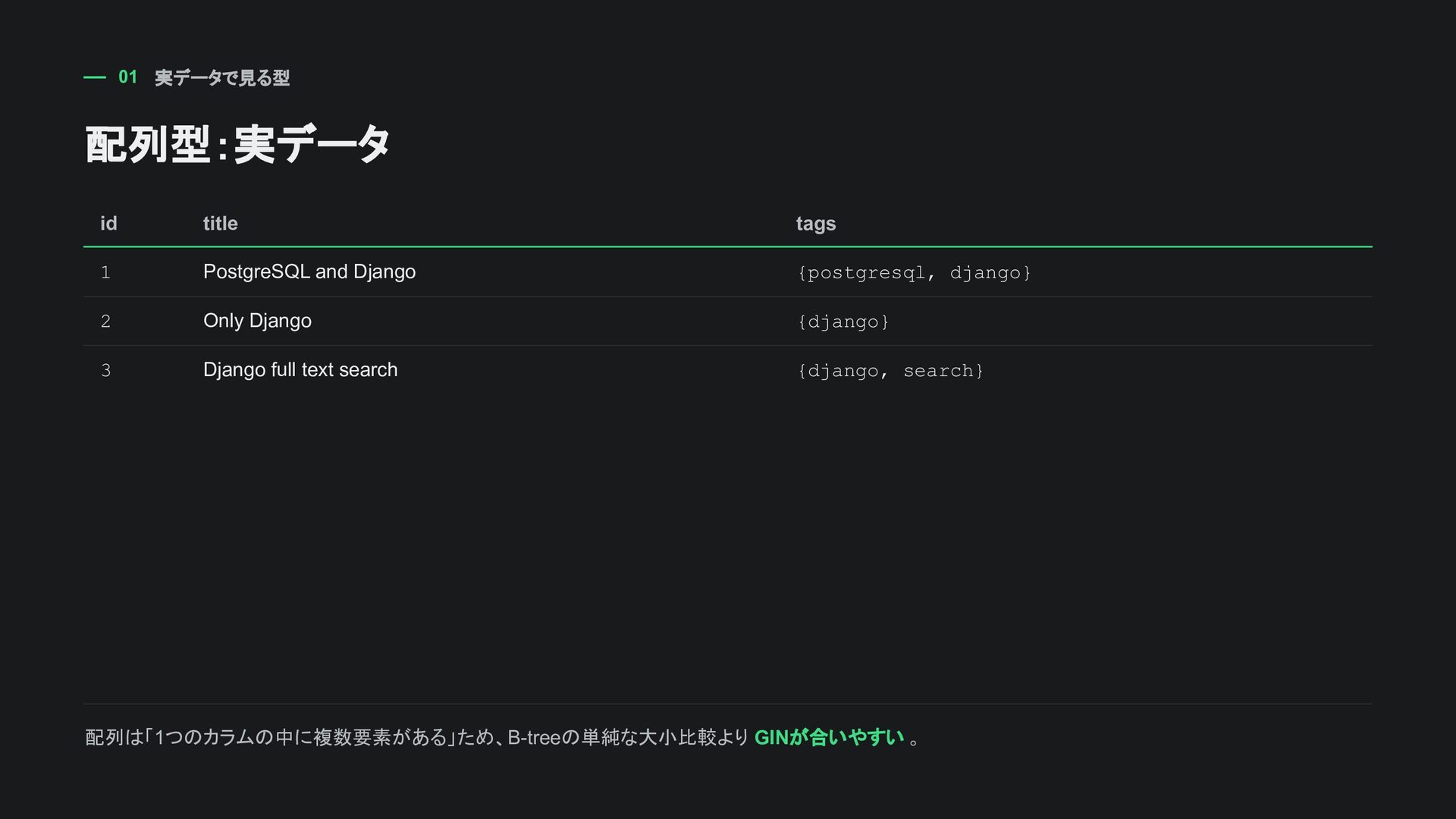
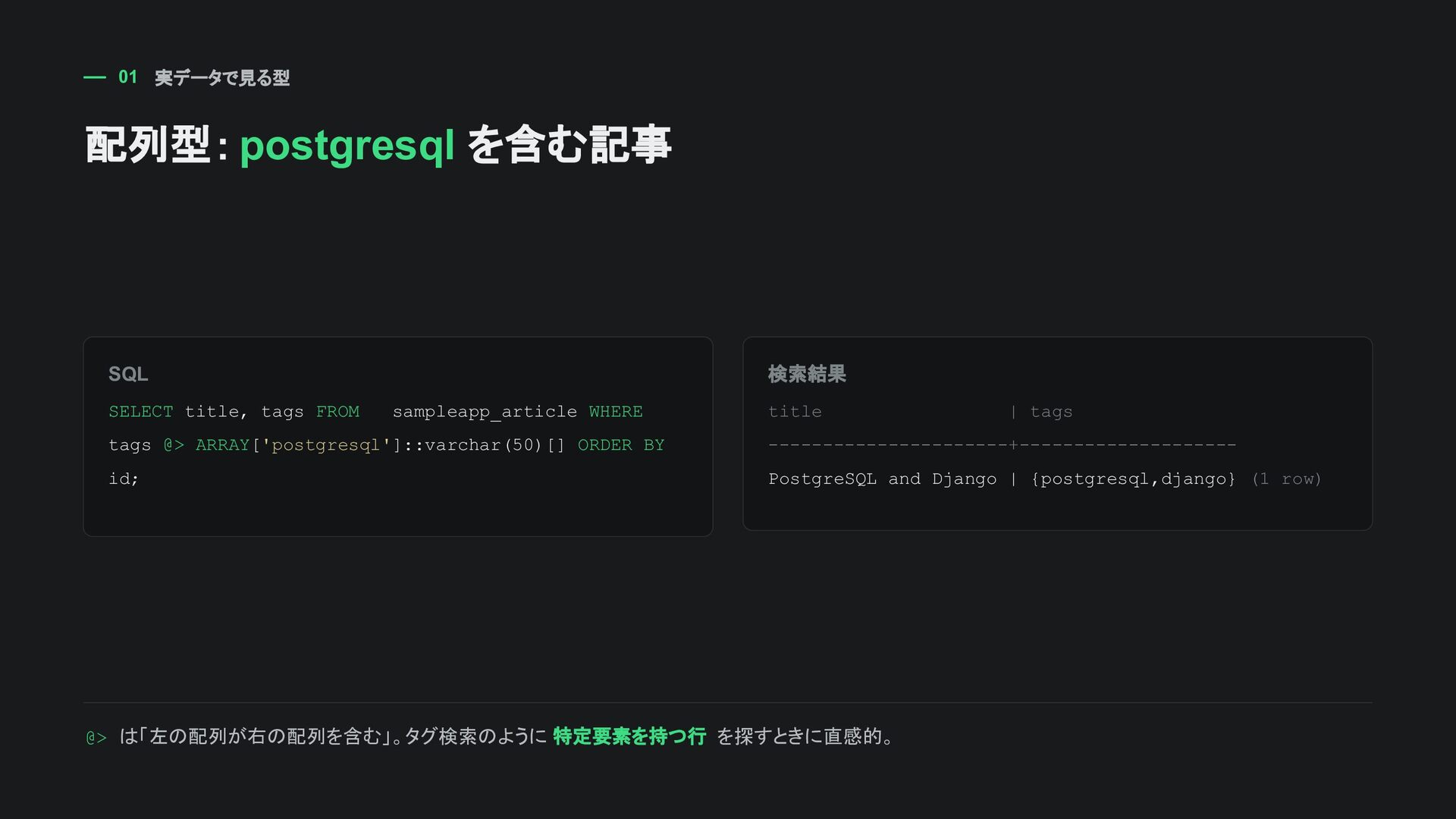
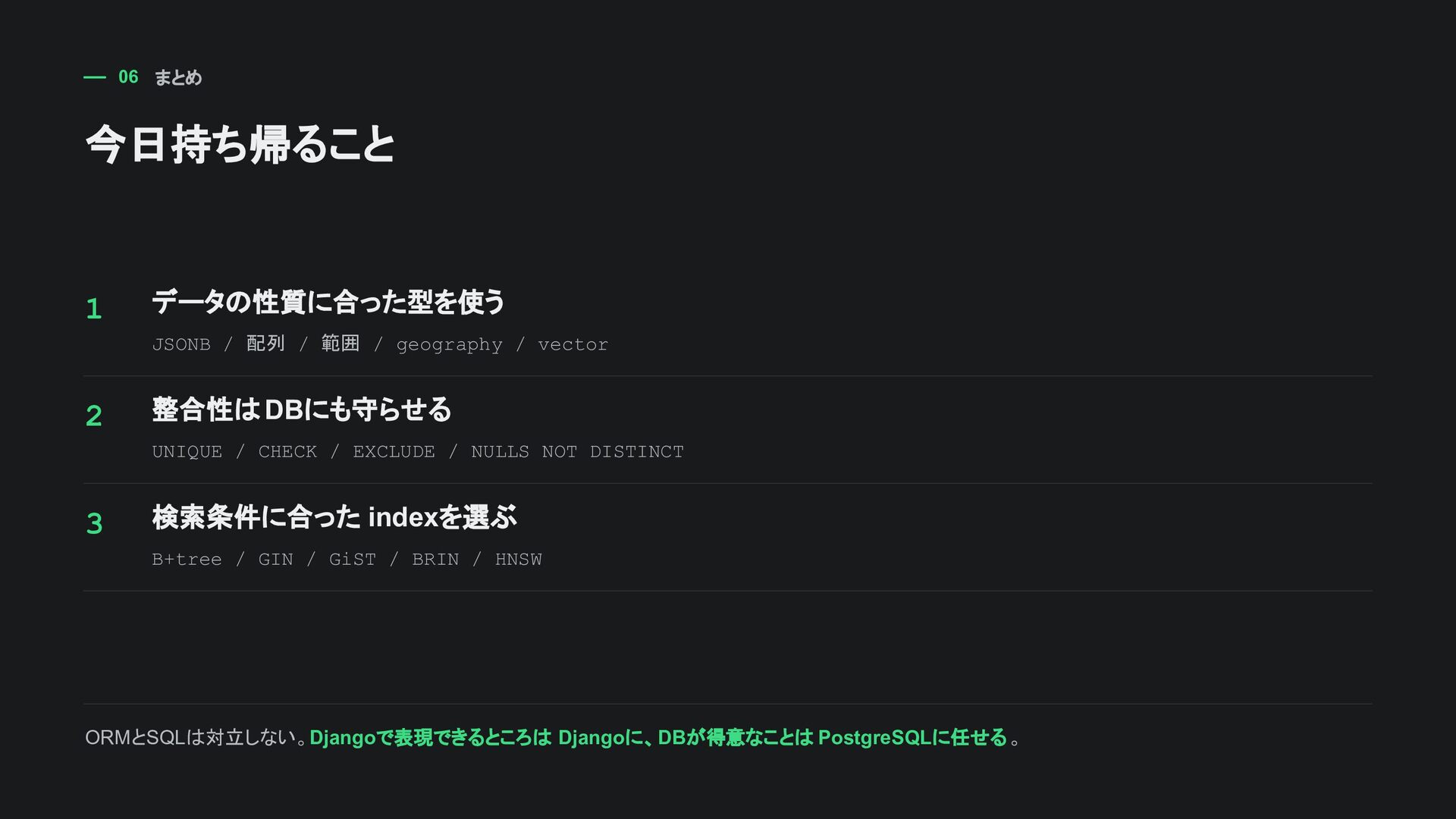
WHERE tags @> ARRAY['postgresql']::varchar(50)[] ORDER BY id; 検索結果 title | tags ----------------------+-------------------- PostgreSQL and Django | {postgresql,django} (1 row) @> は「左の配列が右の配列を含む」。タグ検索のように 特定要素を持つ行 を探すときに直感的。
FROM sampleapp_article WHERE tags && ARRAY['django','postgresql']::varchar(50)[] ORDER BY id; 検索結果 title | tags ------------------------+-------------------- PostgreSQL and Django | {postgresql,django} Only Django | {django} Django full text search | {django,search} (3 rows) && は「重なりがあるか」。どれか 1つでも含めばよい検索では、 ORを自分で展開しなくてよい。
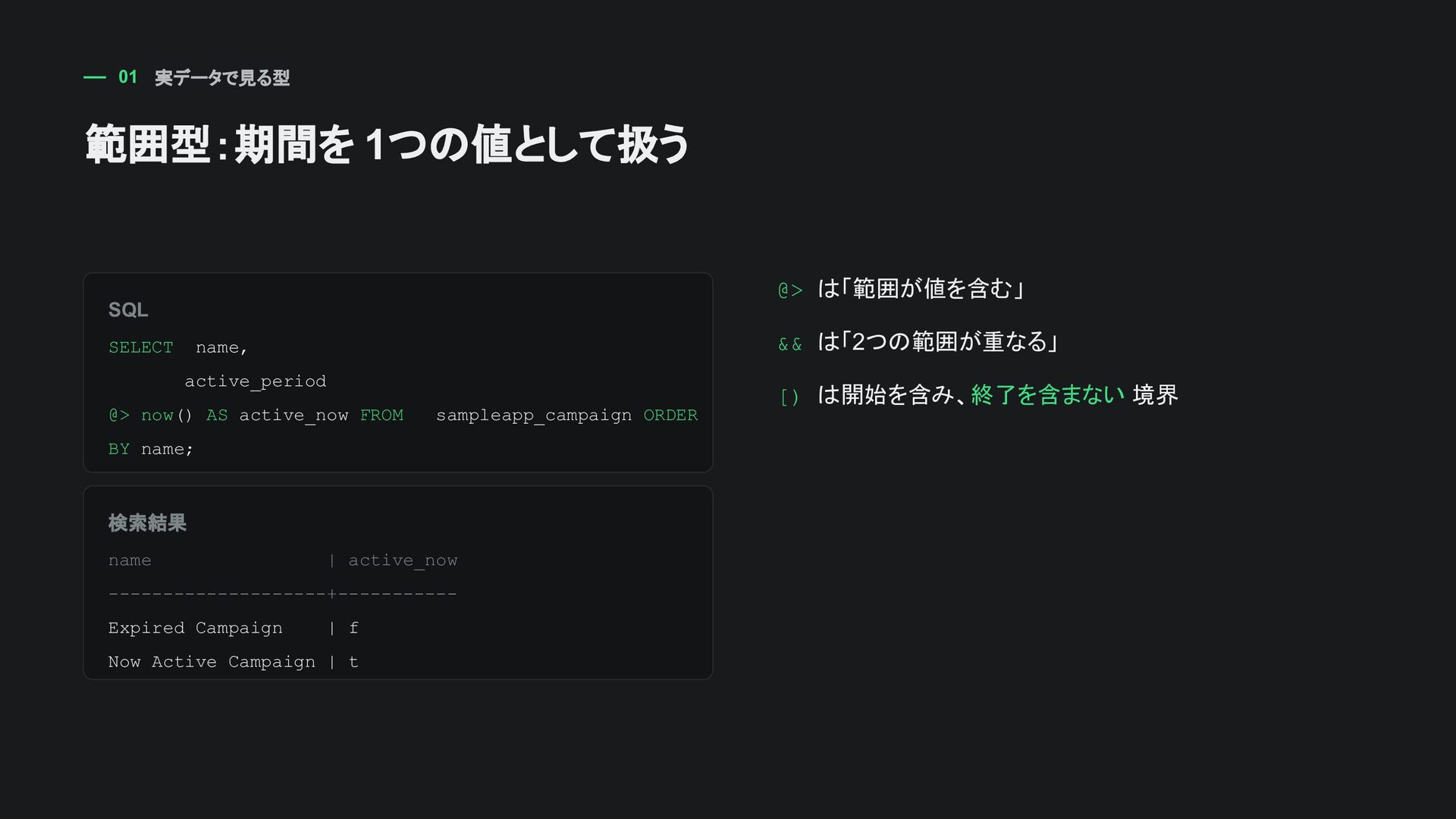
