call goes through OpenAI/Google/Anthropic etc servers They see your prompts, they control access, they set the price What if 10 people could each host a piece of one model and run it together? Presented By: Favour Chukwuedo Codex Community Meetup: Vancouver April 10, 2026
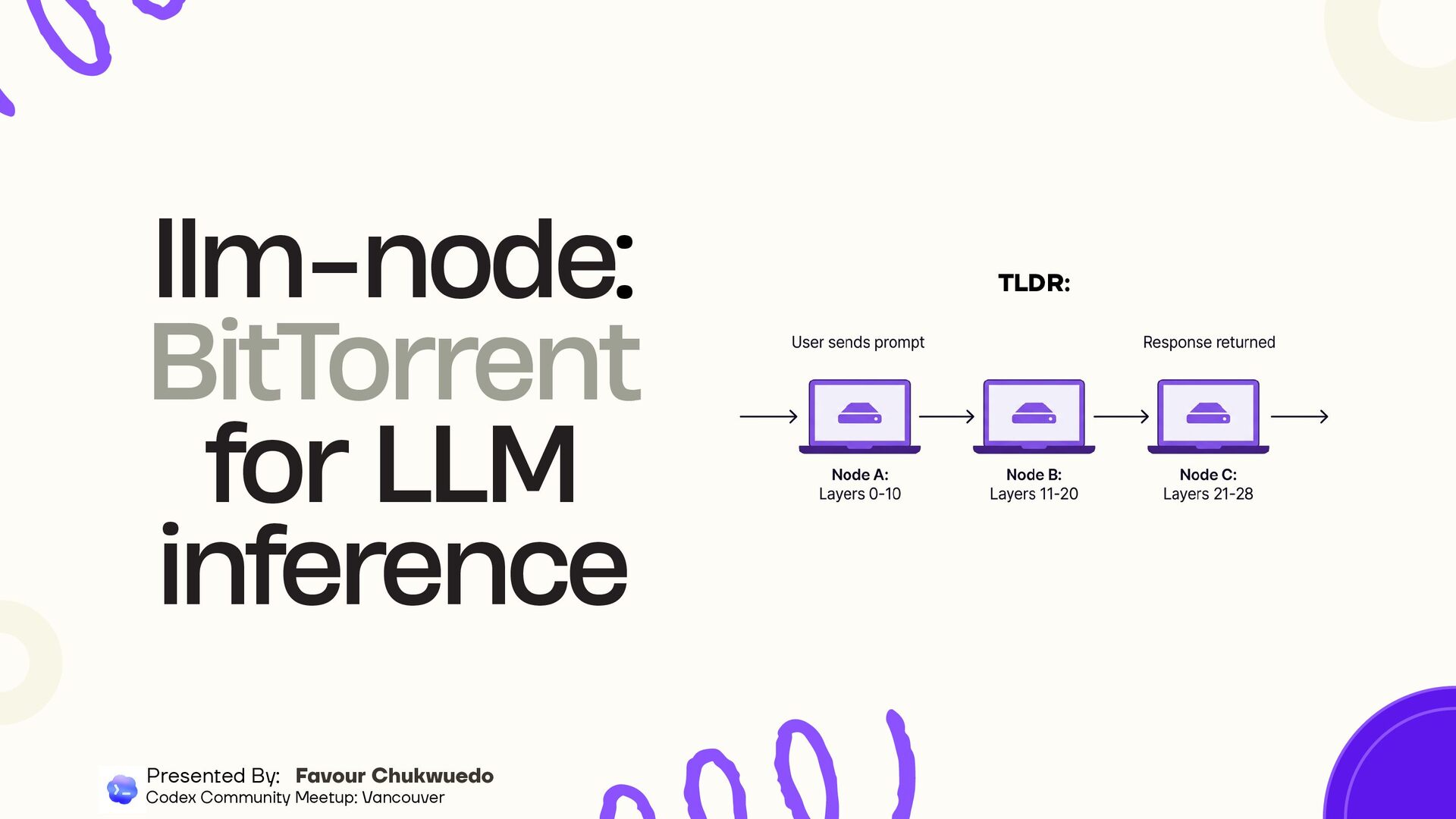
of 28) Nodes find each other automatically (mDNS on LAN, DHT on internet) Inference running as a pipeline: your layers → next node's layers → response