Tackling contention: the monsters inside the `sync.Locker`
Go is all about parallelism and concurrency, but they don’t come for free. This talk is about measuring their contention price and being able to reduce it.
potential profiles. Just run your benchmarks with -cpuprofile=cpu.out Then run go tool pprof <exec.test> cpu.out Now type "web". Can also be collected live with minimum overhead and "net/http/pprof".
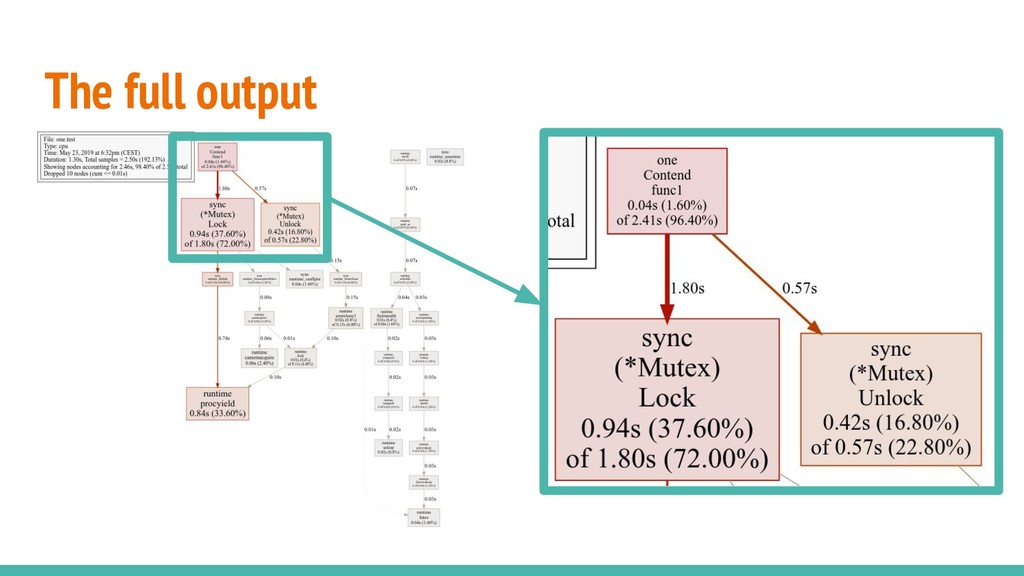
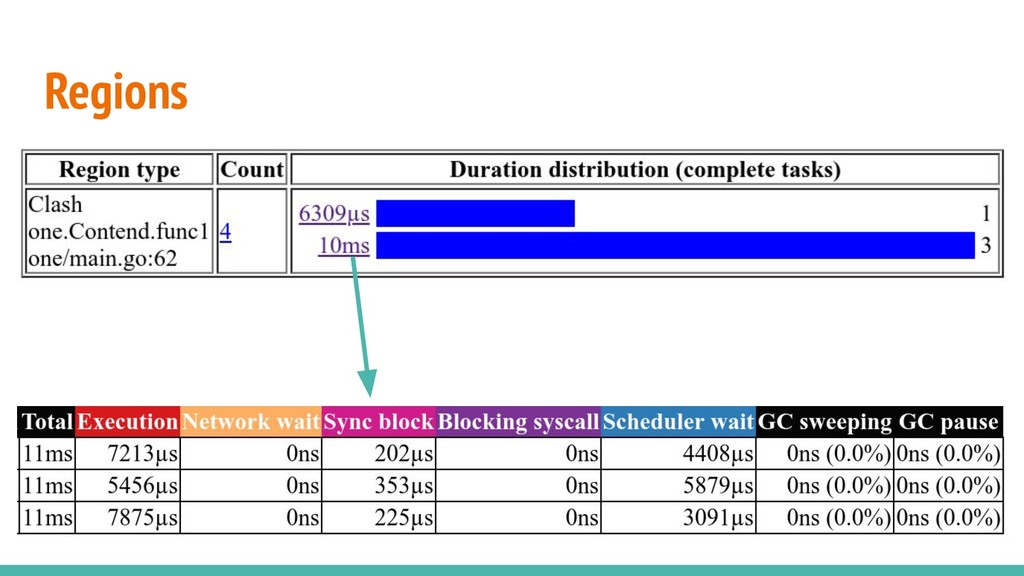
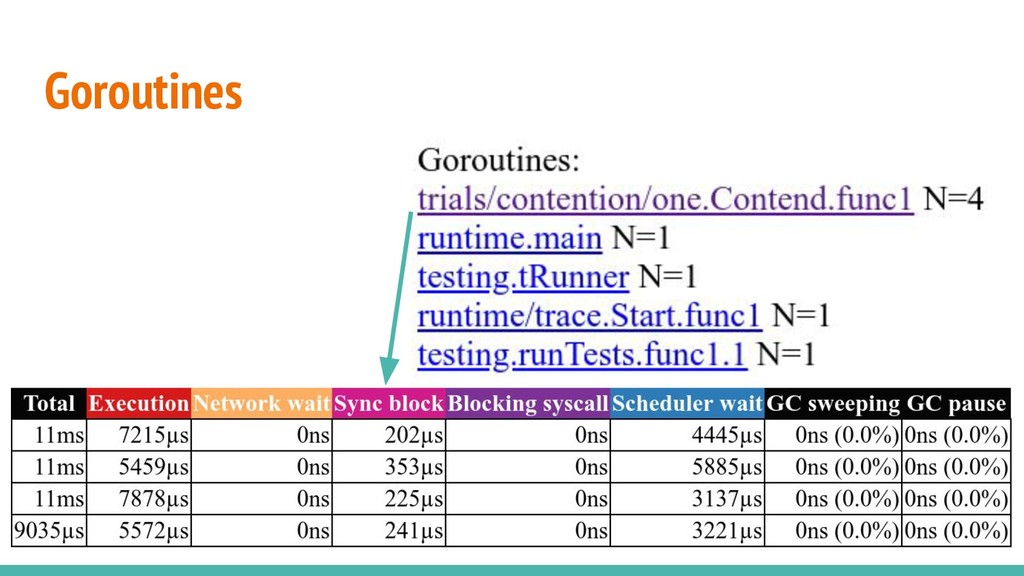
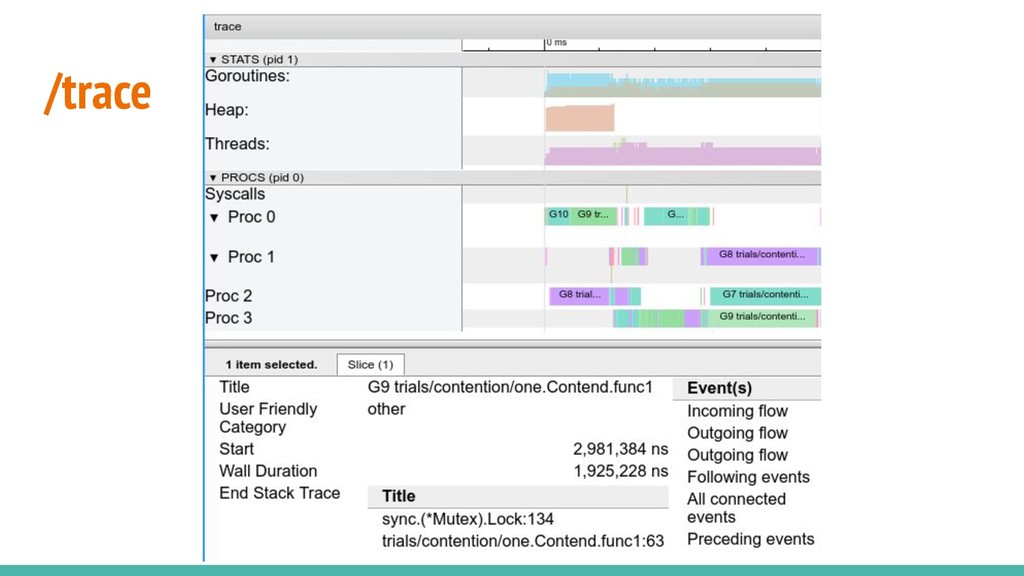
by importing "net/http/pprof". Traces can also be generated with go test -trace. go tool trace opens a browser (/trace only works with chrome). The blocking profile is still pprof.
