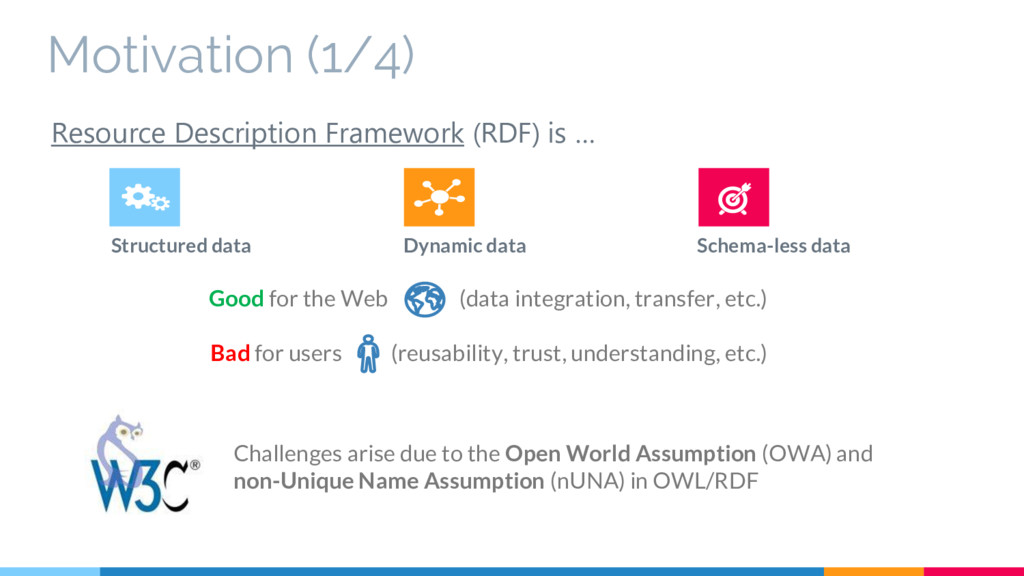
is … Good for the Web (data integration, transfer, etc.) Bad for users (reusability, trust, understanding, etc.) Challenges arise due to the Open World Assumption (OWA) and non-Unique Name Assumption (nUNA) in OWL/RDF Motivation (1/4)
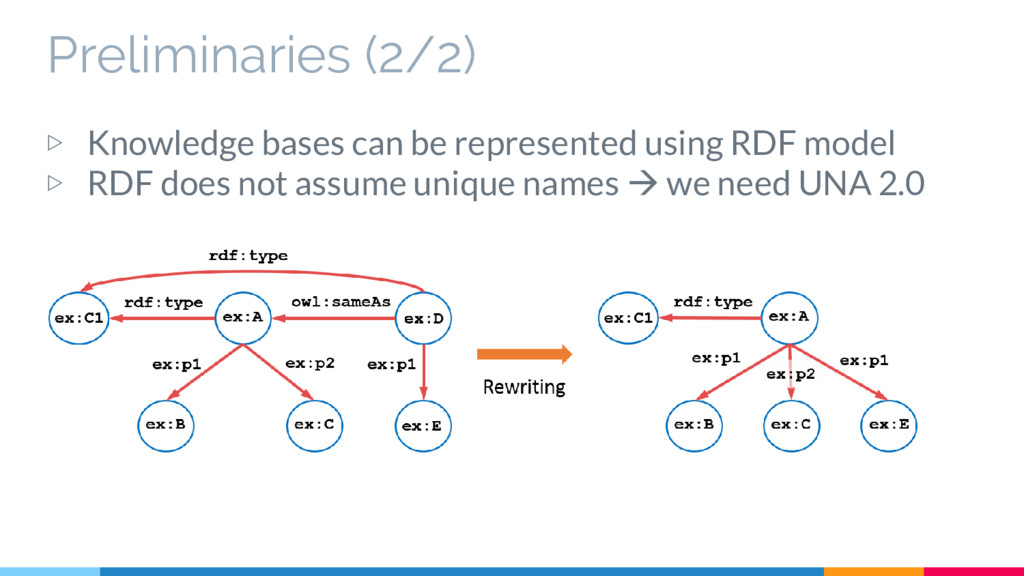
an assertion is not necessarily known If an assertion is not in the knowledge base we cannot say it is negative ▷ No Unique Name Assumption: Individuals may have more than one name
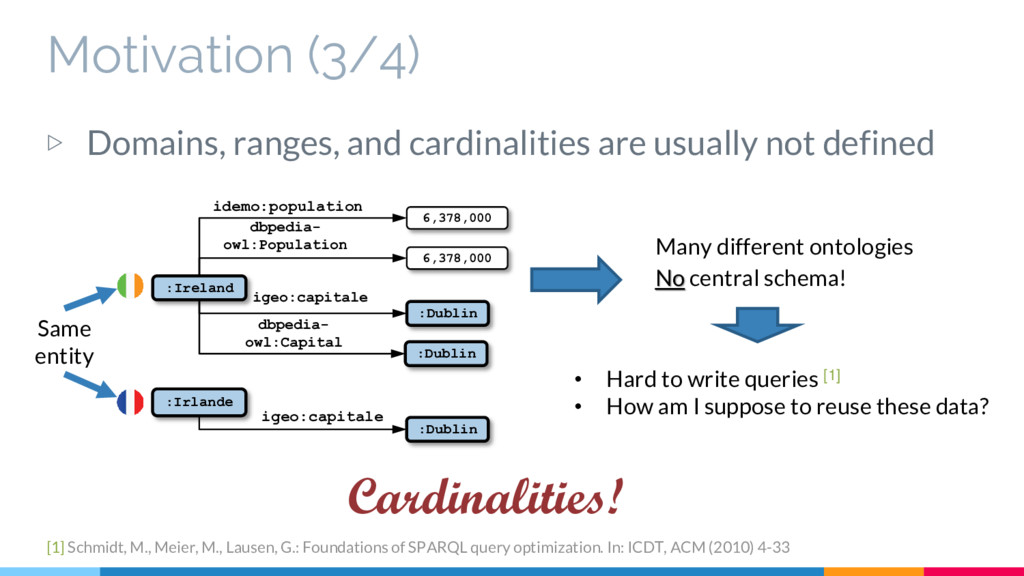
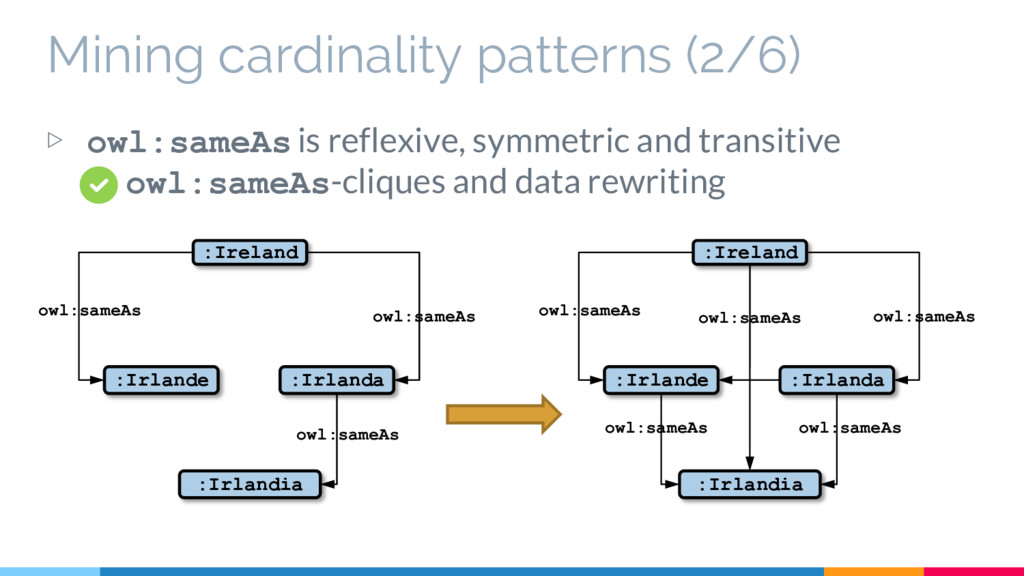
defined :Ireland 6,378,000 idemo:population dbpedia- owl:Population 6,378,000 igeo:capitale :Dublin dbpedia- owl:Capital :Dublin No central schema! • Hard to write queries [1] • How am I suppose to reuse these data? Cardinalities! :Irlande igeo:capitale :Dublin Many different ontologies [1] Schmidt, M., Meier, M., Lausen, G.: Foundations of SPARQL query optimization. In: ICDT, ACM (2010) 4-33 Same entity
