Talk at the Machine Learning Galway Meetup
https://www.meetup.com/machine-learning-galway/events/266142136/
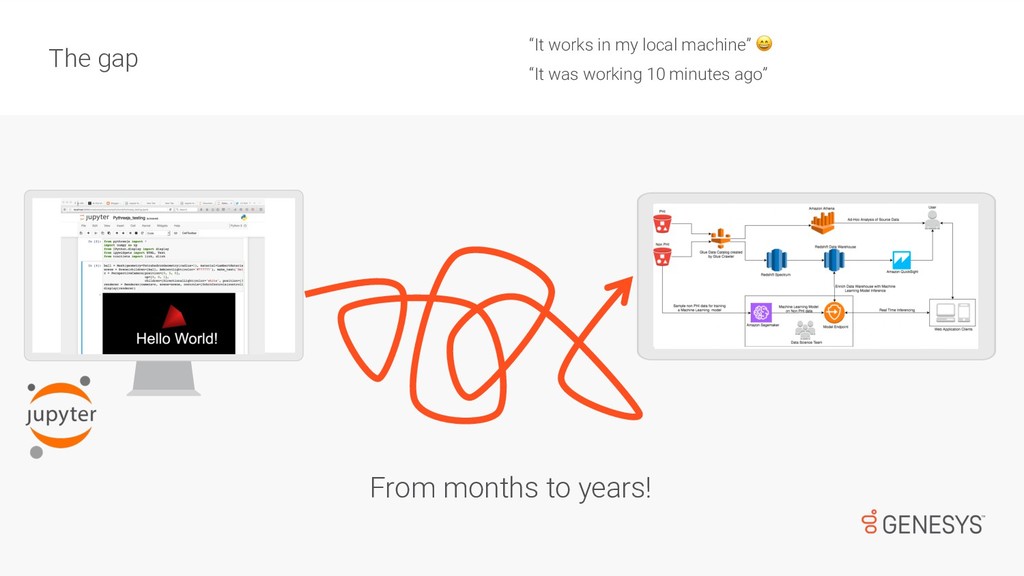
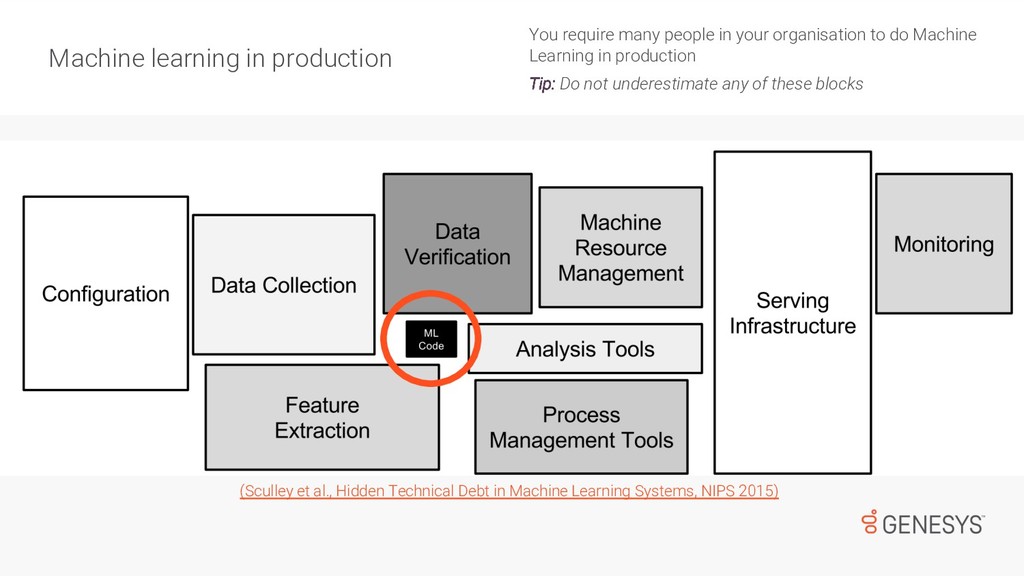
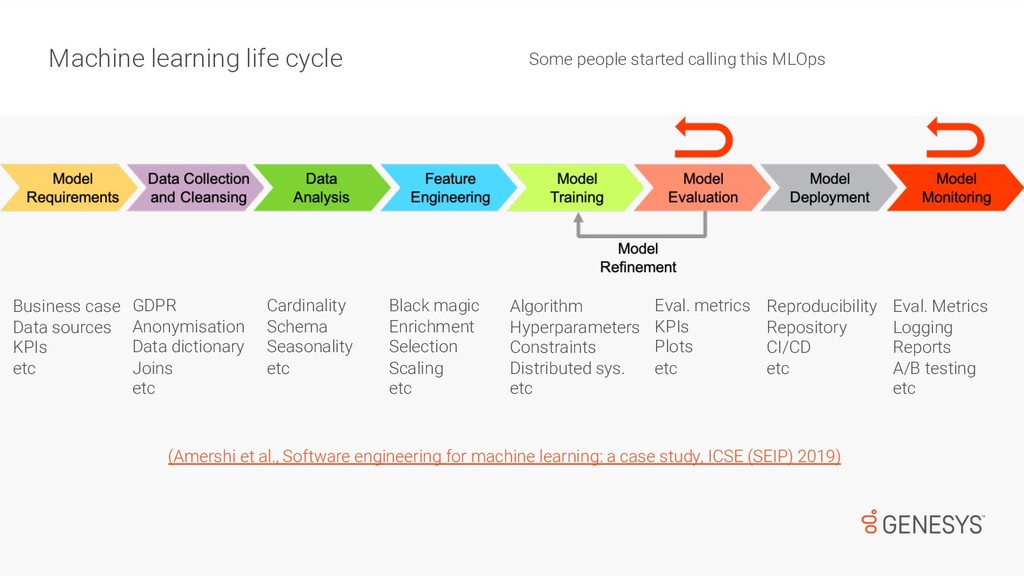
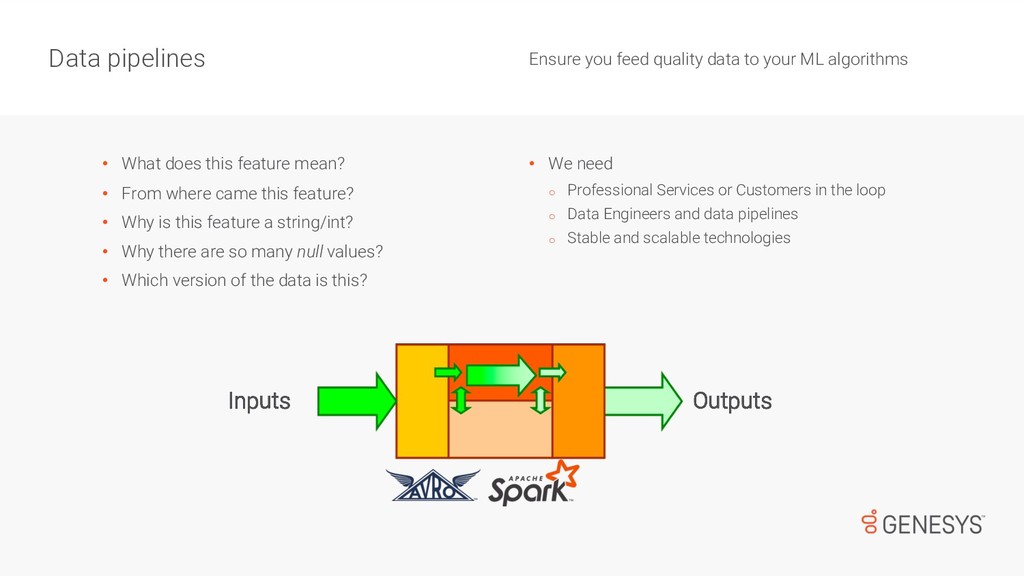
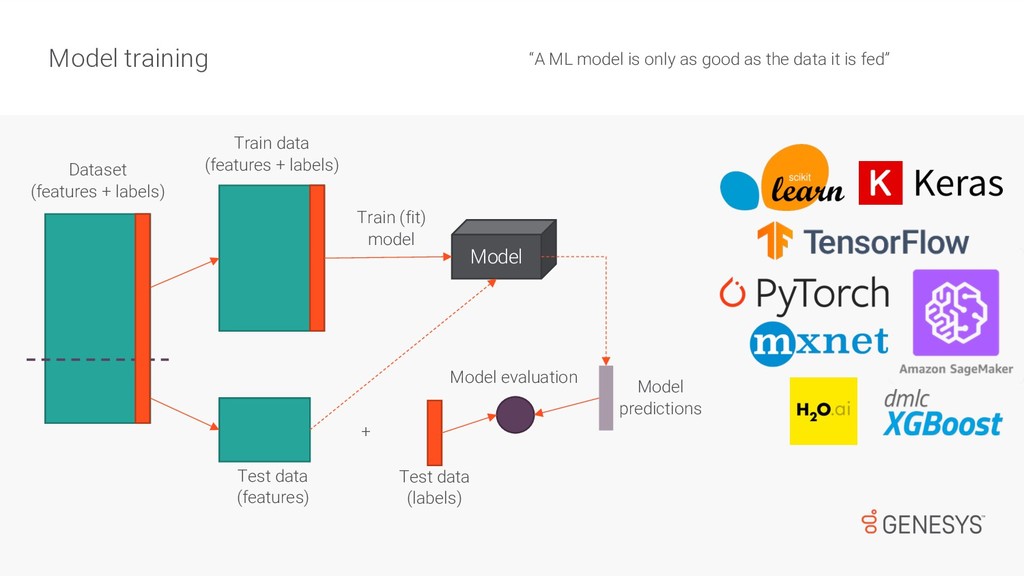
