From server health checks to network monitoring to customer activity events -- logs are everywhere at DigitalOcean. In a single day, we collect more than a terabyte of real-time log data over our entire operations infrastructure. Buried in that non-stop stream of data is everything we need to know to keep DigitalOcean's cloud services up and running. This talk covers how we collect, parse, route, store, and make this data available to operations and engineers while keeping things simple enough for a small team to manage.
Elastic{ON} Tour | New York City | November 17, 2015
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
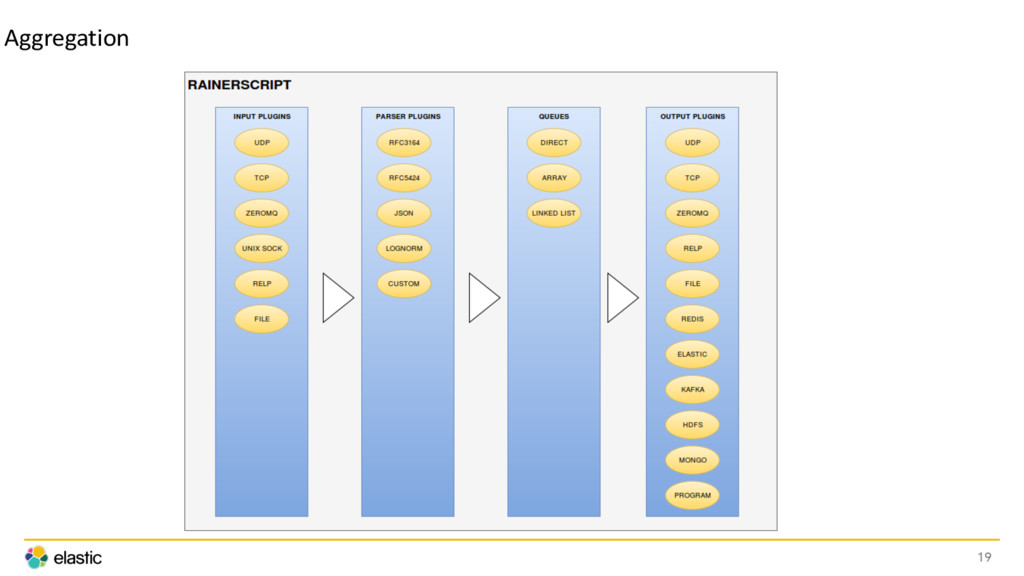{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
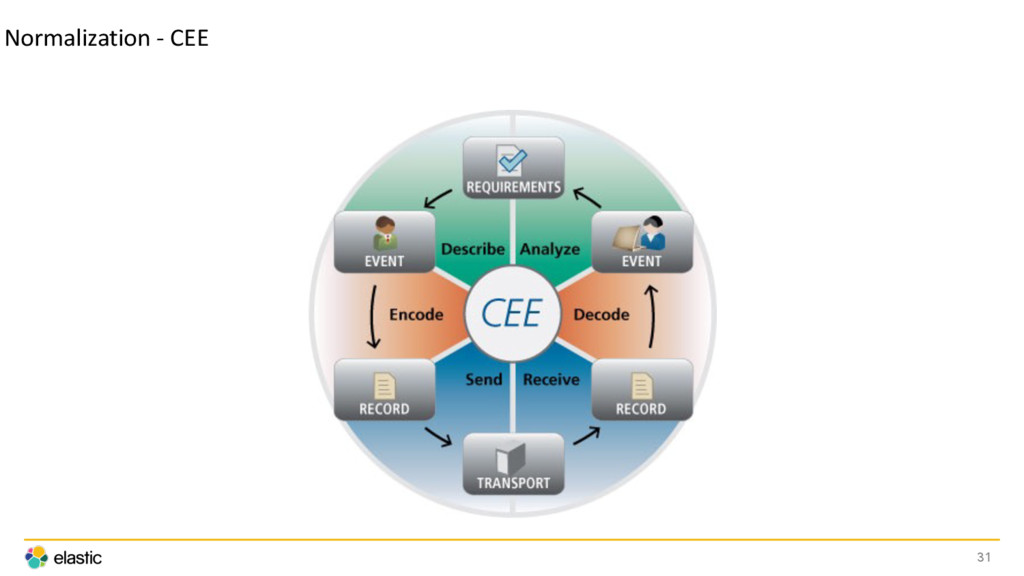{kind=link}
{kind=link}
{kind=link}
{kind=link}
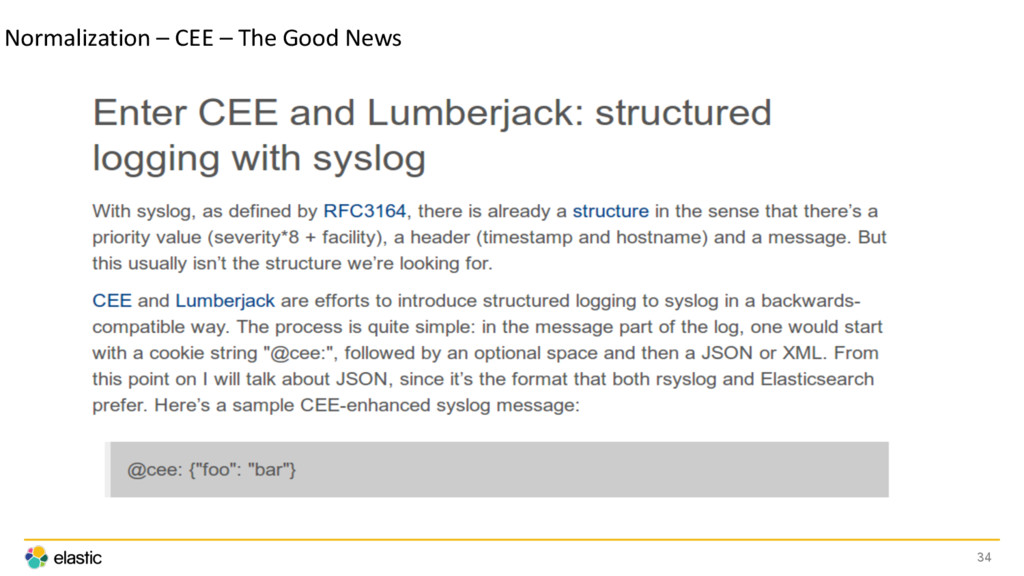
