Abstract: The 5.0 release of Elasticsearch took advantage of the cleanups in 2.0 to add a slew of new features on top of a rock-solid foundation. Ryan will give an overview of the changes already released in the 5.x series, and a taste of the big new features coming in 6.0.
Ryan Ernst is an Apache Lucene/Solr committer and PMC member. He is an Elasticsearch developer and enjoys working on anything with bits. Prior to Elastic, he worked on Amazon's Product Search and AWS CloudSearch.
https://www.meetup.com/Silicon-Valley-Elastic-Fantastics/events/241914389/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
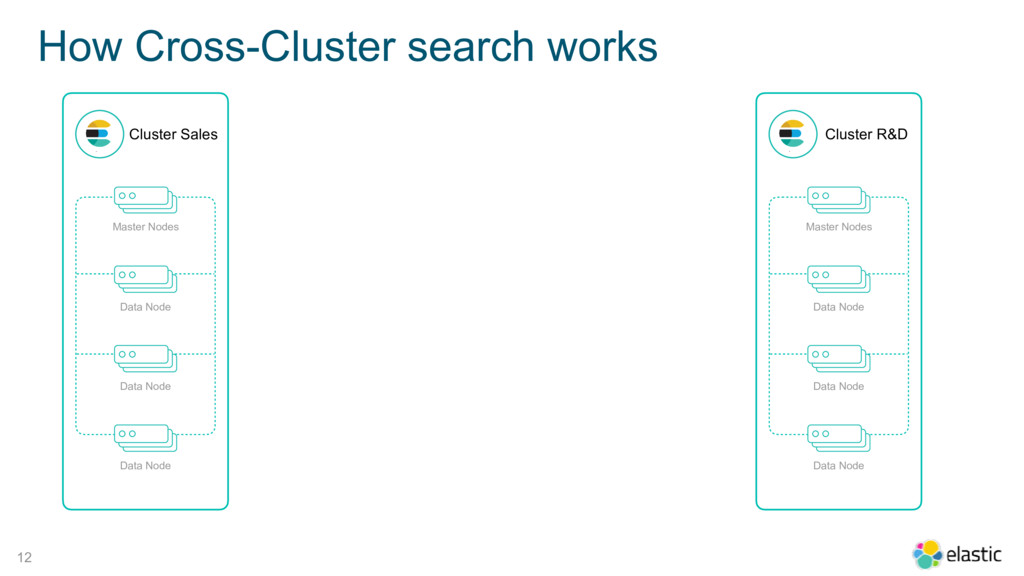{kind=link}
