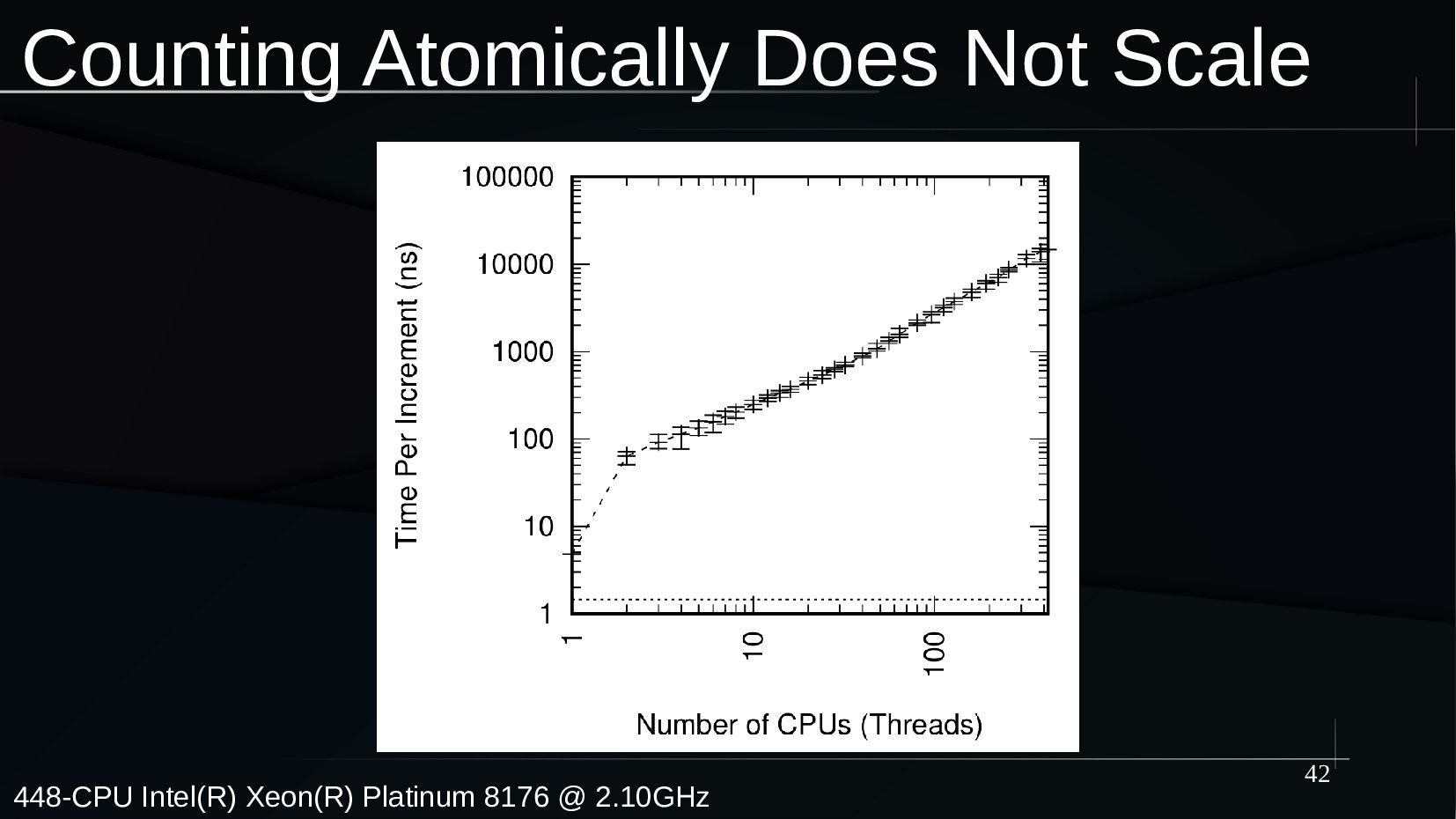
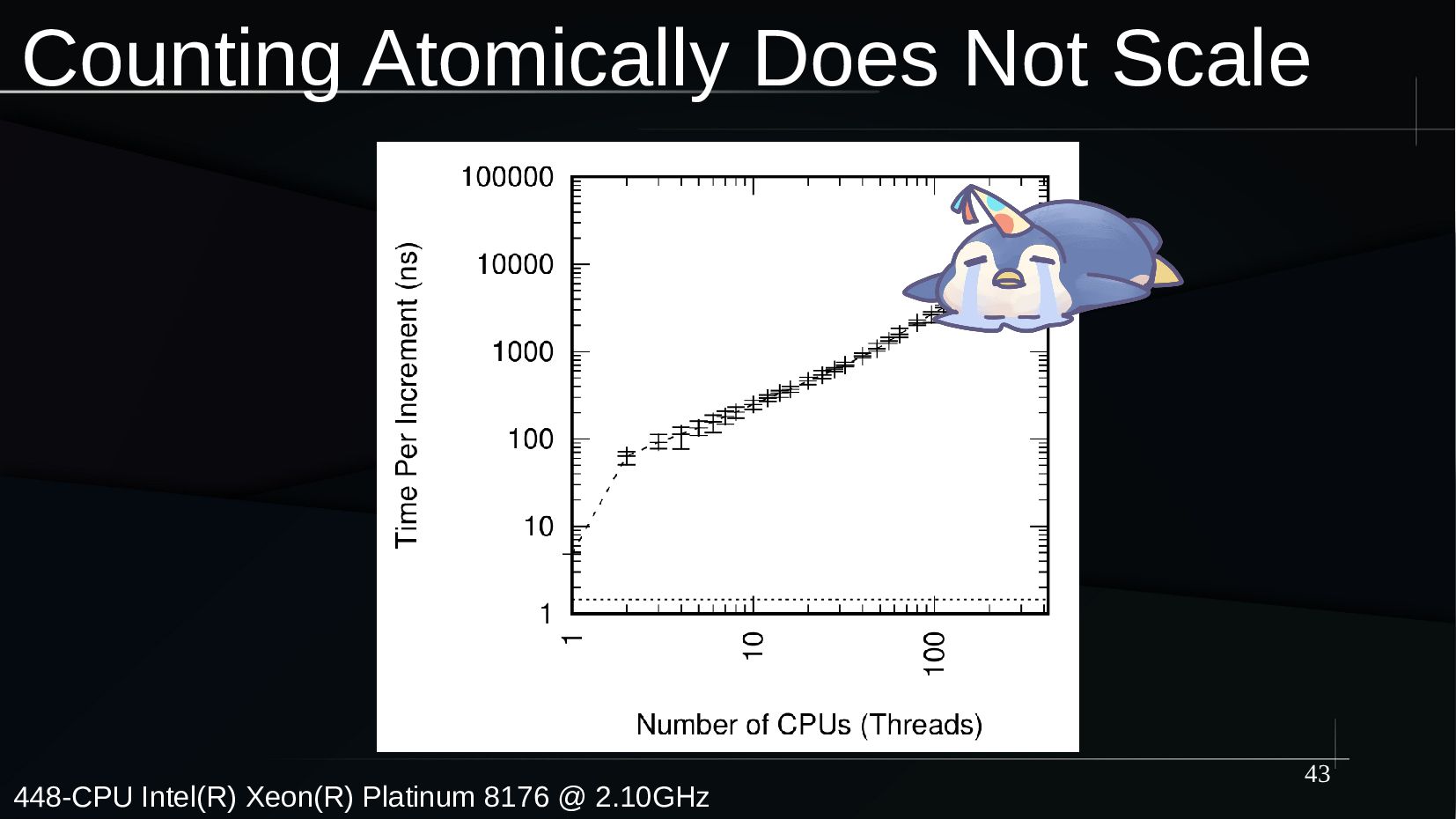
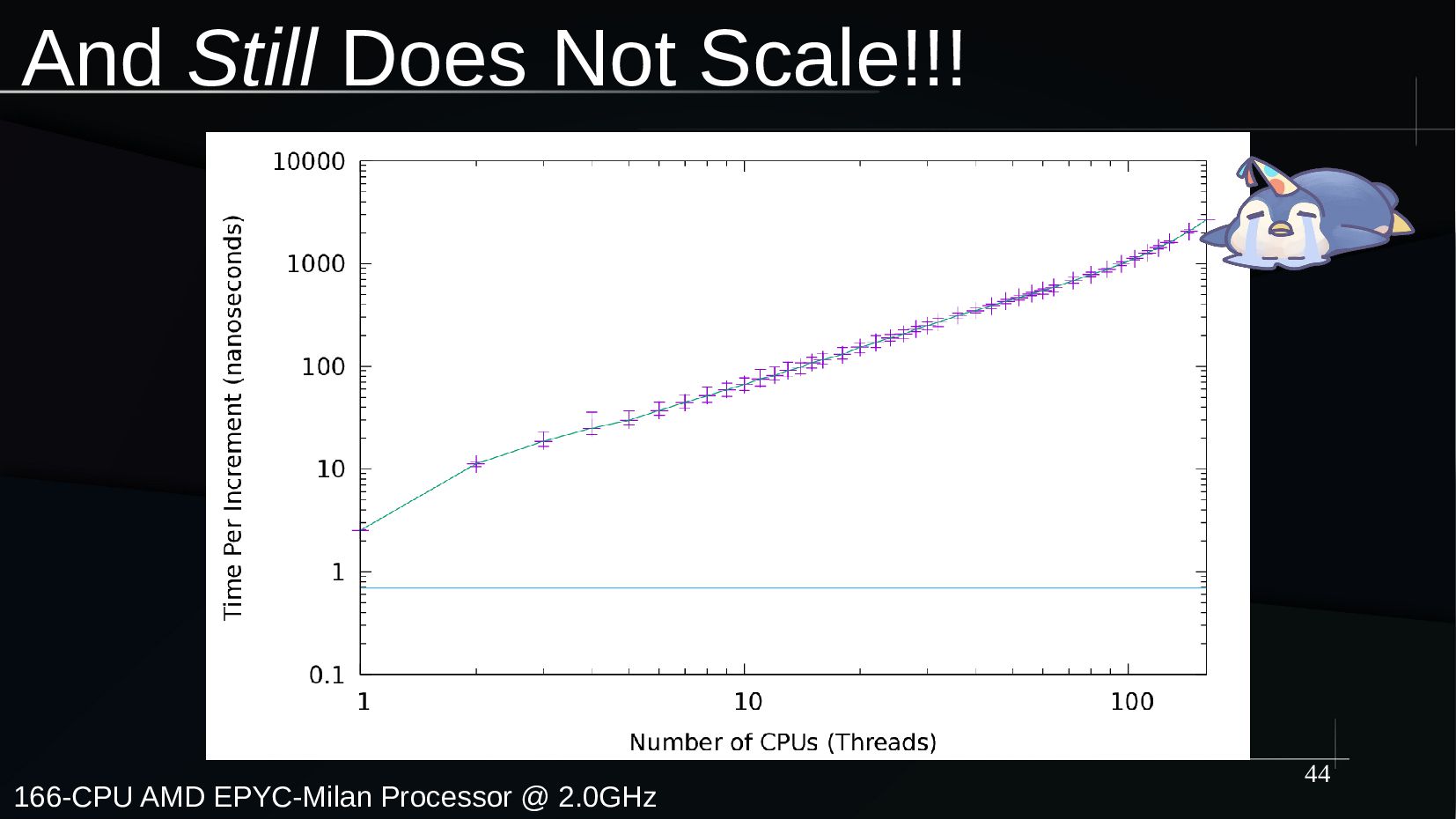
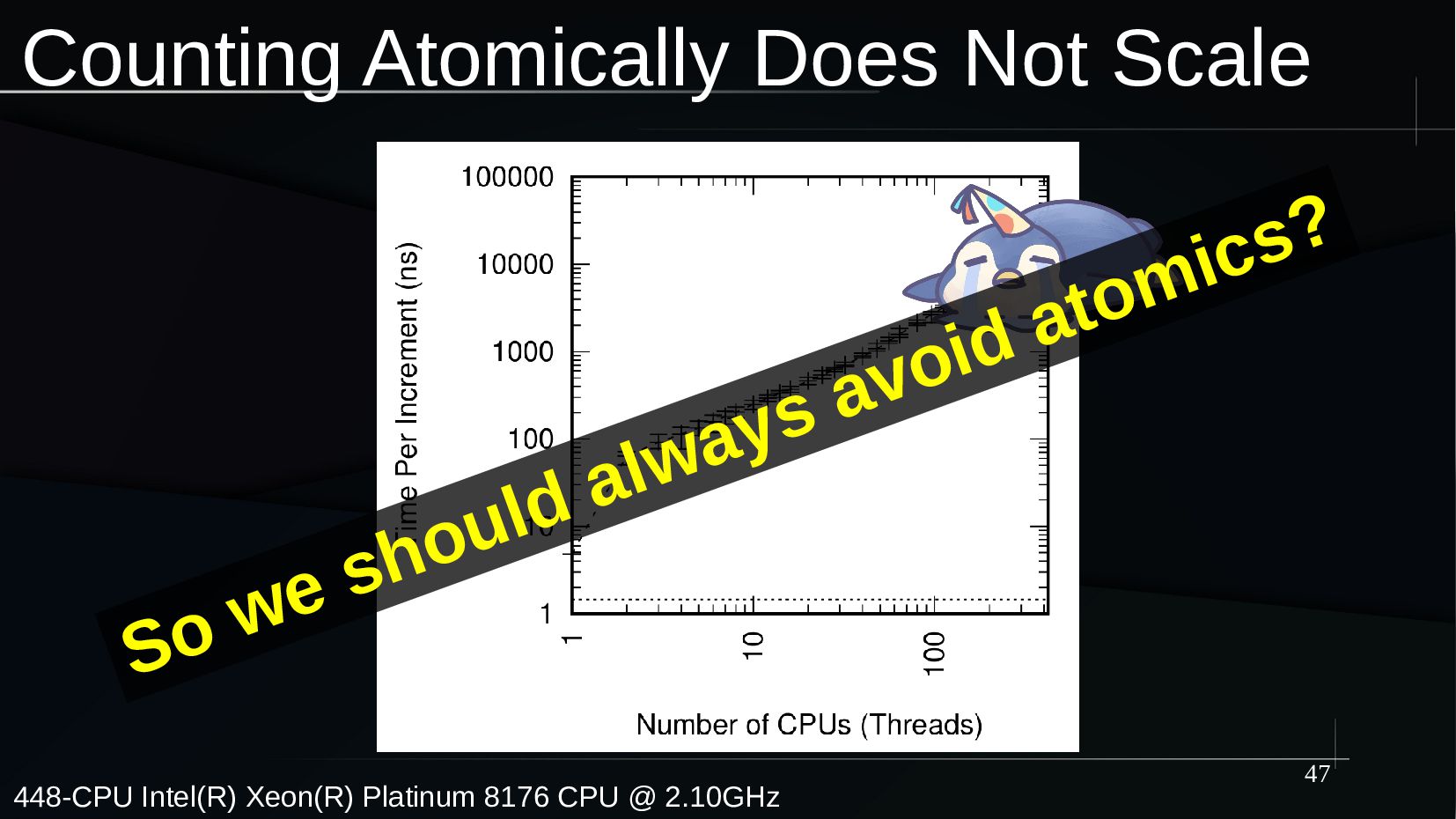
Counting is perhaps the simplest and most natural possible form of mathematics. However, counting efficiently and scalably on a large multicore system is quite