Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
いまさら聞けないarmを使ったNEONの基礎と活用事例
Search
株式会社フィックスターズ
April 01, 2022
Programming
1.7k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
いまさら聞けないarmを使ったNEONの基礎と活用事例
2021年8月5日開催「いまさら聞けないarmを使ったNEONの基礎と活用事例」セミナー資料です。
株式会社フィックスターズ
April 01, 2022
More Decks by 株式会社フィックスターズ
See All by 株式会社フィックスターズ
コンピュータービジョンセミナー5 / 3次元復元アルゴリズム Multi-View Stereo の CUDA高速化
fixstars
0
1.2k
Kaggle_スコアアップセミナー_DFL-Bundesliga_Data_Shootout編/Kaggle_fixstars_corporation_20230509
fixstars
1
1.2k
実践的!FPGA開発セミナーvol.21 / FPGA_seminar_21_fixstars_corporation_20230426
fixstars
0
1.6k
量子コンピュータ時代のプログラミングセミナー / 20230413_Amplify_seminar_shift_optimization
fixstars
0
1.2k
実践的!FPGA開発セミナーvol.18 / FPGA_seminar_18_fixstars_corporation_20230125
fixstars
0
1k
実践的!FPGA開発セミナーvol.19 / FPGA_seminar_19_fixstars_corporation_20230222
fixstars
0
1.1k
実践的!FPGA開発セミナーvol.20 / FPGA_seminar_20_fixstars_corporation_20230329
fixstars
0
950
量子コンピュータ時代のプログラミングセミナー / 20230316_Amplify_seminar _route_planning_optimization
fixstars
0
920
量子コンピュータ時代のプログラミングセミナー / 20230216_Amplify_seminar _production_planning_optimization
fixstars
0
800
Other Decks in Programming
See All in Programming
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
820
LaravelLive Japan の裏方のすべて — 第188回 PHP勉強会@東京 (2026-06-24)
suguruooki
2
150
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
130
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
140
初めてのKubernetes 本番運用でハマった話
oku053
0
130
AI 輔助遺留系統現代化的經驗分享
jame2408
1
1.2k
気圧・高度・GPSを記録&可視化するアプリ「Koudo」を作った話
hjmkth
1
360
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
330
共通化で考えるべきは、実装より公開する型だった
codeegg
0
250
AIエージェントで 変わるAndroid開発環境
takahirom
2
680
Performance Engineering for Everyone
elenatanasoiu
0
270
継続モナドとリアクティブプログラミング
yukikurage
3
610
Featured
See All Featured
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Automating Front-end Workflow
addyosmani
1370
210k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Being A Developer After 40
akosma
91
590k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Transcript
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation いまさら聞けない armを使ったNEONの基礎と活用事例 2021年8月5日
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 本日のAgenda • はじめに
• フィックスターズのご紹介 • 技術講演 • ARMとは • ARM NEONの特徴 • ARM NEONのintrinsicの読み方と探し方 • ケーススタディ • ARM NEONの活用事例 • Q&A time Google Meetのチャット欄にご質問を寄せて頂ければ、 ご質問順で講演後に回答いたします。 口頭でご質問をご希望の方は、時間が許す限り回答いたしますので Q&A timeにGoogle Meetの挙手ボタンをクリックしてください。 • 告知 2
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation はじめに
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 本講演の位置づけ • 本講演のねらい
• ARM上で動くソフトウェアを開発している方 • SIMDについて概念的な理解はあるが使用歴がない/少ない がARM NEONを用いてソフトウェアを高速化できるようになるための 基礎的な知識をお届けする • 歴史的経緯 • 東京大学 次世代知能科学研究センター主催のセミナーにおいて 『ARM CPUにおけるSIMDを用いた高速計算入門』と題して講演 • Slideshareで資料公開中 https://www.slideshare.net/fixstars/arm-cpusimd • 本日の講演は概ね上記講演を踏襲 • 変更点 • SIMDプログラミングの概念の理解は前提、ARM NEONの話に焦点 • 活用事例として実際に弊社で行った高速化事例を紹介 • 復習の際は上記講演資料をご利用ください 4
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 発表者紹介 • 今泉
良紀 (Yoshiki Imaizumi) • シニアエンジニア • 高速化業務を複数経験 • 組み込みソフトウェアのSIMD化 • ARM NEON • DSP • スマートフォン向けGPGPUコード • メタプログラミングや プログラミング言語の構文解析に興味 5 • 宮元 直也 (Naoya Miyamoto) • ディレクター • 画像処理や信号処理に関する プロジェクトの管理を担当 • 自動車やFA機器向けの開発 • アルゴリズム開発から組み込みCPUや DSP向けの高速化
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation フィックスターズのご紹介
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation フィックスターズの強み フィックスターズは、コンピュータの性能を最大限に引き出し大量データの高速処理を実現する、 高速化のエキスパート集団です。
低レイヤ ソフトウェア技術 アルゴリズム 実装力 各産業・研究 分野の知見 7
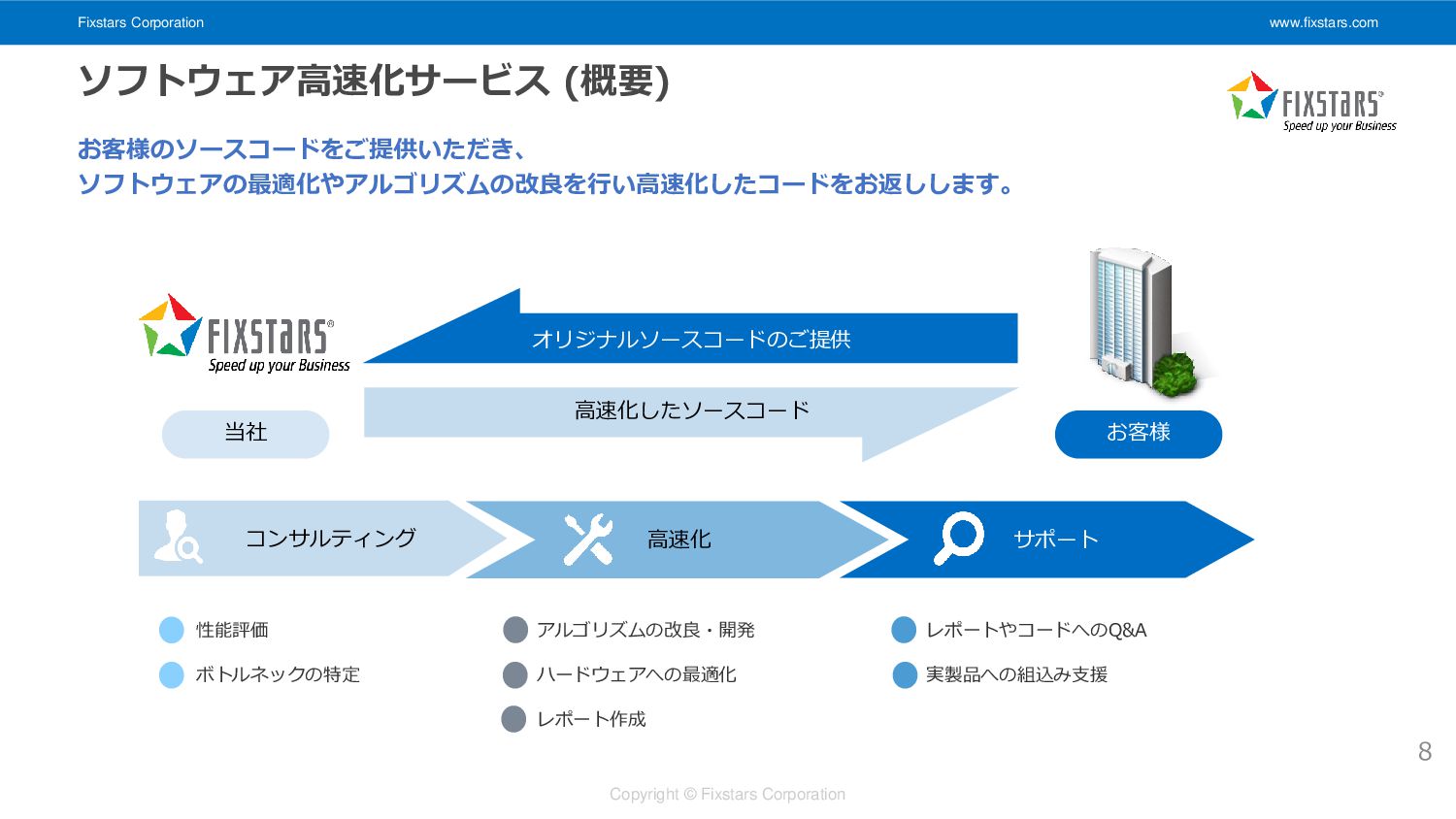
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ソフトウェア高速化サービス (概要) お客様のソースコードをご提供いただき、
ソフトウェアの最適化やアルゴリズムの改良を行い高速化したコードをお返しします。 当社 お客様 オリジナルソースコードのご提供 高速化したソースコード コンサルティング 高速化 サポート 性能評価 ボトルネックの特定 アルゴリズムの改良・開発 ハードウェアへの最適化 レポート作成 レポートやコードへのQ&A 実製品への組込み支援 8