AS active_now FROM sampleapp_campaign ORDER BY name; 検索結果 name | active_now --------------------+----------- Expired Campaign | f Now Active Campaign | t @> は「範囲が値を含む」 && は「2つの範囲が重なる」 [) は開始を含み、終了を含まない 境界
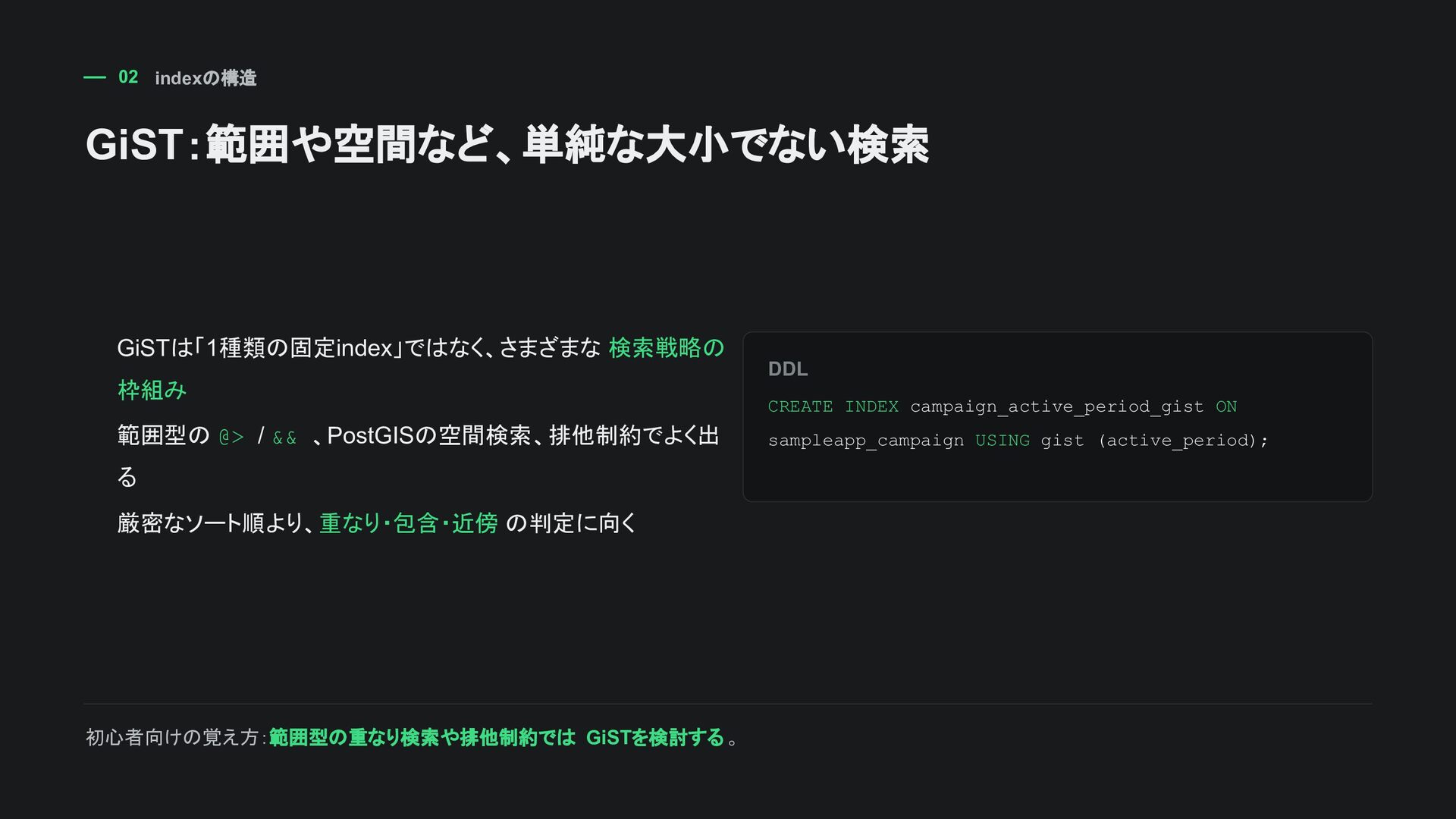
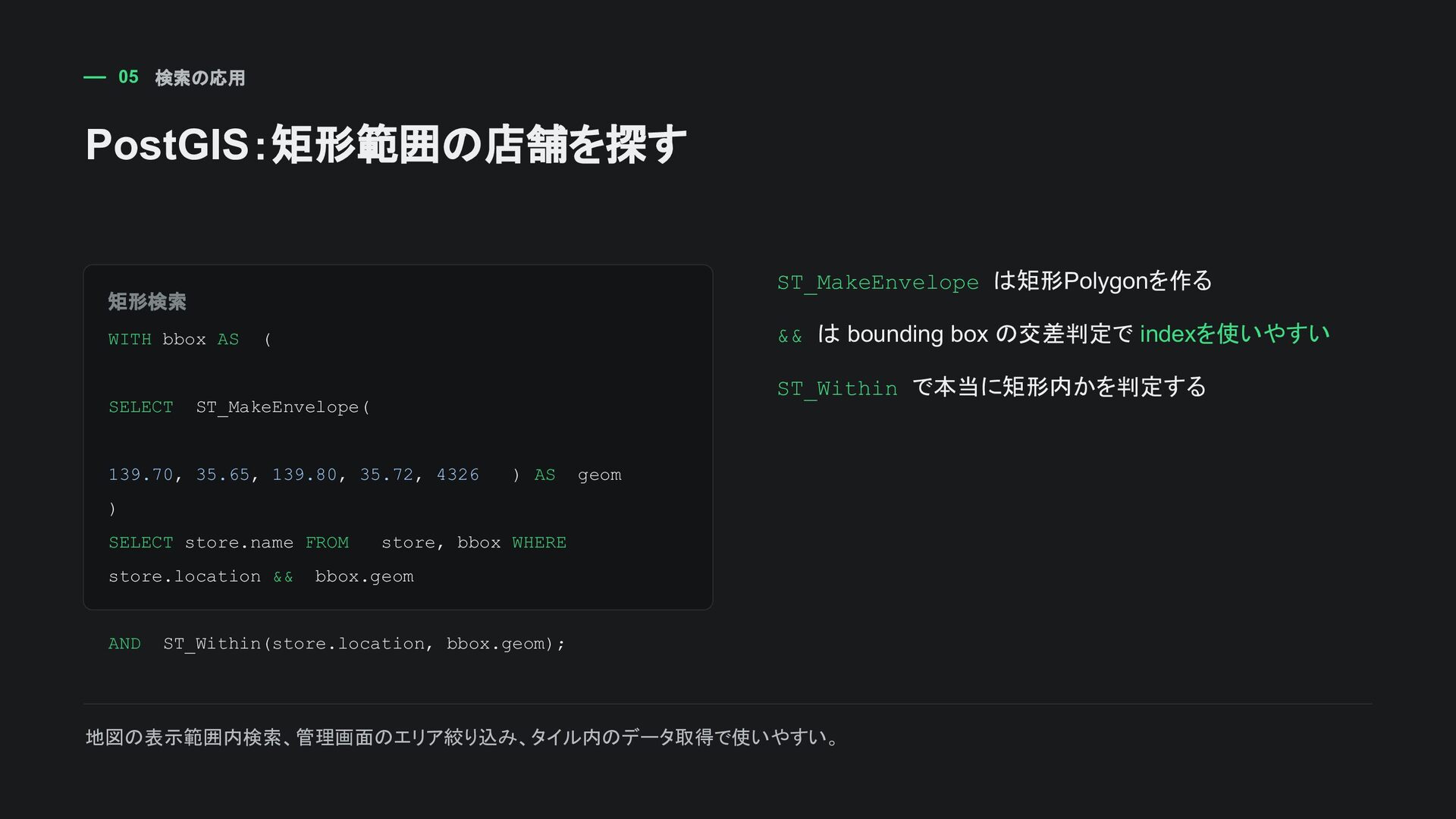
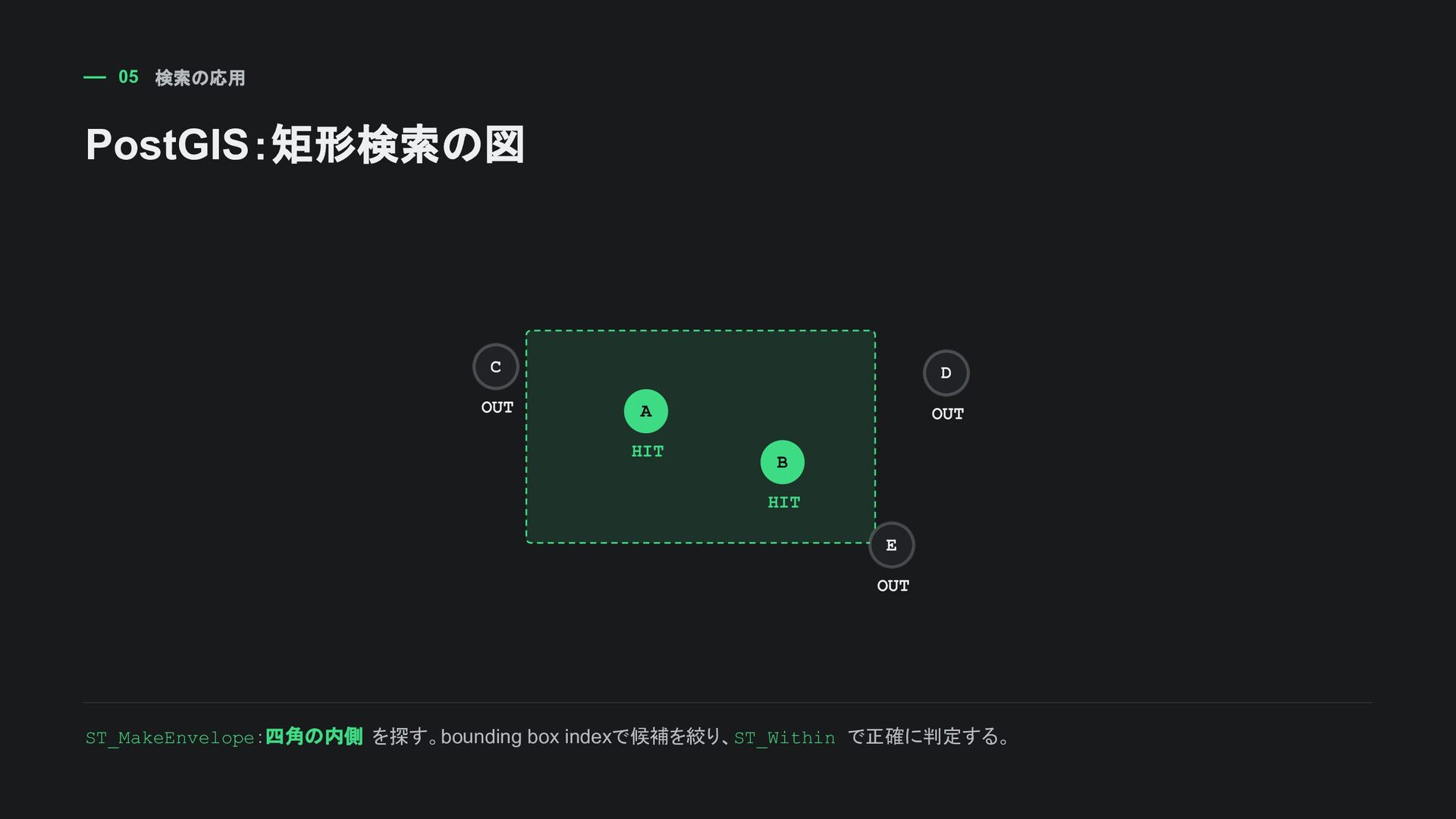
、PostGISの空間検索、排他制約でよく 出る 厳密なソート順より、重なり・包含・近傍 の判定に向く DDL CREATE INDEX campaign_active_period_gist ON sampleapp_campaign USING gist (active_period); 初心者向けの覚え方: 範囲型の重なり検索や排他制約ではGiSTを検討する。
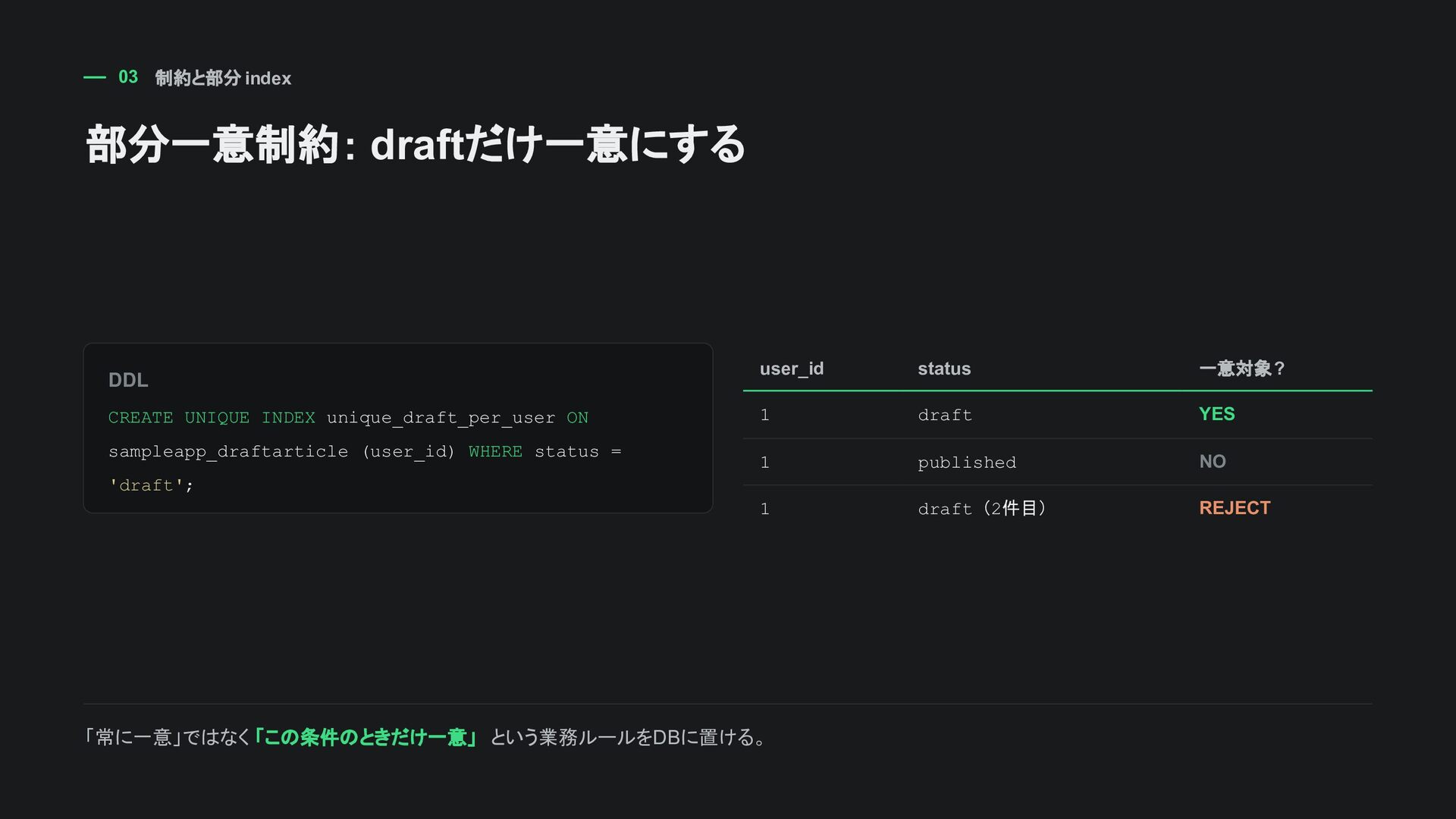
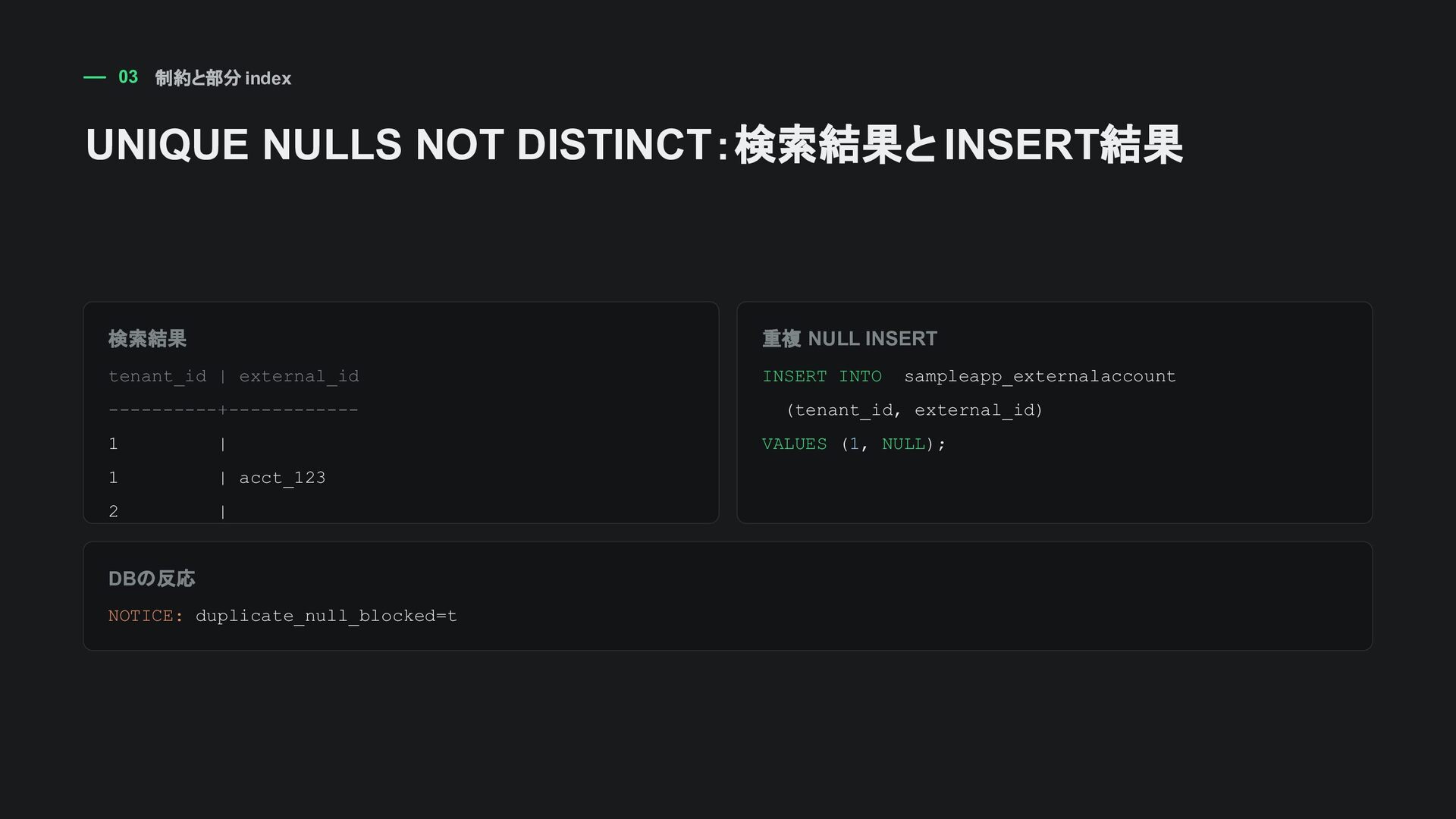
ON sampleapp_draftarticle (user_id) WHERE status = 'draft'; user_id status 一意対象? 1 draft YES 1 published NO 1 draft(2件目) REJECT 「常に一意」ではなく 「この条件のときだけ一意」 という業務ルールを DBに置ける。
