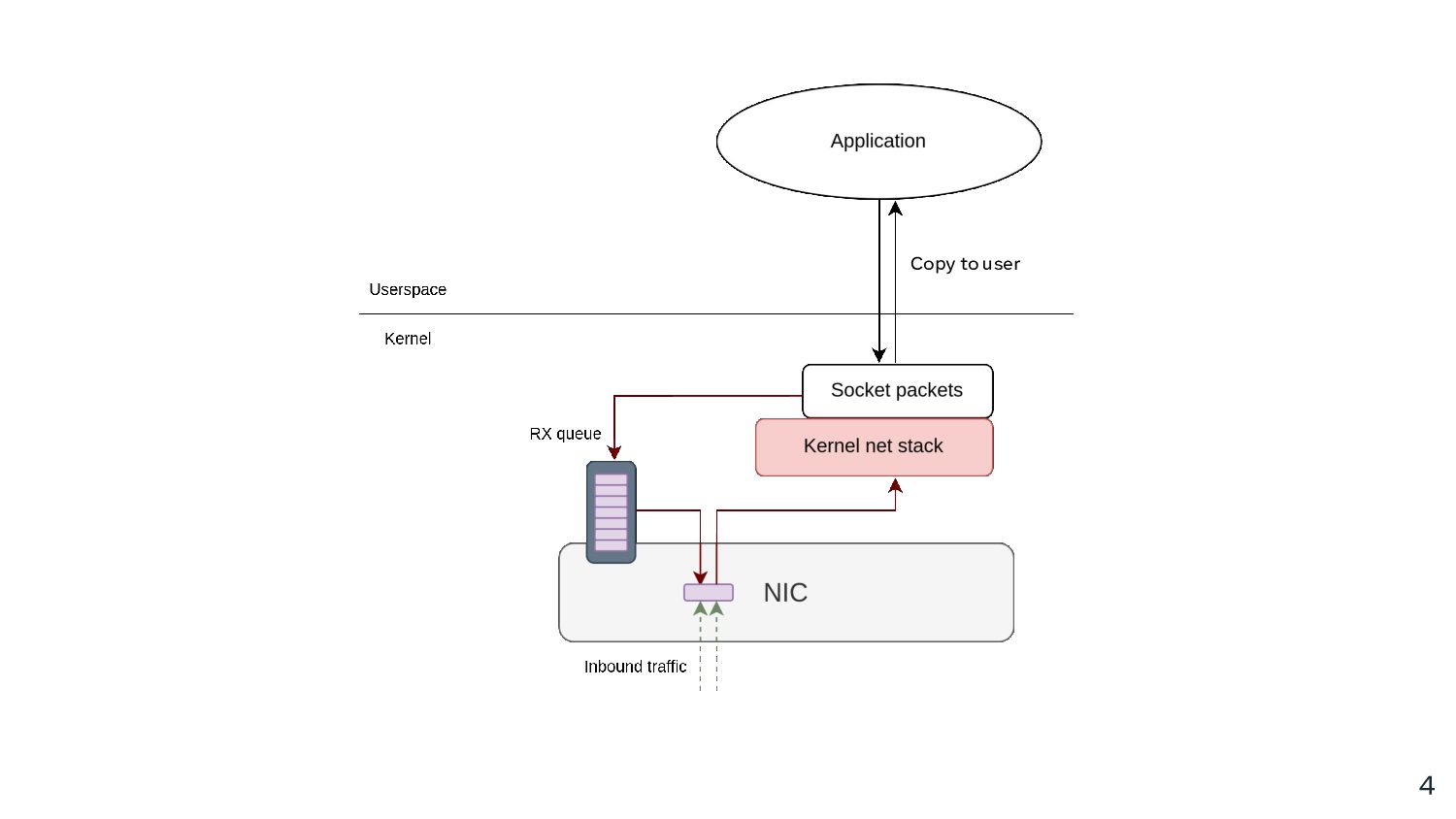
Zero copy receive has had its fair share of troubles, where approaches have various shortcomings, whether it’s bypassing the kernel network stack or resorting to expensive page flipping tricks.