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ソフトウェア高速化サービス (注力領域) 大量データの高速処理がお客様の製品競争力の源泉となる、
様々な領域でソフトウェア開発・高速化サービスを提供しています。 ・NAND型フラッシュメモリ向けファー ムウェア開発 ・次世代AIチップ向け開発環境基盤開発 Semiconductor ・デリバティブシステムの高速化 ・HFT(アルゴリズムトレード)の高速化 Finance ・自動運転の高性能化、実用化 ・次世代パーソナルモビリティの研究開発 Mobility ・ゲノム解析の高速化 ・医用画像処理の高速化 ・AI画像診断システムの研究開発 Life Science ・Smart Factory化支援 ・マシンビジョンシステムの高速化 Industrial 9
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ソフトウェア高速化サービス事例(組込み高速化) • お客様の課題
• 画像処理アルゴリズムは完成したが、実機性能が確認できないと商品化に踏み切れない • 実機のプロセッサがコロコロ変わるので、実機向けの高速な実装を毎度準備するのが辛い • 少しでも低スペックのプロセッサで処理できるようにしてコストを下げたい • R&D部署の成果を商品開発に結び付けたいが、引き継ぎなどの連携がうまくいかない • 弊社の支援内容 • H/W選定に向けたコンサルティング • ターゲットH/Wに向けたお客様アルゴリズムの移植 • ボトルネック調査、最適化方針提案、実施 • 目標性能未達の見込みの場合、アルゴリズム改善の提案 10
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ソフトウェア高速化サービス事例(画像処理・アルゴリズム開発) https://www.cs.toronto.edu/~frossard/post/vgg16/ •
お客様の課題 • 高度な画像処理、深層学習等のアルゴリズム開発を行える人材が社内に限られている • 考案中のアルゴリズムで機能要件は満たせそうだが、ターゲット機器上で性能要件まで クリアできるか不安 • 研究開発の成果が製品化にうまく結びつかない • 弊社の支援内容 • 課題に応じたアルゴリズム調査 • 深層学習ネットワーク精度改善、推論高速化手法調査 • 論文調査、実装 11
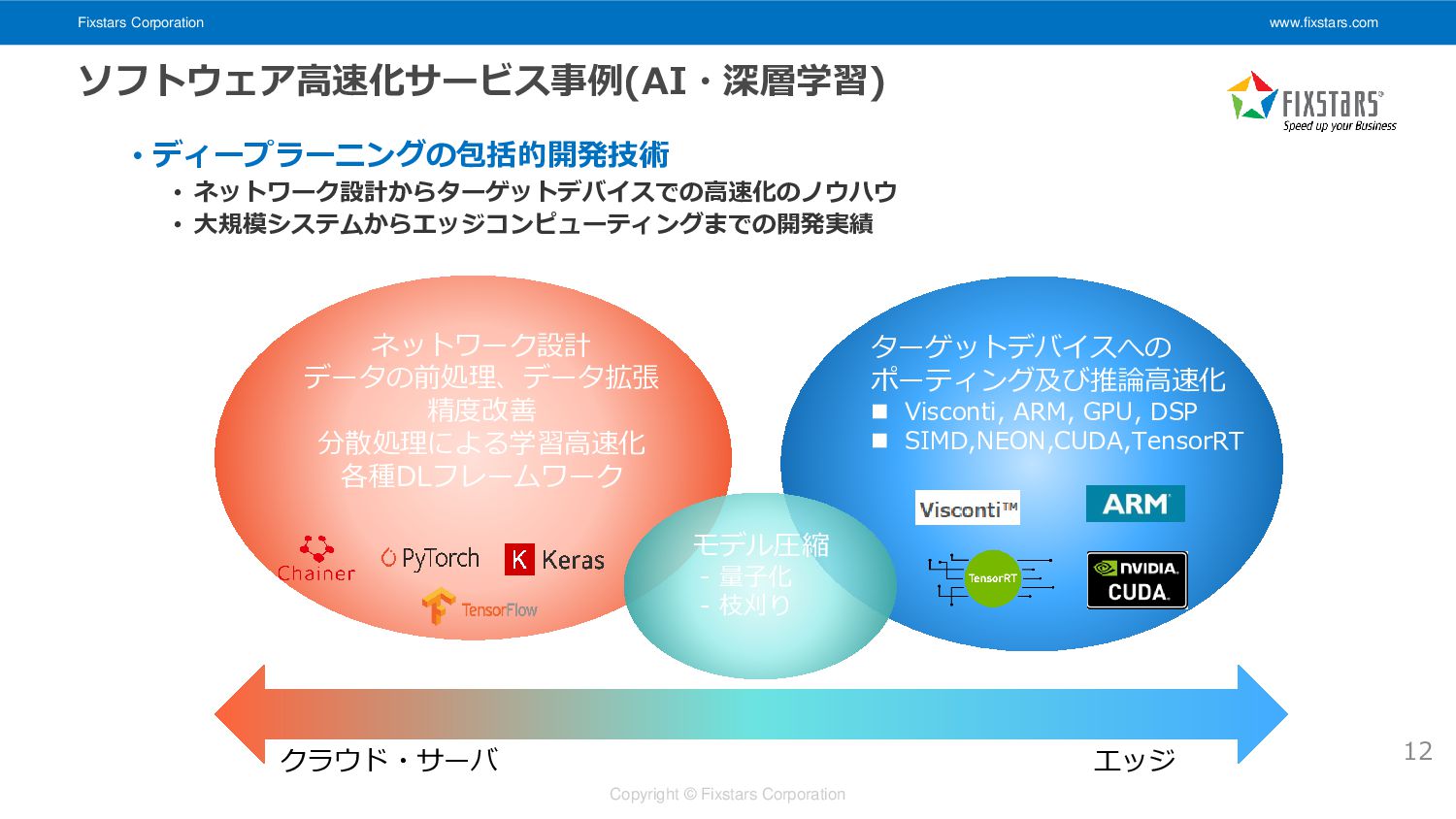
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ソフトウェア高速化サービス事例(AI・深層学習) ネットワーク設計 データの前処理、データ拡張
精度改善 分散処理による学習高速化 各種DLフレームワーク クラウド・サーバ エッジ モデル圧縮 - 量子化 - 枝刈り ターゲットデバイスへの ポーティング及び推論高速化 ◼ Visconti, ARM, GPU, DSP ◼ SIMD,NEON,CUDA,TensorRT • ディープラーニングの包括的開発技術 • ネットワーク設計からターゲットデバイスでの高速化のノウハウ • 大規模システムからエッジコンピューティングまでの開発実績 12
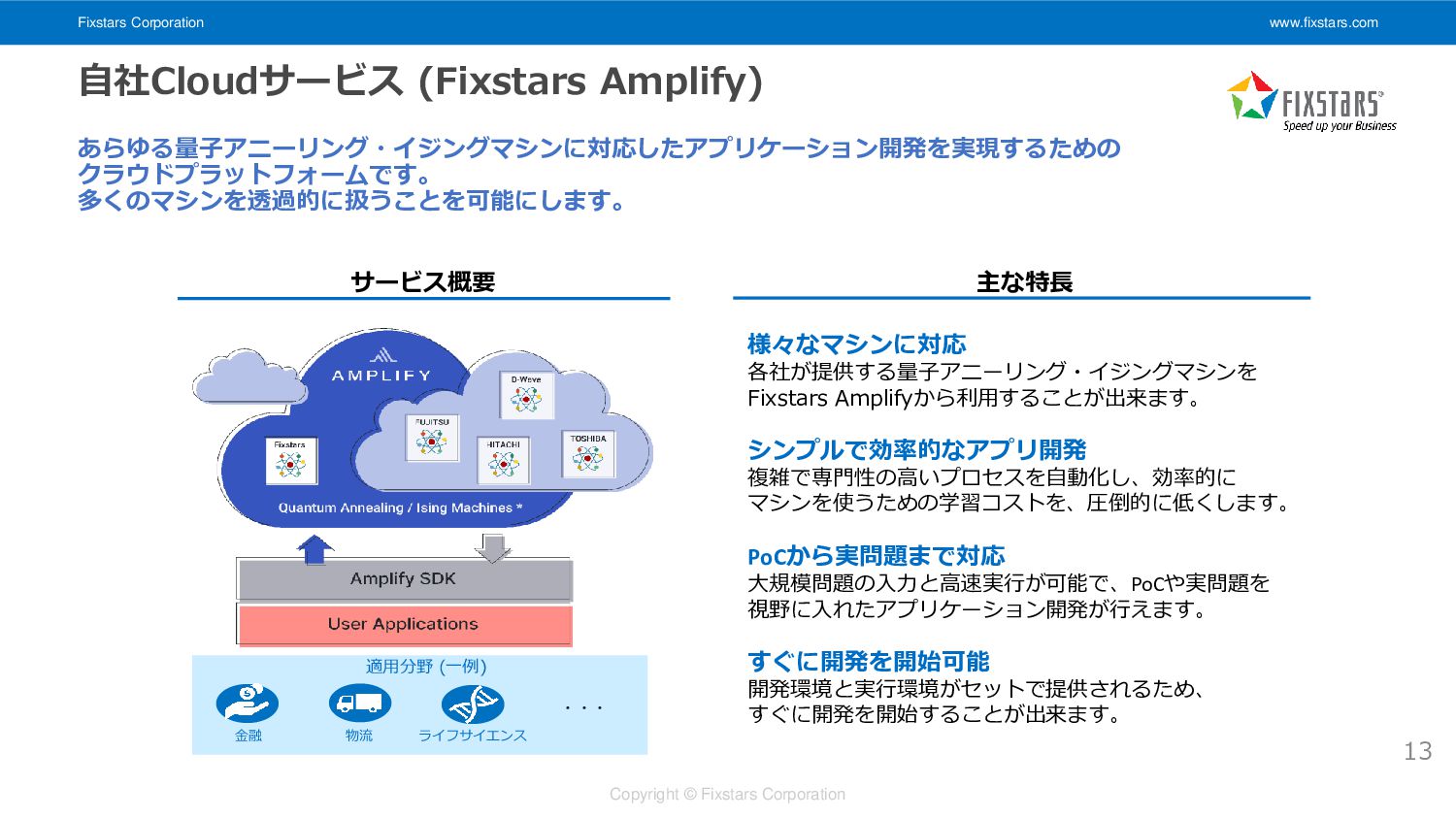
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 自社Cloudサービス (Fixstars Amplify)
13 あらゆる量子アニーリング・イジングマシンに対応したアプリケーション開発を実現するための クラウドプラットフォームです。 多くのマシンを透過的に扱うことを可能にします。 ・・・ 適用分野 (一例) 金融 物流 ライフサイエンス 様々なマシンに対応 各社が提供する量子アニーリング・イジングマシンを Fixstars Amplifyから利用することが出来ます。 シンプルで効率的なアプリ開発 複雑で専門性の高いプロセスを自動化し、効率的に マシンを使うための学習コストを、圧倒的に低くします。 PoCから実問題まで対応 大規模問題の入力と高速実行が可能で、PoCや実問題を 視野に入れたアプリケーション開発が行えます。 すぐに開発を開始可能 開発環境と実行環境がセットで提供されるため、 すぐに開発を開始することが出来ます。 主な特長 サービス概要
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 自社Cloudサービス (GENESIS) 自動運転やFA等、様々な分野で利用拡大が見込まれるエッジビジョンAI/IoT向けのクラウド評価環境です。
ビジョンAIなどのアプリを自動でデバイスに最適化した上で性能評価し、最適なハードウェア選定を可能にします。 FA ドローン 自動運転 モバイル エッジビジョンAI 評価プラットフォーム GENESIS 開発者 サプライヤ CPU GPU FPGA AI Chip Vision Sensor Imaging Sensing その他IoT機器 アプリケーションの カスタムサービス ハードウェア販売・開発をサポートする 性能評価・比較環境の提供 最新ハードウェアを 使ったPoC生成 サービス概要 14 主な特長 必要なデバイス選定を強力に支援 プログラムの最適化をフィックスターズ独自開発の技術 で自動化し、センサーやチップごとに性能を引き出した 上で比較できます 高速化済みアプリを簡単にデプロイ クラウドに接続された実デバイスを使った開発環境によ り、デプロイしても最適化済みのアプリがすぐに動作し ます。 ノーコードとテンプレートで高速AI評価 開発済みのプログラムをつなぎ合わせて作るノーコード 開発により、エッジAIチップのパフォーマンスを評価で きます。
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation 技術講演 ARM NEONの基礎と活用事例
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>ARMとは • Arm:
CPUなどの設計をしているイギリスの会社 • 命令セットアーキテクチャ(ISA)からマイクロアーキテクチャまで設計 • 命令セットアーキテクチャ: ARMv7, ARMv8, ... • マイクロアーキテクチャ: Cortex-A72, Neoverse N1, ... • 設計したアーキテクチャ(の情報)をライセンス販売している • 買った企業がそれぞれ製造する • Arm社自身がチップの製造をすることはない • 近年ARMアーキテクチャのCPUが幅広い環境で採用されている • 組み込み機器 • 元々低消費電力などを売りにしていたので主戦場 • スマートフォン • ほぼ寡占状態 iPhoneも殆どのAndroidもARM • PC(Apple M1, Microsoft SQ2など) • クラウドコンピューティングのインスタンス(Amazon EC2 C6g/R6g/M6g AWS Graviton2) • スパコン(富岳/不老 富士通 A64FX) 16
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>ARMのデータ並列向け命令セット • SVE:
Scalable Vector Extension • ベクトル(拡張)命令 • ベクトルレジスタ長がCPU毎に可変: SVEでは256bit~2048bitまでを取りうる • ダイサイズや消費電力を富豪的に使える環境では処理性能を大きく伸ばせる • 現状はA64FX専用命令のような状態 • Neoverse N2などにはSVE2が搭載されており、2022年頃には市場に投入される見通し • NEON • SIMD命令 • SIMDレジスタ長が不変(命令セットで規定): ARMv8のNEONでは128bit • ARMv7でも拡張命令セットとして存在し、既に広く使われている技術 • 本日の講演ではNEONについて掘り下げていく • いずれもフリンの分類上はSIMDであり、データ並列に有効な命令セット 17
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>ARM NEONとは •
