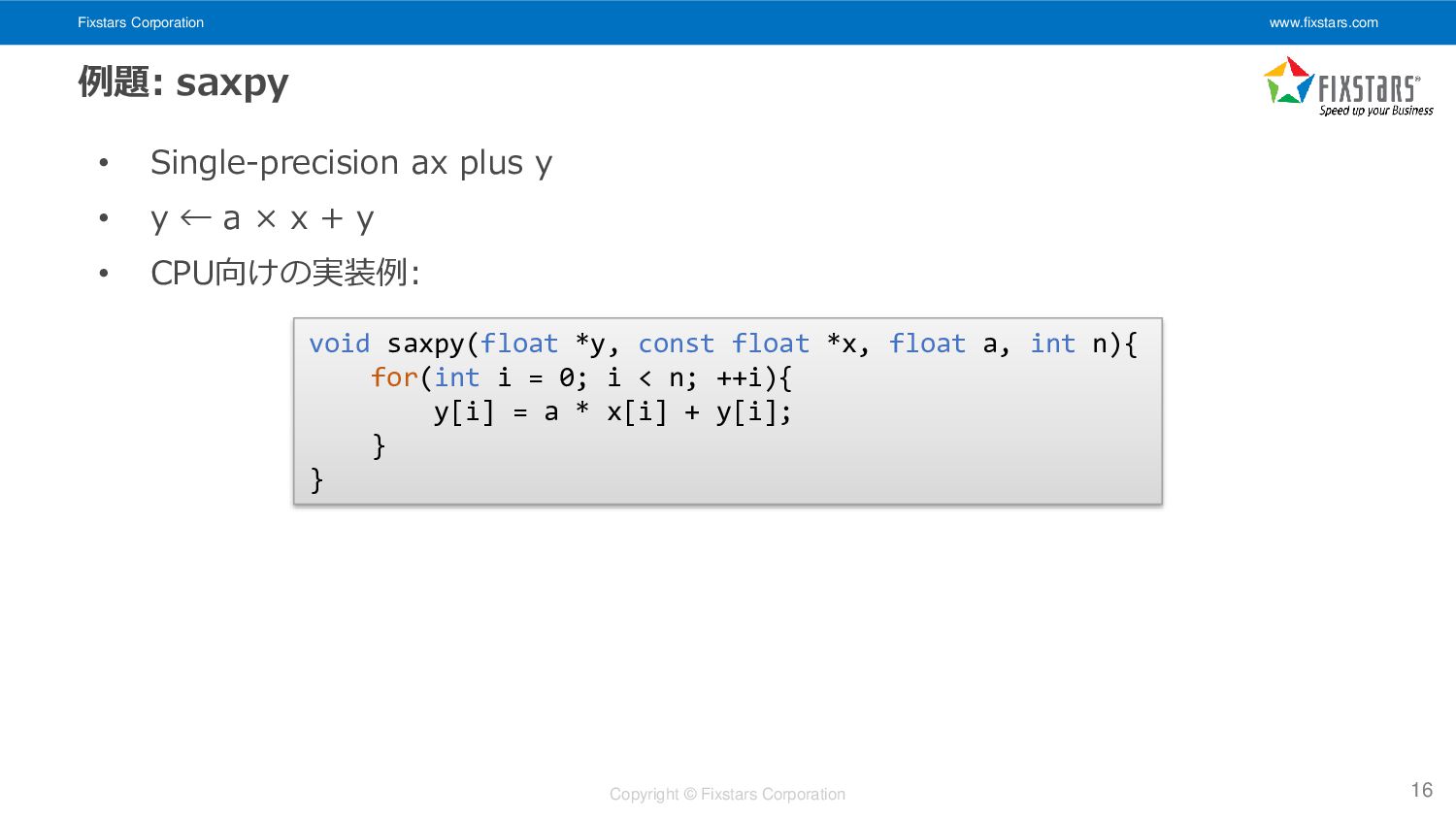
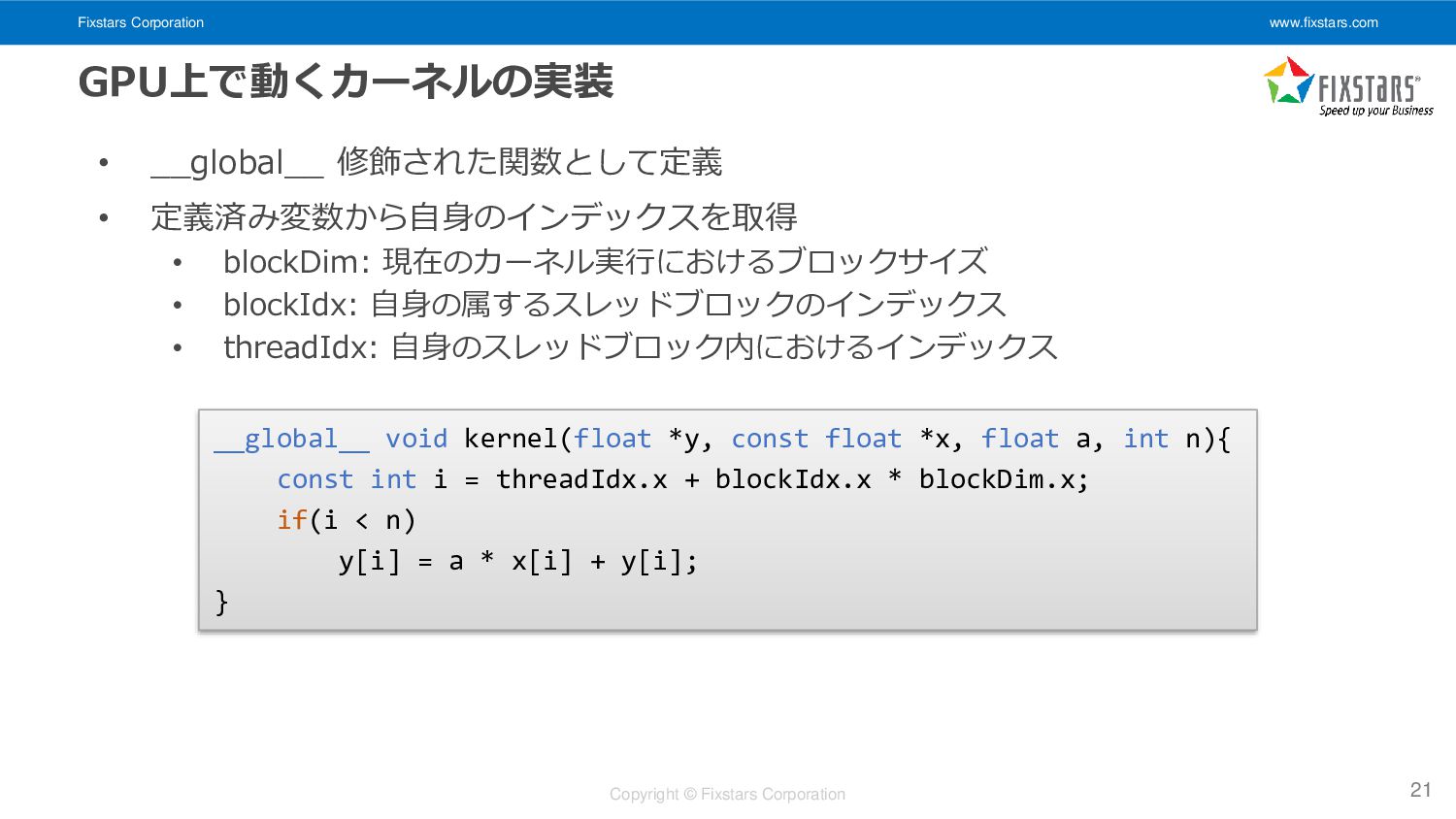
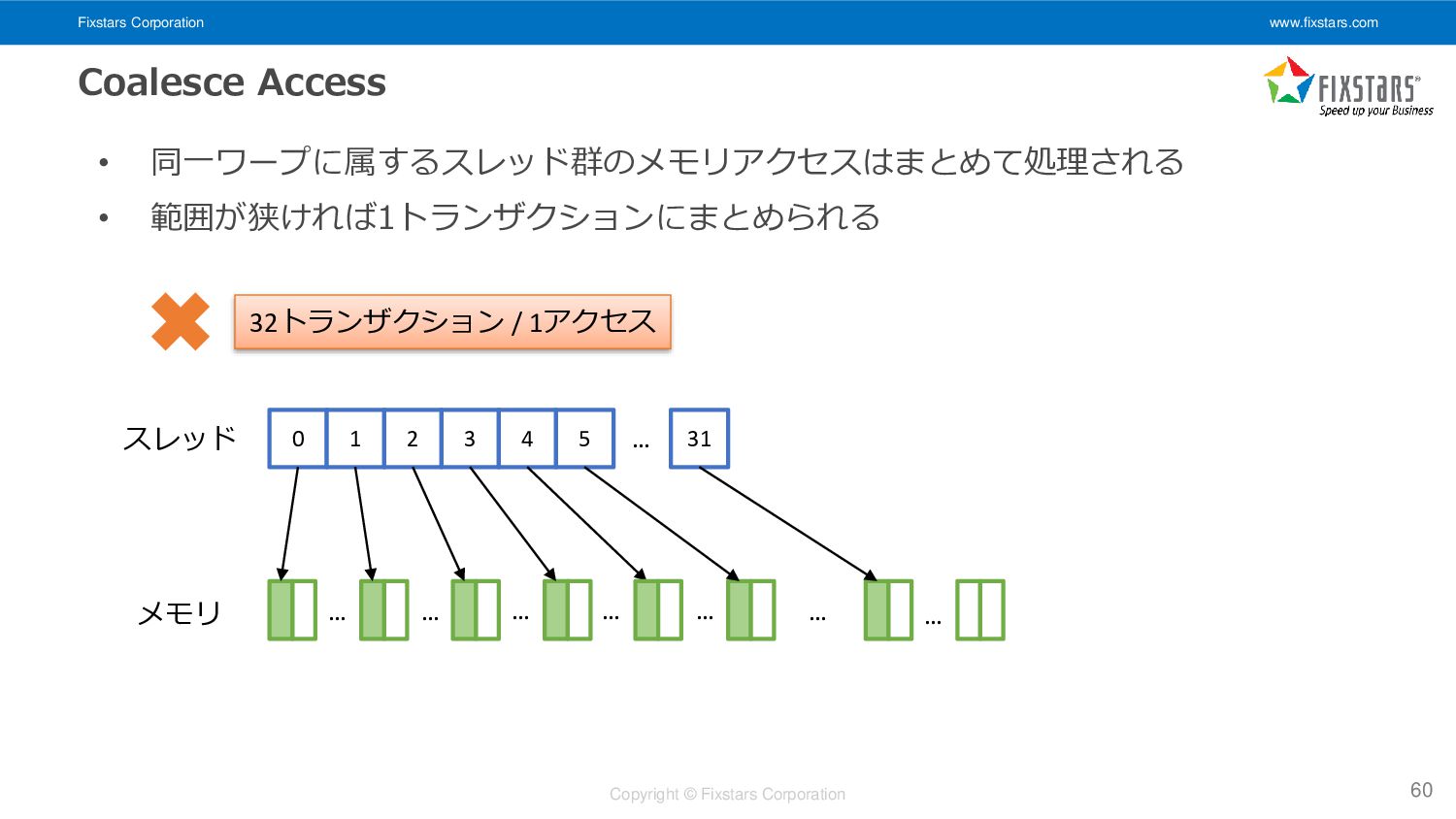
Single-precision ax plus y • y ← a × x + y • CPU向けの実装例: 16 void saxpy(float *y, const float *x, float a, int n){ for(int i = 0; i < n; ++i){ y[i] = a * x[i] + y[i]; } }
