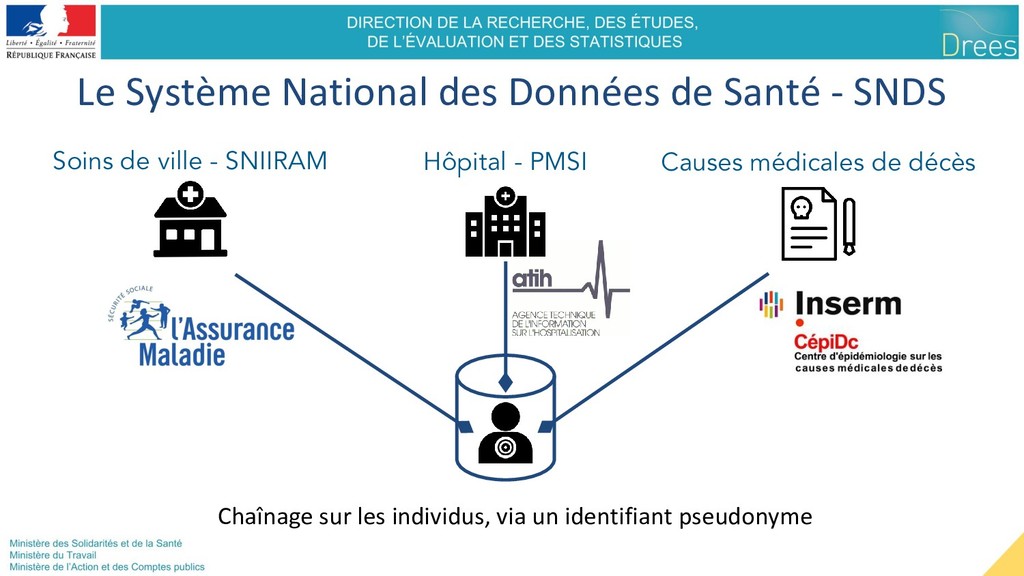
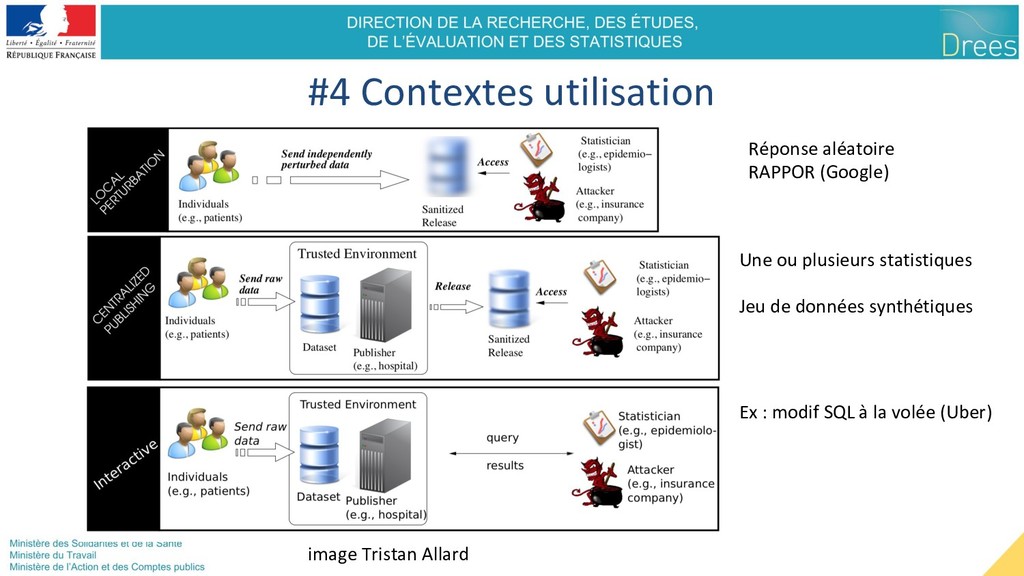
freinent l’utilisation => Les données sorties doivent être “anonymes” Loi création SNDS Utilité : Meilleure santé - Connaissance médicale - Épidémiologie - Suivi de la qualité des soins - IA médical, etc. Ouverture des données Sensibilité : Causer du tort aux individus - Réidentification - violation secret médical - Discrimination statistique - volontaire ou non Référentiel de sécurité
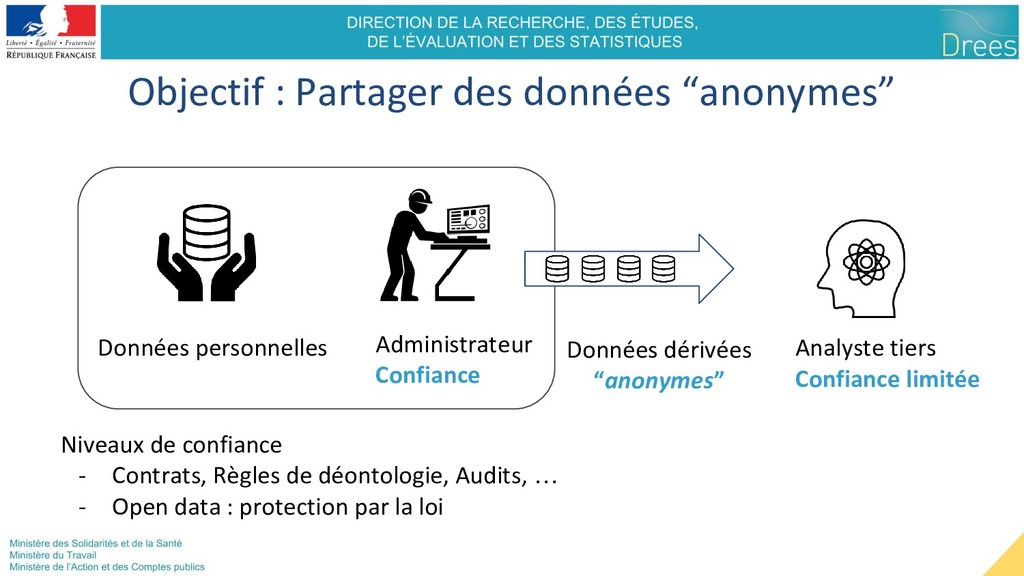
Analyste tiers Confiance limitée Données dérivées “anonymes” Niveaux de confiance - Contrats, Règles de déontologie, Audits, … - Open data : protection par la loi
ou quasi-identifiantes - Retirer ces valeurs (dé-identification) - Ou remplacer ces valeurs par un pseudonyme non-réversible - aléatoire ou hash avec secret Exemples - Recherche manuelle ou automatique d’entités - compte rendus médicaux, textes de loi, etc. - Pseudonymisation à 2 niveaux dans le SNDS (FOIN)
Publication Open Data médical dé-identifié - contient code postal, sexe, date de naissance Latanya Sweeney, doctorante - Achète le registre électoral avec données démographiques - Attage par couplage => Identifie le gouverneur Limite Pseudonymisation + Données auxiliaire => Réidentification