challenging. And this is all to the good, because the simplicity of the underlying concept of counting allows us to explore the fundamental issues of concurrency without the distractions of elaborate data structures or complex synchronization primitives. These issues include design, coding, and validation.
This talk will therefore use counting as an introduction to concurrency.
Paul MCKENNEY
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
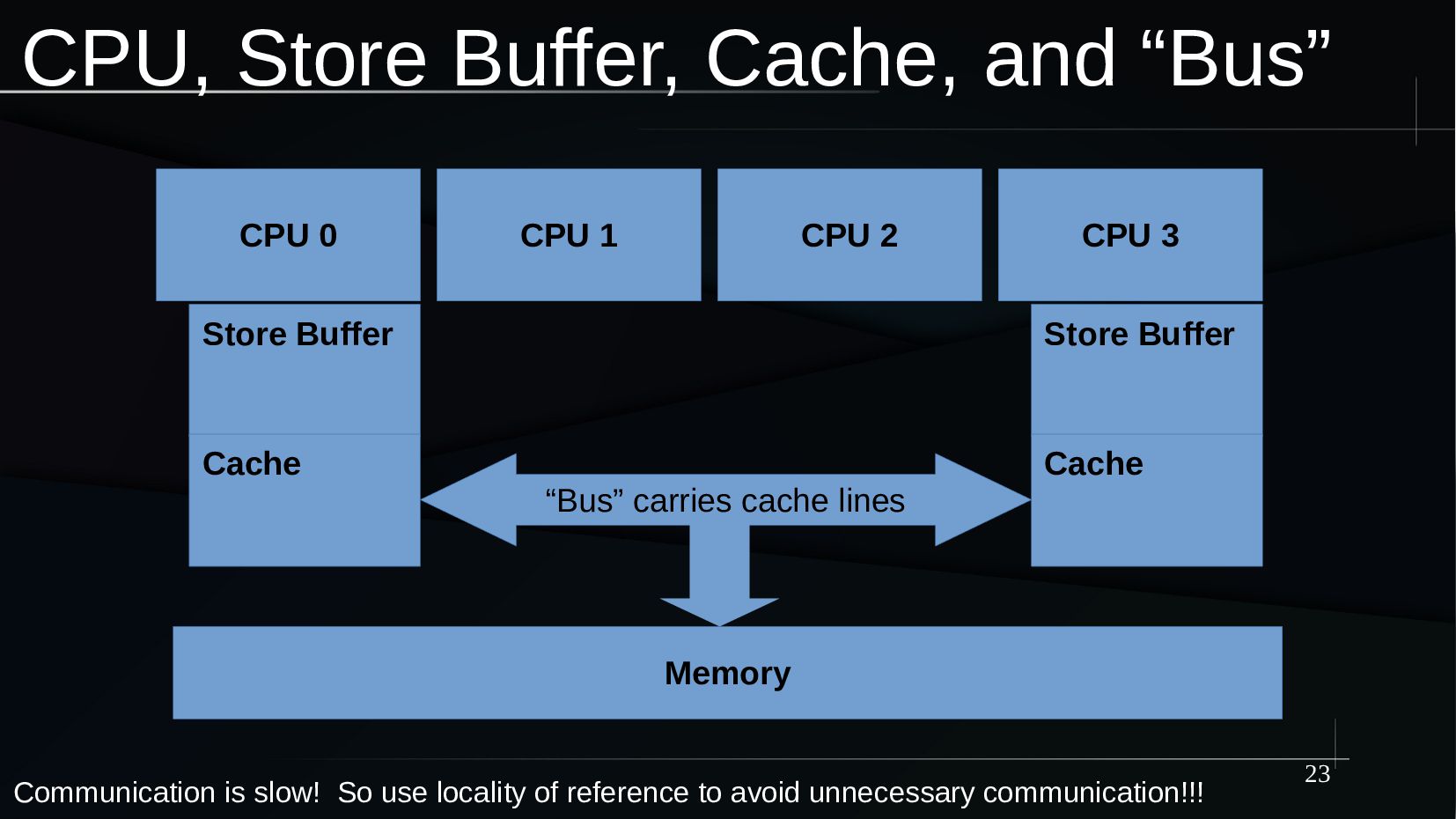{kind=link}
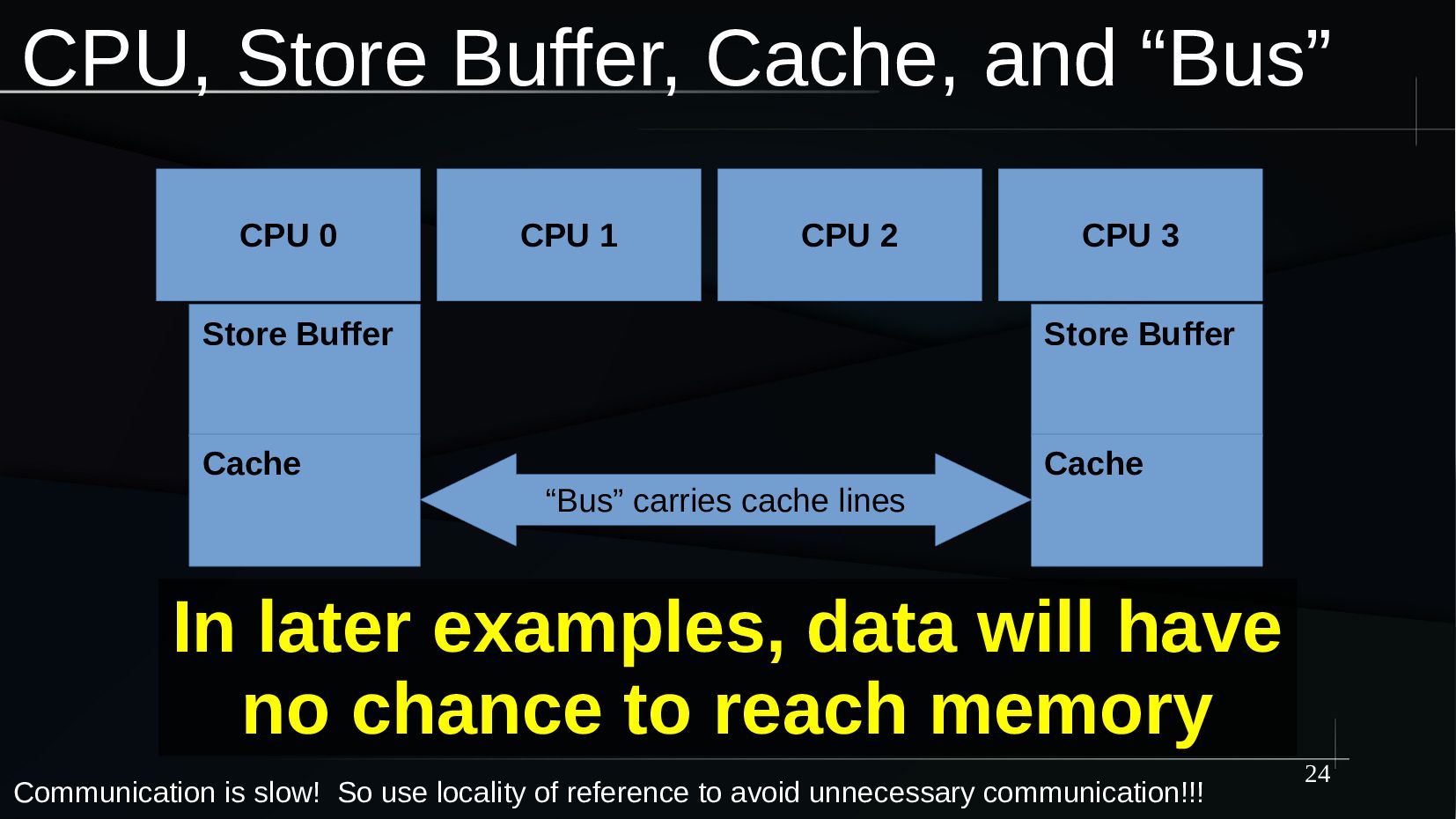{kind=link}
{kind=link}
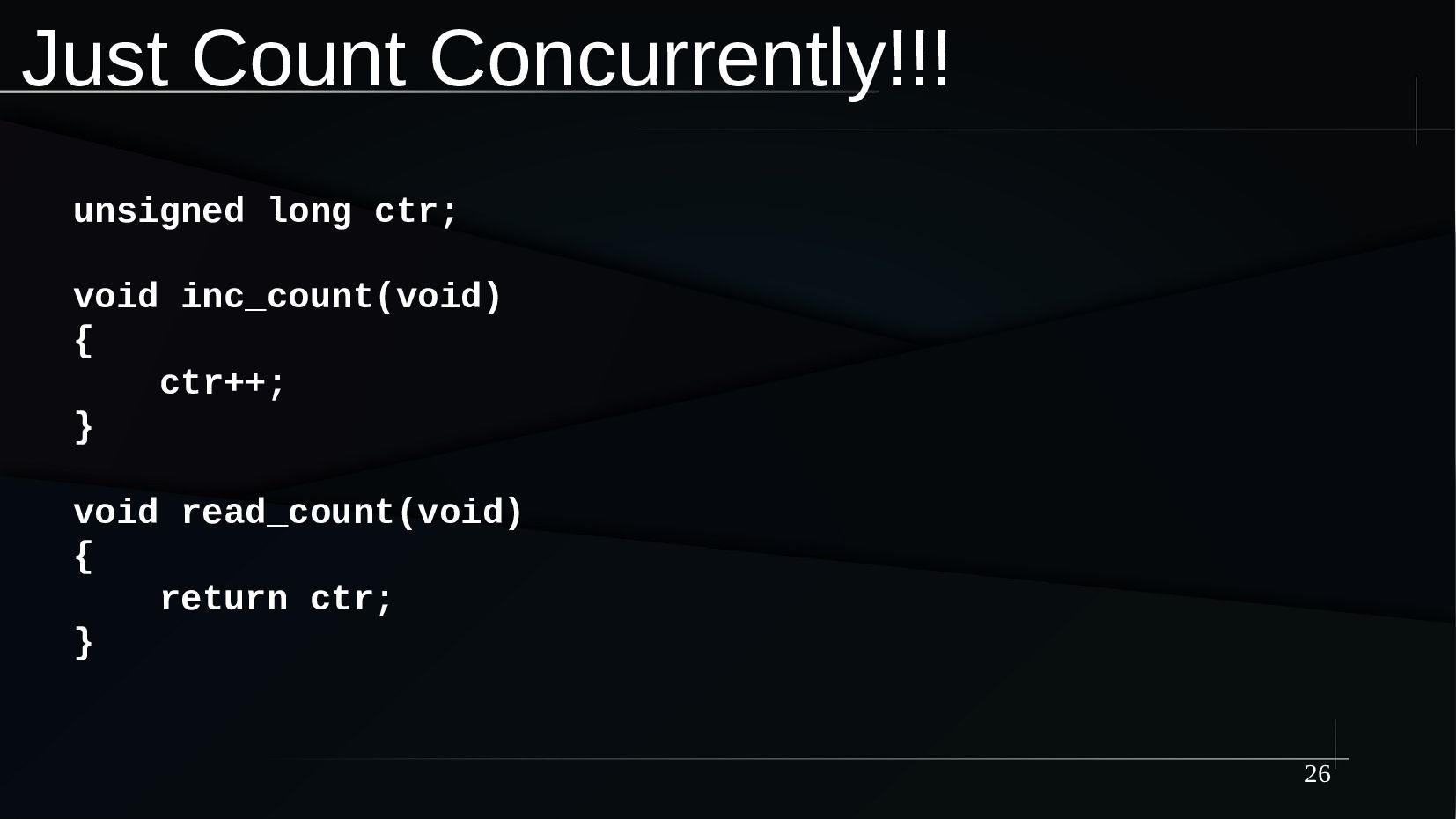{kind=link}
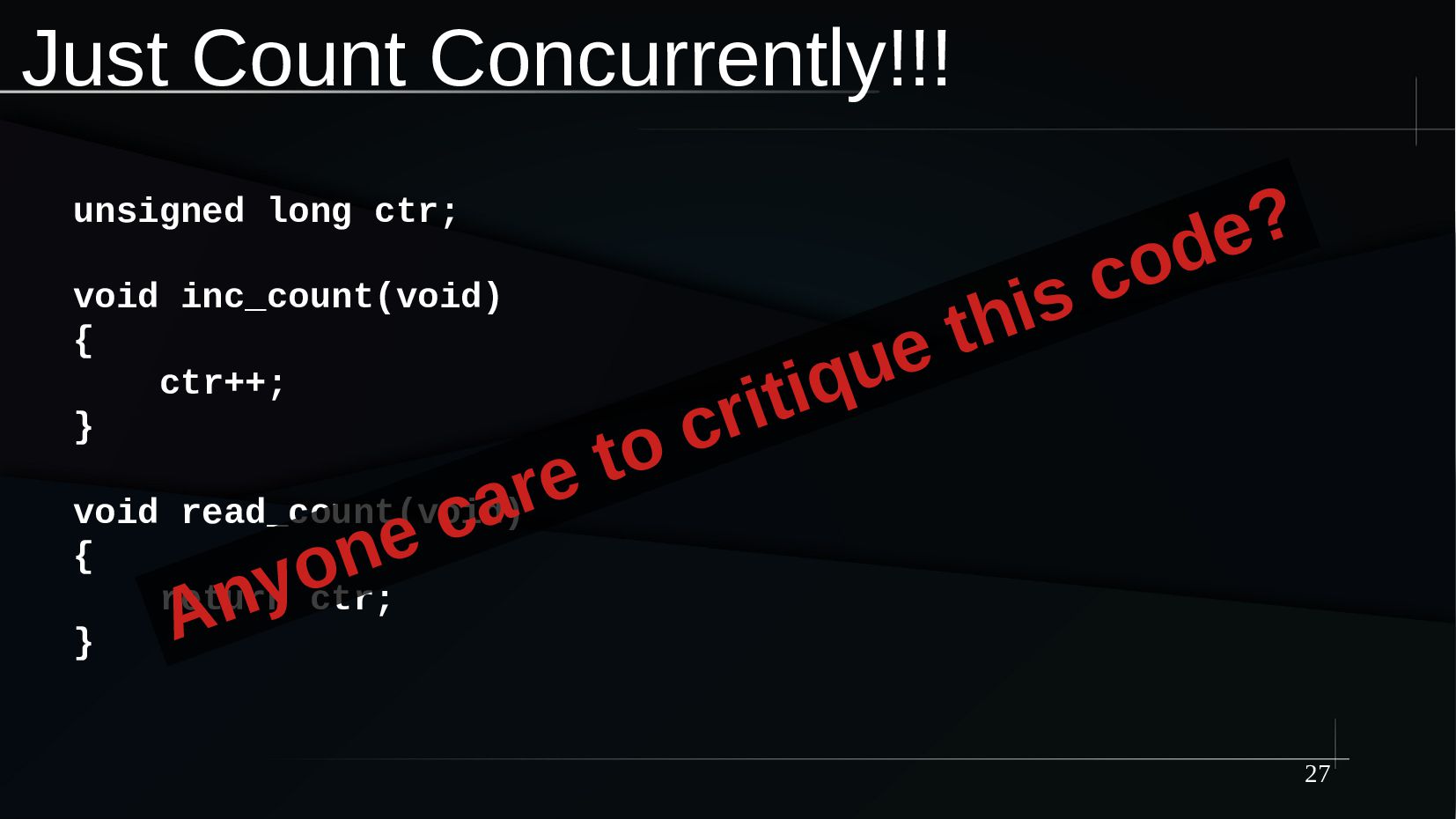{kind=link}
