Forests: A Unified Framework for Classification, Regression, Density Estimation, Manifold Learning and Semi-Supervised Learning, Foundations and Trends in Computer Graphics and Vision, 2012.
and train on large data Can deal with a huge number of features Naturally multi-class Noise-resistant, generalizes well Non-parametric Easy to use, just two hyperparameters
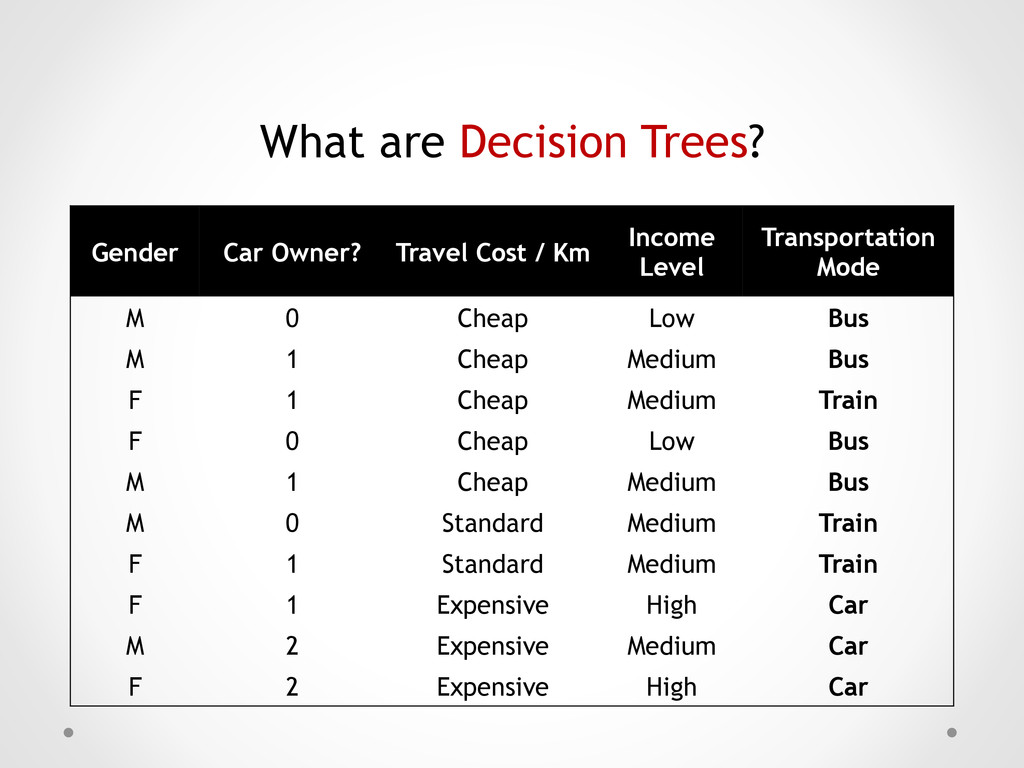
