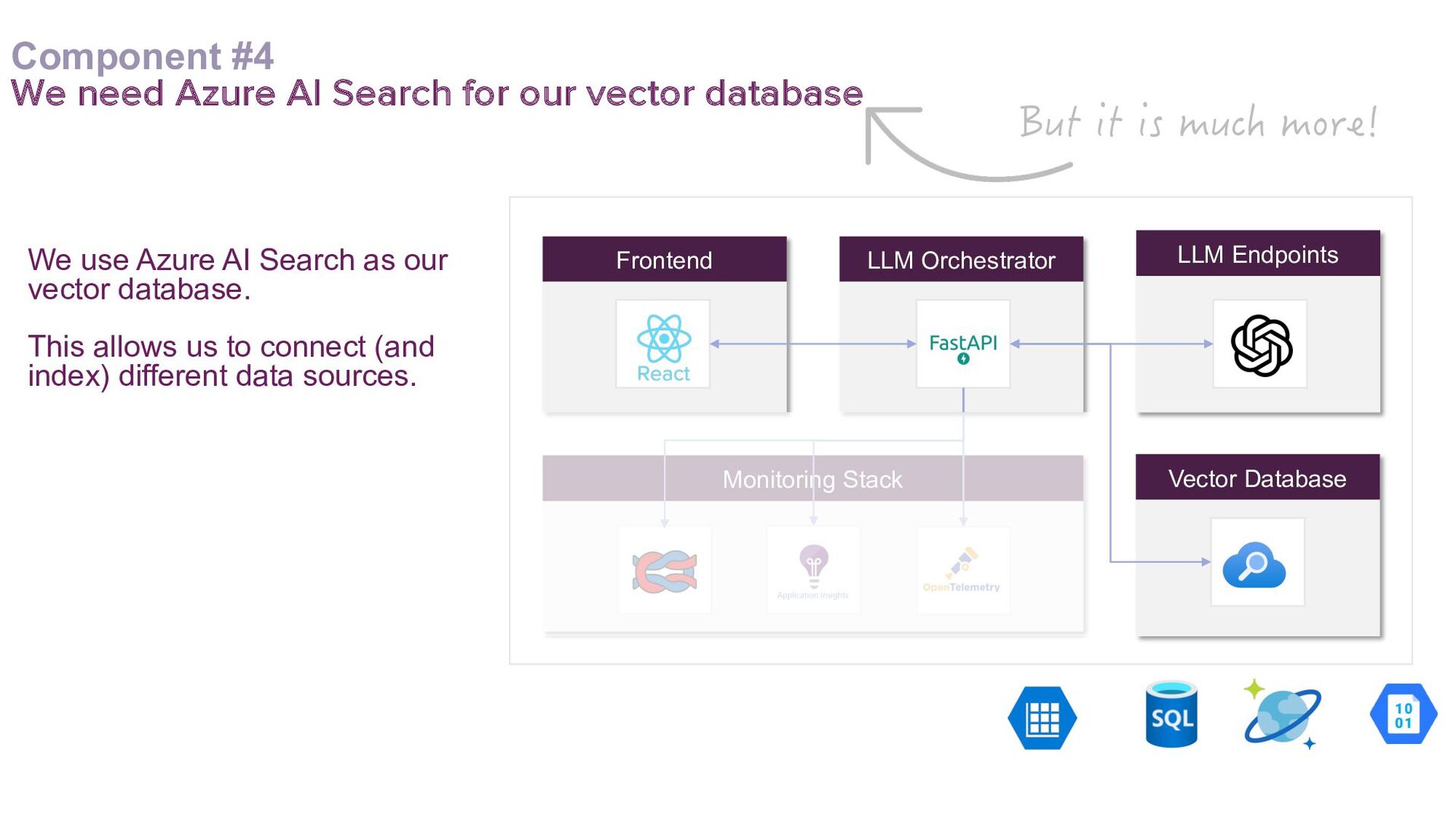
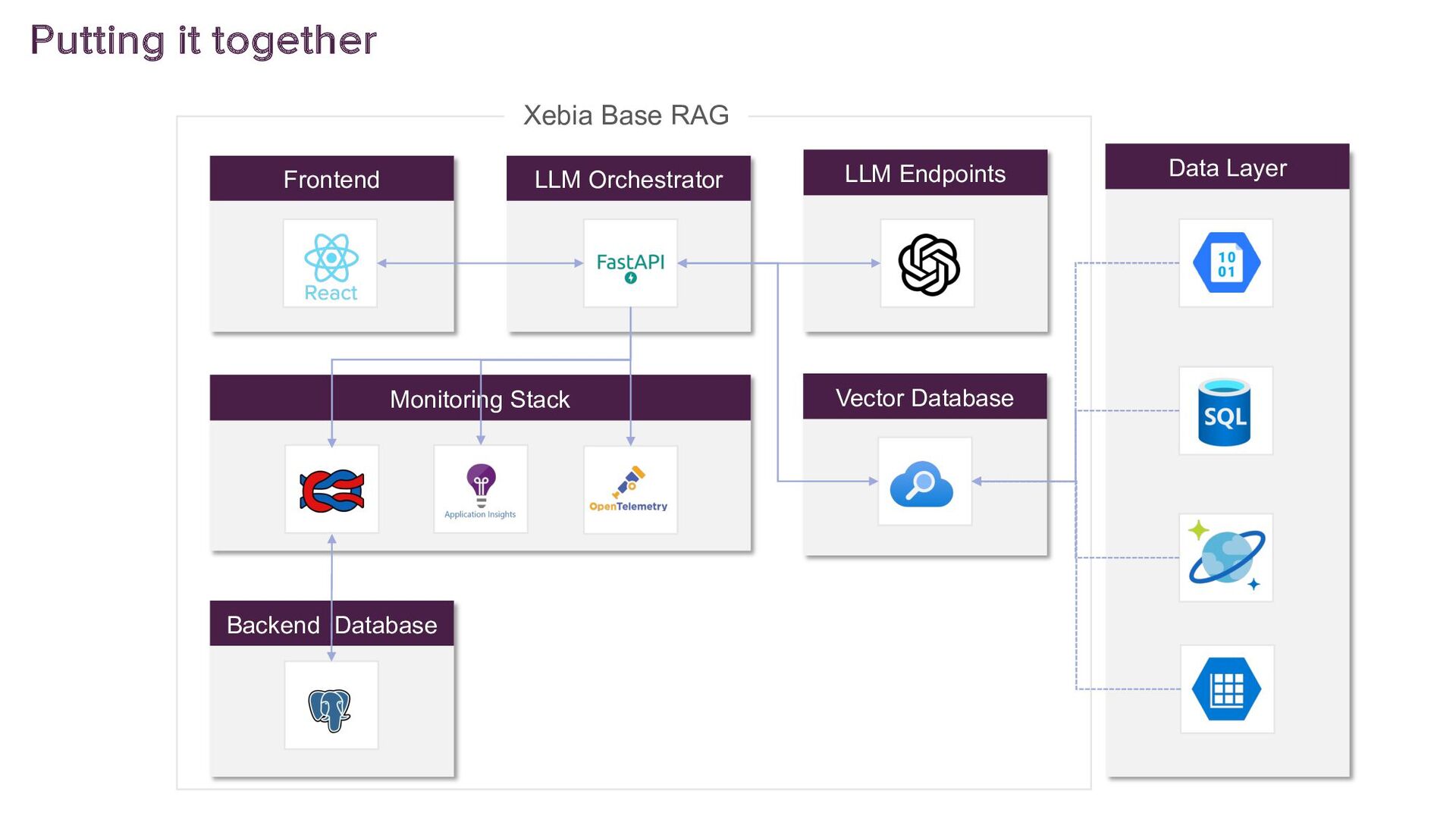
This talk presents a practical approach to building End-to-End LLMOps platforms specifically for Retrieval Augmented Generation (RAG) applications on Azure. Using