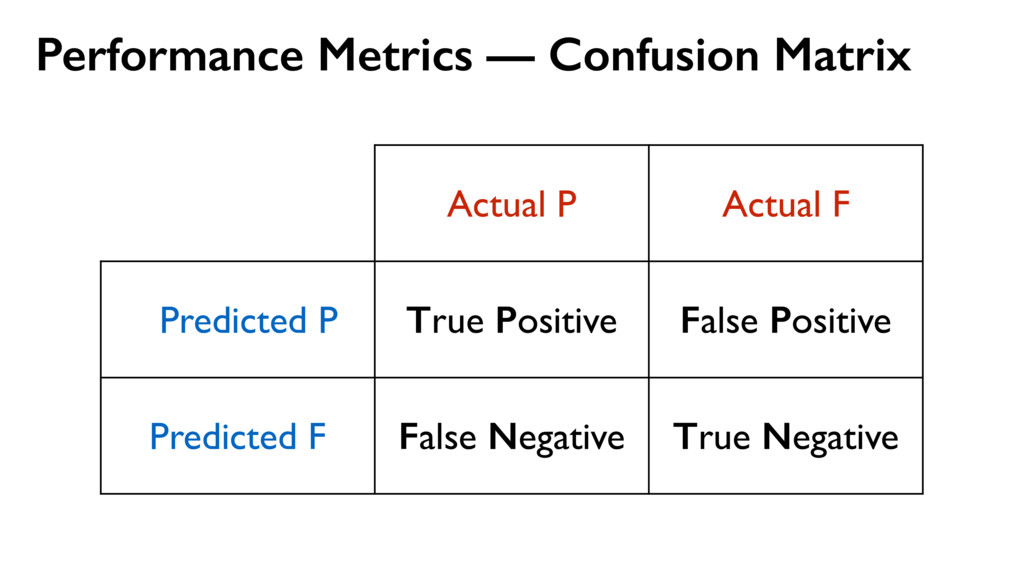
wish to minimize the probability of misclassification, this is done by assigning the test point x to the class having the largest posterior probability, corresponding to the largest value of Kk/K. Thus to classify a new point, we identify the K nearest points from the training data set and then assign the new point to the class having the largest number of representatives amongst this set. Ties can be broken at random. The particular case of K = 1 is called the nearest-neighbour rule, because a test point is simply assigned to the same class as the nearest point from the training set. These concepts are illustrated in Figure 2.27. In Figure 2.28, we show the results of applying the K-nearest-neighbour algo- rithm to the oil flow data, introduced in Chapter 1, for various values of K. As expected, we see that K controls the degree of smoothing, so that small K produces many small regions of each class, whereas large K leads to fewer larger regions. x6 x7 K = 1 0 1 2 0 1 2 x6 x7 K = 3 0 1 2 0 1 2 x6 x7 K = 31 0 1 2 0 1 2 Figure 2.28 Plot of 200 data points from the oil data set showing values of x6 plotted against x7 , where the red, green, and blue points correspond to the ‘laminar’, ‘annular’, and ‘homogeneous’ classes, respectively. Also shown are the classifications of the input space given by the K-nearest-neighbour algorithm for various values of K.
wish to minimize the probability of misclassification, this is done by assigning the test point x to the class having the largest posterior probability, corresponding to the largest value of Kk/K. Thus to classify a new point, we identify the K nearest points from the training data set and then assign the new point to the class having the largest number of representatives amongst this set. Ties can be broken at random. The particular case of K = 1 is called the nearest-neighbour rule, because a test point is simply assigned to the same class as the nearest point from the training set. These concepts are illustrated in Figure 2.27. In Figure 2.28, we show the results of applying the K-nearest-neighbour algo- rithm to the oil flow