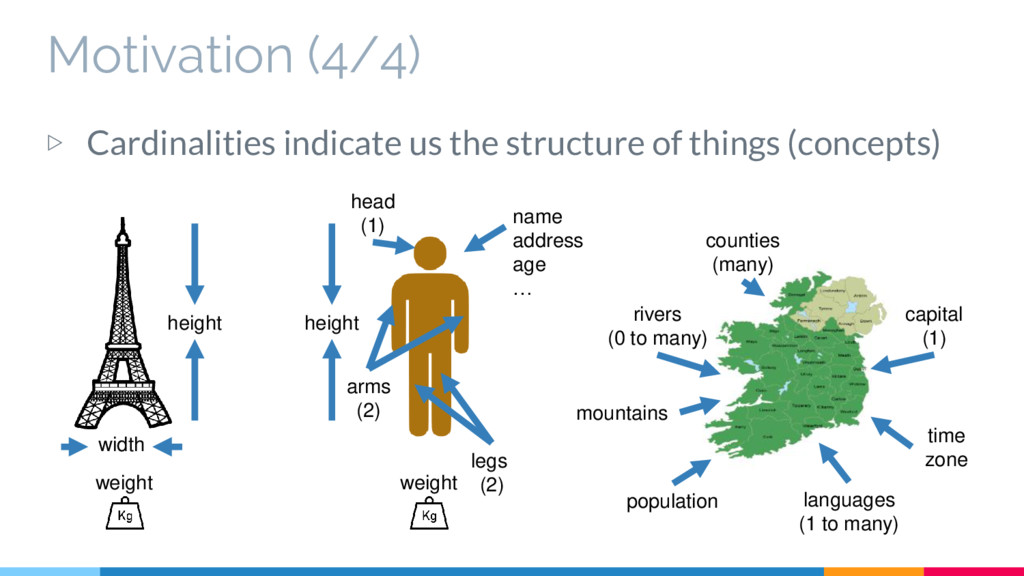
(concepts) height width weight legs (2) arms (2) head (1) name address age … capital (1) counties (many) height weight rivers (0 to many) mountains population languages (1 to many) time zone
ShEx[2], RDD[3], SHACL[4], SPIN[5], OSLC[6] ▷ Consistency in RDF KBs No work has focused on the extraction of cardinalities to detect inconsistencies in KBs. Previous work focused on property values missing, not cardinalities ▷ RDF schema discovery Use of rule mining to infer an ontology Use of SPARQL queries to mine simple cardinalities (issues) [2] https://www.w3.org/2013/ShEx/Primer [3] P. M. Fischer, G. Lausen, A. Schatzle, and M. Schmidt. RDF Constraint Checking. EDBT/ICDT Workshops 2015. [4] https://www.w3.org/TR/shacl/ [5] http://spinrdf.org/ [6] https://www.w3.org/Submission/2014/SUBM-shapes-20140211/
model ▷ RDF does not assume unique names we need UNA 2.0 RDF model Set of resource: ℛ e.g.: ex:JonSnow Set of blank nodes: ℬ e.g.: _:bnode Set of predicates: e.g.: rdf:type Set of literals: ℒ e.g.: “Francia@es” ≡ { , , ∈ ∪ × × ( ∪ ∪ )}