Infrastructure-as-Code (IaC) principles, it will be demonstrated how to use Terraform to a create secure, version-controlled, and reproducible platform.
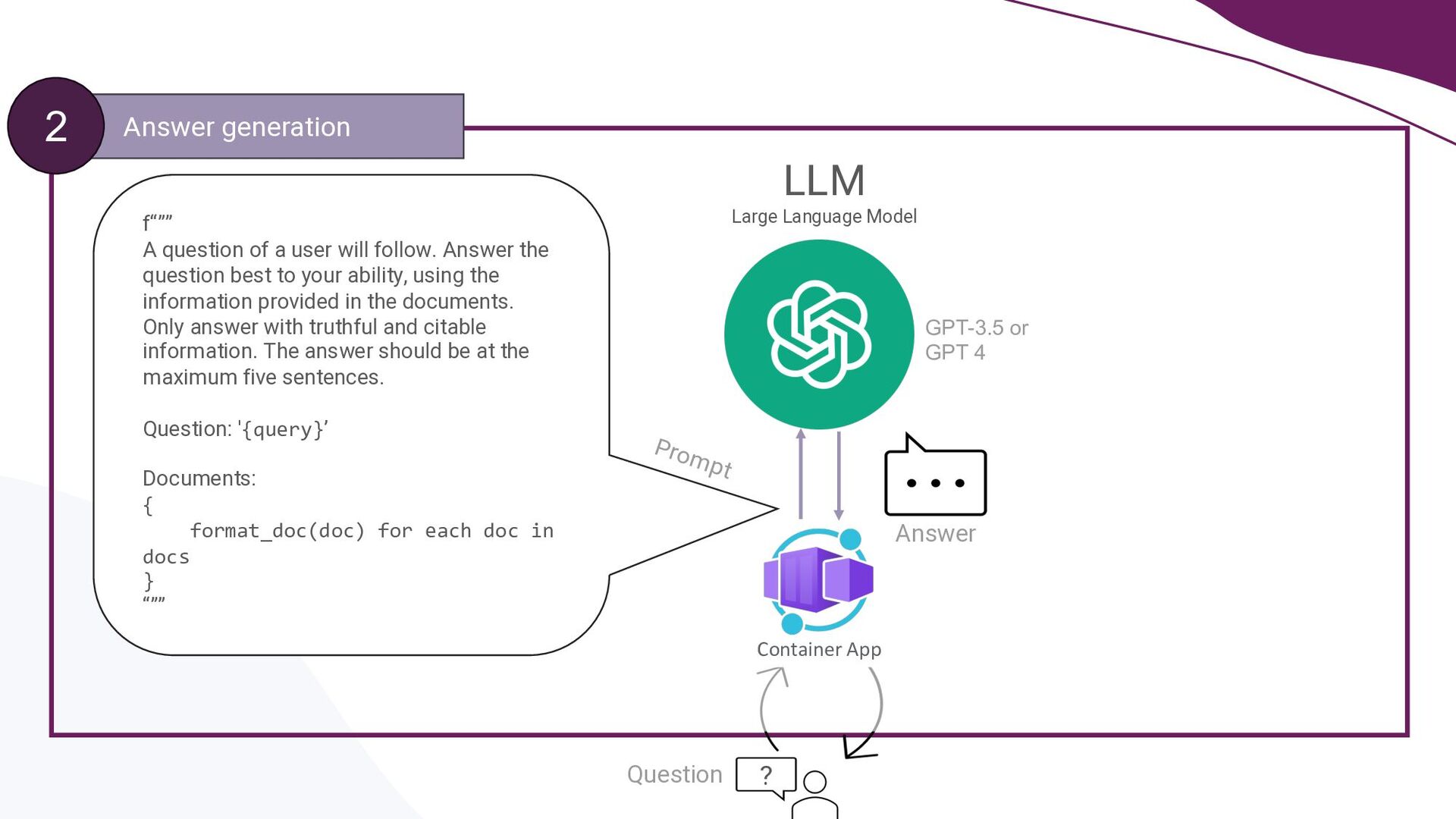
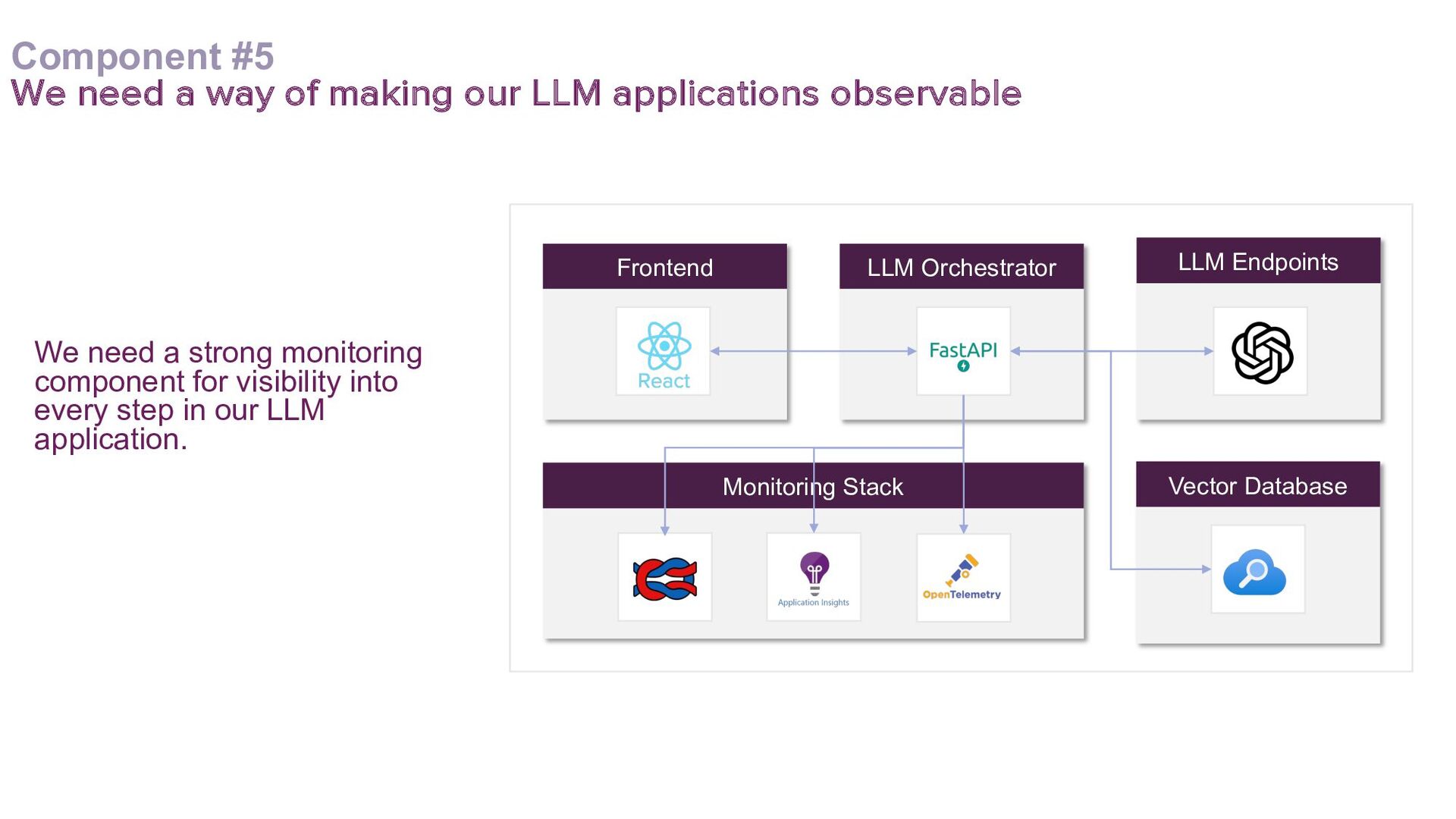