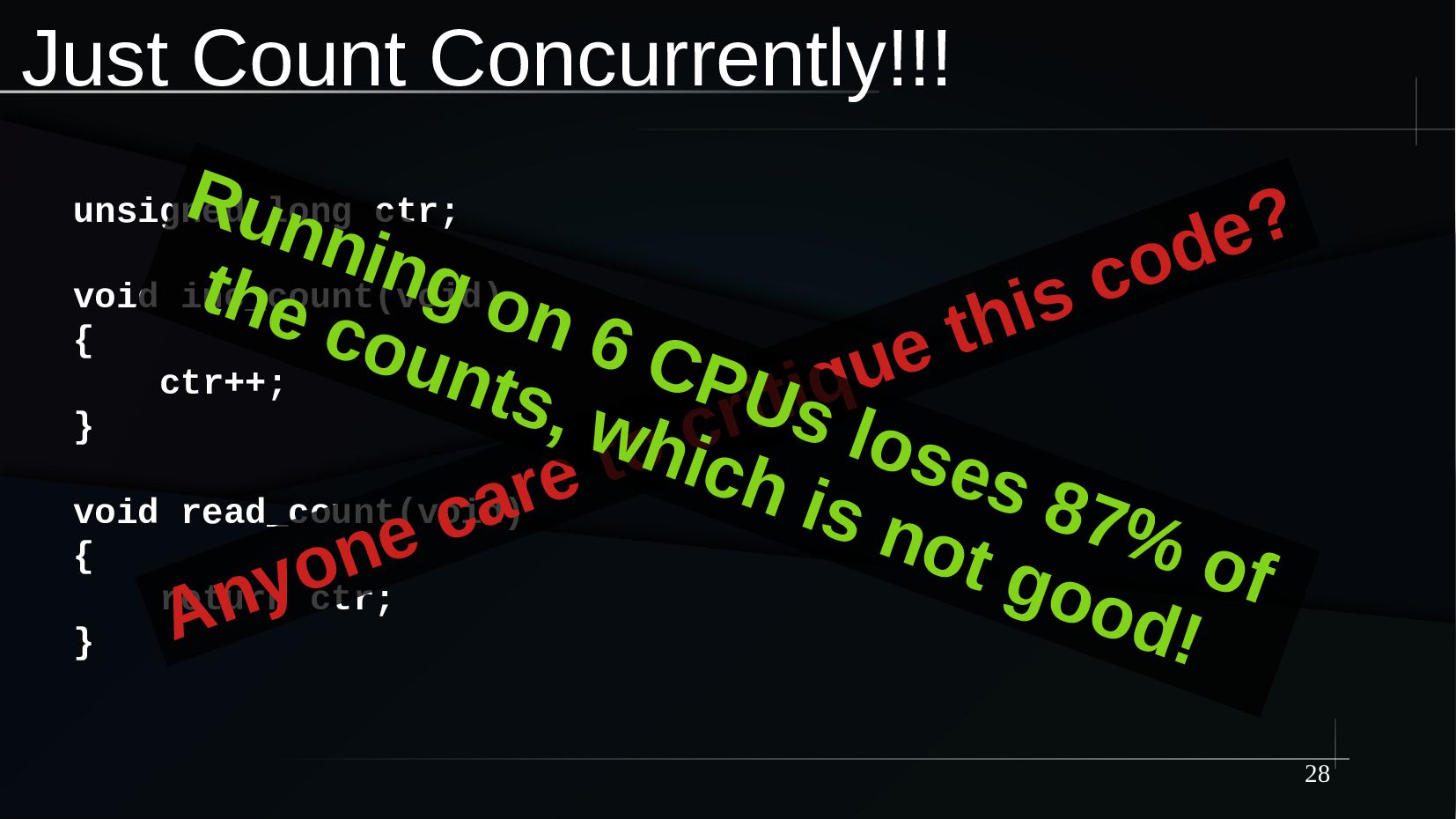{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
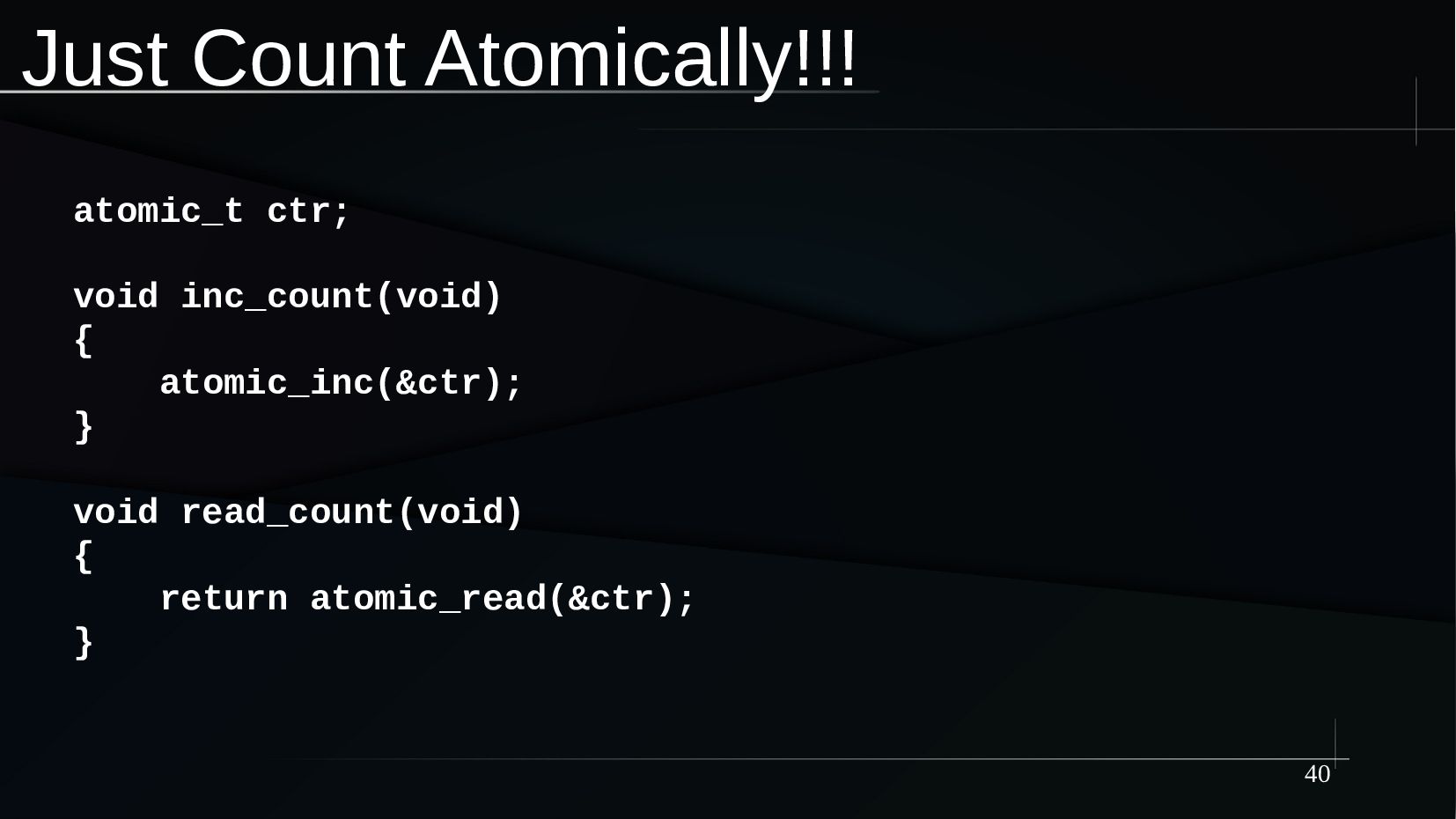{kind=link}
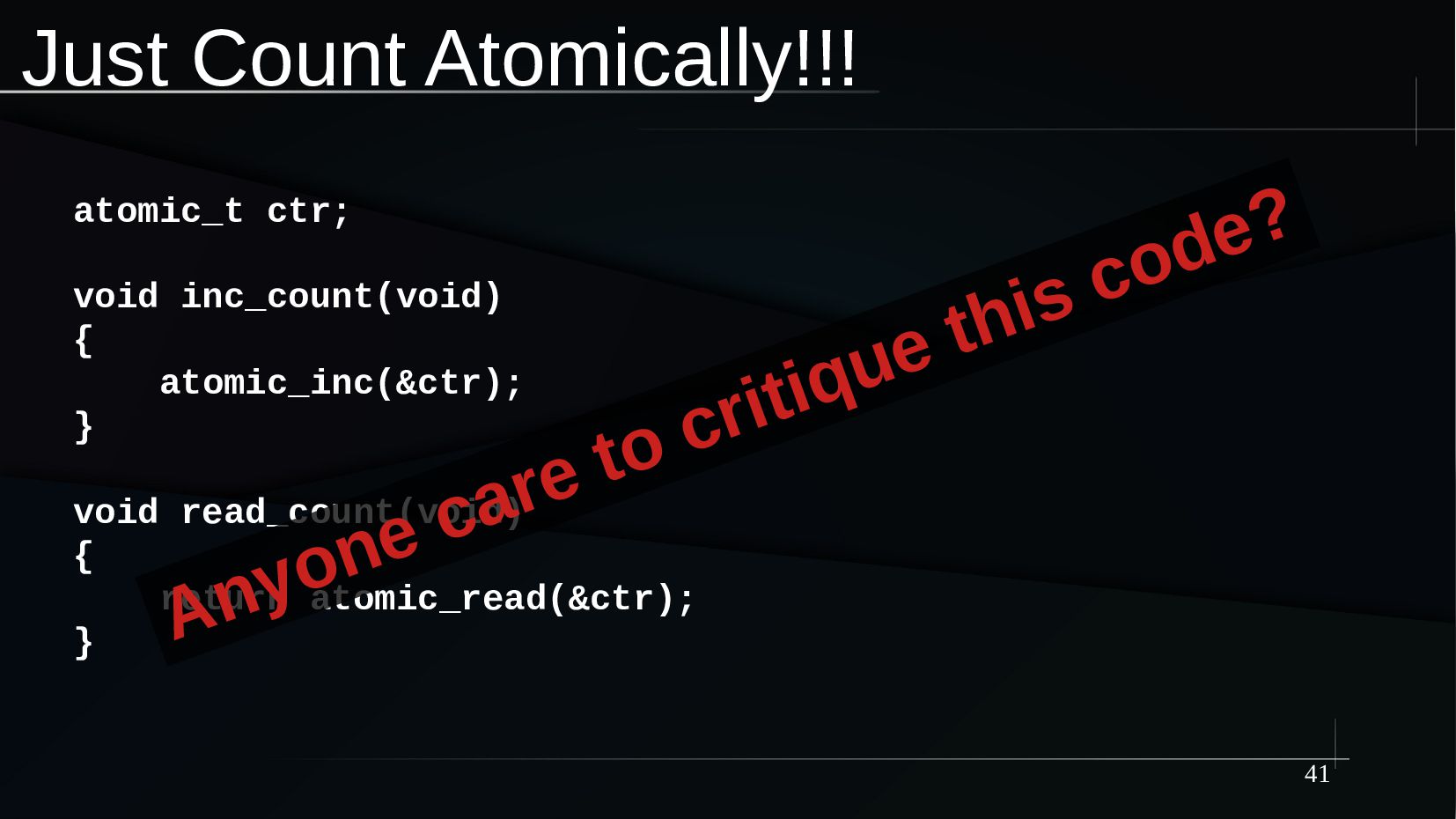{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
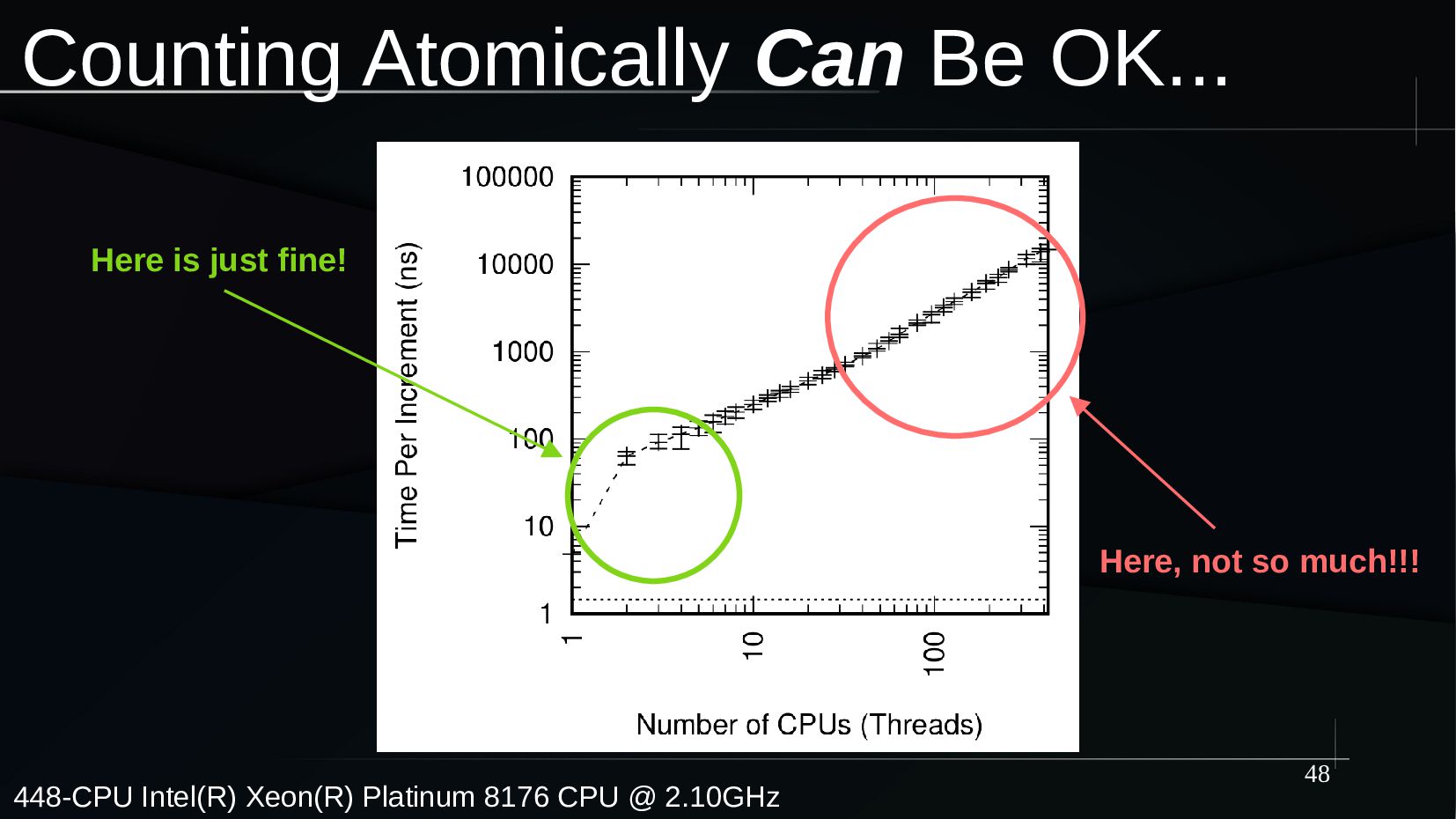{kind=link}