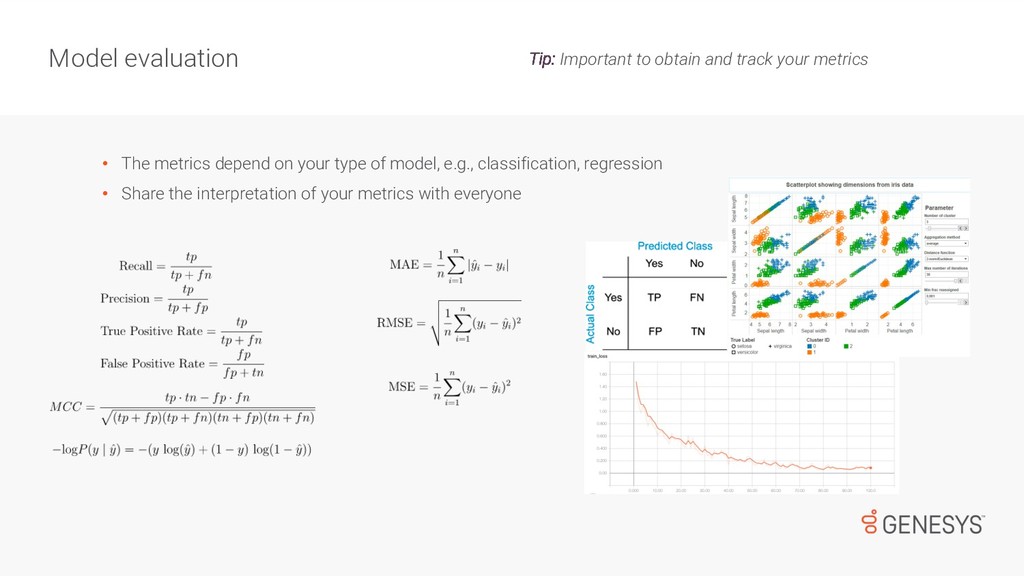
While most of us have done Machine Learning over well-known/clean/small datasets, there is a big difference when dealing with noisy/large data, which is used to train models and support near-real-time services available to customers. First, there are challenges collecting and