the Netherlands and Belgium • Product owner & tech lead for 2 platforms: metrics & logsearch • Opensource user + contributor • Husband and dad of 2 cool kids! 3 Please to meet you
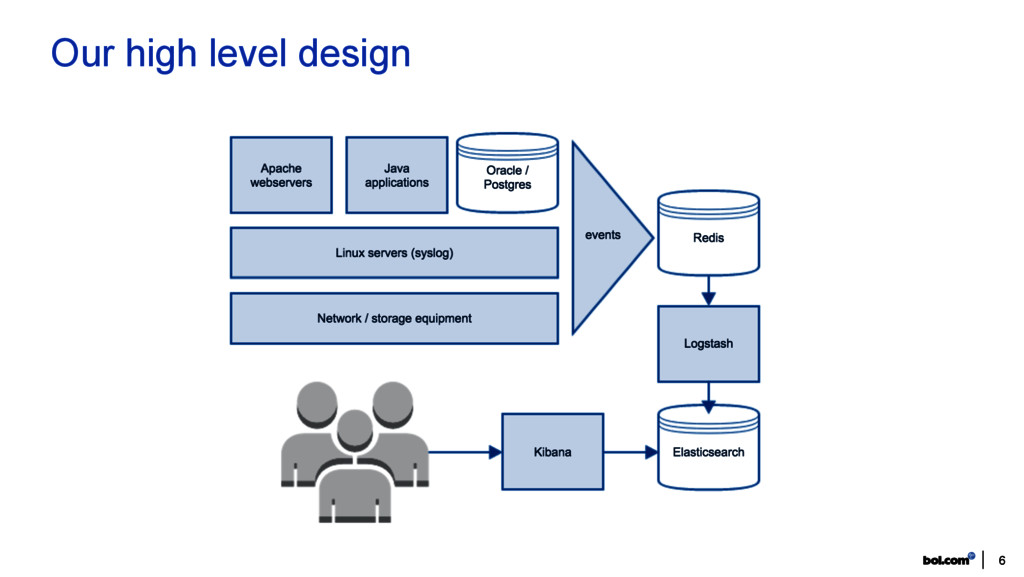
from many layers of our infrastructure. Central user interface for querying: Kibana. For software developers, system engineers & our security team (~300 potential users). Supports development & operations co-op (sharing Kibana dashboards = 1 truth). Bottomline: faster incident resolution = less revenue loss. 4 bol.com & ELK
in 2014. Getting feeds from: • 3 datacenters • 5 frontend apps, 80+ services • lots of databases Log types: Apache and Tomcat access logging, Log4j, PostgreSQL, Oracle, syslog, … Numbers: • 1600+ servers emitting log events • 500-600 million events per day, indexing peaks at 25k/sec • 23 billion events stored, 14TB * 2 on disk • We keep 90 days available for search. 5 ELK as 1st class citizen
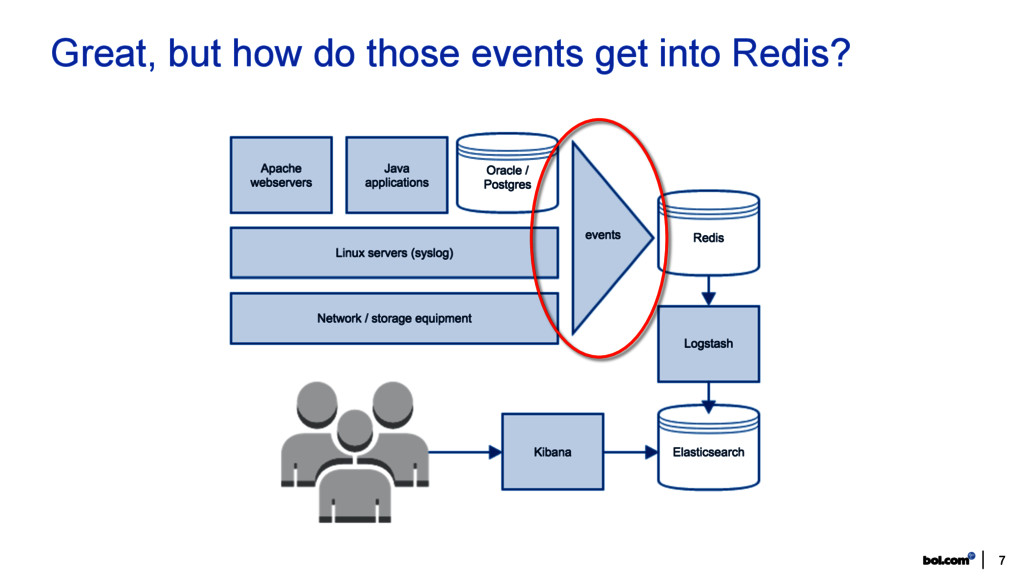
UDP. Lots of grokking. Logstash (1 instance) unable to process feed in real time => data loss, incomplete events. Need for speed & simplicity! • Scale Logstash instances. Use Redis as message bus, to feed multiple Logstash instances. • Reduce need for complex grok. Format events in a structured format. In 2015: events get converted into JSON docs at the source. Our shippers run inside JVMs and DBs. Logstash reads from Redis and decodes events. No more grokking. Logstash out of work? No. Cleanup, enrichment (IP geo location) and metrics generations (lag, throughput). 8 Struggles in log shipping
