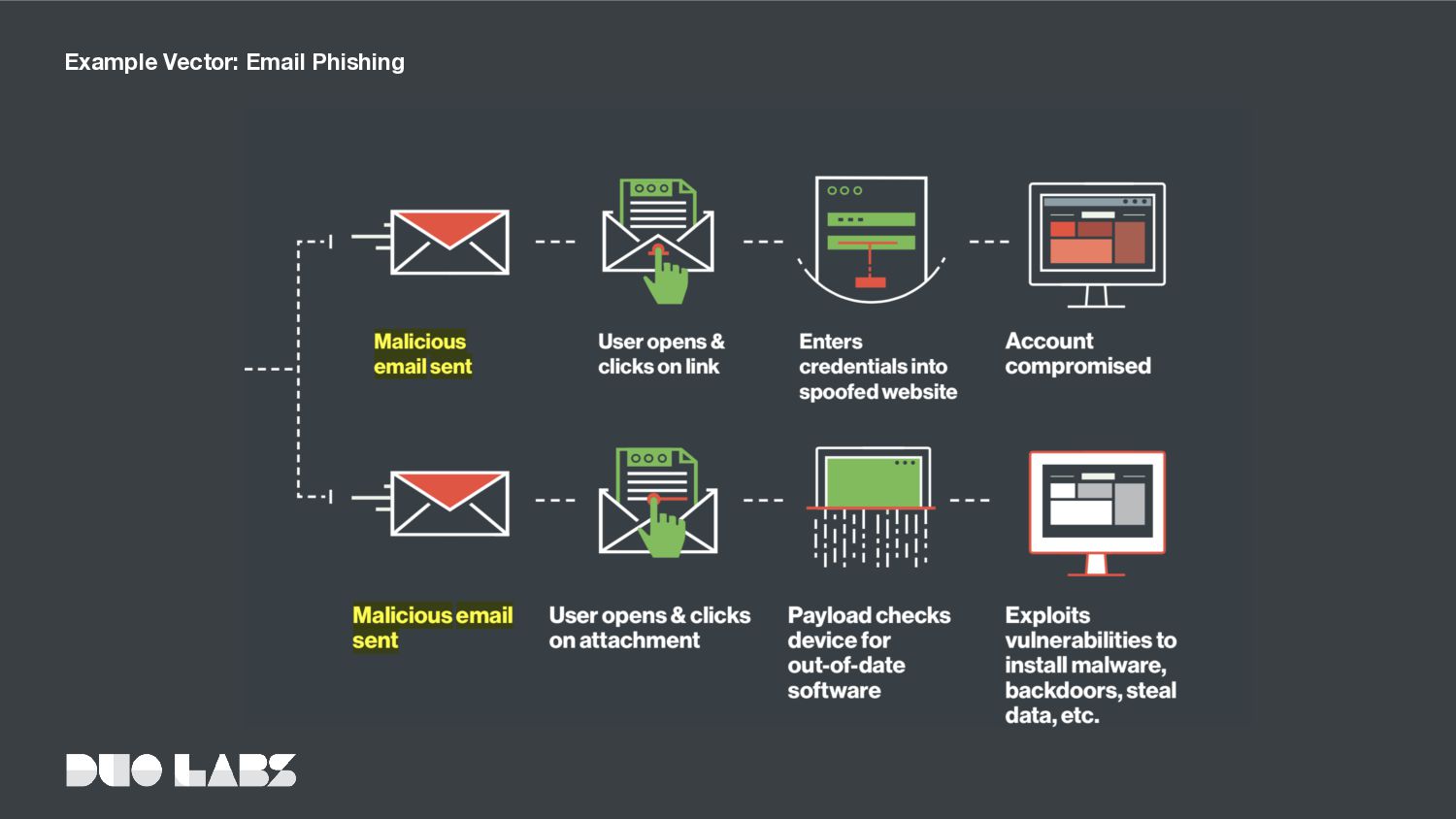
◦ Data breaches ◦ Malware (e.g. keyloggers) ◦ Breaking and leveraging weak credentials ◦ ... • ~ 2 billion usernames and passwords exposed via breaches in March 2016-2017 (Thomas, Li, et al., 2017). • ~ 63% of all breaches in the 2016 Verizon Data Breach Investigations Report were associated with credential theft. Credential Theft and Account Takeover
access log that are indicative of policy violations or breaches. • Security analysts analyze data sources (e.g. access logs) and use domain expertise to manually pull out interesting events. • Many automated threat detection systems are based around signatures and static rules. ◦ Need to build extensive domain knowledge (patterns known to be malicious) ◦ Organizations and their data tend to evolve quickly ◦ Tend to be reactive rather than proactive
access log that are indicative of policy violations or outright breaches. • Security analysts analyze data sources (e.g. access logs) and use domain expertise to manually pull out interesting events. • Most automated threat detection systems are based around static rules and signatures. ◦ Need to build extensive domain knowledge ◦ Organizations and their data tend to evolve quickly ◦ Tend to be reactive rather than proactive
care about and that is very resource intensive, so it is worth optimizing. Cybersecurity attacks are frequent, on the rise, underreported, and costly. Base rates are hard to quantify. Why does care?