• バンクは4バイトごとに切り替わる • 同じバンクの異なる領域へのアクセスはまとめて処理できない: バンクコンフリクト 64 Bank 31 Bank 30 Bank 29 Bank 28 Bank 27 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0 0x00000000 0x00000080 0x00000100 …
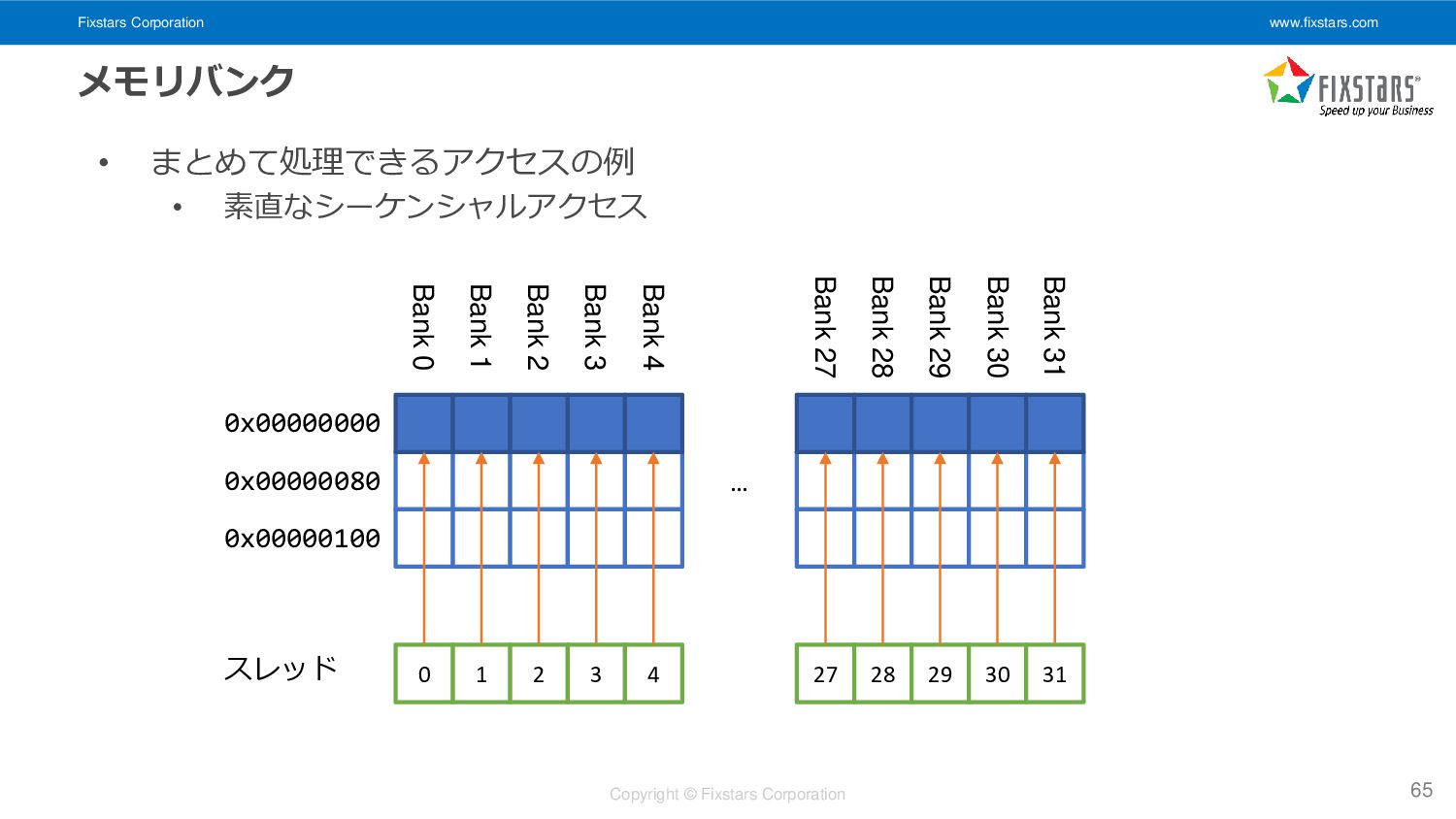
