This is geared towards engineers with some data experience who would like to dip their toes into using Apache Spark.
This workshop covers how to:
* use a notebook environment
* write simple Apache Spark queries to filter and transform a dataset
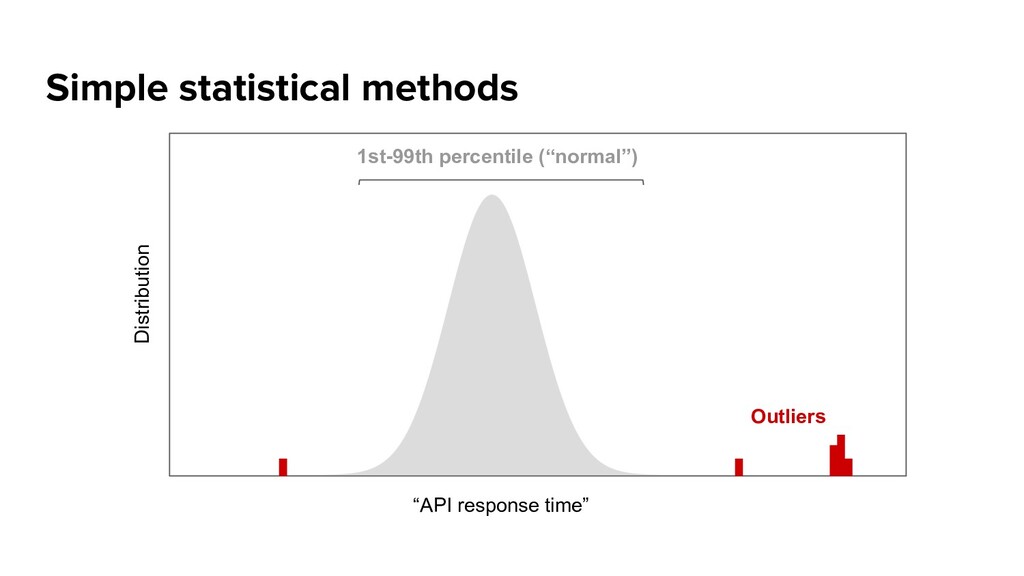
* do very simple outlier detection
and is taught using the Amazon Electronics reviews dataset.
The prerequisites are available at: https://github.com/stefano-meschiari/spark_workshop
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}