{kind=link}
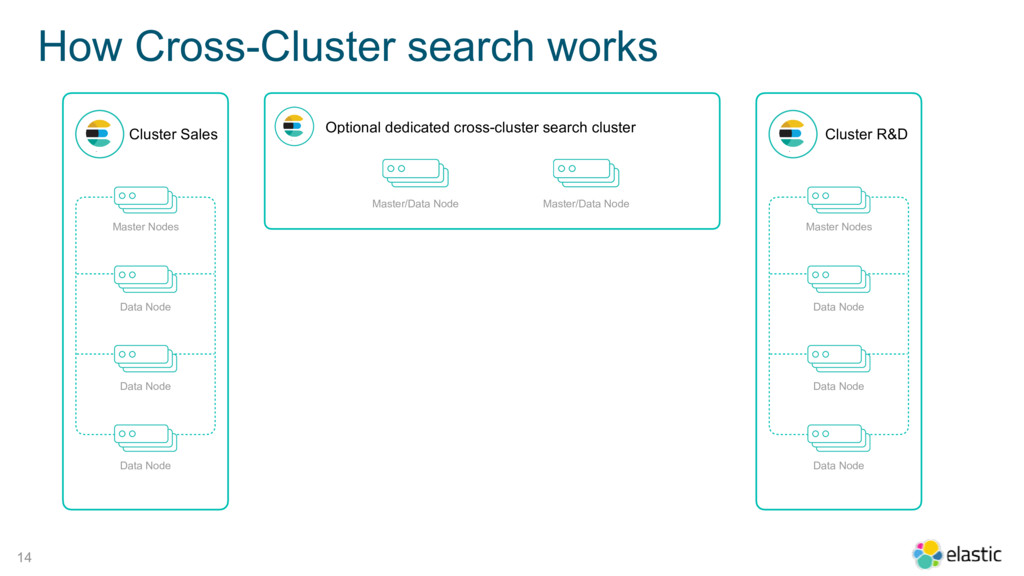{kind=link}
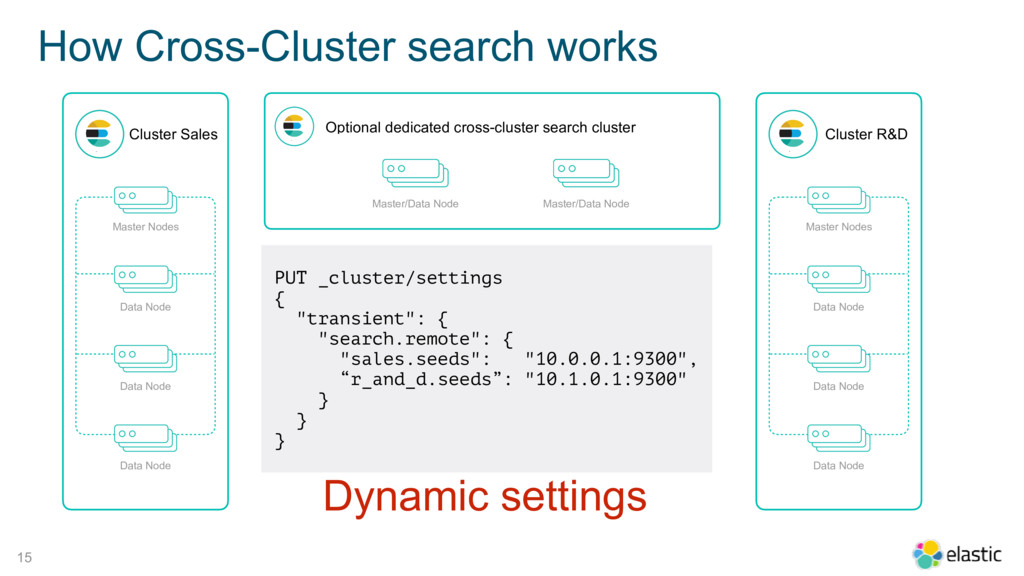{kind=link}
{kind=link}
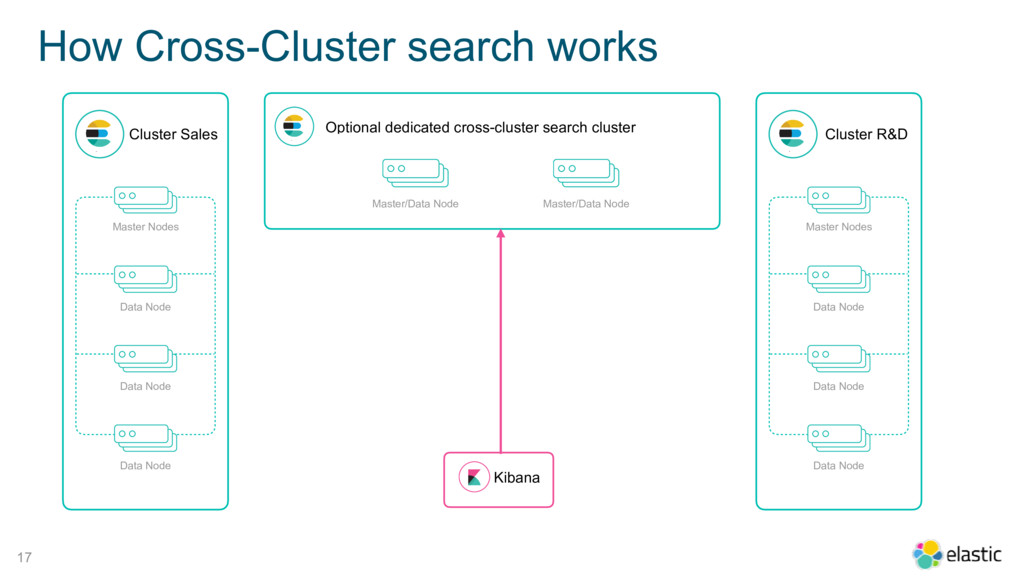{kind=link}
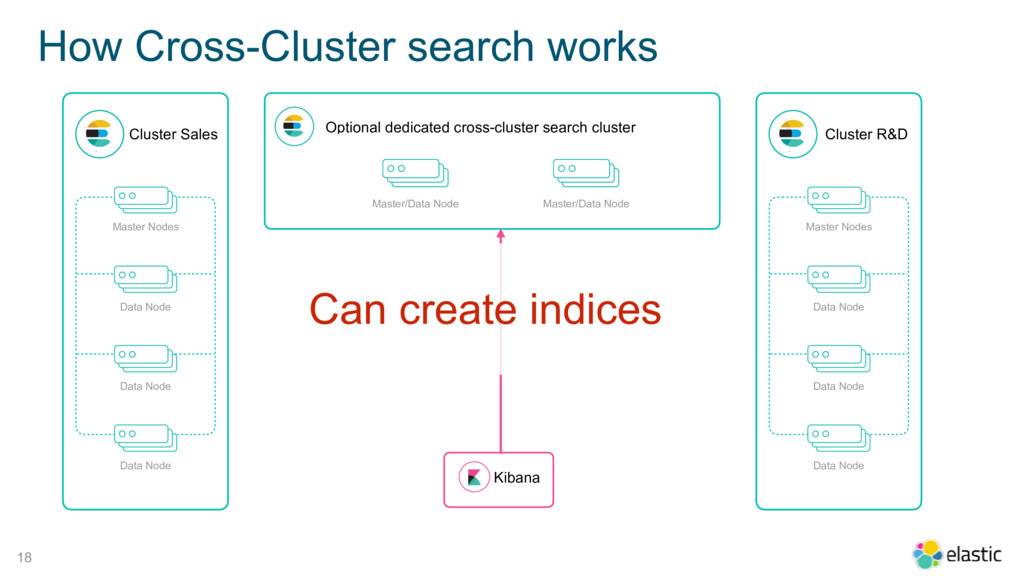{kind=link}