Privacy-first: onion-routed traffic, .llm cryptographic addresses llm-node: BitTorrent for LLM inference Presented By: Favour Chukwuedo Codex Community Meetup: Vancouver
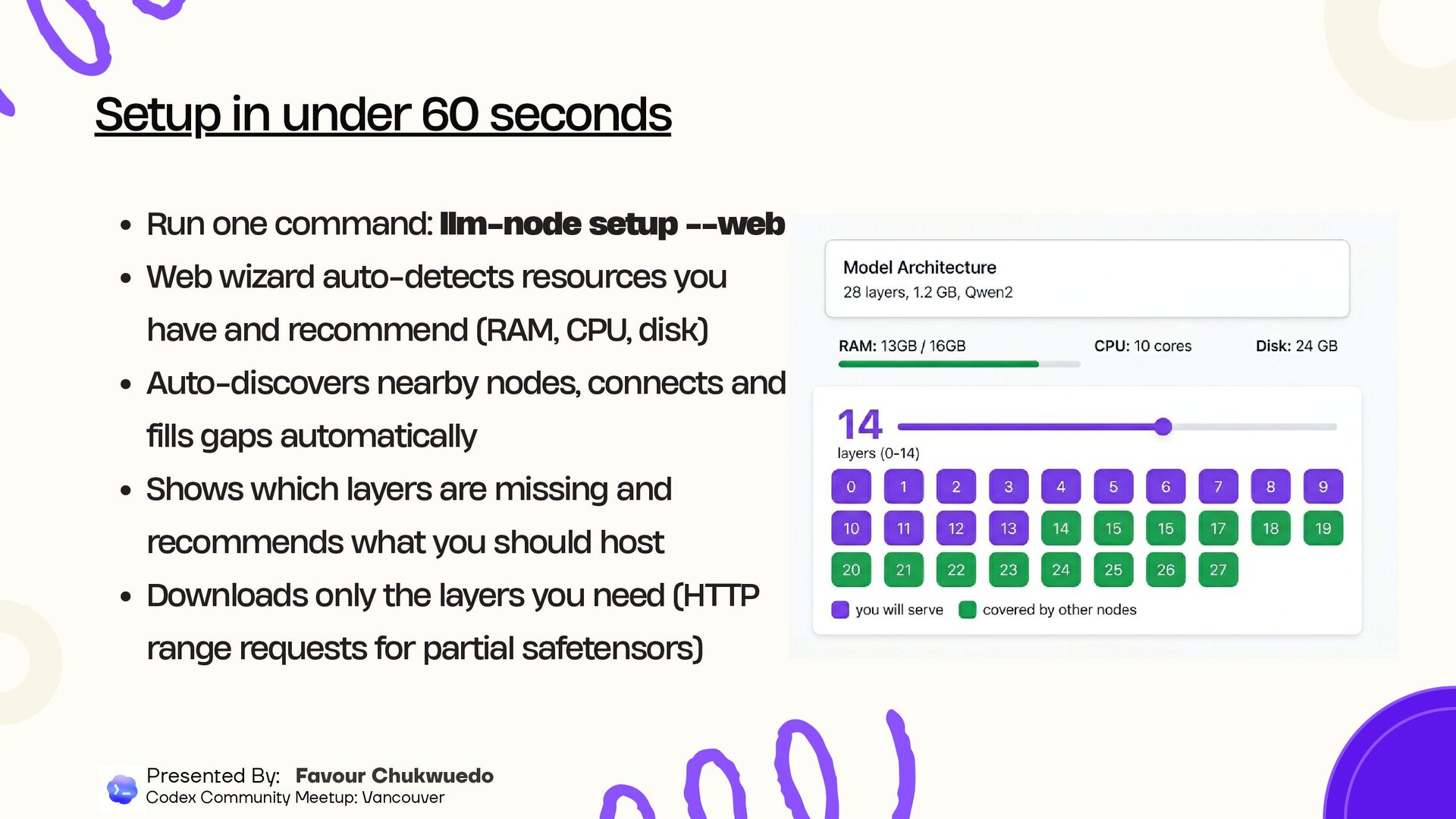
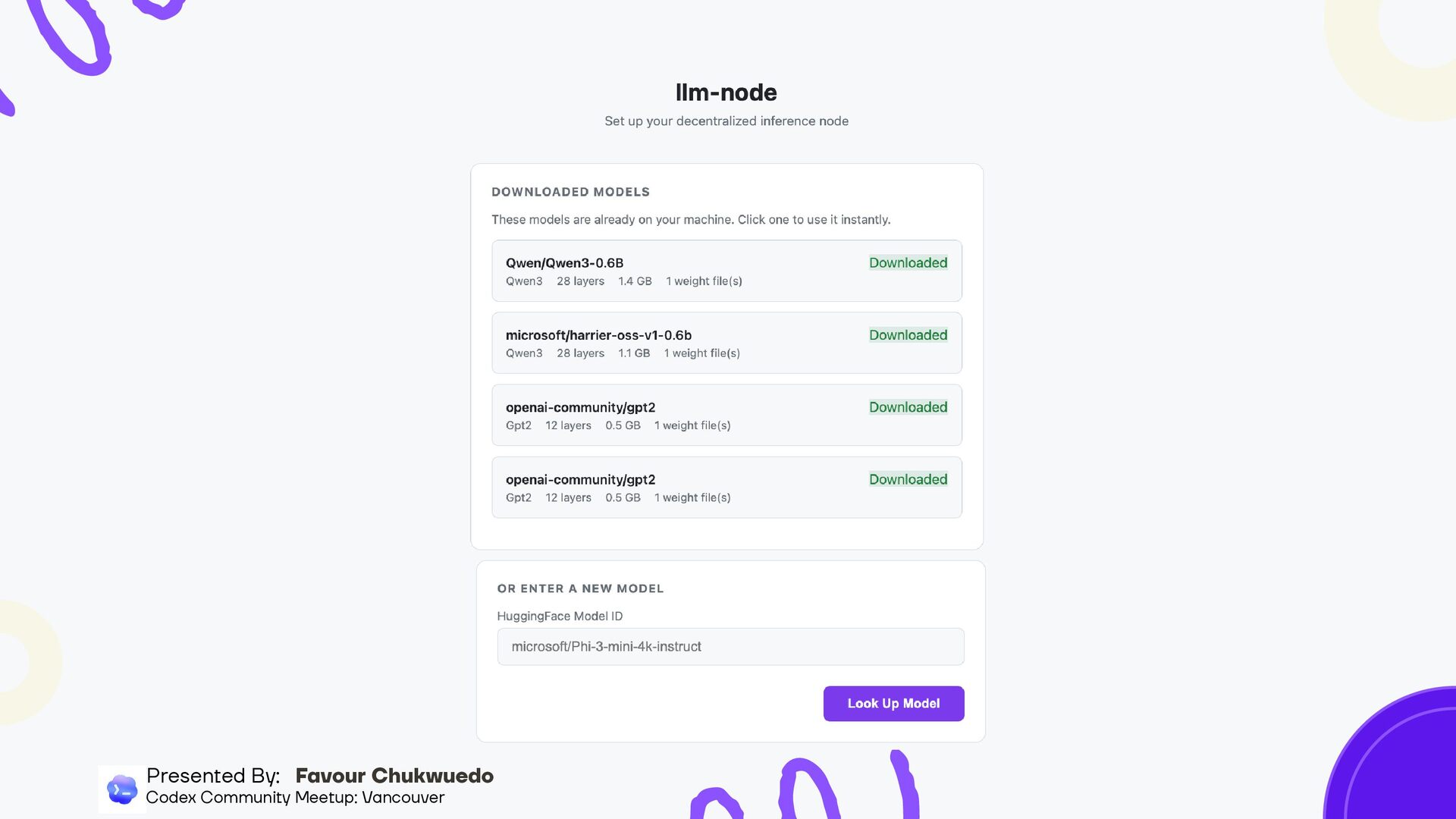