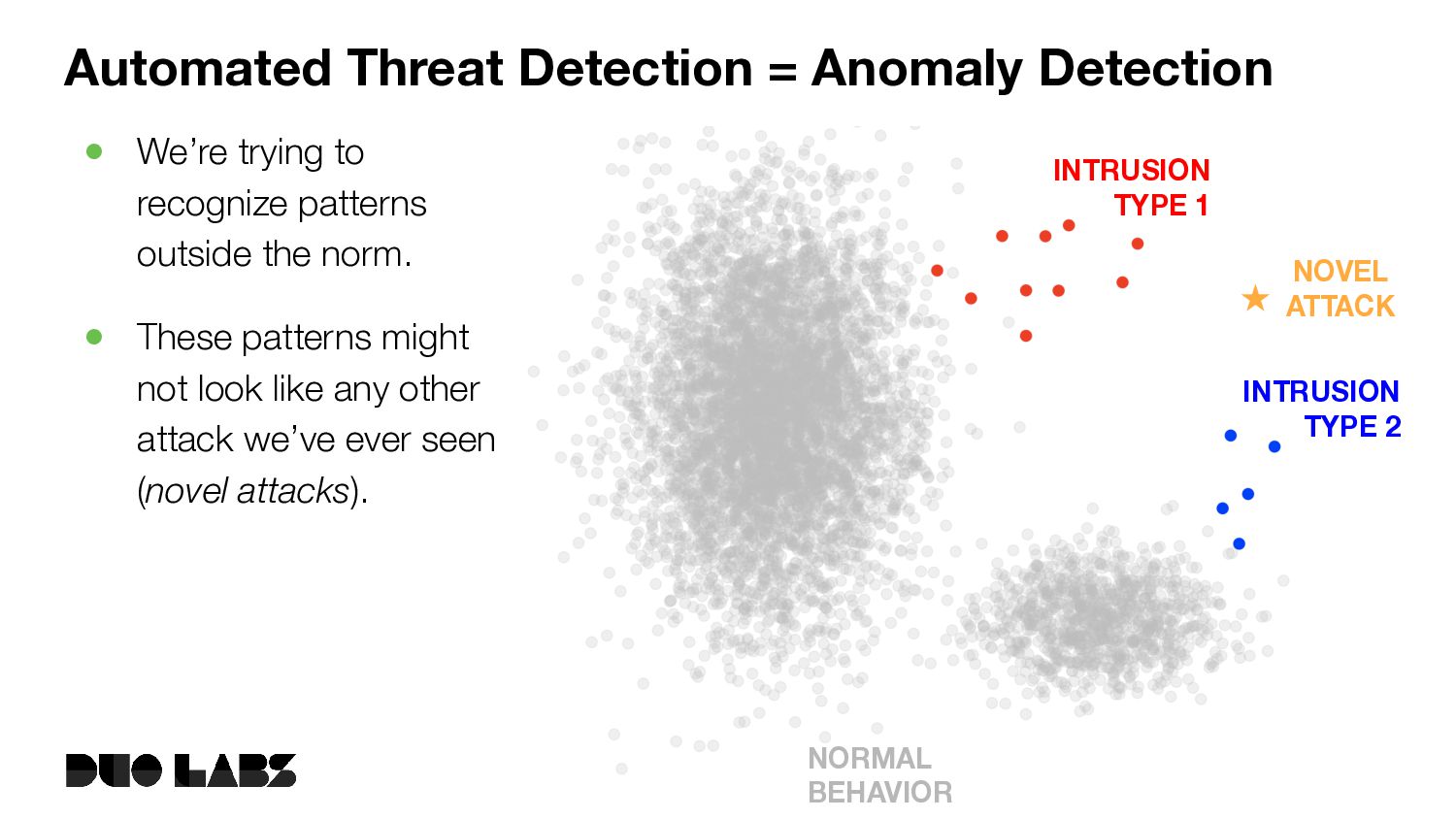
These patterns might not look like any other attack we’ve ever seen (novel attacks). NORMAL BEHAVIOR INTRUSION TYPE 2 INTRUSION TYPE 1 NOVEL ATTACK Automated Threat Detection = Anomaly Detection
that many algorithms can successfully detect attacks when tested on common synthetic datasets. see, e.g., Gilmore & Hayadaman, 2016 TAKE YOUR PICK! ◦ Simple density-based / statistical detectors ◦ Clustering ◦ Bayesian Networks ◦ Isolation Forests ◦ One-class SVMs ◦ Inductive Association Rules, Frequent Sequence Mining ◦ NLP-inspired DL models ◦ … That success doesn’t always translate to an industrial setting...
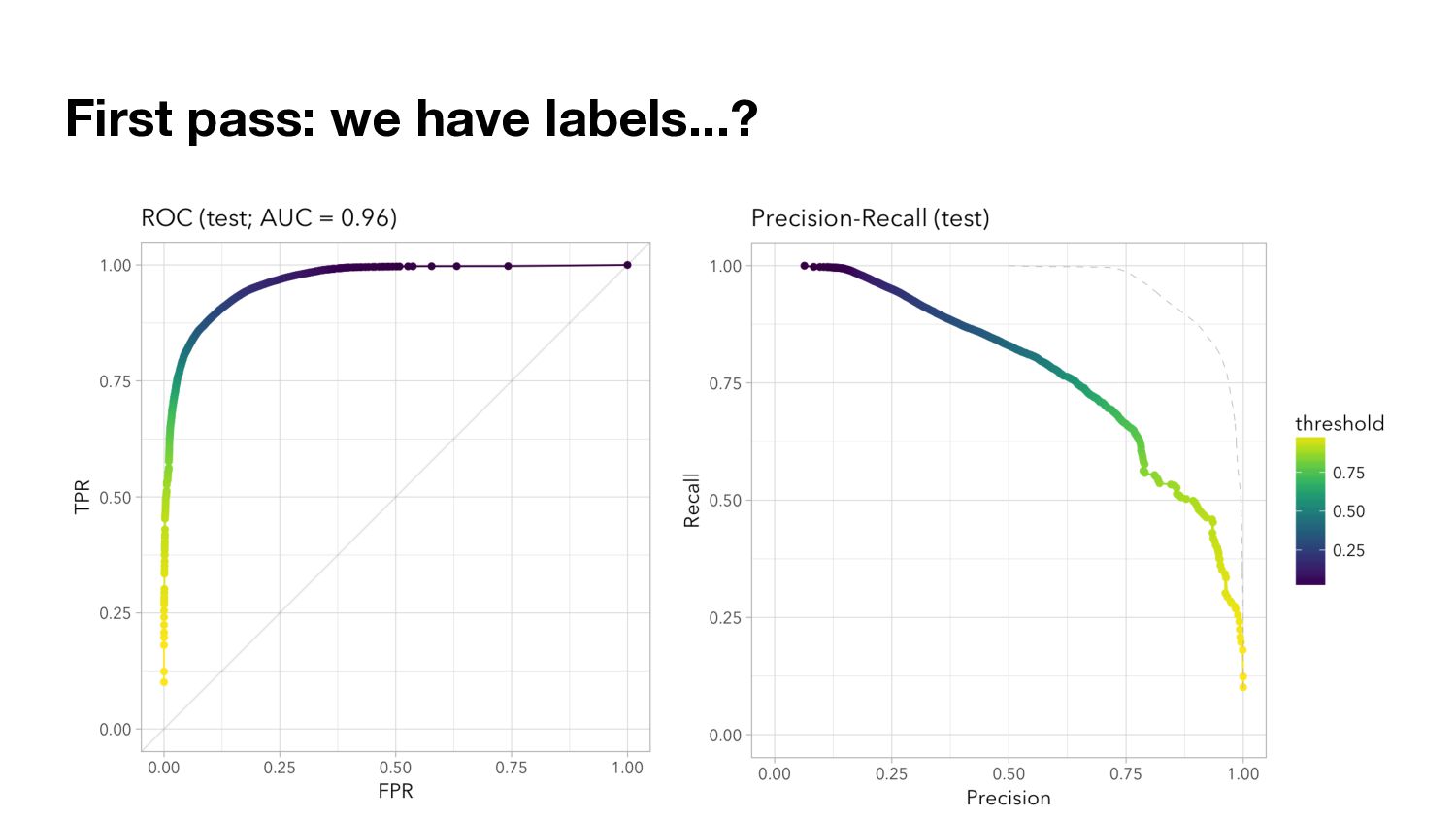
at all (Attacks are rare). • Unsupervised. • Strong assumptions on “normality” vs. “attack”. • Without ground truth, you can’t verify your assumptions (easily)
Detection system Context Providing contextual behavior information Explanation Justifying model decisions Feedback Human-in-the-loop knowledge transfer Action Suggesting next steps and mitigations A great model produces useful, understandable, actionable detections. Model accuracy is not sufficient.