data, introduced in Chapter 1, for various values of K. As expected, we see that K controls the degree of smoothing, so that small K produces many small regions of each class, whereas large K leads to fewer larger regions. x6 x7 K = 1 0 1 2 0 1 2 x6 x7 K = 3 0 1 2 0 1 2 x6 x7 K = 31 0 1 2 0 1 2 Figure 2.28 Plot of 200 data points from the oil data set showing values of x6 plotted against x7 , where the red, green, and blue points correspond to the ‘laminar’, ‘annular’, and ‘homogeneous’ classes, respectively. Also shown are the classifications of the input space given by the K-nearest-neighbour algorithm for various values of K. Non-linear decision boundary
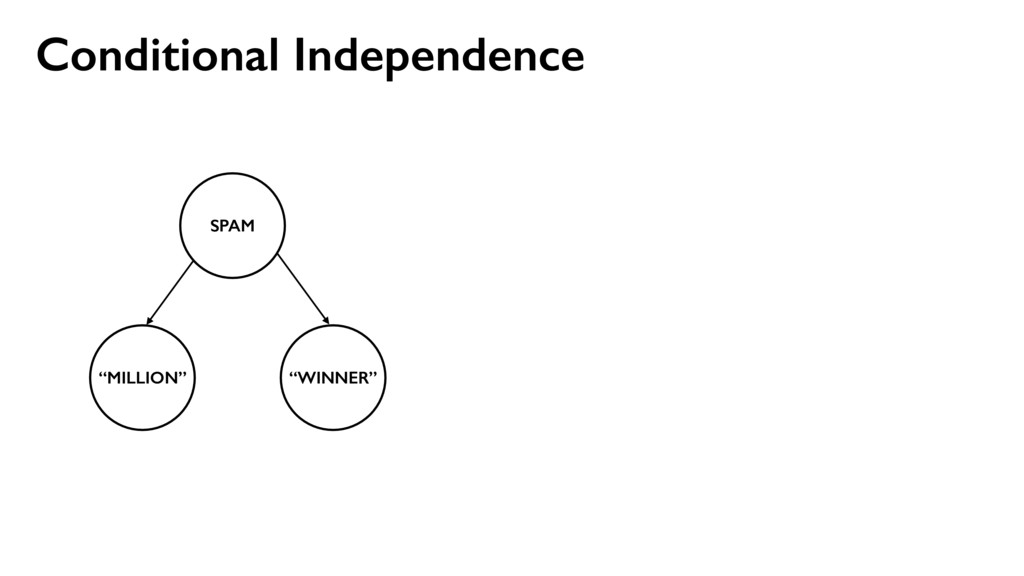
LePendu, P., and Shah, N. Finding progression stages in time-evolving event sequences. WWW 2014. Maximize the data likelihood xij ⇠ Multinomial(⇥(ci, sj)) ⇥(ci, sj) ⇠ Dirichlet( ) A generative model
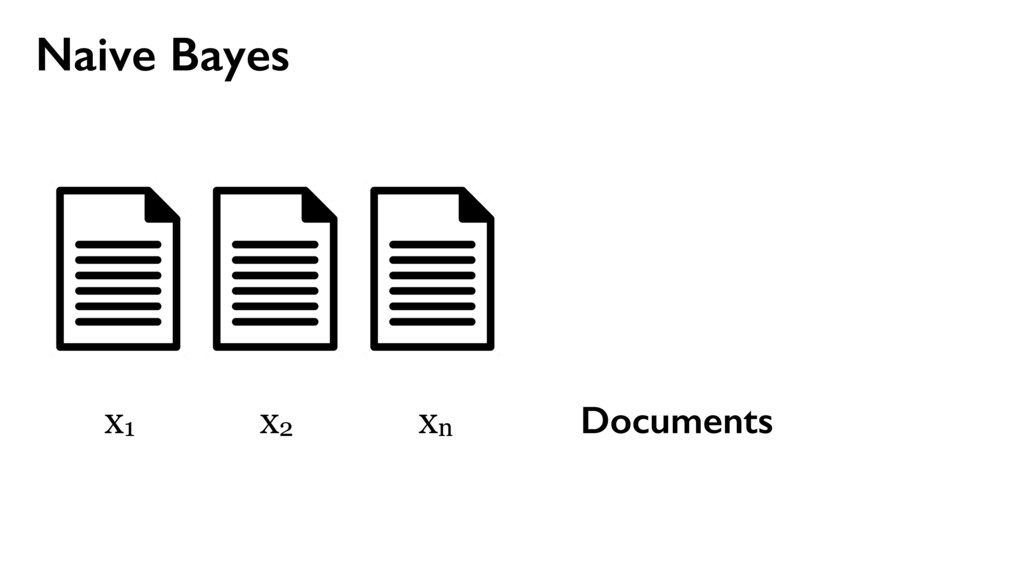
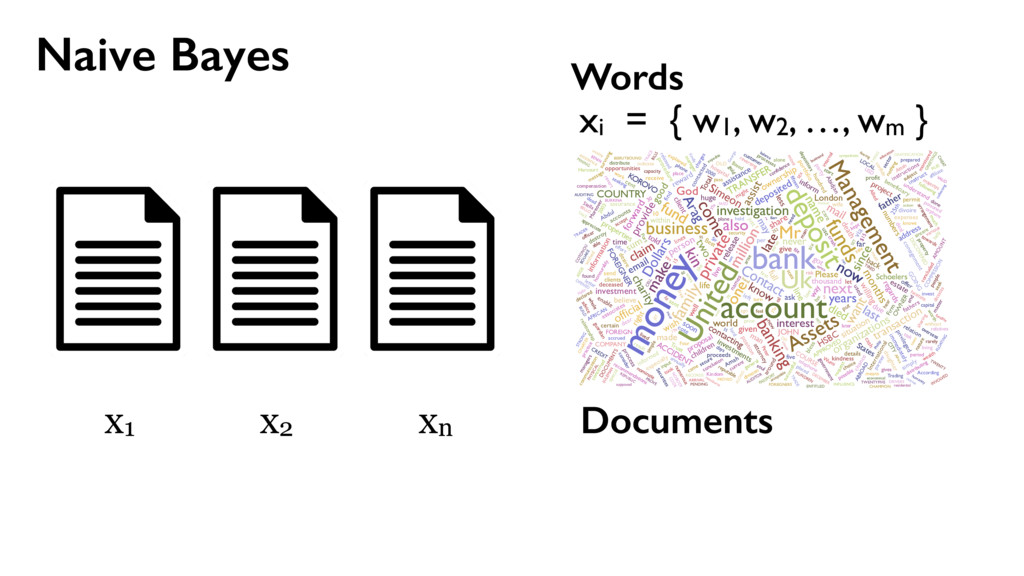
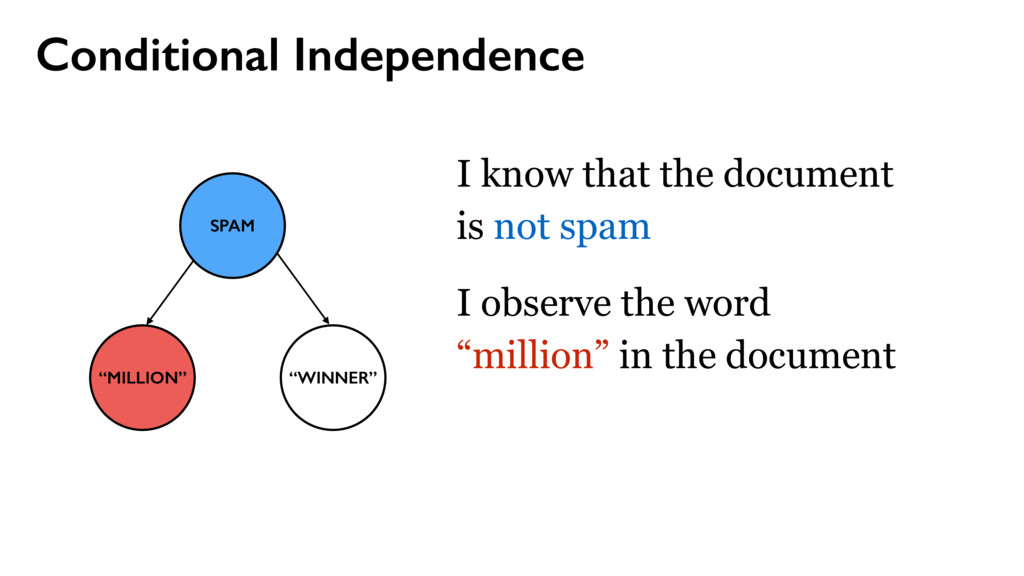
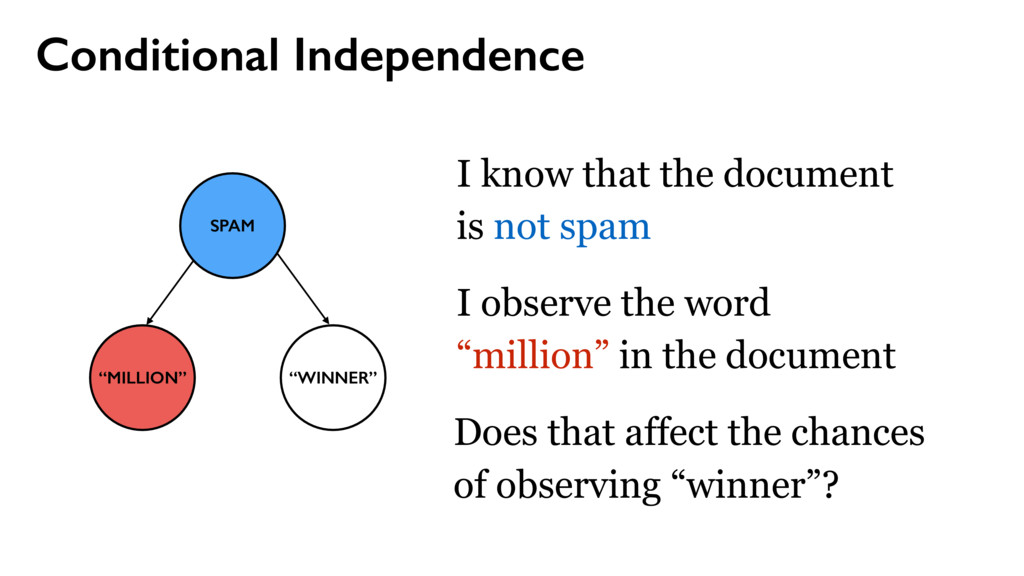
w2, …, wm } Words use place line one via money bank account United deposit Uk Assets funds Mr family come private kin also next now years last two died sum life full give well far 25th left care sent put 10 Allied kept USD Sir lord arise fax business fund want late claim share death inform client regards dear offer five find partner gold sincere manager prior nature state turn OLD able oil 15 5 end file 30 M incur collecting Kindly action west acceptable Africa town $ TW ENTY BELLO 2 FASO AUDITING ran OPENED FILES CHARTER JET 50 BENIN 55 TRADER TRADE 60 70 THING 95 hand DIE TIRED Mrs sence VALID DRIVERS George CHEAT HIT 1To TRACE visit SET ASIDE TAKE 252 2To BILLS SEX cocoa CELL CODE 3To Barr banking million make Dollars Arag Contact investigation since name charity organizations assist months official transaction know Simeon God mail interest provide forward world person father email deposited may COUNTRY good TRANSFER never London Please ownership situation contacting HSBC wish given made willing release investment live proposal thousand JOHN KOROVO FOREIGNER huge soon reward