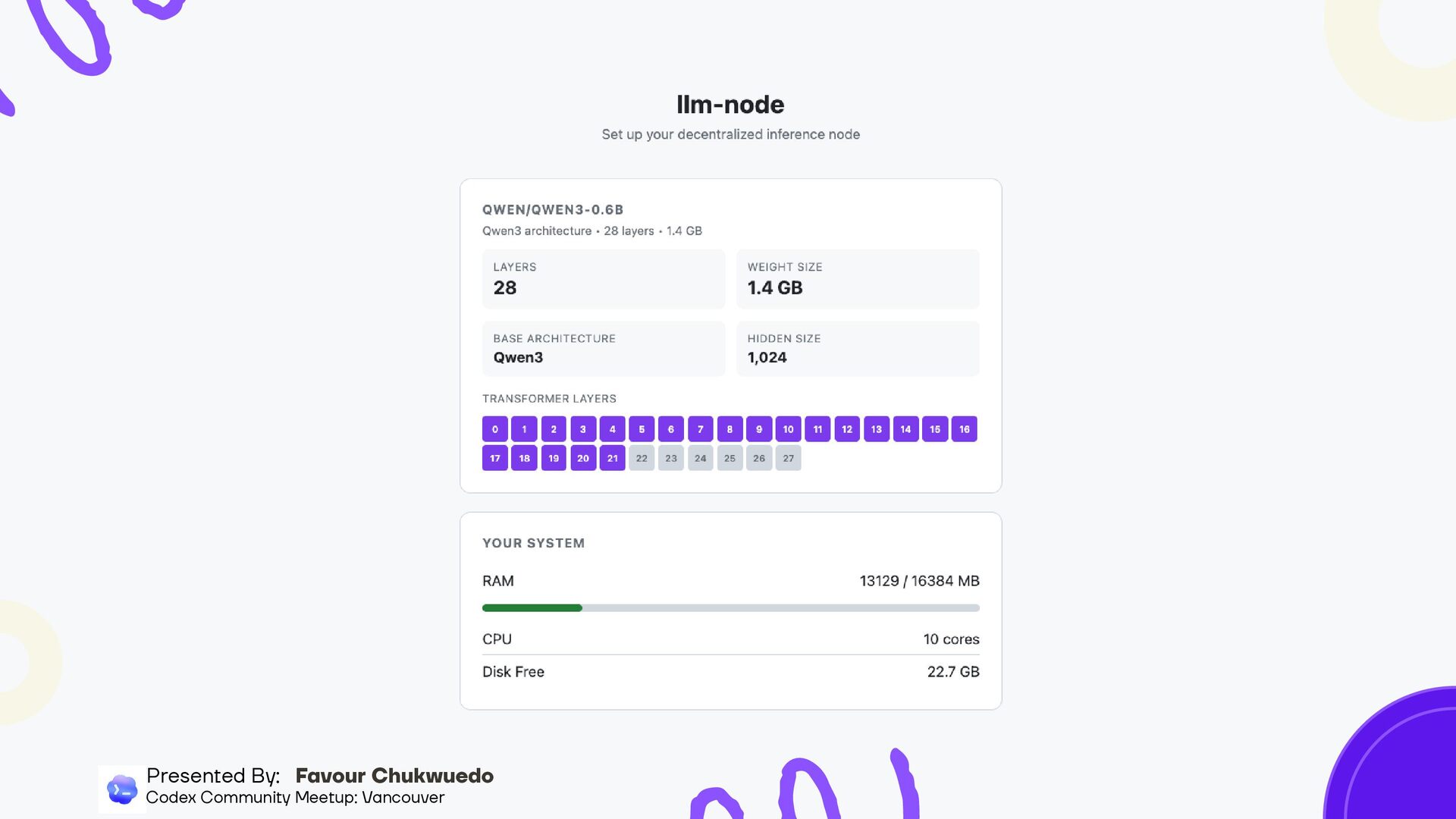
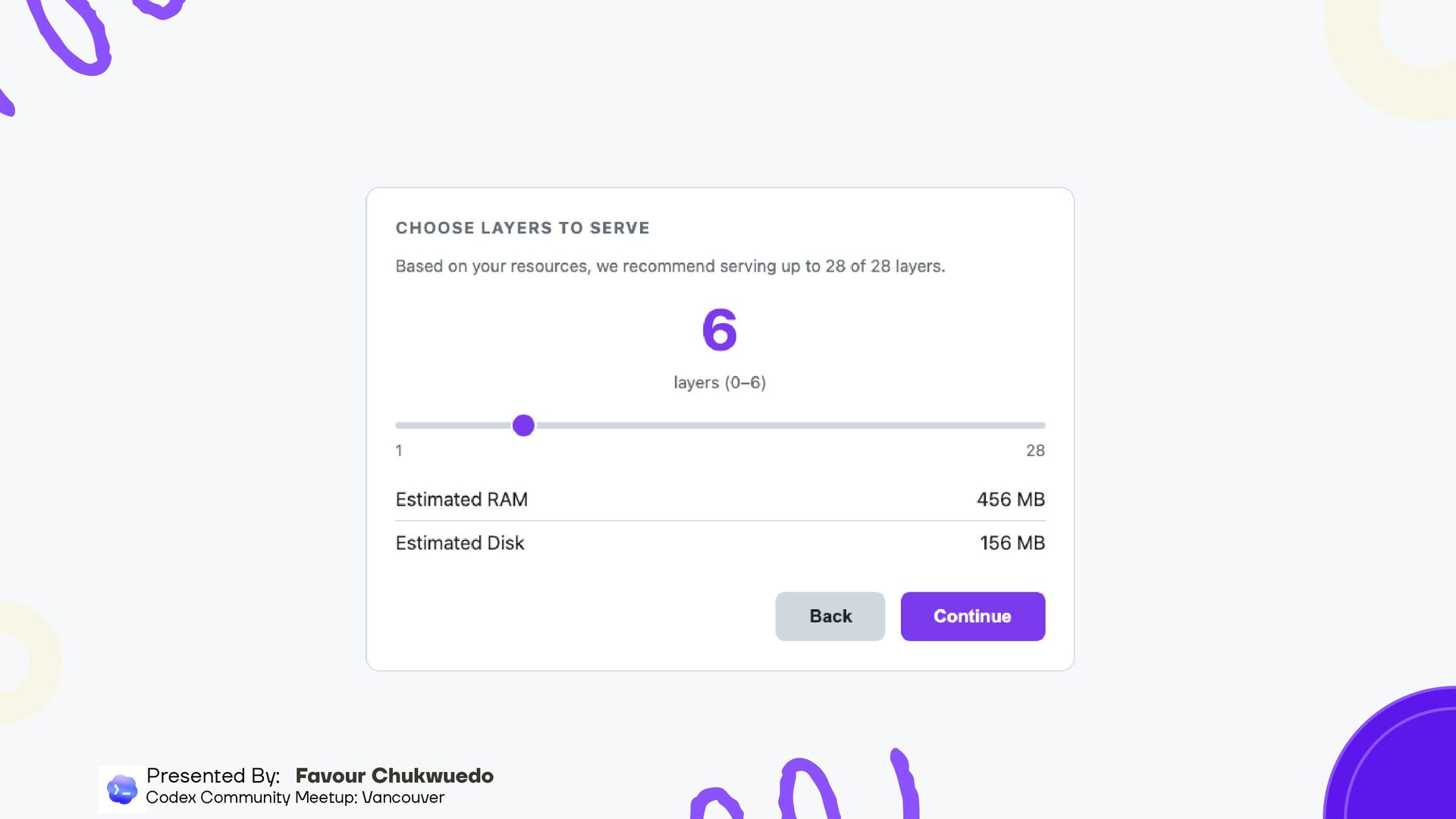
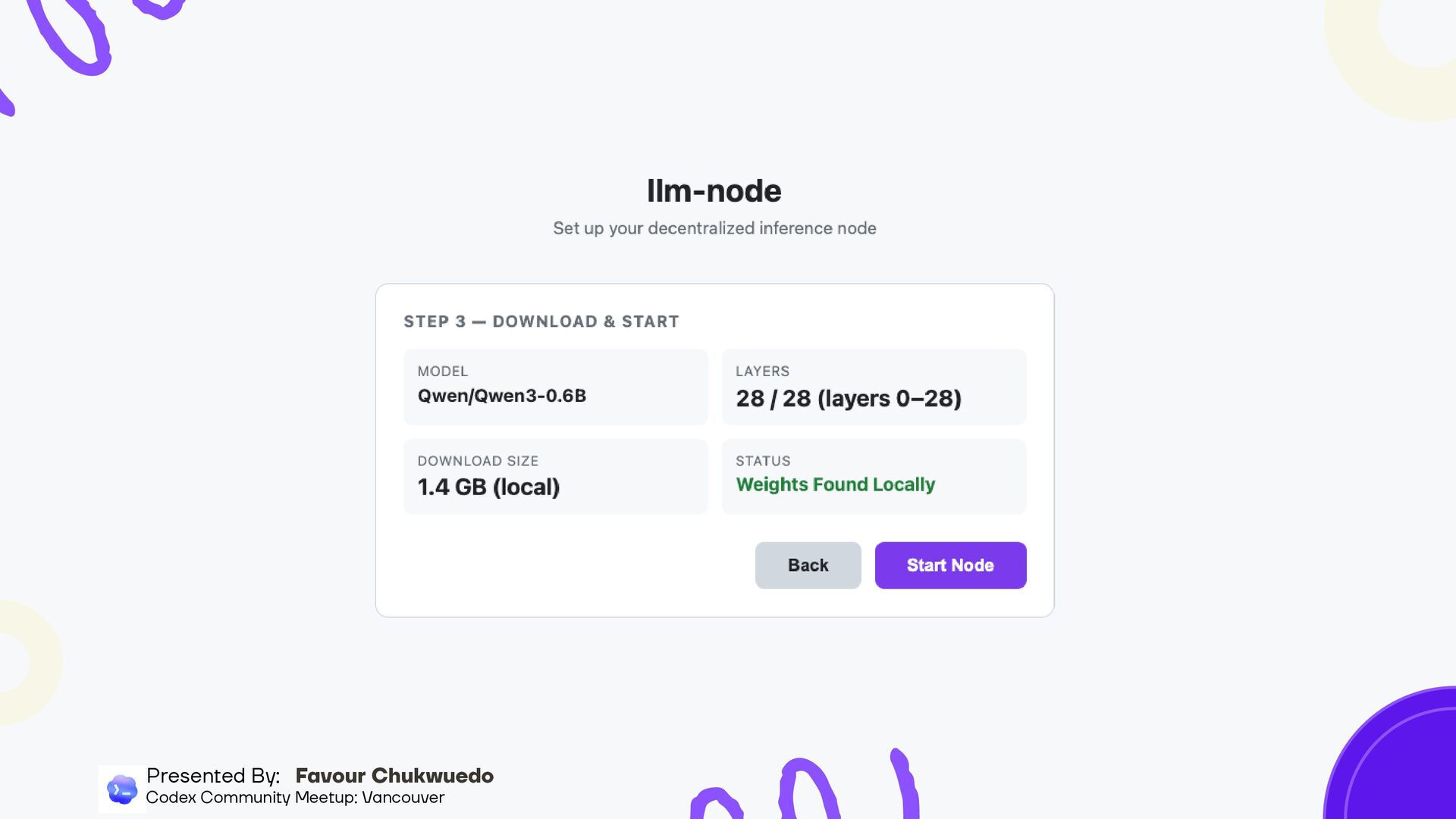
you have and recommend (RAM, CPU, disk) Auto-discovers nearby nodes, connects and fills gaps automatically