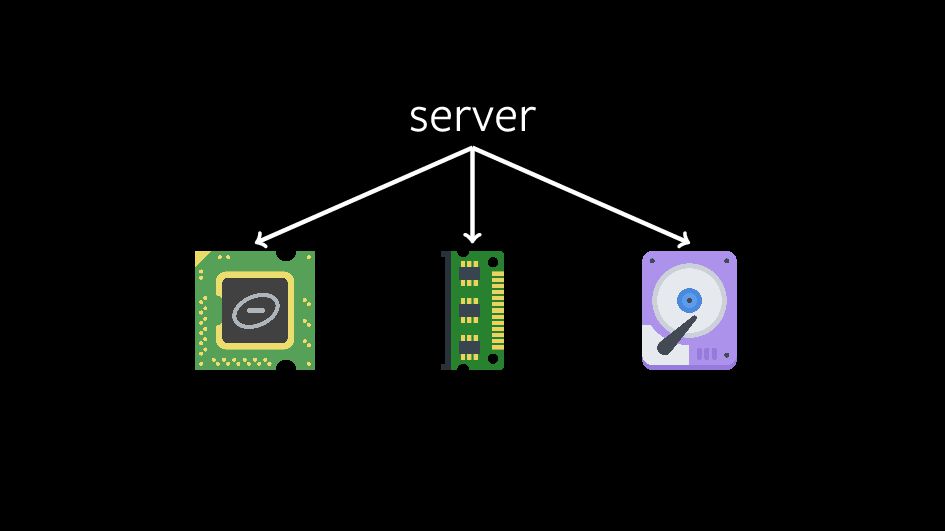
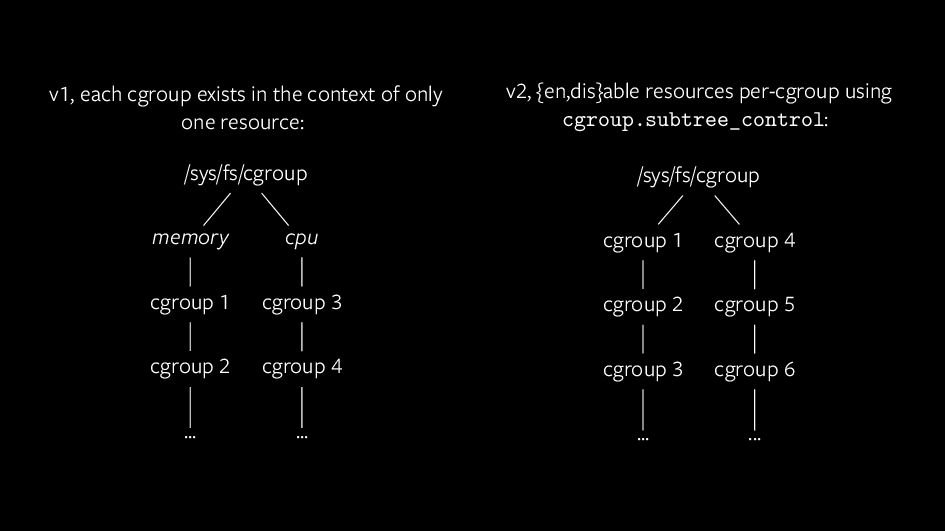
Control groups (or cgroups for short) are one of the most fundamental technologies underpinning our modern love of containerisation and resource control. Back in 2016, we released a complete overhaul of how cgroups work internally: cgroup v2, released with Linux 4.5. This brought many new and exciting possibilities to increase system stability and throughput, but with those possibilities have also come challenges of a type which we have largely not faced in Linux before.
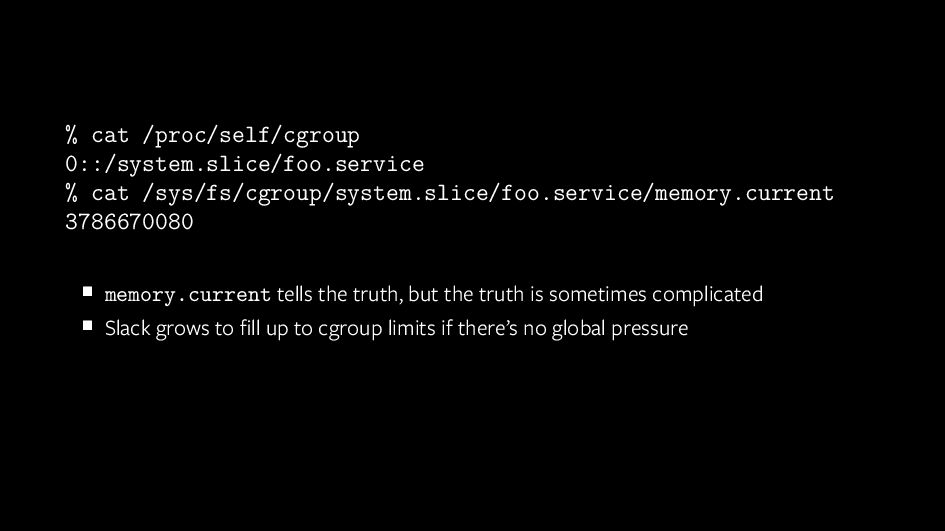
This talk will go into some of the challenges faced in overhauling Linux’s resource isolation and control capabilities, and how we’ve gone about fixing them. This will include some of the most complex and counter-intuitive practical effects we’ve seen in production, with details of how our expectations and knowledge have developed over the last 5 years using this on over a million machines in production, with insights that are immediately applicable to anyone who runs Linux at scale.