cleaning data for training ML models. Then, once the models are trained and ready for deployment, there are monitoring tasks that go beyond DevOps and that can have a huge impact on the performance of products and services. In this talk, Emir will speak about how to standardise the process of data collection for ML, and how to deal with the challenges that appear after models are deployed in production.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
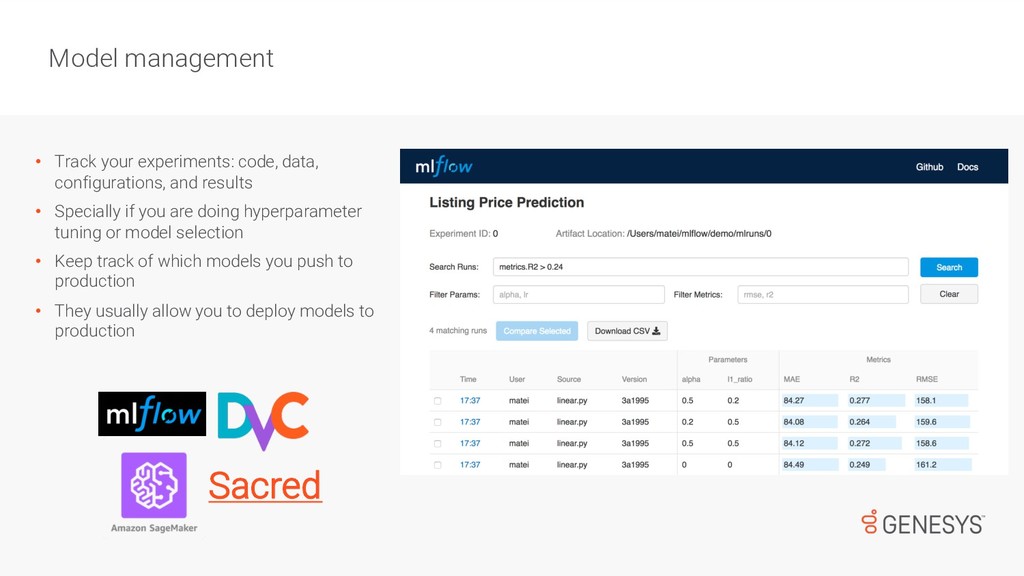{kind=link}
{kind=link}
{kind=link}
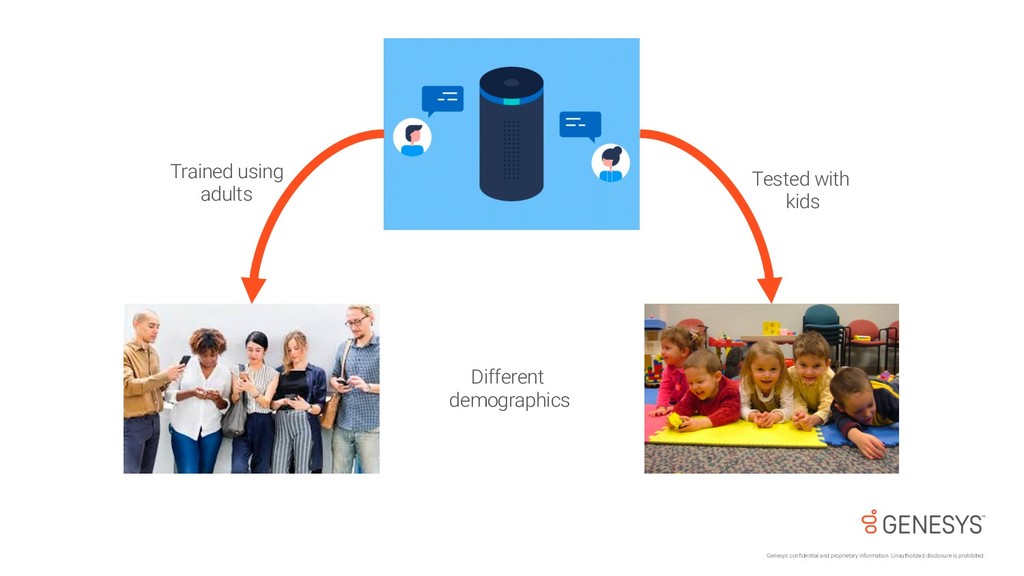{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}