• 素直なシーケンシャルアクセス 65 Bank 31 Bank 30 Bank 29 Bank 28 Bank 27 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0 0x00000000 0x00000080 0x00000100 … 0 1 2 3 4 27 28 29 30 31 スレッド
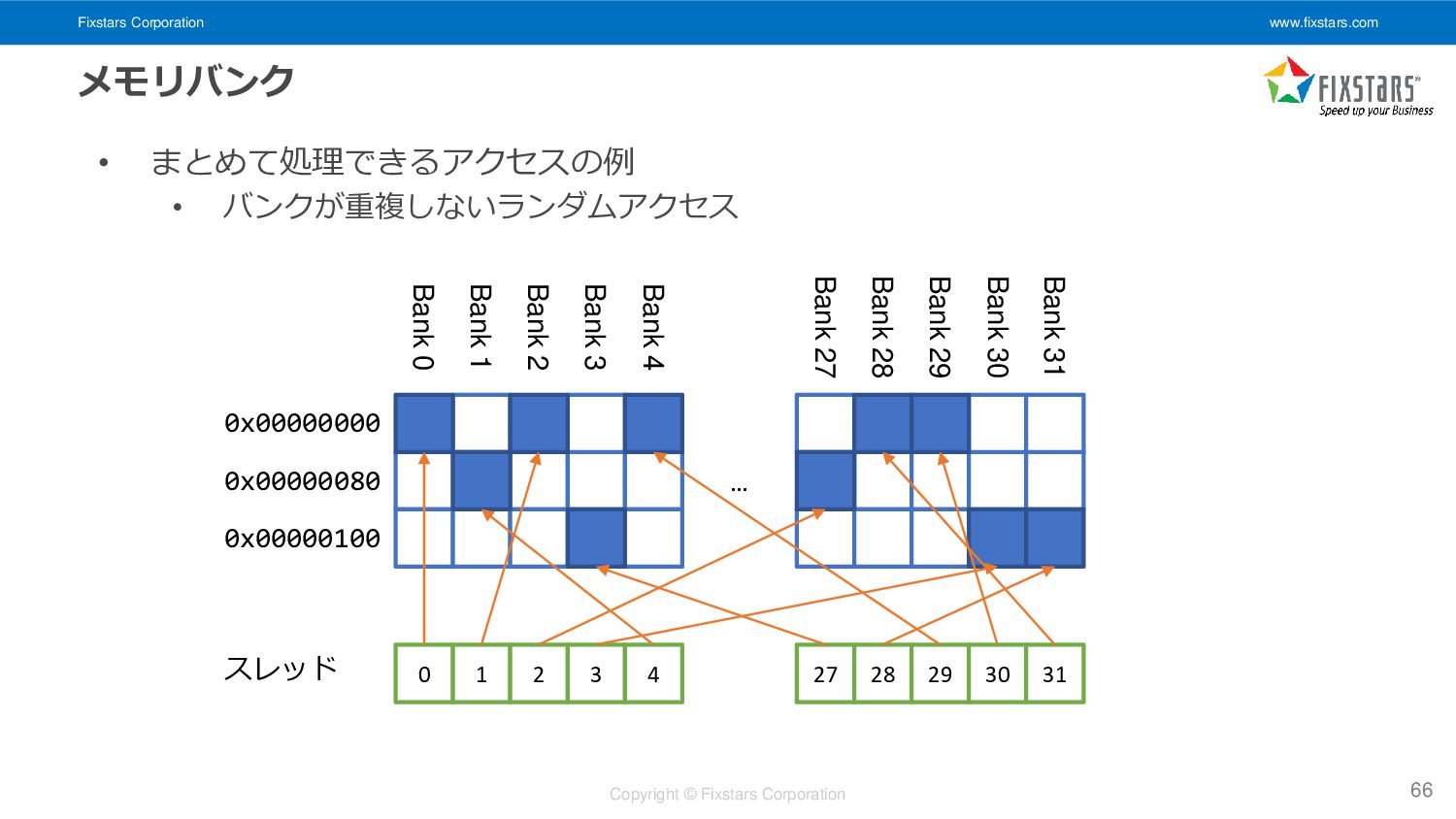
• バンクが重複しないランダムアクセス 66 Bank 31 Bank 30 Bank 29 Bank 28 Bank 27 