France Résumé de Sortie Anonyme des hospitalisations (PMSI) - définition avec la CNIL - diffusion libre Données retirées - nom, NIR - dates de naissance et d’hospitalisation => mois année - code géographique de moins de mille habitants 1996 et 1998 : Réalisation des possibilités de croisement → Diffusion limitée, chapitres IX et X LIL
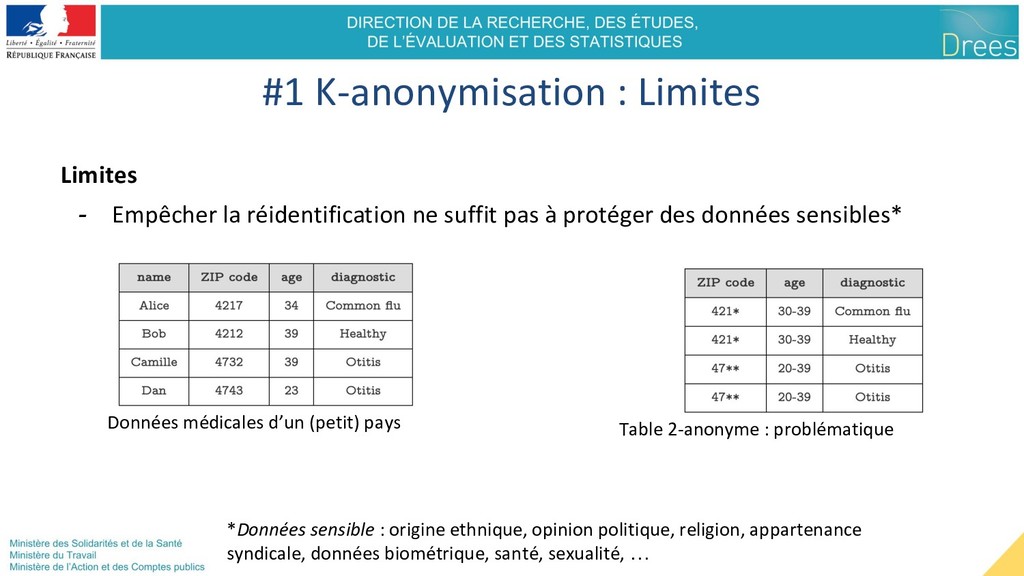
: Toute combinaison de quasi-identifiants* concerne plus de K individus #2 K-anonymisation : Définition Table 2-anonyme *Quasi-identifiants : sexe, âge, adresse, … dépend du contexte et de l’attaquant desfontain.es/privacy/k-anonymity.html
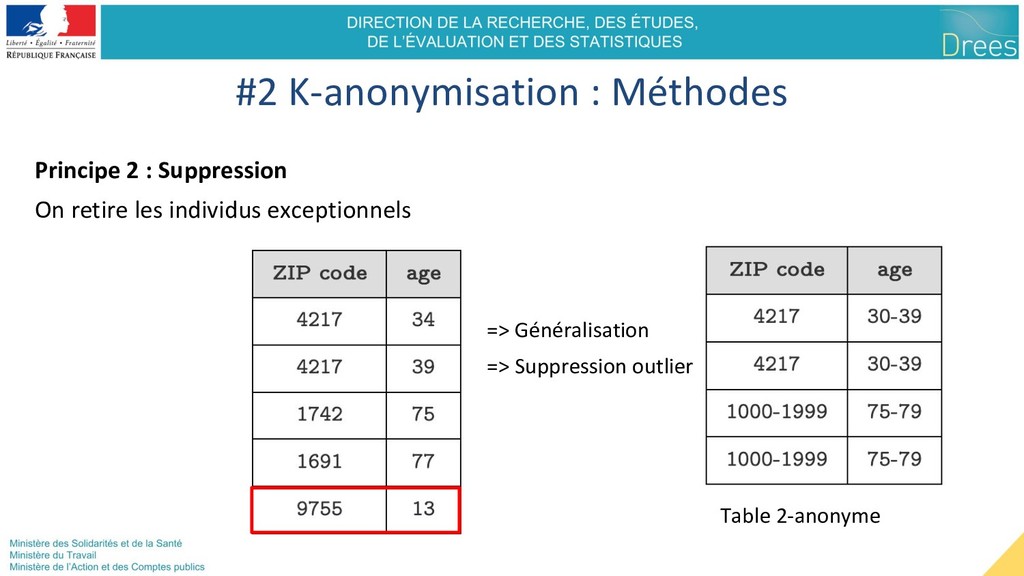
Intervalle - Niveau hiérarchique (ex CIM-10) - Valeur manquante #2 K-anonymisation : Méthodes Pas 2-anonyme Table 2-anonyme => Tranche d’âge => Groupe de codes
très utilisée Exemple : secret statistique - Quel sont les quasi-identifiants / variables sensibles ? - Plus de quasi-identifiants => plus de généralisation et suppression Outils - Principalement ARX (Open-Source) - Souvent implémentations spécifiques au sujet
choix de K Nadège Thomas, OR2S Issu d’un document de travail sur les risques de réidentification dans publications open data, proposition méthode floutage - Pas de garantie sur les combinaisons entre plusieurs publications Exemple : Évolution des zonage géographique au cours du temps