NULL YES [email protected] 2026-06-xx NO この条件ならindexと合う SELECT email, name FROM sampleapp_customer WHERE email = '[email protected]' AND deleted_at IS NULL; 検索条件が部分indexのWHERE条件と 論理的に一致 するかを確認する。
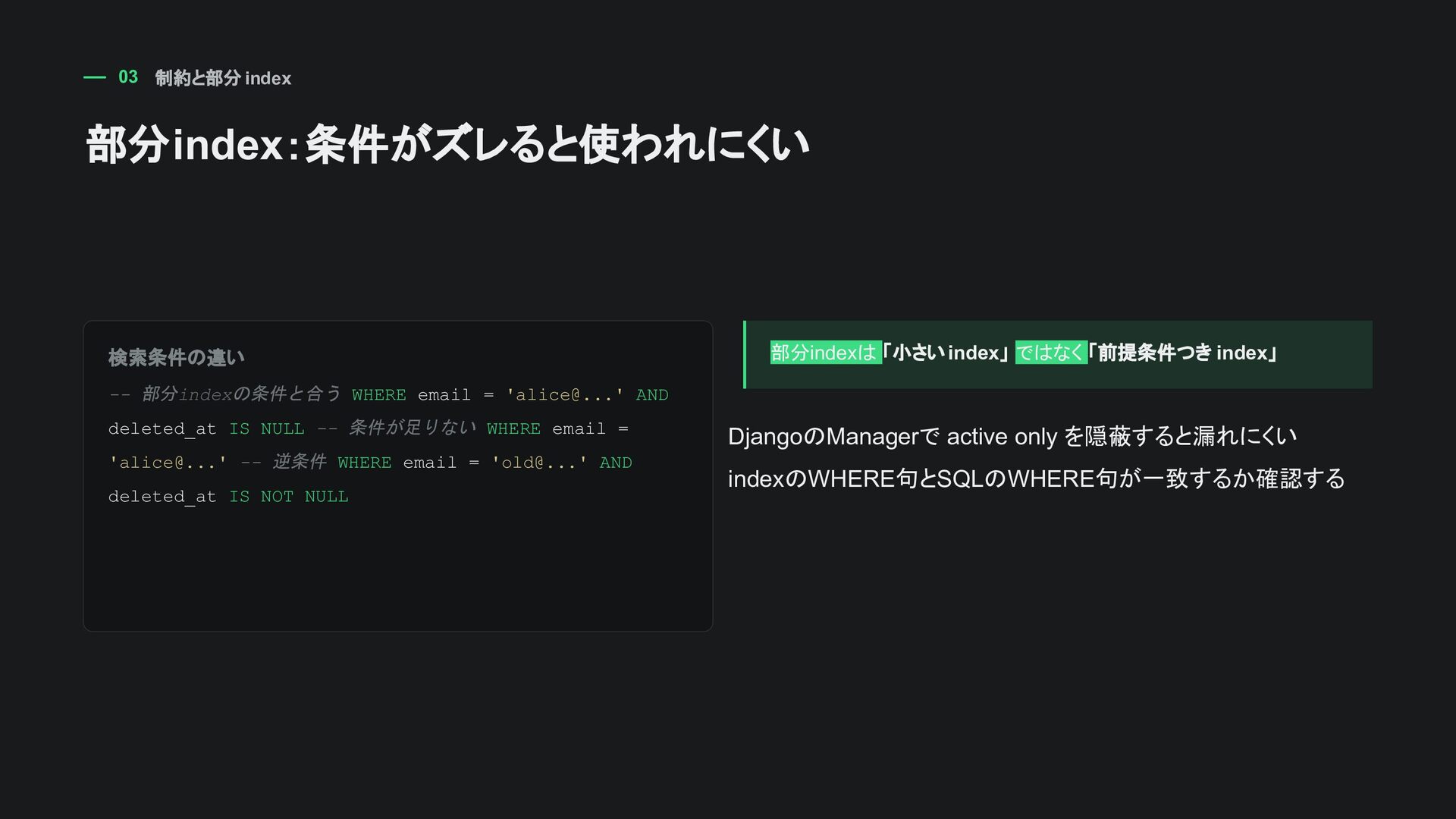
'alice@...' AND deleted_at IS NULL -- 条件が足りない WHERE email = 'alice@...' -- 逆条件 WHERE email = 'old@...' AND deleted_at IS NOT NULL 部分indexは 「小さいindex」 ではなく 「前提条件つきindex」 DjangoのManagerで active only を隠蔽すると漏れにくい indexのWHERE句とSQLのWHERE句が一致するか確認する
customer_lower_email_idx ON sampleapp_customer ((lower(email))); SELECT email, name FROM sampleapp_customer WHERE lower(email) = 'alice@...'; カバリングindex CREATE INDEX customer_email_inc_name_idx ON sampleapp_customer (email) INCLUDE (name); SELECT email, name FROM sampleapp_customer WHERE email = 'alice@...'; indexは 「よく実行するSQLの形」 に合わせて作る。式・ WHERE条件・返す列まで含めて考える。