We will also go over the state-of-the-art of resource control in the “real world” outside of companies like Meta and Google, looking at how cgroup v2 is changing the technical landscape for distributions and containerisation technologies for the better.
Chris Down
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
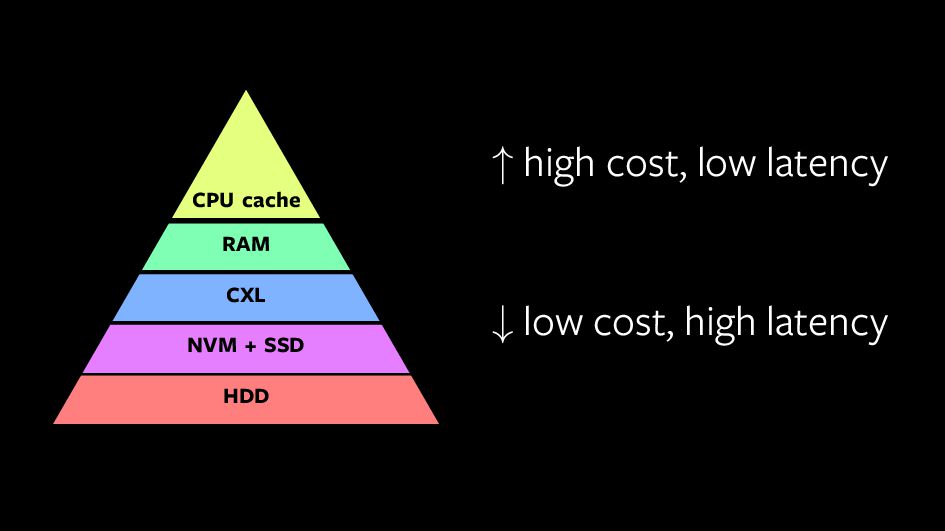{kind=link}
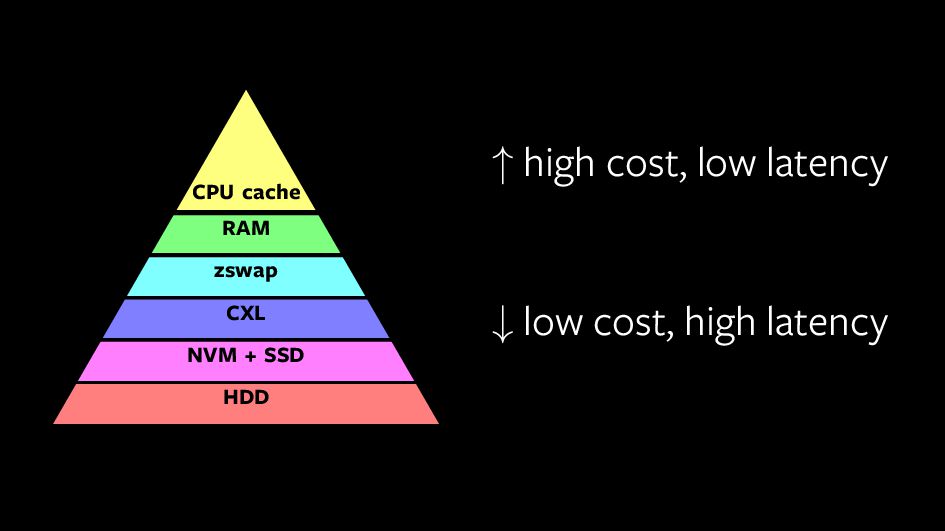{kind=link}
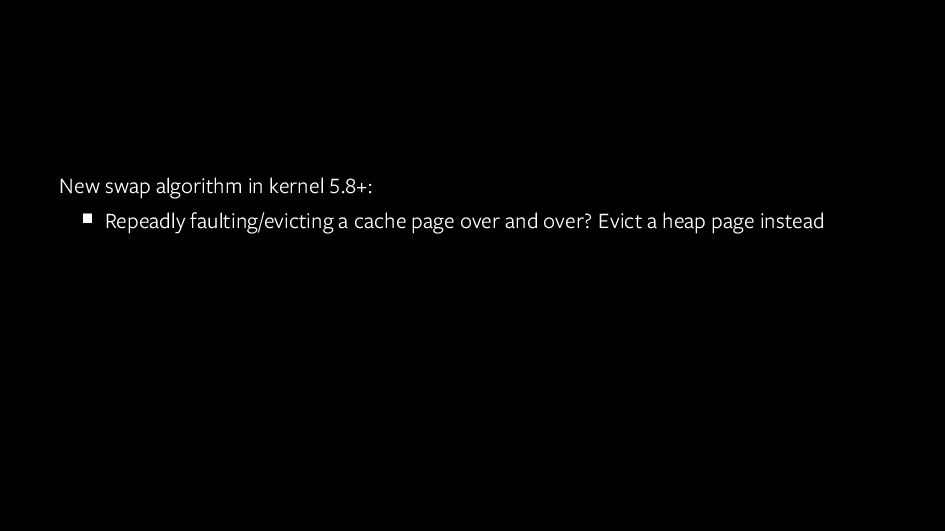{kind=link}
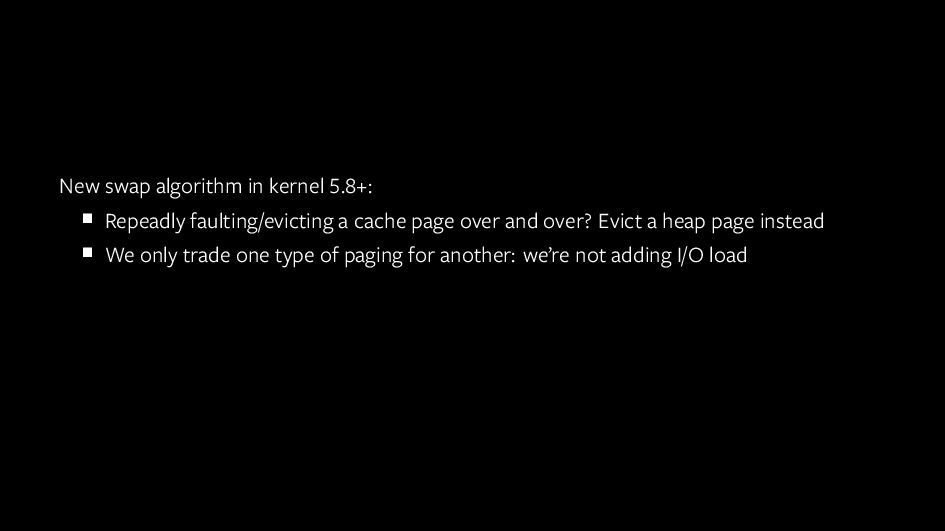{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