Shows which layers are missing and recommends what you should host Downloads only the layers you need (HTTP range requests for partial safetensors) Setup in under 60 seconds Presented By: Favour Chukwuedo Codex Community Meetup: Vancouver
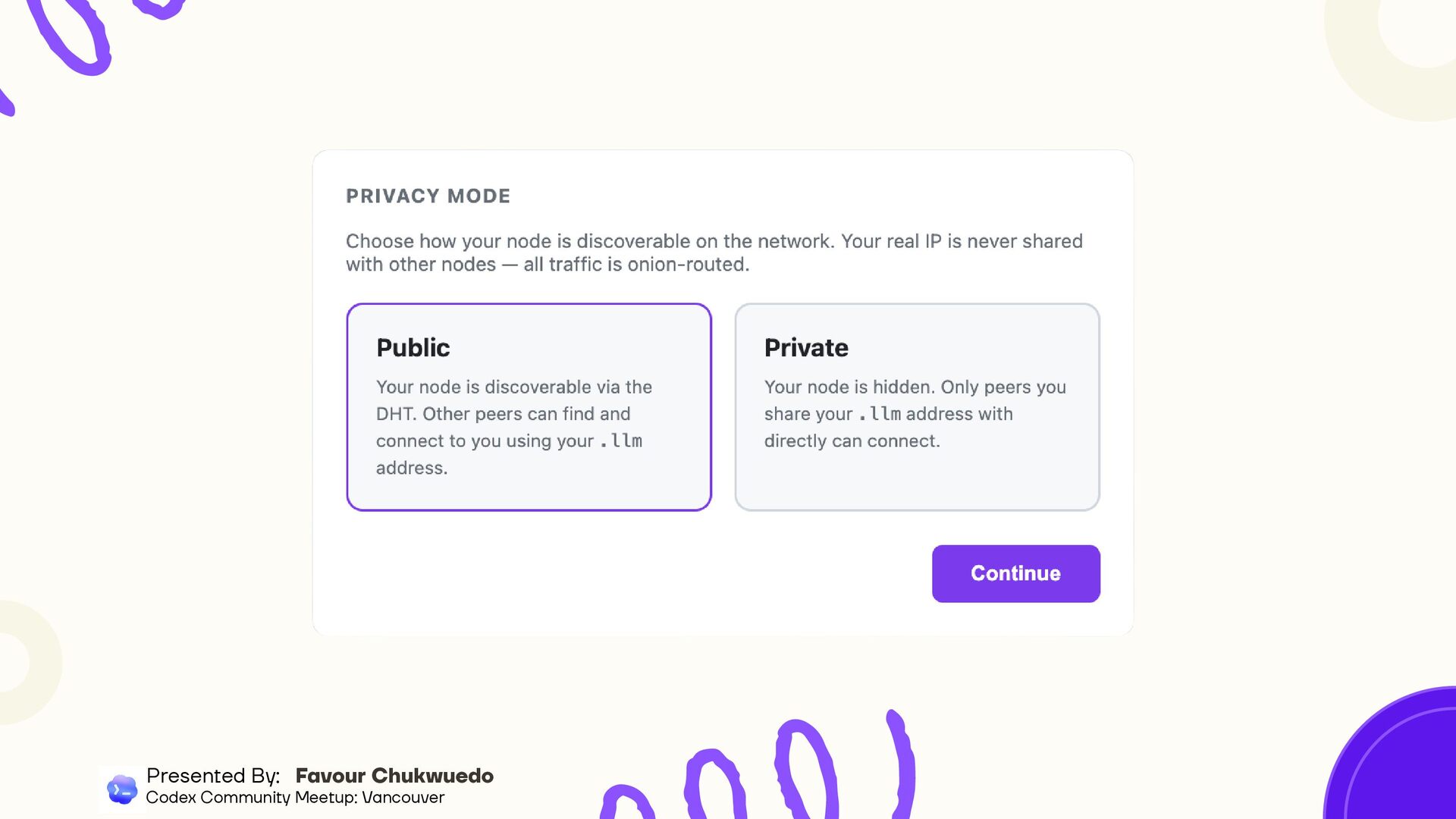
a message → model responds via local inference or distributed pipeline Second node joins → dashboard updates in real-time, coverage map fills in Every node gets a .llm address (like a .onion