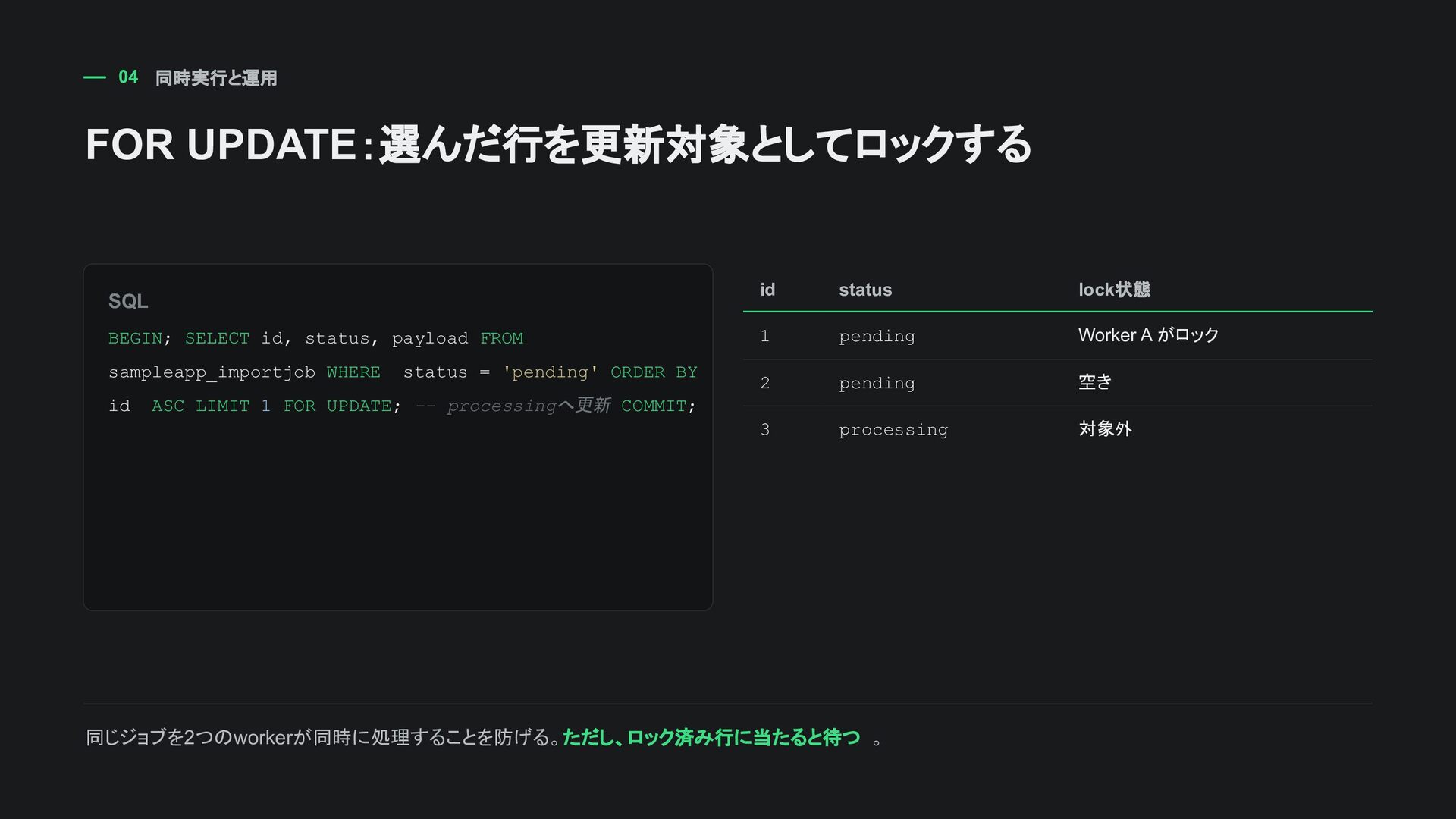
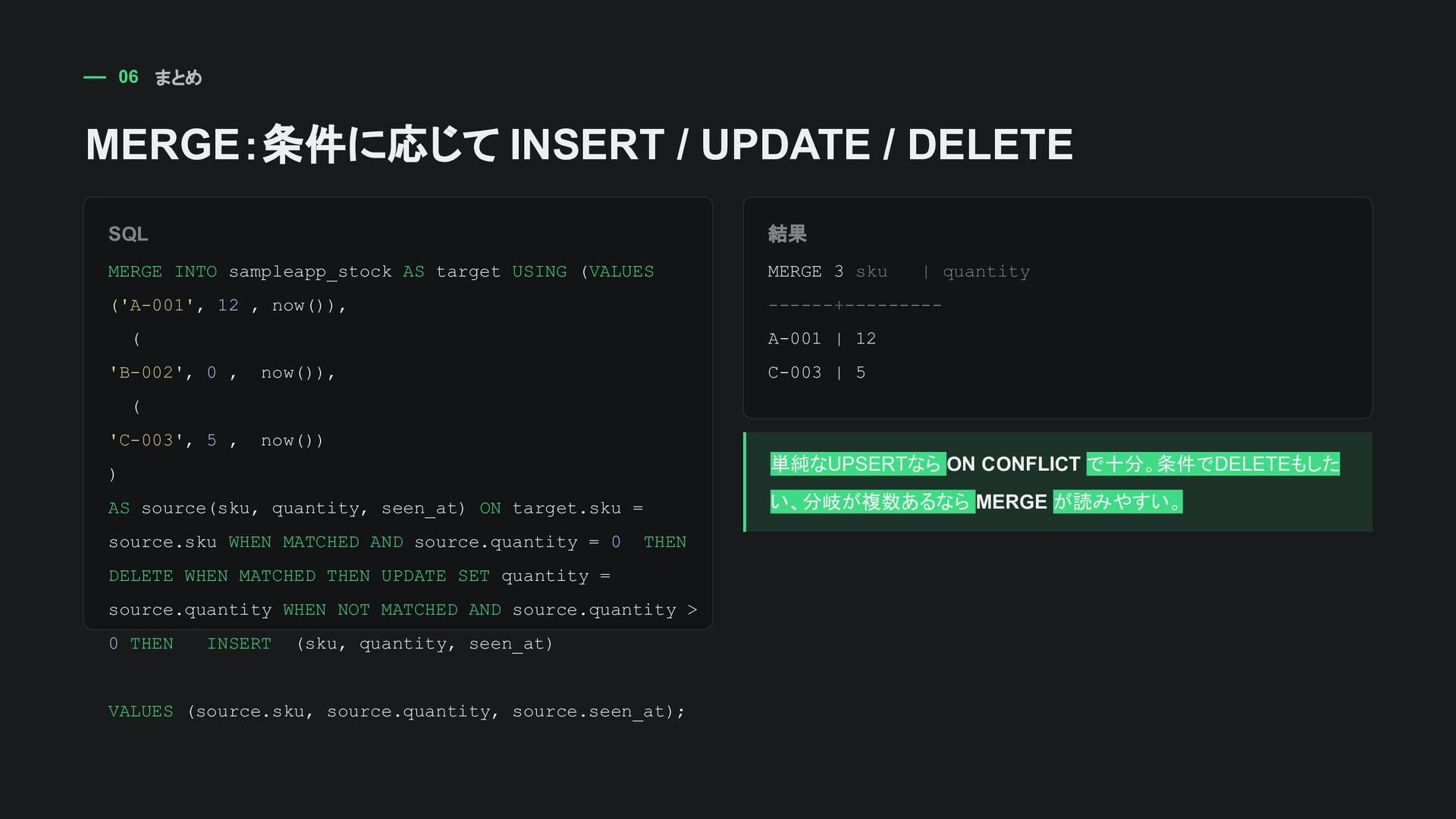
FROM sampleapp_importjob WHERE status = 'pending' ORDER BY id ASC LIMIT 1 FOR UPDATE; -- processingへ更新 COMMIT; id status lock状態 1 pending Worker A がロック 2 pending 空き 3 processing 対象外 同じジョブを2つのworkerが同時に処理することを防げる。 ただし、ロック済み行に当たると待つ。
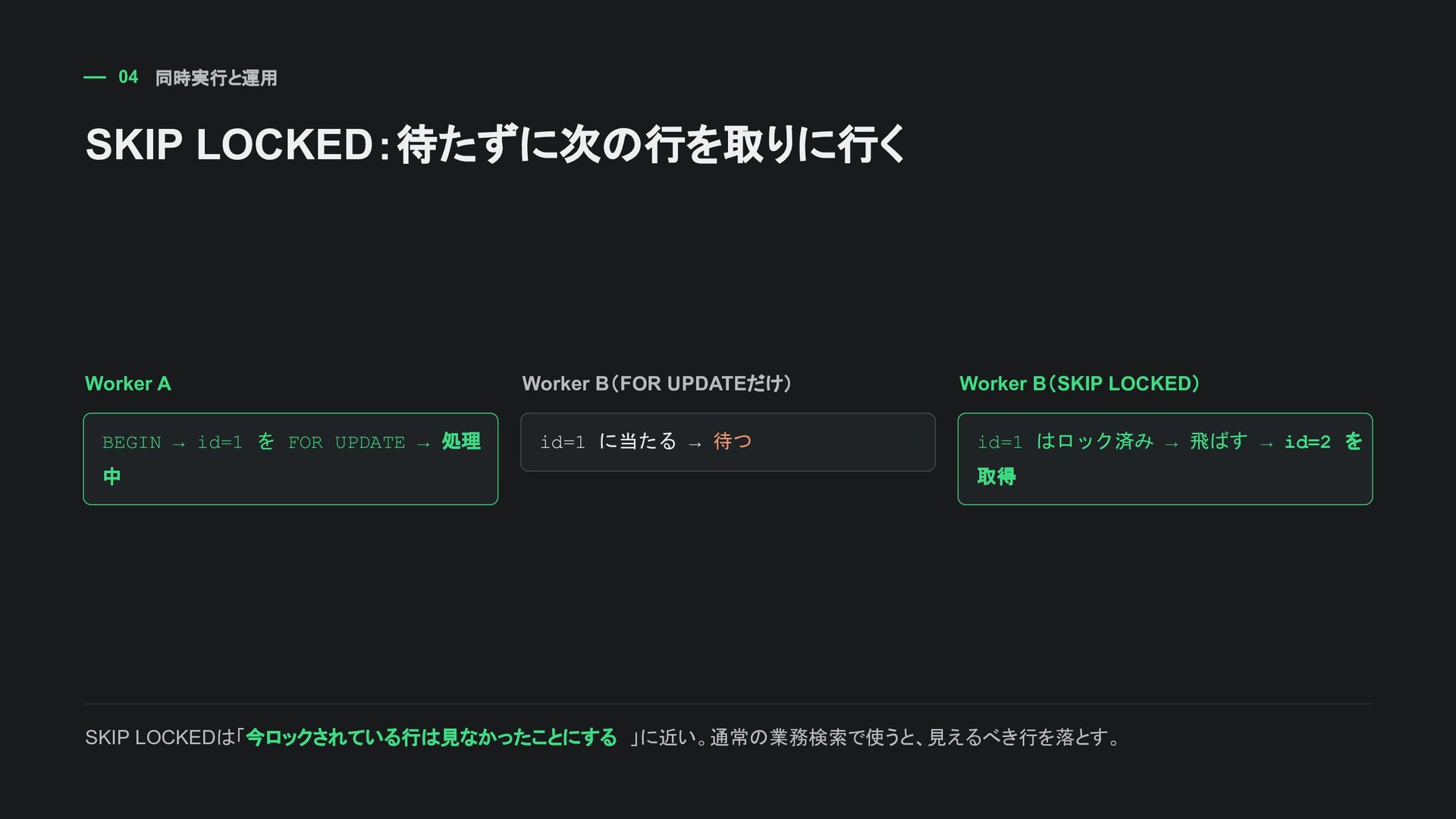
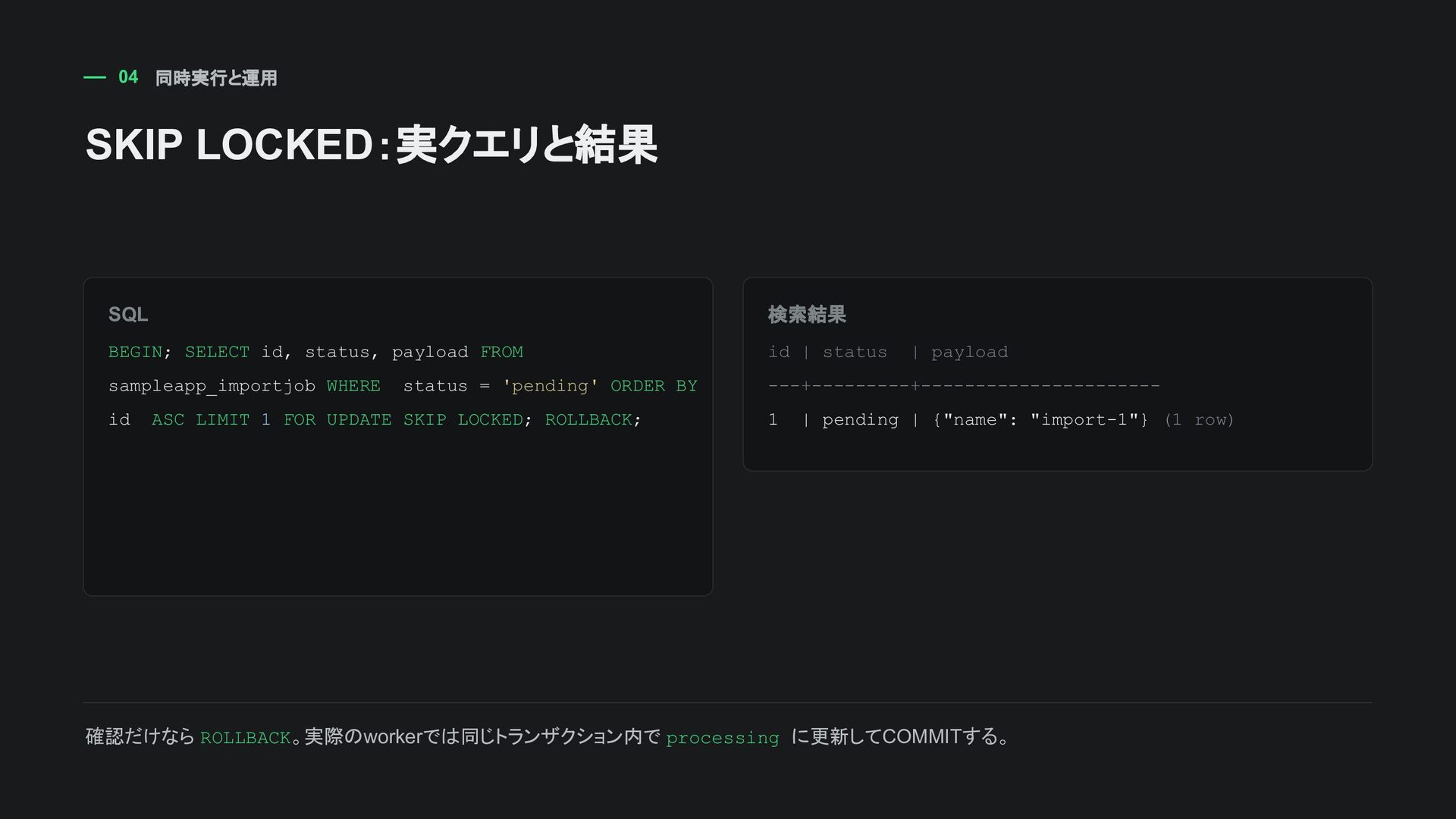
FROM sampleapp_importjob WHERE status = 'pending' ORDER BY id ASC LIMIT 1 FOR UPDATE SKIP LOCKED; ROLLBACK; 検索結果 id | status | payload ---+---------+---------------------- 1 | pending | {"name": "import-1"} (1 row) 確認だけなら ROLLBACK。実際のworkerでは同じトランザクション内で processing に更新してCOMMITする。
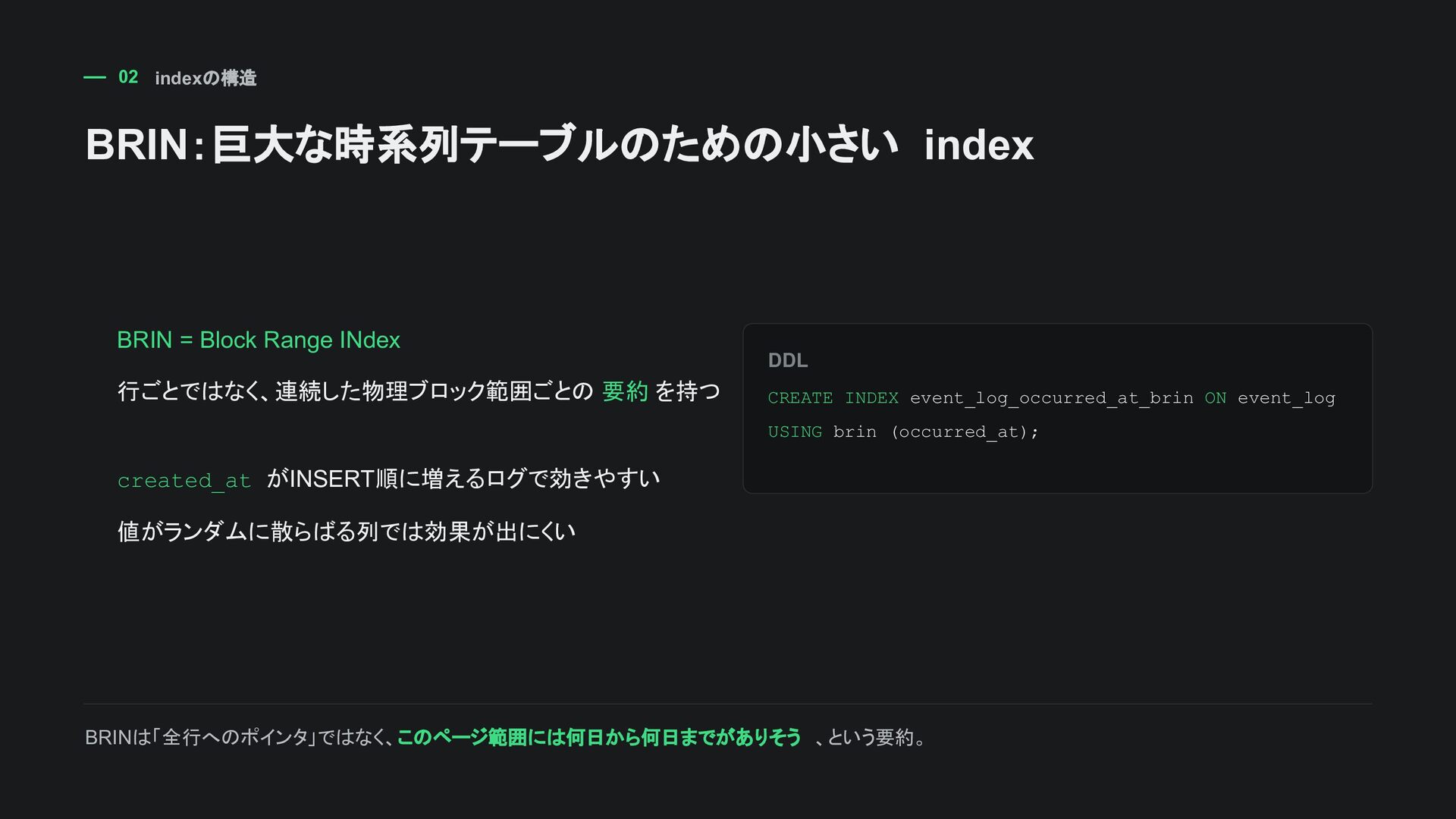