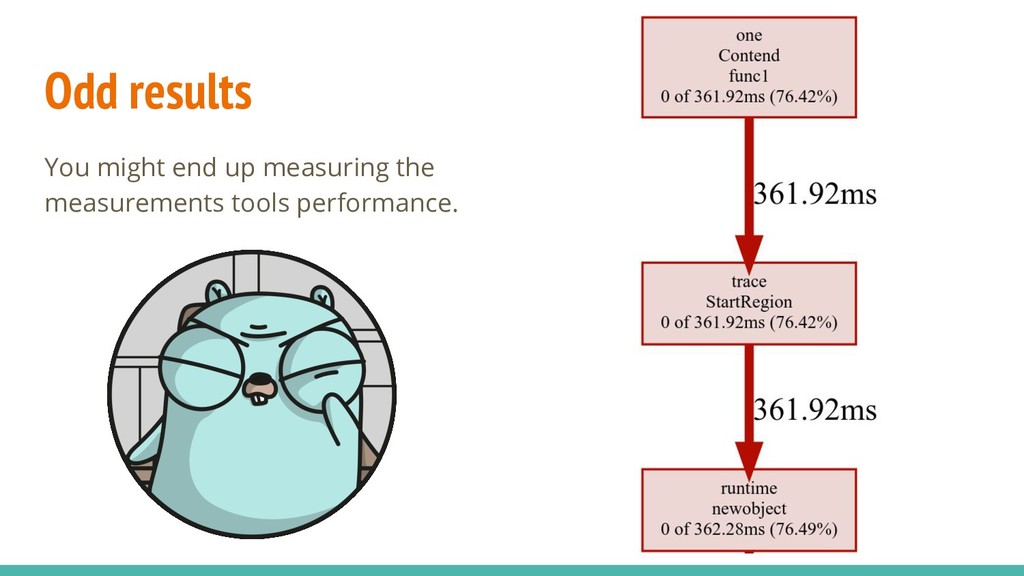
on what follows you should measure. Never optimize for contention reduction unless you know it is your bottleneck. When you measure, beware of sample size: small samples will give wrong results.
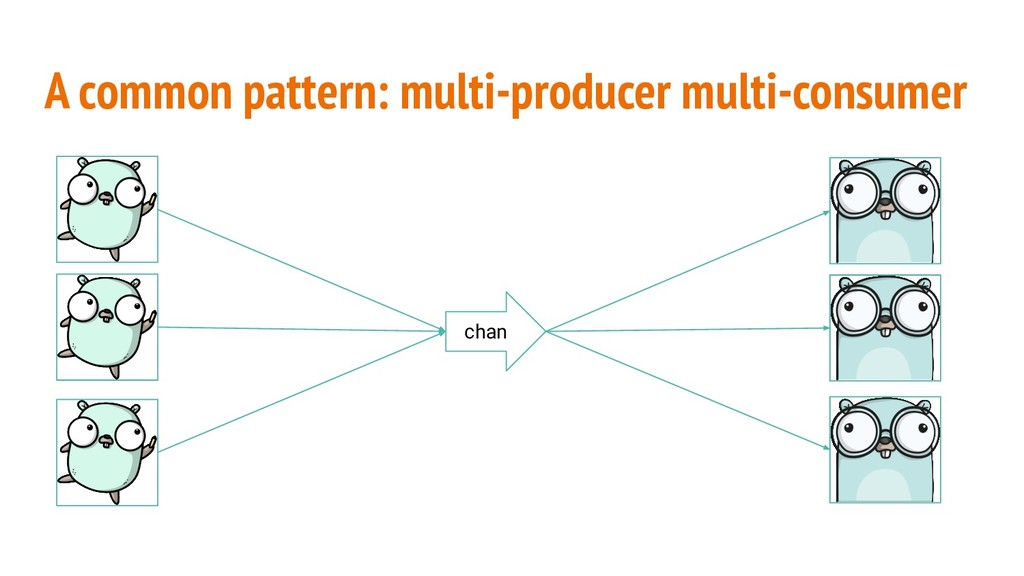
unbuffered every single operation will block. If many send/receive operations are executed in parallel they will fight for the lock. // runtime/chan.go type hchan struct { // Lots of unexported fields lock mutex }
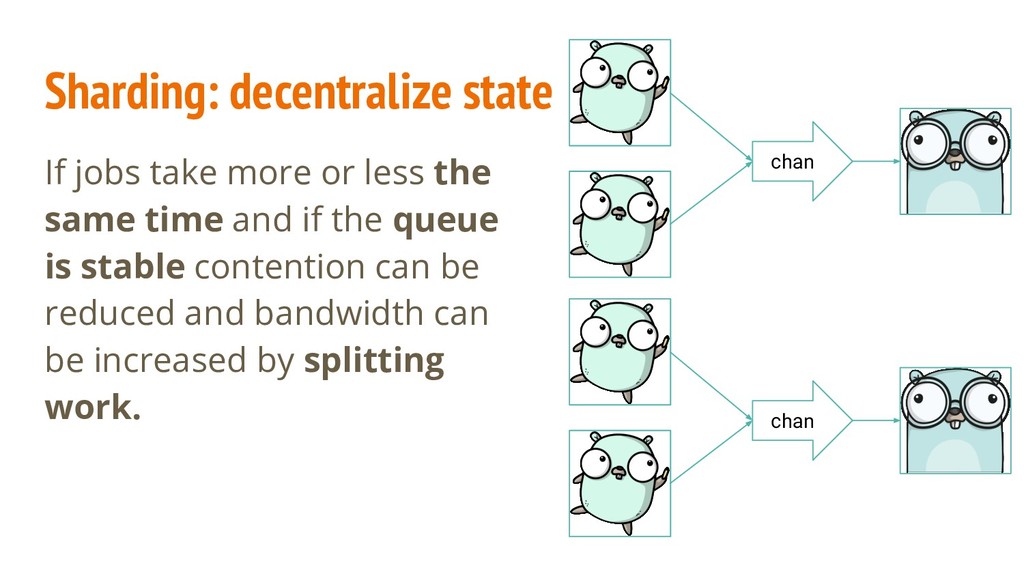
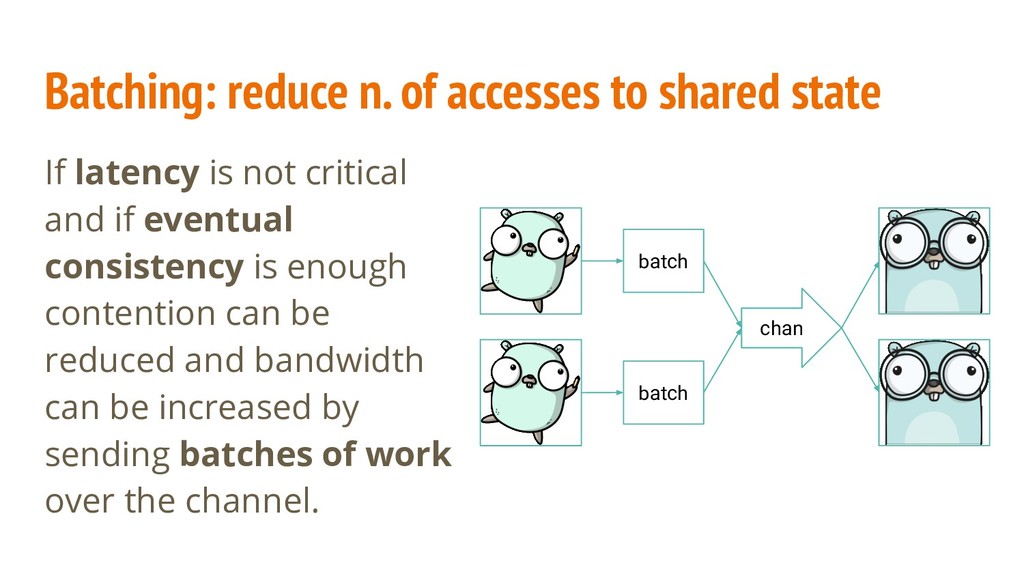
is not critical and if eventual consistency is enough contention can be reduced and bandwidth can be increased by sending batches of work over the channel. chan batch batch
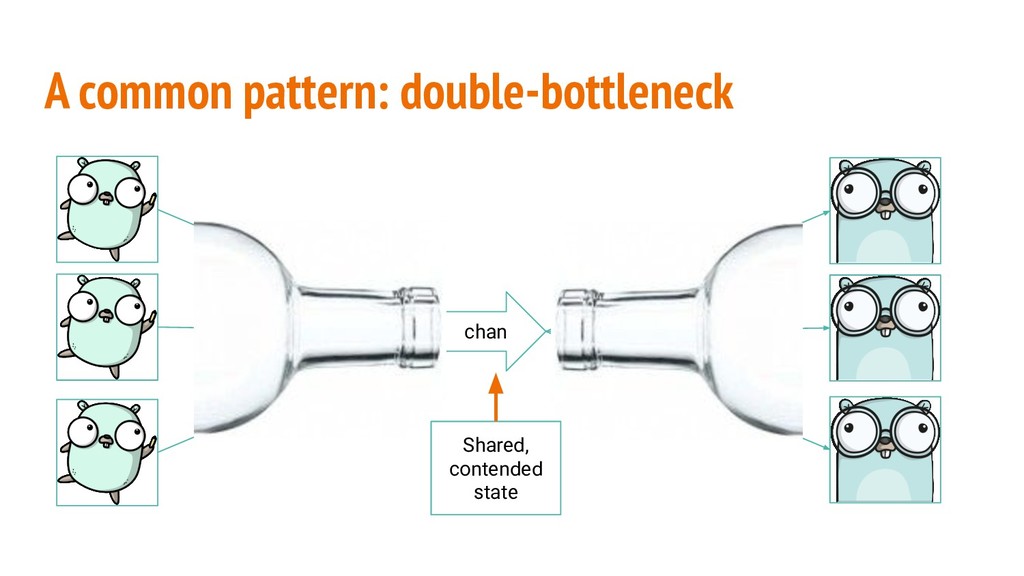