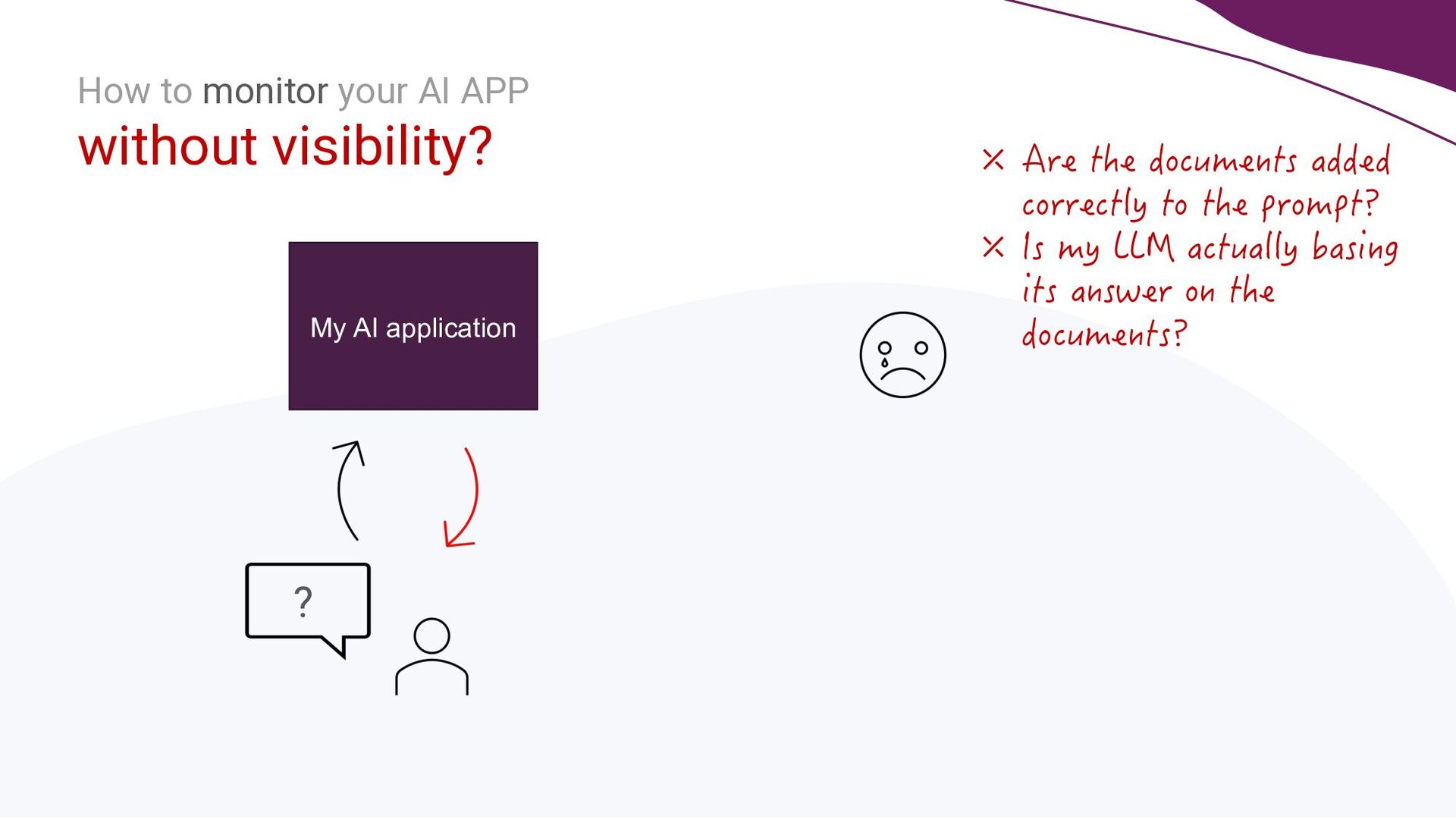
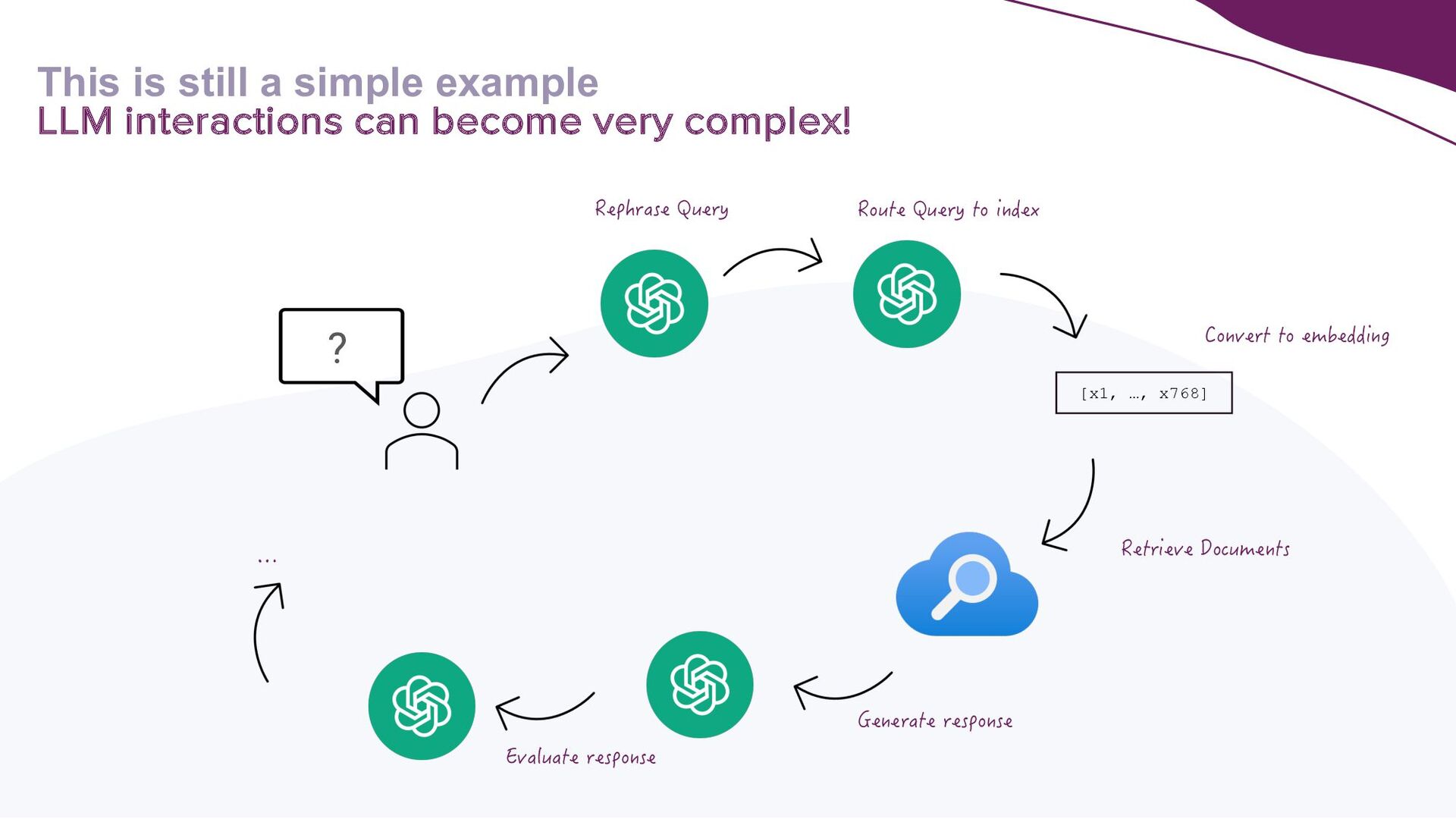
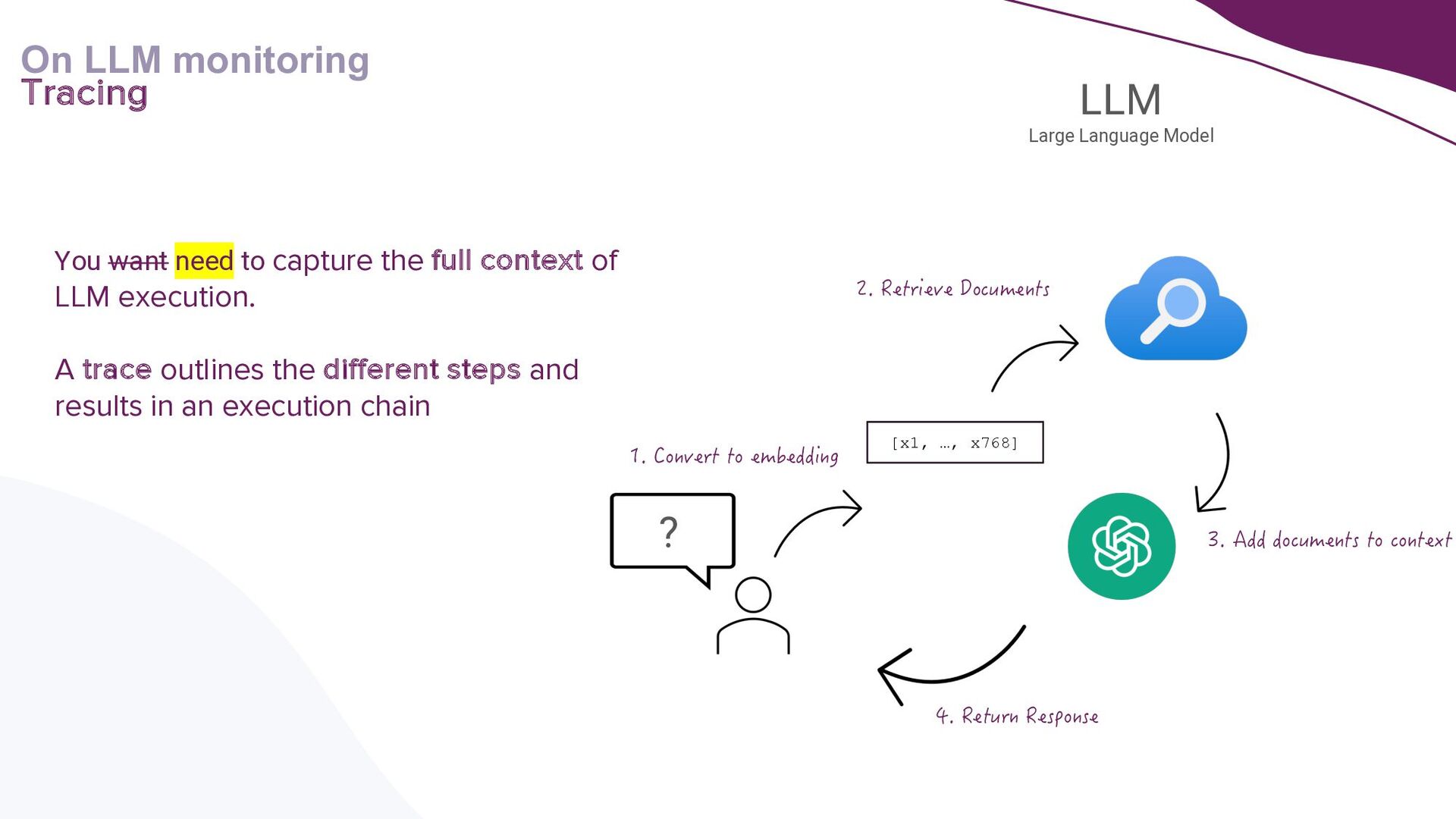
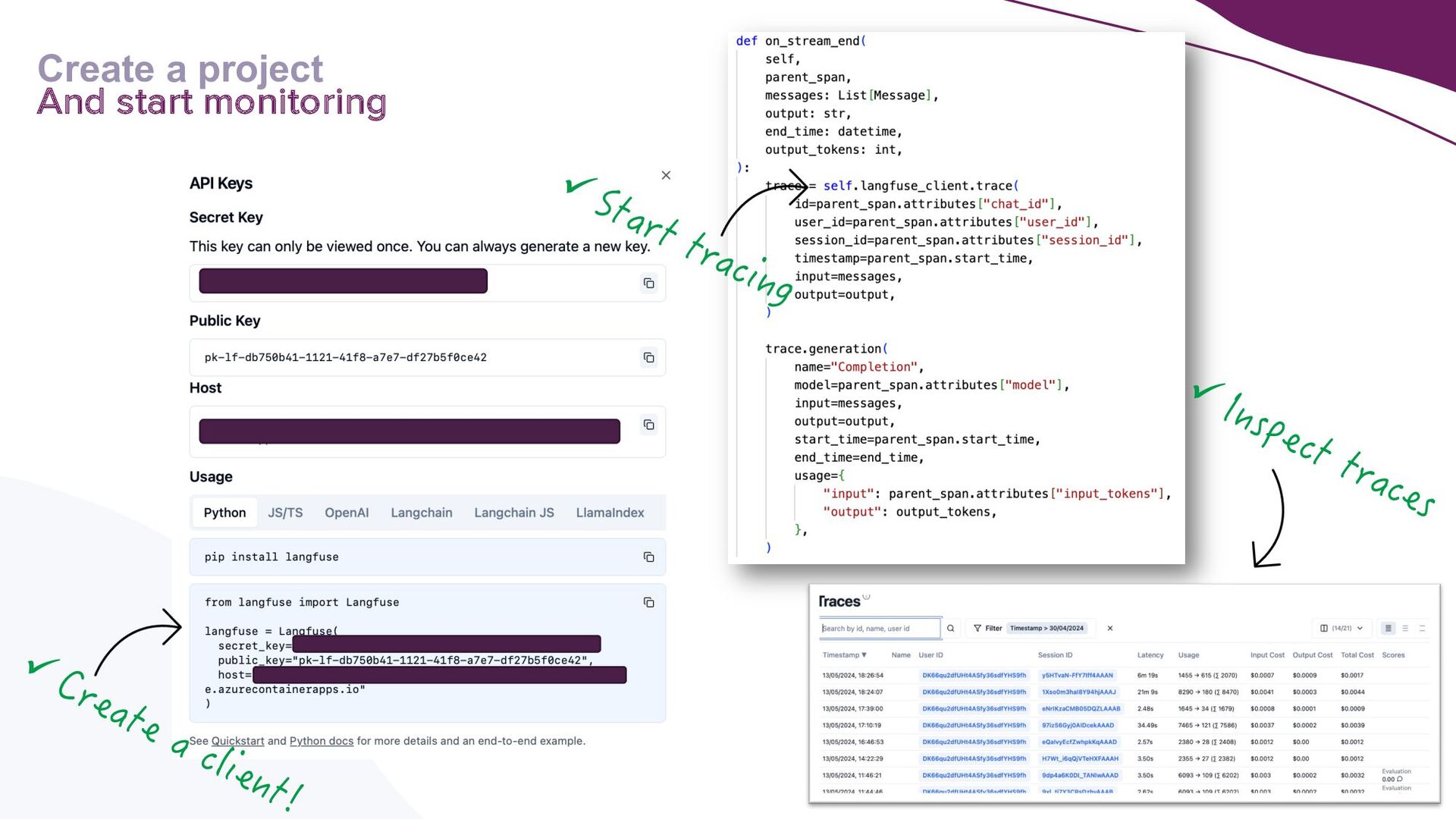
A key focus will be addressing the distinct requirements within the LLMOps lifecycle, with a strong emphasis