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0 0x00000000 0x00000080 0x00000100 … 0 1 2 3 4 27 28 29 30 31 スレッド
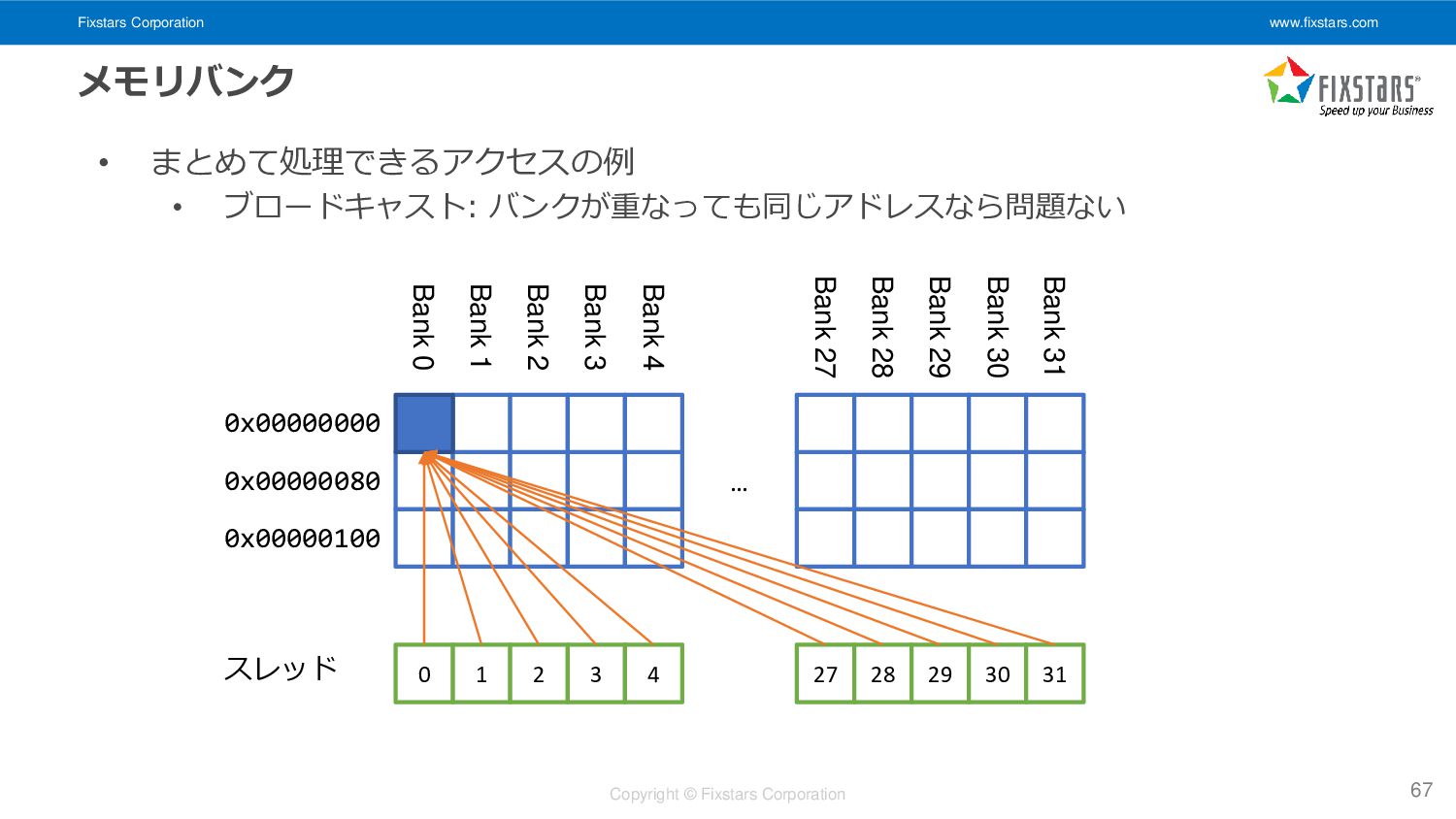
• ブロードキャスト: バンクが重なっても同じアドレスなら問題ない 67 Bank 31 Bank 30 Bank 29 Bank 28 Bank 27 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0 