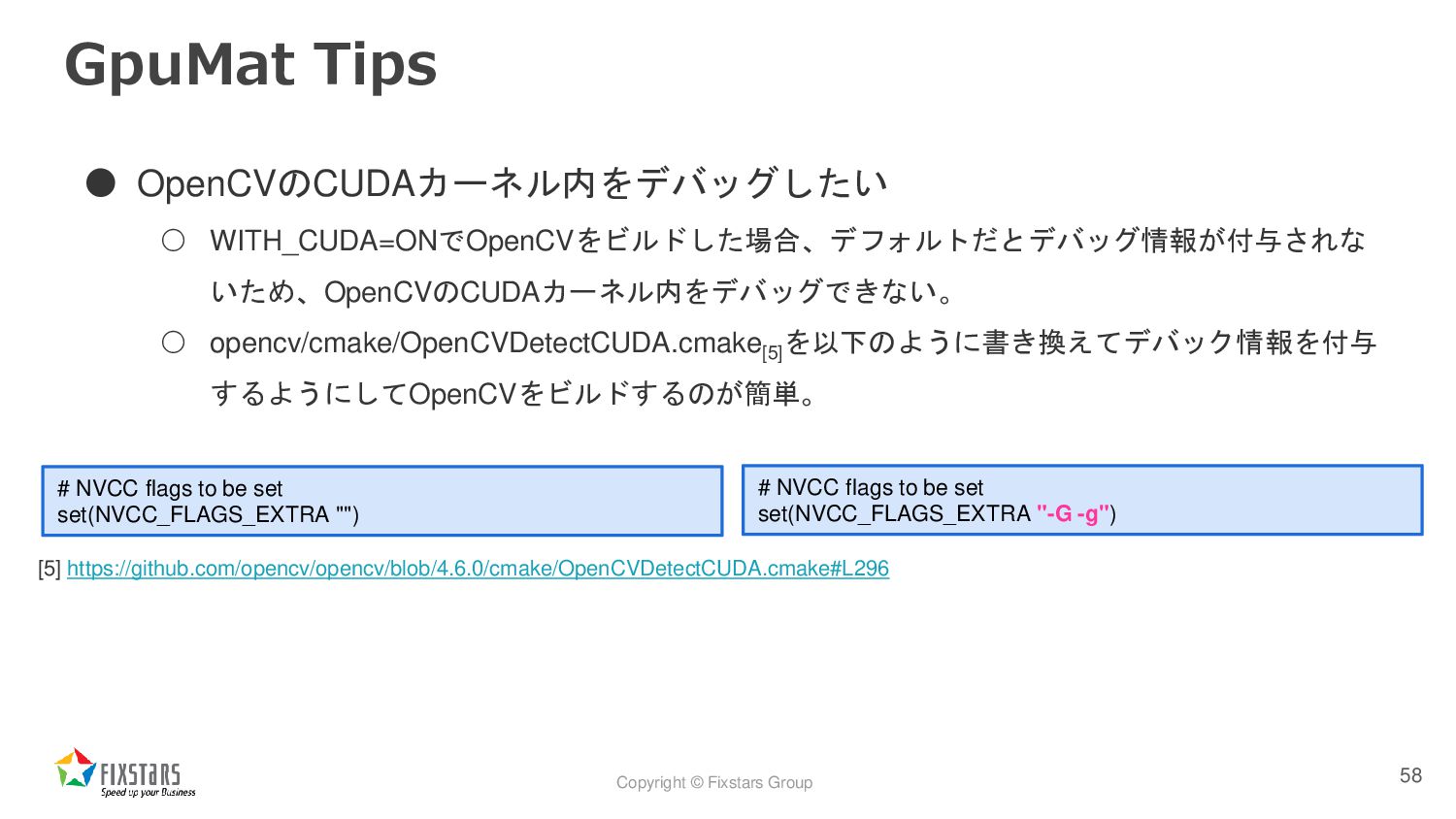
いため、OpenCVのCUDAカーネル内をデバッグできない。 ◦ opencv/cmake/OpenCVDetectCUDA.cmake[5] を以下のように書き換えてデバック情報を付与 するようにしてOpenCVをビルドするのが簡単。 58 [5] https://github.com/opencv/opencv/blob/4.6.0/cmake/OpenCVDetectCUDA.cmake#L296 # NVCC flags to be set set(NVCC_FLAGS_EXTRA "") # NVCC flags to be set set(NVCC_FLAGS_EXTRA "-G -g")