NEON: ARMv7時代のSIMD拡張命令 • 拡張命令なので使えるかどうかは確認する必要があった • SIMD演算器を載せていないCPUで実行するとエラーになってしまう • 64bit/128bit SIMDレジスタを扱う • ARMv7では64bit SIMDレジスタを2本束ねて128bitレジスタとして扱う • 128bitレジスタを扱う命令を使うと実質的にSIMDレジスタ本数が半分になってしまう • ARMv8では128bit SIMDレジスタの半分を64bitレジスタとして扱う • 128bitレジスタに64bitのデータを2つ載せられるわけではない(レジスタ本数は倍にならない) • ARMv8からはSIMD命令が基本命令セットに入った • つまりARMv8CPUであれば必ずSIMD命令が使える • この際NEONという呼び名ではなくなっている • が、「ARMのSIMD」という呼称はややこしいのでここではARMv8のSIMD命令もNEONと呼称 • v7時代のNEONと概ね同じ命令セット • ARMv8のSIMDでは128bit SIMDレジスタを32本使える • 上述の通り64bitでもこのレジスタを1本使うので注意(64本扱いにはならない) 18
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>Intrinsicについて • Intrinsic:
特定の命令列に翻訳されることが保証されている組み込み関数 • NEONの命令列に変換されるintrinsicもある • Intrinsicは特定の命令と1対1で対応するわけではないことに注意 e.g.) vmlaq_f32(a, b, c): vaddq_f32(a, vmulq_f32(b, c)) と等価(1intrinsicが2命令になる) • vfmaq_f32(a, b, c) (1命令の融合積和演算)とインターフェースを統一することが目的 e.g.) vreinterepretq_f32_u8(x): 実際には機械語命令は生成されない(1intrinsicが0命令になる) • Intrinsic向けのSIMDレジスタ変数型を読み替えるためのintrinsic • 機械語的にはそのまま同じレジスタを参照すれば良い • 本講演ではintrinsicを用いたNEONプログラミングのみを扱う • アセンブリを用いたプログラミングはレジスタ管理を自力で行う必要がある • コンパイラのauto vectorizerは複雑な処理をSIMD命令に変換できない • Intrinsicを使うとレジスタ管理をコンパイラに任せつつ確実にSIMD命令を呼べる 19
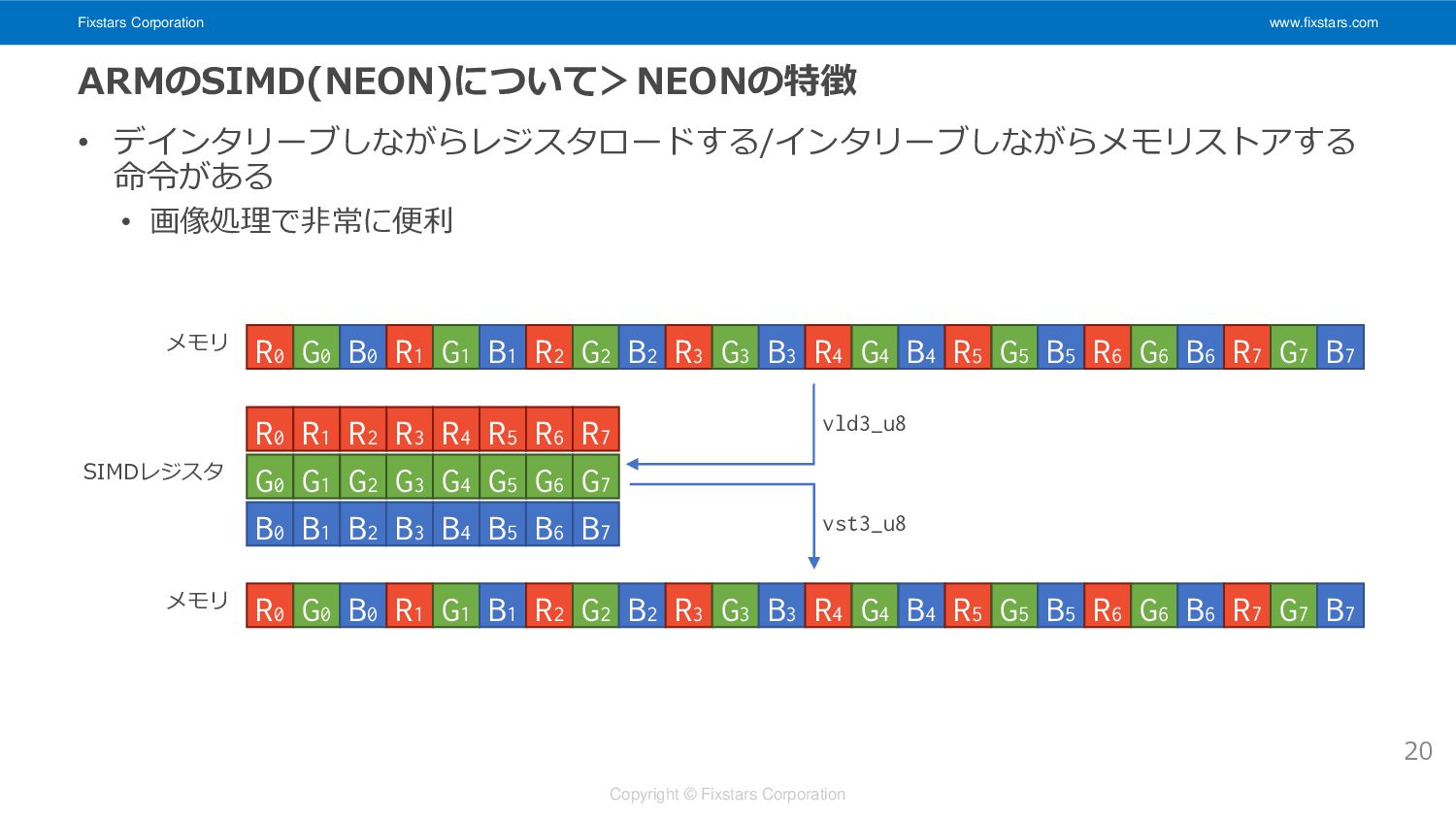
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>NEONの特徴 • デインタリーブしながらレジスタロードする/インタリーブしながらメモリストアする
命令がある • 画像処理で非常に便利 20 R0 G0 B0 R1 G1 B1 R2 G2 B2 R3 G3 B3 R4 G4 B4 R5 G5 B5 R6 G6 B6 R7 G7 B7 R0 R1 R2 R3 R4 R5 R6 R7 G0 G1 G2 G3 G4 G5 G6 G7 B0 B1 B2 B3 B4 B5 B6 B7 R0 G0 B0 R1 G1 B1 R2 G2 B2 R3 G3 B3 R4 G4 B4 R5 G5 B5 R6 G6 B6 R7 G7 B7 vld3_u8 vst3_u8 メモリ SIMDレジスタ メモリ
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>NEONの特徴 • SIMDレジスタ用の変数の型がしっかりついているのでintrinsicが読み書きしやすい
e.g.) uint8x8_t(64bit), float32x4_t(128bit)など • x86のSIMD(SSEやAVXなど)は整数のSIMDレジスタ型がすべて同じ型 • 実際にどのサイズの型いくつでSIMDレジスタを扱っているかを intrinsicの使われ方から推測しなければならない • 同じSIMDレジスタ変数に対してuint16とuint8向けの操作ができてしまう • うっかり間違えたとしてもそのままコンパイルされる • NEONのSIMDレジスタ型は以下の形式 • 𝑇𝑀x𝑁_t • 𝑇: int, uint, floatなど • 𝑀: 各要素のサイズ 8, 16, 32, 64など(𝑇によっては指定できない物も) • 𝑁: レーン数 64/𝑀 または 128/𝑀 e.g.) 倍精度(64bit)浮動小数点数(float)2個は float64x2_t 21
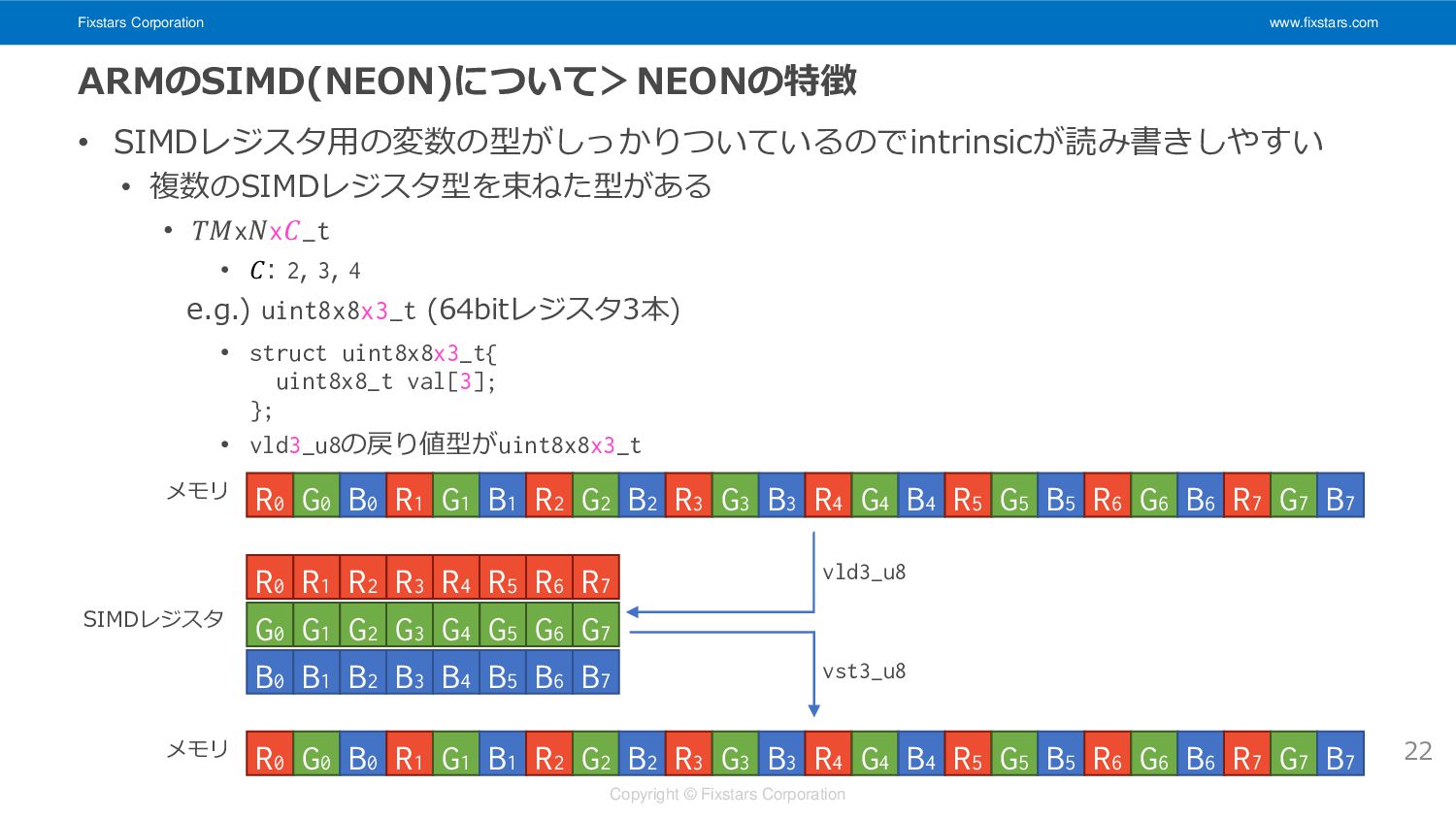
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>NEONの特徴 • SIMDレジスタ用の変数の型がしっかりついているのでintrinsicが読み書きしやすい
• 複数のSIMDレジスタ型を束ねた型がある • 𝑇𝑀x𝑁x𝐶_t • 𝐶: 2, 3, 4 e.g.) uint8x8x3_t (64bitレジスタ3本) • struct uint8x8x3_t{ uint8x8_t val[3]; }; • vld3_u8の戻り値型がuint8x8x3_t 22 R0 G0 B0 R1 G1 B1 R2 G2 B2 R3 G3 B3 R4 G4 B4 R5 G5 B5 R6 G6 B6 R7 G7 B7 R0 R1 R2 R3 R4 R5 R6 R7 G0 G1 G2 G3 G4 G5 G6 G7 B0 B1 B2 B3 B4 B5 B6 B7 R0 G0 B0 R1 G1 B1 R2 G2 B2 R3 G3 B3 R4 G4 B4 R5 G5 B5 R6 G6 B6 R7 G7 B7 vld3_u8 vst3_u8 メモリ SIMDレジスタ メモリ
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>intrinsicの読み方 • NEONのintrinsicは基本的に以下の形式
• v𝐼𝑄_𝑇 • 𝐼: 命令 足し算ならadd、引き算ならsubなど • 𝑄: 64bitならなにも無し 128bitならqを付ける • 𝑇: 引数の型に応じた接尾辞 • 符号付き整数: s𝑁(𝑁は要素のbit数) s8, s16, s32, s64 • 符号なし整数: u𝑁(𝑁は要素のbit数) u8, u16, u32, u64 • 浮動小数点数: f𝑁(𝑁は要素のbit数) f16, f32, f64 e.g.) vaddq_f32 : float32の足し算(128bit) • なので (float32x4_t, float32x4_t) -> float32x4_t e.g.) vminv_u8 : uint8のレジスタ内最小値(64bit) • なので uint8x8_t -> uint8_t 23 0 1 2 3 20 30 40 50 20 31 42 53 254 140 42 89 51 115 178 60 42
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ARMのSIMD(NEON)について>intrinsicの探し方 • Armのreference(Neon
Intrinsics Reference)から探す • https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics • intrinsicの詳細を知りたい場合やintrinsic自体を探す場合に便利 • Arm公式のNeon Intrinsics ReferenceだがちゃんとARMv8のSIMDについても記載アリ • 英語でググってStack Overflowのいい感じの質問を探し当てる • intrinsicを複数組み合わせる操作やユースケースから探す際に便利 e.g.) 同じベクトル内で要素を回転させたい • rotate命令はNEONにはない • 「vextを同じベクトルに使えば実現できる」 • <arm_neon.h> を読む • オフラインでも読めるしgrepやテキストエディタの検索などが使える • 実装は基本的に読めないので関数が何をするのかはヘッダからは読み取れないことが多い 24 0 1 2 3 1 2 3 0
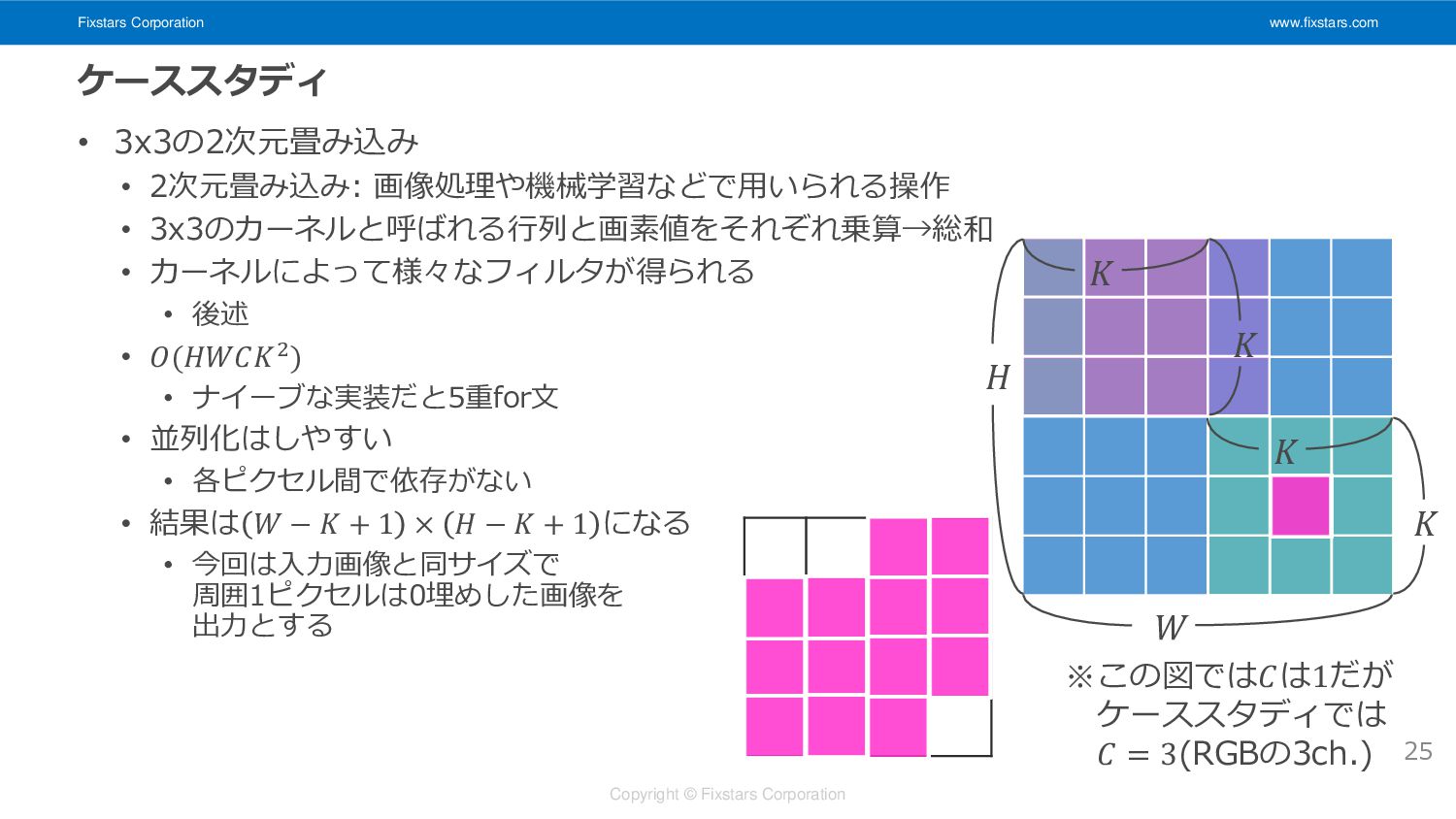
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 3x3の2次元畳み込み
• 2次元畳み込み: 画像処理や機械学習などで用いられる操作 • 3x3のカーネルと呼ばれる行列と画素値をそれぞれ乗算→総和 • カーネルによって様々なフィルタが得られる • 後述 • 𝑂(𝐻𝑊𝐶𝐾2) • ナイーブな実装だと5重for文 • 並列化はしやすい • 各ピクセル間で依存がない • 結果は 𝑊 − 𝐾 + 1 × 𝐻 − 𝐾 + 1 になる • 今回は入力画像と同サイズで 周囲1ピクセルは0埋めした画像を 出力とする 25 𝐻 𝑊 𝐾 𝐾 𝐾 𝐾 ※この図では𝐶は1だが ケーススタディでは 𝐶 = 3(RGBの3ch.)