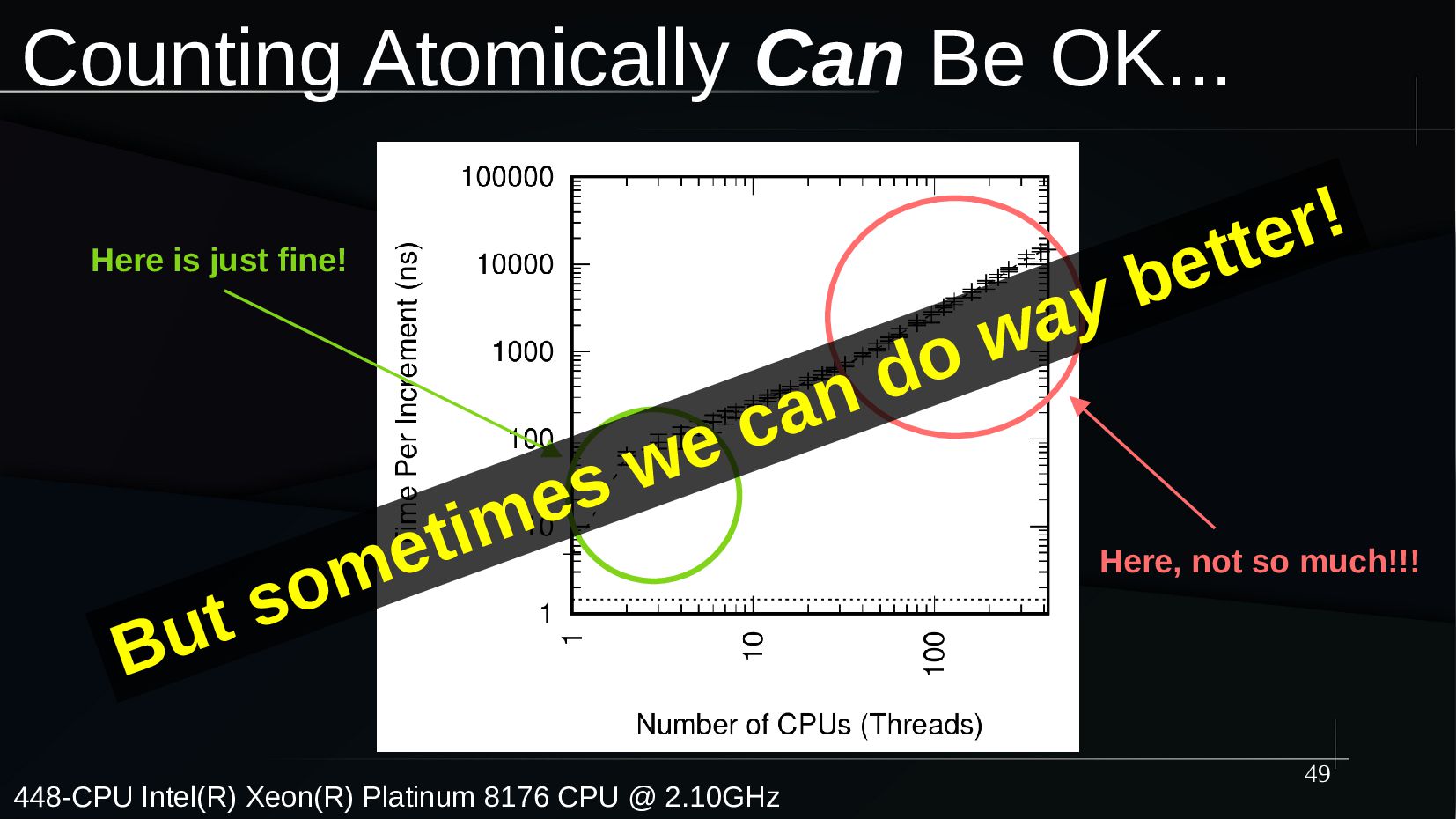{kind=link}
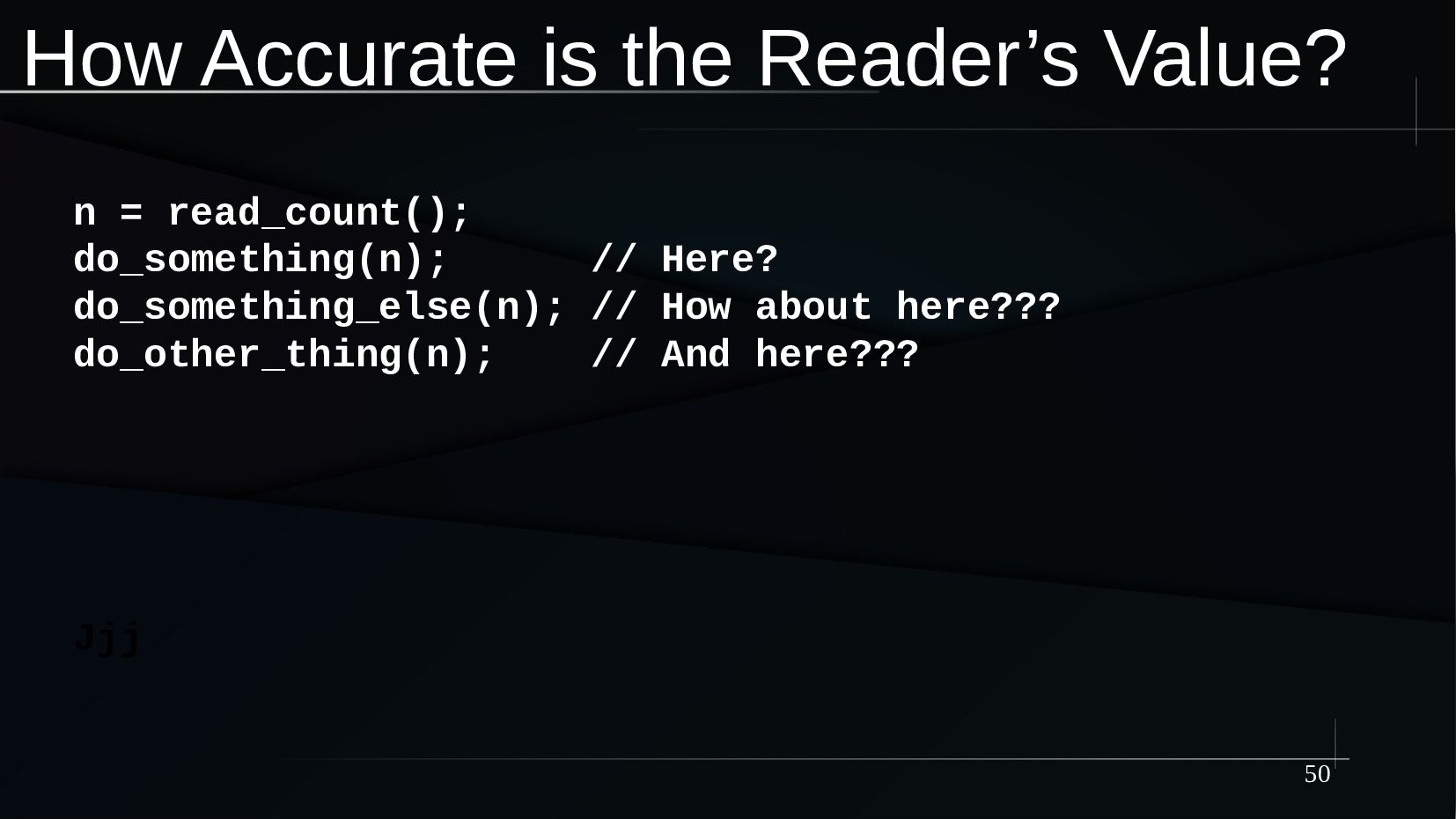{kind=link}
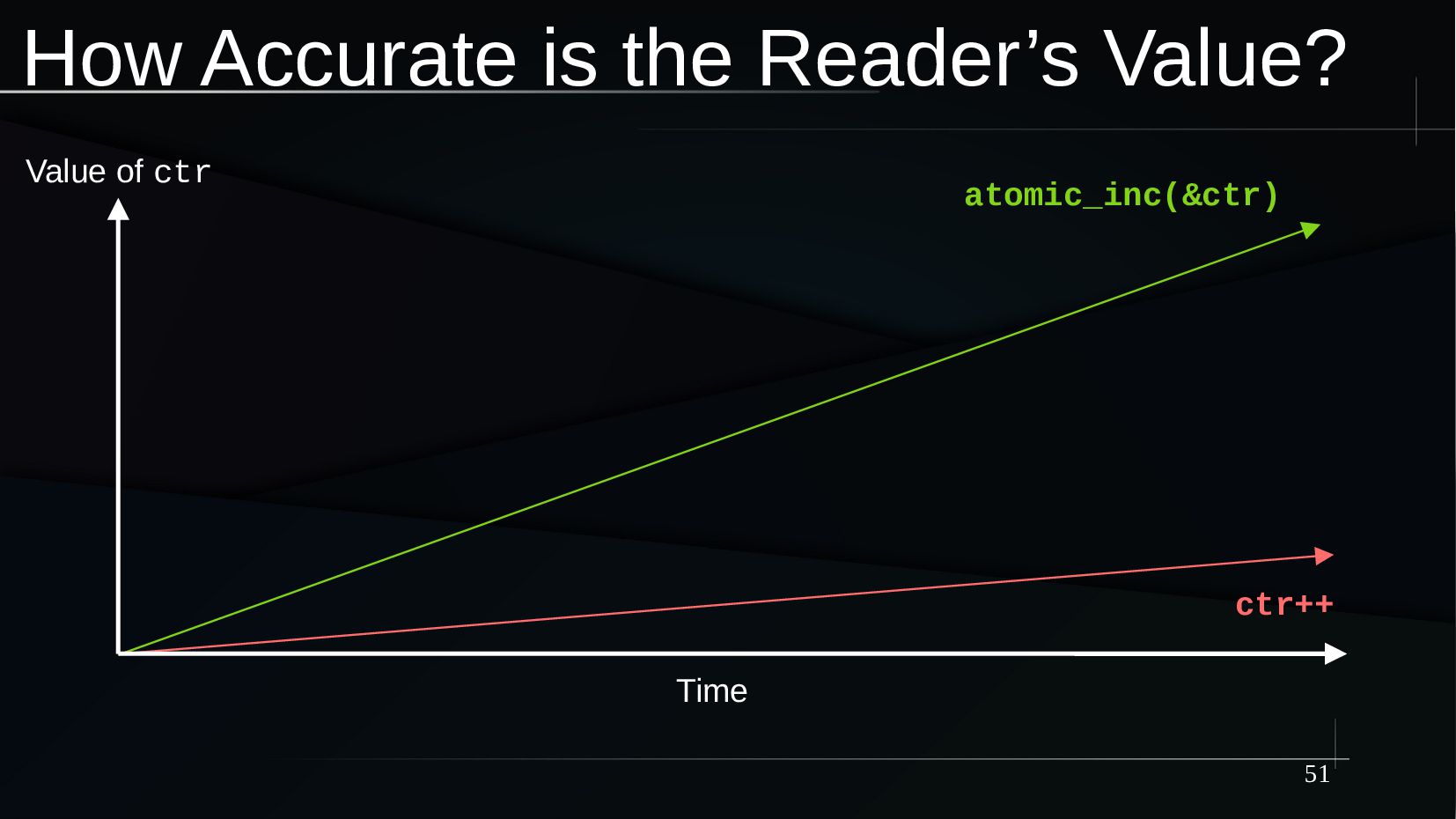{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
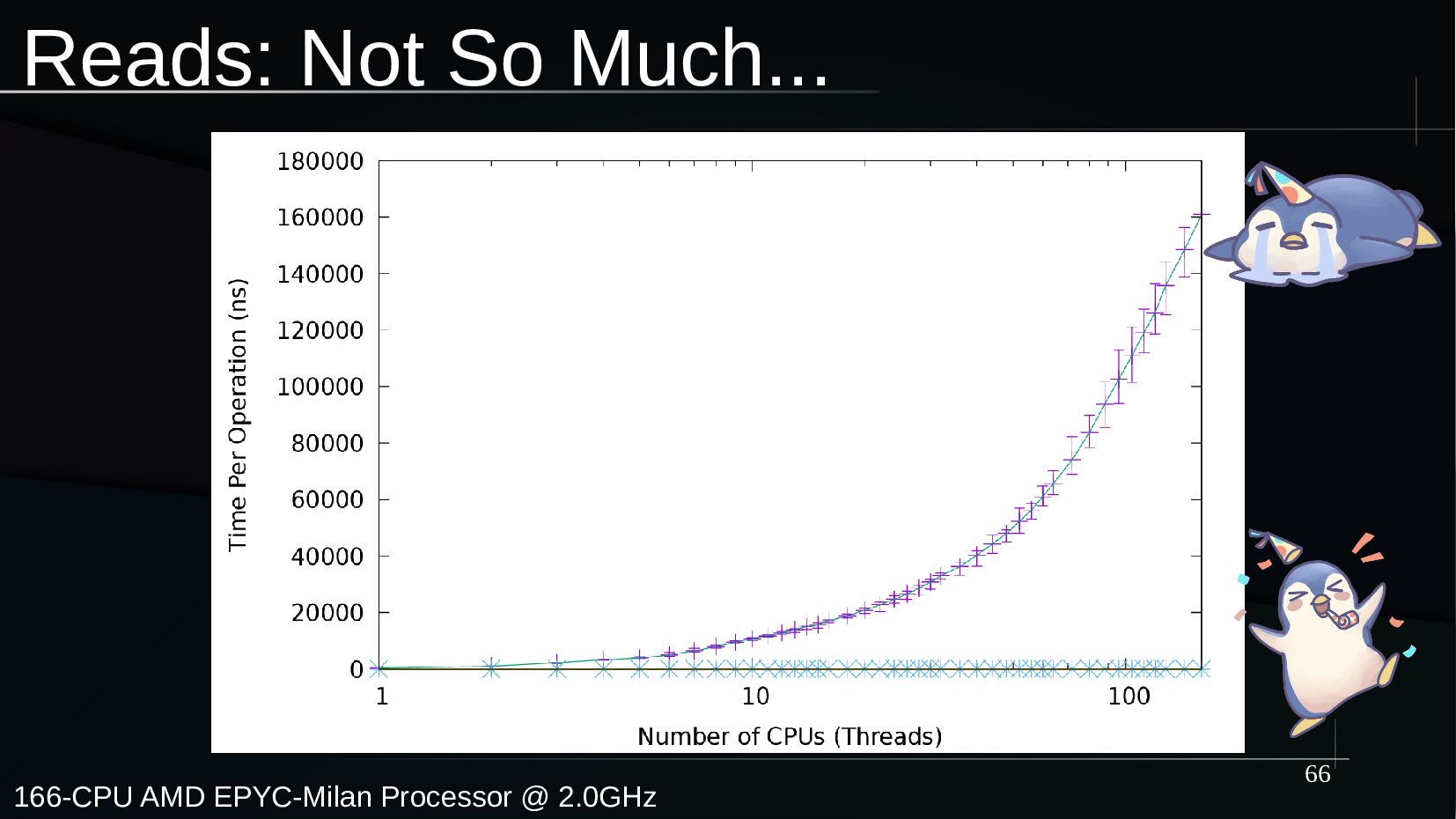
{kind=link}
{kind=link}
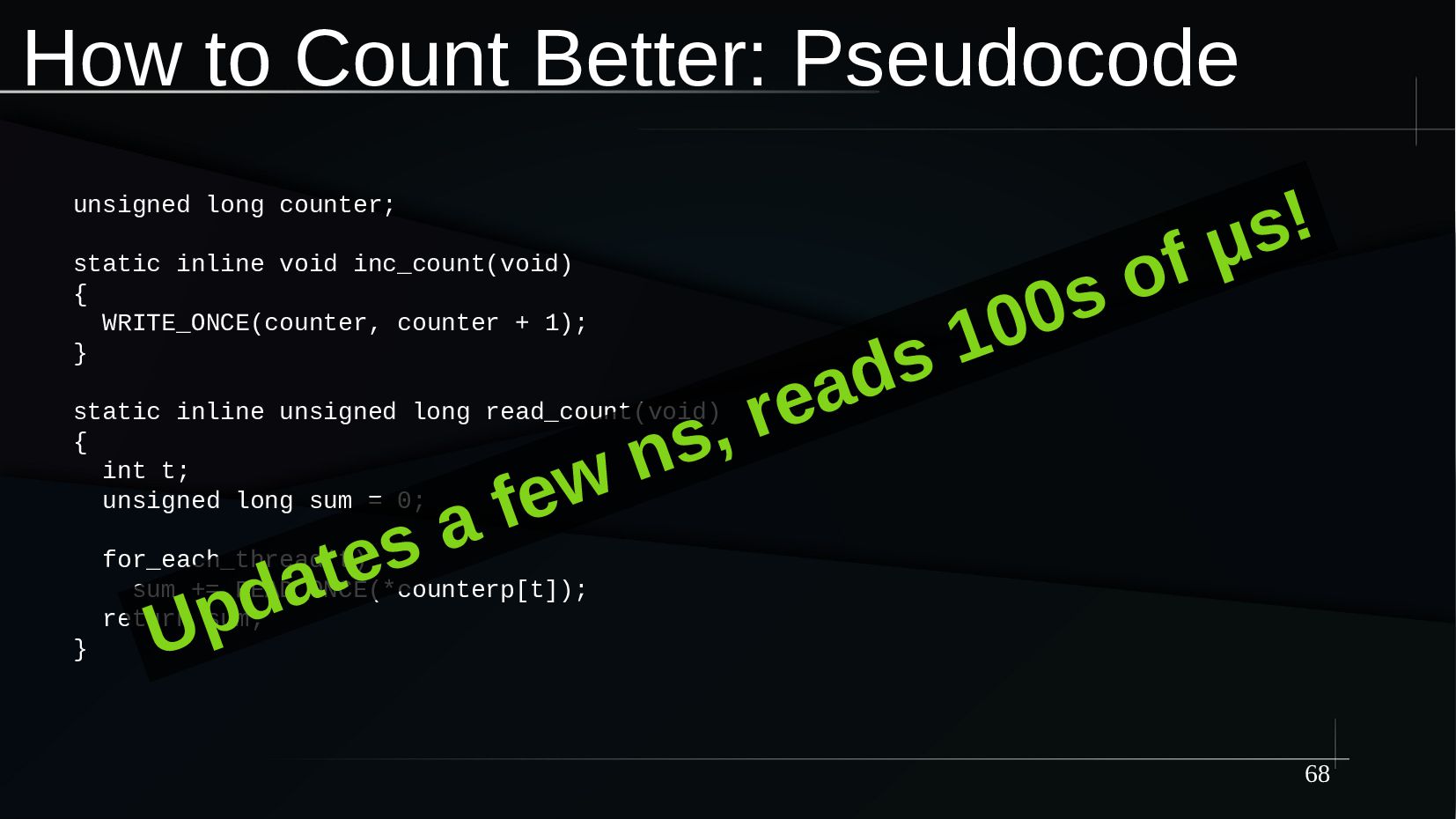
{kind=link}
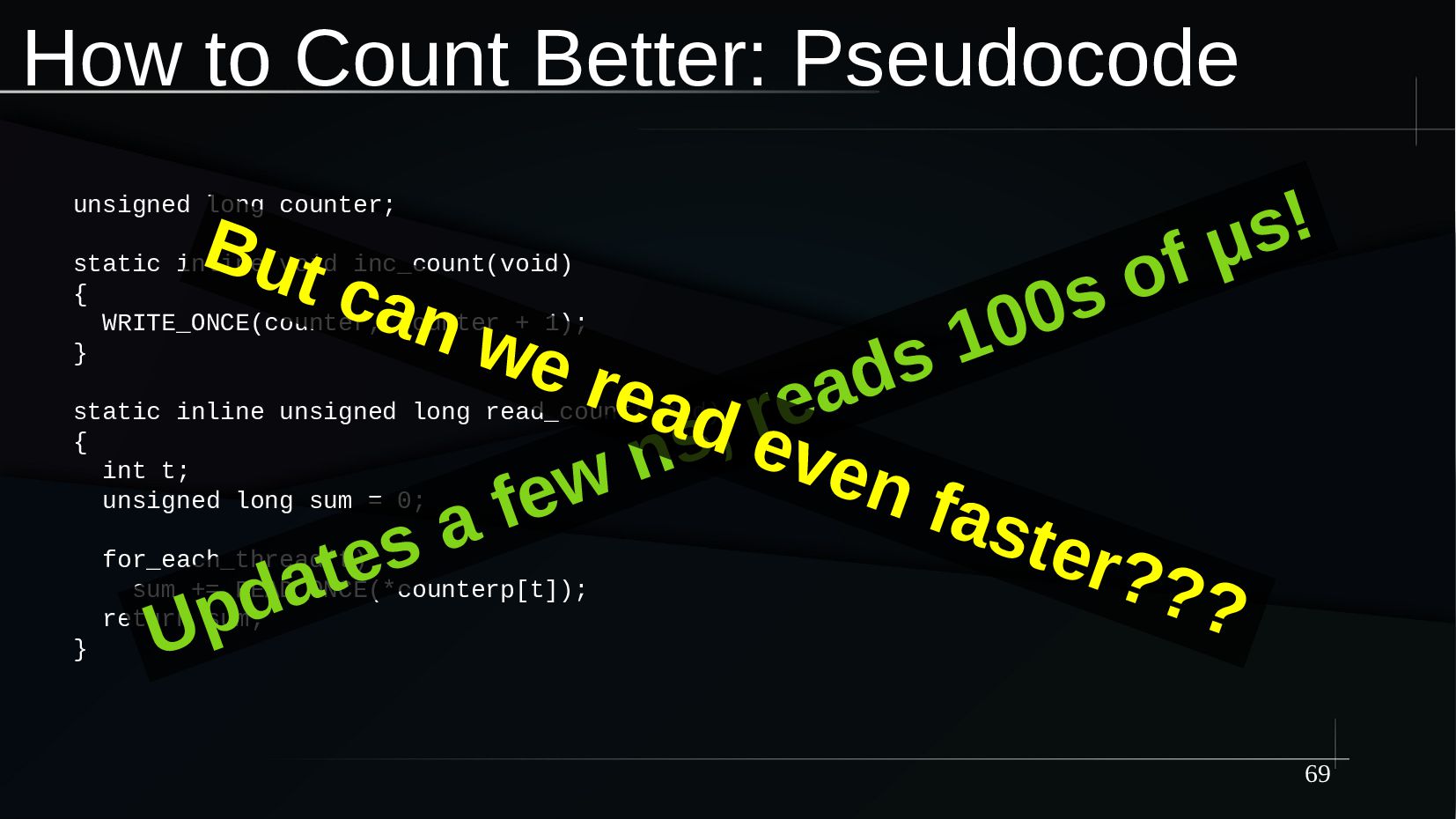