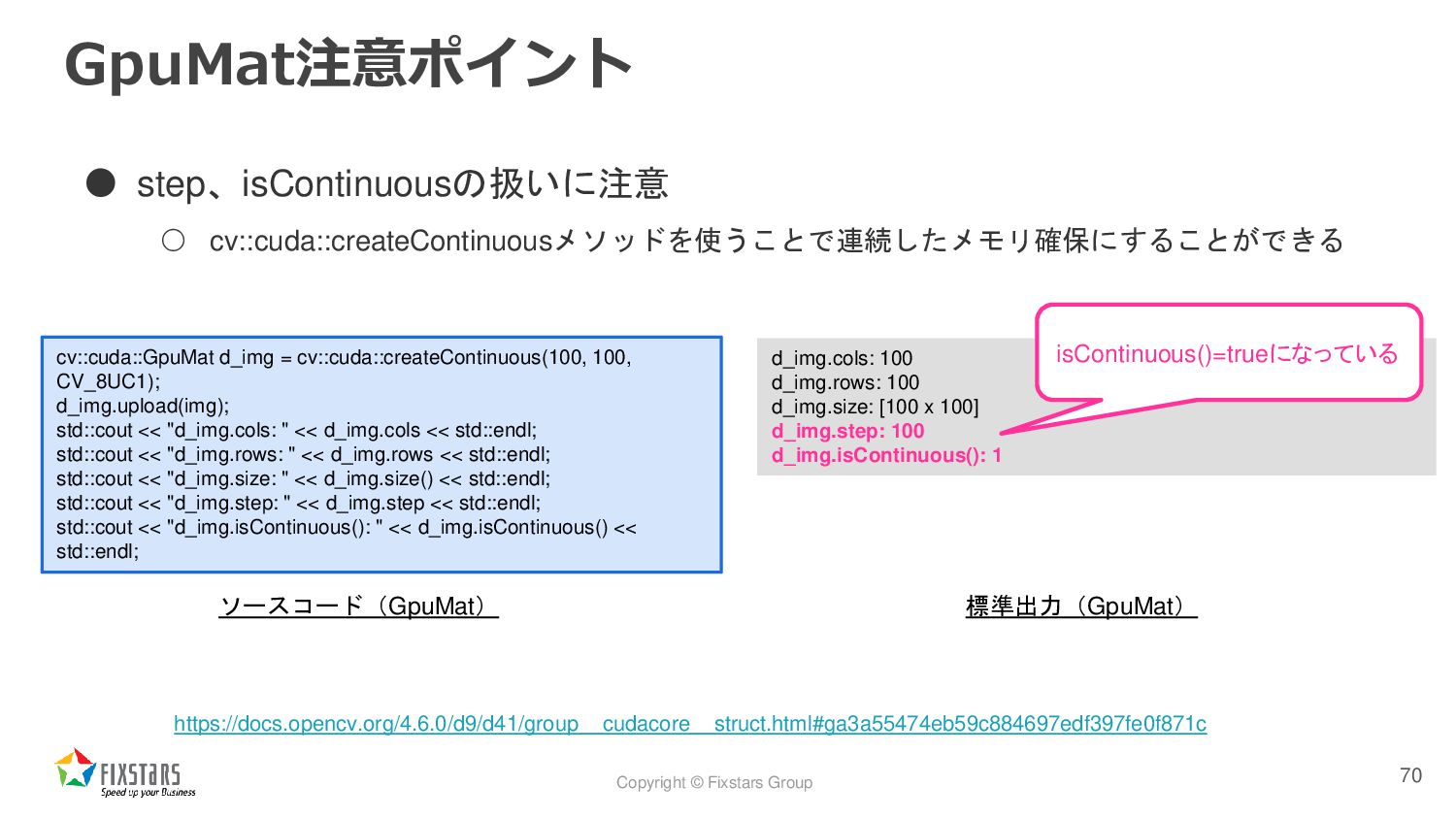
◦ GpuMatの画像バッファのメモリは、ハードウェアに依存してアラインメントされるため、多 くのケースではisContinuous()==falseとなることに気を付ける ▪ 例外として行数が1のGpuMatクラスのインスタンスはisContinuous()==trueとなる 67 In contrast with Mat, in most cases GpuMat::isContinuous() == false . This means that rows are aligned to a size depending on the hardware. Single-row GpuMat is always a continuous matrix.