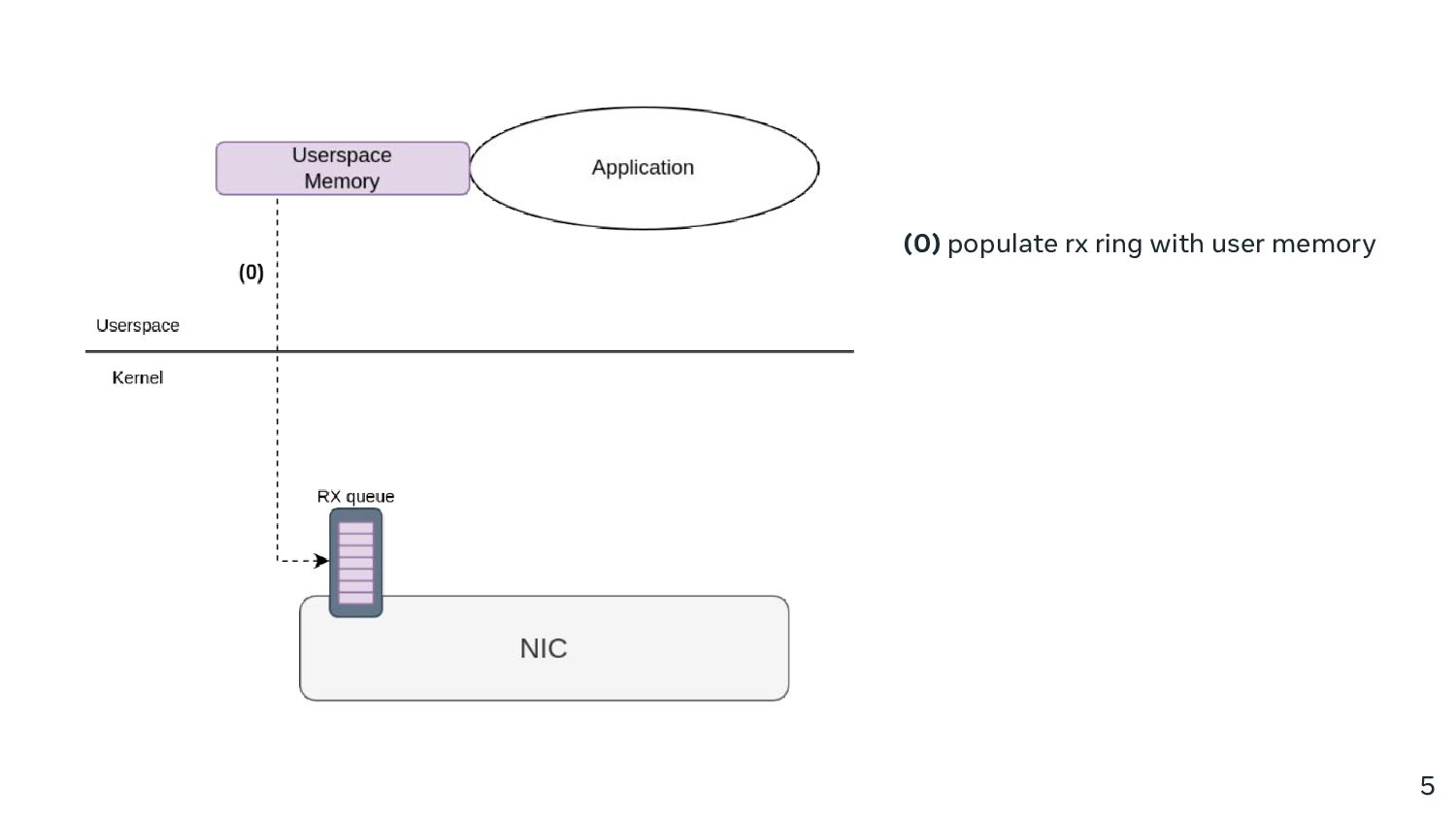
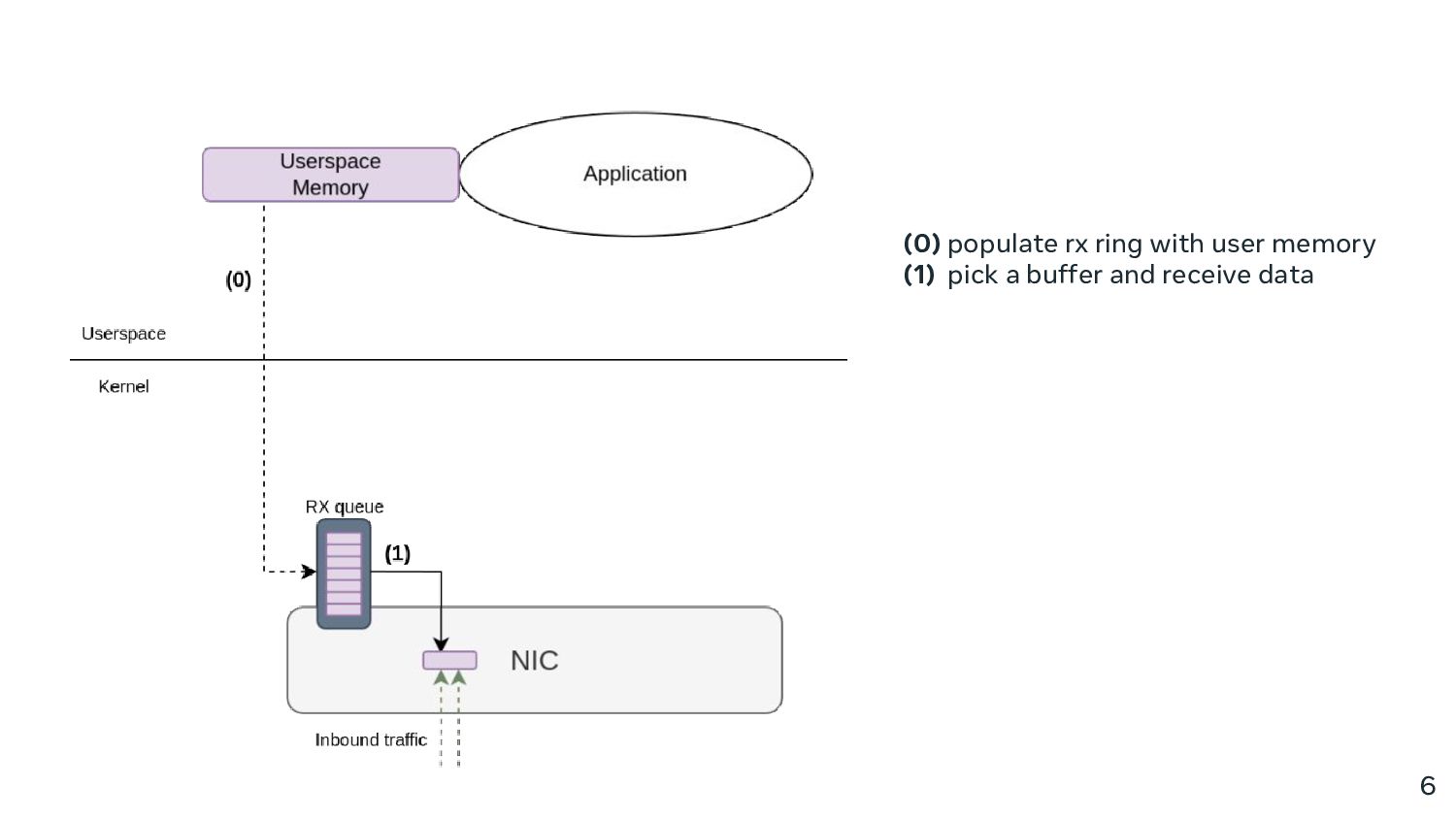
However, it doesn’t have to be this way! In this talk, we present a solution that utilises the kernel networking stack, is efficient even with small transfer sizes, and compatible with vanilla TCP and protocol agnostic in general. We’ll go over the design, initial performance results, as well as some of the nifty work that went into making it happen.