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 3x3の2次元畳み込み
• カーネルによって様々なフィルタが得られる • ボックスフィルタ(平滑化) • ソーベルフィルタ(エッジ抽出) 26 1 1 1 1 1 1 1 1 1 -1 -2 -1 0 0 0 1 2 1
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • ナイーブな実装
• 2560x1440の画像に対して57.8ms • 実行環境: Amazon EC2 c6g.4xlarge • vCPU: AWS Graviton2 27 static constexpr std::size_t kernel_size = 3; static constexpr std::size_t half_kernel_size = kernel_size/2; for(std::size_t y = half_kernel_size; y < h-half_kernel_size; ++y) for(std::size_t x = half_kernel_size; x < w-half_kernel_size; ++x) for(std::size_t c = 0; c < 3; ++c){ float t = 0.f; for(std::size_t i = 0; i < kernel_size; ++i) for(std::size_t j = 0; j < kernel_size; ++j) t += src[y-half_kernel_size+i][x-half_kernel_size+j][c] * kernel[i][j]; dst[y][x][c] = std::clamp<std::uint8_t>(static_cast<std::uint8_t>(t), 0u, 255u); } //cループ・xループ・yループの終わり
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ループの入れ替え • チャネル(RGB)のループを内側に入れる
• メモリアクセスを連続にする • RGBRGBRGB...と並んでいるので、それに沿ってアクセス • 50.2ms(-7.6ms) 28 static constexpr std::size_t kernel_size = 3; static constexpr std::size_t half_kernel_size = kernel_size/2; for(std::size_t y = half_kernel_size; y < h-half_kernel_size; ++y) for(std::size_t x = half_kernel_size; x < w-half_kernel_size; ++x){ float t[3] = {}; for(std::size_t i = 0; i < kernel_size; ++i) for(std::size_t j = 0; j < kernel_size; ++j) for(std::size_t c = 0; c < 3; ++c) t[c] += src[y-half_kernel_size+i][x-half_kernel_size+j][c] * kernel[i][j]; for(std::size_t c = 0; c < 3; ++c) dst[y][x][c] = std::clamp<std::uint8_t>(static_cast<std::uint8_t>(t[c]), 0u, 255u); } //xループ・yループの終わり
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • どこをNEON化するか
• 計算 • 各ピクセルの各色毎にfloatの乗算と加算を9回行っている • ここを複数ピクセル同時に行う • float(32bit)なので128/32=4個ずつ同時に扱える • 読み込み/書き込み • RGBでインタリーブされたuint8_tのデータ列 • vld3q_u8/vst3q_u8を使えば128/8=16ピクセルずつ同時に読み書き可能 • しかもデインタリーブ/インタリーブは自動で行われる • まずは計算からNEON化してみる 29
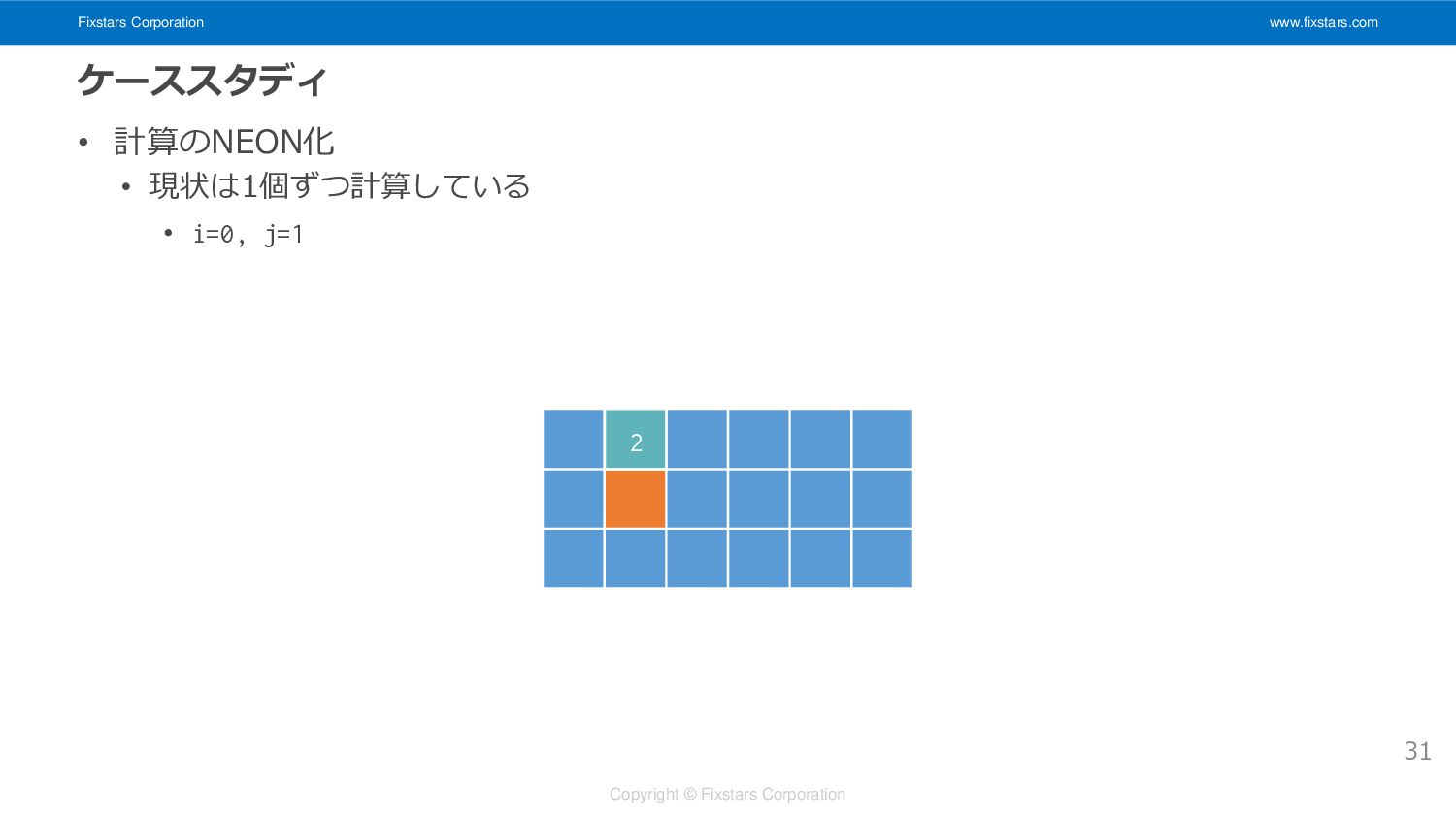
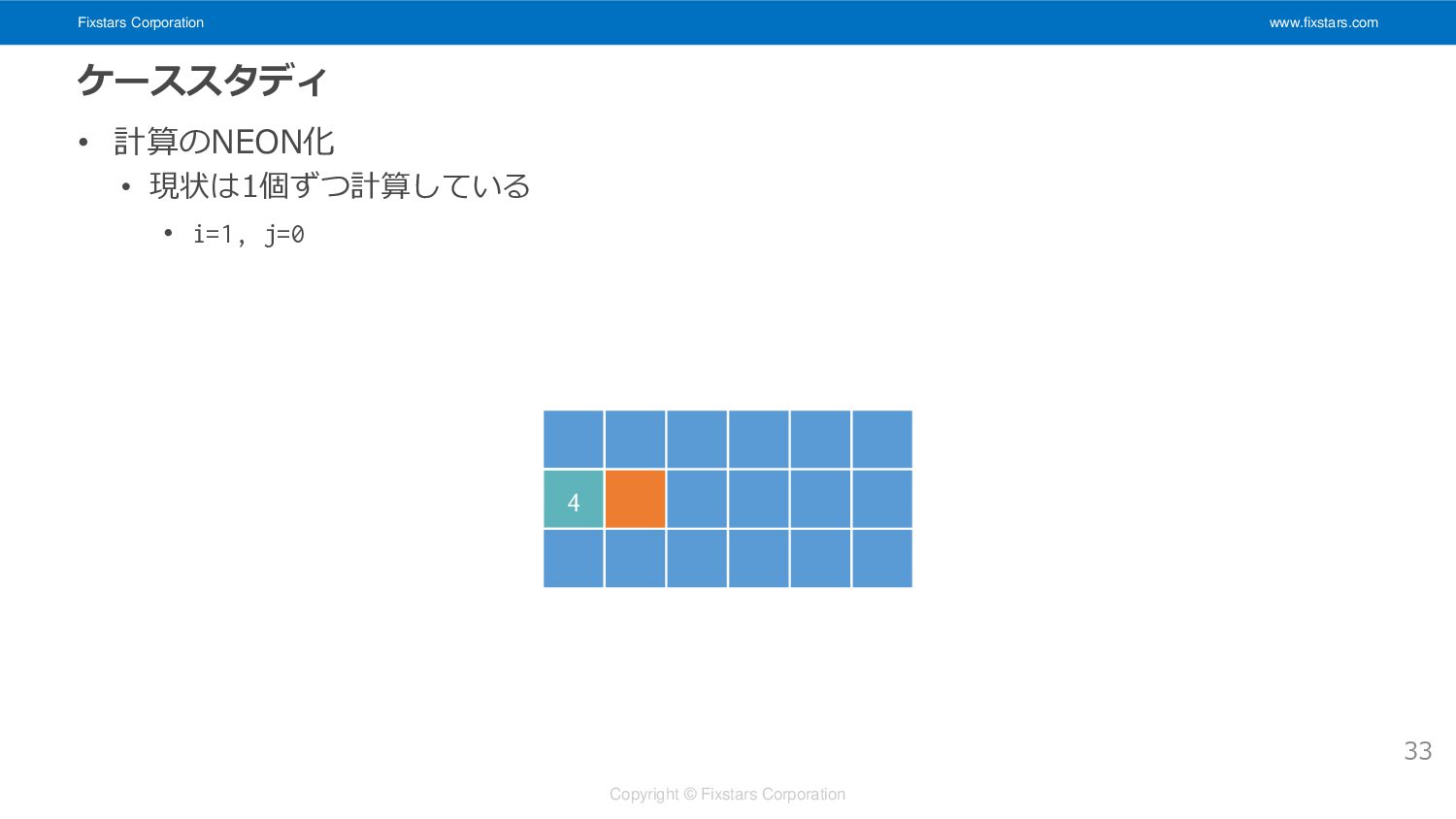
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 現状は1個ずつ計算している • i=0, j=0 30 1
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 現状は1個ずつ計算している • i=0, j=1 31 2
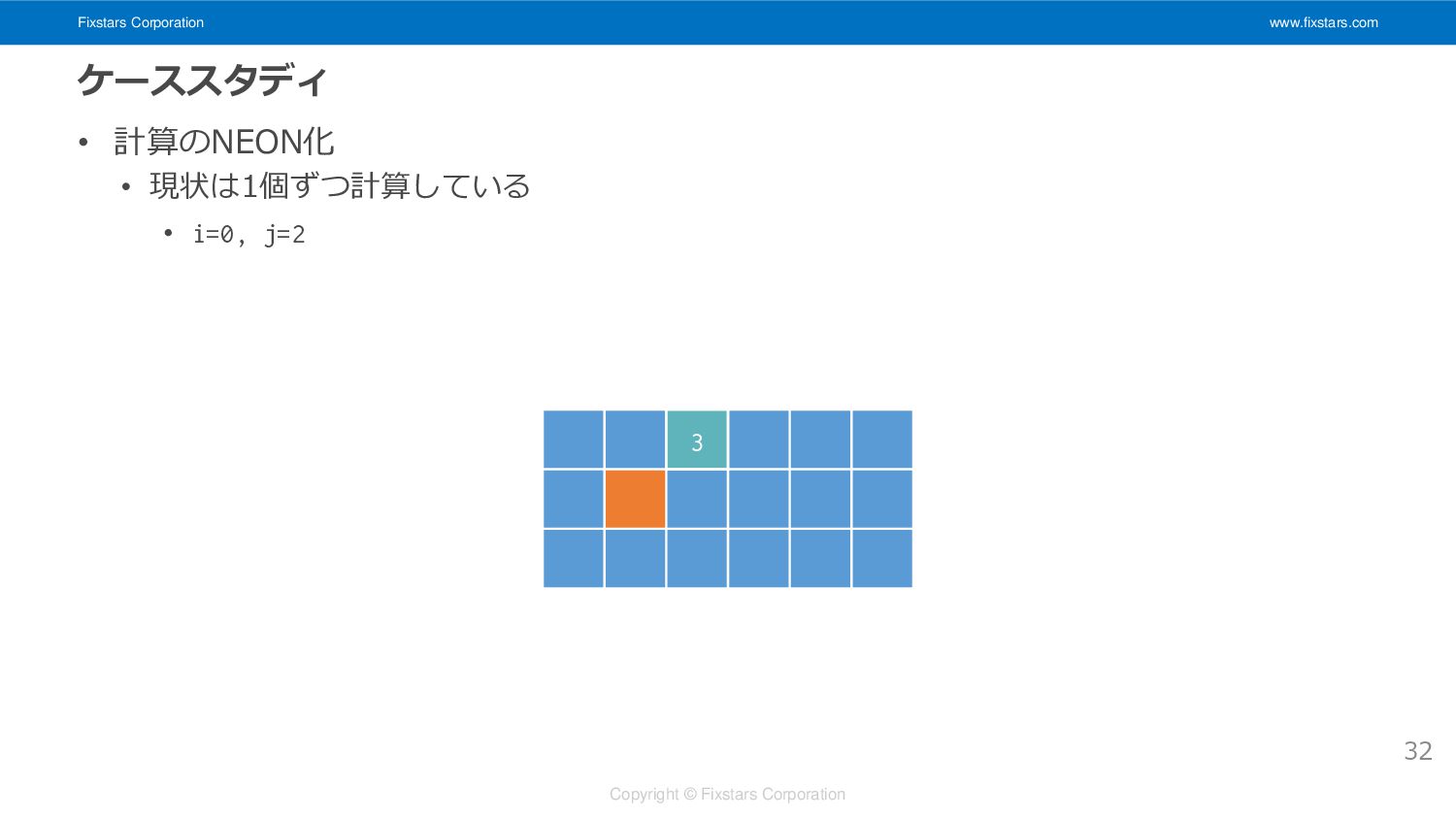
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 現状は1個ずつ計算している • i=0, j=2 32 3
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 現状は1個ずつ計算している • i=1, j=0 33 4
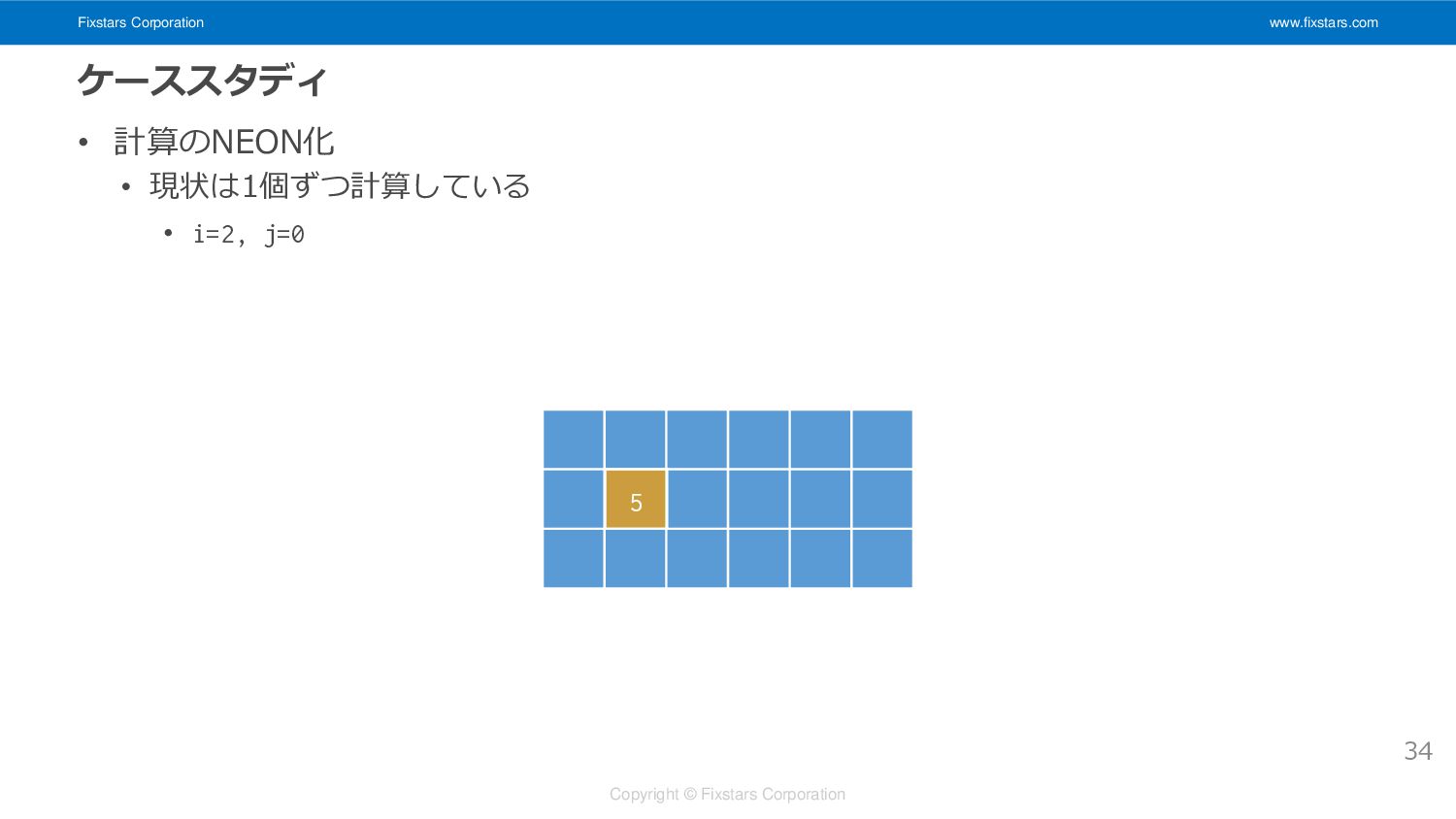
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 現状は1個ずつ計算している • i=2, j=0 34 5
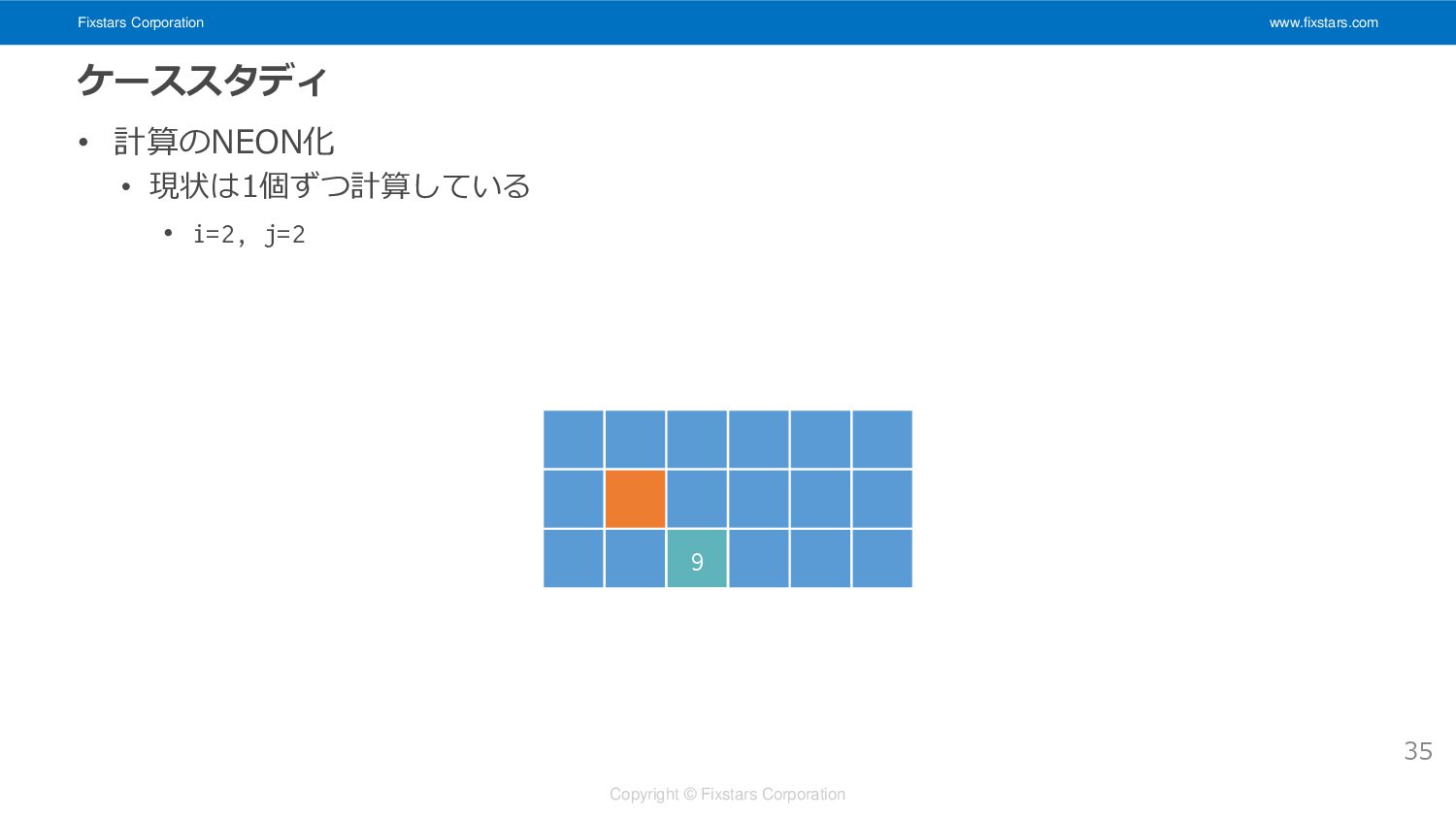
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 現状は1個ずつ計算している • i=2, j=2 35 9
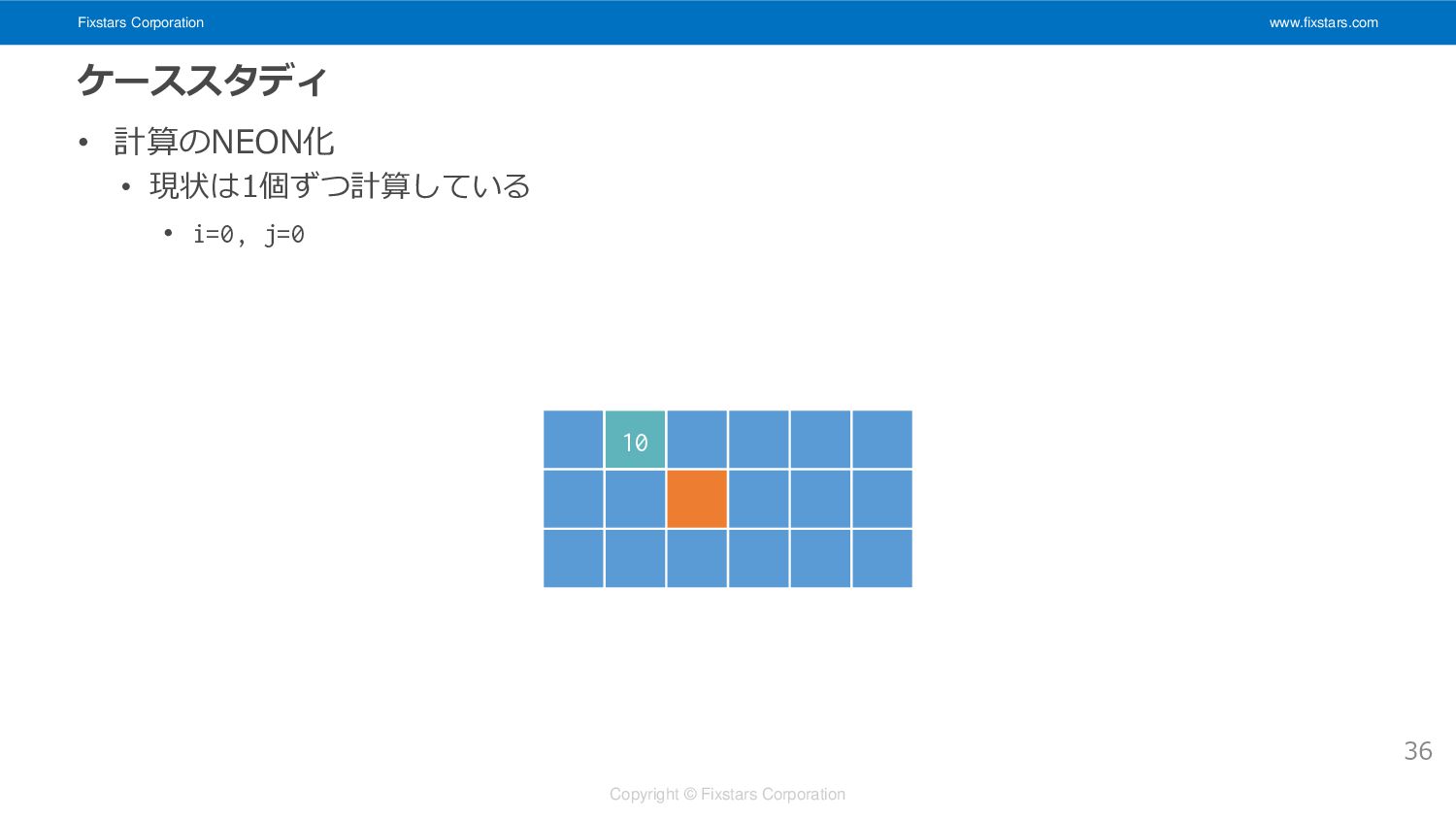
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 現状は1個ずつ計算している • i=0, j=0 36 10
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 現状は1個ずつ計算している • i=2, j=2 37 36
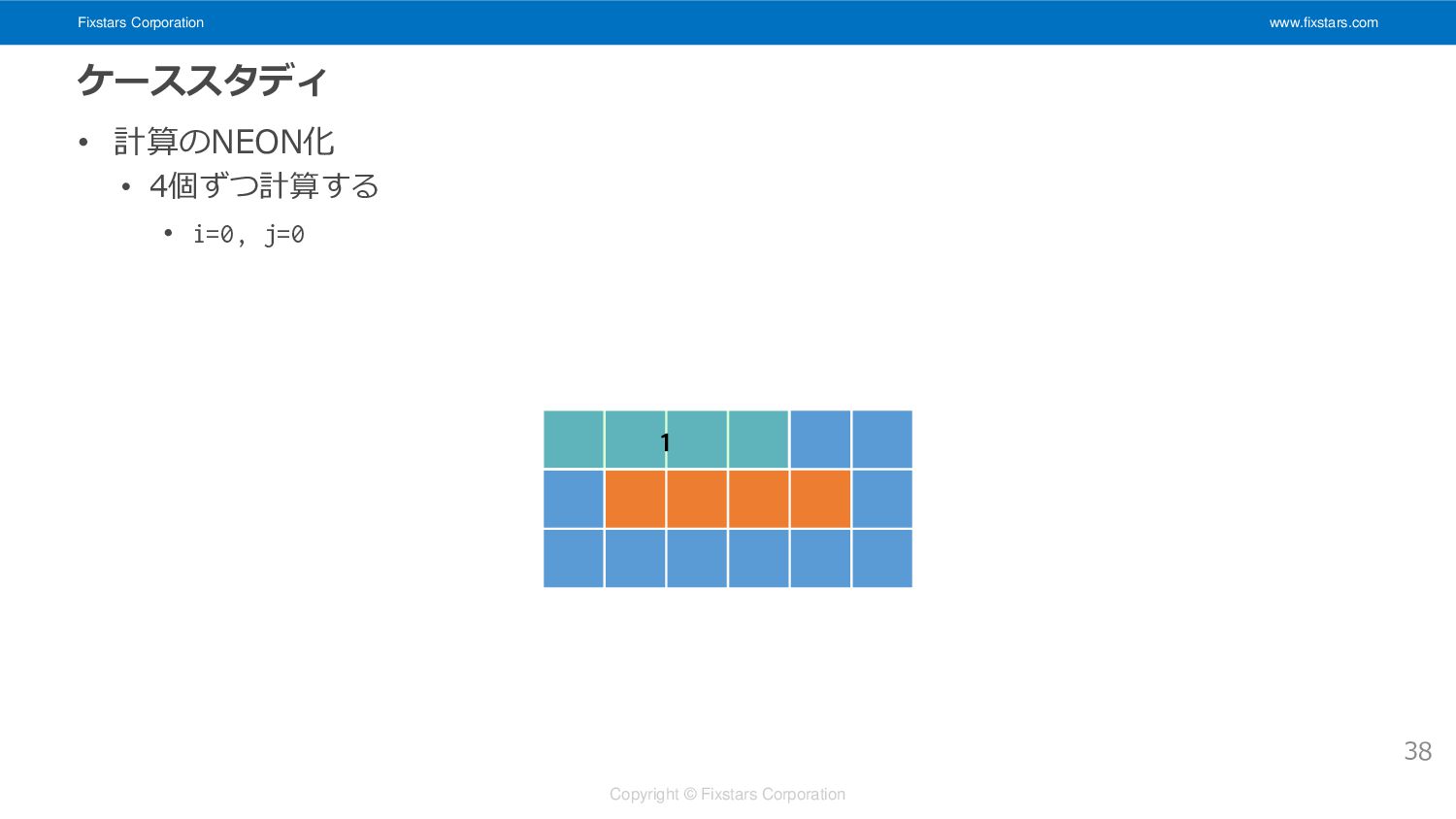
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 4個ずつ計算する • i=0, j=0 38 1
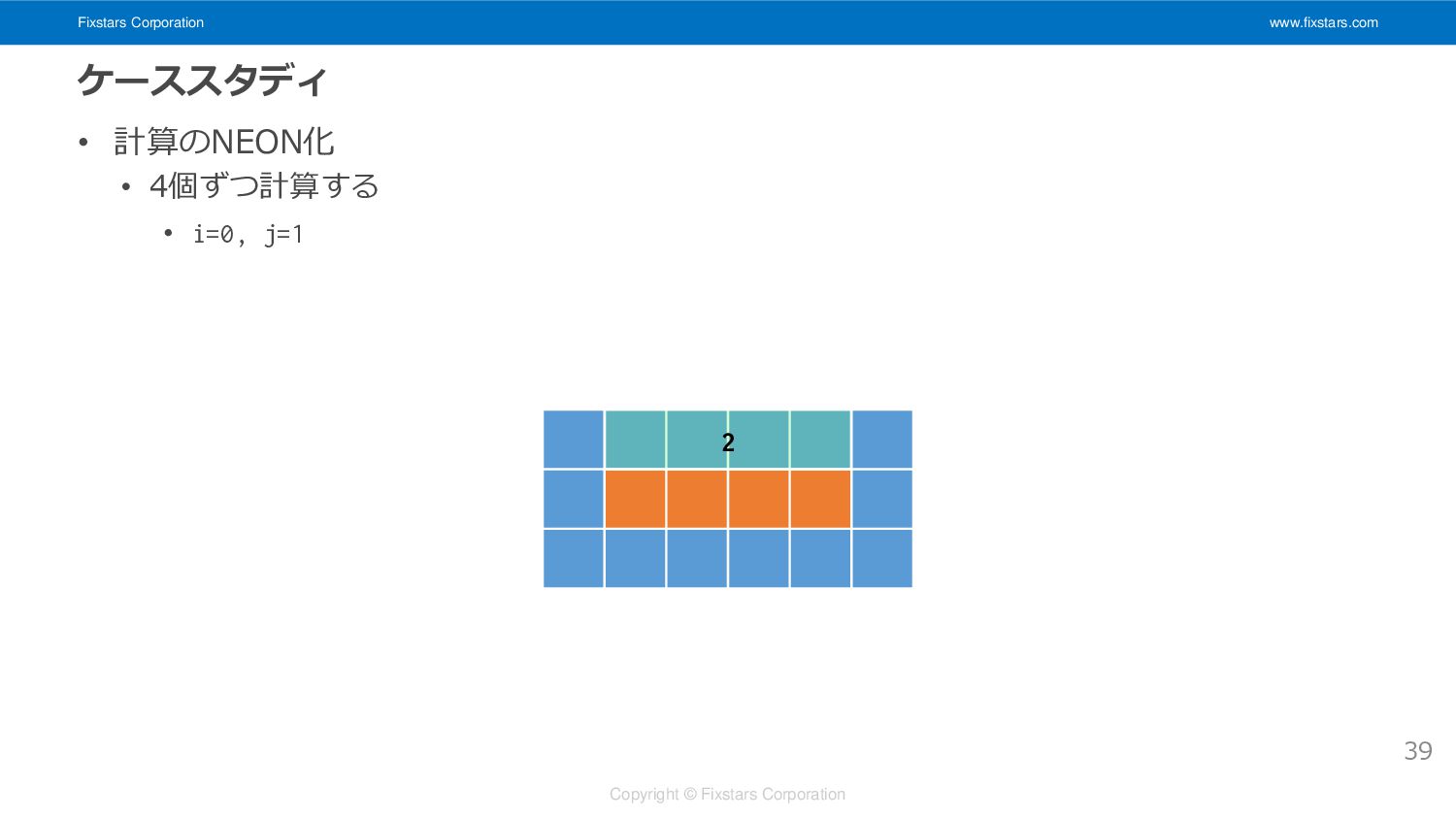
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 4個ずつ計算する • i=0, j=1 39 2
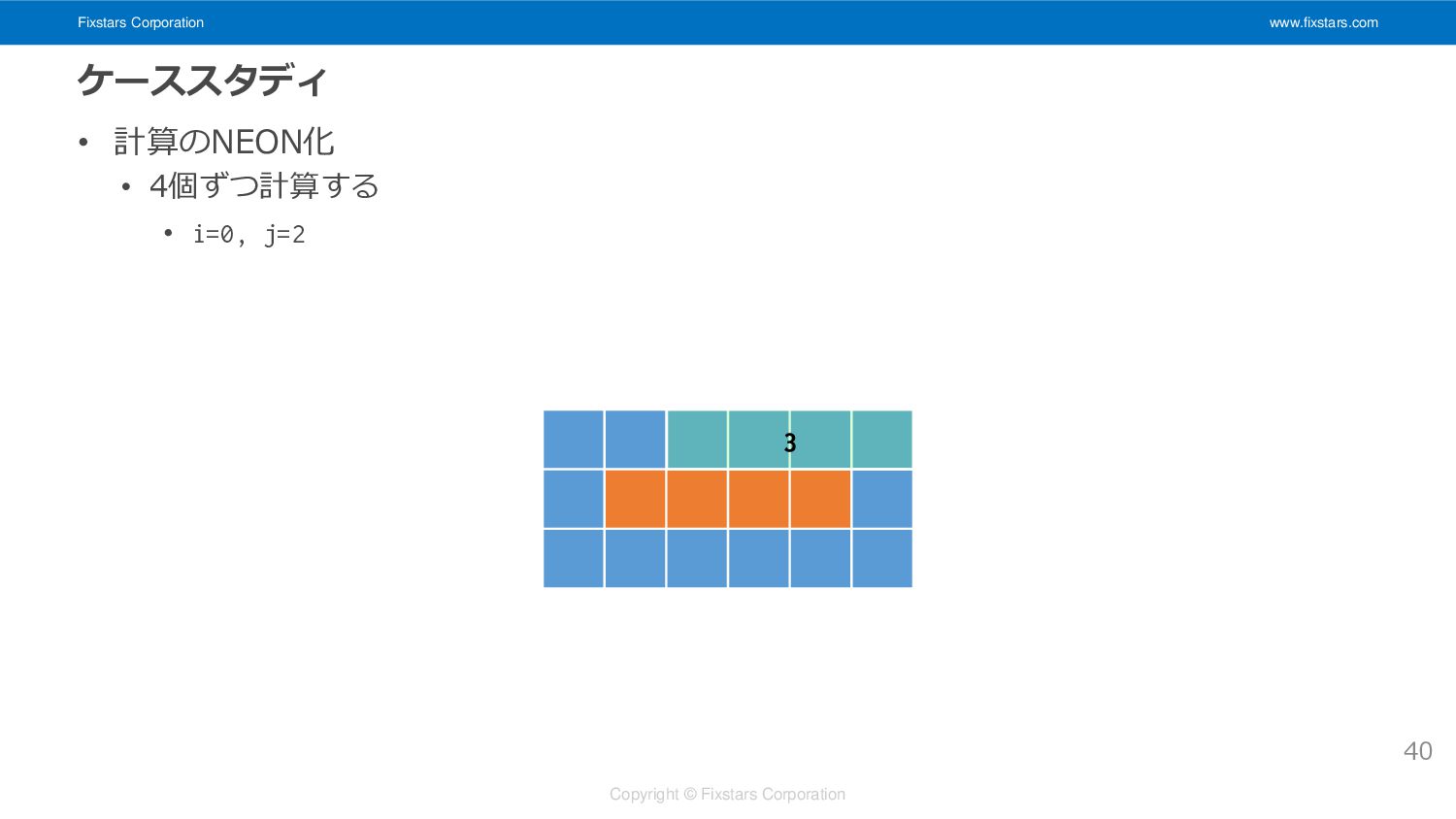
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 4個ずつ計算する • i=0, j=2 40 3
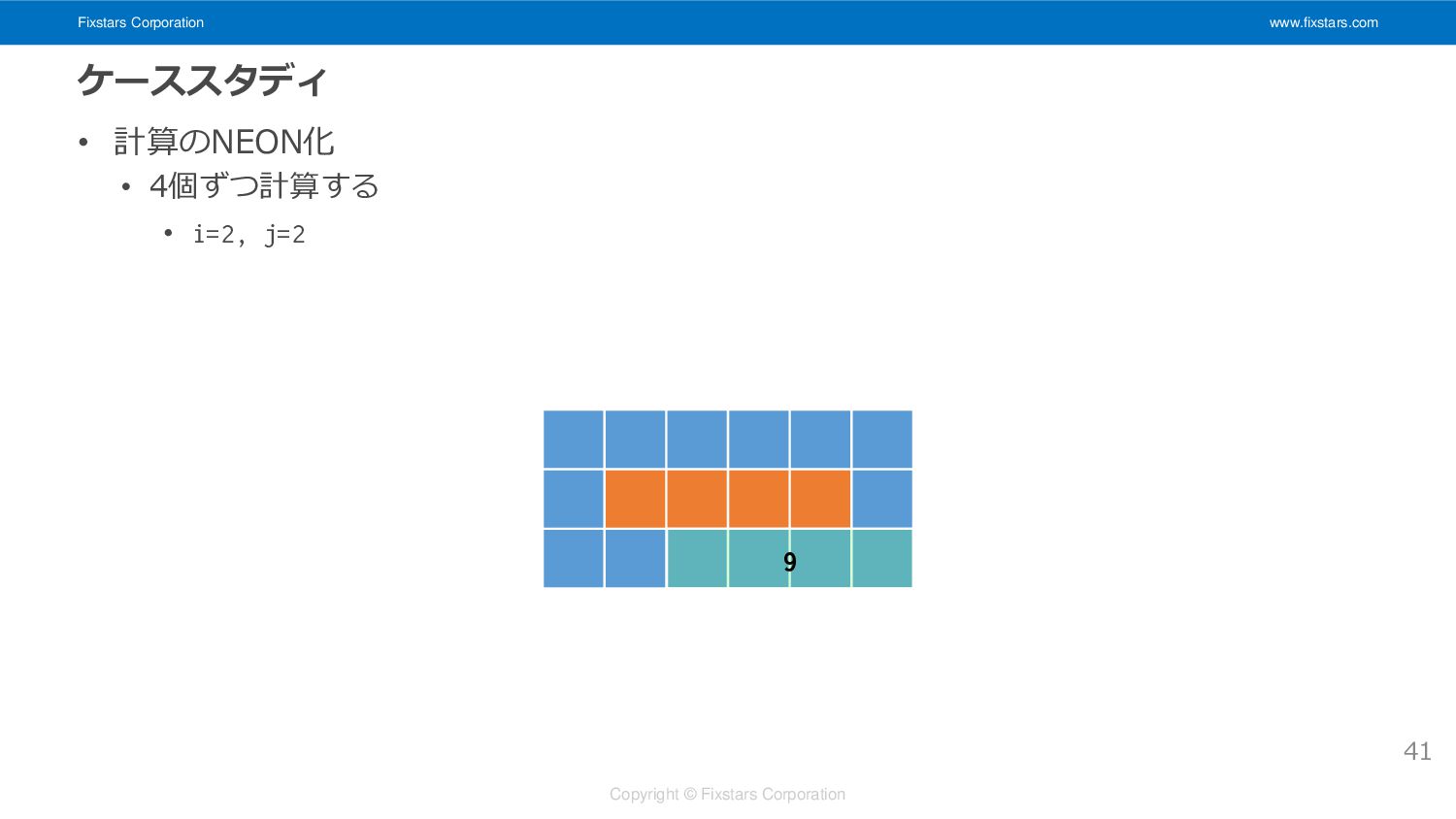
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ • 計算のNEON化
• 4個ずつ計算する • i=2, j=2 41 9
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ループアンロールとpeel loop •
x方向のループを両端と真ん中で分割する • 真ん中のループをNEON化していく(前後のがpeel loop) 42 //(略) for(std::size_t y = half_kernel_size; y < h-half_kernel_size; ++y){ std::size_t x = half_kernel_size; for(; x < 4; ++x){/*同じ処理*/} const std::std::size_t simd_end = w-half_kernel_size - (w-half_kernel_size)%4; for(; x < simd_end; ++x){ float t[3] = {}; for(std::size_t i = 0; i < kernel_size; ++i) for(std::size_t j = 0; j < kernel_size; ++j) for(std::size_t c = 0; c < 3; ++c) t[c] += src[y-half_kernel_size+i][x-half_kernel_size+j][c] * kernel[i][j]; for(std::size_t c = 0; c < 3; ++c) dst[y][x][c] = std::clamp<std::uint8_t>(static_cast<std::uint8_t>(t[c]), 0u, 255u); } //xループの終わり for(; x < w-half_kernel_size; ++x){/*同じ処理*/} } //yループの終わり