![Normalization - CEE <190>2015-03-25T16:57:40.945788-04:00 prod-imageindexer01 indexer[13813]: @cee:{"action":"image_delete", "controller":"images", "count":0, "egid":0,](https://files.speakerdeck.com/presentations/15755434090643409ac794dc9a20bde7/slide_34.jpg){kind=link}
{kind=link}
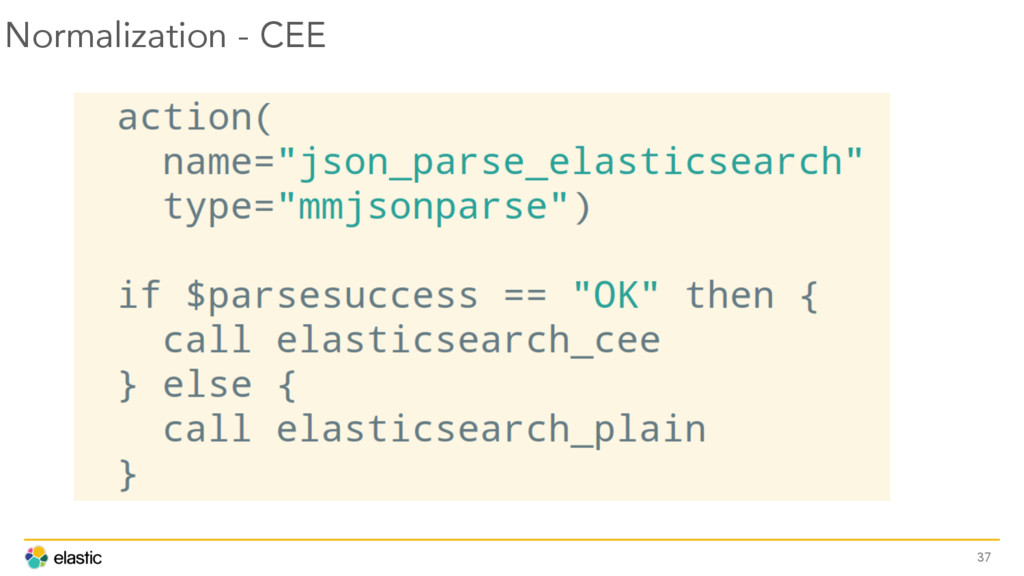{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
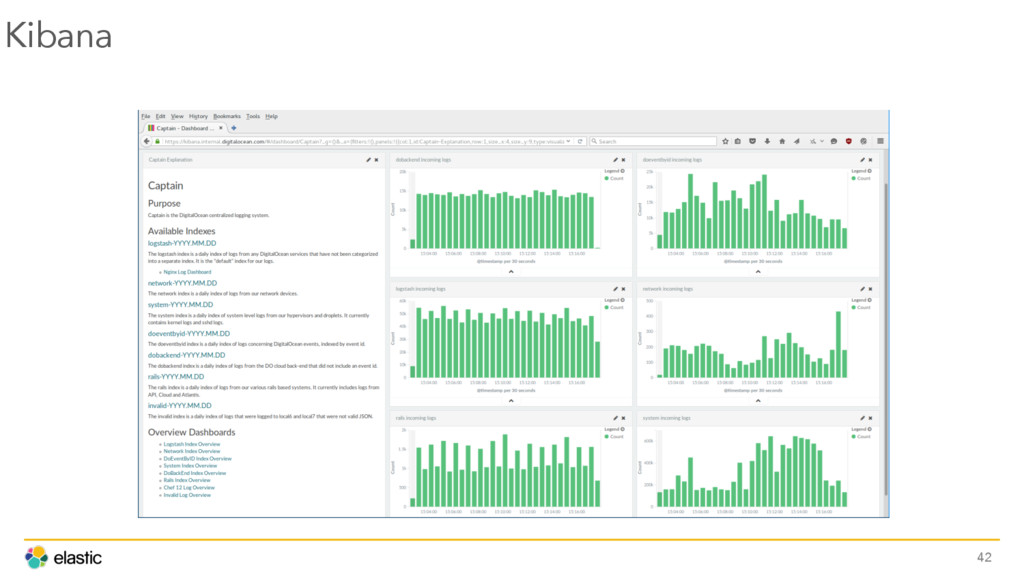{kind=link}
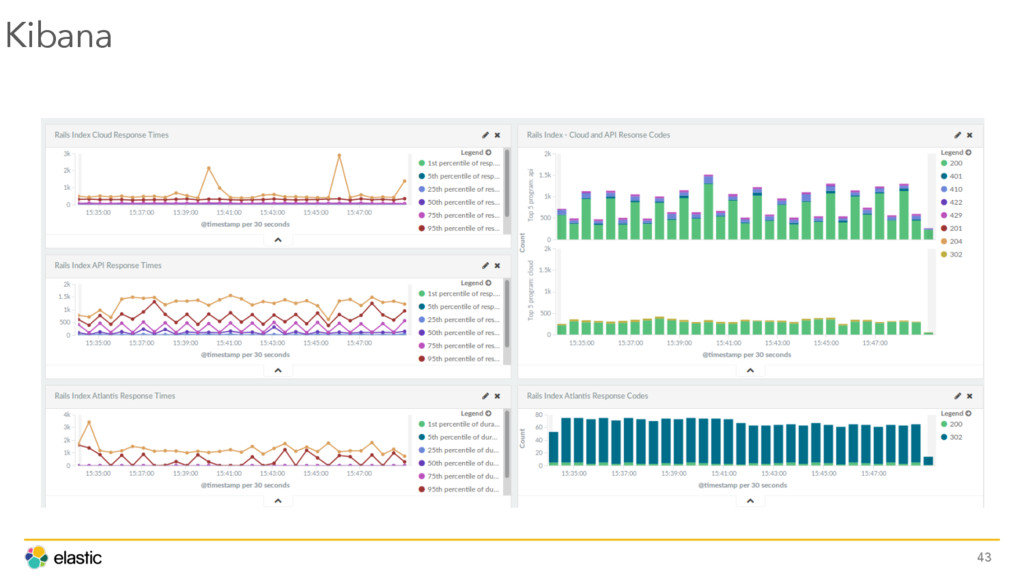{kind=link}
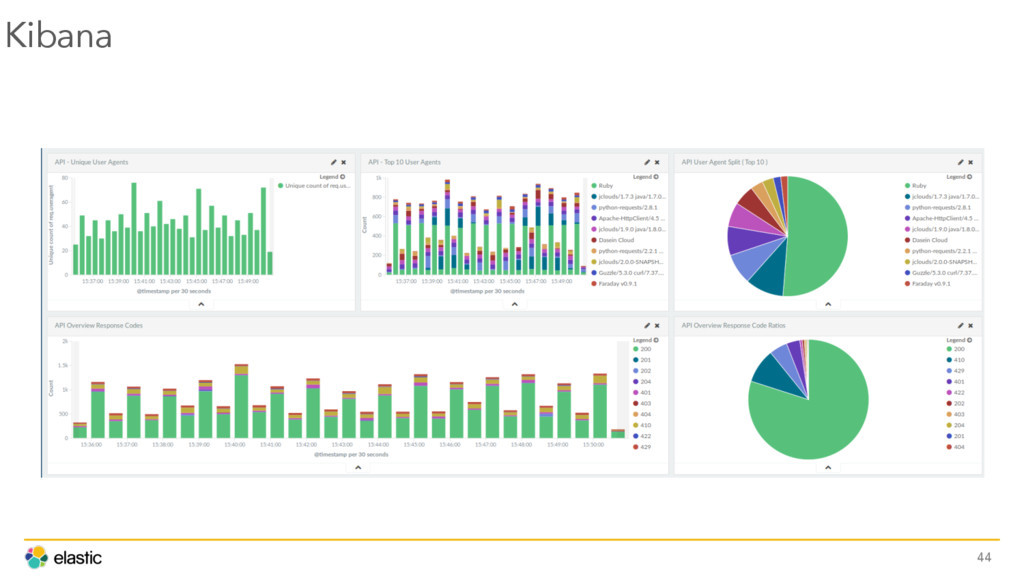{kind=link}