orchestration, readability and writability for the extra speed. That said Go mutexes are fair and fast. If a mutex becomes contended the same principles apply: ◦ Sharding (beware of Zipf law) ◦ Batching (beware of inconsistency) ◦ Shorten critical section to what is needed RWMutex: for a very high reads/writes ratio
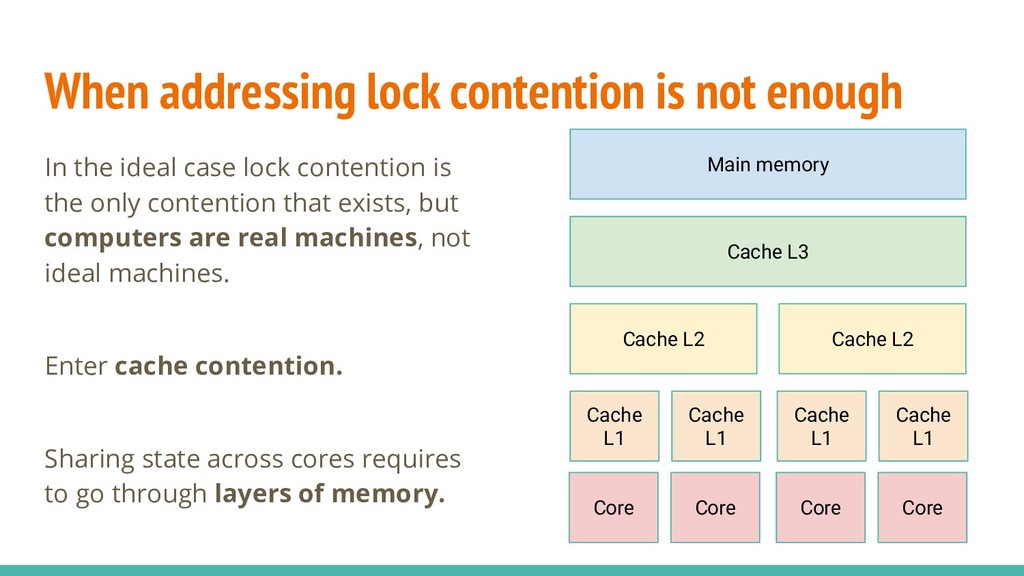
case lock contention is the only contention that exists, but computers are real machines, not ideal machines. Enter cache contention. Sharing state across cores requires to go through layers of memory. Main memory Cache L3 Cache L2 Cache L2 Cache L1 Cache L1 Cache L1 Cache L1 Core Core Core Core
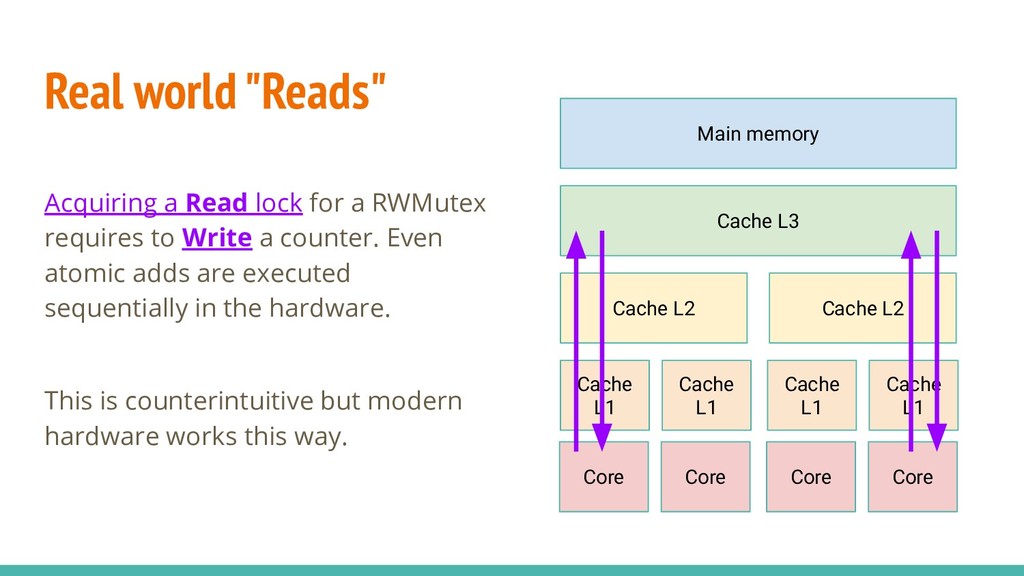
requires to Write a counter. Even atomic adds are executed sequentially in the hardware. This is counterintuitive but modern hardware works this way. Main memory Cache L3 Cache L2 Cache L2 Cache L1 Cache L1 Cache L1 Cache L1 Core Core Core Core