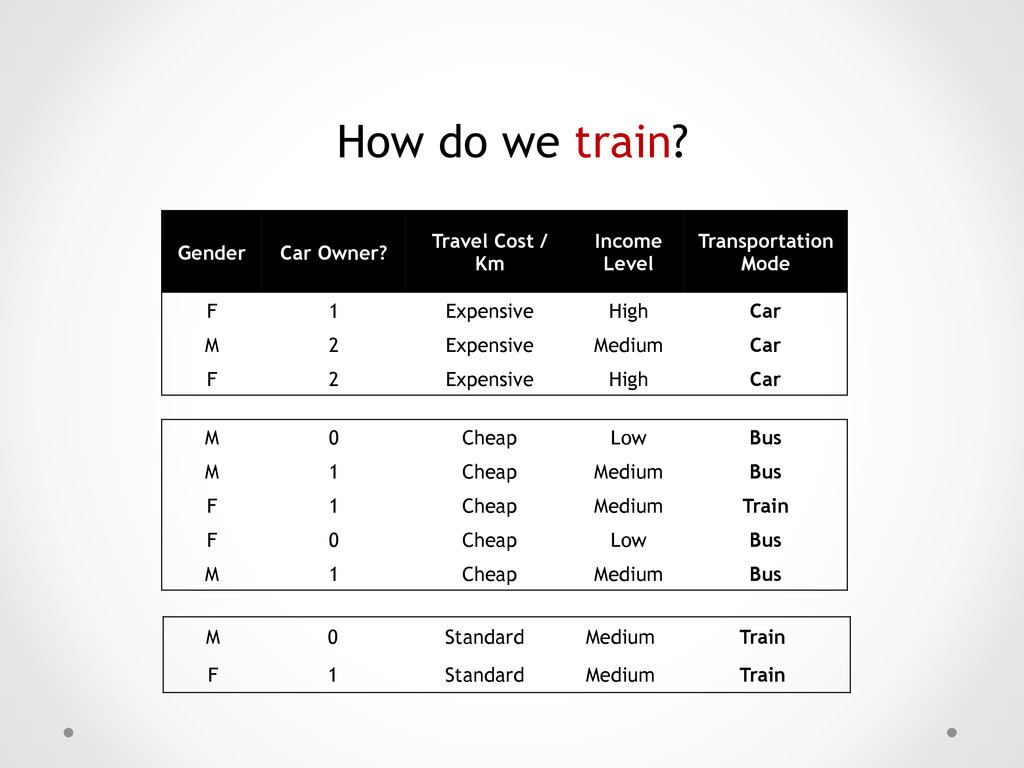
Km Income Level Transportation Mode M 0 Cheap Low Bus M 1 Cheap Medium Bus F 1 Cheap Medium Train F 0 Cheap Low Bus M 1 Cheap Medium Bus M 0 Standard Medium Train F 1 Standard Medium Train F 1 Expensive High Car M 2 Expensive Medium Car F 2 Expensive High Car
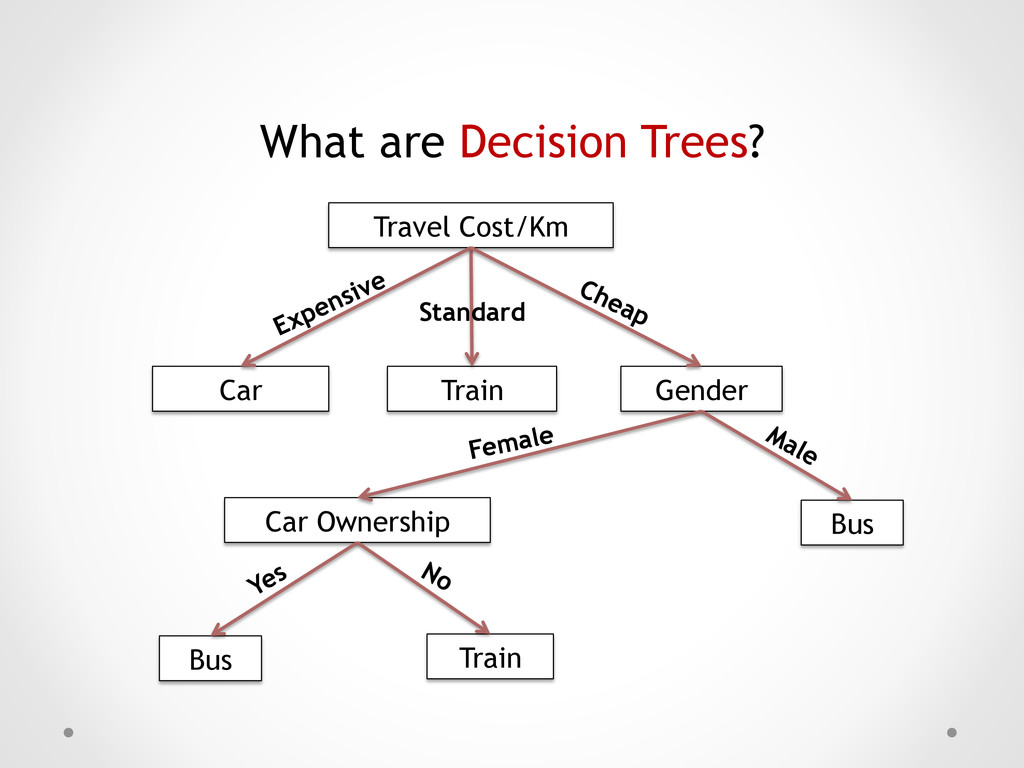
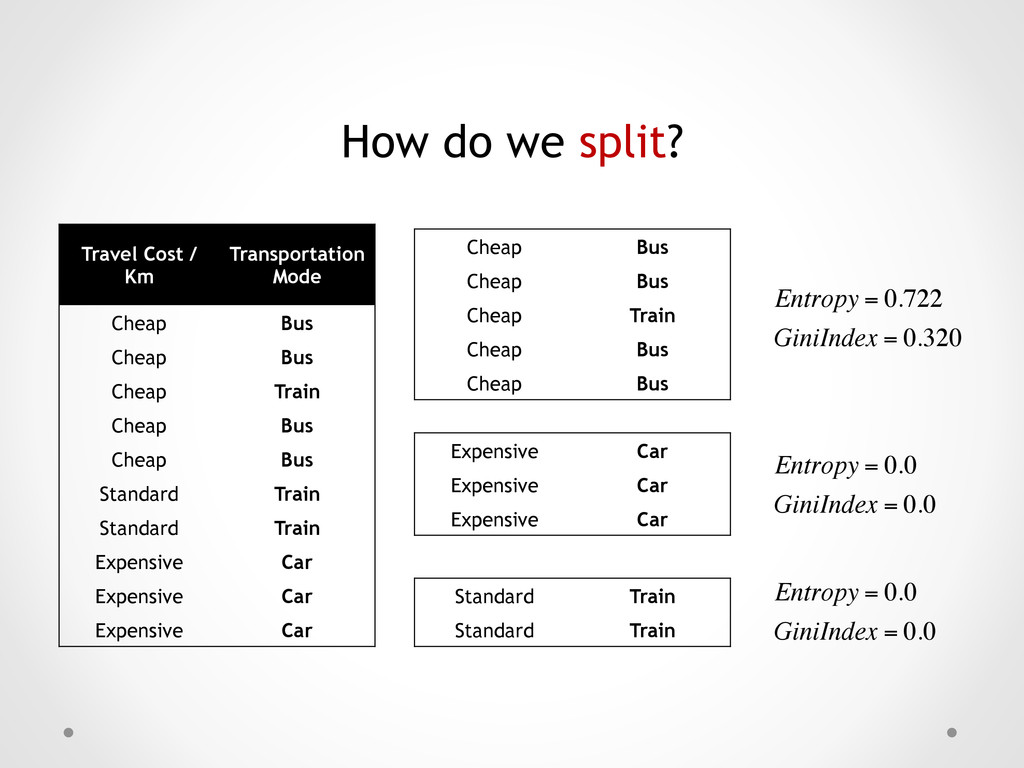