told way investments Schoelers properties within back time due numbers Total right believe less project information man estate children ACCIDENT got States assistance ask address hundred consignment OW NER beneficiary profit APPROVED assurance International position desire receive expenses attorney law deceased might COURSE used names associates deal proceeds contacted immediately GOING accounts bless procedure just details clients send Best per daughter enable kindness lines hospital Abidjan fathers FOREIGN chance Amah privileged cote wife divoire Firm six Trust informed certain permit portfolio new especially around opportunities cash COMPANY process instructions understand party relation Abdul instruct simply destroy let cent general DISCOVERED hesitate choice plane crash security knows confide capacity DOCUMENTS need simple Wumi 2000 sharing confidence conclusion honourably telephone secure phone seeking 2003 annually property Based following ways subject serve nothing sale indicate main towards concluded reverting Moreover current period revert LOCAL capital fifteen effort start input successful first feel message Four free According lived accept Peter Attah whole soul gives recommendations living CREDIT ABROAD invest letter CITY Port Harcourt like hear came division ago people advice took risk done $15 later task sector days dead held depositors alone much help seek move pass work must Management arrangement guardian monitored majestys government compensation distributing poisoned overseas consider AFRICAN COMMISSION appreciate without relationship placed request result reputable communication explained wished officer numerous wealth various managers found AMOUNT Kindom orphans Securities Trading charges affiliate processes worth concerned special declared possible surviving means existence rarely nominate internal dictates matter Stella practice relatives customer prepared accrued released distribute BOUAKE expedite HUNDREN SULEMAN AUDITOR BURKINA FLOATING economical GREETINGS RECORDS BEIRUTBOUND businessI fundHe DECEMBER COTONOU REPUBLIC NOBODY MINING PROVED ALONG INVOLVED reimburse TWENTYFIVE PASSPORT humanity STRONG sympathetic INFLUENCE mutual FOREIGNERS PENDING PHYSICAL ARRIVAL PROVE supposed balance BUILD retrive ENTITLED GRATIFICATION wealthy fearing education residential CHAMPION Hello Phillip