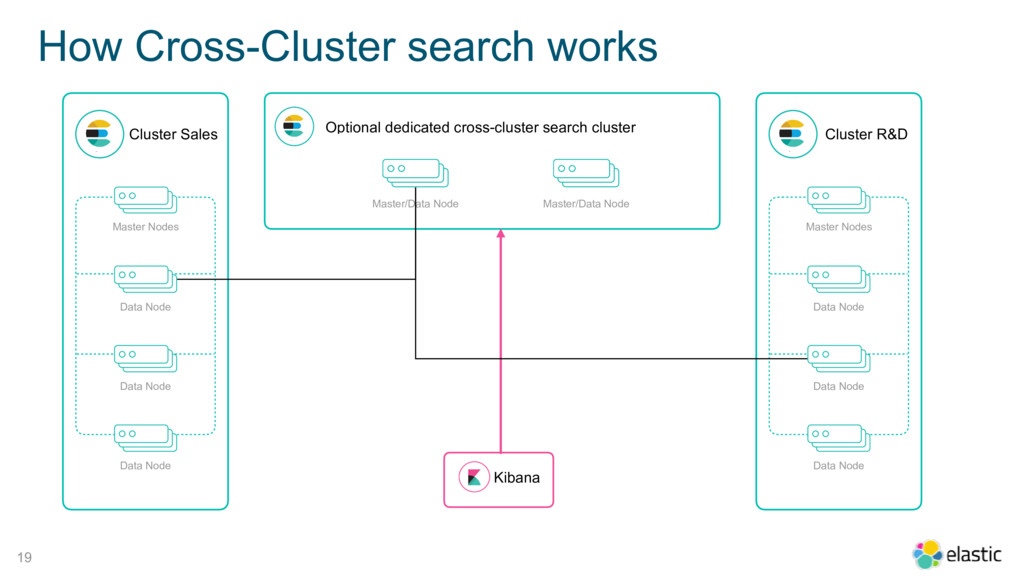{kind=link}
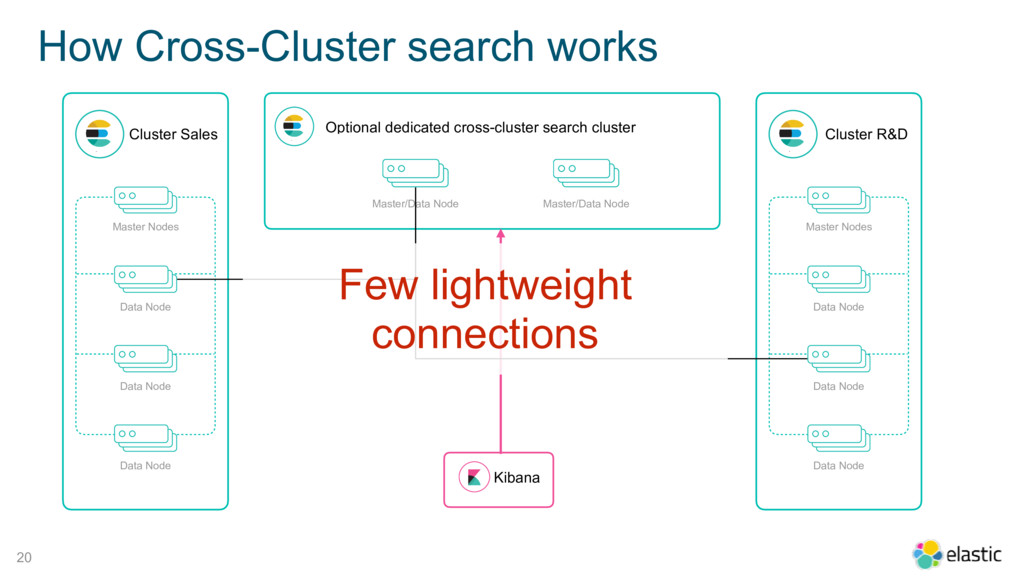{kind=link}
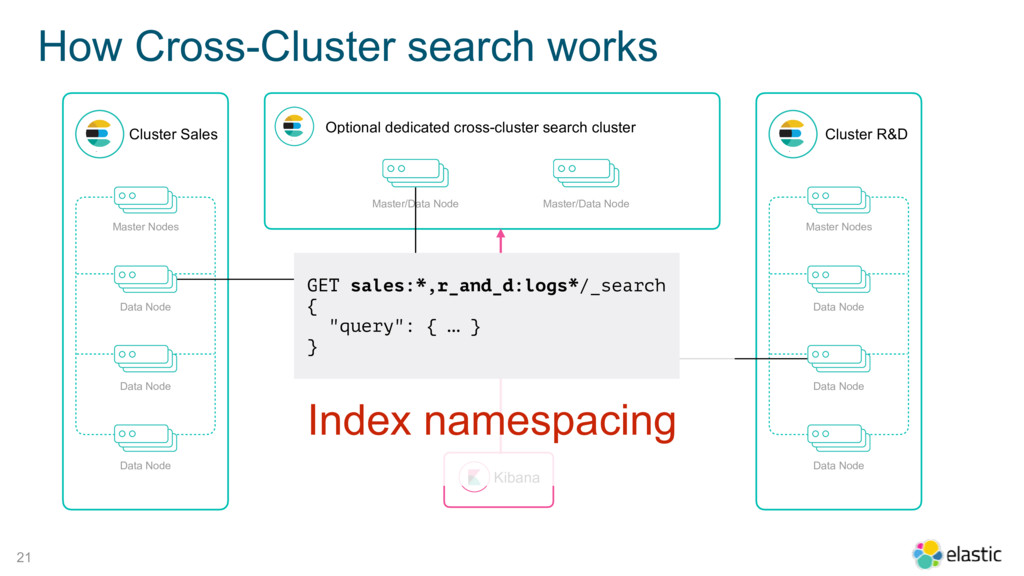{kind=link}
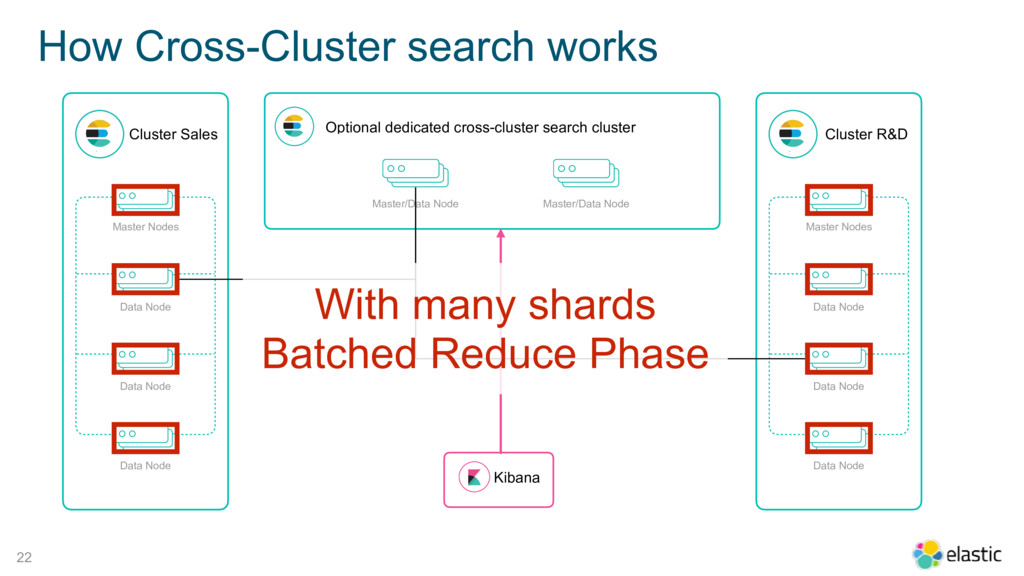{kind=link}