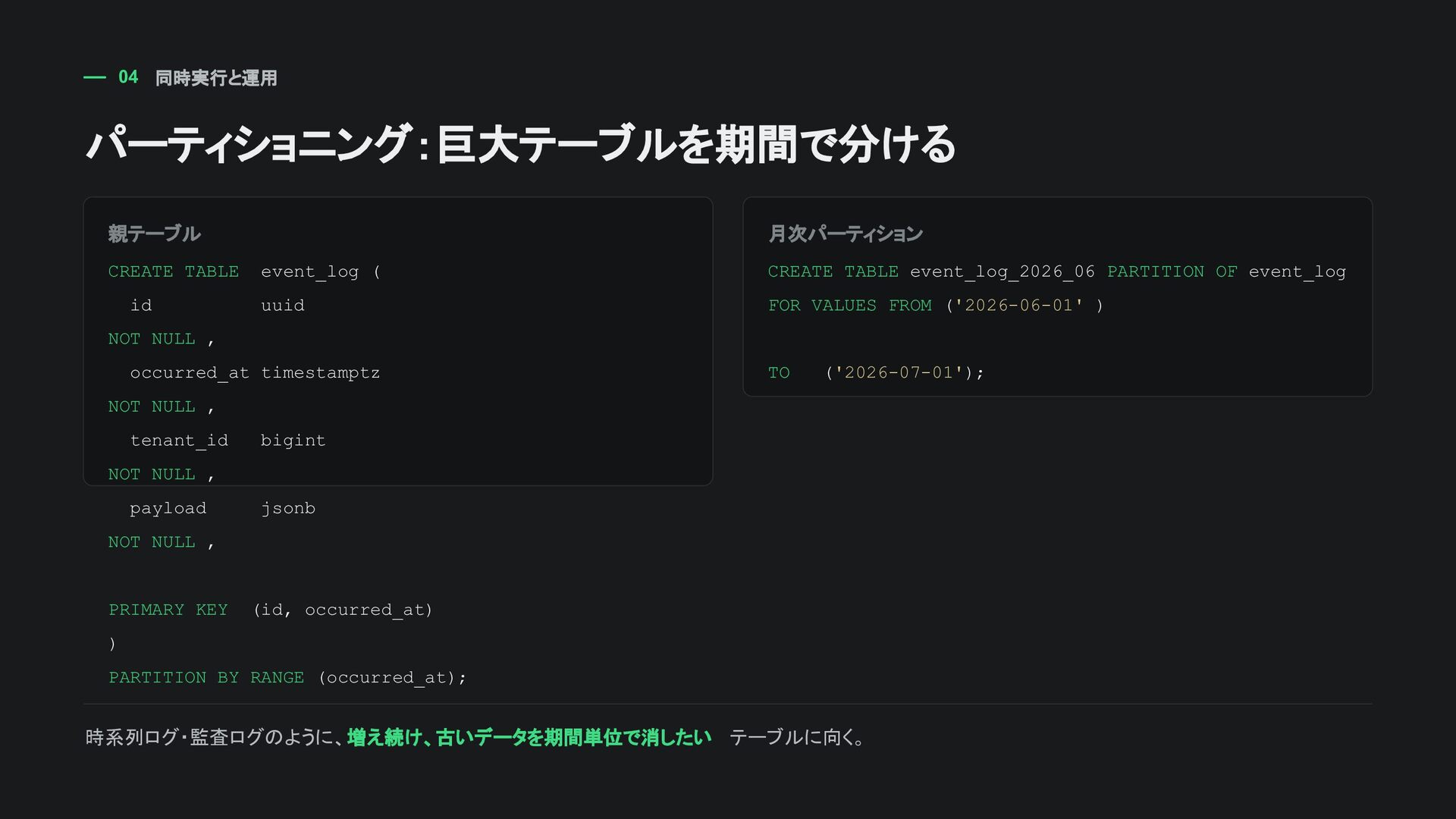
NOT NULL , occurred_at timestamptz NOT NULL , tenant_id bigint NOT NULL , payload jsonb NOT NULL , PRIMARY KEY (id, occurred_at) ) PARTITION BY RANGE (occurred_at); 月次パーティション CREATE TABLE event_log_2026_06 PARTITION OF event_log FOR VALUES FROM ('2026-06-01' ) TO ('2026-07-01'); 時系列ログ・監査ログのように、 増え続け、古いデータを期間単位で消したい テーブルに向く。
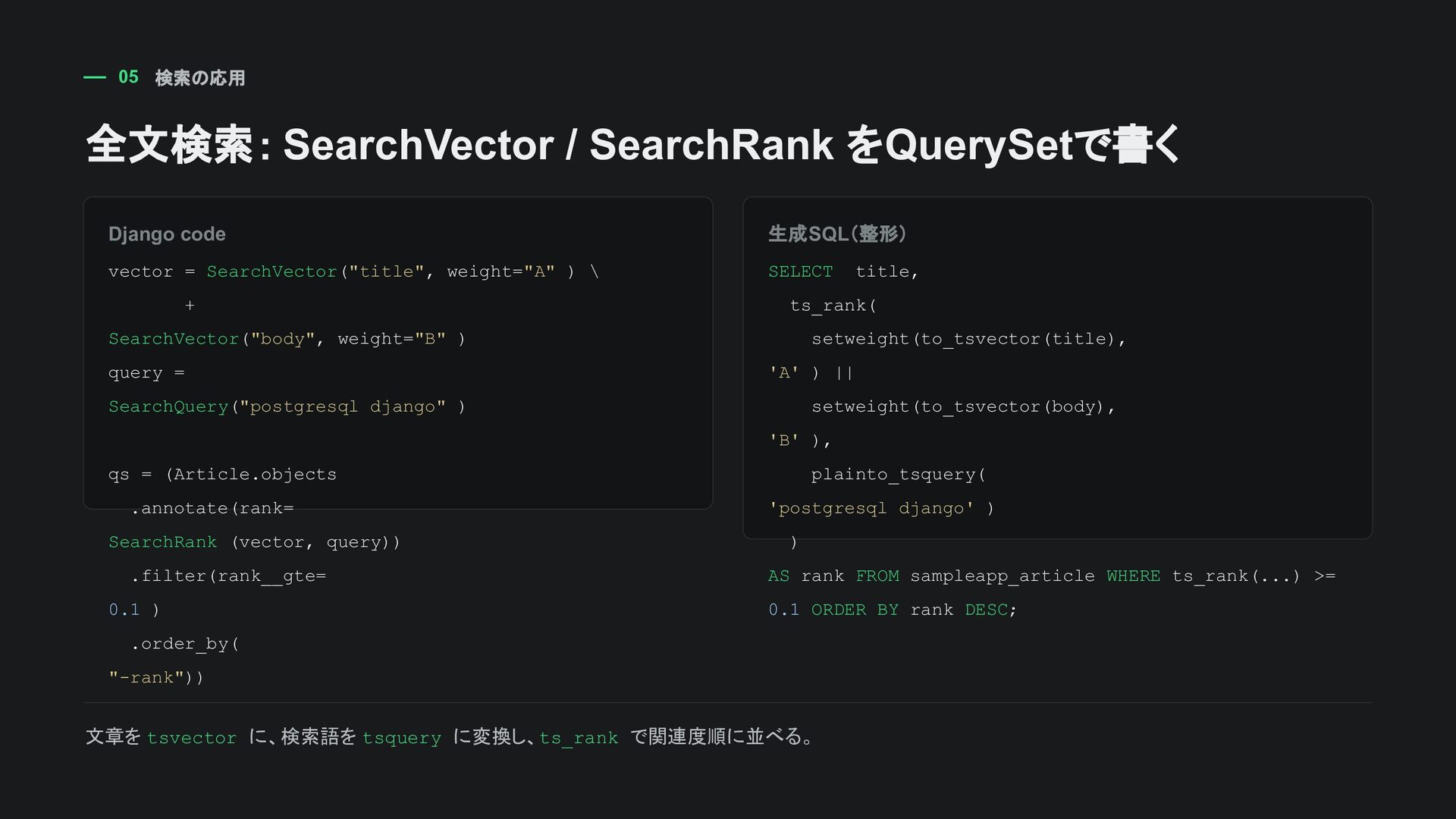
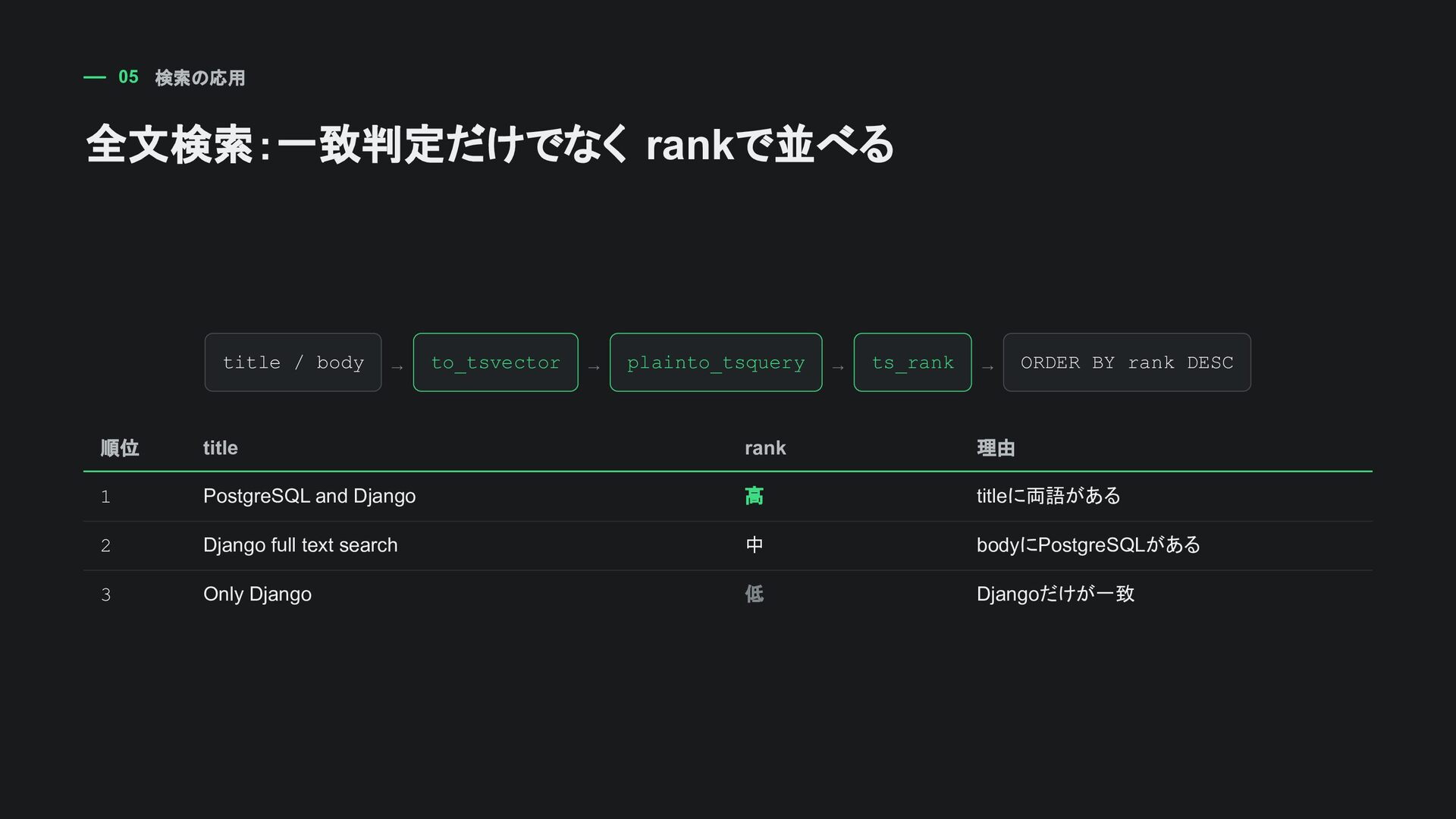
plainto_tsquery → ts_rank → ORDER BY rank DESC 順位 title rank 理由 1 PostgreSQL and Django 高 titleに両語がある 2 Django full text search 中 bodyにPostgreSQLがある 3 Only Django 低 Djangoだけが一致
