Building an Analytics Pipeline with Elasticsearch (and Logstash and Kibana)
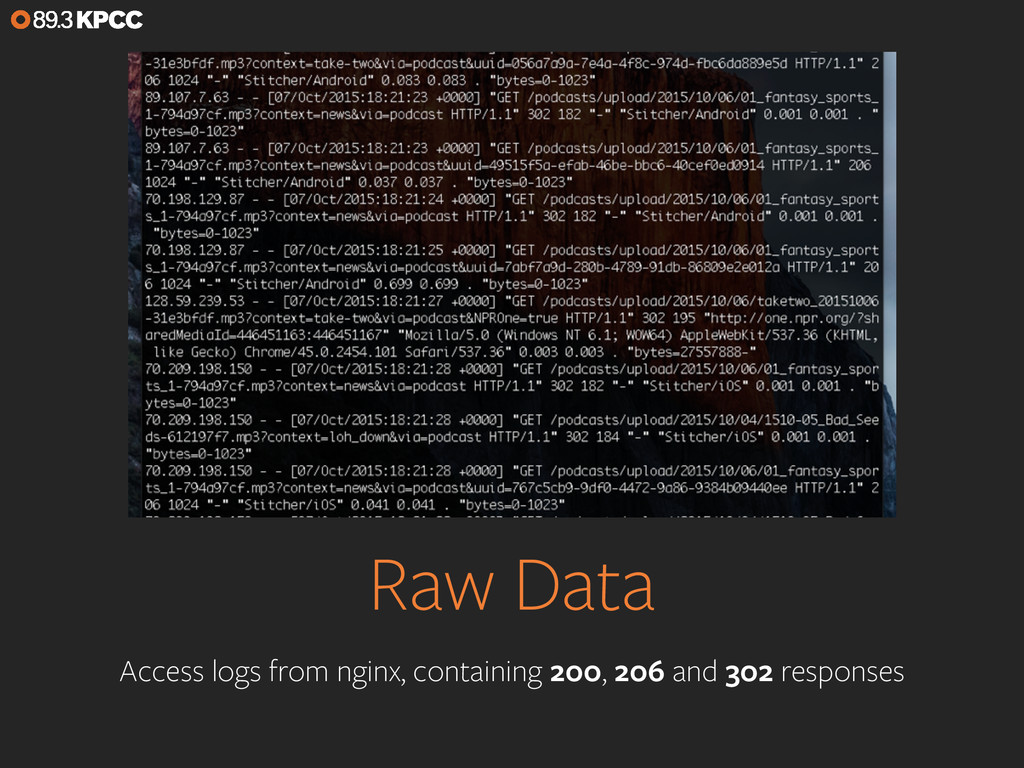
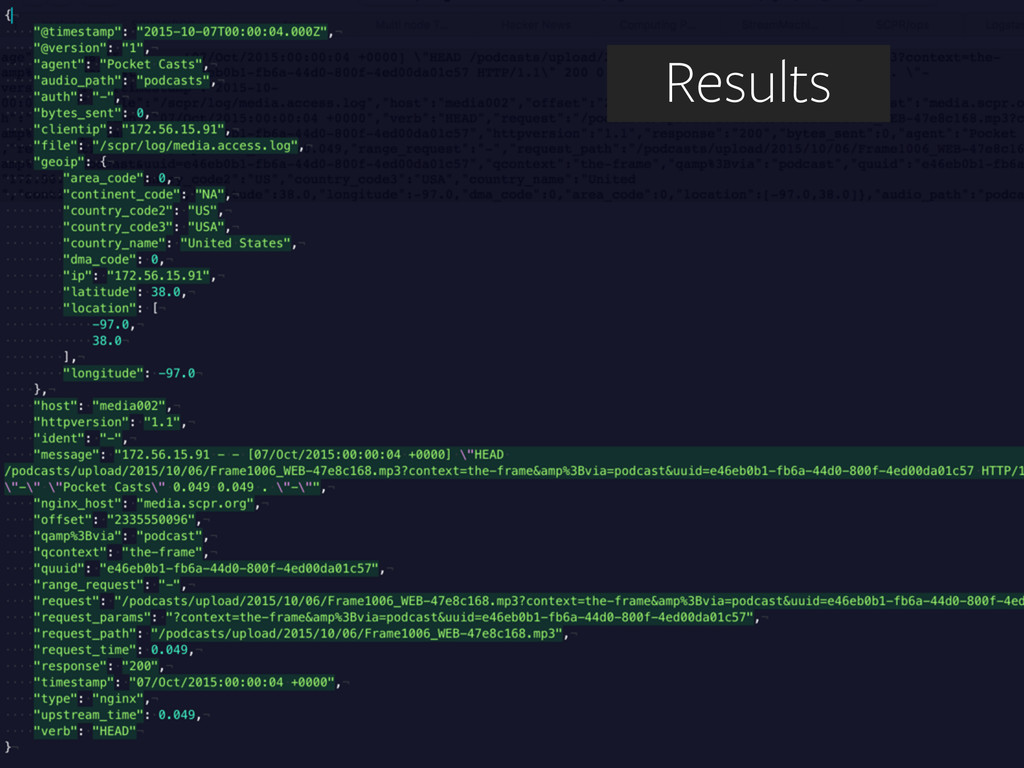
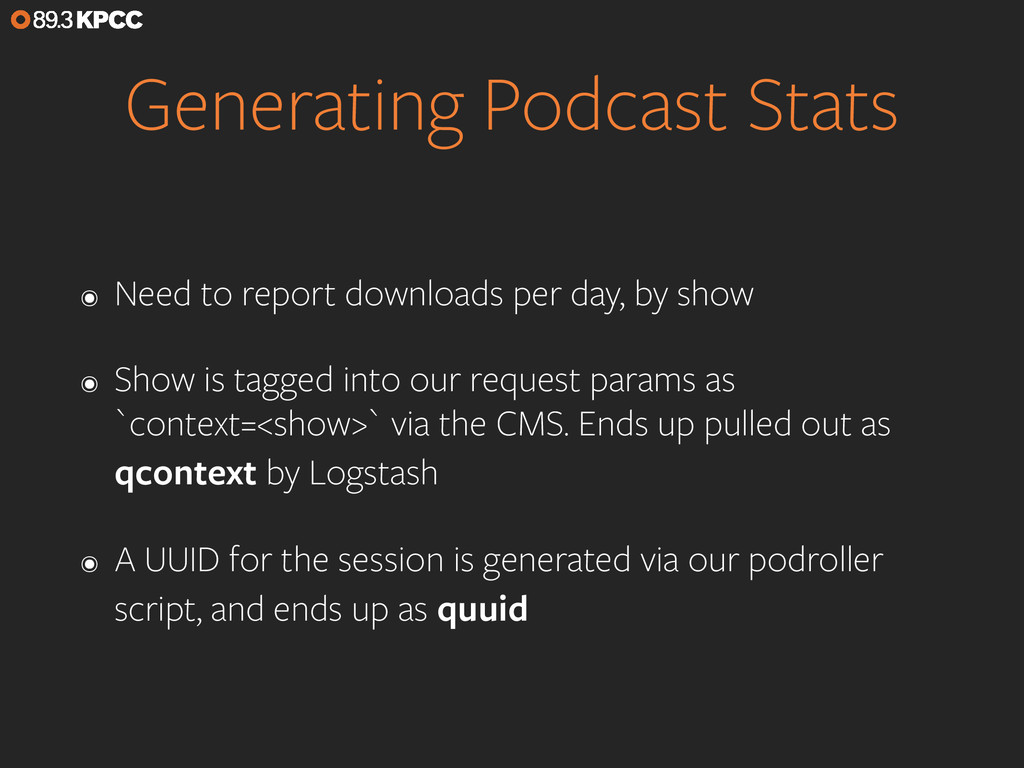
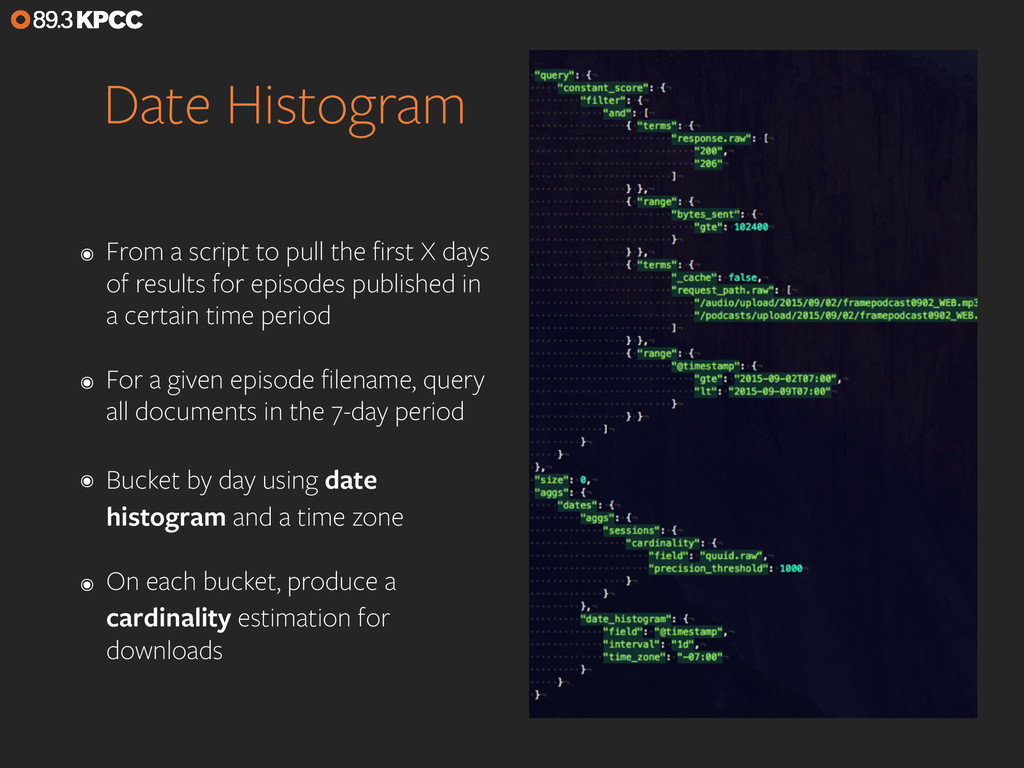
If you want to monitor your web traffic, you just drop in the tracking code for Google Analytics. But what if you want to monitor traffic that’s a little more esoteric, such as podcast downloads and audio stream listening? We’ll look at the analytics pipeline we’ve set up for Southern California Public Radio that leans on Elasticsearch aggregations to do the heavy lifting needed to turn our raw logs into listener data and realtime stats. We’ll also touch on using Logstash for data ingest and Kibana for visualizations and exploration.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] github.com/ewr github.com/SCPR github.com/scpr-cookbooks github.com/StreamMachine Thanks!](https://files.speakerdeck.com/presentations/a66f31b4d17f4c24b14fccc9626d7f1b/slide_39.jpg){kind=link}