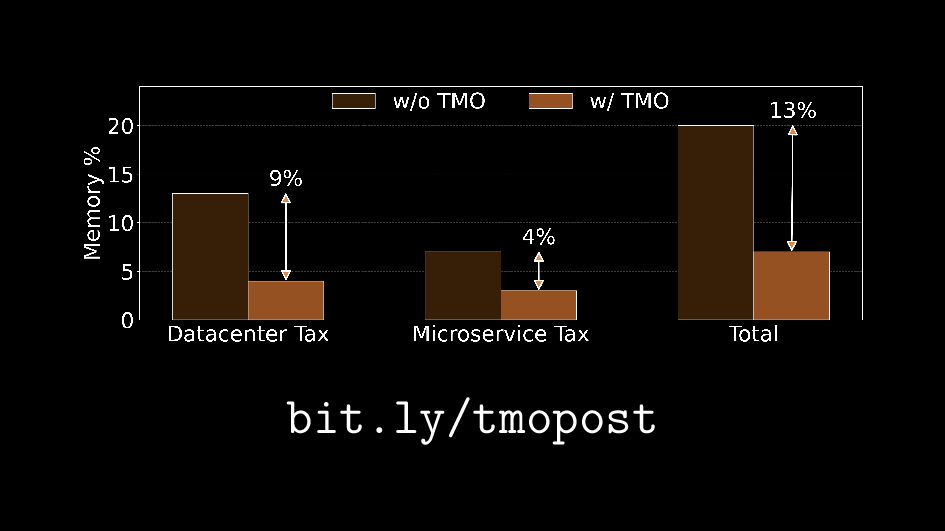{kind=link}
{kind=link}
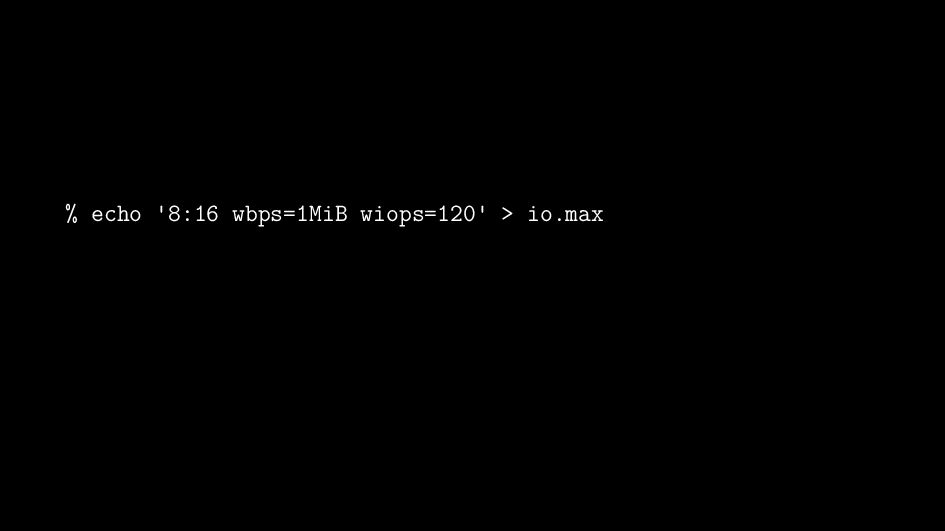{kind=link}
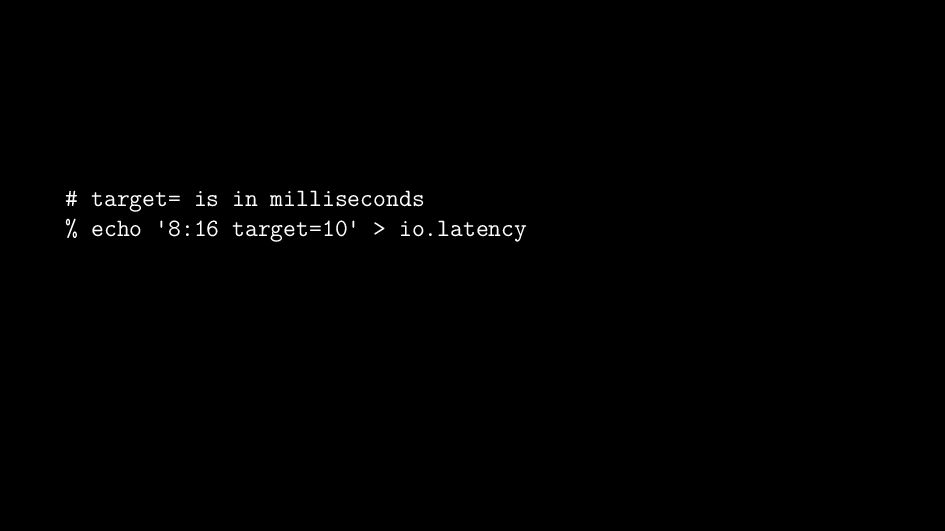{kind=link}
{kind=link}
{kind=link}
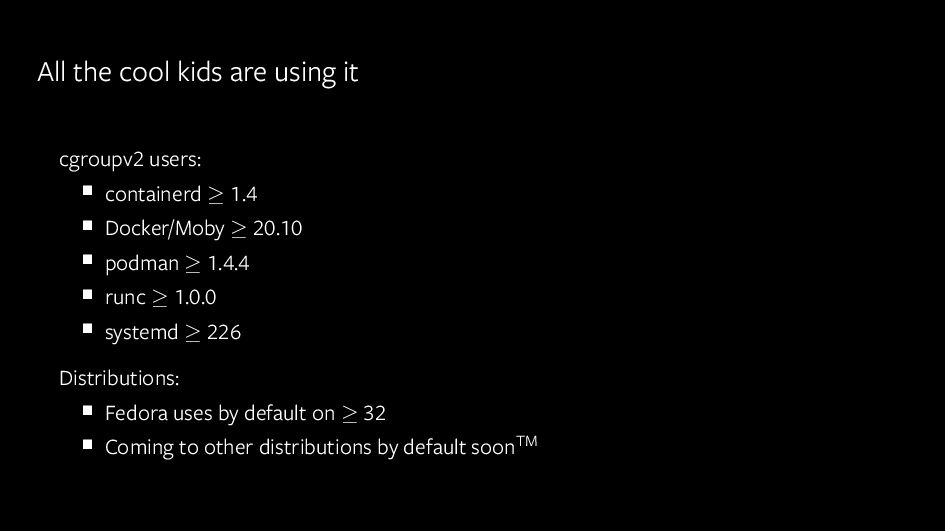{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}