JSON doc and send to Redis: https://github.com/bolcom/redis-log-valve Java application logging (Log4j): Inside JVM: convert events into JSON doc and send to Redis: https://github.com/bolcom/log4j-jsonevent-layout + https://github.com/bolcom/log4j-redis-appender Webserver access logging (Apache): • Custom LogFormat to output ‘hit’ as JSON: http://untergeek.com/2013/09/11/getting-apache-to-output-json-for-logstash-1-2-x/ • Apache sends JSON docs to external process, which sends to Redis. Docker logging: Shipper container: subscribes to logs for all running containers, convert events into JSON doc and send to Redis: https://github.com/bolcom/logspout-redis-logstash Oracle logging: Inside database: custom PL/SQL package with API, creates JSON docs and send to Redis. PostgreSQL logging: Inside database: hooks into logging, convert events into JSON doc and send to Redis: https://github.com/2ndquadrant-it/redislog 9 The logshippers we use
connected to 25 services. Request ID gets attached to all service calls. It gets logged in many places. Correlation time! Search for a Request ID and see: • initial Webshop request • all service calls made Including: order, parameters, status codes and responsetimes. 10 Special sauce 1/2: the call stack
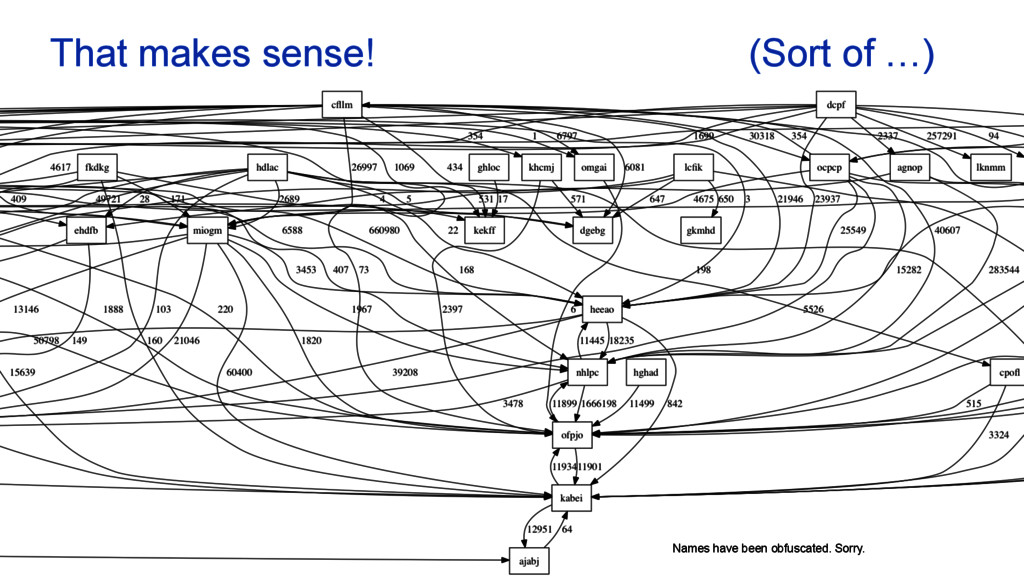
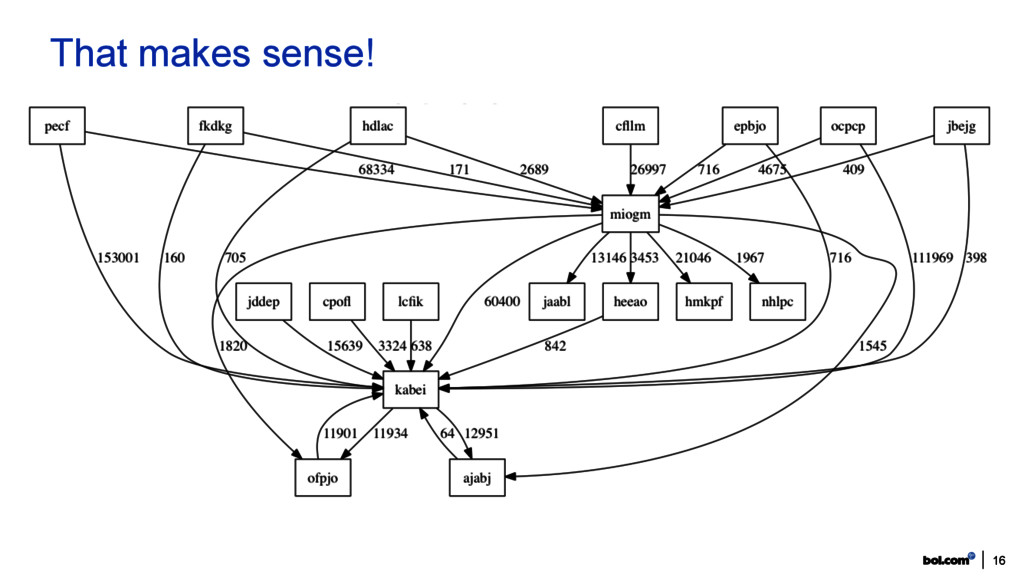
services. New services get introduced. New connections are made. Canary releases. A/B testing… Its a living distributed architecture. We need a map, we can trust! Let’s build a directed graph. • Use the Tomcat access logging • Add “A called B” information • Elasticsearch aggregation query • Transform the result and draw graph 11 Special sauce 2/2: the service map
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Renzo Tomà [email protected] Thanks!](https://files.speakerdeck.com/presentations/d0f3411bc4b74a1bbfa45185e3f82e7c/slide_16.jpg){kind=link}