sensible sur un individu, à partir de ses quasi-identifiants Définition (2006) : Tout groupe de quasi-identifiants doit comprendre + de L valeurs sensibles distinctes #3 L-diversité : Définition Table 2-anonyme problématique Table 2-diverse => Généralisation (=> Suppression) Méthodes : Similaire K-anonymisation
plus difficile que K - Les L valeurs pour un individus peuvent rester sensibles - Cancer bras gauche ou Cancer bras droit ? => demande une analyse experte - N’empêche pas un gain d’information probabiliste - Ex : Lupus a 90% de chance Table 2-diverse problématique Définition rarement utilisé - Perte massive d’utilité des données - Même modèle d’attaque que K-anonymat, en corrigeant un problème mais pas tous desfontain.es/privacy/l-diversity.html
ne doit rien pouvoir apprendre sur un individu avec les données produites Problème de cette idée : Si les données permettent d’apprendre un lien statistique “fumer => cancer”, on apprend une information sur les fumeurs, qui peut leur nuire. Objectif : Résoudre ce paradoxe - Apprendre des informations statistiques sur une population - Ne rien apprendre de spécifique à un individu
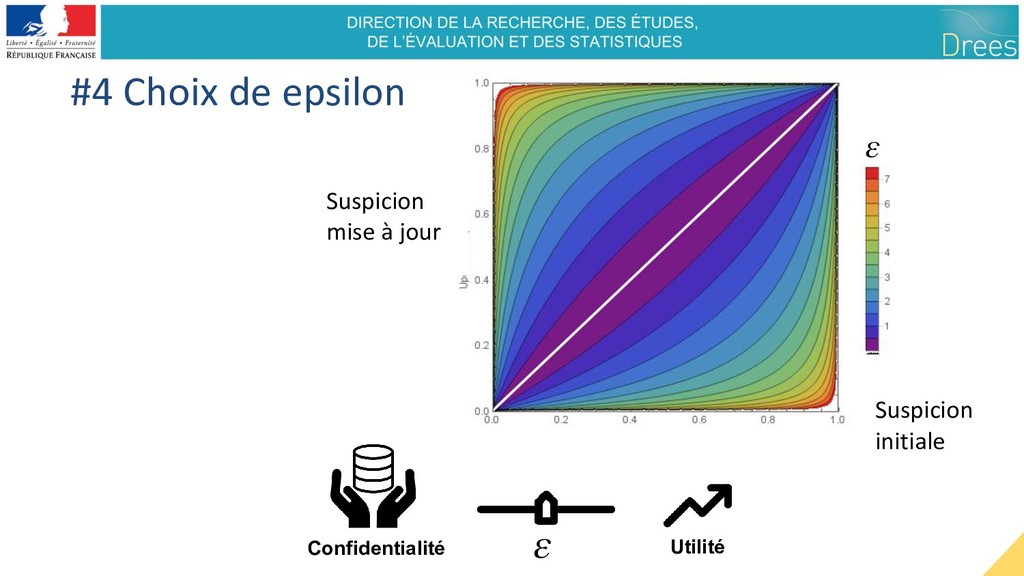
de la source #4 Confidentialité Différentielle : Définition intuitive Promesse : Aucune conséquence négative additionnelle si vos données sont utilisées dans une analyse, quelles que soient les informations auxiliaires disponibles desfontain.es/privacy/differential-privacy-awesomeness.html