Cheap Bus Cheap Bus Cheap Train Cheap Bus Cheap Bus Standard Train Standard Train Expensive Car Expensive Car Expensive Car Cheap Bus Cheap Bus Cheap Train Cheap Bus Cheap Bus Standard Train Standard Train Expensive Car Expensive Car Expensive Car Entropy = 0.722 GiniIndex = 0.320 Entropy = 0.0 GiniIndex = 0.0 Entropy = 0.0 GiniIndex = 0.0
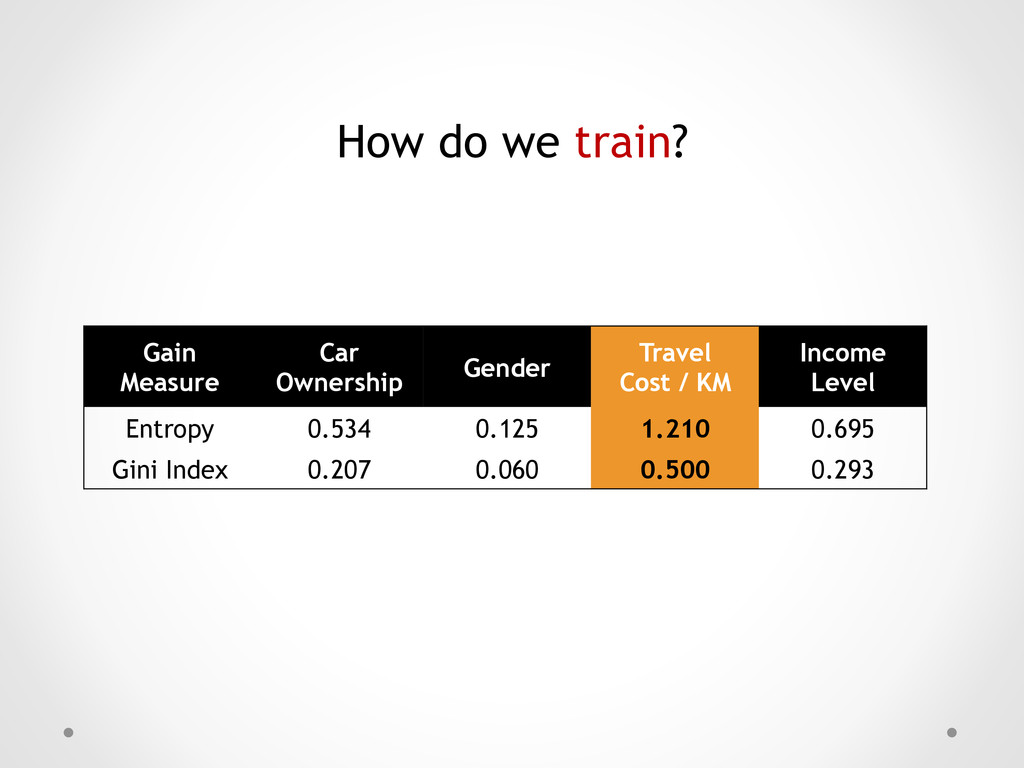