0x00000000 0x00000080 0x00000100 … 0 1 2 3 4 27 28 29 30 31 スレッド
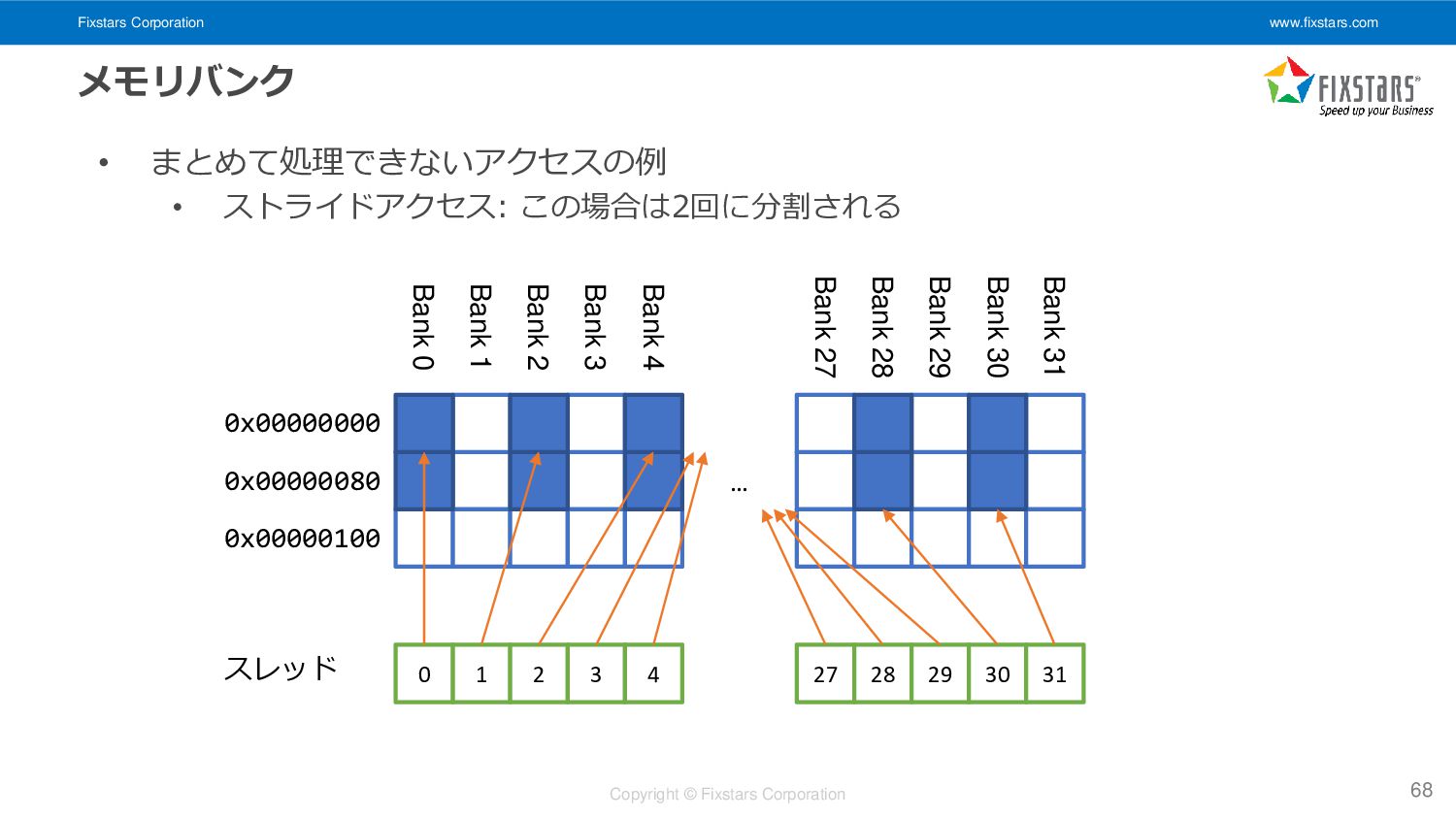
• ストライドアクセス: この場合は2回に分割される 68 Bank 31 Bank 30 Bank 29 Bank 28 Bank 27 Bank 4 Bank 3 Bank 2 Bank 1 Bank 0 0x00000000 0x00000080 0x00000100 … 0 1 2 3 4 27 28 29 30 31 スレッド