spam } y1 y2 yn use place line one via money bank account United deposit Uk Assets funds Mr family come private kin also next now years last two died sum life full give well far 25th left care sent put 10 Allied kept USD Sir lord arise fax business fund want late claim share death inform client regards dear offer five find partner gold sincere manager prior nature state turn OLD able oil 15 5 end file 30 M incur collecting Kindly action west acceptable Africa town $ TW ENTY BELLO 2 FASO AUDITING ran OPENED FILES CHARTER JET 50 BENIN 55 TRADER TRADE 60 70 THING 95 hand DIE TIRED Mrs sence VALID DRIVERS George CHEAT HIT 1To TRACE visit SET ASIDE TAKE 252 2To BILLS SEX cocoa CELL CODE 3To Barr banking million make Dollars Arag Contact investigation since name charity organizations assist months official transaction know Simeon God mail interest provide forward world person father email deposited may COUNTRY good TRANSFER never London Please ownership situation contacting HSBC wish given made willing release investment live proposal thousand JOHN KOROVO FOREIGNER huge soon reward told way investments Schoelers properties within back time due numbers Total right believe less project information man estate children ACCIDENT got States assistance ask address hundred consignment OW NER beneficiary profit APPROVED assurance International position desire receive expenses attorney law deceased might COURSE used names associates deal proceeds contacted immediately GOING accounts bless procedure just details clients send Best per daughter enable kindness lines hospital Abidjan fathers FOREIGN chance Amah privileged cote wife divoire Firm six Trust informed certain permit portfolio new especially around opportunities cash COMPANY process instructions understand party relation Abdul instruct simply destroy let cent general DISCOVERED hesitate choice plane crash security knows confide capacity DOCUMENTS need simple Wumi 2000 sharing confidence conclusion