{kind=link}
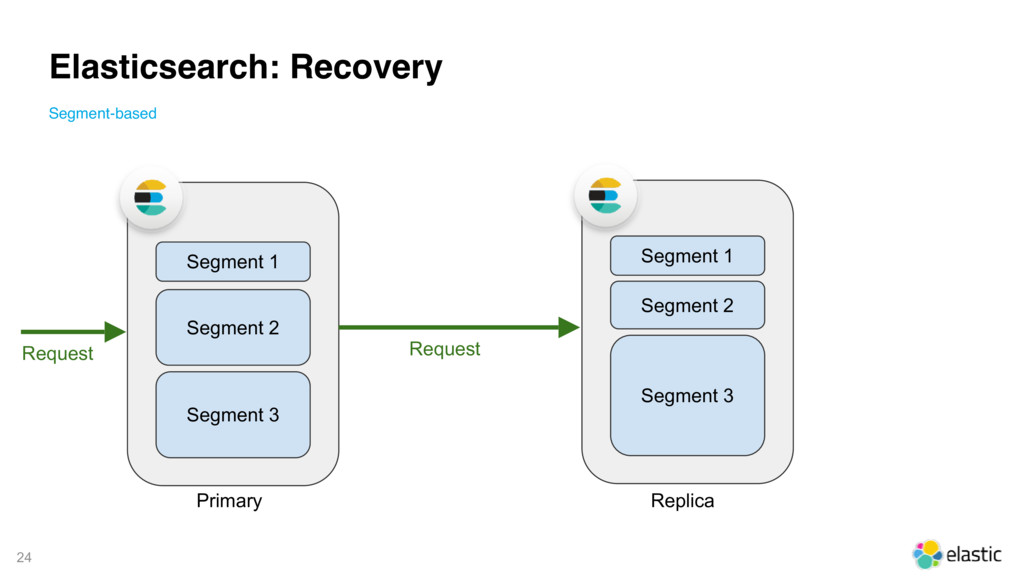{kind=link}
{kind=link}
{kind=link}
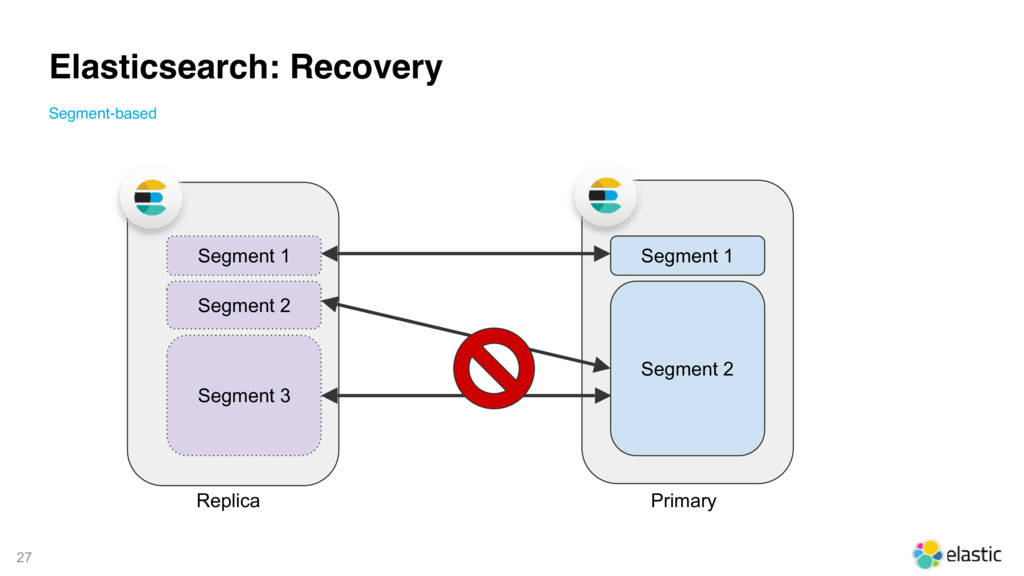{kind=link}
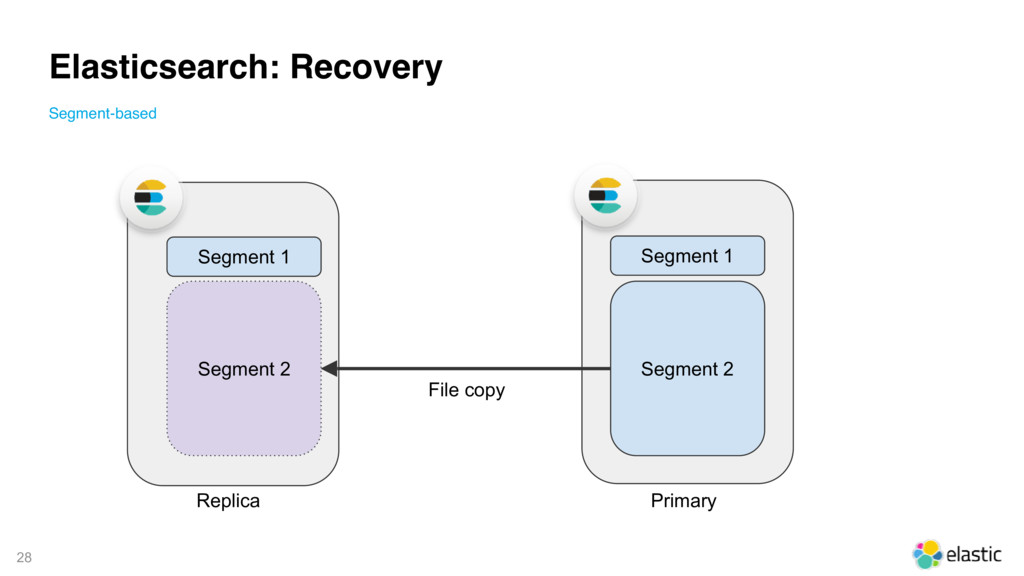{kind=link}