NOT EXISTS pg_trgm; SELECT title, SIMILARITY(title, 'postgress') AS similarity FROM sampleapp_article WHERE SIMILARITY(title, 'postgress') > 0.2 ORDER BY similarity DESC; title 判定 意味 PostgreSQL and Django HIT 表記ゆれに近い Only Django OUT 類似度が低い Django full text search OUT titleが近くない pg_trgm は 3文字単位の類似度。短い語や日本語LIKEでは pg_bigm も検討する。
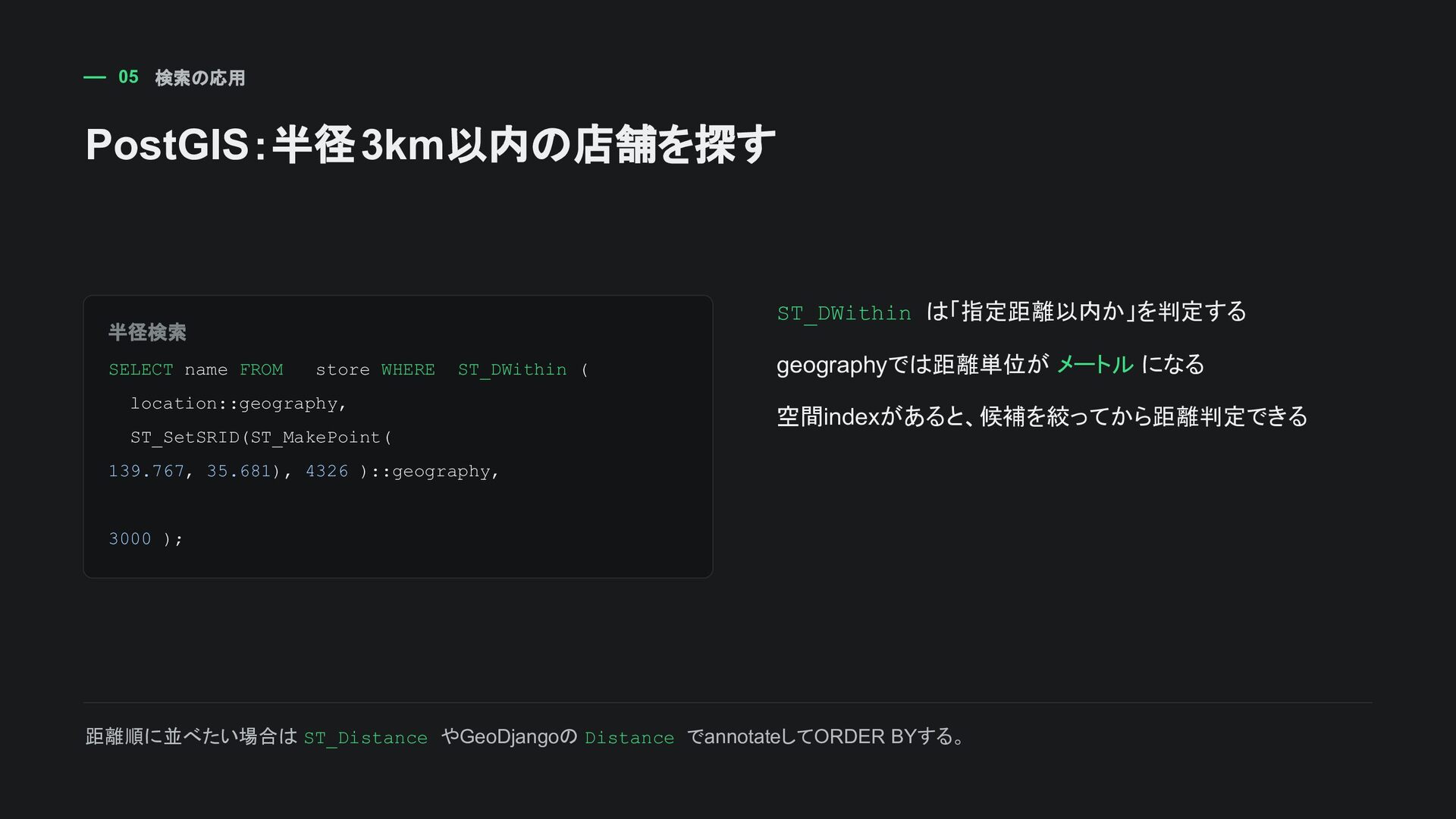
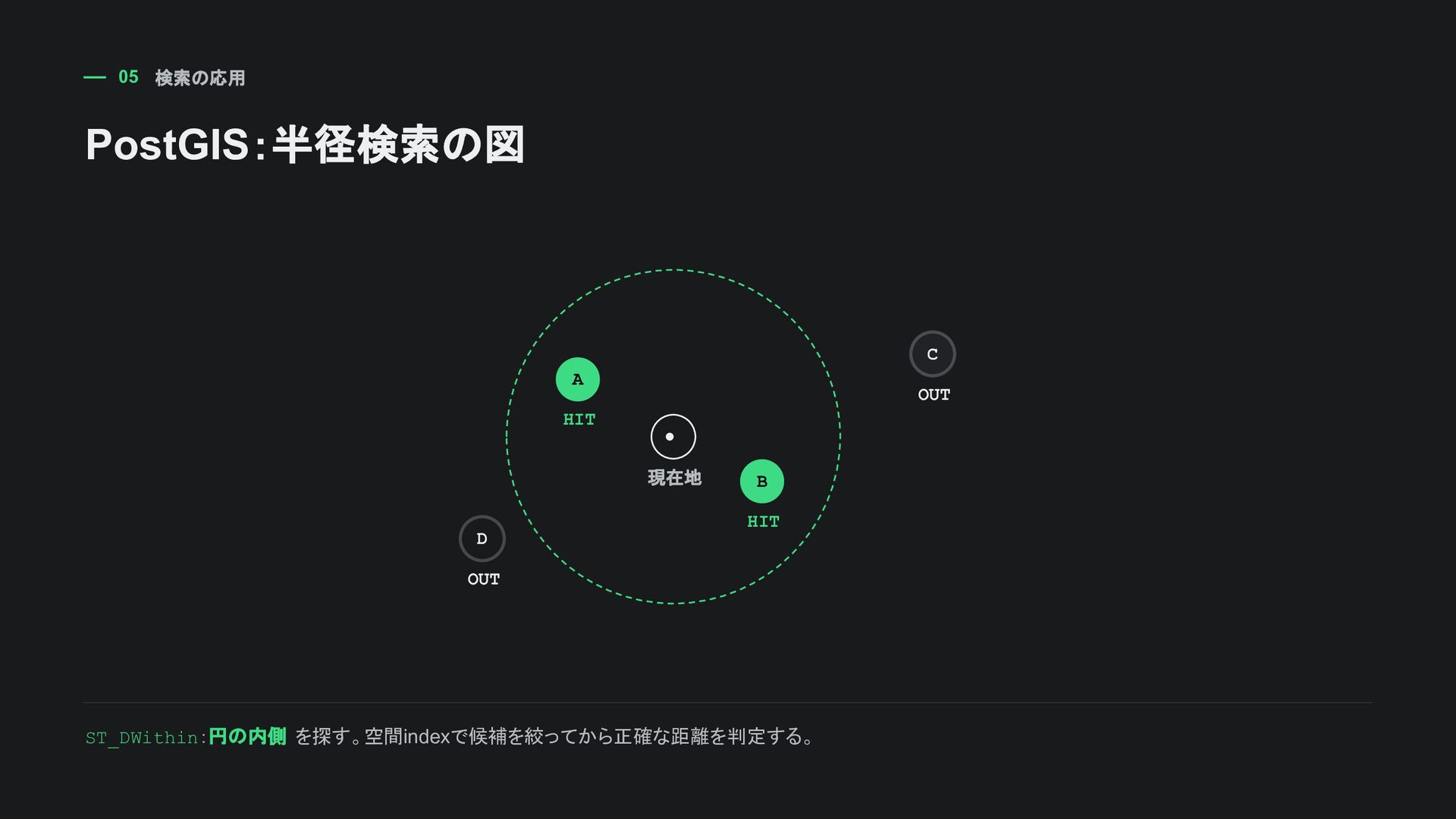
PointField(srid=4326) などで扱う DDL CREATE EXTENSION IF NOT EXISTS postgis; CREATE TABLE store ( id bigserial PRIMARY KEY , name text NOT NULL , location geometry(Point, 4326) NOT NULL ); 位置情報が ビジネスの中心 なら最初からPostGISを検討。単なる補助情報なら導入コストと相談。
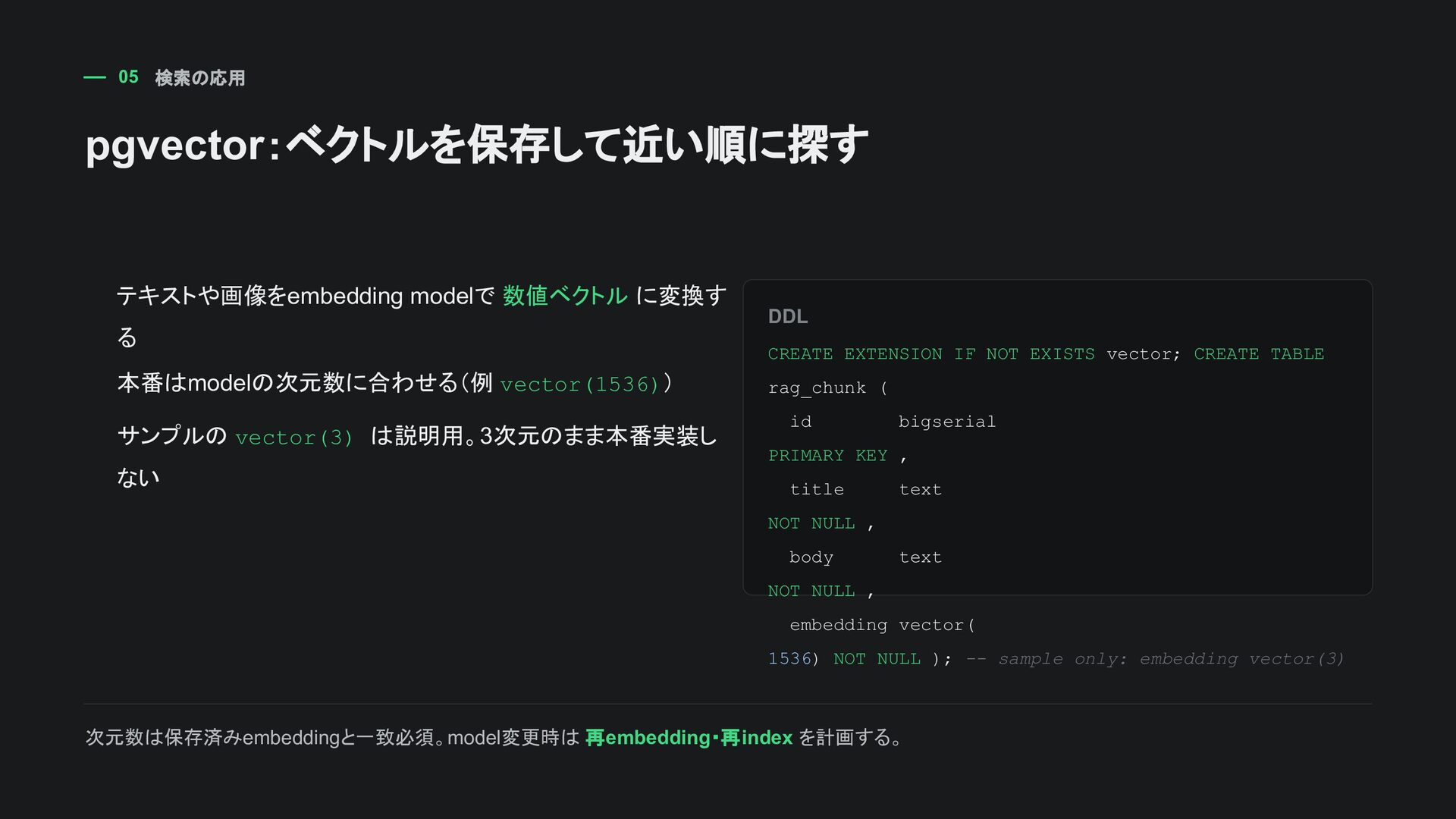
) サンプルの vector(3) は説明用。3次元のまま本番実装 しない DDL CREATE EXTENSION IF NOT EXISTS vector; CREATE TABLE rag_chunk ( id bigserial PRIMARY KEY , title text NOT NULL , body text NOT NULL , embedding vector( 1536) NOT NULL ); -- sample only: embedding vector(3) 次元数は保存済みembeddingと一致必須。