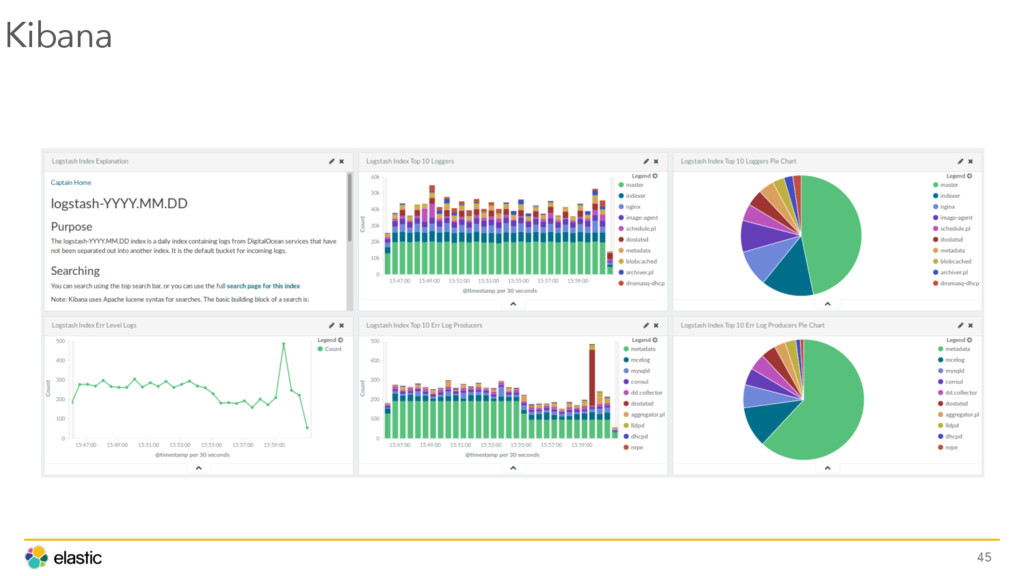{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
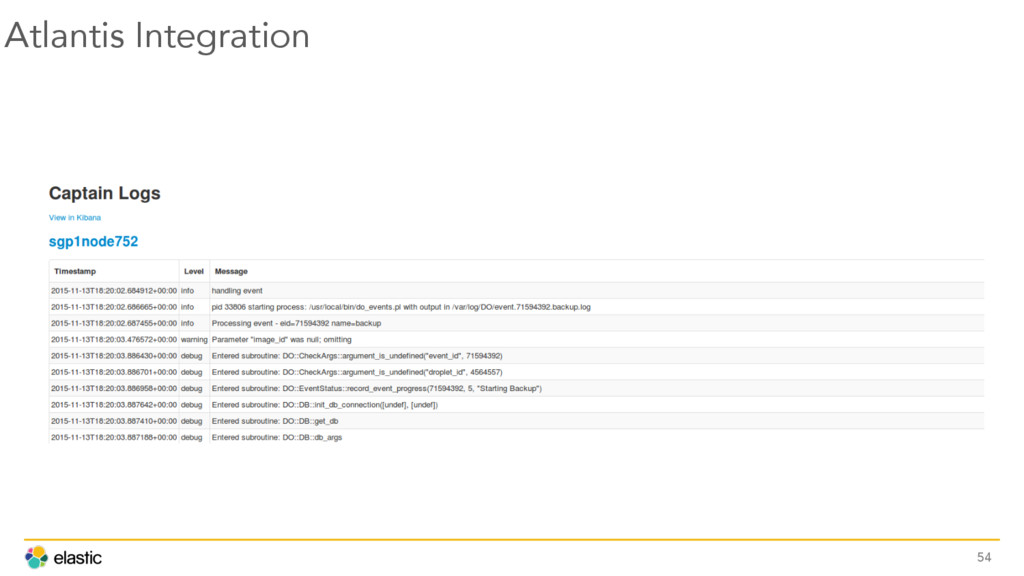{kind=link}
{kind=link}
{kind=link}
{kind=link}
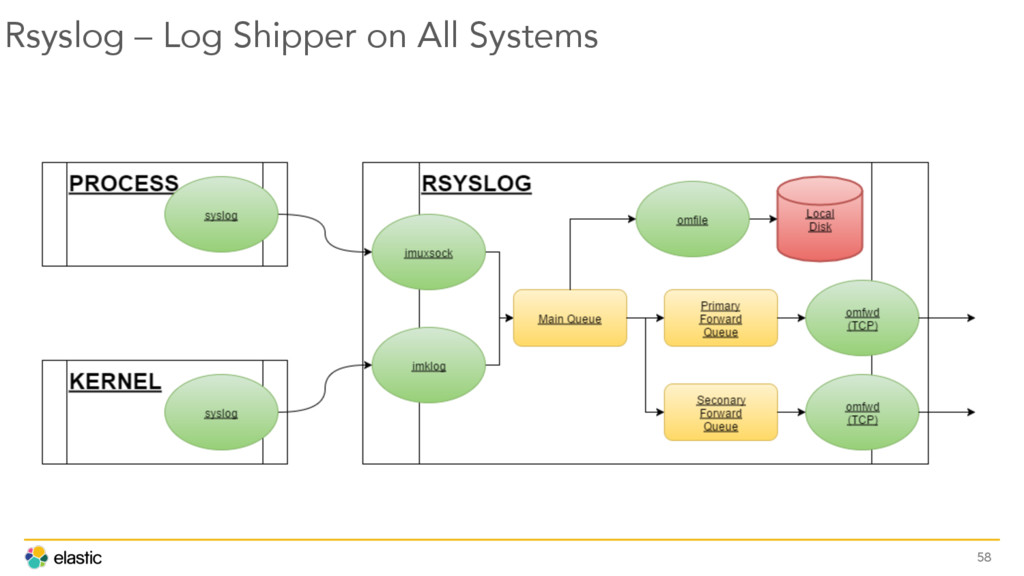{kind=link}
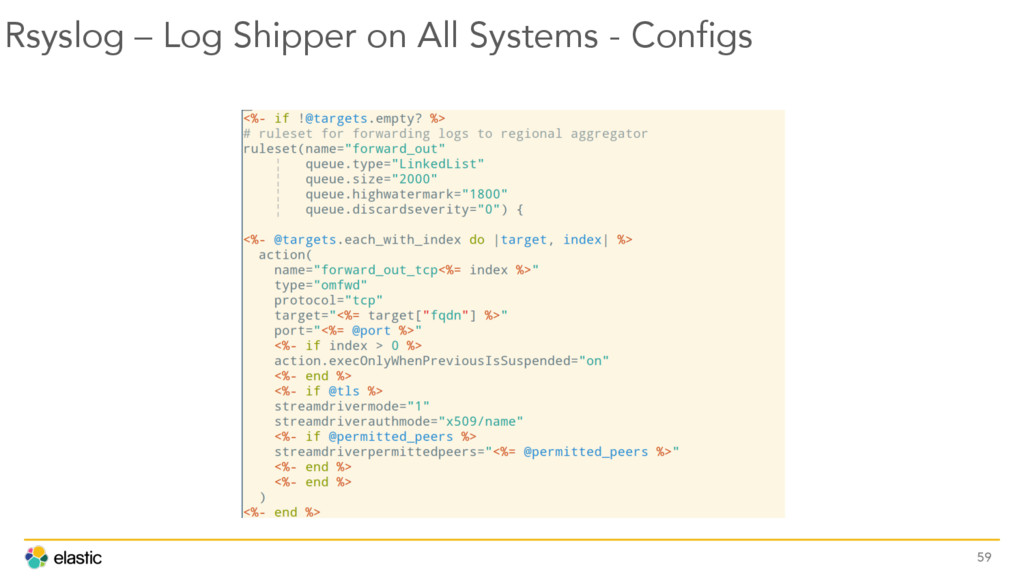{kind=link}