GpuMatクラスのインスタンスをstatic、グローバル変数として確保することは非推奨となっ ている 74 You are not recommended to leave static or global GpuMat variables allocated, that is, to rely on its destructor. The destruction order of such variables and CUDA context is undefined. GPU memory release function returns error if the CUDA context has been destroyed before.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
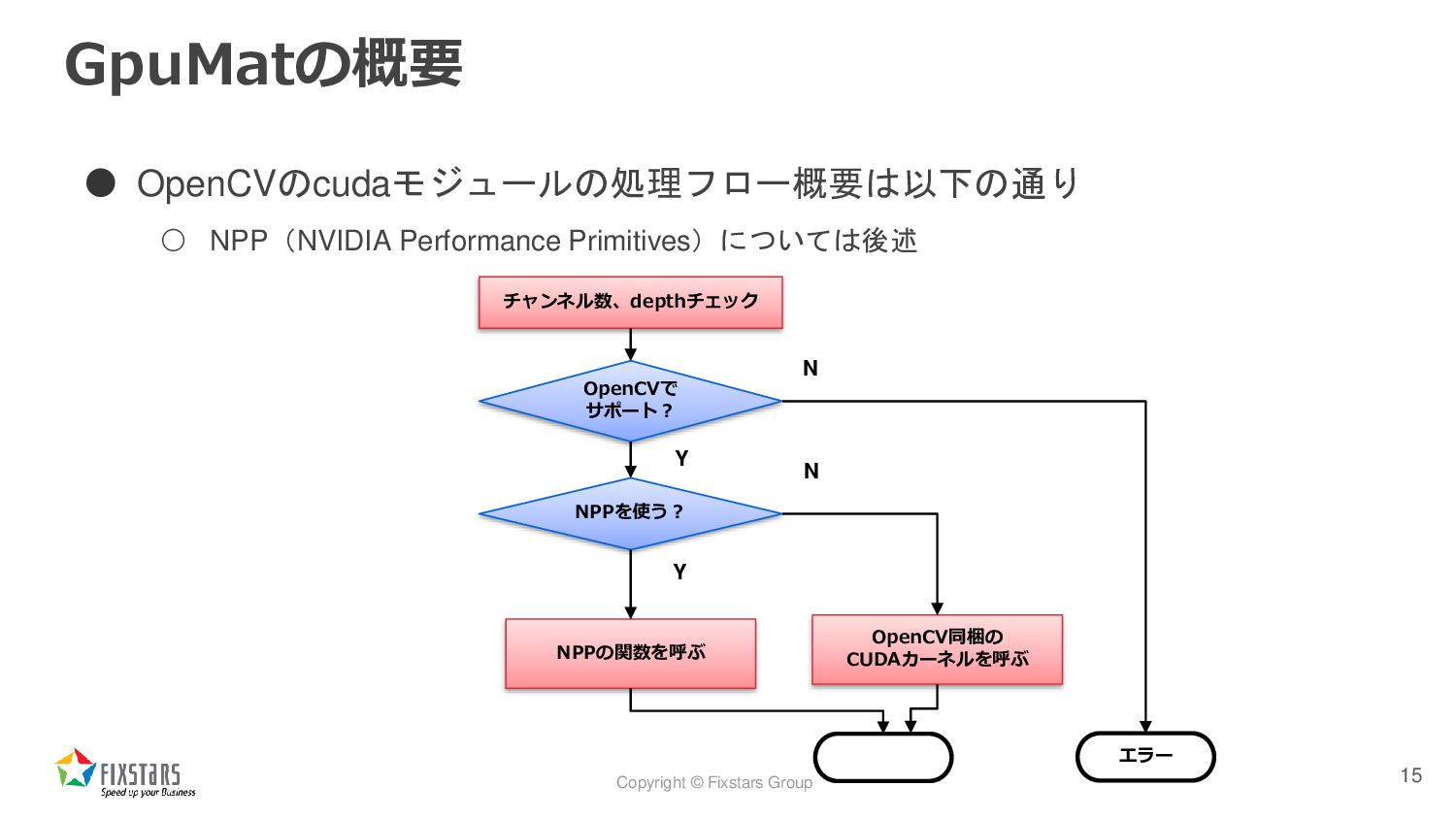