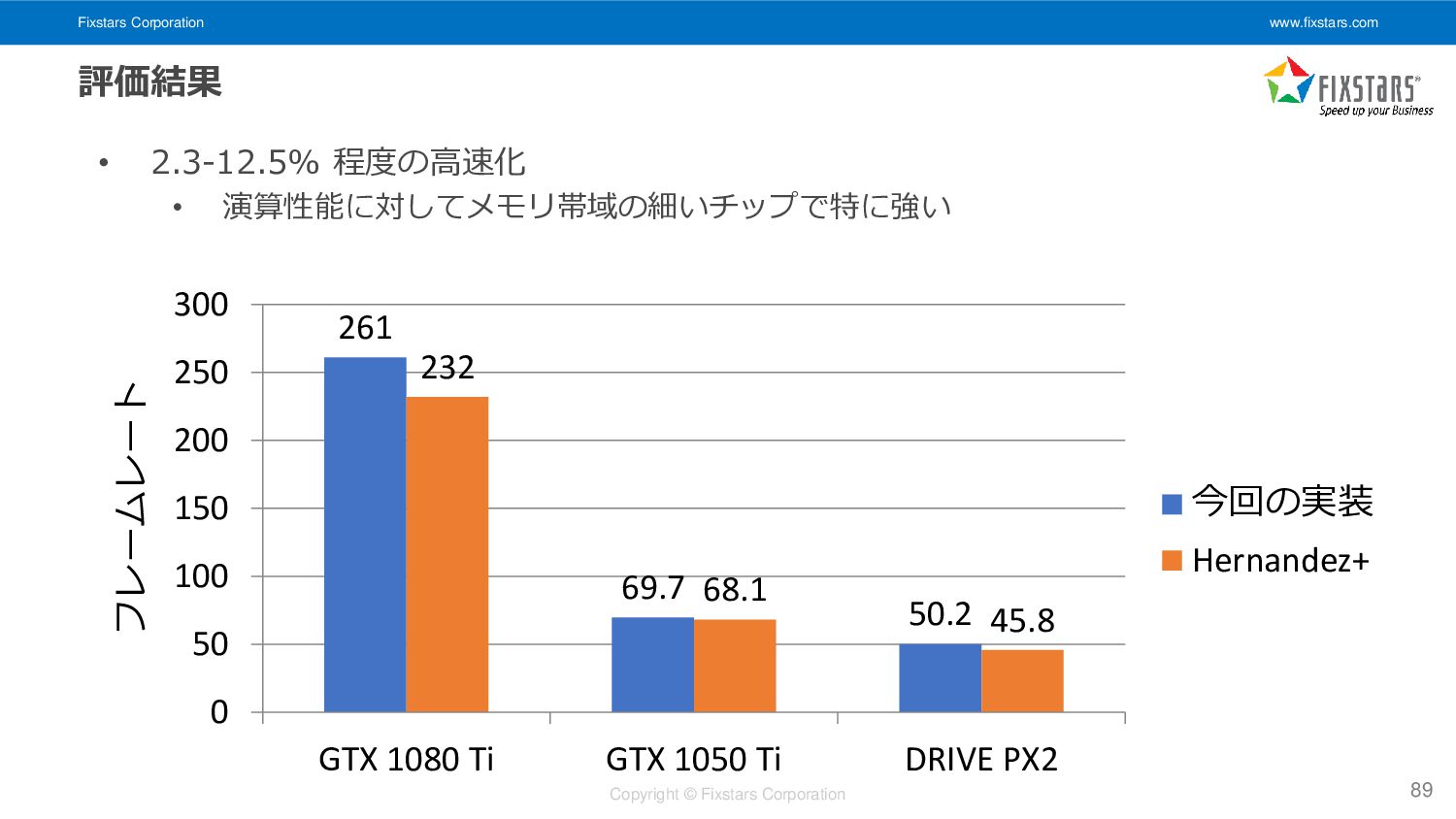
• 比較対象: Embedded real-time stereo estimation via Semi-Global Matching on the GPU, D. Hernandez-Juarez et al, ICCS 2016. • https://github.com/dhernandez0/sgm • 実際にはもう一つ大きいカーネルがあるのですがそちらの詳細は省略しています 88
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