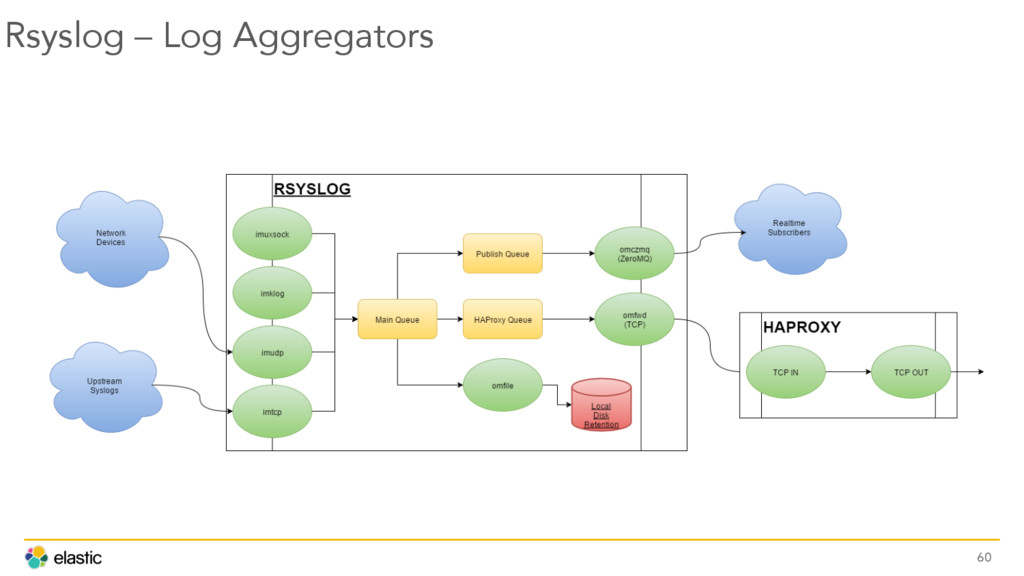{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
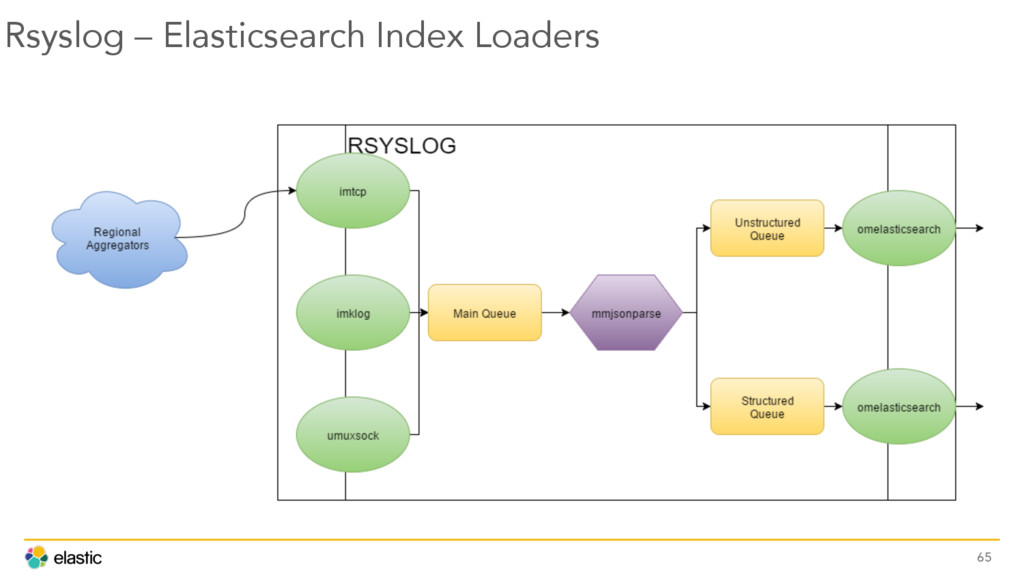{kind=link}
{kind=link}
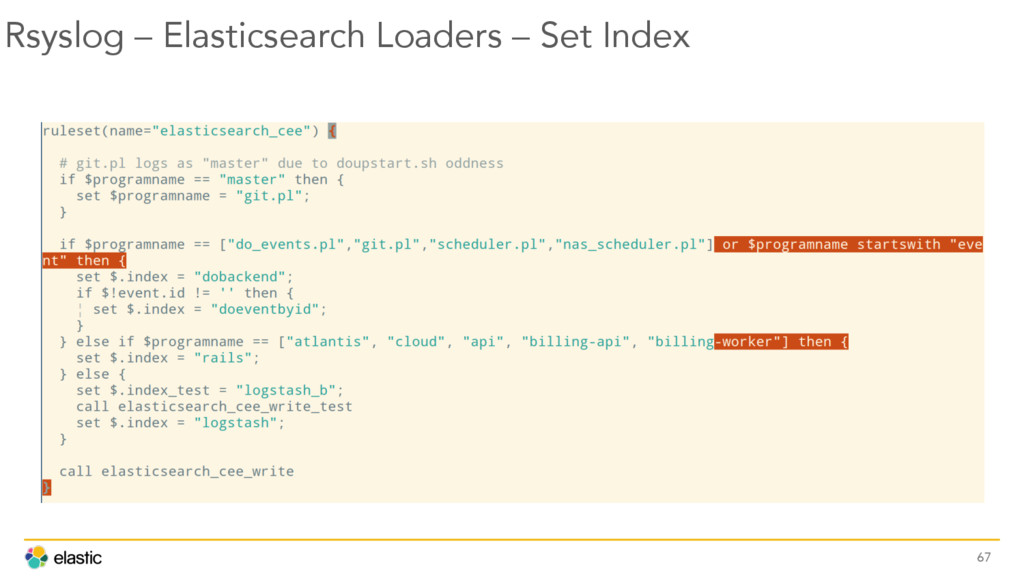{kind=link}
{kind=link}
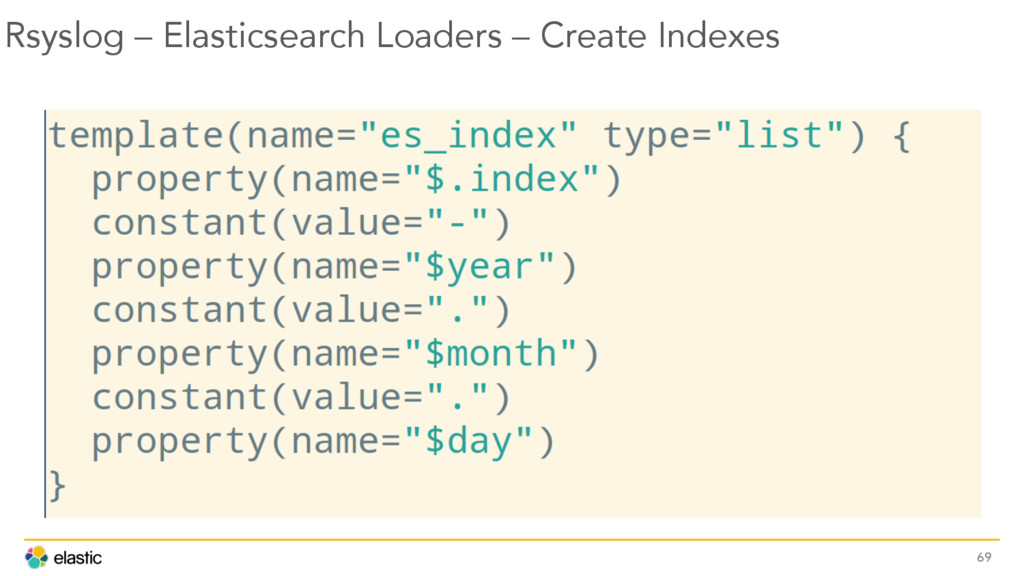{kind=link}
{kind=link}
