Scheduling with superpowers: Using sched_ext to get big perf gains
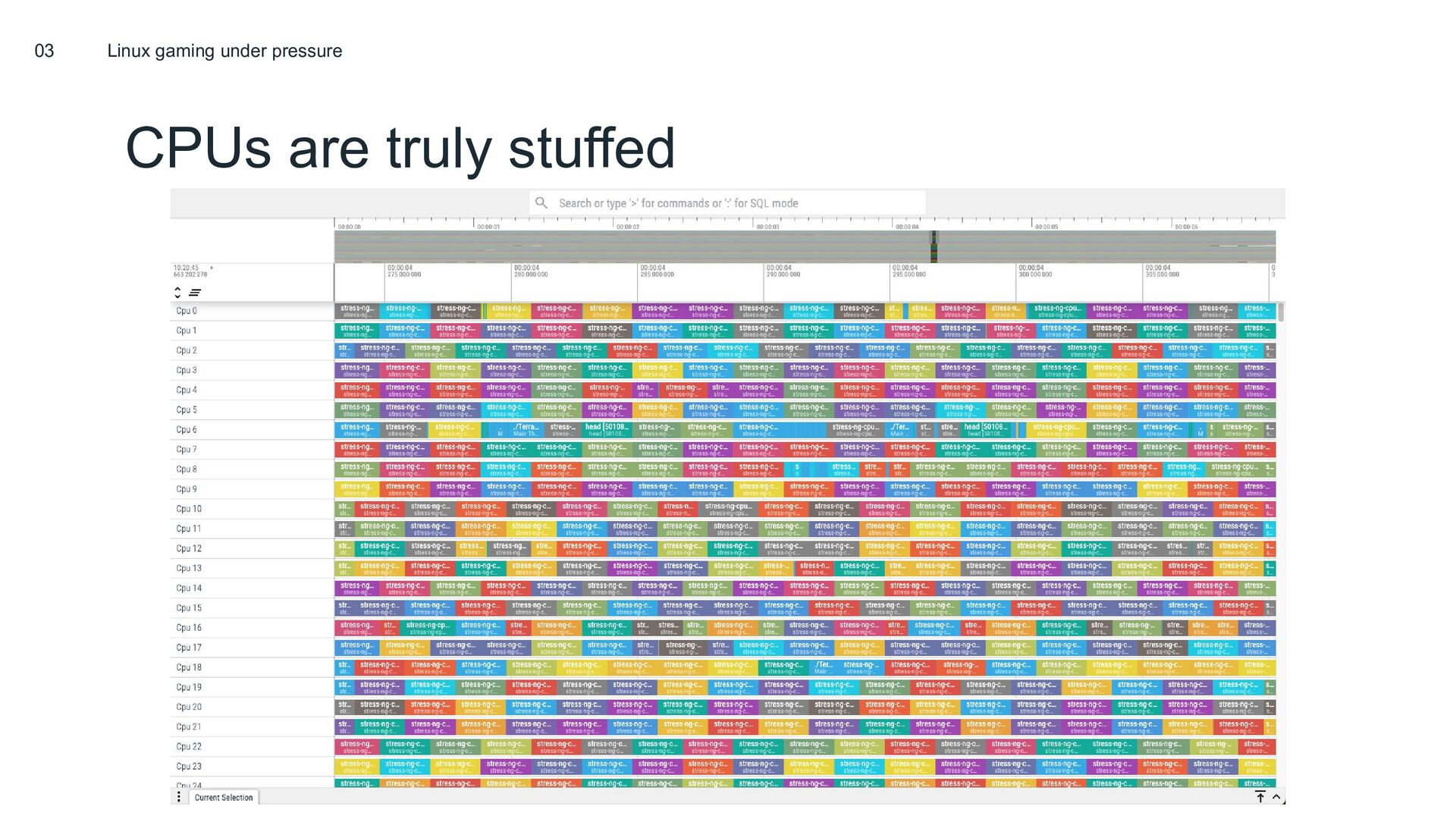
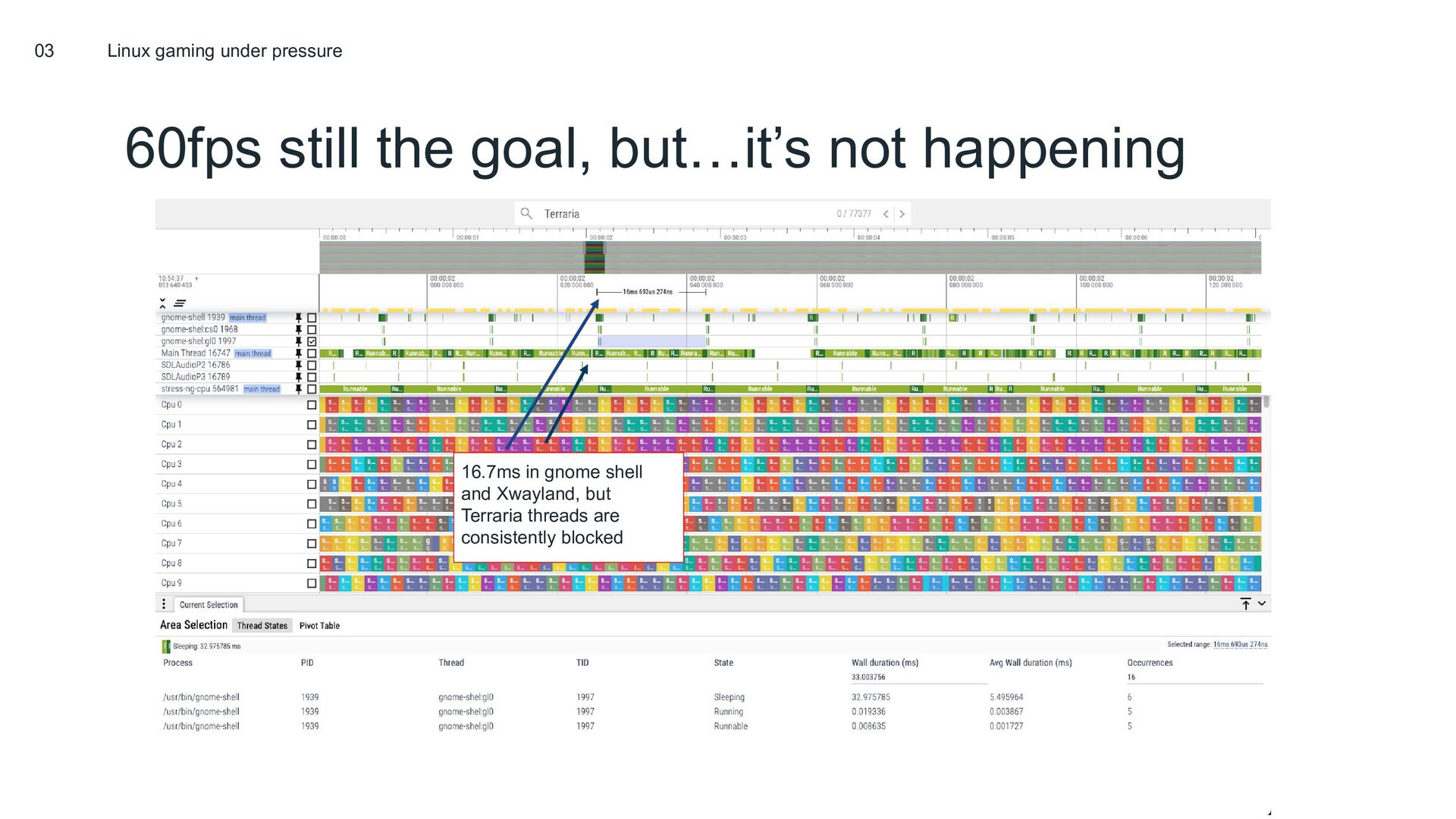
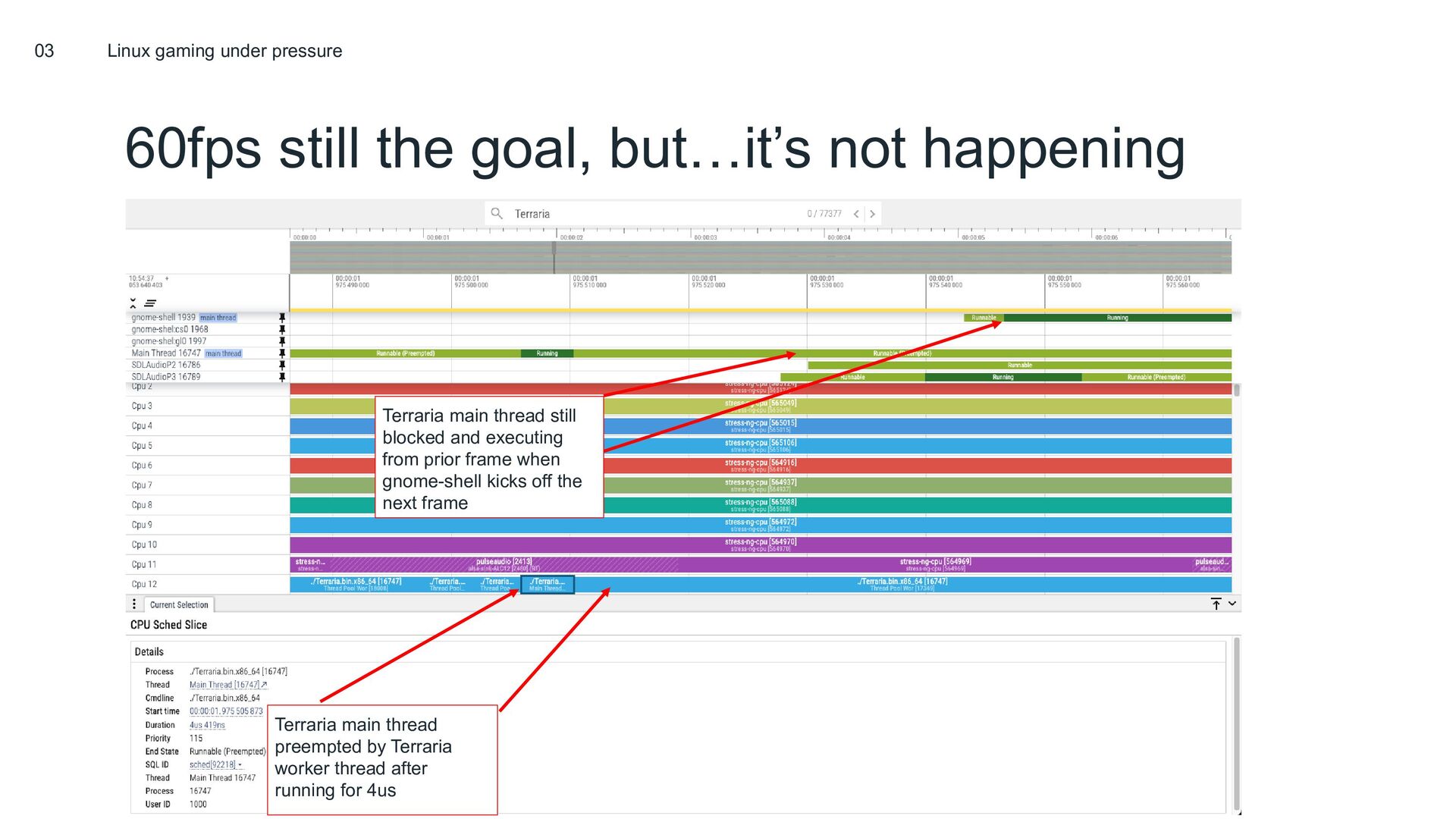
Last year, we presented on sched_ext: a new pluggable CPU scheduling framework that enables writing and safely running host-wide kernel CPU scheduling policies in BPF. Since then, the project has grown significantly; both in terms of its technical capabilities, as well as in the number of contributors and users of the project. sched_ext now runs at massive scale at Meta, and will also soon run as the default scheduler on Steam Deck devices (the year of Linux gaming is upon us at last)!