{kind=link}
{kind=link}
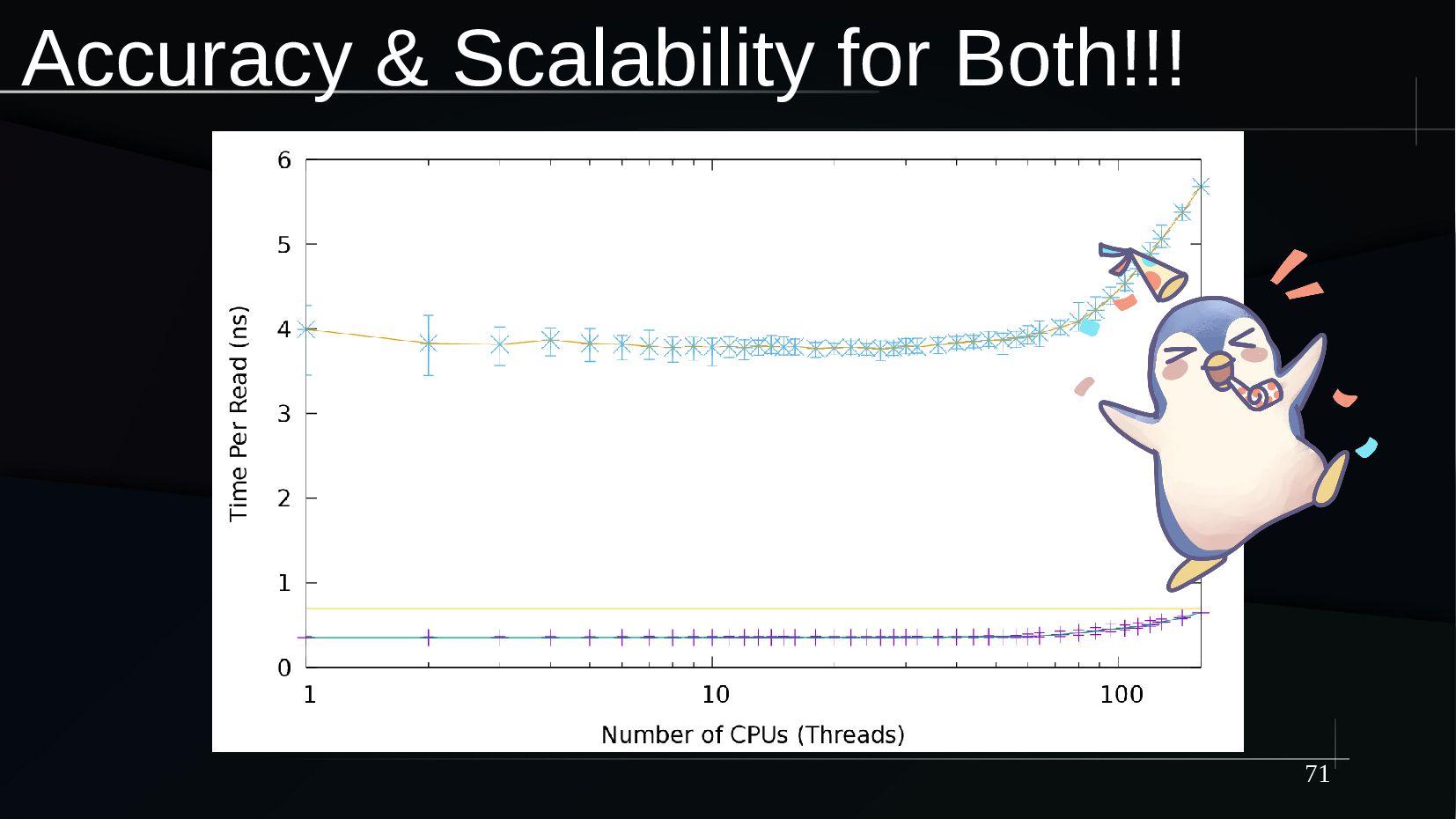
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![85 SRCU Counts of Readers (Case 3/3) lock[0]:0 lock[1]:0 unlock[0]:0](https://files.speakerdeck.com/presentations/099b86cc047942baaeccf781a8cd1a04/slide_84.jpg){kind=link}