![Copyright © Fixstars Group GpuMatの概要 • OpenCV[1] は、NVIDIA GPUに処理をオフロードするためのデータ構造として GpuMatクラス](https://files.speakerdeck.com/presentations/d8a941fbf1ca459b948662c027a82af1/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
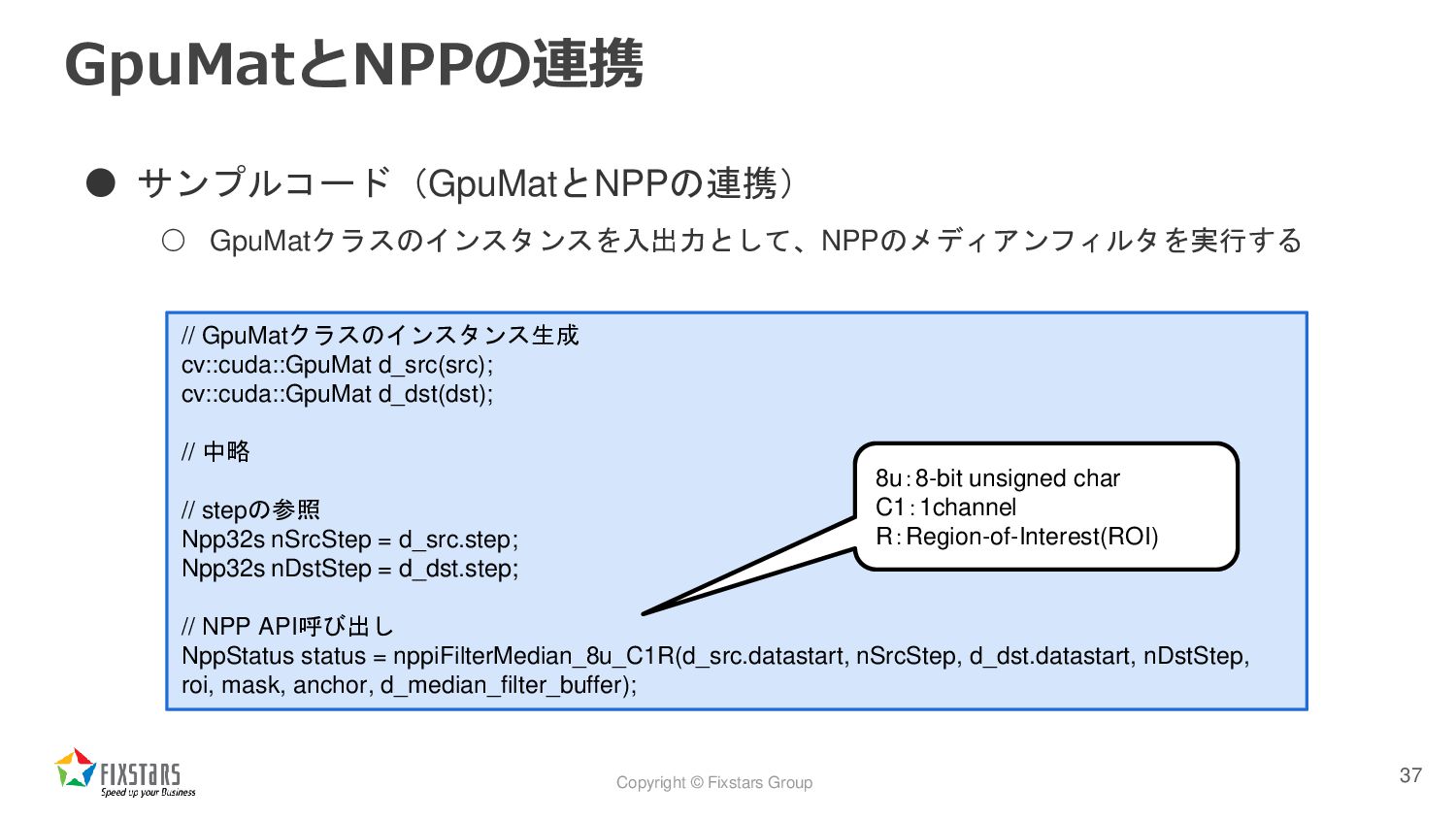
![Copyright © Fixstars Group GpuMatとNPPの連携 • NPP[3] とは ◦ NVIDIA](https://files.speakerdeck.com/presentations/d8a941fbf1ca459b948662c027a82af1/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