address) Presented By: Favour Chukwuedo Codex Community Meetup: Vancouver
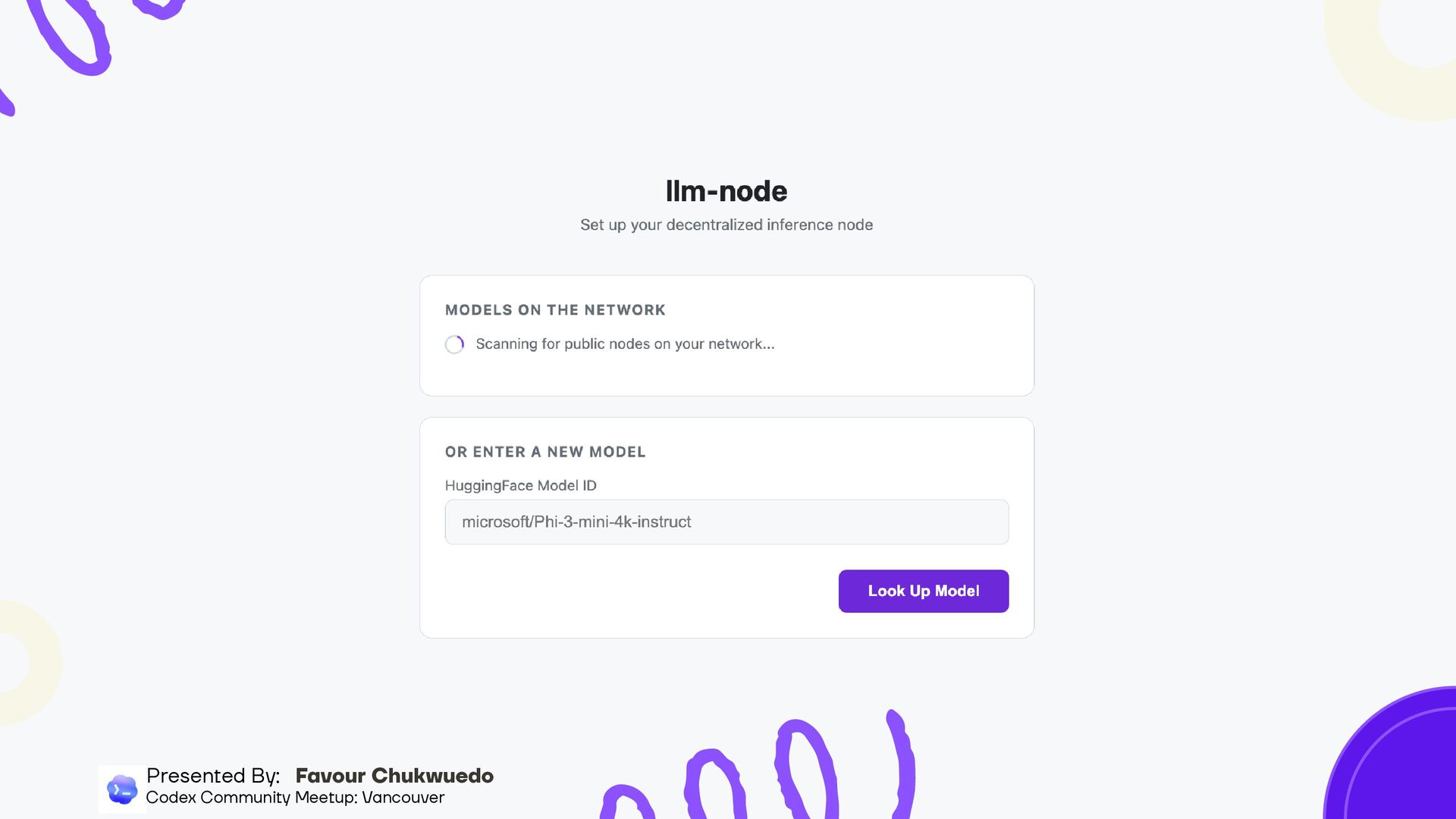
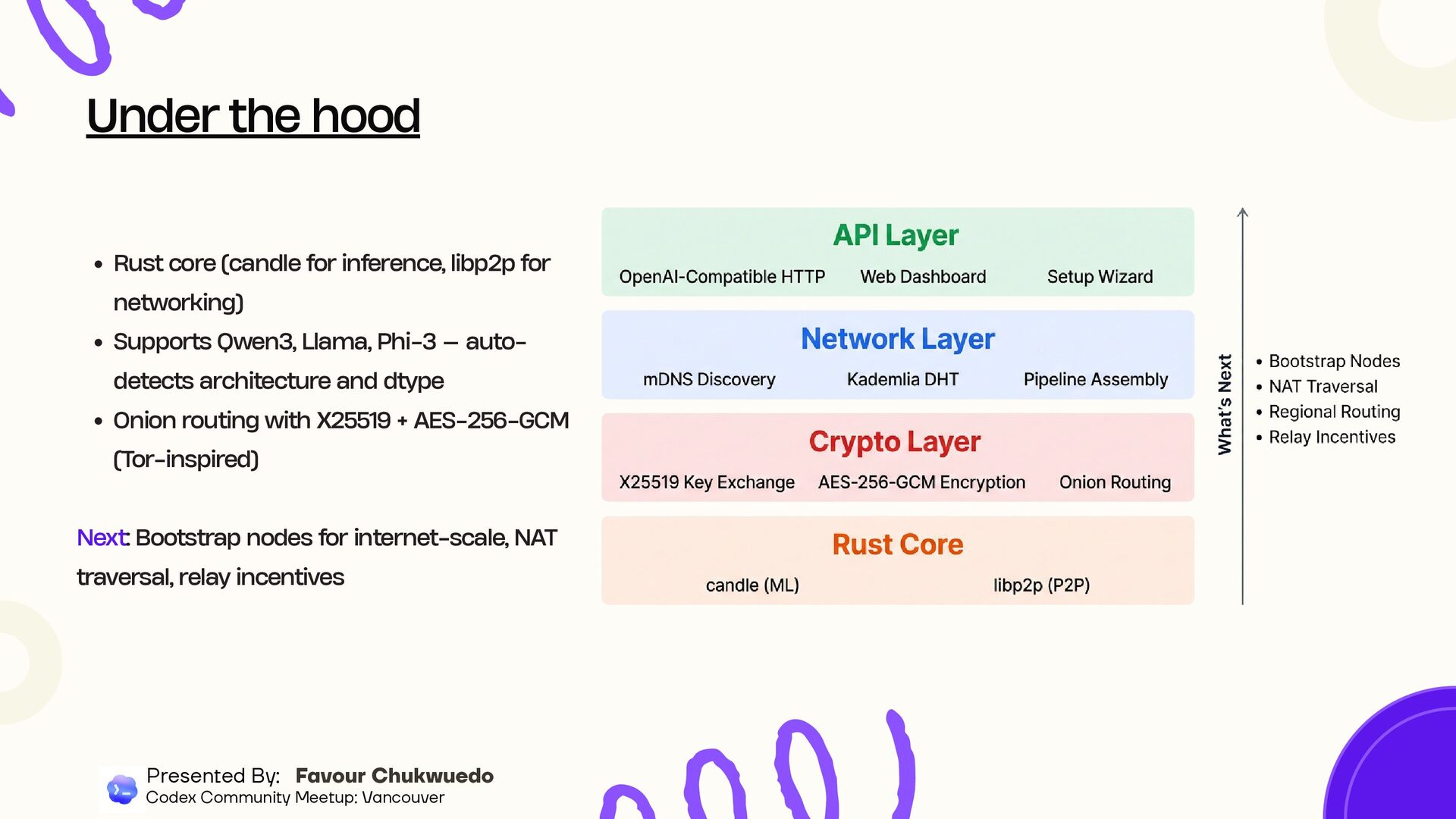
Llama, Phi-3 — auto- detects architecture and dtype Onion routing with X25519 + AES-256-GCM (Tor-inspired) Next: Bootstrap nodes for internet-scale, NAT traversal, relay incentives Under the hood Presented By: Favour Chukwuedo Codex Community Meetup: Vancouver
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}