selected 1 class per dataset and 5 predicates ▷ A property in the context of a type is complete given a cardinality constraint if every entity of type has the ‘right number’ of triples (, , ); and incomplete otherwise ▷ A predicate in the context of a type is consistent if the triples with predicate and subject of type comply with the cardinality bounds; and inconsistent otherwise
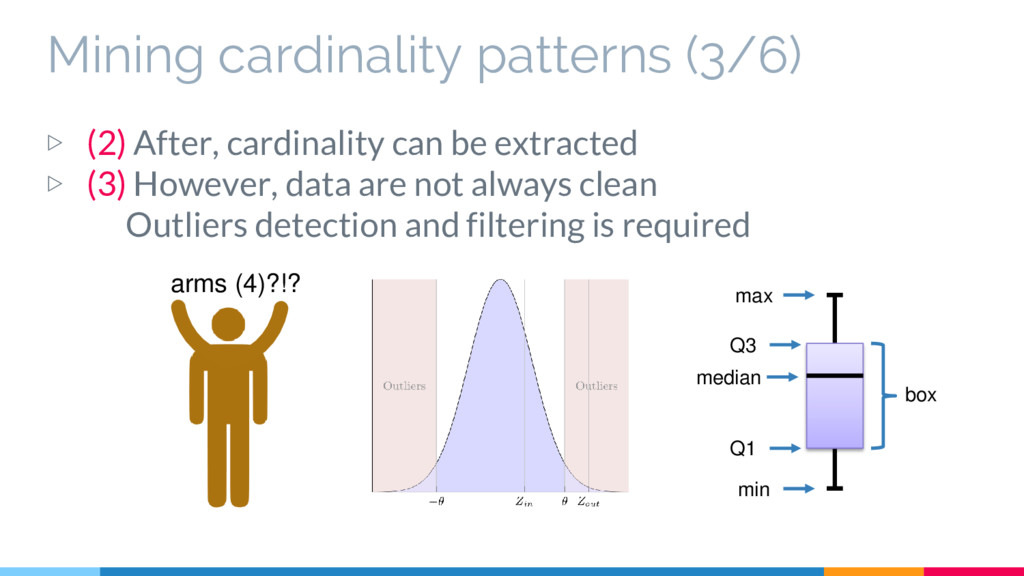
lack the description of cardinalities - A data normalization is required to extract accurate cardinalities - An outlier filtering is required to extract robust cardinalities - Cardinality bounds can help us to assess consistency and completeness
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Any questions? Emir Muñoz [email protected] Key points: - KBs](https://files.speakerdeck.com/presentations/d9adc78002944c86a059aa15bf2882ee/slide_22.jpg){kind=link}