In this talk we’ll take a look at some of the cutting edge sched_ext schedulers, and learn about why they enable such great performance on certain workloads. We’ll also discuss some of the new, powerful features available in sched_ext, such as cpufreq integration, and why they hold so much promise for awesome scheduling features that can fundamentally improve both datacenter and handheld workloads.
David VERNET
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
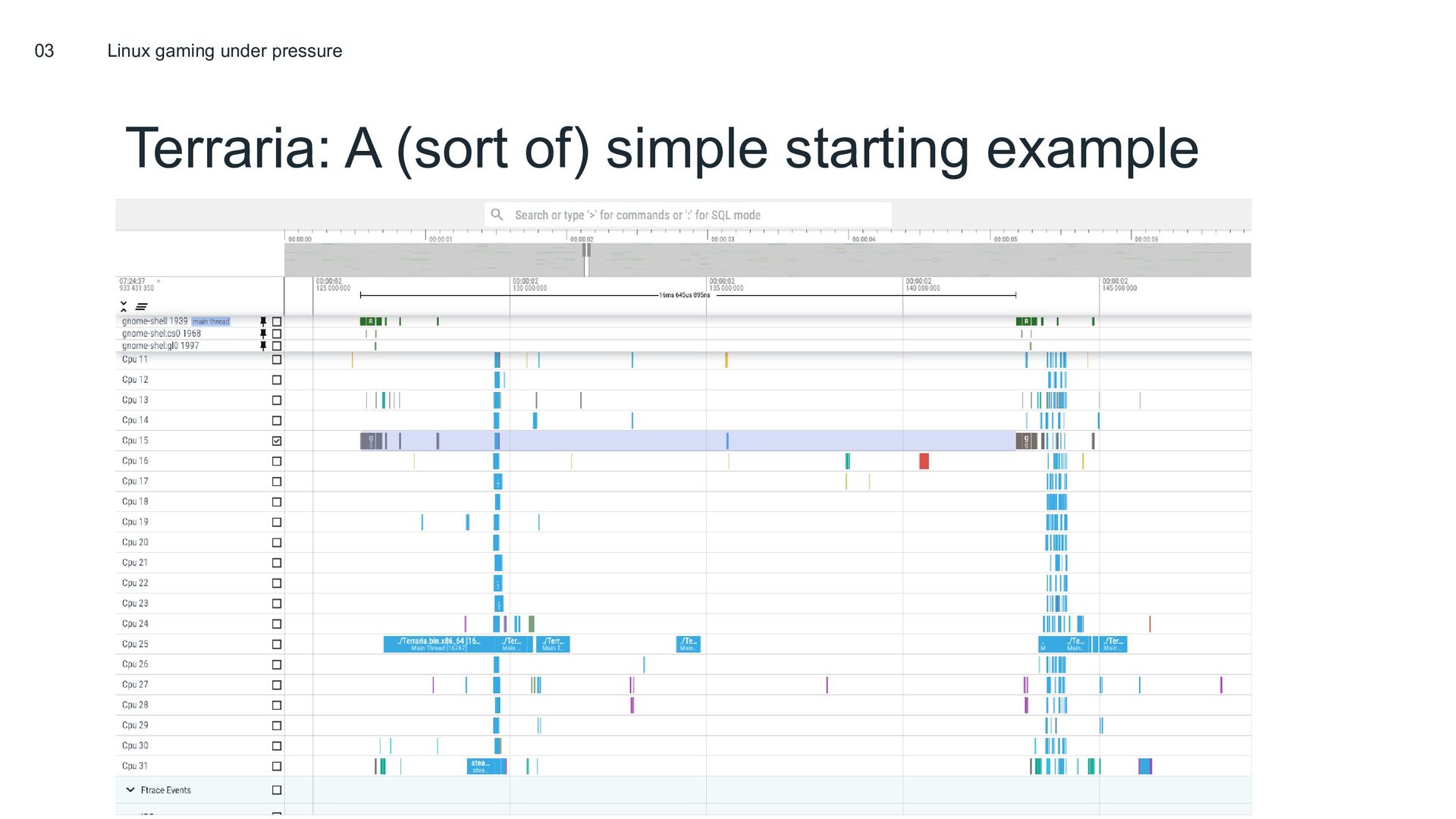{kind=link}
{kind=link}