on LLM observability. Recognising the complexities of deploying LLM applications to production, the talk will highlight the critical role of robust observability mechanisms. It will do this by showcasing how to leverage open-source tooling such as LangFuse to tackle this. Moreover, the talk will highlight how to self-host LangFuse in your own environment, and how to incorporate the LangFuse SDK to add observability to your existing LLM applications.
The talk aims to aid ML engineers, data scientists, and platform engineers with the knowledge and tools to address the challenges of building and managing RAG applications in production environments, by using a solid set of principles that can be effectively implemented in their own projects.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Blob Storage [x1, …, x768] 🔍 Convert search query to](https://files.speakerdeck.com/presentations/ecc75868ebc54eb6ab85d2b03666ce37/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
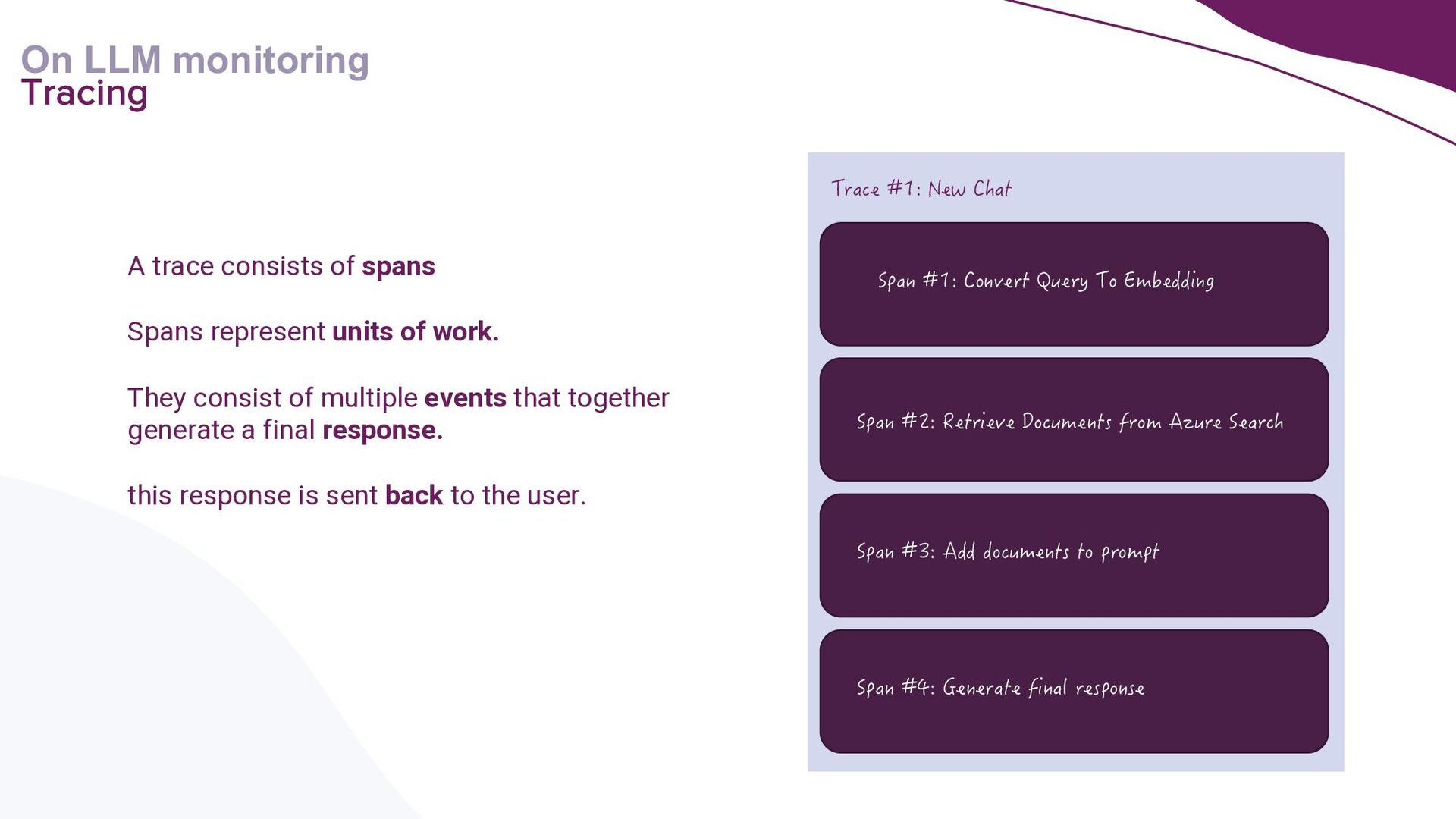{kind=link}
{kind=link}
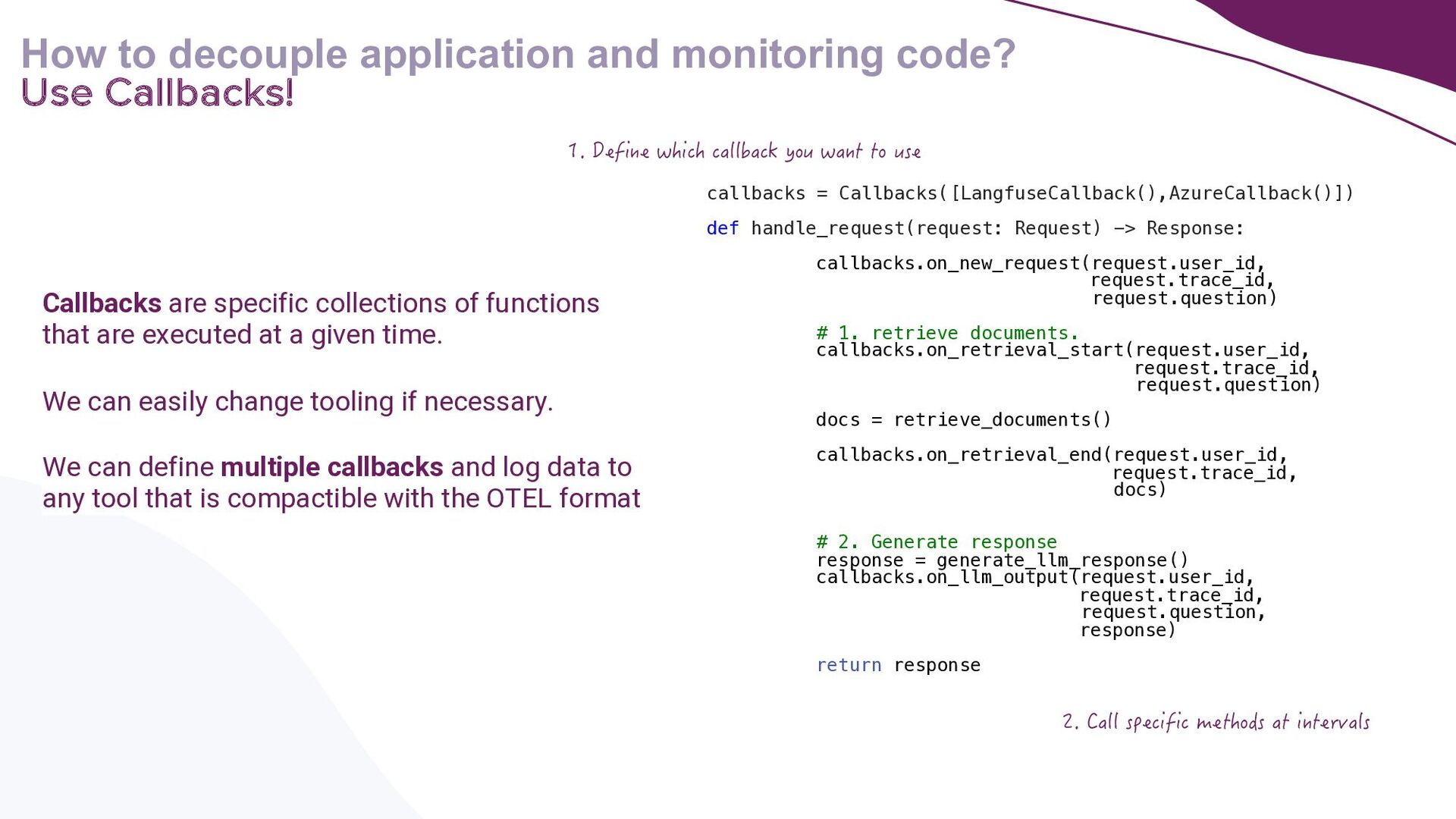{kind=link}
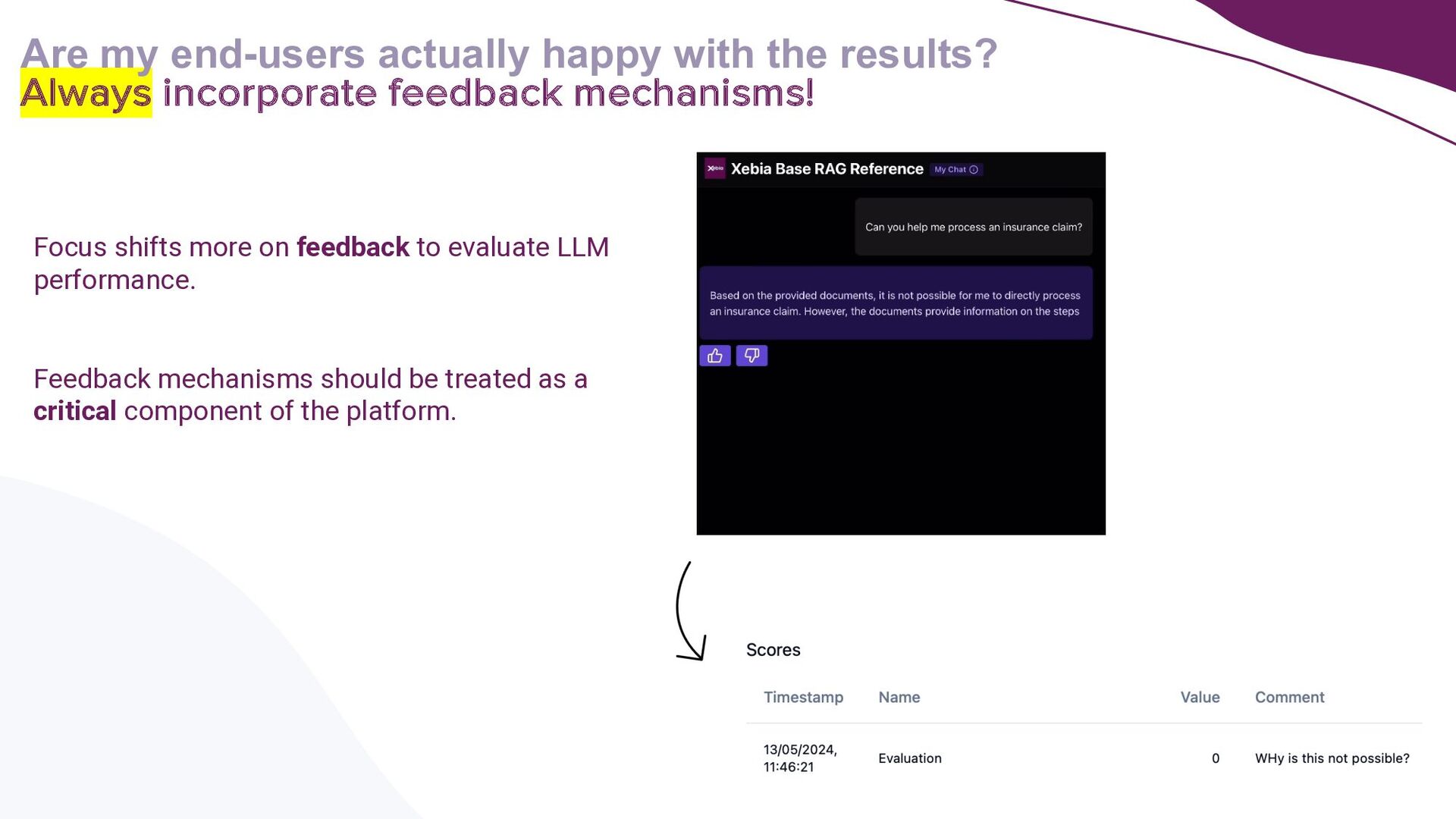{kind=link}
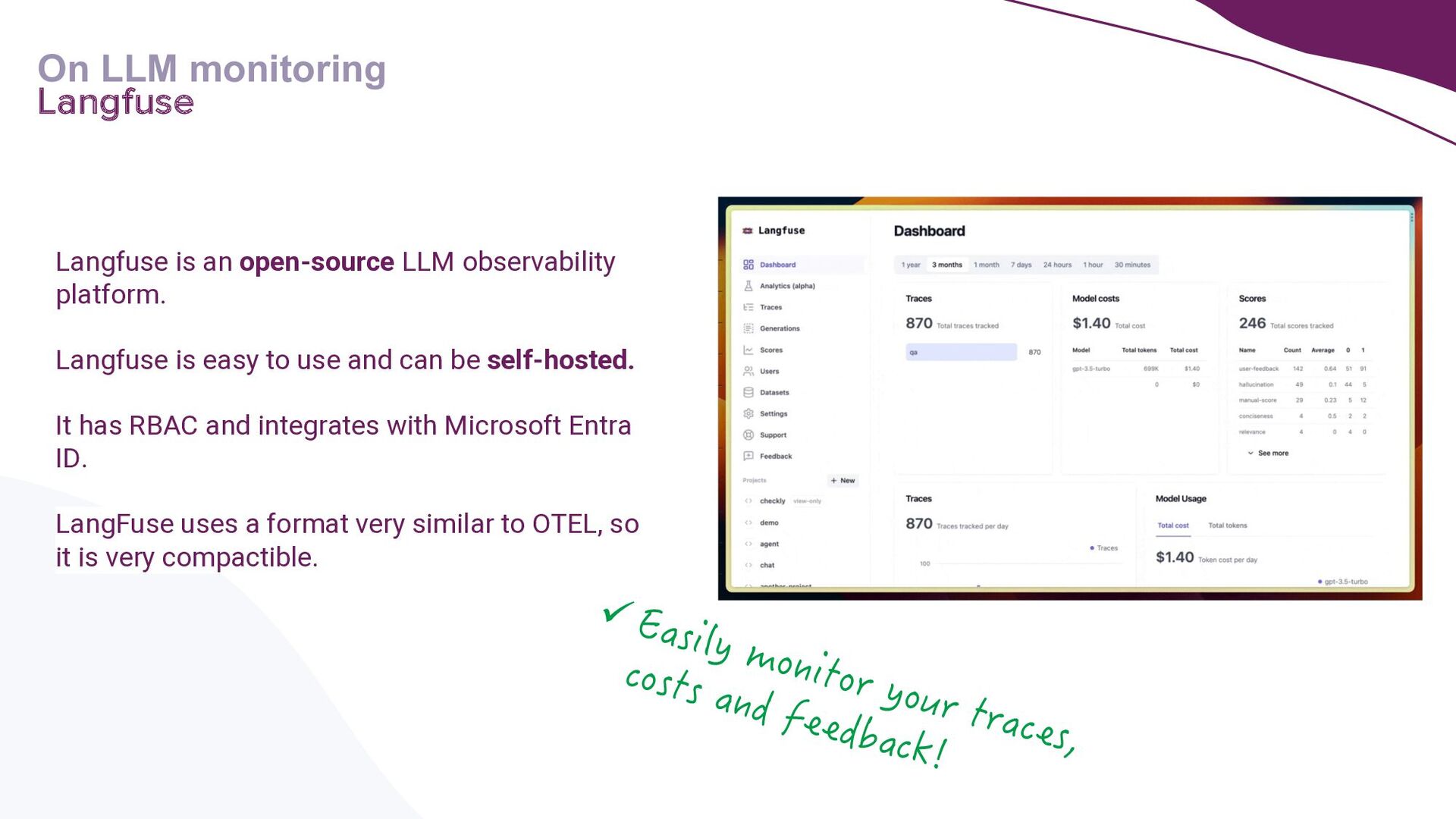{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}