model変更時は 再embedding・再index を計画する。
) AS cosine_distance FROM sampleapp_ragchunk ORDER BY embedding <=> '[0.9,0.1,0.2]' LIMIT 3; 検索結果 title | cosine_distance -----------------------+---------------- JSONField and jsonb | 0.000000 pgvector for RAG | 0.004004 PostgreSQL range types | 0.618754 <=> は cosine距離。距離が小さいほど近い。実運用は利用モデルの次元に合わせた query embeddingを渡す。
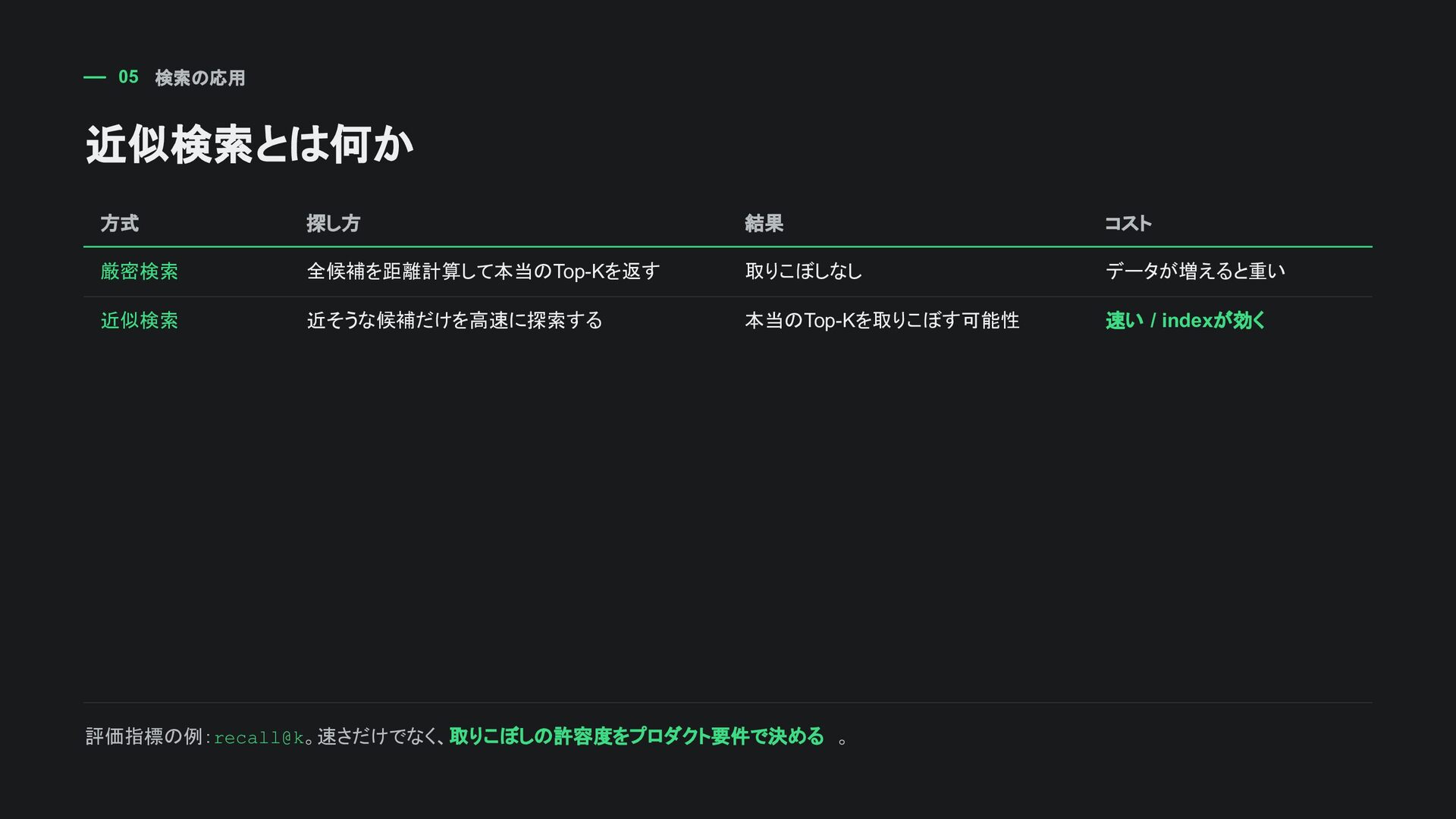
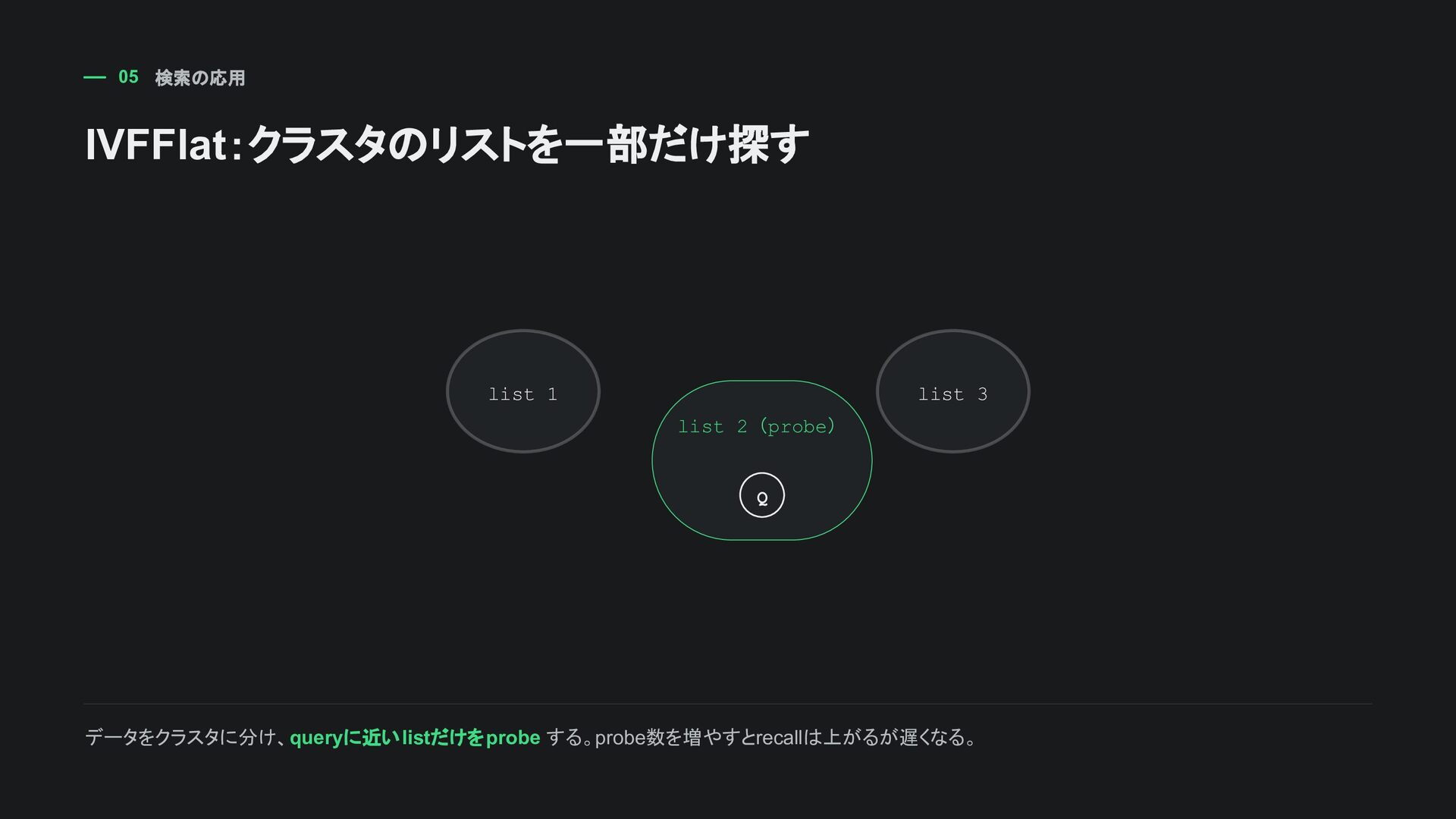
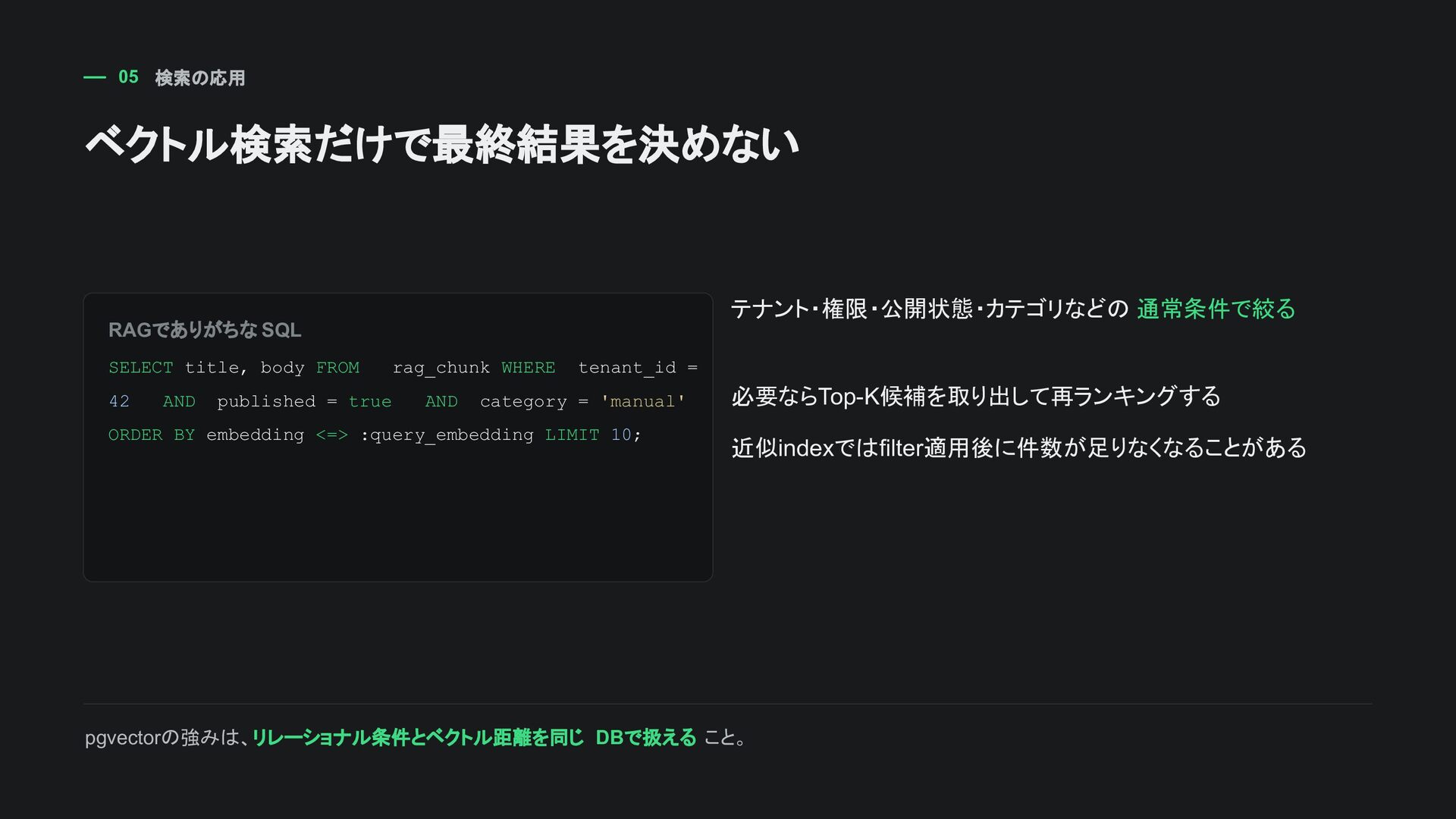
tenant_id = 42 AND published = true AND category = 'manual' ORDER BY embedding <=> :query_embedding LIMIT 10; テナント・権限・公開状態・カテゴリなどの 通常条件で絞る 必要ならTop-K候補を取り出して再ランキングする 近似indexではfilter適用後に件数が足りなくなることがある pgvectorの強みは、リレーショナル条件とベクトル距離を同じ DBで扱える こと。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![02 indexの構造 B+tree:ソートされたキーから行を探す root [ m ] internal [ a](https://files.speakerdeck.com/presentations/b1af7e620edb4cba8fe644ebf006e1d6/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![03 制約と部分 index 部分index:対象になる行 / ならない行 email deleted_at index対象? [email protected]](https://files.speakerdeck.com/presentations/b1af7e620edb4cba8fe644ebf006e1d6/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![05 検索の応用 pgvector:実クエリと検索結果 SQL SELECT title, round((embedding <=> '[0.9,0.1,0.2]')::numeric, 6](https://files.speakerdeck.com/presentations/b1af7e620edb4cba8fe644ebf006e1d6/slide_66.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}