2 10 *0 + 3 10 *0) =1.210 Bus Bus Train Bus Bus Train Train Car Car Car Cheap Bus Cheap Bus Cheap Train Cheap Bus Cheap Bus Standard Train Standard Train Expensive Car Expensive Car Expensive Car Entropy = 0.722 GiniIndex = 0.320 Entropy = 0.0 GiniIndex = 0.0 Entropy = 0.0 GiniIndex = 0.0 Entropy =1.571 GiniIndex = 0.660
1 Cheap Medium Bus F 1 Cheap Medium Train F 0 Cheap Low Bus M 1 Cheap Medium Bus M 0 Standard Medium Train F 1 Standard Medium Train Gender Car Owner? Travel Cost / Km Income Level Transportation Mode F 1 Expensive High Car M 2 Expensive Medium Car F 2 Expensive High Car
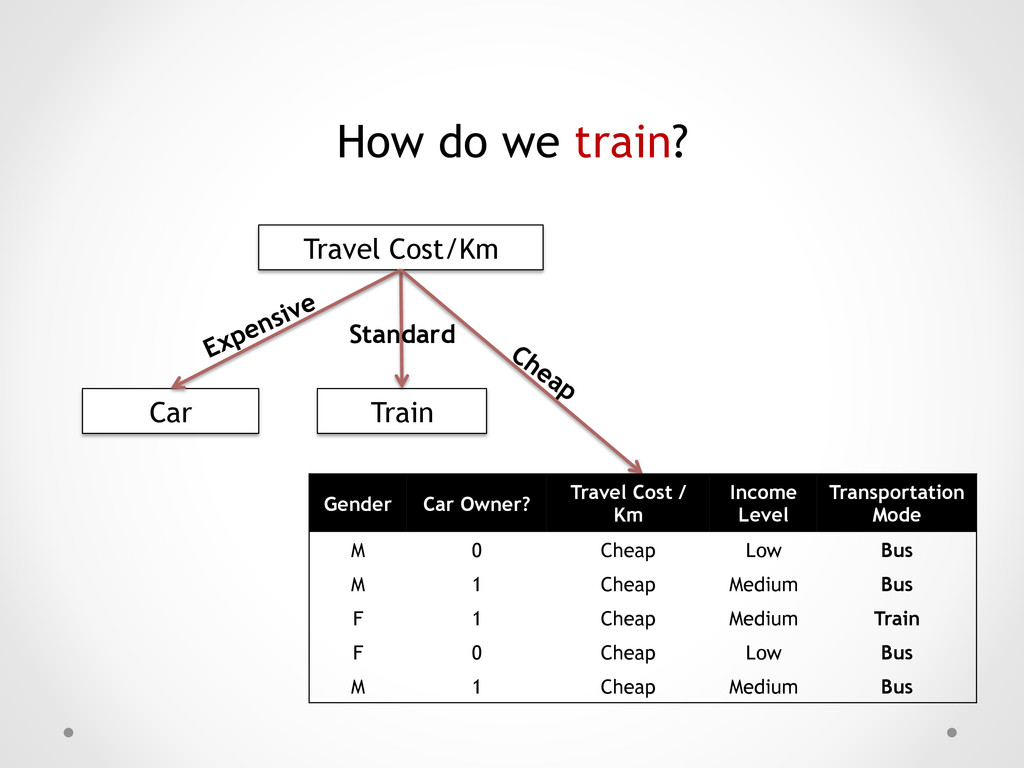
Car Owner? Travel Cost / Km Income Level Transportation Mode M 0 Cheap Low Bus M 1 Cheap Medium Bus F 1 Cheap Medium Train F 0 Cheap Low Bus M 1 Cheap Medium Bus
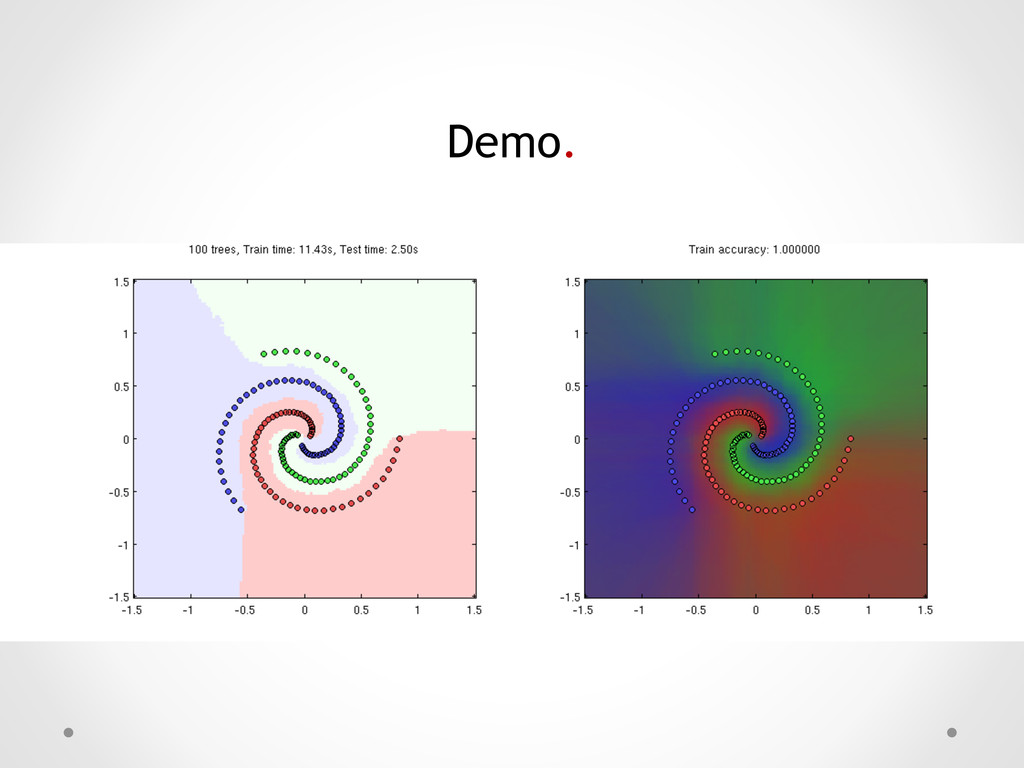