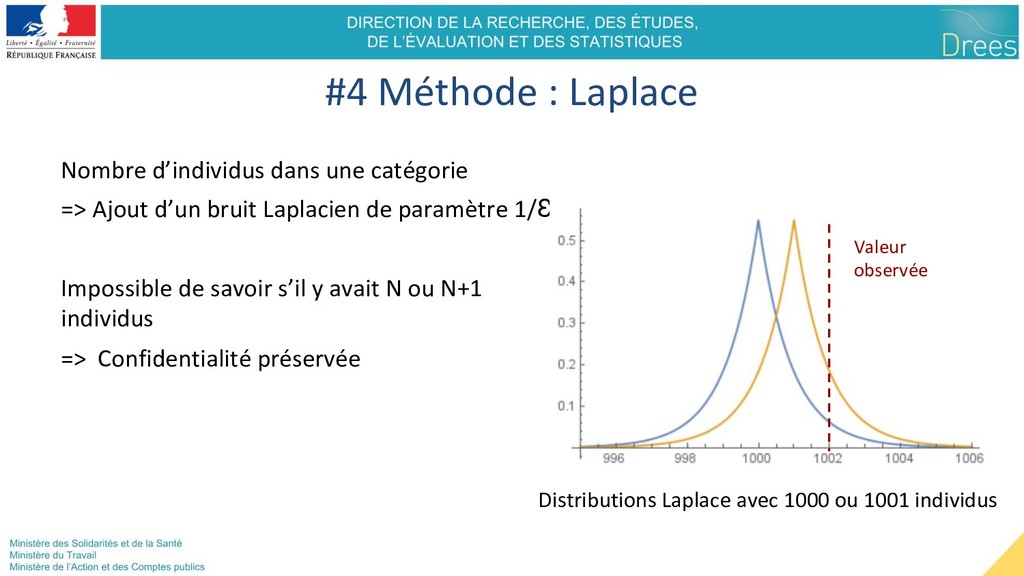
Ajout d’un bruit Laplacien de paramètre 1/Ɛ Impossible de savoir s’il y avait N ou N+1 individus => Confidentialité préservée Distributions Laplace avec 1000 ou 1001 individus Valeur observée
d’attaque – Protège n’importe quelle type d’information à propos d’un individu – Futur proof : données auxiliaires, méthodes, outils, puissance de calcul • Quantification claire de la perte de secret privé, avec paramètre Ɛ • Possibilité de quantifier la combinaison de plusieurs informations dérivées – 4 fois Ɛ => au pire 4 Ɛ
• Manque d’experts => Méthodes avancées, Subtilité, Pièges • Manque de vulgarisation • Manque d’implémentations Des garanties parfois trop fortes ? • Pas de nuancée selon le contexte • Ne permet pas de publier des micro-données à l’échelle individuelle Peu d'expériences sur la mise en oeuvre • Utilisation des données bruitées • Gestion du budget de privacy • Choix par les décideurs de epsilon
risques - Ressources de l'attaquant et intérêt de l'attaque par rapport à ses moyens - Données personnelles les plus valorisées ? - Possibilité d’intrusion ou de collecte de données sensible sans publication - Contrôle des contrats ou loi ?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}