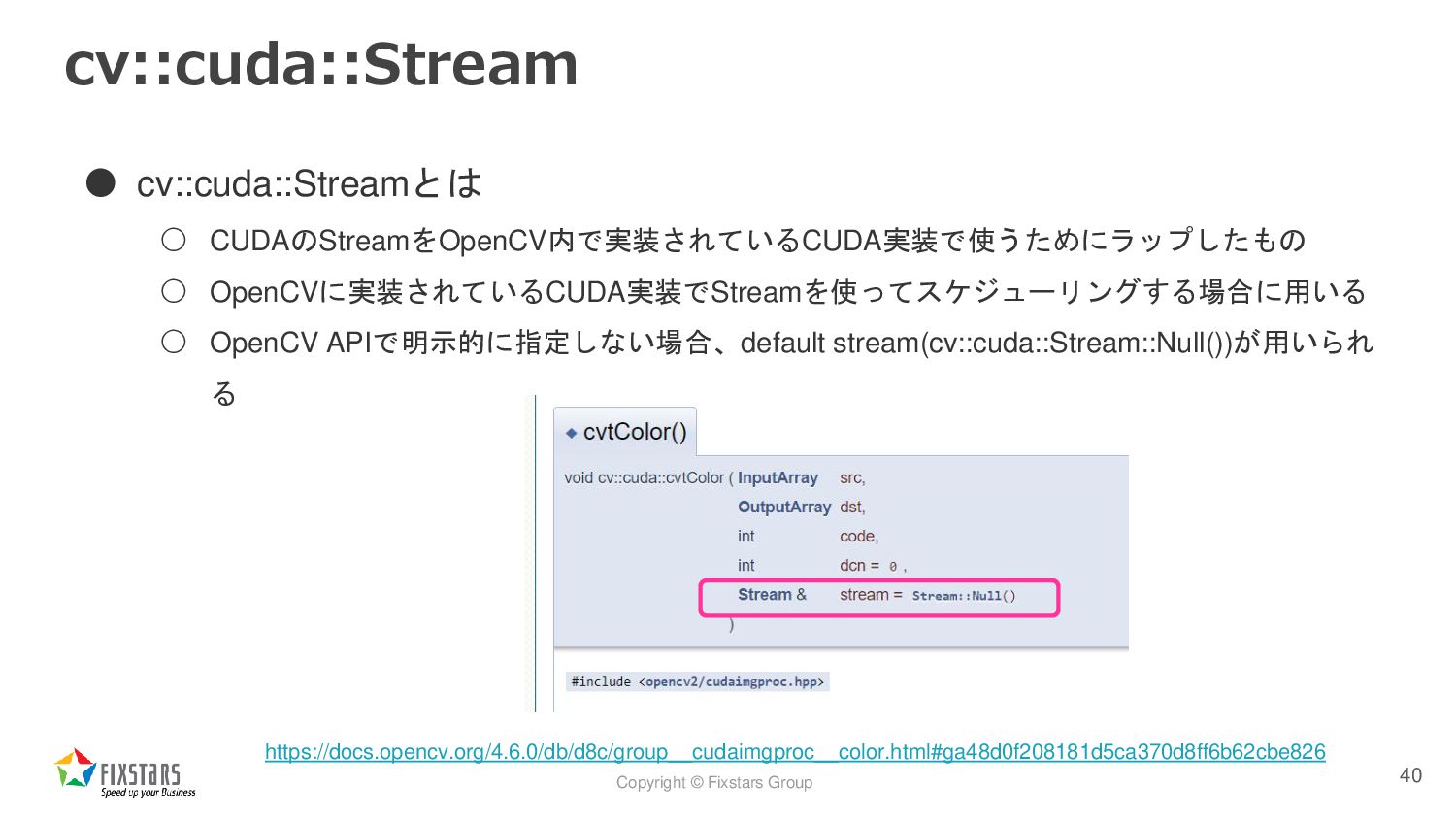
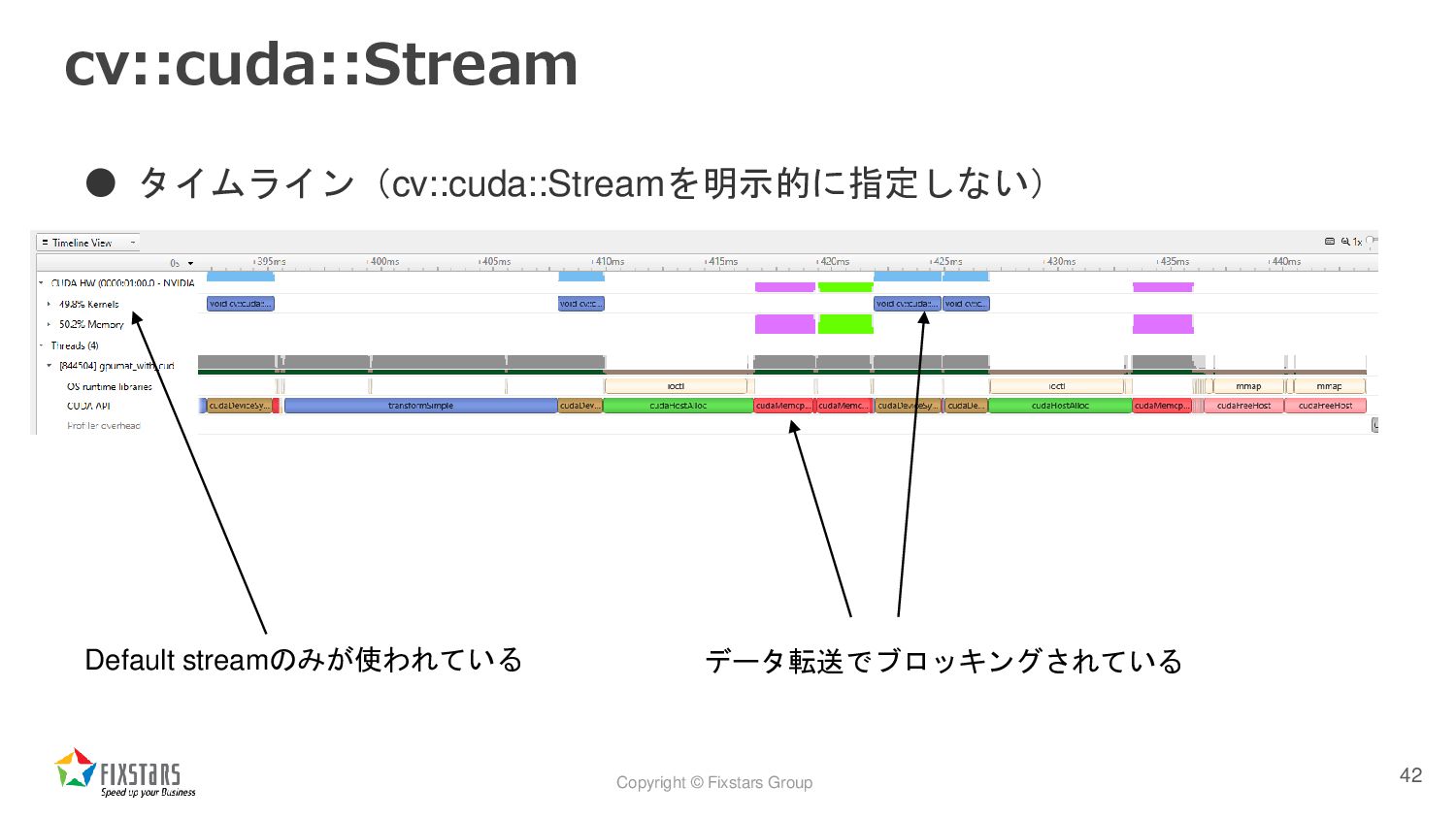
![Copyright © Fixstars Group cv::cuda::Stream • サンプルコード(cv::cuda::Streamを明示的に指定しない) 41 cv::cuda::HostMem gray[2];](https://files.speakerdeck.com/presentations/d8a941fbf1ca459b948662c027a82af1/slide_40.jpg){kind=link}
{kind=link}
![Copyright © Fixstars Group cv::cuda::Stream • サンプルコード(cv::cuda::Streamを明示的に指定する) 