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ループアンロールとpeel loop •
真ん中のループを4でループアンロール • ひとまずループ全体を4回回すように(zループ/後で入れ替える) 43 //(略) for(std::size_t y = half_kernel_size; y < h-half_kernel_size; ++y){ std::size_t x = half_kernel_size; for(; x < 4; ++x){/*同じ処理*/} const std::std::size_t simd_end = w-half_kernel_size - (w-half_kernel_size)%4; for(; x < simd_end; x += 4)for(std::size_t z = 0; z < 4; ++z){ float t[3] = {}; for(std::size_t i = 0; i < kernel_size; ++i) for(std::size_t j = 0; j < kernel_size; ++j) for(std::size_t c = 0; c < 3; ++c) t[c] += src[y-half_kernel_size+i][x+z-half_kernel_size+j][c] * kernel[i][j]; for(std::size_t c = 0; c < 3; ++c) dst[y][x+z][c] = std::clamp<std::uint8_t>(static_cast<std::uint8_t>(t[c]), 0u, 255u); } //zループ・xループの終わり for(; x < w-half_kernel_size; ++x){/*同じ処理*/} } //yループの終わり
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • 読み込みと計算を分離する
44 //(略) for(; x < simd_end; x += 4)for(std::size_t z = 0; z < 4; ++z){ float t[3] = {}; for(std::size_t i = 0; i < kernel_size; ++i) for(std::size_t j = 0; j < kernel_size; ++j){ float s[3] = {}; const float kern = kernel[i][j]; for(std::size_t c = 0; c < 3; ++c) s[c] = src[y-half_kernel_size+i][x+z-half_kernel_size+j][c]; for(std::size_t c = 0; c < 3; ++c) t[c] += s[c] * kern; } //jループ・iループの終わり for(std::size_t c = 0; c < 3; ++c) dst[y][x+z][c] = std::clamp<std::uint8_t>(static_cast<std::uint8_t>(t[c]), 0u, 255u); } //zループ・xループの終わり //(略)
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • ループを入れ替える
• zループを内側に 45 //(略) for(; x < simd_end; x += 4){ float t[3][4] = {}; for(std::size_t i = 0; i < kernel_size; ++i) for(std::size_t j = 0; j < kernel_size; ++j){ float s[3][4] = {}; const float kern = kernel[i][j]; for(std::size_t c = 0; c < 3; ++c) for(std::size_t z = 0; z < 4; ++z) s[c][z] = src[y-half_kernel_size+i][x+z-half_kernel_size+j][c]; for(std::size_t c = 0; c < 3; ++c) for(std::size_t z = 0; z < 4; ++z) t[c][z] += s[c][z] * kern; } //jループ・iループの終わり for(std::size_t c = 0; c < 3; ++c) for(std::size_t z = 0; z < 4; ++z) dst[y][x+z][c] = std::clamp<std::uint8_t>(static_cast<std::uint8_t>(t[c][z]), 0u, 255u); } //xループの終わり //(略)
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • NEONで演算
• まずSIMDレジスタにデータを乗せる 46 //(略) for(; x < simd_end; x += 4){ float32x4x3_t vt; for(std::size_t c = 0; c < 3; ++c) vt.val[c] = vdupq_n_f32(0.f); for(std::size_t i = 0; i < kernel_size; ++i) for(std::size_t j = 0; j < kernel_size; ++j){ float32x4x3_t vs; const float32x4_t kern = vdupq_n_f32(kernel[i][j]); for(std::size_t c = 0; c < 3; ++c){ float s[4]; for(std::size_t z = 0; z < 4; ++z) s[z] = src[y-half_kernel_size+i][x+z-half_kernel_size+j][c]; vs.val[c] = vld1q_f32(s); } //続く
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • NEONで演算
• SIMD演算をしてSIMDレジスタからメモリに書き戻す 47 //続き for(std::size_t c = 0; c < 3; ++c) vt.val[c] = vfmaq_f32(vt.val[c], vs.val[c], kern); } //jループ・iループの終わり for(std::size_t c = 0; c < 3; ++c){ float t[4]; vst1q_f32(t, vt.val[c]); for(std::size_t z = 0; z < 4; ++z) dst[y][x+z][c] = std::clamp<std::uint8_t>(static_cast<std::uint8_t>(t[z]), 0u, 255u); } } //xループの終わり //(略)
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • NEONで演算
• 使ったintrinsic • vdupq_n_f32 • float -> float32x4_t • 4つすべて引数の値で初期化する • vld1q_f32 • const float* -> float32x4_t • メモリから4要素読み込んでSIMDレジスタに格納 • vst1q_f32 • (float*, float32x4_t) -> void • SIMDレジスタからメモリに4要素書き込み • vfmaq_f32 • (float32x4_t, float32x4_t, float32x4_t) -> float32x4_t • FMA(Fused Multiply Add, 融合積和演算) • a+b*cを返す • 丸めを1度しか行わない(精度が良い) • 速い 48
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 Q. これで速くなるか?