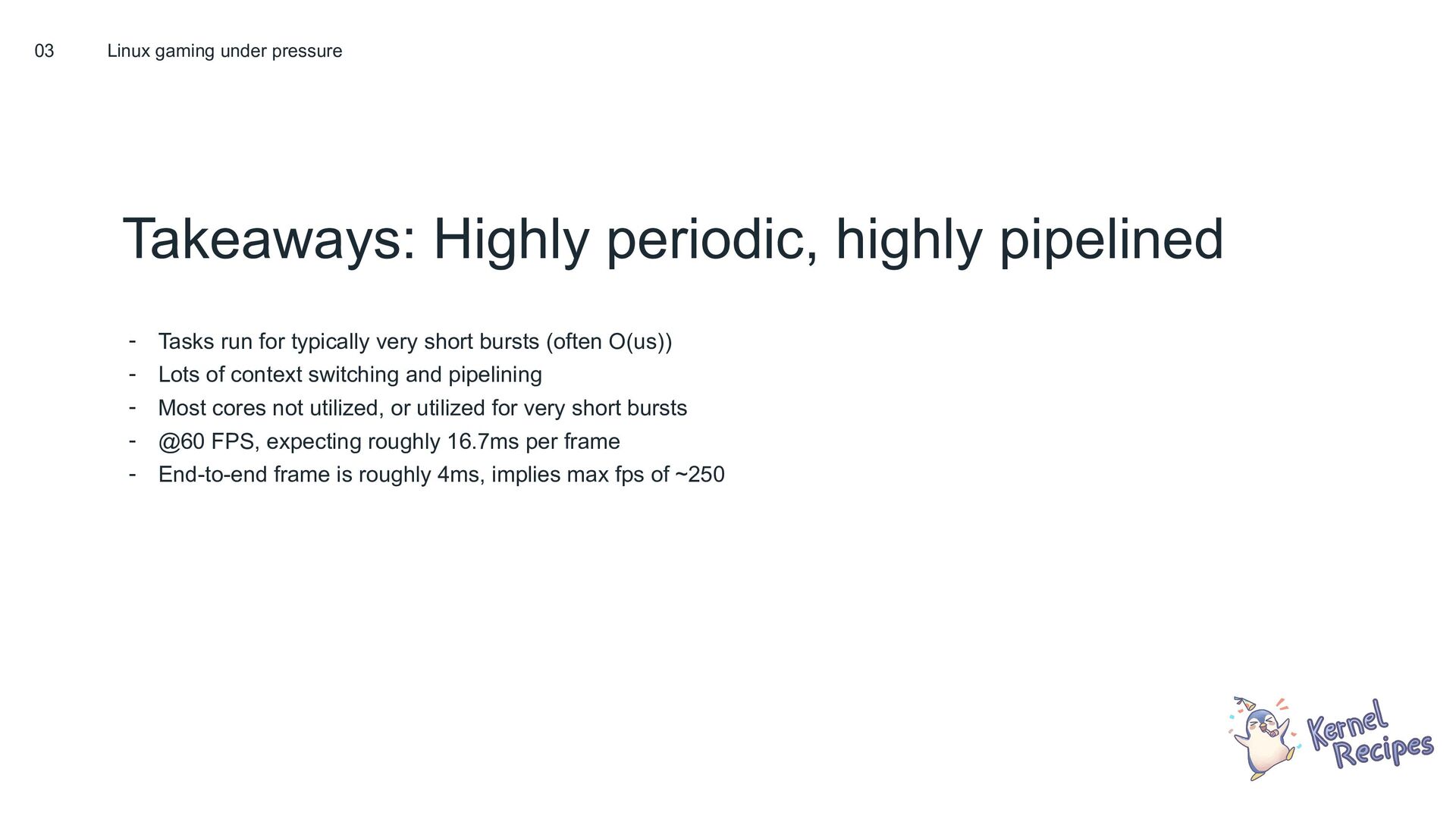{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
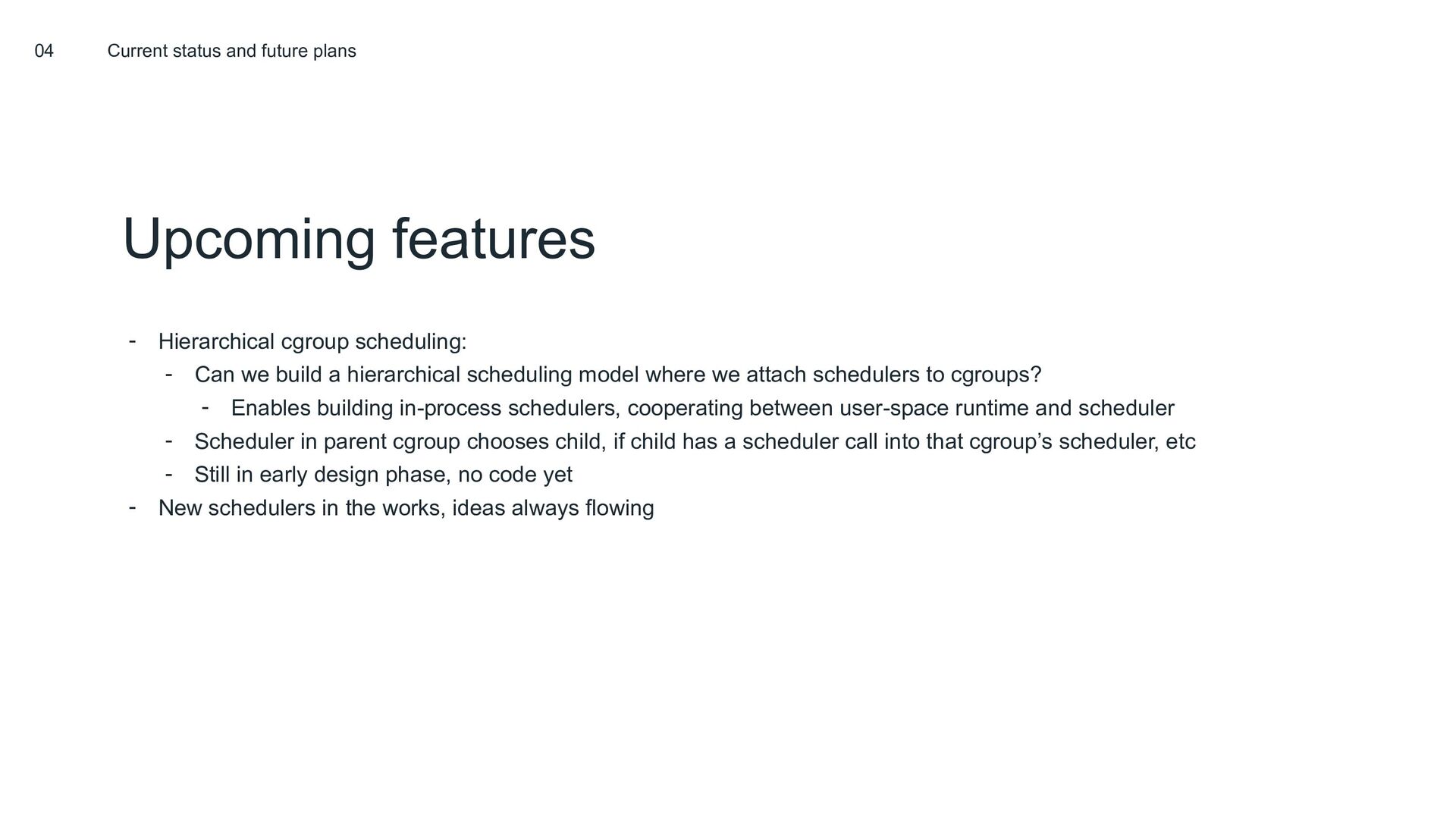{kind=link}
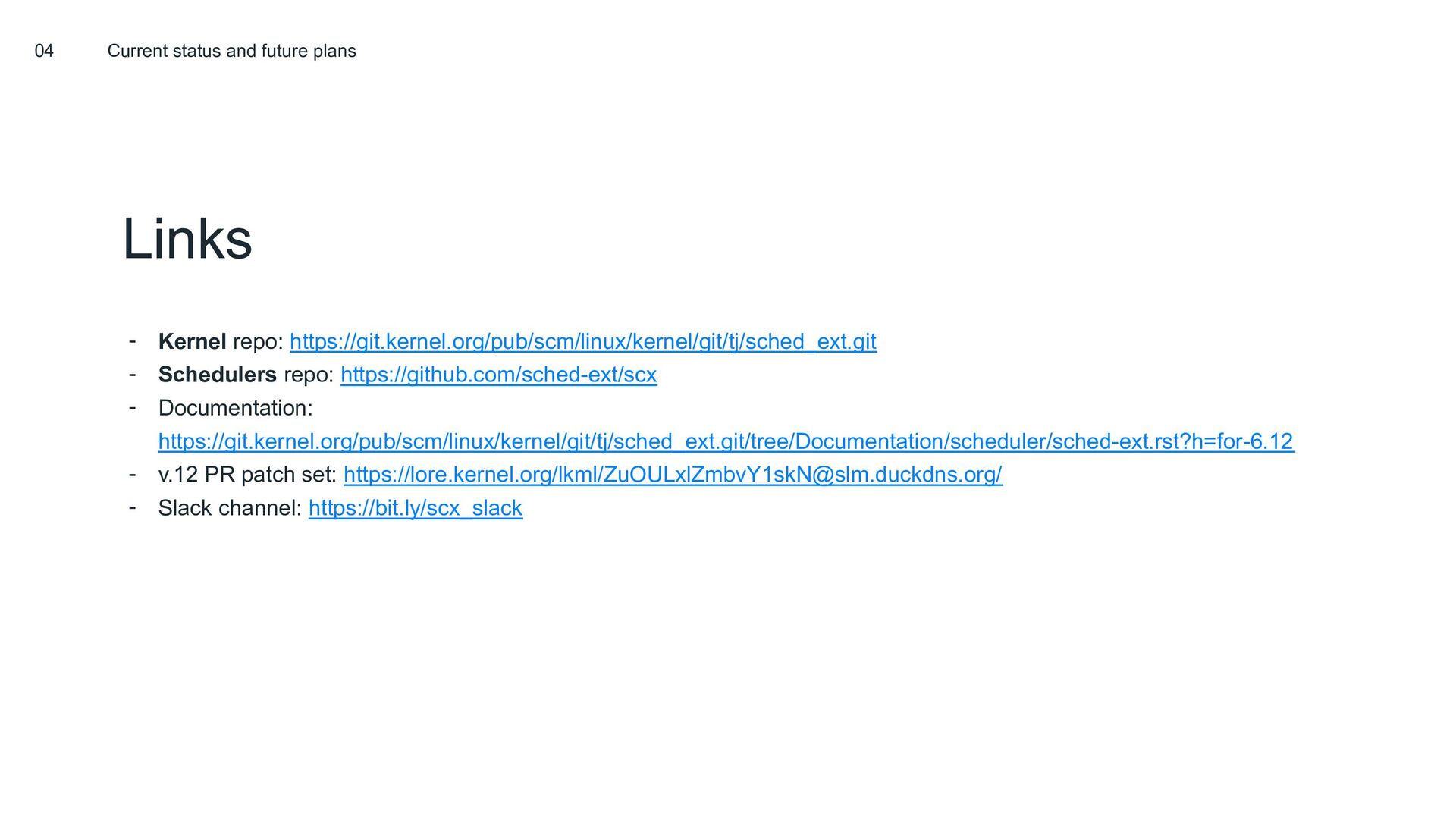{kind=link}
{kind=link}