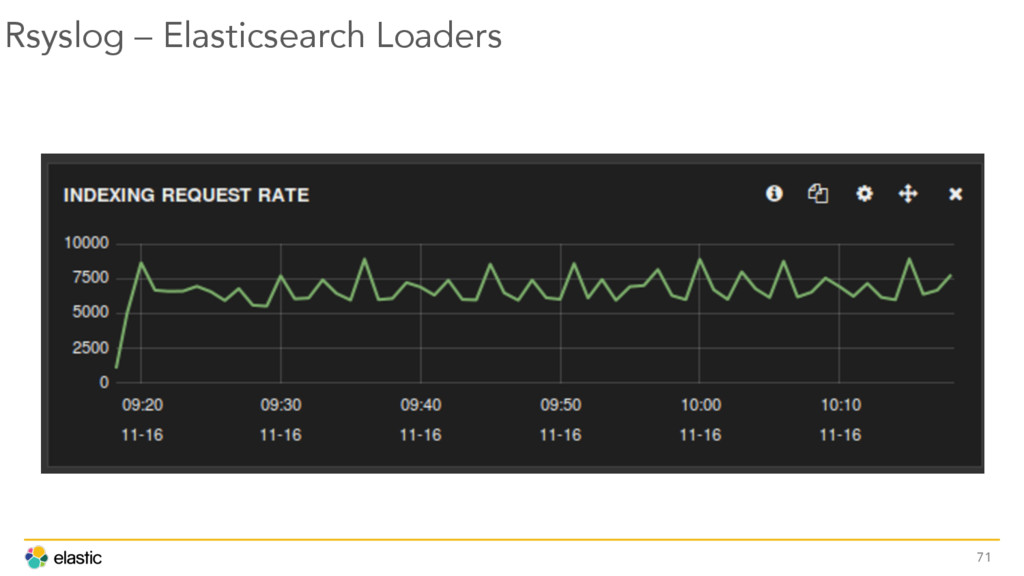{kind=link}
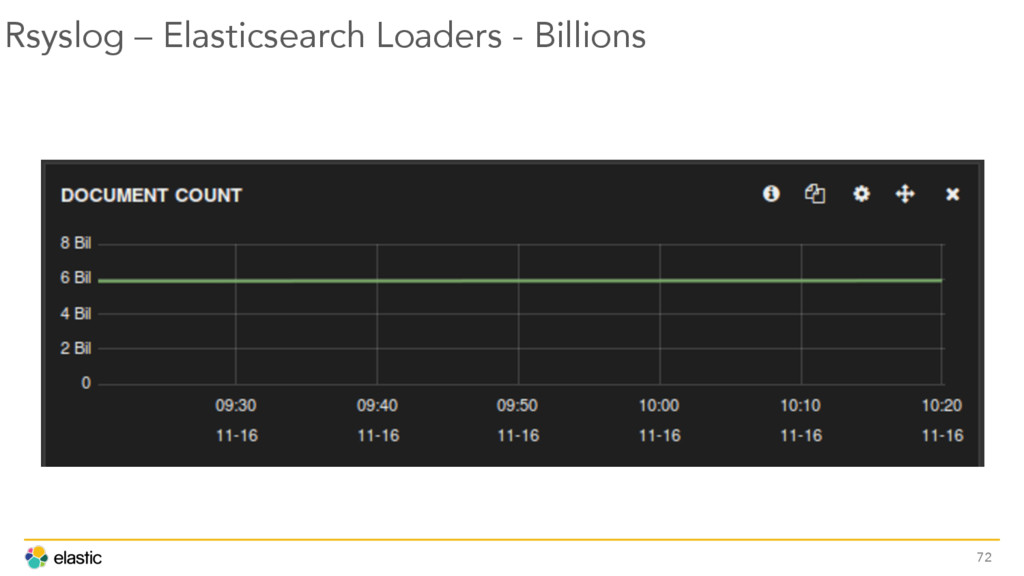{kind=link}
{kind=link}
{kind=link}
{kind=link}
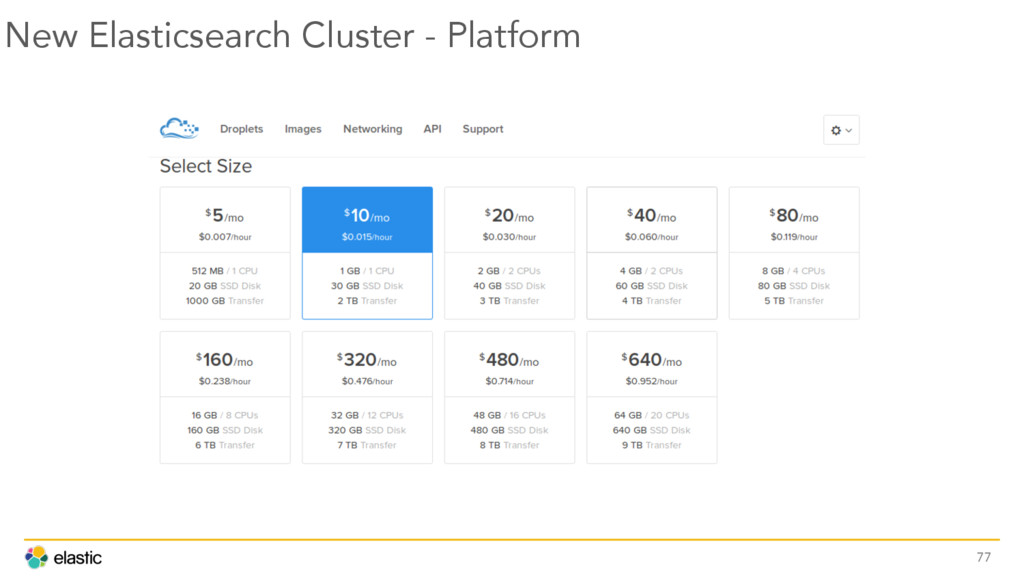
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
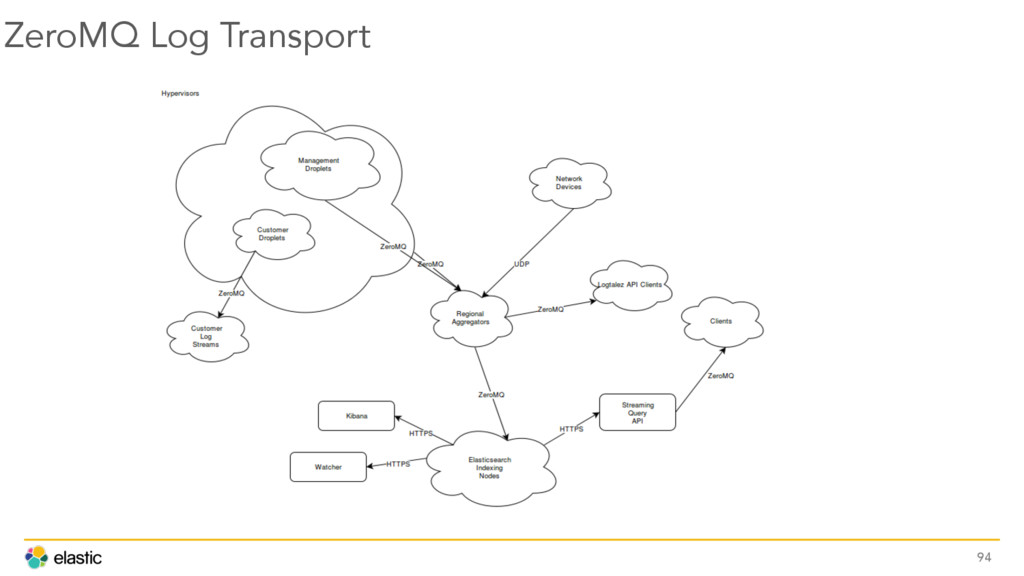
{kind=link}
{kind=link}
{kind=link}