• Company • User • Application • Time of access • Outcome of authentication • Properties of the access device • Properties of the second factor • Network of origin
Artifacts Models Database Queue or Database Normalize data sources Extract features Score and explain Presentation of potential security events Spark on EMR Spark on EMR
models that consider: ◦ Distribution of the geographical origin, timestamp, and essential attributes of the authentications; ◦ Surrounding context at a session level; ◦ Calibration information derived from recent historical data. • We return an anomaly score paired with an explanation (“authenticated from a novel device, ...”) and context (surrounding auths for the user).
from alpha clients very early on, and kept iterating. • Gives iterative insights into: ◦ Threat models What do they consider suspicious vs. merely anomalous? what is “useful”? ◦ Semantic gap Can we explain our outputs? can they explain their decisions? ◦ User populations Dave does X all the time when Y, and it’s not suspicious ◦ Use cases that might be rare in the customer base at large.
Threat Detection, but using it in production requires a lot of care. • The risk score is only a small fraction of the work. • The business metric is whether your end user finds predictions useful and usable. • We have a lot of ongoing research - both on improving ML models, and on usability. THANK YOU! www.stefanom.io @RhymeWithEskimo
of data produced by users and companies. • Unsupervised models are still annoying, and hard to deal with the temporal component. • Categorize blocks of authentications into “tasks” to characterize normal and fraudulent behavior. Research Threads • Learn or impose a data hierarchy. • Point process models can describe temporal patterns. ◦ Intrigued? Attend Bronwyn Woods’ talk at CAMLIS 2018. • Association rules can help surface frequent actions shared by groups of users.
known attacks: if any labels at all, extreme class imbalance. ◦ For novel attacks: nah. • High cost of both false positives and false negatives. • Dearth of realistic public datasets. • Assumes some notion of normal behavior, but there are multiple agents with potentially very different behaviors.