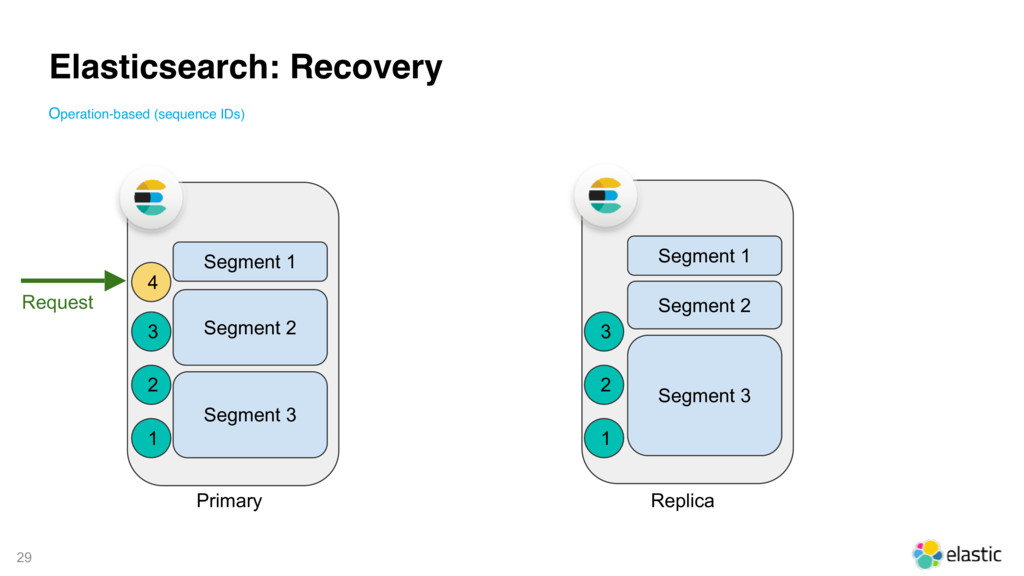{kind=link}
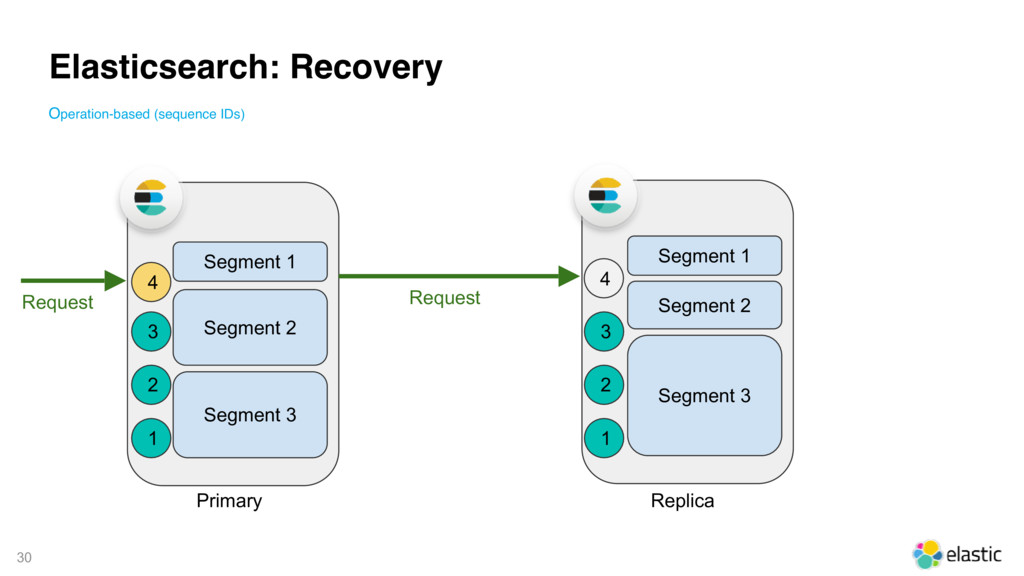{kind=link}
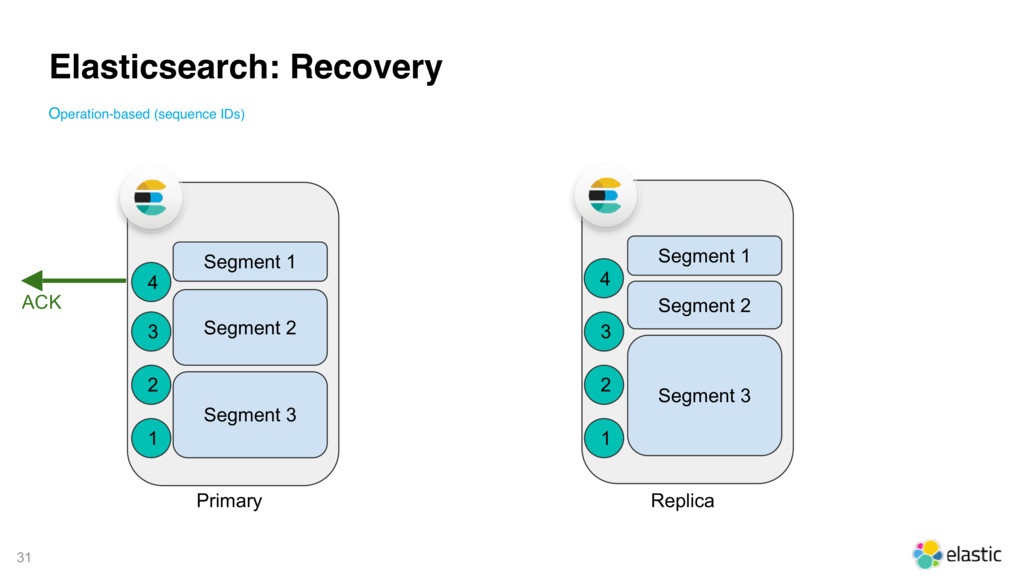{kind=link}
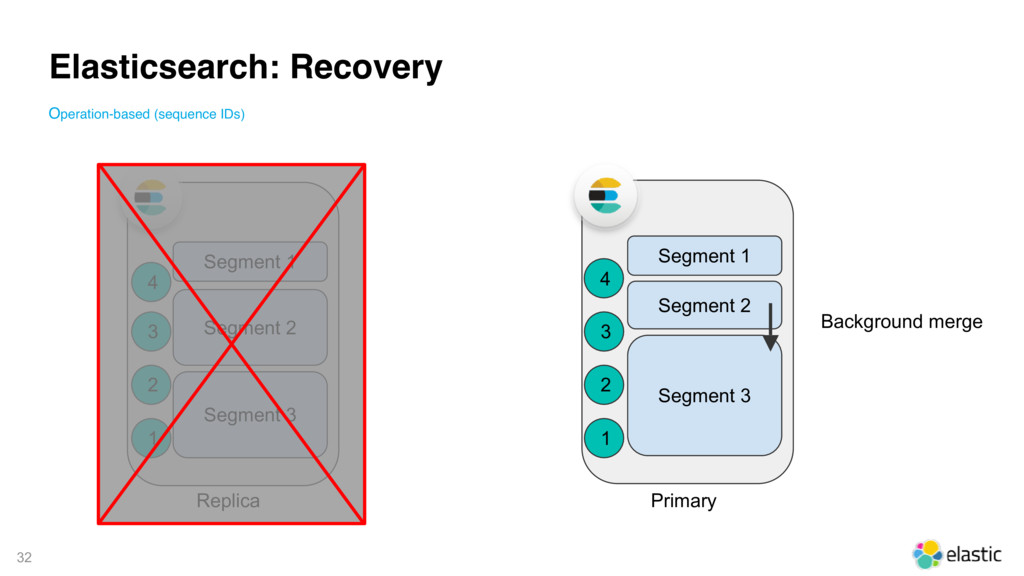{kind=link}
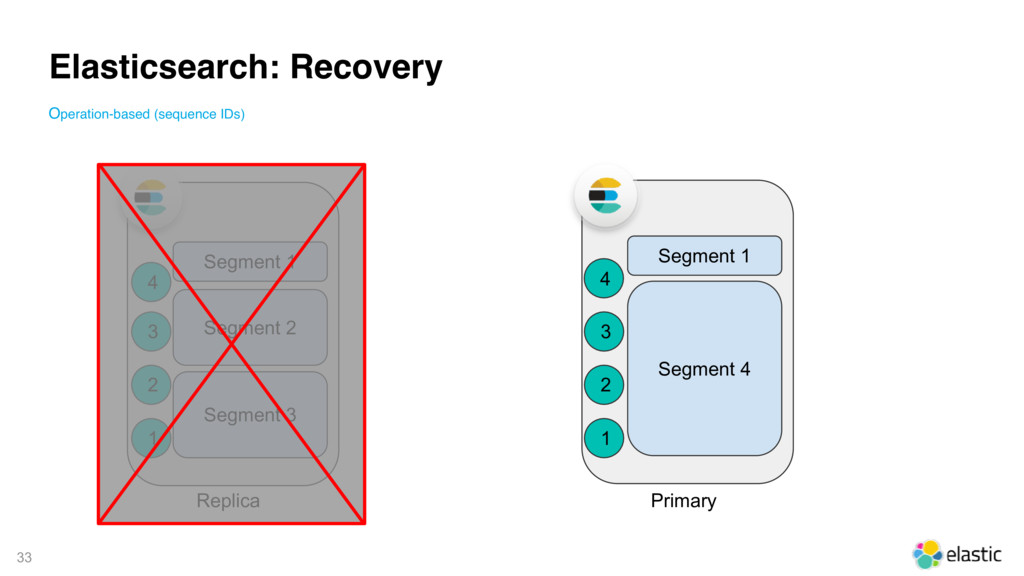{kind=link}