Pavel BEGUNKOV, David WEI
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
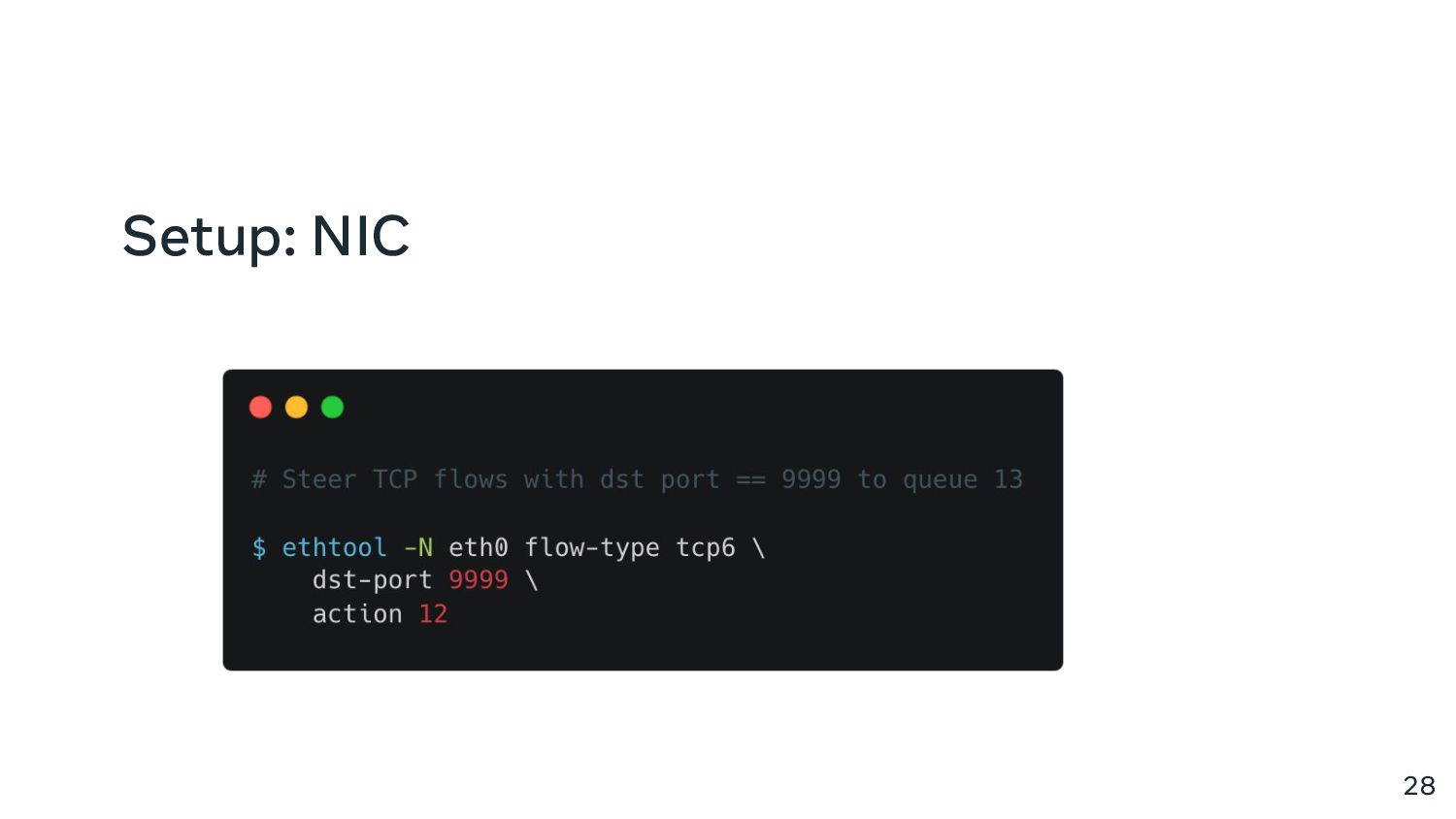{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