A. いいえ • むしろ遅い 131.9ms(+74.1ms) • 計算のたびにメモリ読み込みをしているのが原因 • vld1q_f32で読み込むためにはfloat型の配列に詰めなくてはいけない • チャンネルごとに読み込む都合で詰める際のメモリアクセスが連続でなくなっている • 極力レジスタ上のやりとりで済ませたい 49
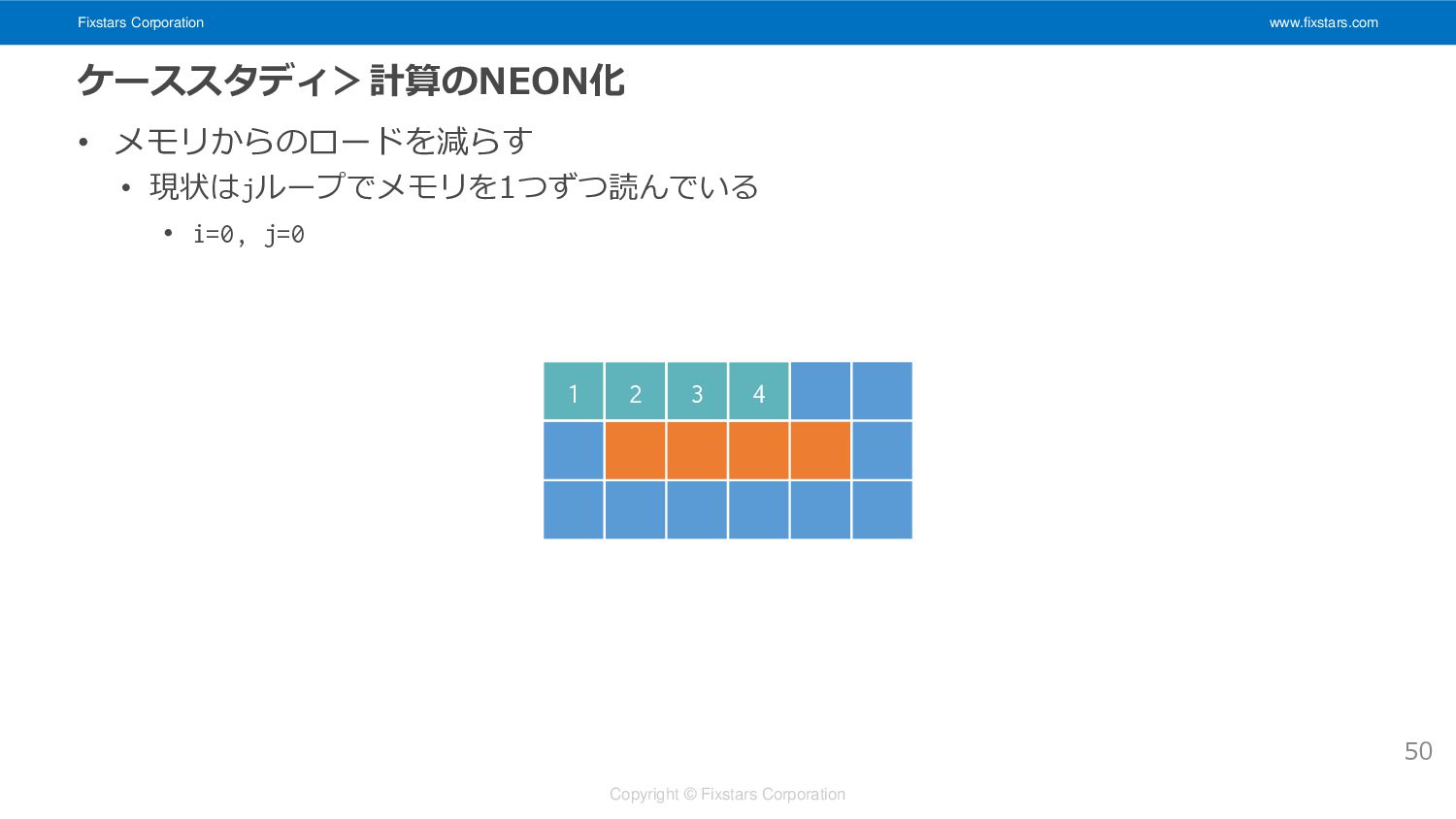
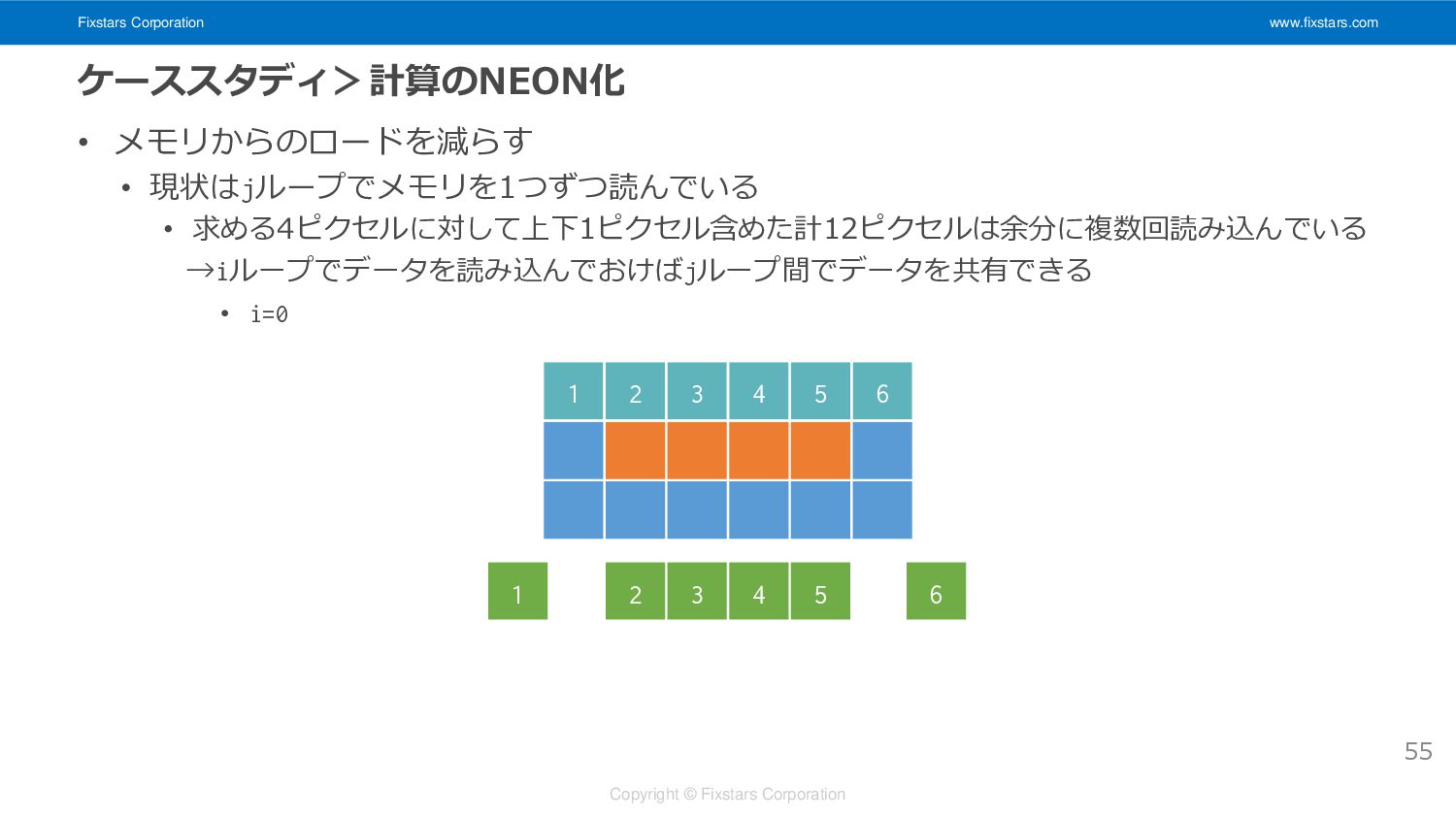
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 現状はjループでメモリを1つずつ読んでいる • i=0, j=0 50 1 2 3 4
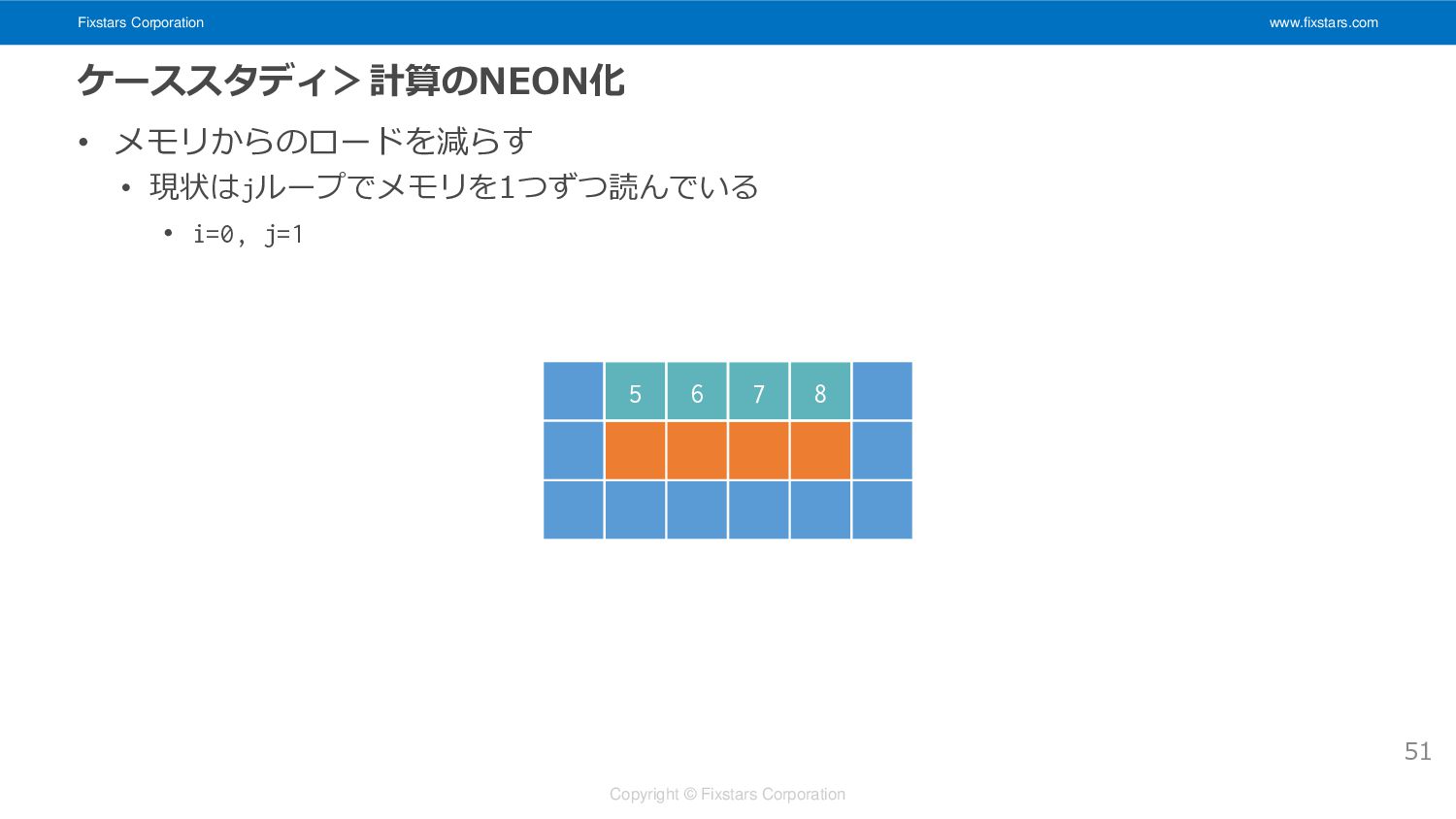
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 現状はjループでメモリを1つずつ読んでいる • i=0, j=1 51 5 6 7 8
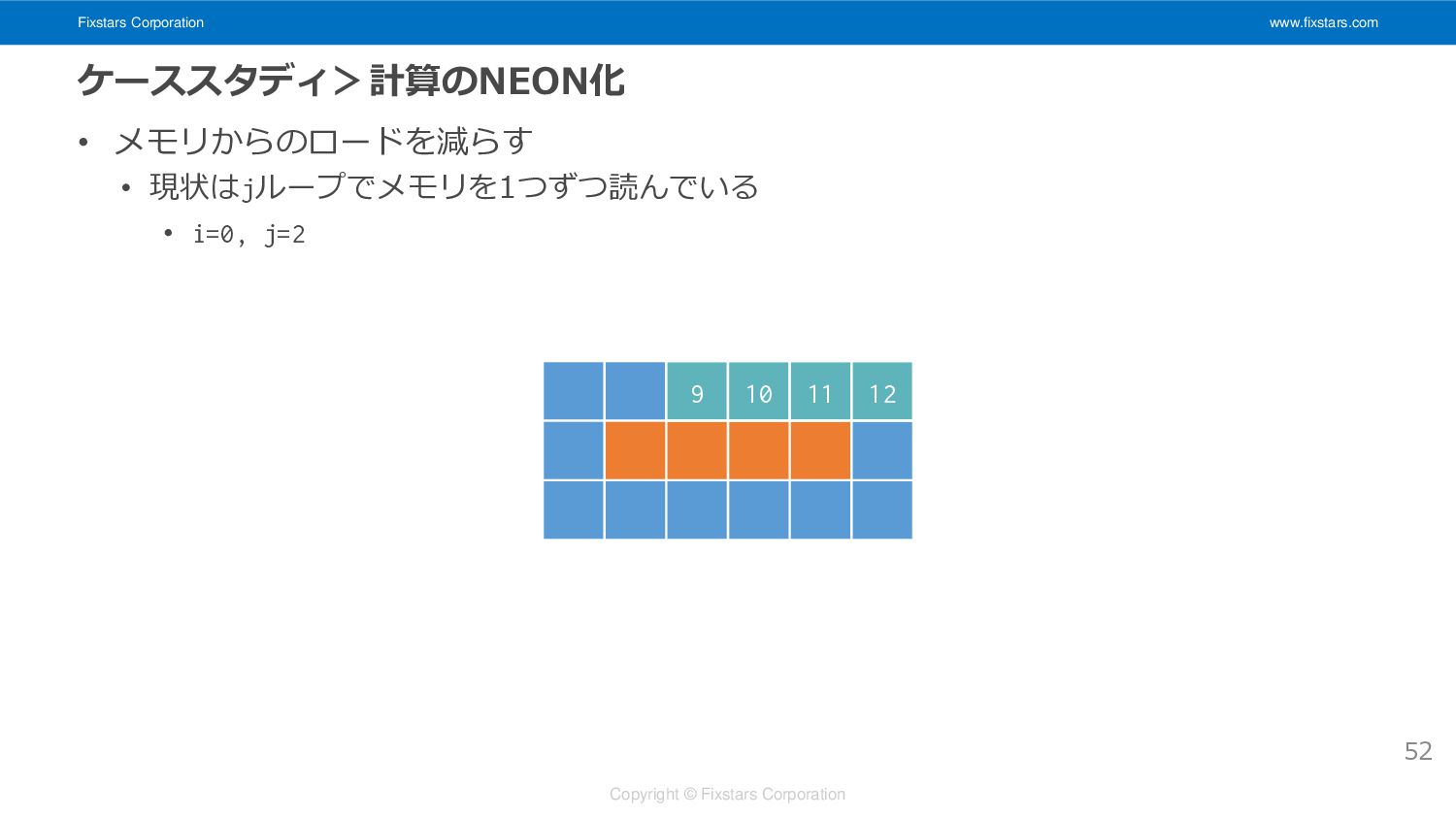
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 現状はjループでメモリを1つずつ読んでいる • i=0, j=2 52 9 10 11 12
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 現状はjループでメモリを1つずつ読んでいる • 求める4ピクセルに対して上下1ピクセル含めた計12ピクセルは余分に複数回読み込んでいる 53
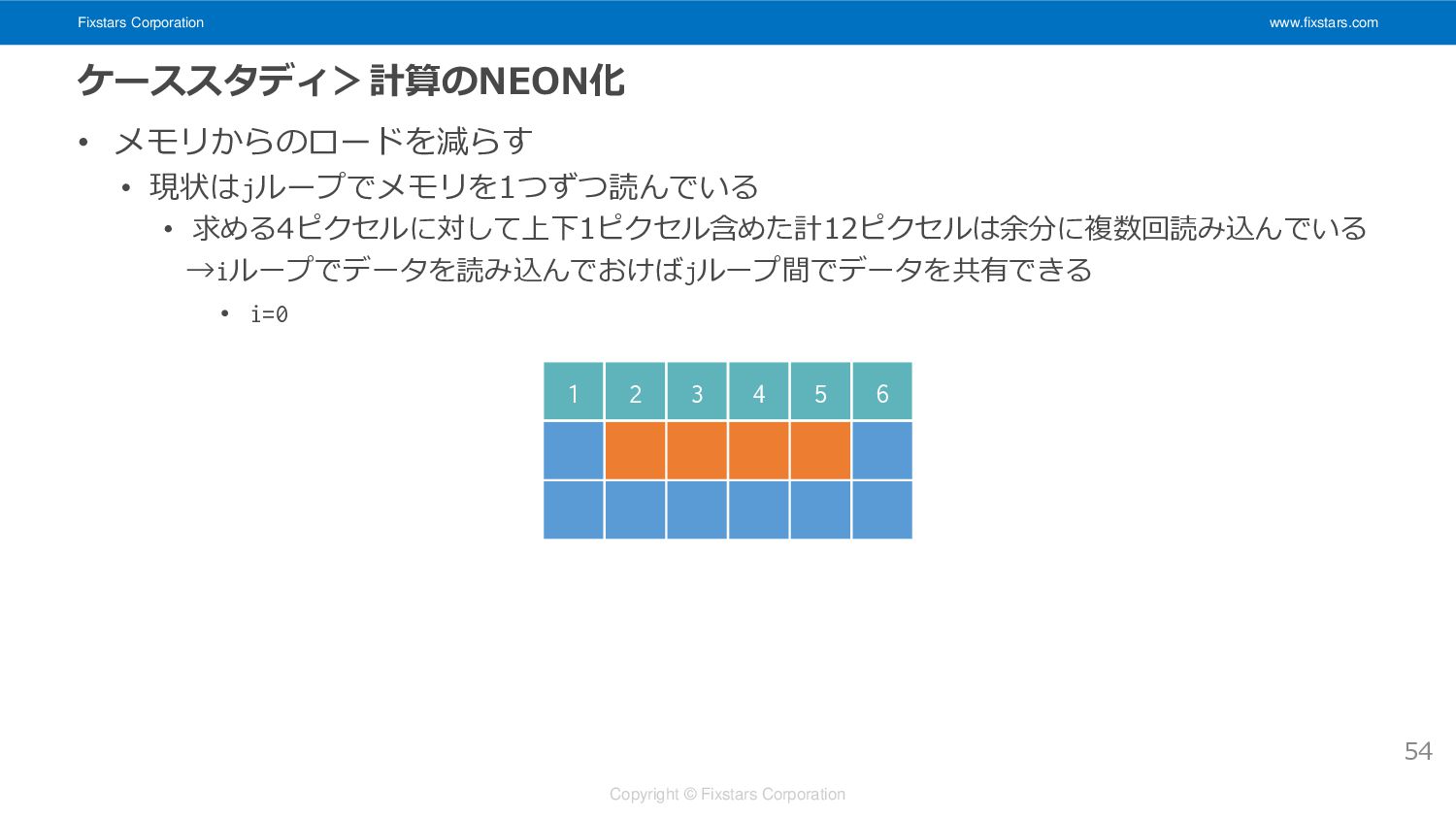
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 現状はjループでメモリを1つずつ読んでいる • 求める4ピクセルに対して上下1ピクセル含めた計12ピクセルは余分に複数回読み込んでいる →iループでデータを読み込んでおけばjループ間でデータを共有できる • i=0 54 1 2 3 4 5 6
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 現状はjループでメモリを1つずつ読んでいる • 求める4ピクセルに対して上下1ピクセル含めた計12ピクセルは余分に複数回読み込んでいる →iループでデータを読み込んでおけばjループ間でデータを共有できる • i=0 55 2 3 4 5 1 6 1 2 3 4 5 6
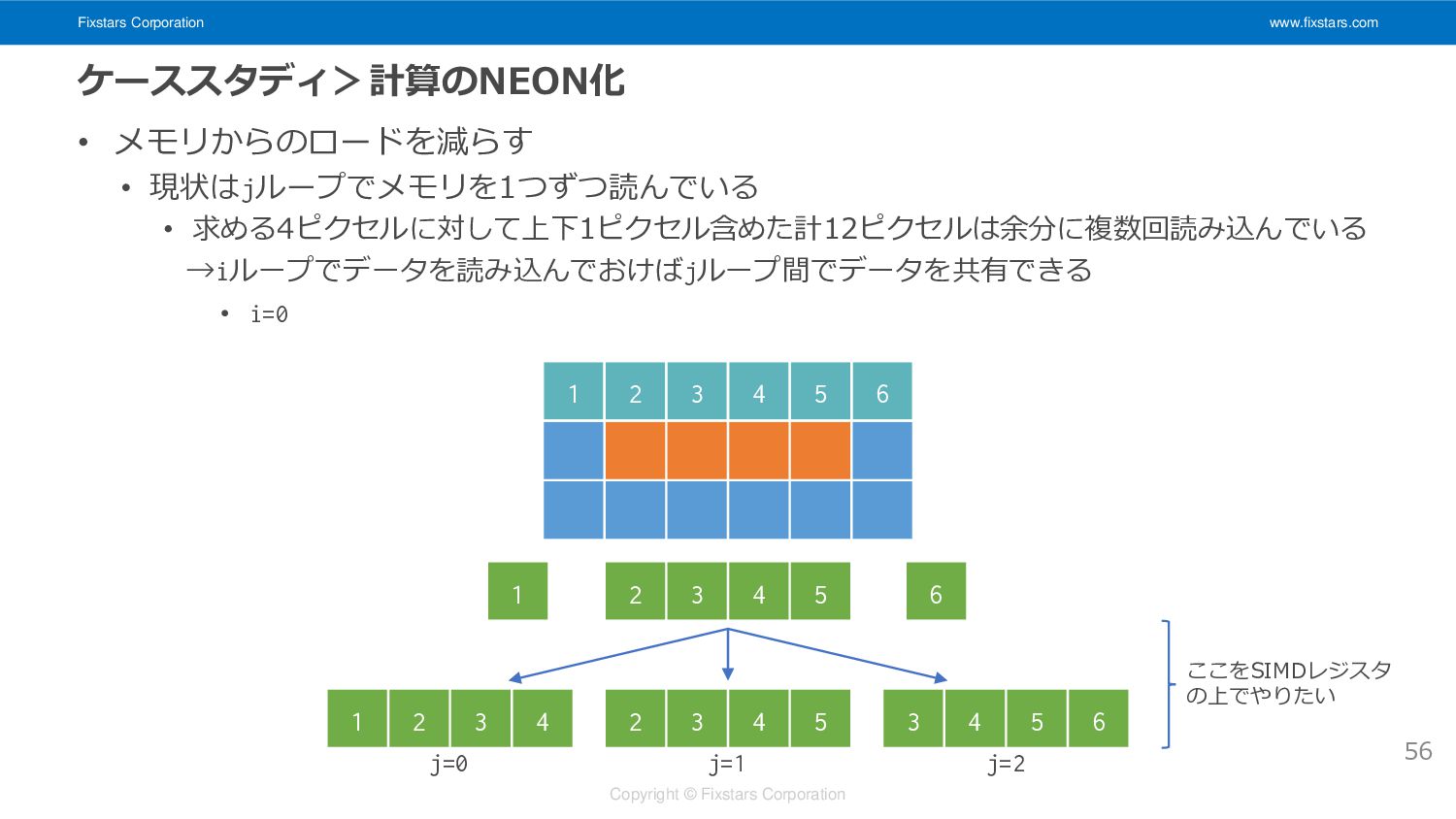
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 現状はjループでメモリを1つずつ読んでいる • 求める4ピクセルに対して上下1ピクセル含めた計12ピクセルは余分に複数回読み込んでいる →iループでデータを読み込んでおけばjループ間でデータを共有できる • i=0 56 2 3 4 5 1 6 1 2 3 4 2 3 4 5 3 4 5 6 ここをSIMDレジスタ の上でやりたい 1 2 3 4 5 6 j=0 j=1 j=2
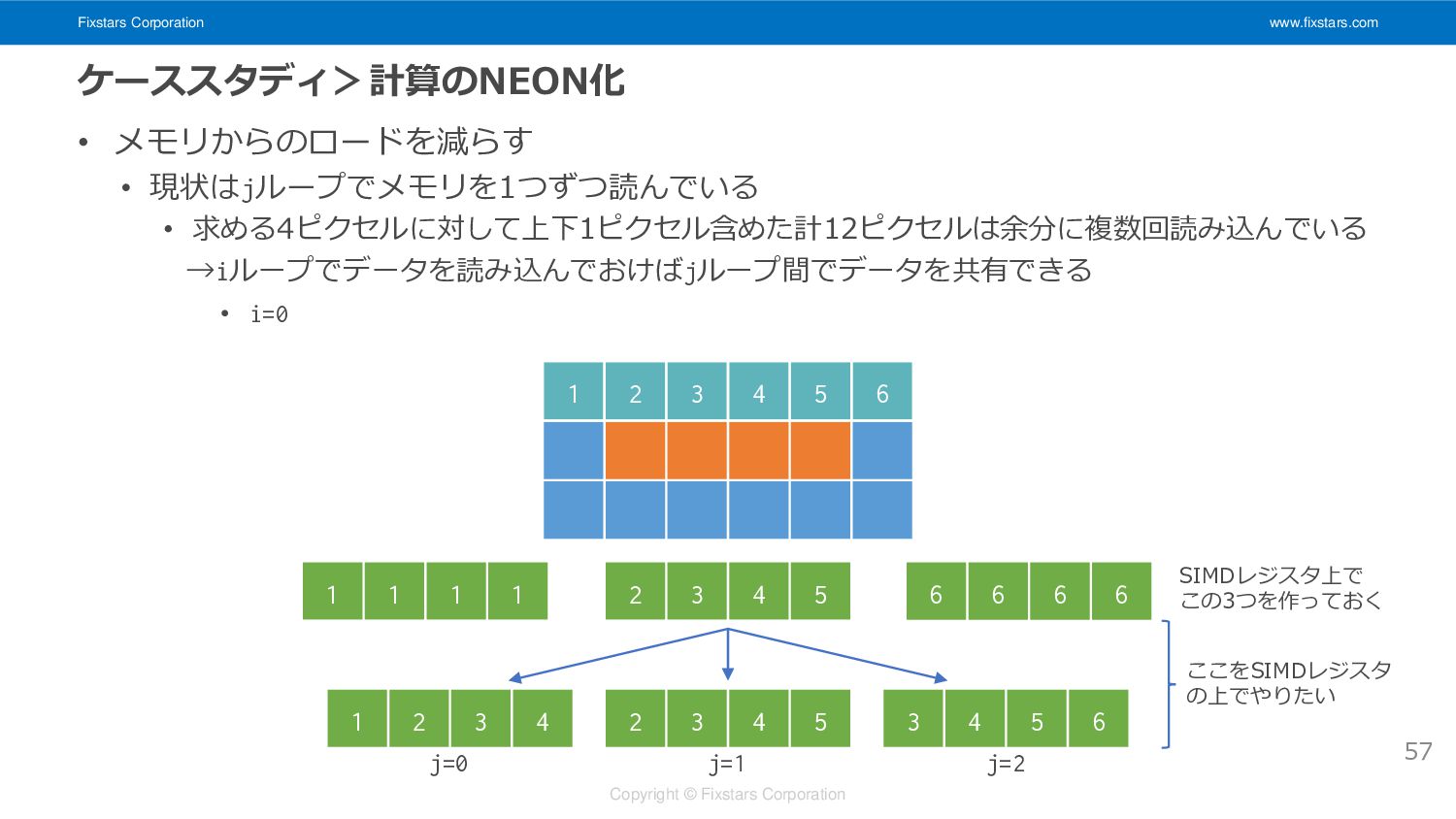
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 現状はjループでメモリを1つずつ読んでいる • 求める4ピクセルに対して上下1ピクセル含めた計12ピクセルは余分に複数回読み込んでいる →iループでデータを読み込んでおけばjループ間でデータを共有できる • i=0 57 2 3 4 5 1 2 3 4 2 3 4 5 3 4 5 6 1 2 3 4 5 6 1 1 1 1 6 6 6 6 SIMDレジスタ上で この3つを作っておく j=0 j=1 j=2 ここをSIMDレジスタ の上でやりたい
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• iループで必要なデータを読み込んでおく 58 //(略) for(; x < simd_end; x += 4){ float32x4x3_t vt; for(std::size_t c = 0; c < 3; ++c) vt.val[c] = vdupq_n_f32(0.f); for(std::size_t i = 0; i < kernel_size; ++i){ float32x4x3_t vss[3]; for(std::size_t c = 0; c < 3; ++c){ vss[0].val[c] = vdupq_n_f32(src[y-half_kernel_size+i][x-half_kernel_size][c]); float s[4]; for(std::size_t z = 0; z < 4; ++z) s[z] = src[y-half_kernel_size+i][x+z-half_kernel_size+j][c]; vss[1].val[c] = vld1q_f32(s); vss[2].val[c] = vdupq_n_f32(src[y-half_kernel_size+i][x+4][c]); } //cループの終わり //続く
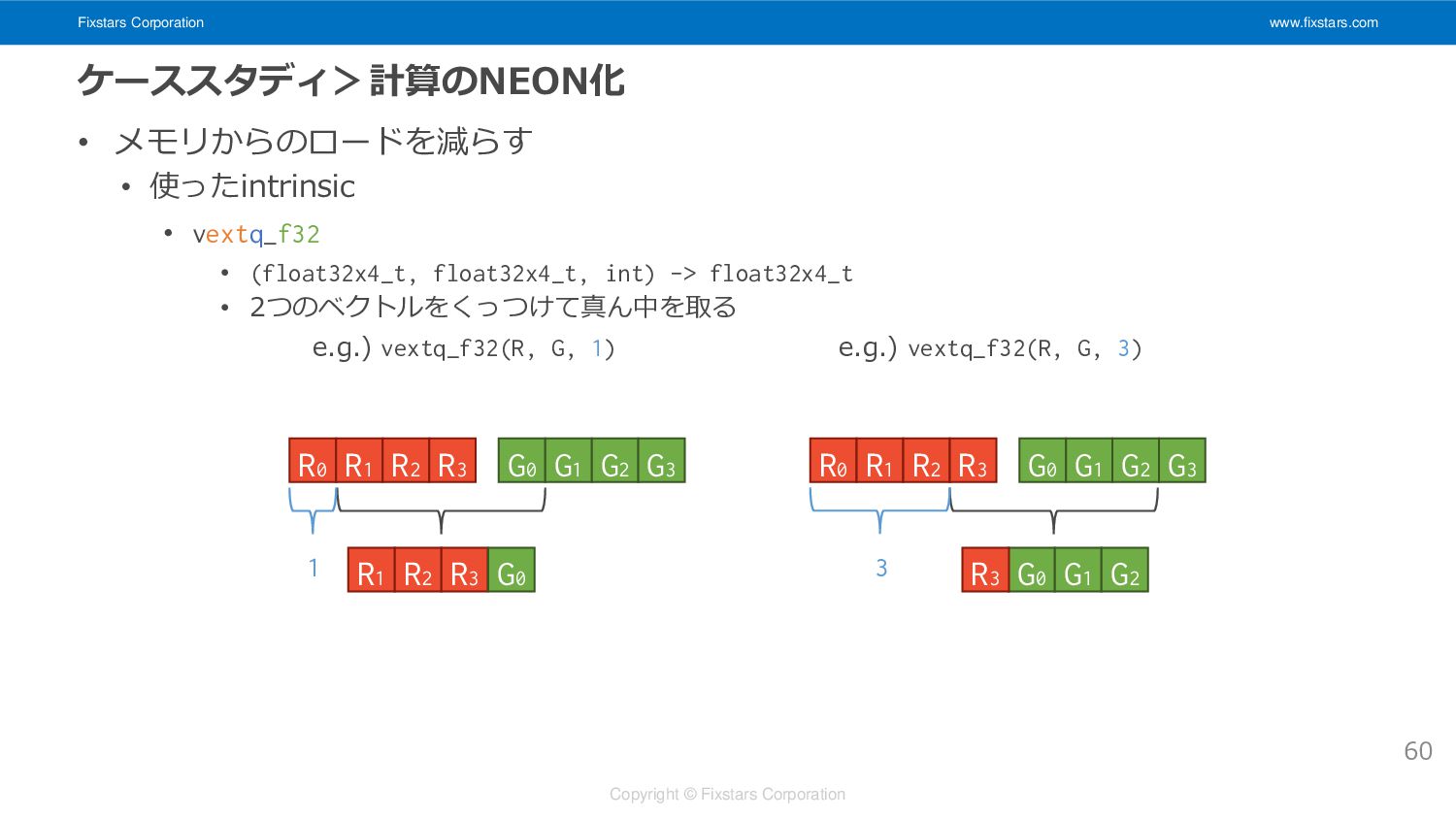