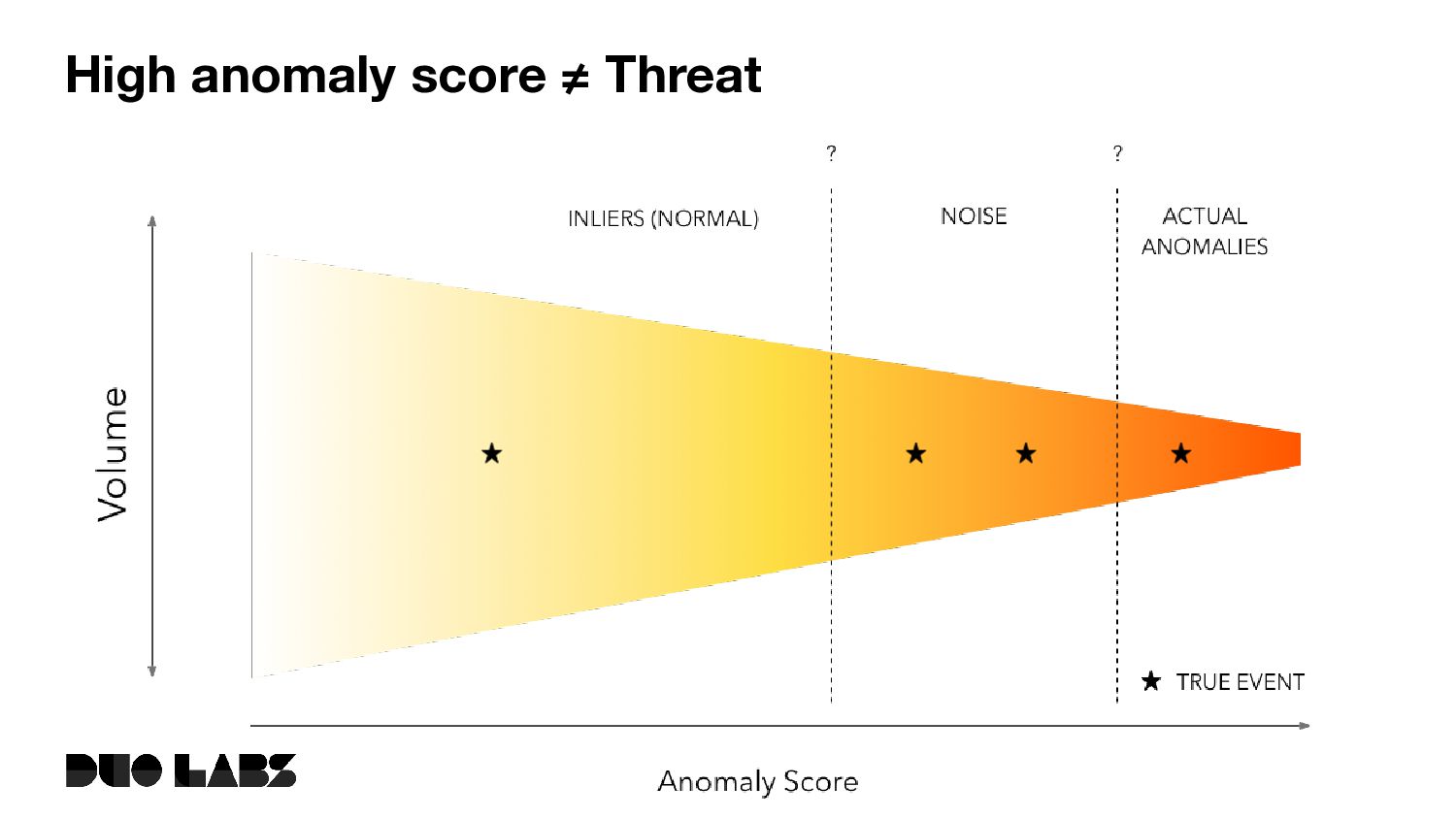
and temporal anomalies, not just point anomalies. • Mixed data types with varying proportions of categorical, boolean, and numerical data. • Context is important. • Hard to distinguish between noise, anomalies, and actual security events. High anomaly score ≠ Threat. see, e.g., Sommer & Paxson, 2010
needed for fast, iterative research and more heavyweight processes for production. ◦ Tooling mismatch. • We don’t have a good story for: ◦ Monitoring model performance ◦ Dynamically scheduling retraining • These are very both important components, especially in an adversarial environment.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}