with an RWMutex and it is cache friendly. Downside is that it gives less guarantees, less methods and loses type safety, so you should only use it if necessary. It is strongly advised to never use it directly but write type-safe wrappers for it. Package sync type Map func (m *Map) Delete(key interface{}) func (m *Map) Load(key interface{}) (val interface{}, ok bool) func (m *Map) Range(f func(key, value interface{}) bool) func (m *Map) Store(key, value interface{})
need to have something different than a map that you rarely write but frequently read. In those rare cases you can use the atomic package. If you deal with objects you'll need to also use unsafe.
detect your races. It is very hard to reason about the code. Very few people can. Even the experts on these topics have a hard time debugging this kind of code.
for { oldValue := atomic.Load(addr) newValue := change(oldValue) if atomic.CompareAndSwap(addr, oldValue, newValue) { break } } Warning: do not just use Store or you'll get a nasty data race. Be also aware of the ABA problem.
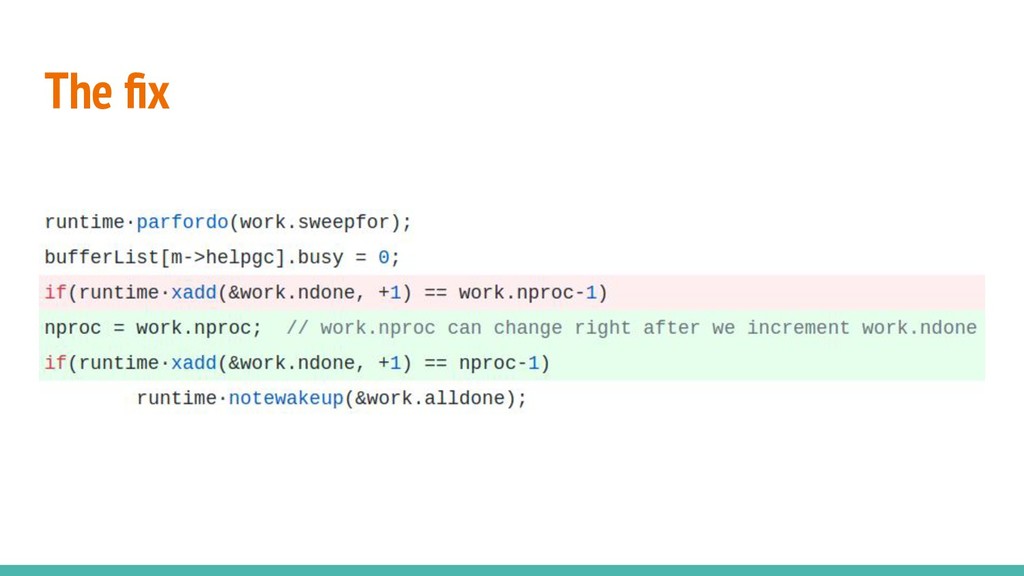
to atomics on Jul 2011. This introduced a bug that caused some random-looking memory corruptions. The bug was fixed on Apr 2014. • A bug in the parallel GC was introduced on Sep 2011 and fixed only on Jan 2014. runtime.parfordo(work.sweepfor); bufferList[m->helpgc].busy = 0; if(runtime.xadd(&work.ndone, +1) == work.nproc-1) runtime.notewakeup(&work.alldone);
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}