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• jループでSIMDレジスタ上で値を組み替えて目的のSIMDベクトルを作る 59 //続き for(std::size_t j = 0; j < kernel_size; ++j){ float32x4x3_t vs; const float32x4_t kern = vdupq_n_f32(kernel[i][j]); for(std::size_t c = 0; c < 3; ++c){ switch(j){ case 0: vs.val[c] = vextq_f32(vss[0].val[c], vss[1].val[c], 3); break; case 1: vs.val[c] = vss[1].val[c]; break; case 2: vs.val[c] = vextq_f32(vss[1].val[c], vss[2].val[c], 1); break; } } for(std::size_t c = 0; c < 3; ++c) vt.val[c] = vfmaq_f32(vt.val[c], vs.val[c], kern); } //jループの終わり //(略)
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• 使ったintrinsic • vextq_f32 • (float32x4_t, float32x4_t, int) -> float32x4_t • 2つのベクトルをくっつけて真ん中を取る e.g.) vextq_f32(R, G, 1) e.g.) vextq_f32(R, G, 3) 60 R0 R1 R2 R3 G0 G1 G2 G3 R1 R2 R3 G0 R0 R1 R2 R3 G0 G1 G2 G3 G0 G1 G2 R3 1 3
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>計算のNEON化 • メモリからのロードを減らす
• これで56.3ms(-1.5ms) • 遅くはないが速くもない • 次に読み込みと書き込みをNEON化する • 今は画像のデータ領域から1個ずつ読んで配列に4個詰めてからSIMDレジスタに ロードしている ストアも同様 • しかもこの際のメモリアクセスが連続でない →直接画像のデータ領域からSIMDレジスタに読み込みたい • uint8を4個取り出して4個のfloat32に型変換する必要がある • uint8x4_tは存在しないので素直にはできない 61
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • どこをNEON化するか(再掲)
• 計算 • 各ピクセルの各色毎にfloatの乗算と加算を9回行っている • ここを複数ピクセル同時に行う • float(32bit)なので128/32=4個ずつ同時に扱える • 読み込み/書き込み • RGBでインタリーブされたuint8_tのデータ列 • vld3q_u8/vst3q_u8を使えば128/8=16ピクセルずつ同時に読み書き可能 • しかもデインタリーブ/インタリーブは自動で行われる • 読み込み/書き込みの並列度と計算の並列度が一致しない →16ピクセル分読み込んで4個ずつの計算を4回行う 62
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 読み書きのNEON化
• 現状はiループでメモリを1つずつ読んでいる • 読んだデータはiループ内で使い回す • i=0 63 1 2 3 4 5 6
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 読み書きのNEON化
• 現状はiループでメモリを1つずつ読んでいる • 読んだデータはiループ内で使い回す • i=0 64 7 8 9 10 11 12
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 読み書きのNEON化
• 現状はiループでメモリを1つずつ読んでいる • 読んだデータはiループ内で使い回す • i=0 65 13 14 15 16 17 18
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 読み書きのNEON化
• 現状はiループでメモリを1つずつ読んでいる • 読んだデータはiループ内で使い回す • i=0 66 19 20 21 22 23 24
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 読み書きのNEON化
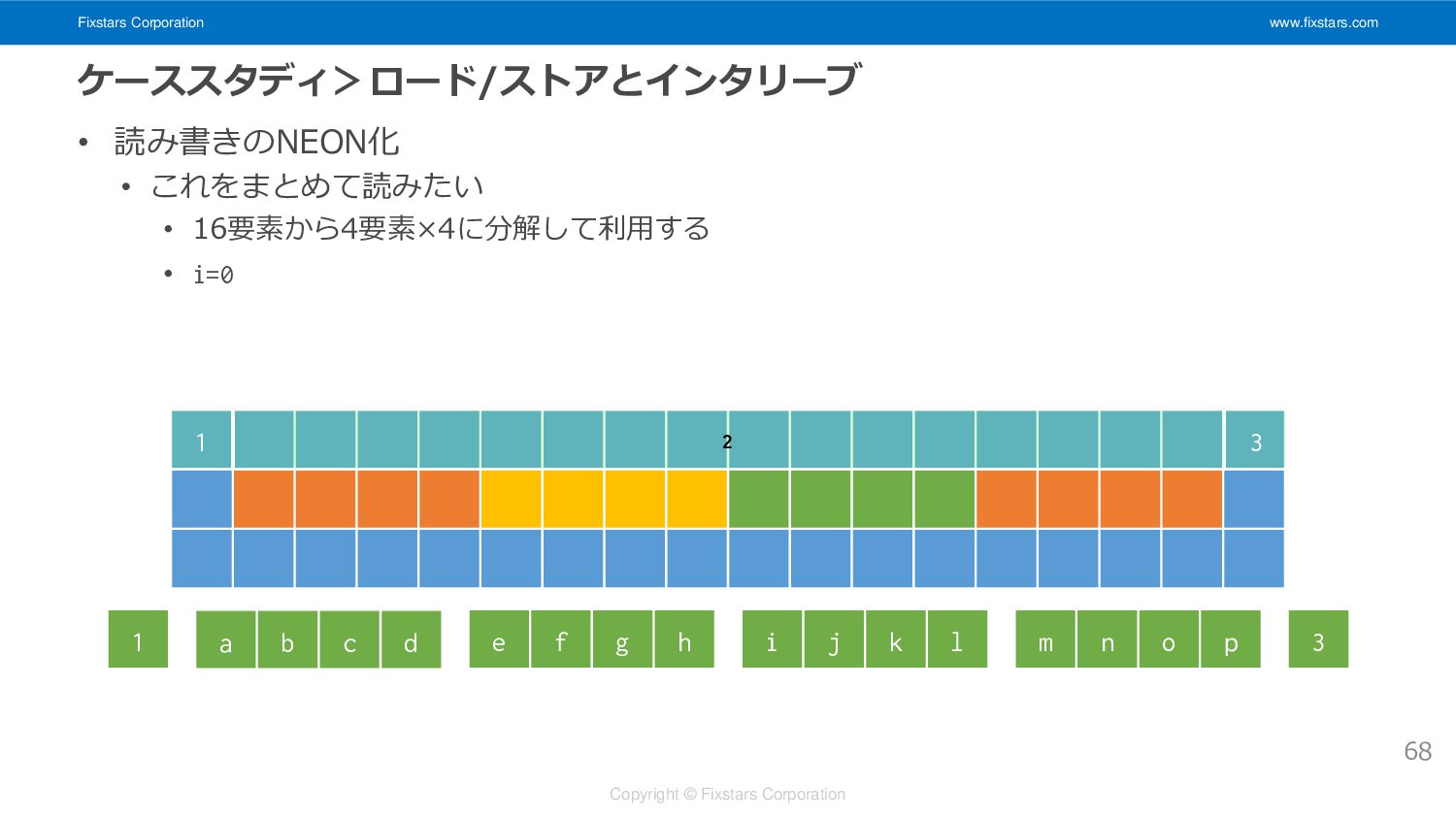
• これをまとめて読みたい • i=0 67 1 3 2
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 読み書きのNEON化
• これをまとめて読みたい • 16要素から4要素×4に分解して利用する • i=0 68 1 3 1 3 a b c d e f g h i j k l m n o p 2
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • ループアンロールを16ずつにする
• 16個ずつ読み書きするため 69 static constexpr std::size_t kernel_size = 3; static constexpr std::size_t half_kernel_size = kernel_size/2; for(std::size_t y = half_kernel_size; y < h-half_kernel_size; ++y){ std::size_t x = half_kernel_size; for(; x < 16; ++x){/*ナイーブな処理*/} const std::std::size_t simd_end = w-half_kernel_size - (w-half_kernel_size)%16; for(; x < simd_end; x += 16){ /*次のページ以降で説明*/ } for(; x < w-half_kernel_size; ++x){/*ナイーブな処理*/} }
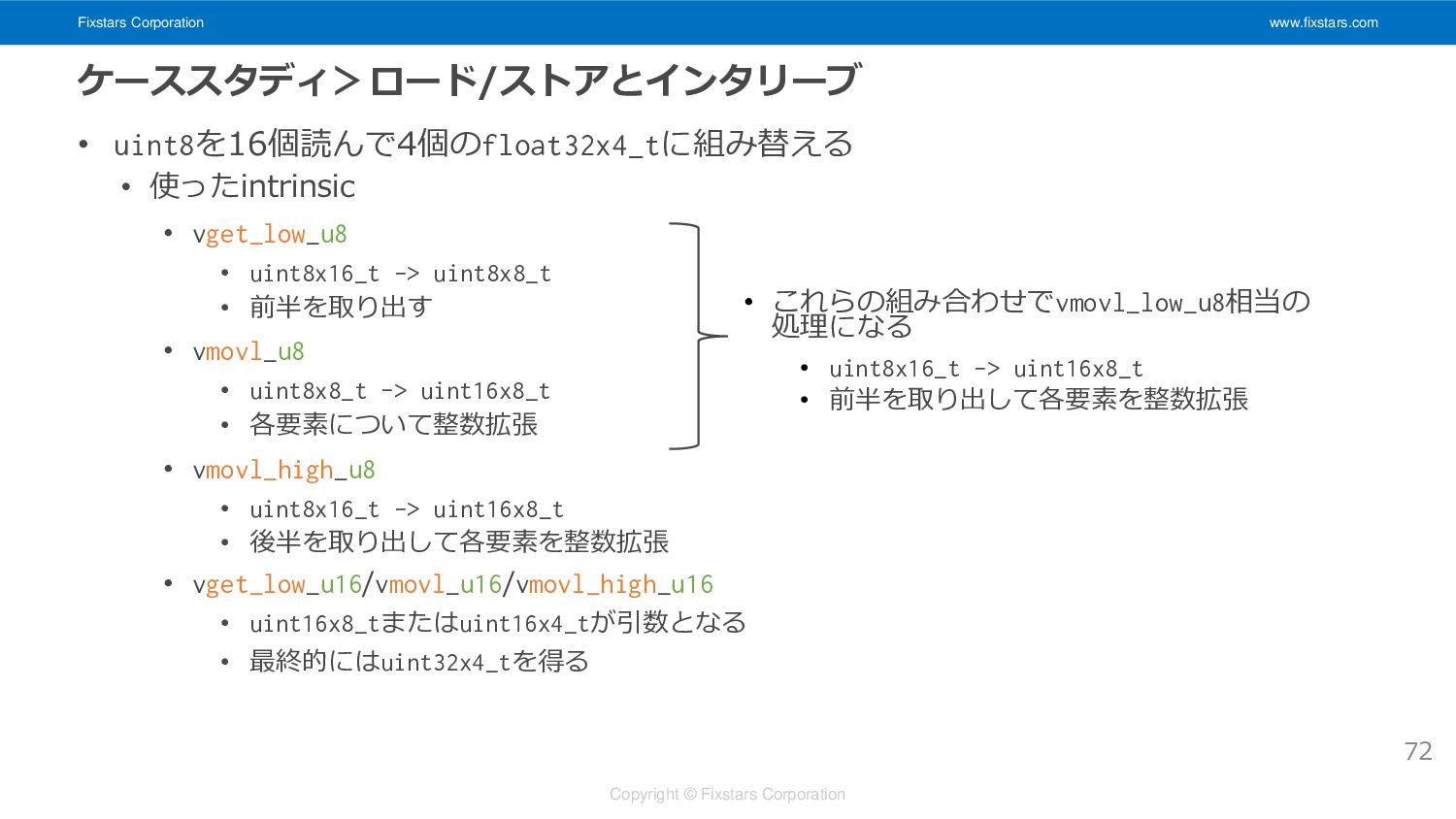
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • uint8を16個読んで4個のfloat32x4_tに組み替える