43 cv::cuda::HostMem gray[2];](https://files.speakerdeck.com/presentations/d8a941fbf1ca459b948662c027a82af1/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
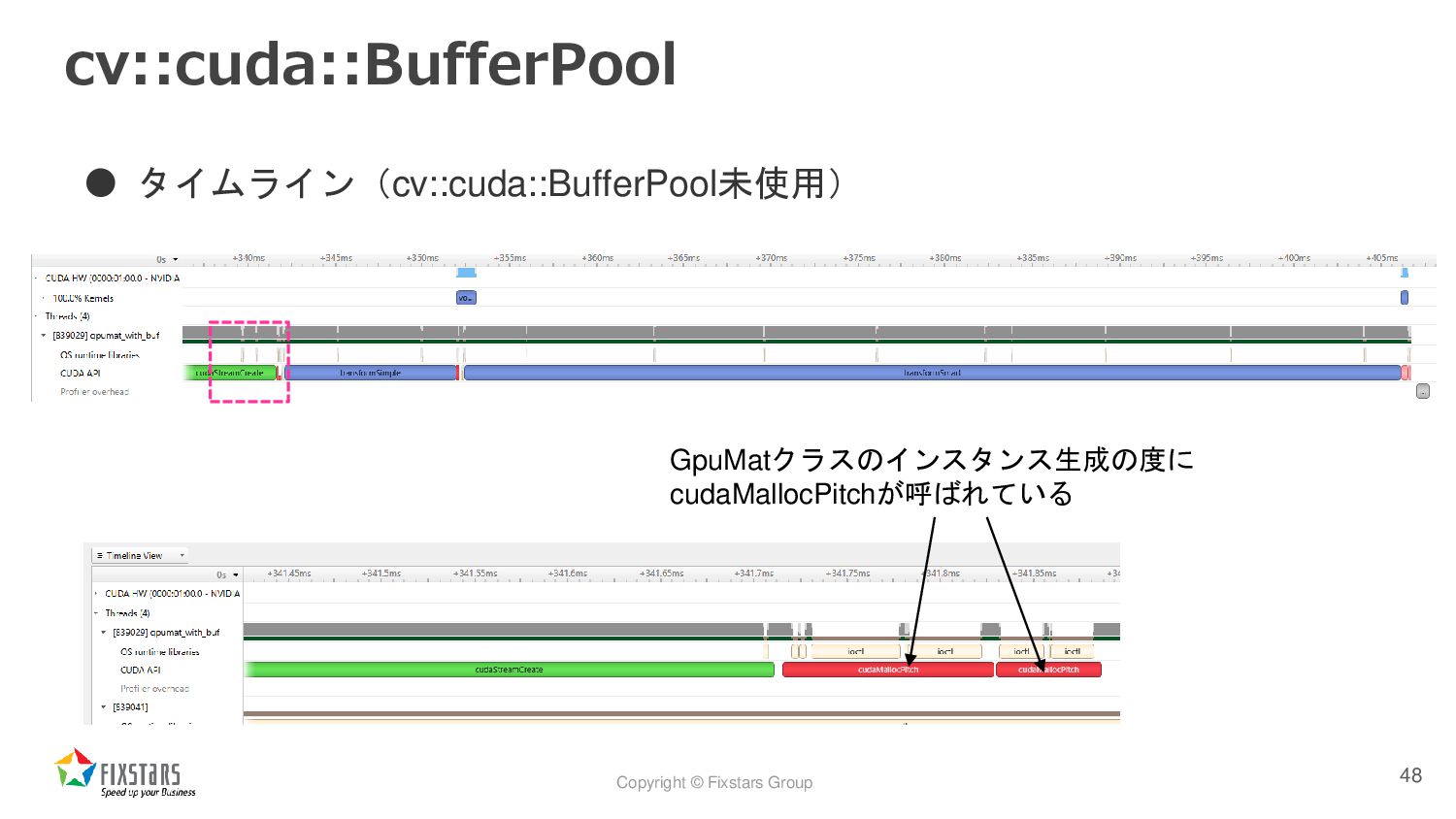
![Copyright © Fixstars Group cv::cuda::BufferPool • cv::cuda::BufferPool[4] とは ◦ あらかじめ確保したGPUのデバイスメモリ領域領域からGpuMatのメモリを割り当てることが](https://files.speakerdeck.com/presentations/d8a941fbf1ca459b948662c027a82af1/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Copyright © Fixstars Group OpenCVコントリビューション活動事例 • 弊社で開発したlibSGM[6] がOpenCVのcudastereoモジュールにマージされて います ◦](https://files.speakerdeck.com/presentations/d8a941fbf1ca459b948662c027a82af1/slide_74.jpg){kind=link}
{kind=link}
![Copyright © Fixstars Group Thank you! お問い合わせ窓口 : [email protected]](https://files.speakerdeck.com/presentations/d8a941fbf1ca459b948662c027a82af1/slide_76.jpg){kind=link}