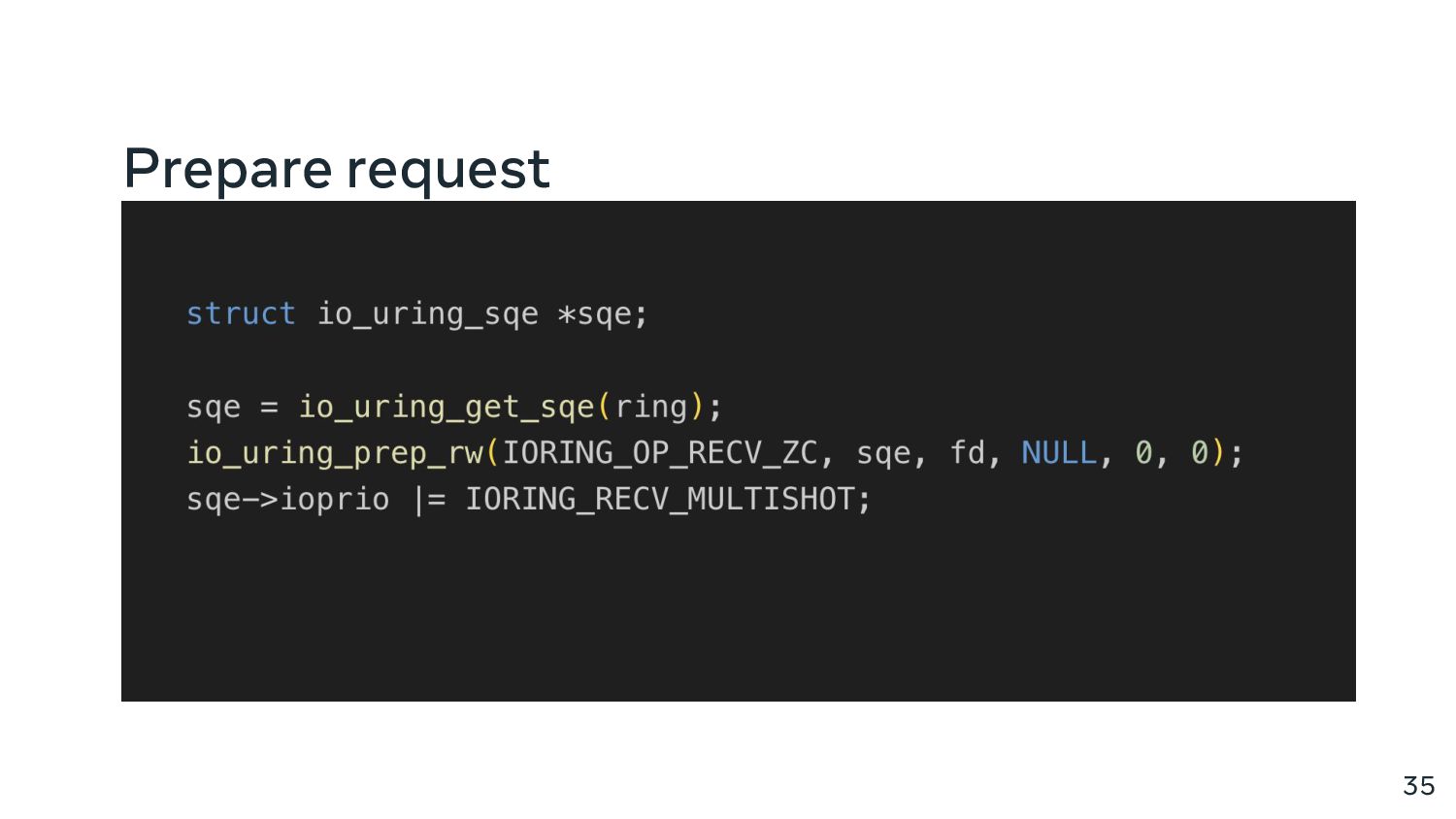{kind=link}
{kind=link}
{kind=link}
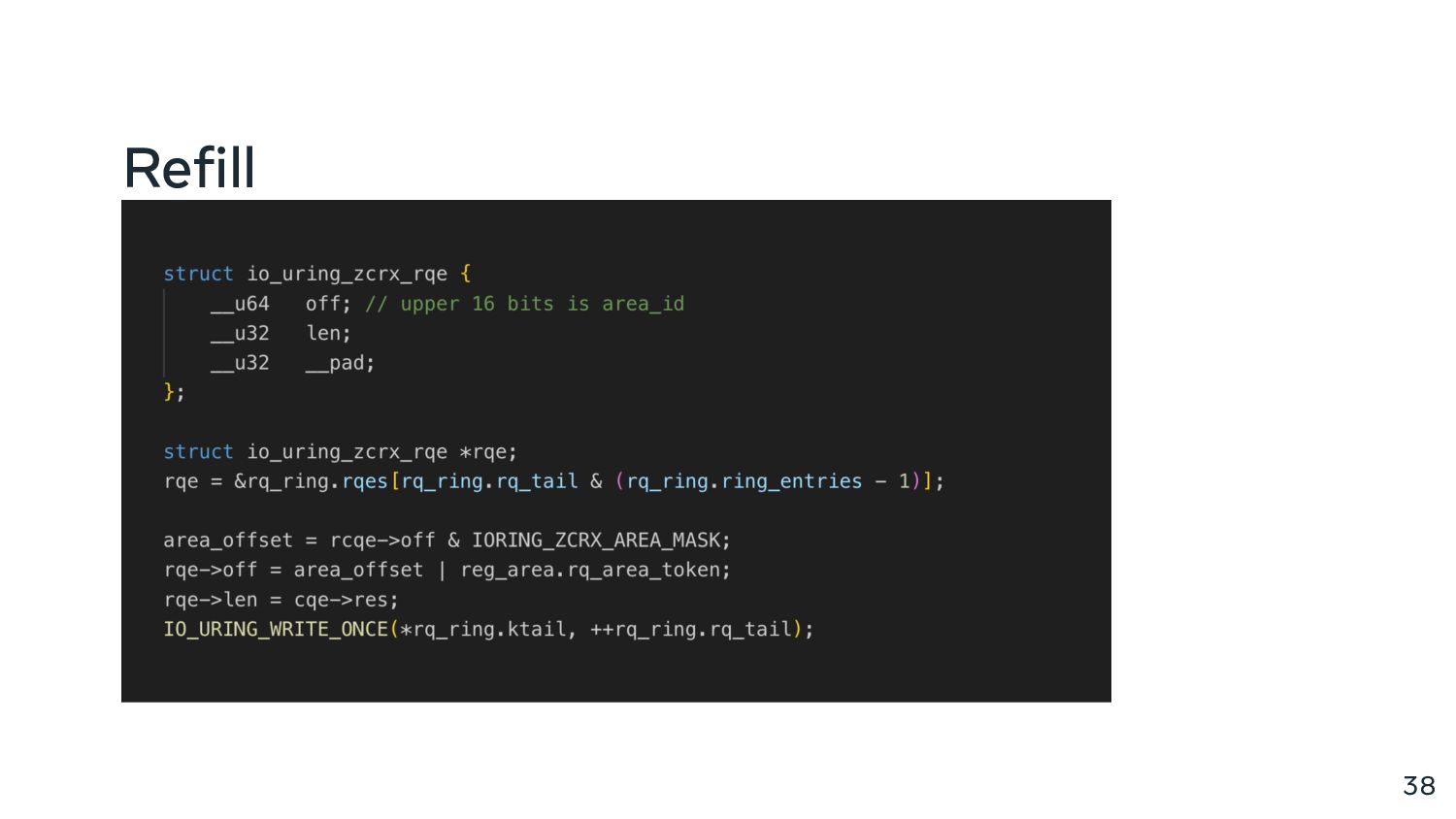{kind=link}
{kind=link}
{kind=link}
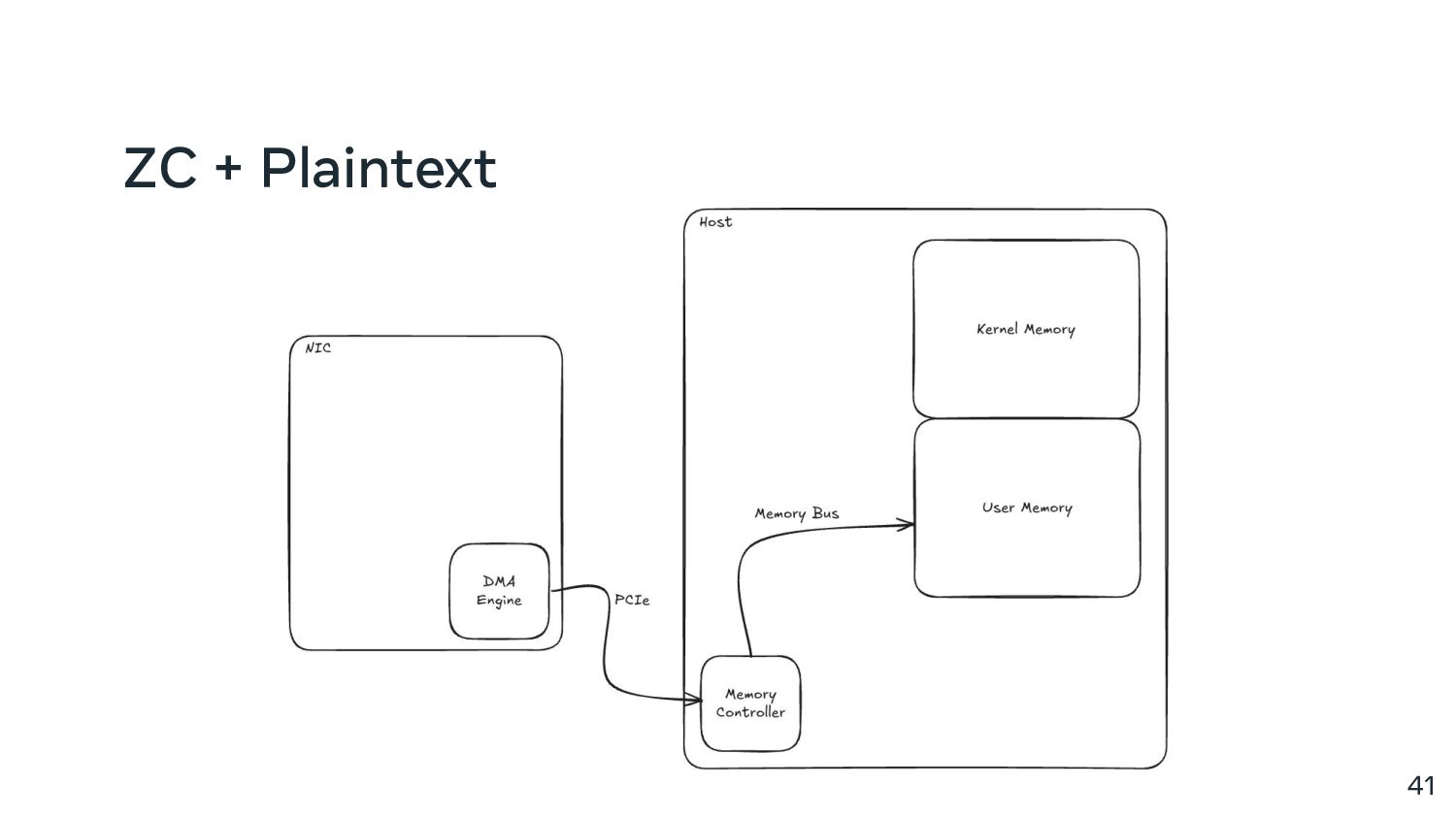{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![https://github.com/isilence/linux.git zcrx/v5-conf Quite outdated RFC: https://lore.kernel.org/io-uring/[email protected]/ Benchmarking: https://github.com/spikeh/netbench/tree/zcrx/next https://github.com/spikeh/kperf/tree/zcrx/next Contact](https://files.speakerdeck.com/presentations/4a01b2b2c48f405cad565f38265882de/slide_49.jpg){kind=link}