for classification, regression & clustering. Just two parameters, but performance is not very sensitive to them, and the rules of thumb work very well. Built-in measure of generalization error (Out-Of-Bag Error). Fast in training and prediction, embarrassingly parallel. Intrinsically multi-class.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
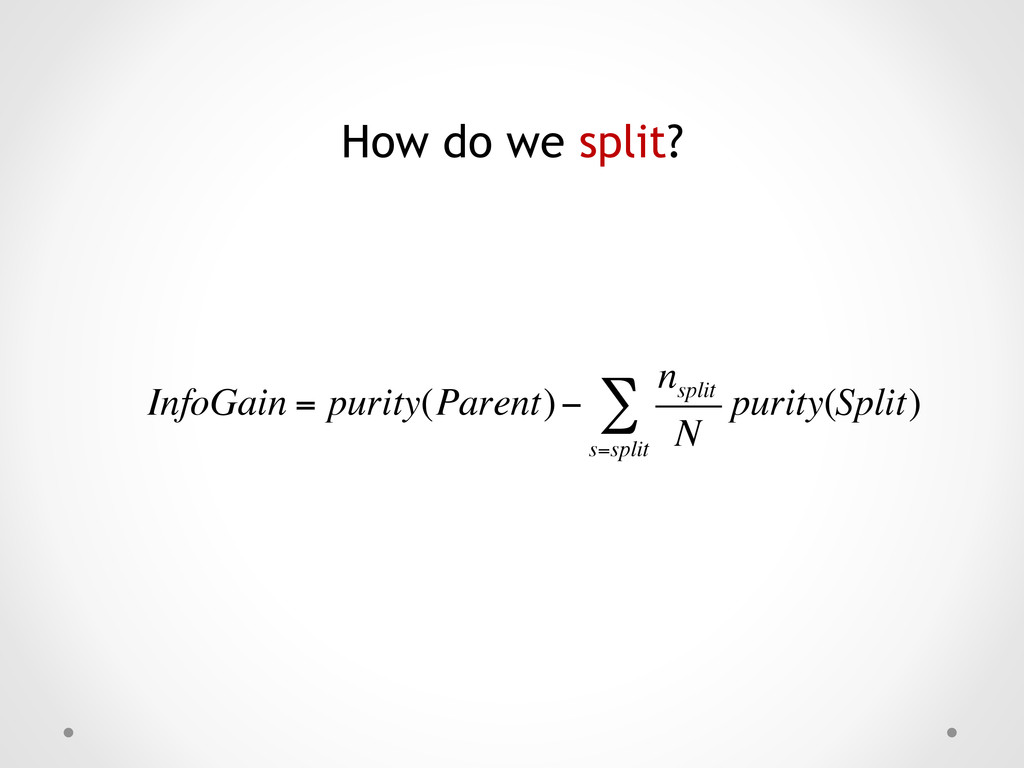{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}