honourably telephone secure phone seeking 2003 annually property Based following ways subject serve nothing sale indicate main towards concluded reverting Moreover current period revert LOCAL capital fifteen effort start input successful first feel message Four free According lived accept Peter Attah whole soul gives recommendations living CREDIT ABROAD invest letter CITY Port Harcourt like hear came division ago people advice took risk done $15 later task sector days dead held depositors alone much help seek move pass work must Management arrangement guardian monitored majestys government compensation distributing poisoned overseas consider AFRICAN COMMISSION appreciate without relationship placed request result reputable communication explained wished officer numerous wealth various managers found AMOUNT Kindom orphans Securities Trading charges affiliate processes worth concerned special declared possible surviving means existence rarely nominate internal dictates matter Stella practice relatives customer prepared accrued released distribute BOUAKE expedite HUNDREN SULEMAN AUDITOR BURKINA FLOATING economical GREETINGS RECORDS BEIRUTBOUND businessI fundHe DECEMBER COTONOU REPUBLIC NOBODY MINING PROVED ALONG INVOLVED reimburse TWENTYFIVE PASSPORT humanity STRONG sympathetic INFLUENCE mutual FOREIGNERS PENDING PHYSICAL ARRIVAL PROVE supposed balance BUILD retrive ENTITLED GRATIFICATION wealthy fearing education residential CHAMPION Hello Phillip xi = { w1, w2, …, wm } Words
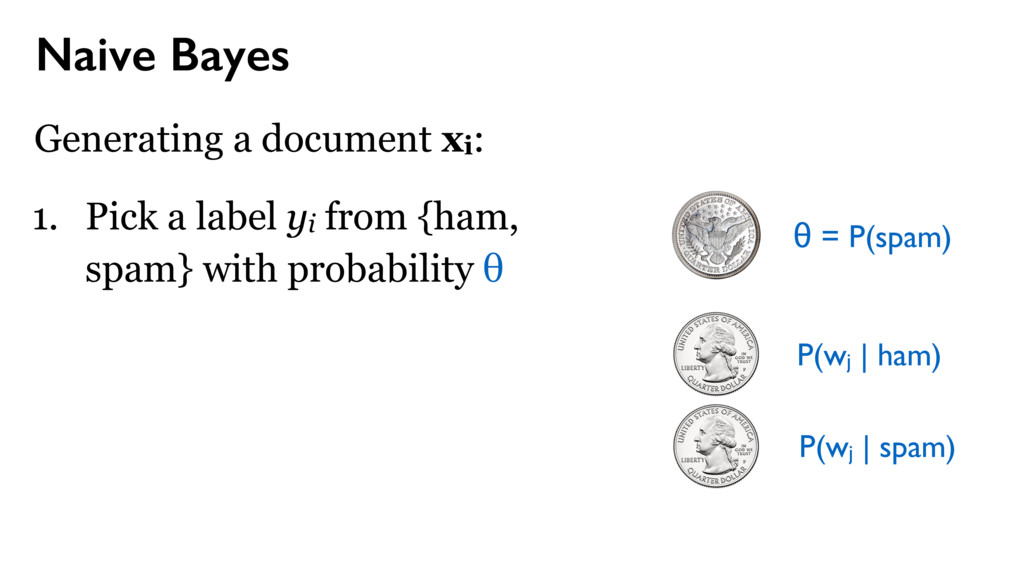
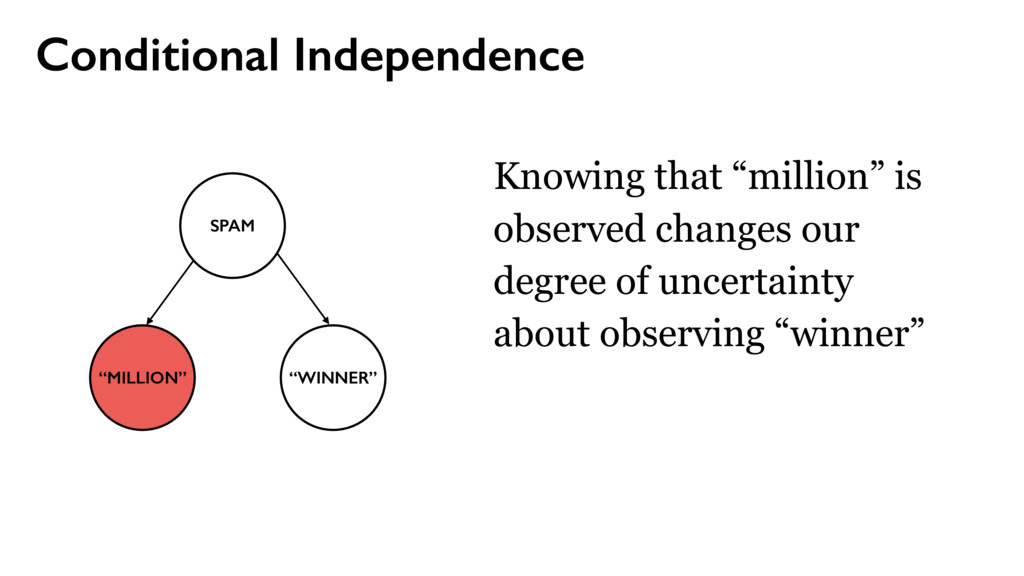
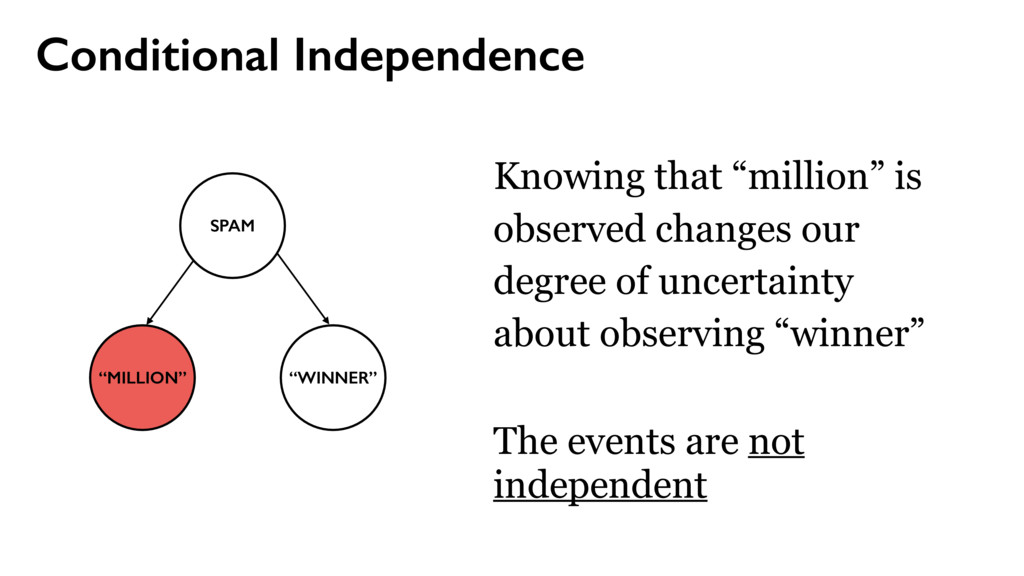
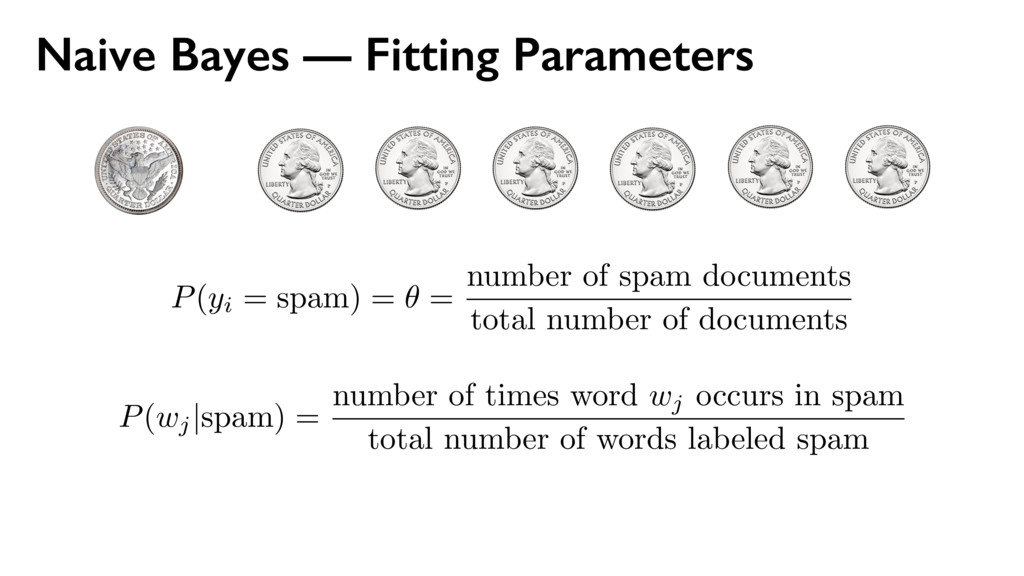
yi from {ham, spam} with probability θ θ = P(spam) P(wj | ham) P(wj | spam) use place line one via money bank account United deposit Uk Assets funds Mr family come private kin also next now years last two died sum life full give well far 25th left care sent put 10 Allied kept USD Sir lord arise fax business fund want late claim share death inform client regards dear offer five find partner gold sincere manager prior nature state turn OLD able oil 15 5 end file 30 M incur collecting Kindly