![86 SRCU Counts of Readers (Case 3/3) lock[0]:0 lock[1]:0 unlock[0]:0](https://files.speakerdeck.com/presentations/099b86cc047942baaeccf781a8cd1a04/slide_85.jpg){kind=link}
![87 SRCU Counts of Readers (Case 3/3) lock[0]:0 lock[1]:0 unlock[0]:0](https://files.speakerdeck.com/presentations/099b86cc047942baaeccf781a8cd1a04/slide_86.jpg){kind=link}
![88 SRCU Counts of Readers (Case 3/3) lock[0]:0 lock[1]:0 unlock[0]:0](https://files.speakerdeck.com/presentations/099b86cc047942baaeccf781a8cd1a04/slide_87.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
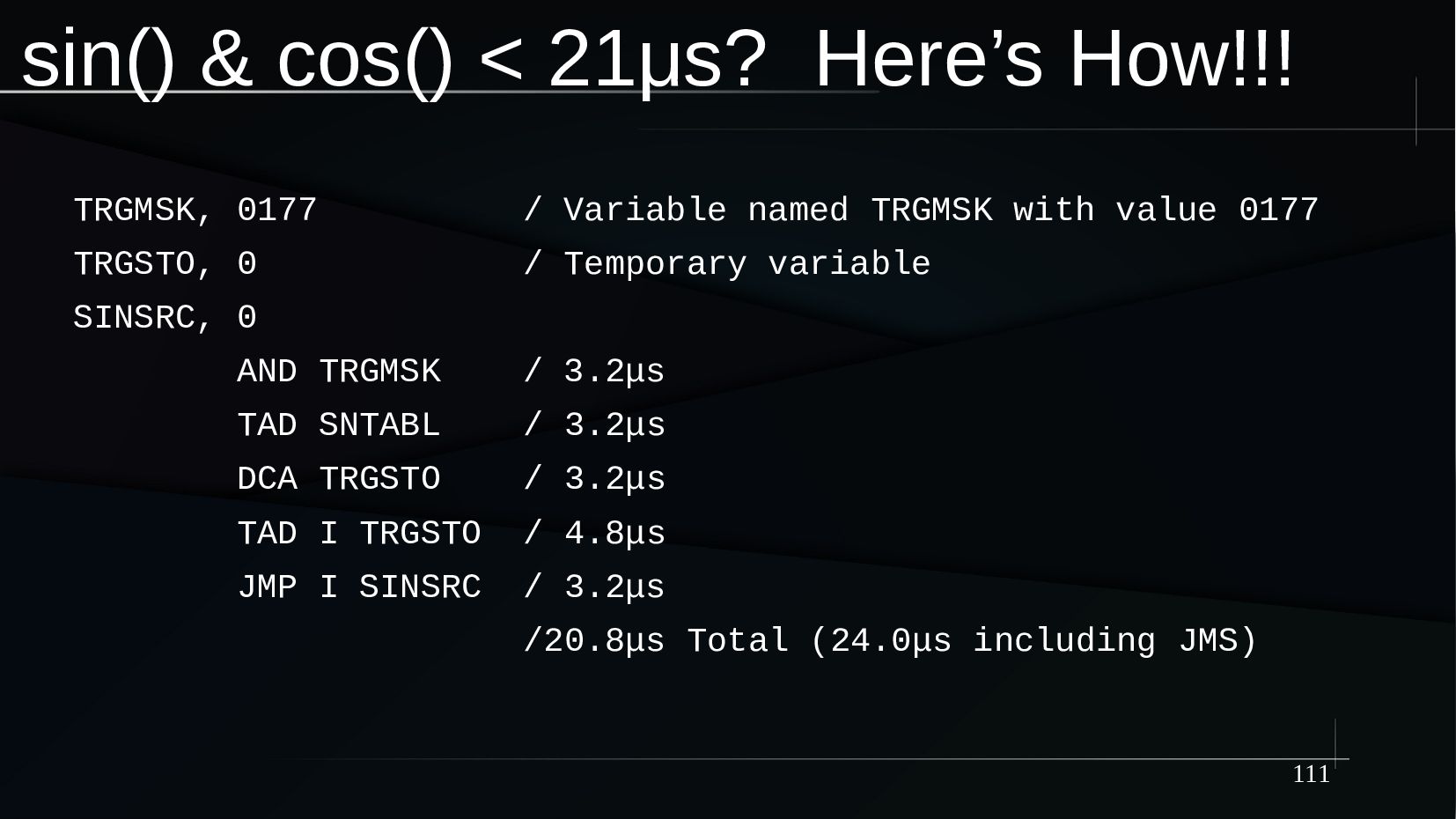{kind=link}
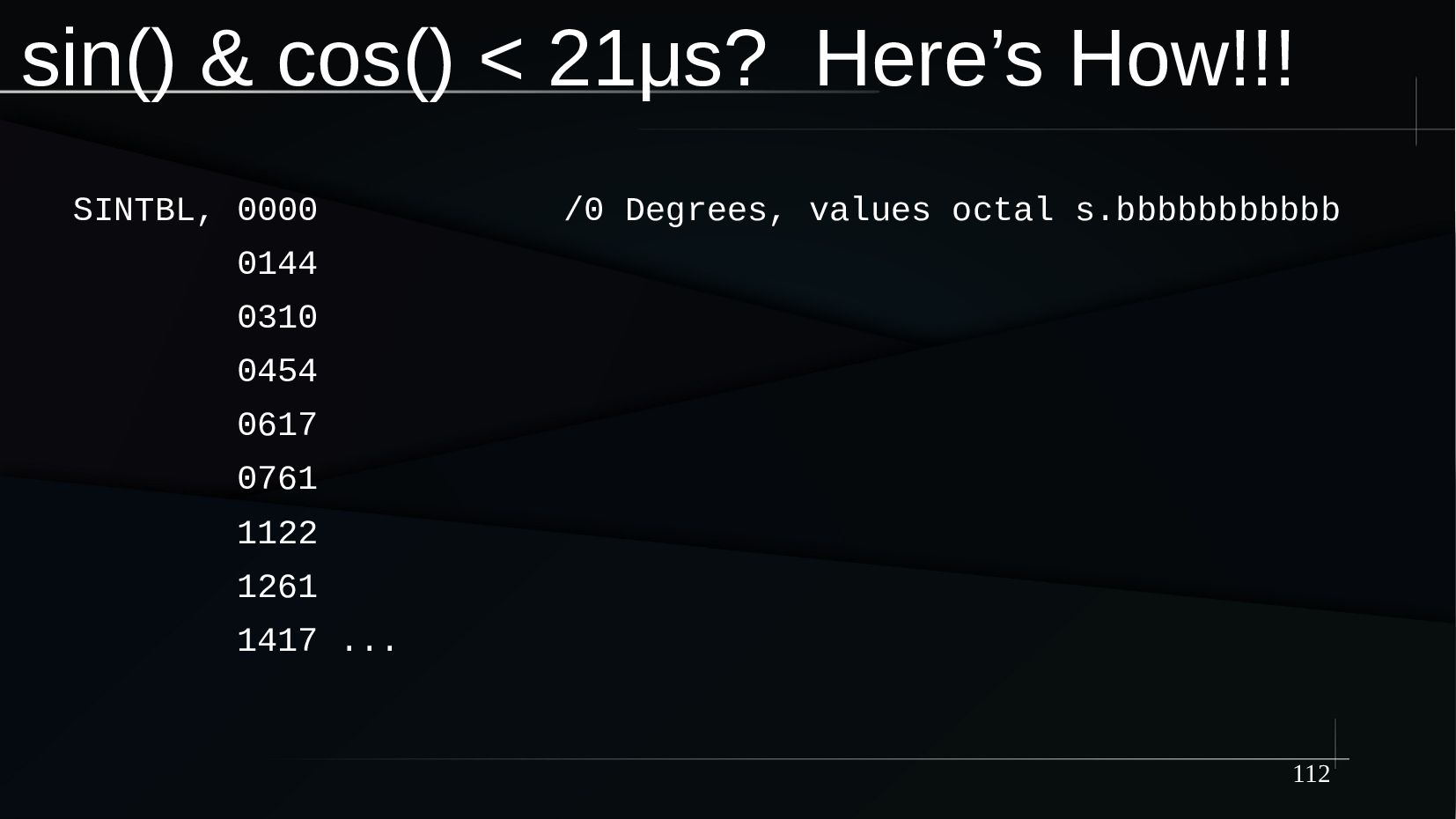{kind=link}