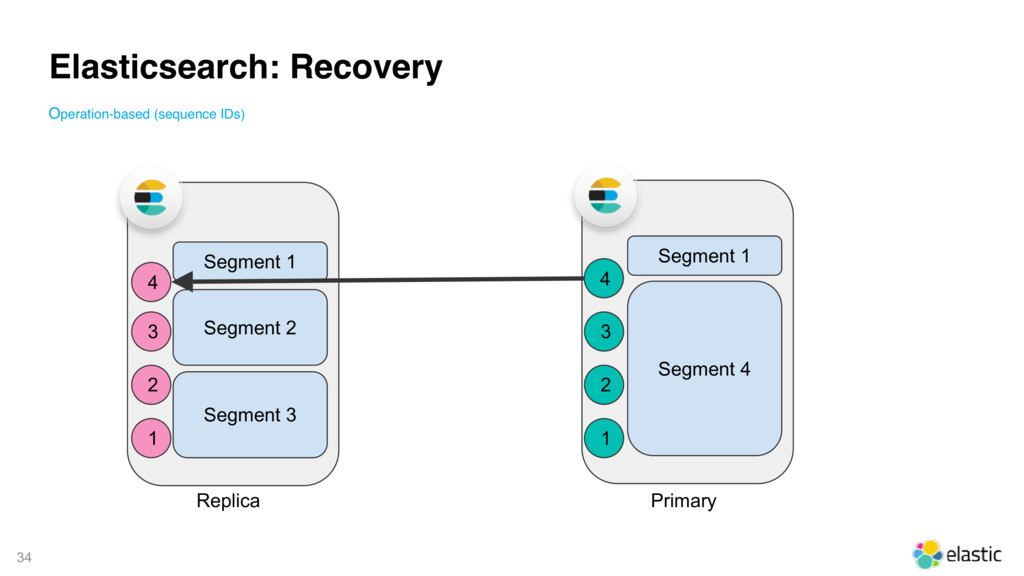{kind=link}
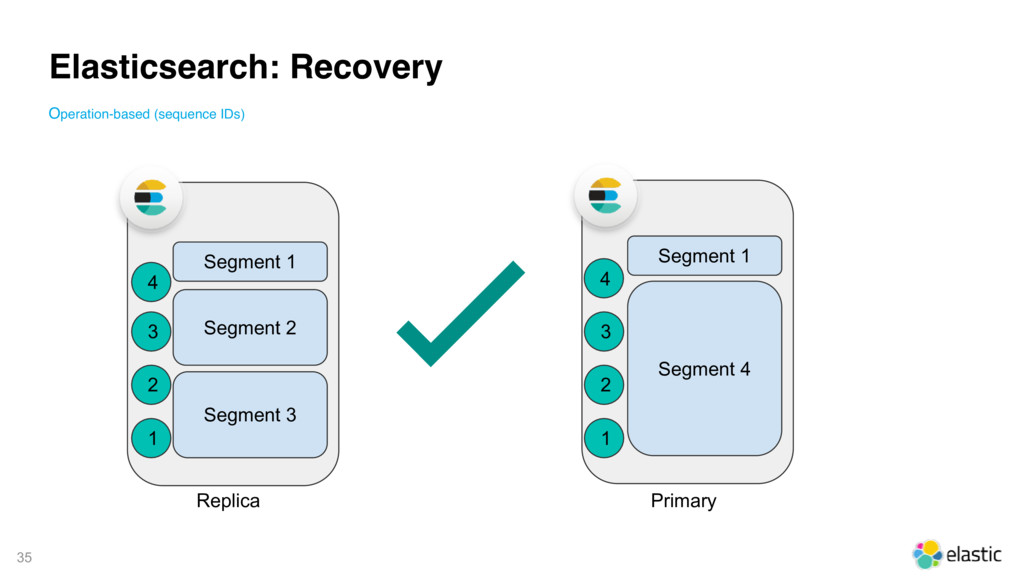{kind=link}
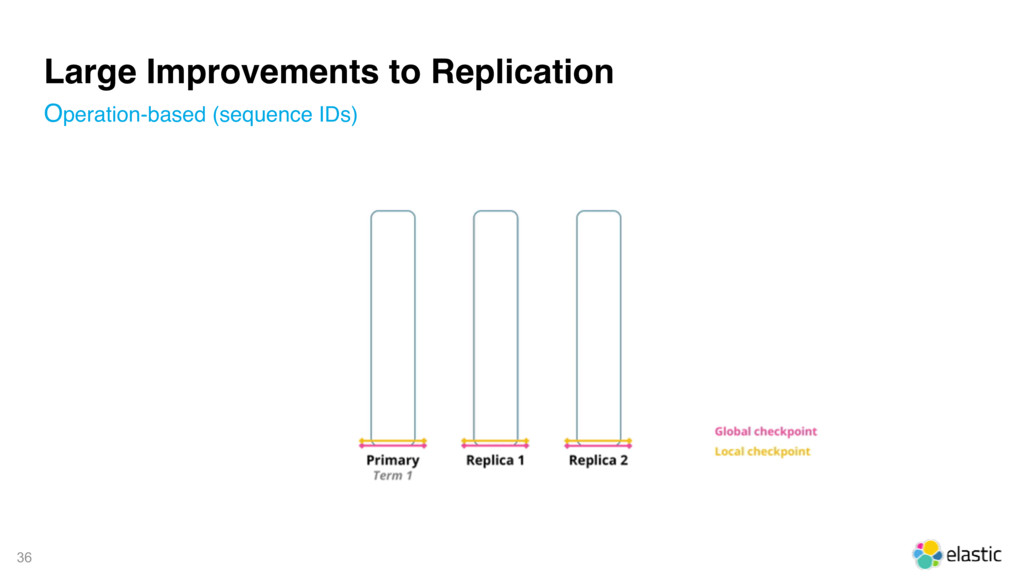{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}