action west acceptable Africa town $ TW ENTY BELLO 2 FASO AUDITING ran OPENED FILES CHARTER JET 50 BENIN 55 TRADER TRADE 60 70 THING 95 hand DIE TIRED Mrs sence VALID DRIVERS George CHEAT HIT 1To TRACE visit SET ASIDE TAKE 252 2To BILLS SEX cocoa CELL CODE 3To Barr banking million make Dollars Arag Contact investigation since name charity organizations assist months official transaction know Simeon God mail interest provide forward world person father email deposited may COUNTRY good TRANSFER never London Please ownership situation contacting HSBC wish given made willing release investment live proposal thousand JOHN KOROVO FOREIGNER huge soon reward told way investments Schoelers properties within back time due numbers Total right believe less project information man estate children ACCIDENT got States assistance ask address hundred consignment OW NER beneficiary profit APPROVED assurance International position desire receive expenses attorney law deceased might COURSE used names associates deal proceeds contacted immediately GOING accounts bless procedure just details clients send Best per daughter enable kindness lines hospital Abidjan fathers FOREIGN chance Amah privileged cote wife divoire Firm six Trust informed certain permit portfolio new especially around opportunities cash COMPANY process instructions understand party relation Abdul instruct simply destroy let cent general DISCOVERED hesitate choice plane crash security knows confide capacity DOCUMENTS need simple Wumi 2000 sharing confidence conclusion honourably telephone secure phone seeking 2003 annually property Based following ways subject serve nothing sale indicate main towards concluded reverting Moreover current period revert LOCAL capital fifteen effort start input successful first feel message Four free According lived accept Peter Attah whole soul gives recommendations living CREDIT ABROAD invest letter CITY Port Harcourt like hear came division ago people advice took risk done $15 later task sector days dead held depositors alone much help seek move pass work must Management arrangement guardian monitored majestys government compensation distributing