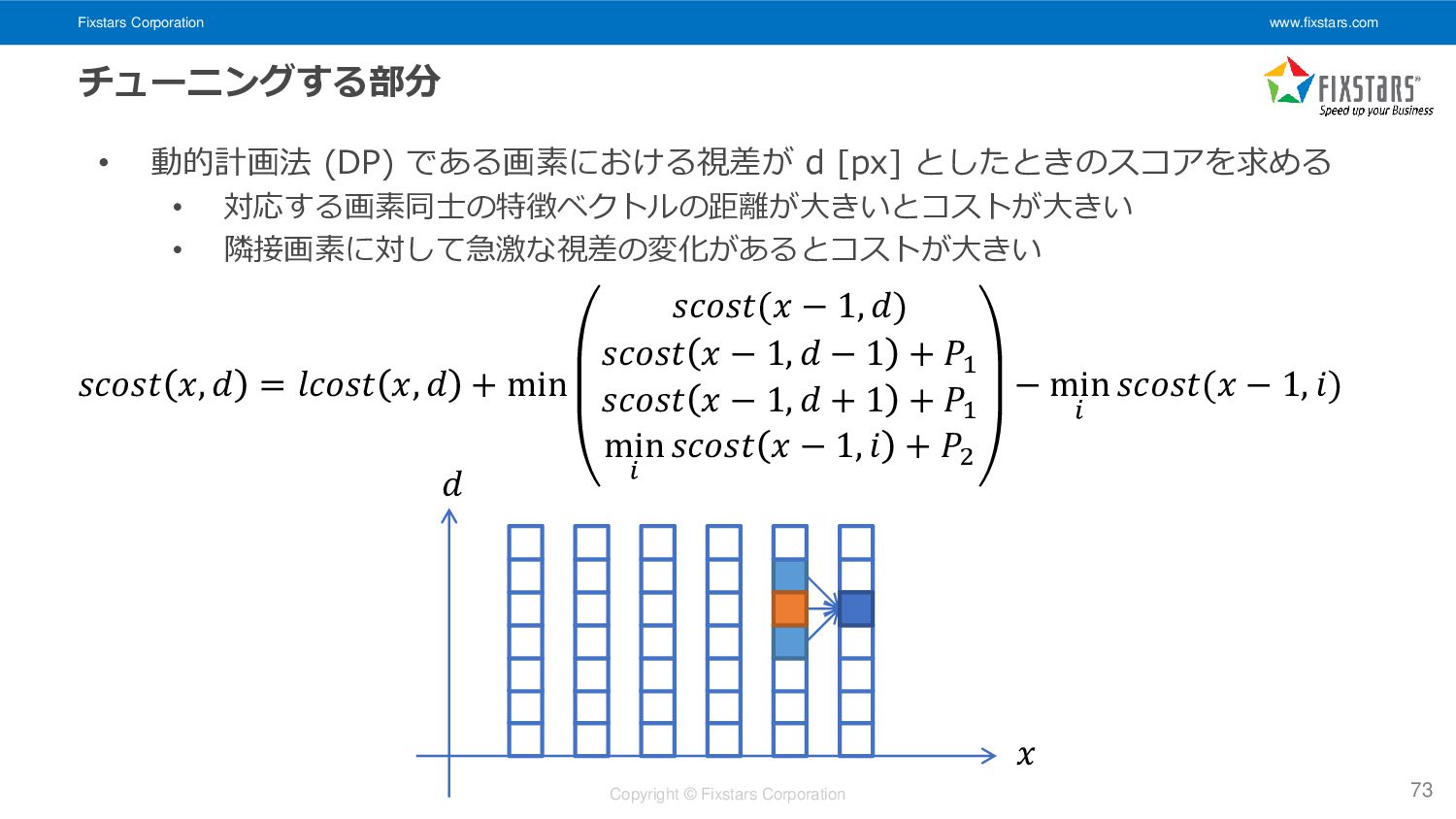
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
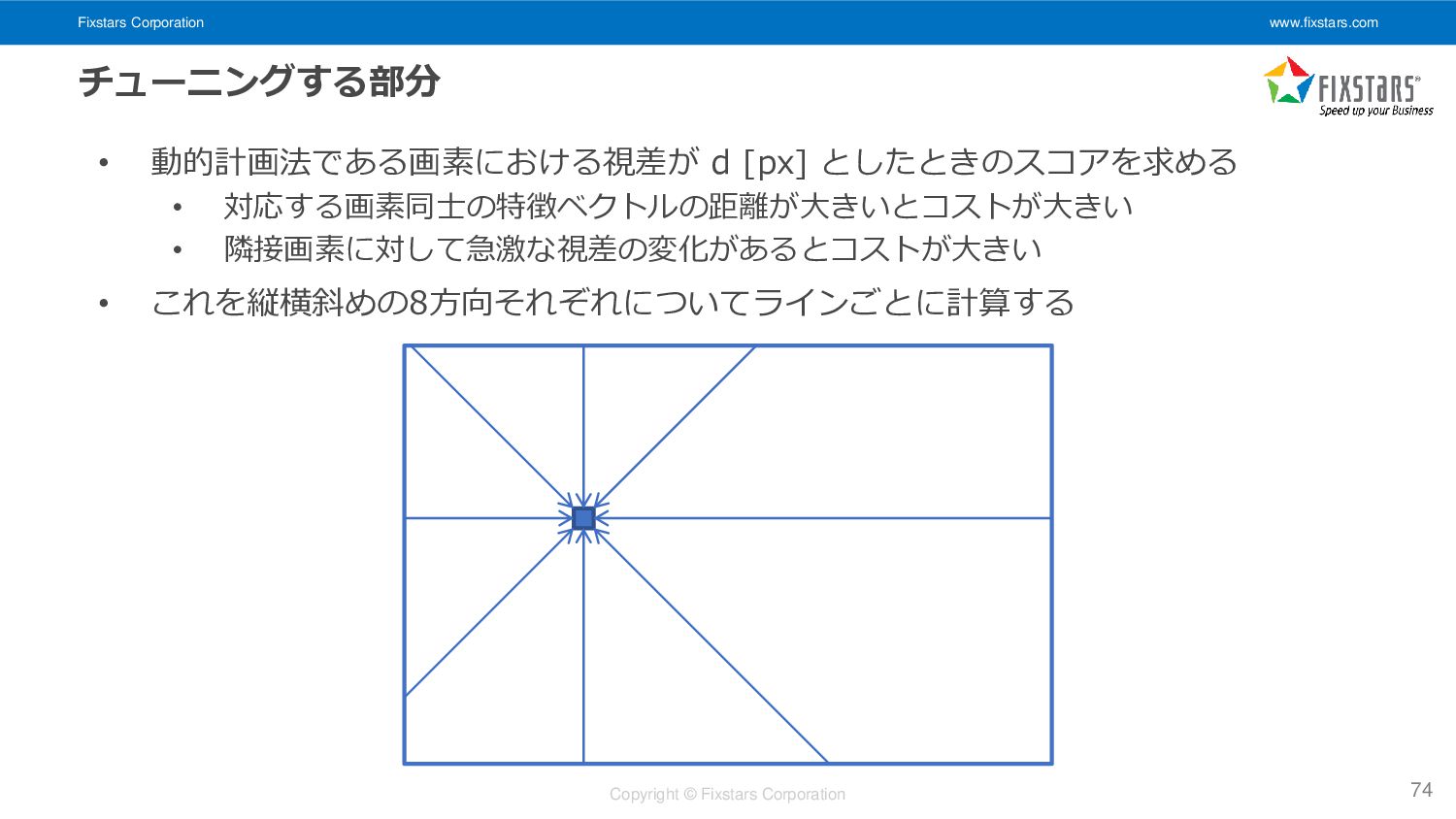
{kind=link}
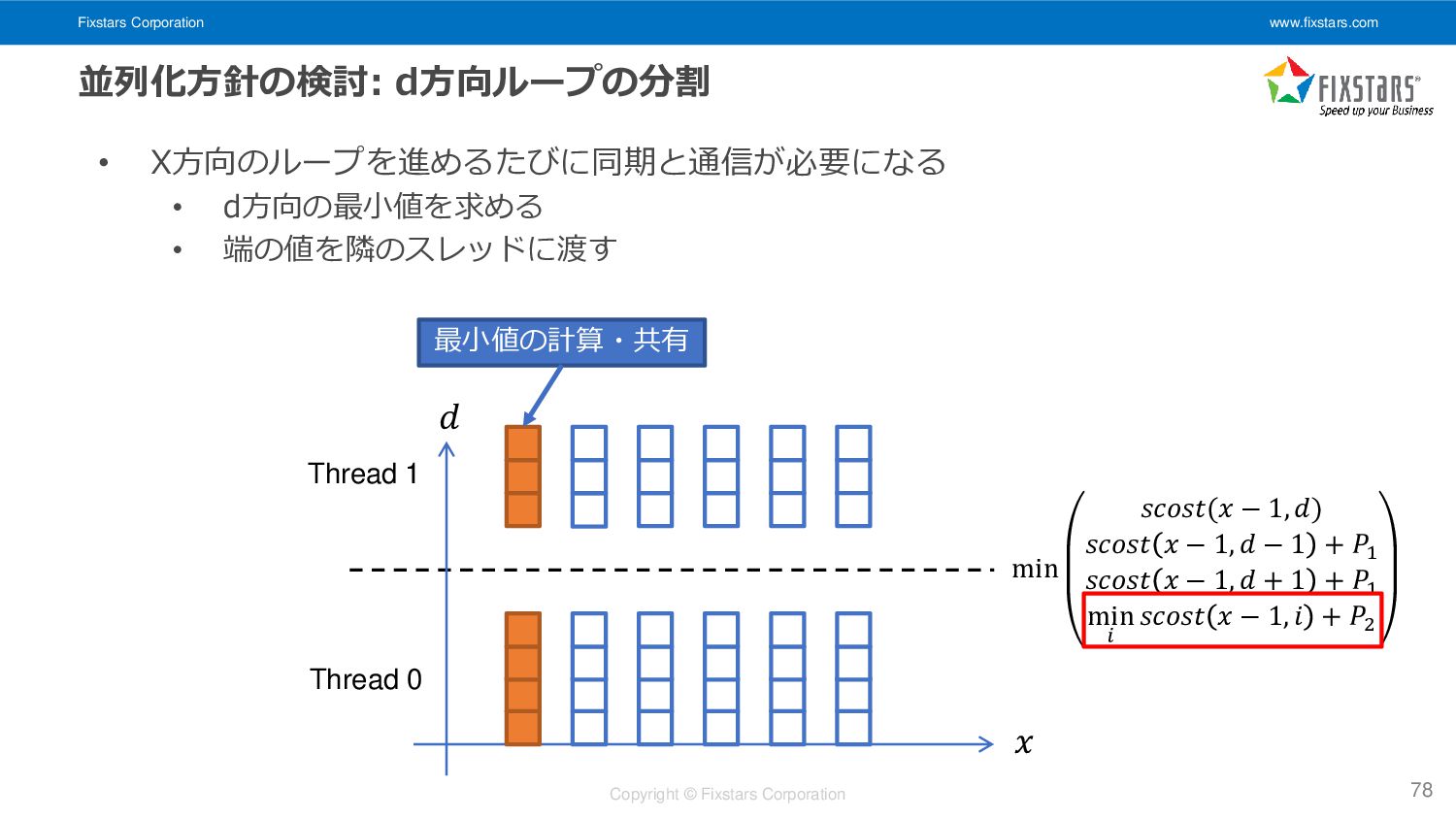
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
