This talk was presented at the inaugural Elastic{ON} conference, http://elasticon.com
Session Abstract:
With 700-800 production nodes spread across 100 Elasticsearch clusters, Netflix is pushing the envelope when it comes to extracting real-time insights on a massive scale. This talk will highlight how they deploy and manage an environment of that scale and touch on Raigad - their internally-built open source sidecar management tool for Elasticsearch.
Presented by Sagar Loke & Homajeet Cheema, Netflix
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
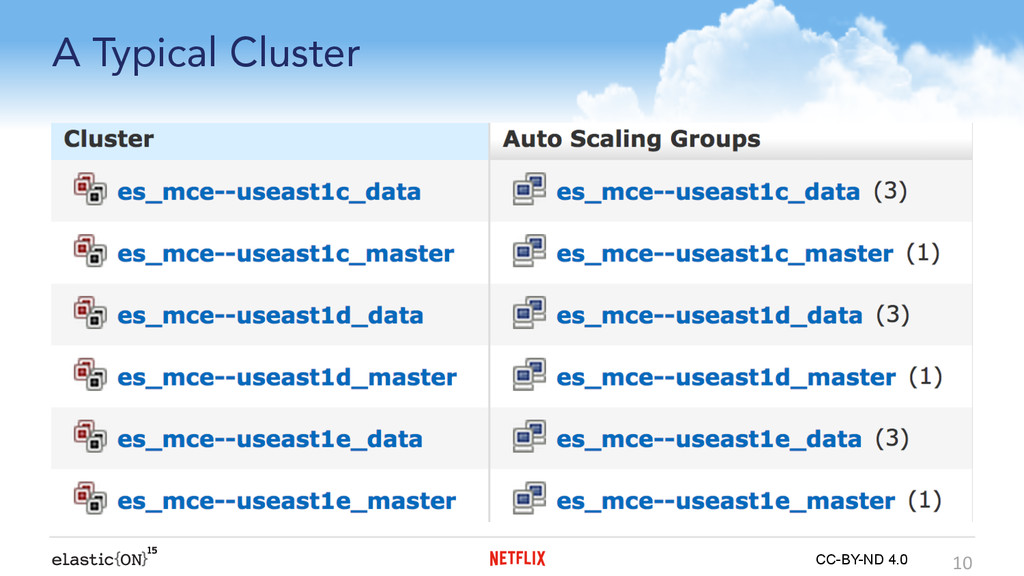{kind=link}
{kind=link}
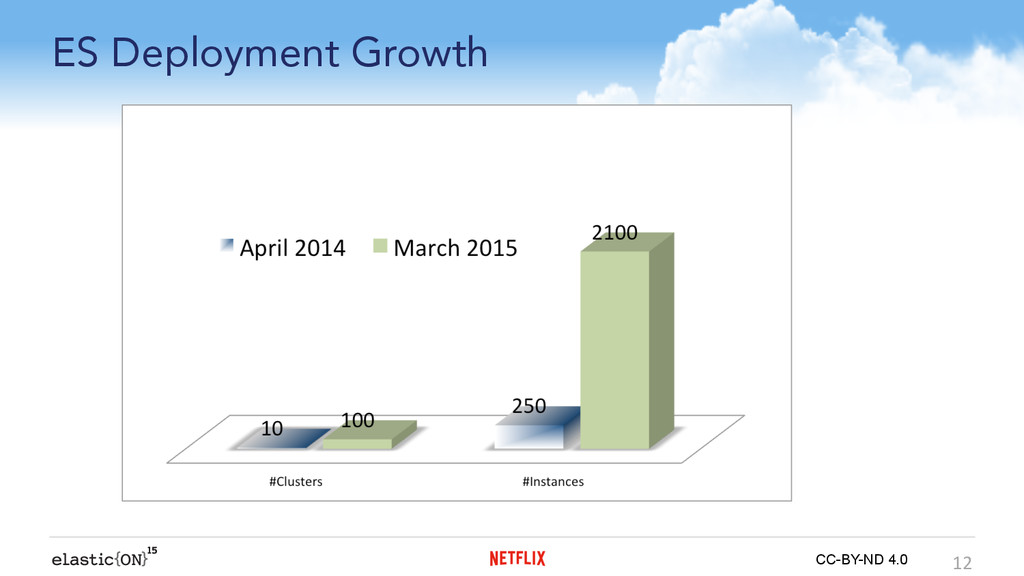{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
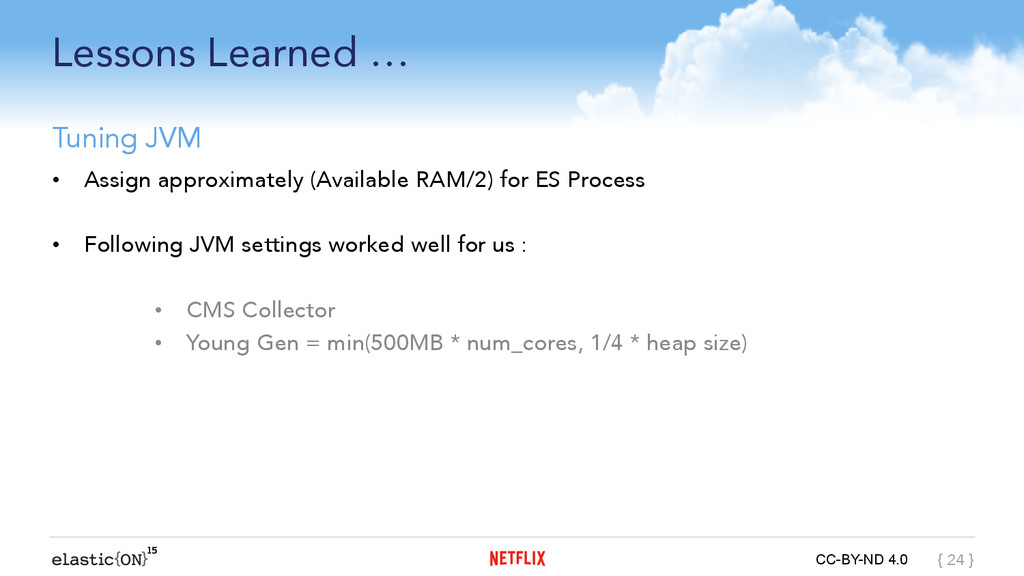{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}