poisoned overseas consider AFRICAN COMMISSION appreciate without relationship placed request result reputable communication explained wished officer numerous wealth various managers found AMOUNT Kindom orphans Securities Trading charges affiliate processes worth concerned special declared possible surviving means existence rarely nominate internal dictates matter Stella practice relatives customer prepared accrued released distribute BOUAKE expedite HUNDREN SULEMAN AUDITOR BURKINA FLOATING economical GREETINGS RECORDS BEIRUTBOUND businessI fundHe DECEMBER COTONOU REPUBLIC NOBODY MINING PROVED ALONG INVOLVED reimburse TWENTYFIVE PASSPORT humanity STRONG sympathetic INFLUENCE mutual FOREIGNERS PENDING PHYSICAL ARRIVAL PROVE supposed balance BUILD retrive ENTITLED GRATIFICATION wealthy fearing education residential CHAMPION Hello Phillip word words sprite placed area algorithm layout candidate step collision bounding without retrieve operation perform hierarchical time 32 possible draw placement data pixel expensive pixels even masks implementation simple detection starting larger whole previously comparing move box large think version single tree separately always use overlap animations prevents browsers event loop blocking placing incredibly available GitHub important Attempt place point usually near middle somewhere central horizontal line intersects open source one along increasing spiral Repeat intersections found hard part making license efficiently According Jonathan Feinberg Wordle uses combination d3cloud Note boxes quadtrees achieve reasonable speeds Glyphs JavaScript isnt way code precise glyph shapes via DOM except perhaps SVG fonts Instead text hidden canvas element rendering final Retrieving output requires many additional batch development Sprites initial quite performed slow hundred using run doesnt copy appropriate position asynchronously representing configurable Cloud advantage involves positioning size relevant rather previous Somewhat surprisingly lowlevel hack made tremendous difference constructing compressed blocks 1bit 32bit integers thus reducing number checks memory times fact turned beat makes quadtree everything tried Generator areas font sizes animate primarily Works needs stuttering test per whereas compare every overlaps slightly Another possibility merge recommended fairly though compared analagous mask essentially ORing block converting