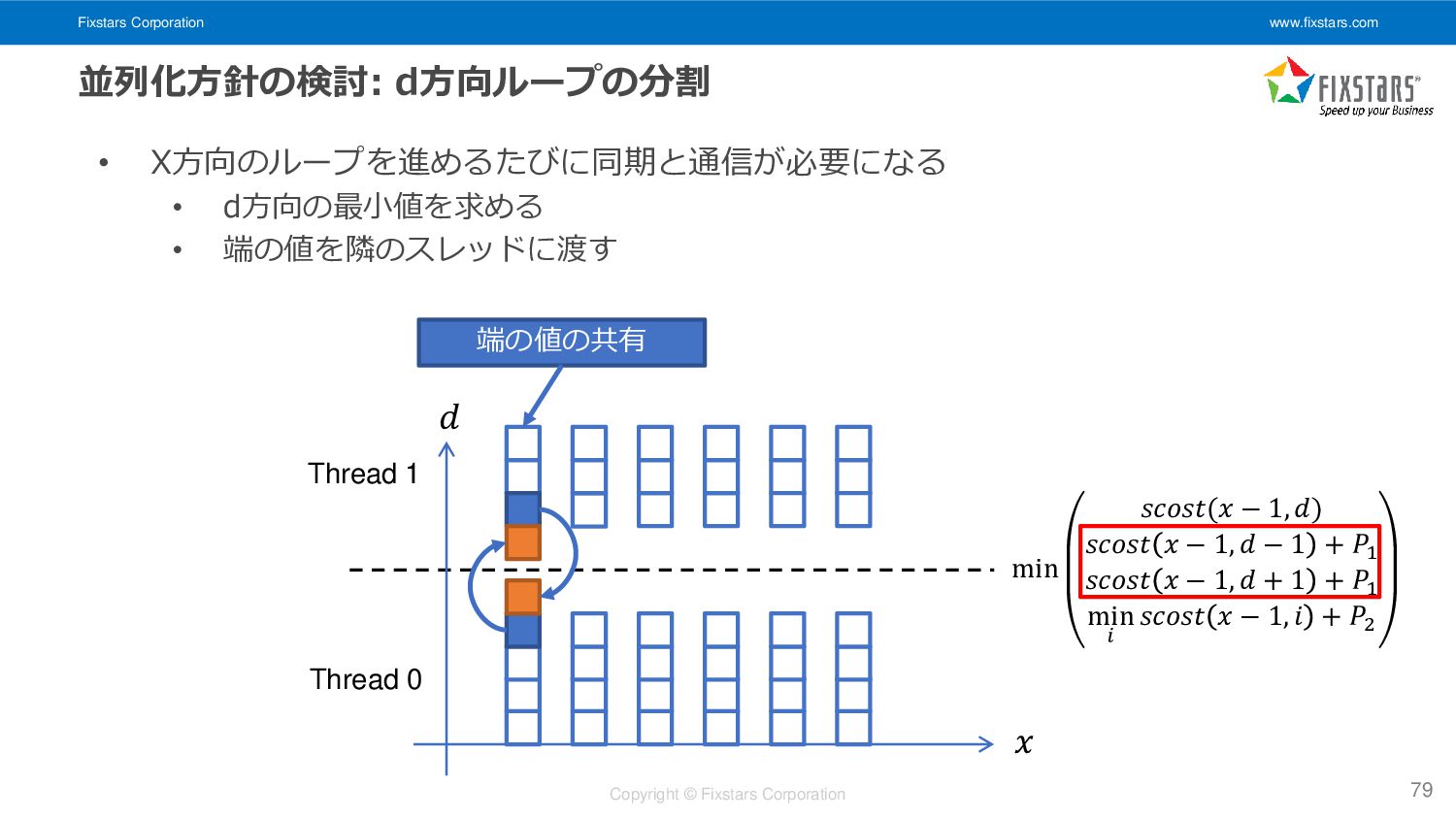{kind=link}
{kind=link}
{kind=link}
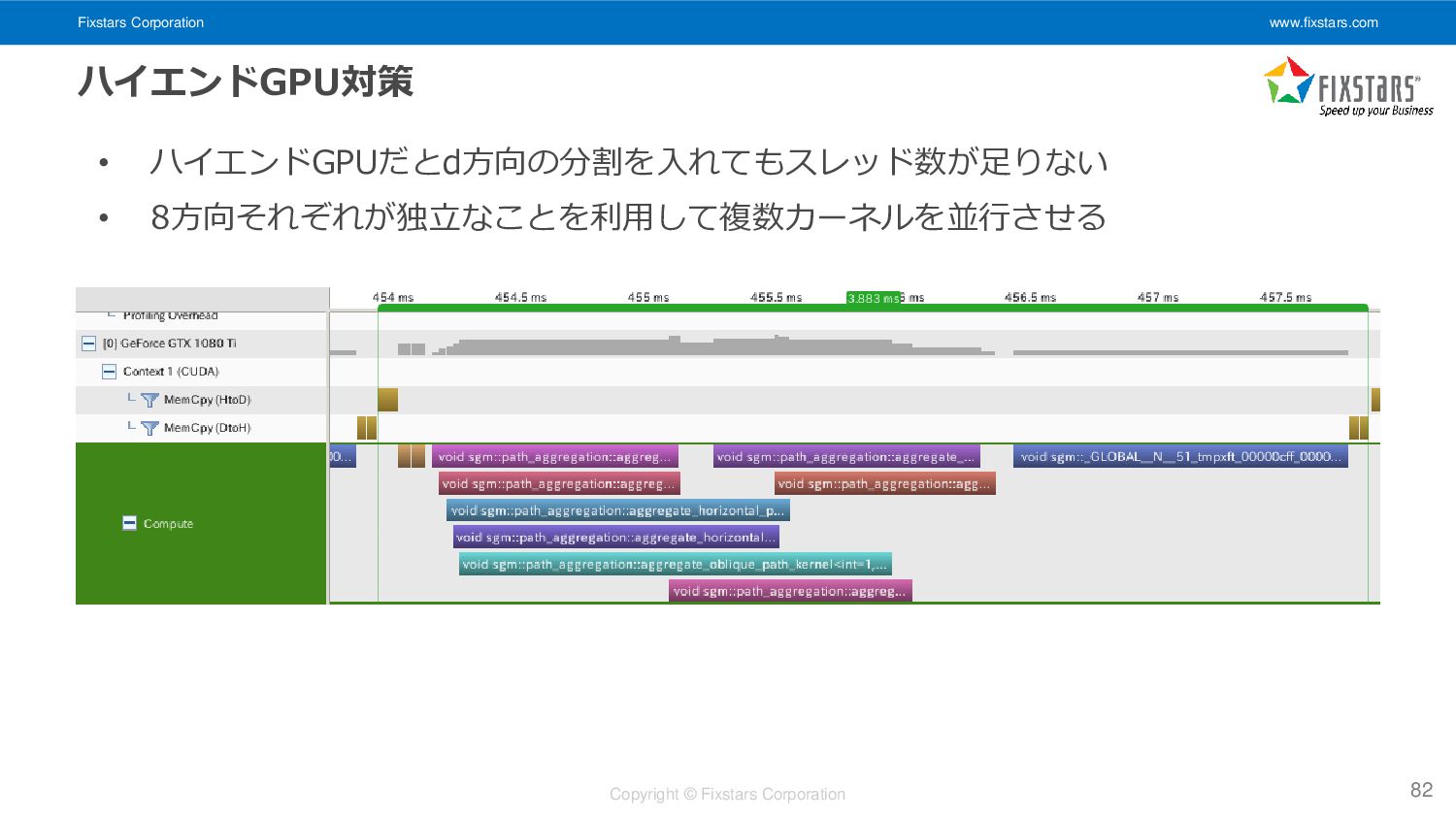{kind=link}
{kind=link}
{kind=link}
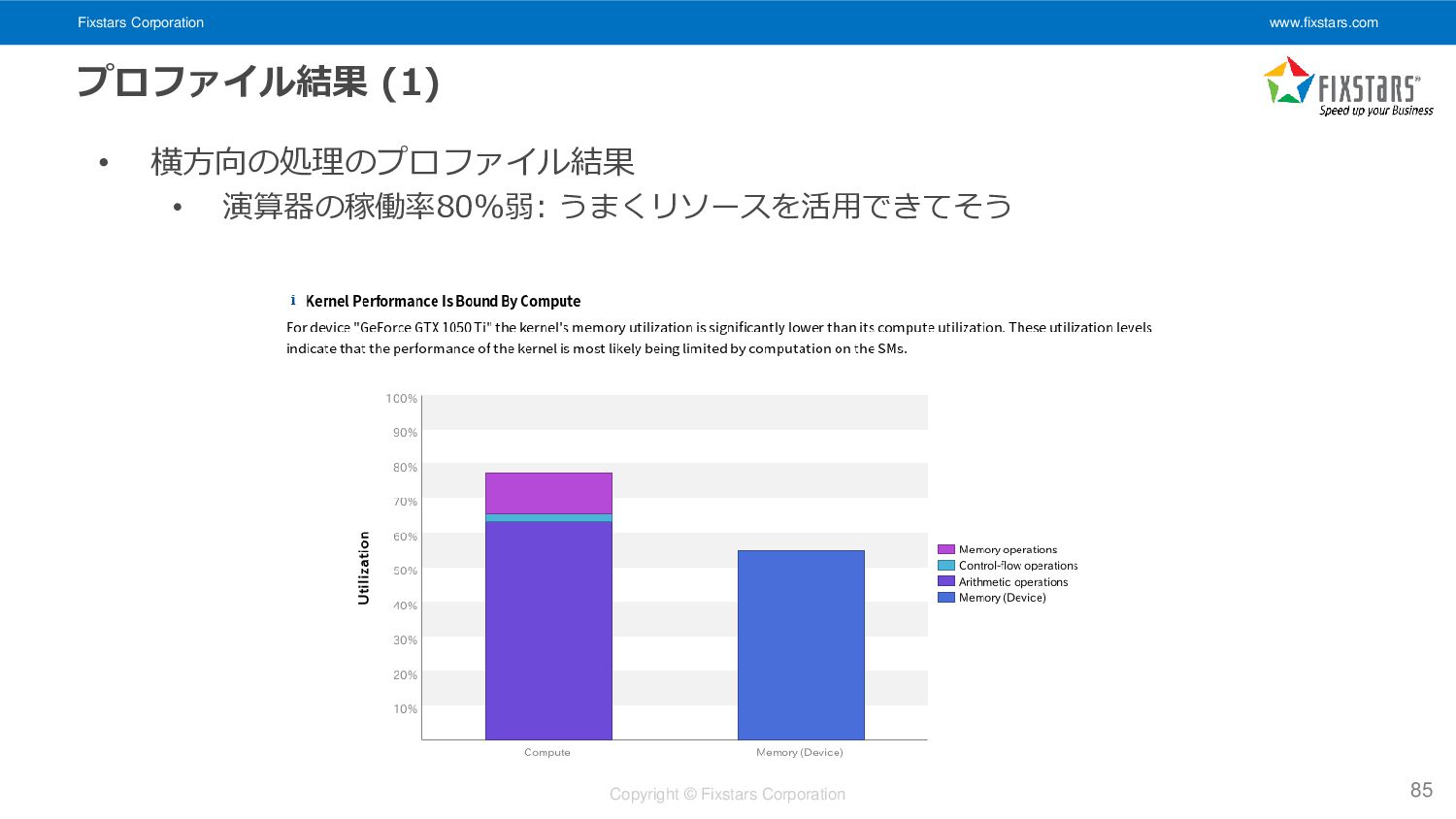{kind=link}
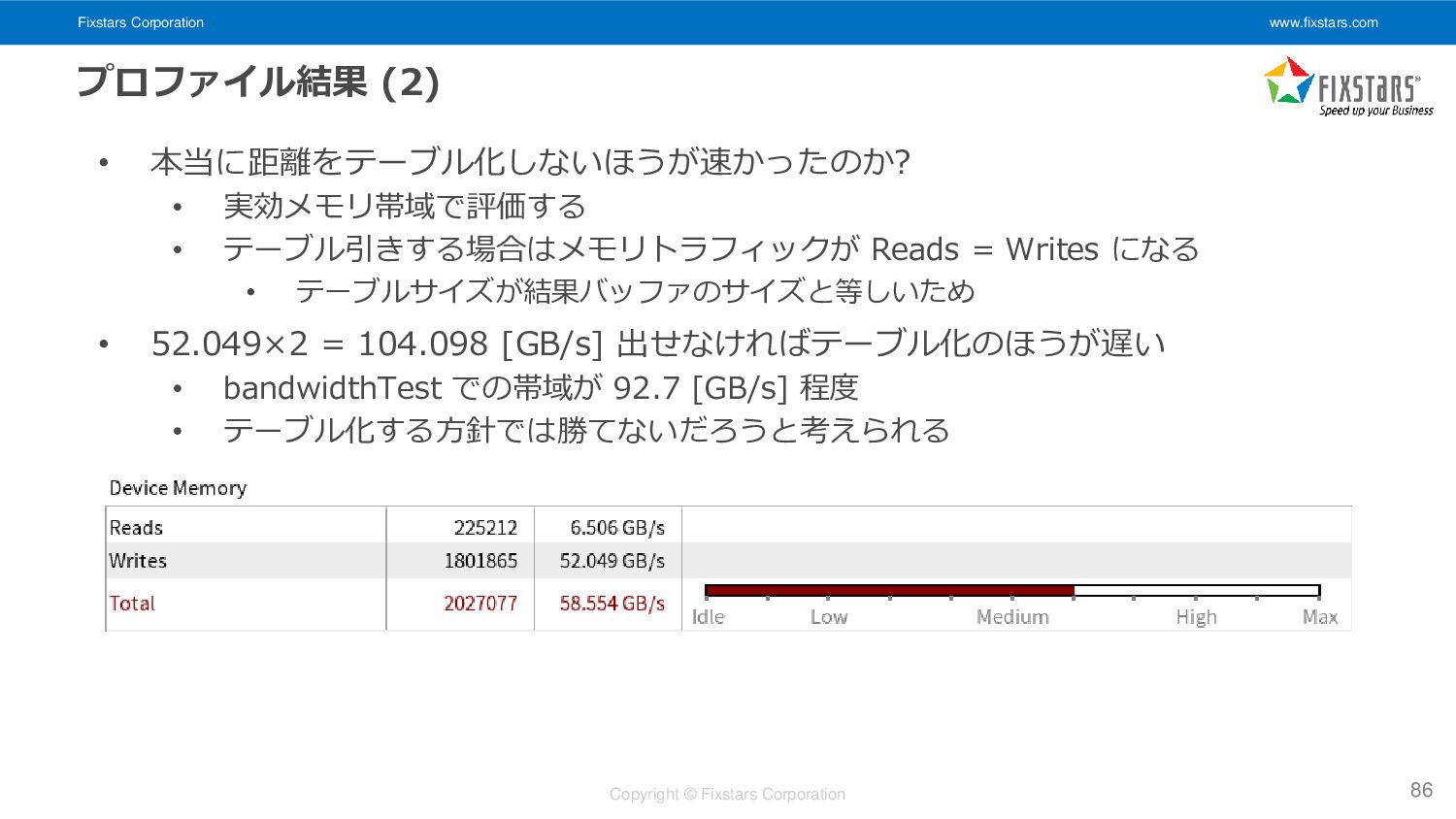{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}