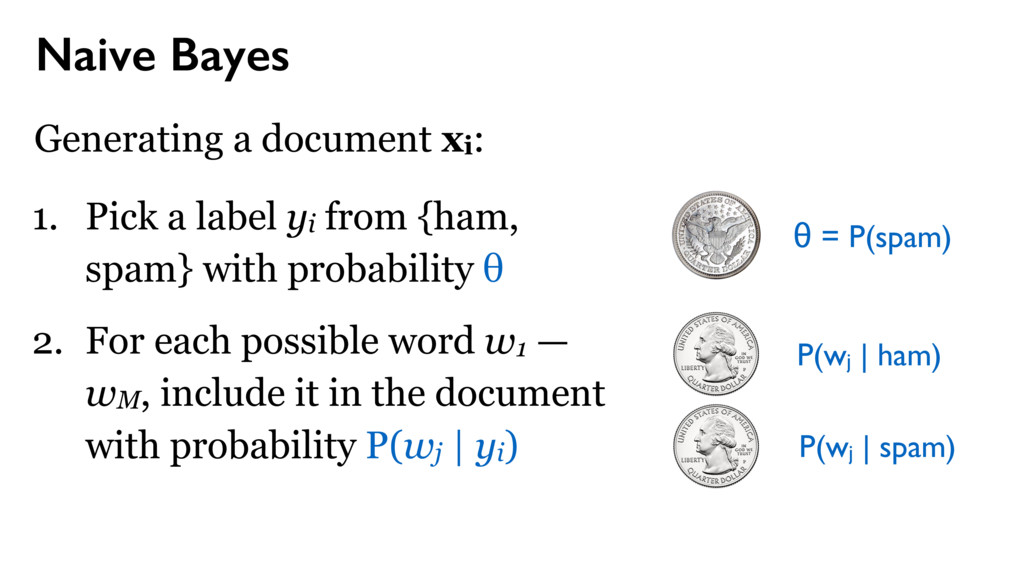
yi from {ham, spam} with probability θ 2. For each possible word w1 — wM, include it in the document with probability P(wj | yi) θ = P(spam) P(wj | ham) P(wj | spam)
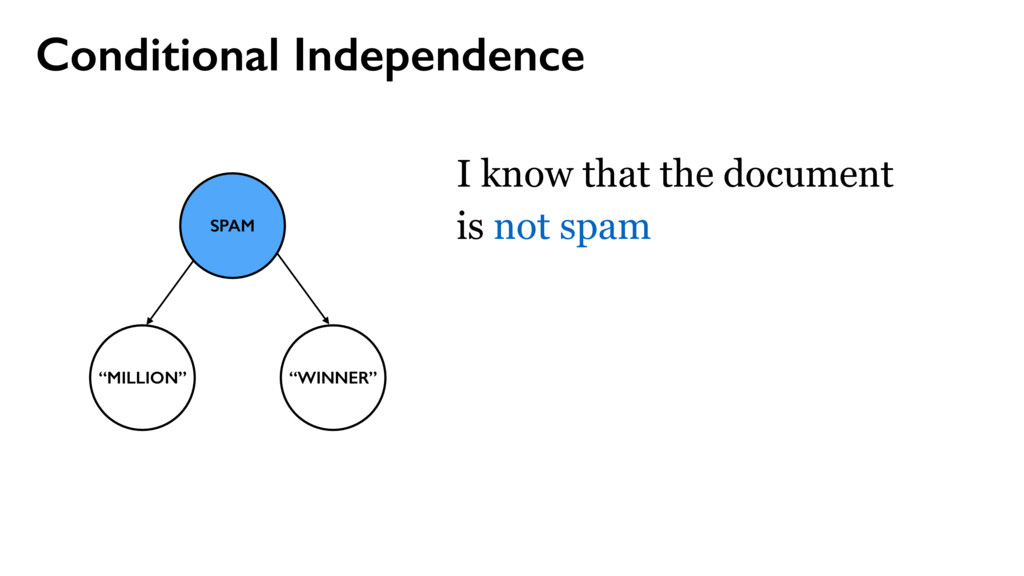
cocoa merchant in Abidjan, the economic capital of Ivory Coast before he was poisoned to death by his business associates on one of their outing to discus on a business deal. http://www.hoax-slayer.net/wumi-abdul-advance-fee-scam/ P(y = spam) ∝ P(“my” | spam)…P(“deal” | spam)P(spam) P(y = ham) ∝ P(“my” | ham)…P(“deal” | ham)P(spam)
of times word wj occurs in spam + 1 total number of words labeled spam + |V | ccurs in spam + 1 eled spam + |V | unique words in the training data Naive Bayes — Smoothing
train and test • Split train data randomly into k equal “folds” • Train on k-1 folds, validate on the remaining • Average the k metrics from each fold • See sklearn.model_selection.KFold
{kind=link}
{kind=link}
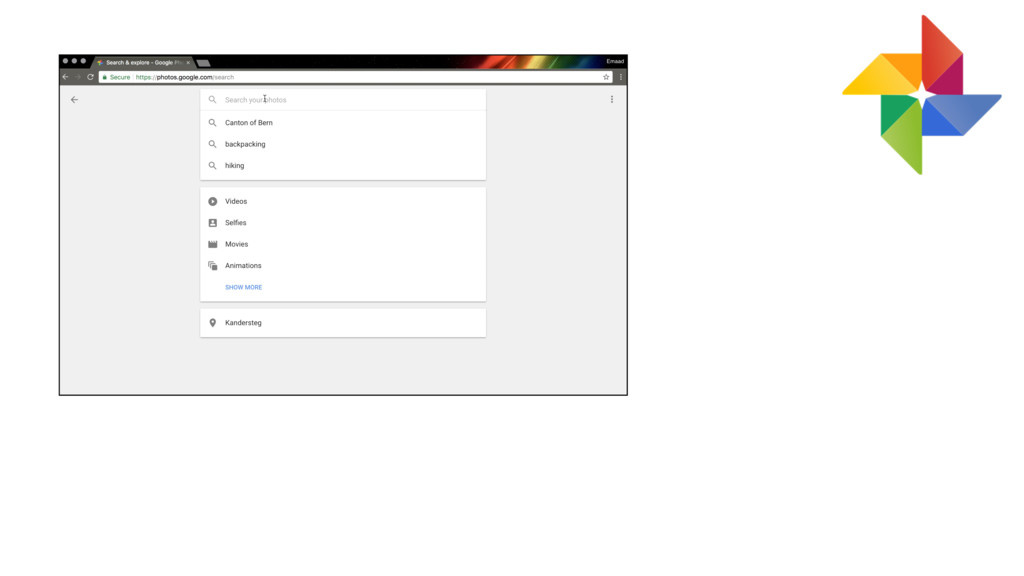{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
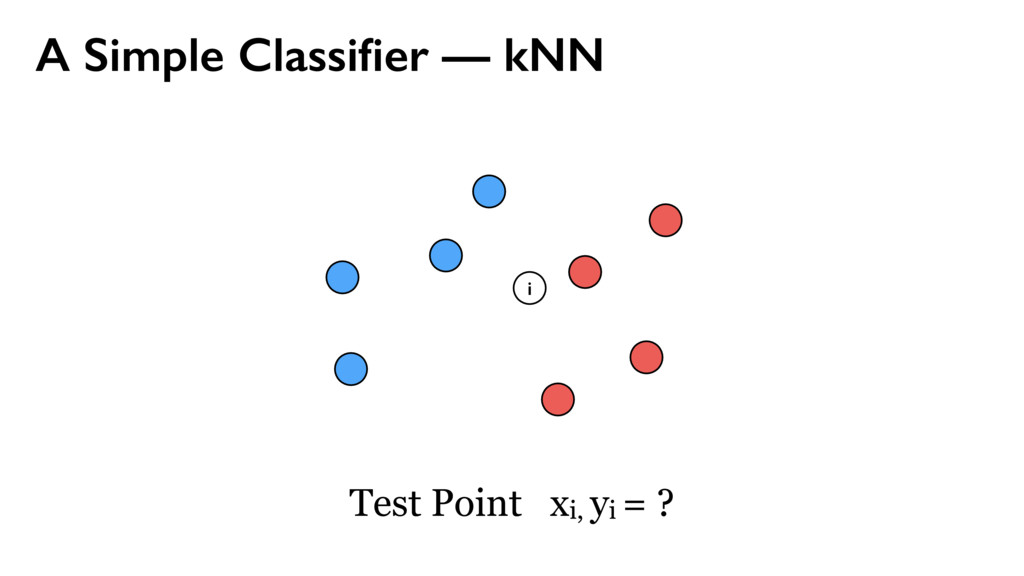{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
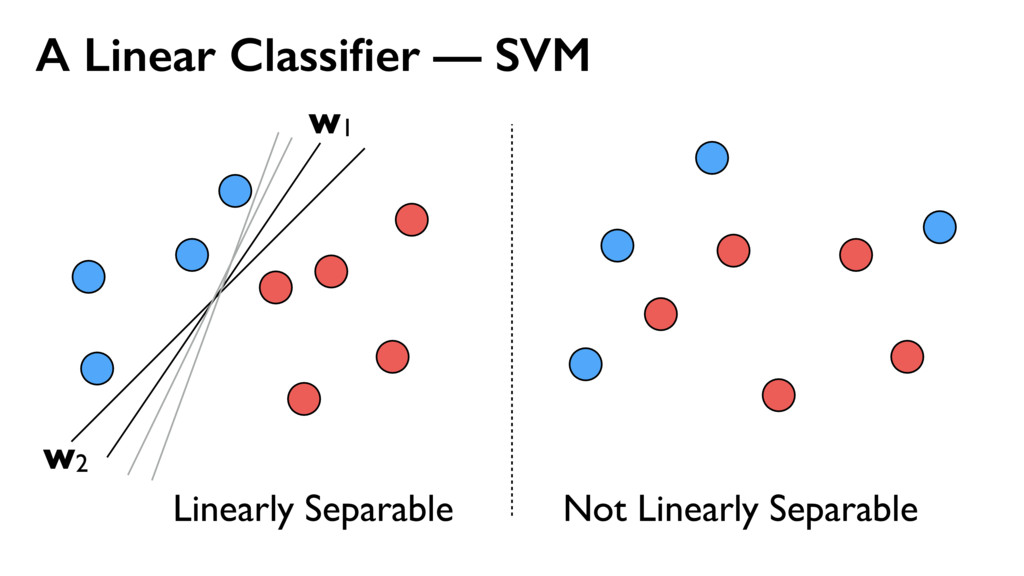{kind=link}
{kind=link}
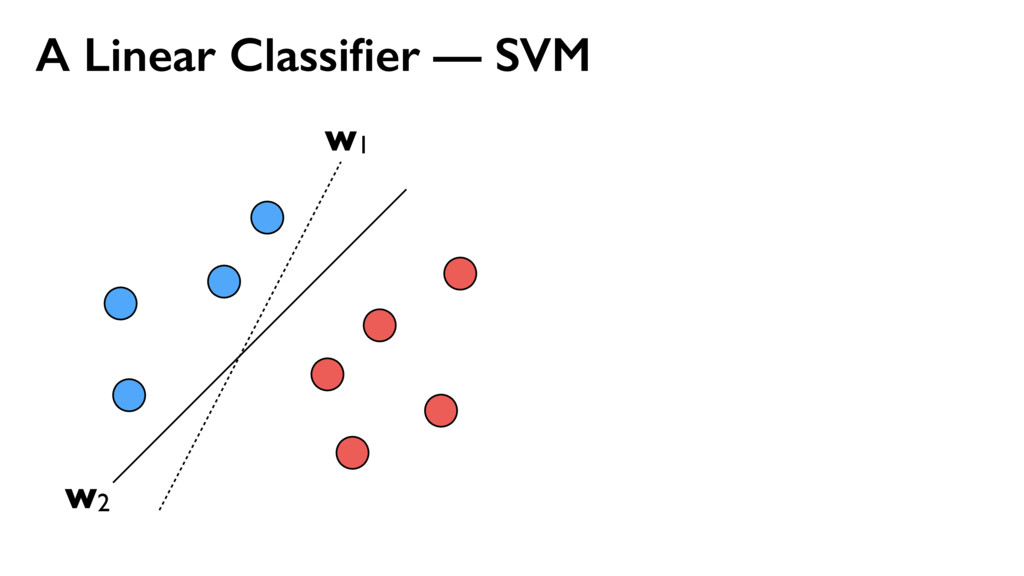{kind=link}
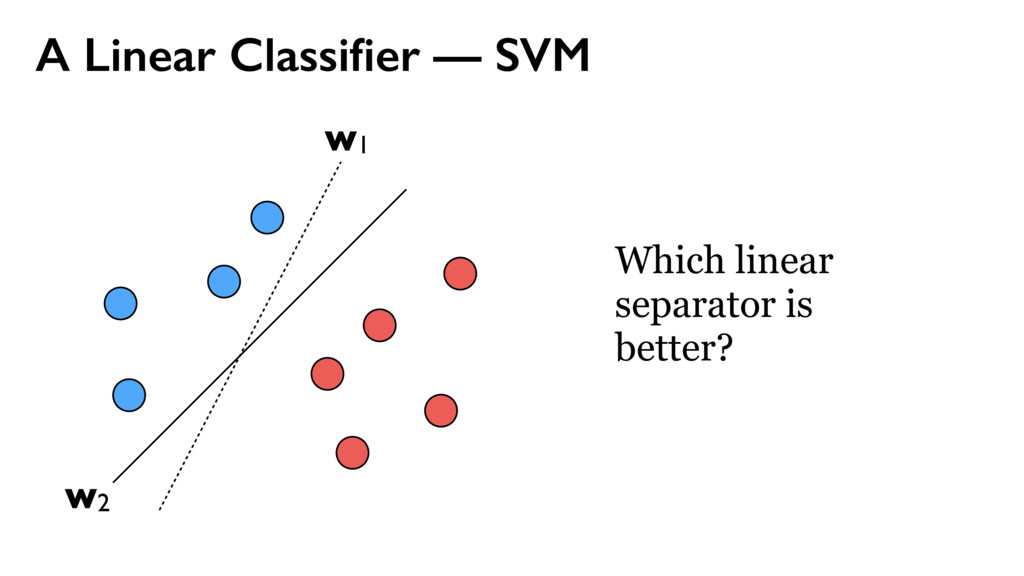{kind=link}
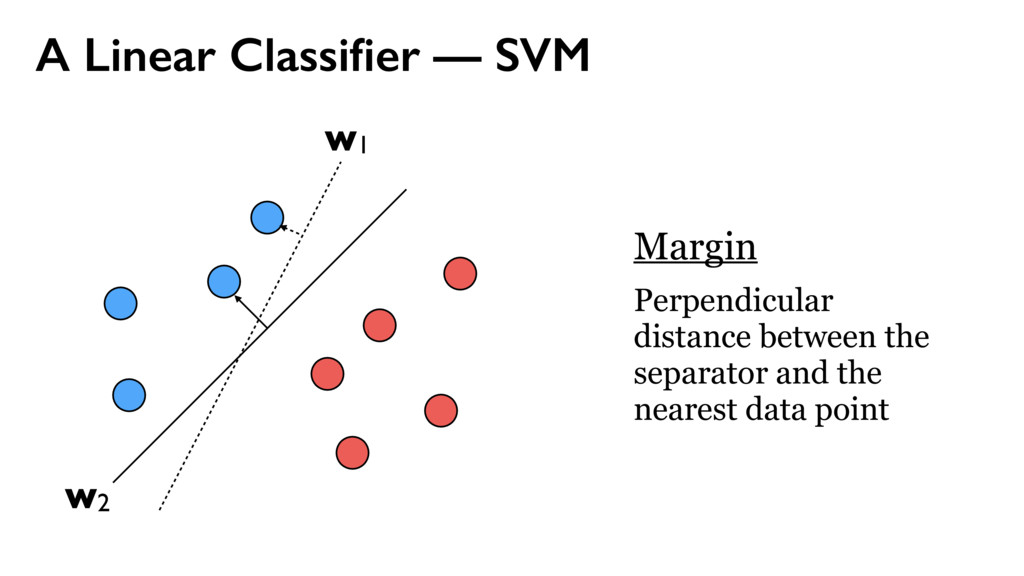{kind=link}
{kind=link}
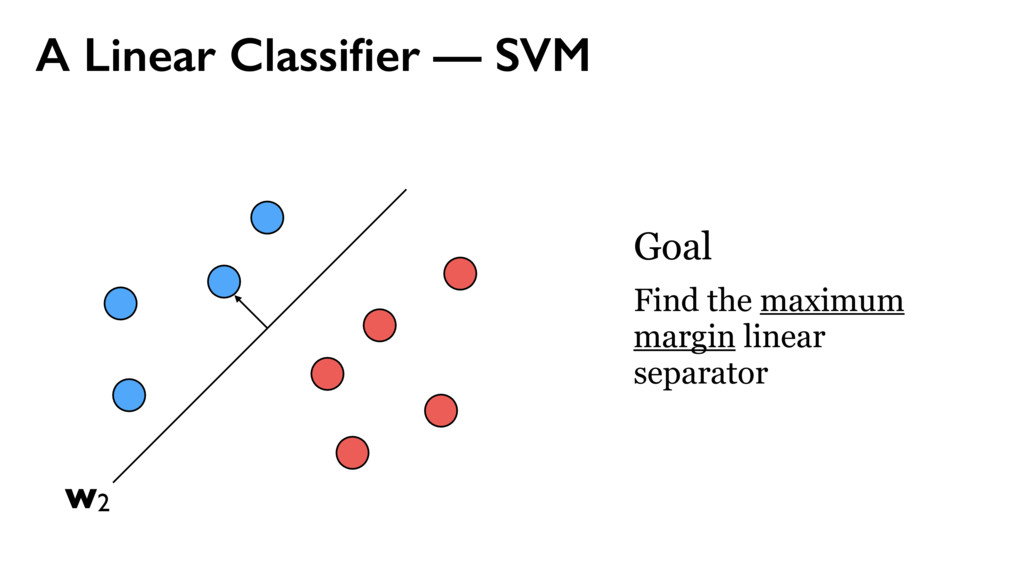{kind=link}
{kind=link}
{kind=link}
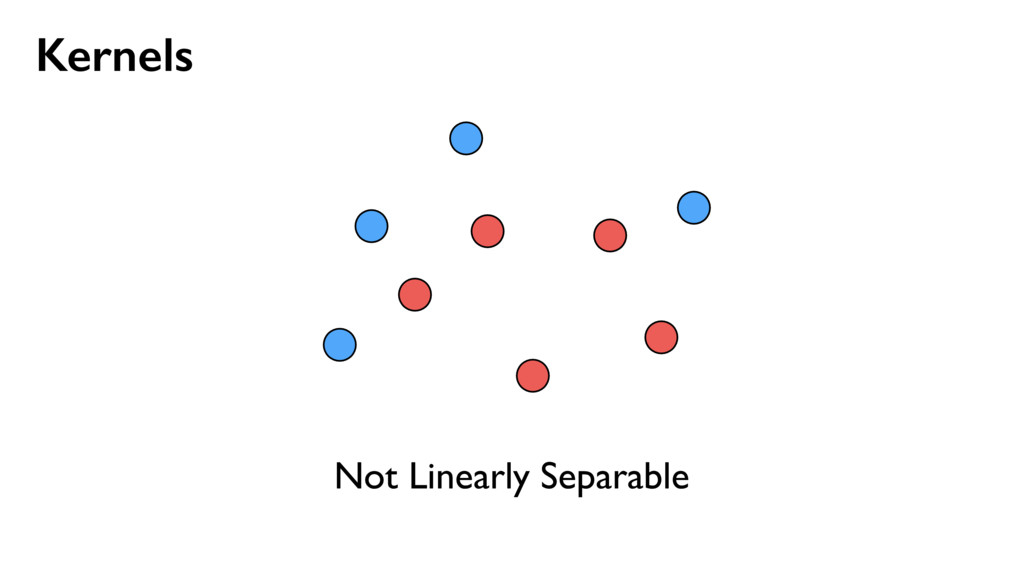{kind=link}
![Kernels [ x, y ] [ x, y, x2, y2](https://files.speakerdeck.com/presentations/1ec68096701c43adba79e5adcec1bd01/slide_36.jpg){kind=link}
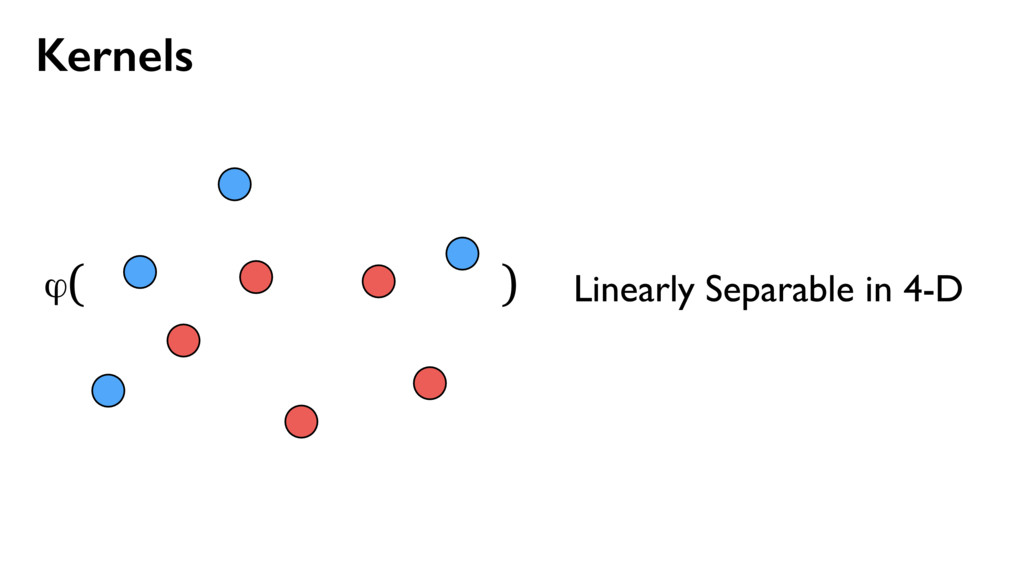{kind=link}
{kind=link}
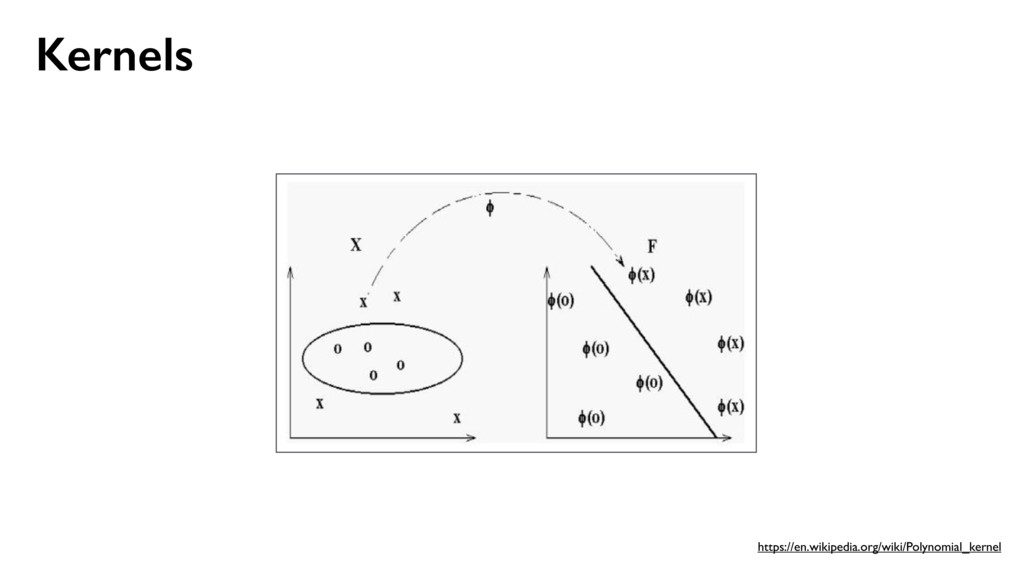{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
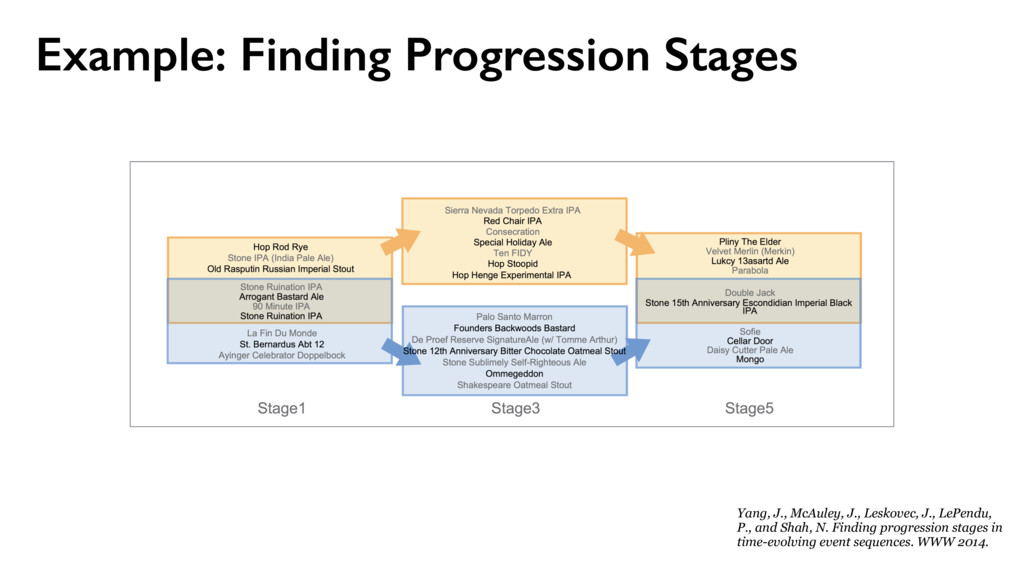{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}