70 //(略) for(; x < simd_end; x += 16){ float32x4x3_t vts[4]; for(std::size_t z = 0; z < 4; ++z) for(std::size_t c = 0; c < 3; ++c) vts[z].val[c] = vdupq_n_f32(0.f); for(std::size_t i = 0; i < kernel_size; ++i){ const uint8x16x3_t s = vld3q_u8(src[y-half_kernel_size+i][x]); float32x4x3_t vss[6]; //6 = 1+4+1 for(std::size_t c = 0; c < 3; ++c){ vss[0].val[c] = vdupq_n_f32(src[y-half_kernel_size+i][x-half_kernel_size][c]); vss[1].val[c] = vcvtq_f32_u32(vmovl_u16(vget_low_u16(vmovl_u8(vget_low_u8(s.val[c]))))); vss[2].val[c] = vcvtq_f32_u32(vmovl_high_u16( vmovl_u8(vget_low_u8(s.val[c])))); vss[3].val[c] = vcvtq_f32_u32(vmovl_u16(vget_low_u16(vmovl_high_u8( s.val[c])))); vss[4].val[c] = vcvtq_f32_u32(vmovl_high_u16( vmovl_high_u8( s.val[c]))); vss[5].val[c] = vdupq_n_f32(src[y-half_kernel_size+i][x+16][c]); } //続く
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • uint8を16個読んで4個のfloat32x4_tに組み替える
• 使ったintrinsic • vld3q_u8 • const uint8_t* -> uint8x16x3_t • 16ピクセル分データを取ってきてデインタリーブして Rのuint8x16_t, Gのuint8x16_t, Bのuint8x16_tの3本にする • vcvtq_f32_u32 • uint32x4_t -> float32x4_t • u32からf32へのキャスト(128bit) 71
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • uint8を16個読んで4個のfloat32x4_tに組み替える
• 使ったintrinsic • vget_low_u8 • uint8x16_t -> uint8x8_t • 前半を取り出す • vmovl_u8 • uint8x8_t -> uint16x8_t • 各要素について整数拡張 • vmovl_high_u8 • uint8x16_t -> uint16x8_t • 後半を取り出して各要素を整数拡張 • vget_low_u16/vmovl_u16/vmovl_high_u16 • uint16x8_tまたはuint16x4_tが引数となる • 最終的にはuint32x4_tを得る 72 • これらの組み合わせでvmovl_low_u8相当の 処理になる • uint8x16_t -> uint16x8_t • 前半を取り出して各要素を整数拡張
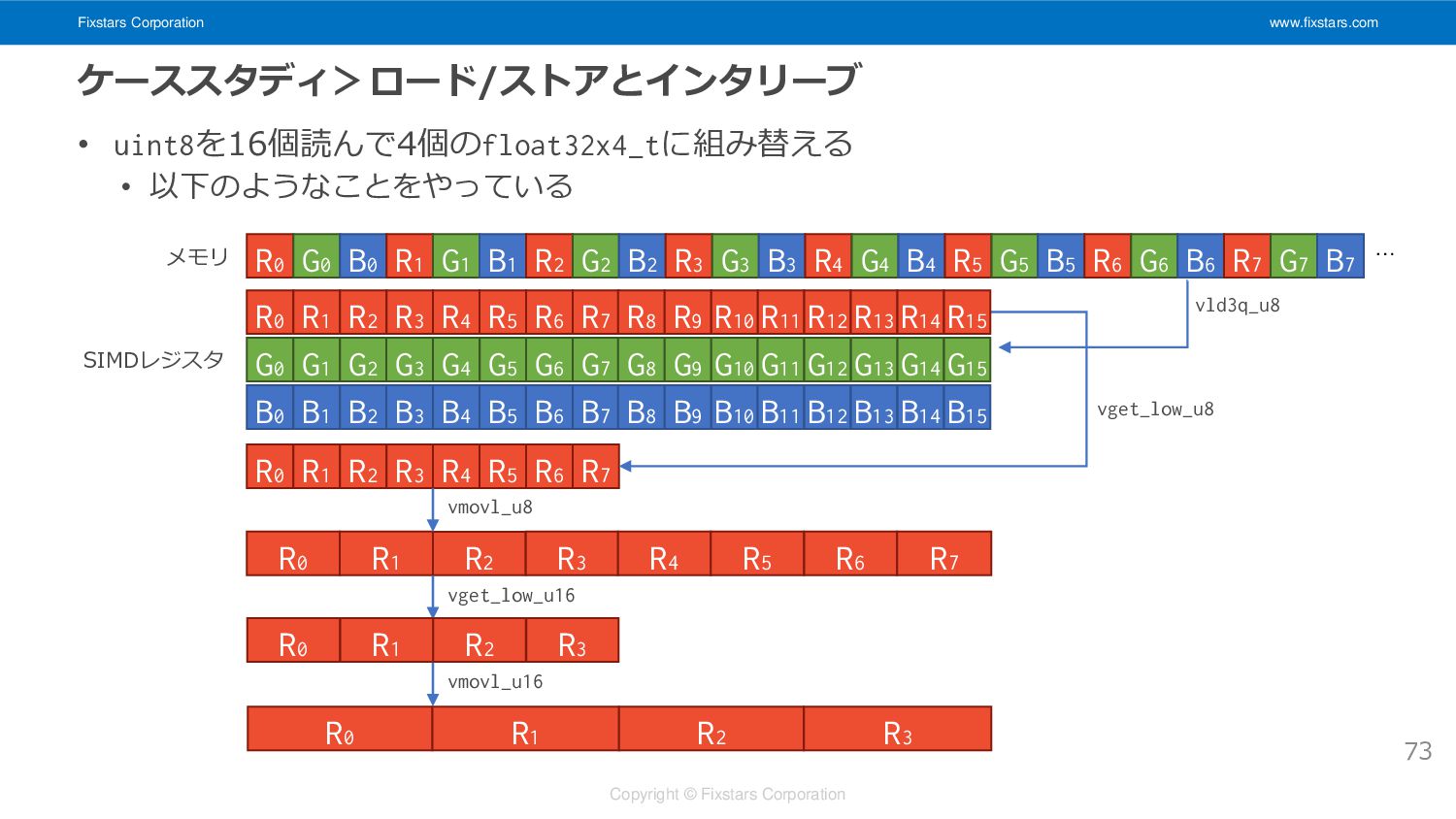
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • uint8を16個読んで4個のfloat32x4_tに組み替える
• 以下のようなことをやっている 73 R0 G0 B0 R1 G1 B1 R2 G2 B2 R3 G3 B3 R4 G4 B4 R5 G5 B5 R6 G6 B6 R7 G7 B7 R0 R1 R2 R3 R4 R5 R6 R7 G0 G1 G2 G3 G4 G5 G6 G7 B0 B1 B2 B3 B4 B5 B6 B7 vld3q_u8 メモリ SIMDレジスタ R0 R1 R2 R3 R4 R5 R6 R7 vget_low_u8 … R8 R9 R10 R11 R12 R13 R14 R15 G8 G9 G10 G11 G12 G13 G14 G15 B8 B9 B10 B11 B12 B13 B14 B15 R0 R1 R2 R3 R4 R5 R6 R7 vmovl_u8 vget_low_u16 R0 R1 R2 R3 R0 R1 R2 R3 vmovl_u16
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 4回計算する
• 計算のたびに読み込むベクトルを変える 74 //続き for(std::size_t j = 0; j < kernel_size; ++j) for(std::size_t z = 0; z < 4; ++z){ float32x4x3_t vs; const float32x4_t kern = vdupq_n_f32(kernel[i][j]); for(std::size_t c = 0; c < 3; ++c){ switch(j){ case 0: vs.val[c] = vextq_f32(vss[z].val[c], vss[z+1].val[c], 3); break; case 1: vs.val[c] = vss[z+1].val[c]; break; case 2: vs.val[c] = vextq_f32(vss[z+1].val[c], vss[z+2].val[c], 1); break; } } for(std::size_t c = 0; c < 3; ++c) vts[z].val[c] = vfmaq_f32(vts[z].val[c], vs.val[c], kern); } //zループ・jループの終わり } //iループの終わり //続く
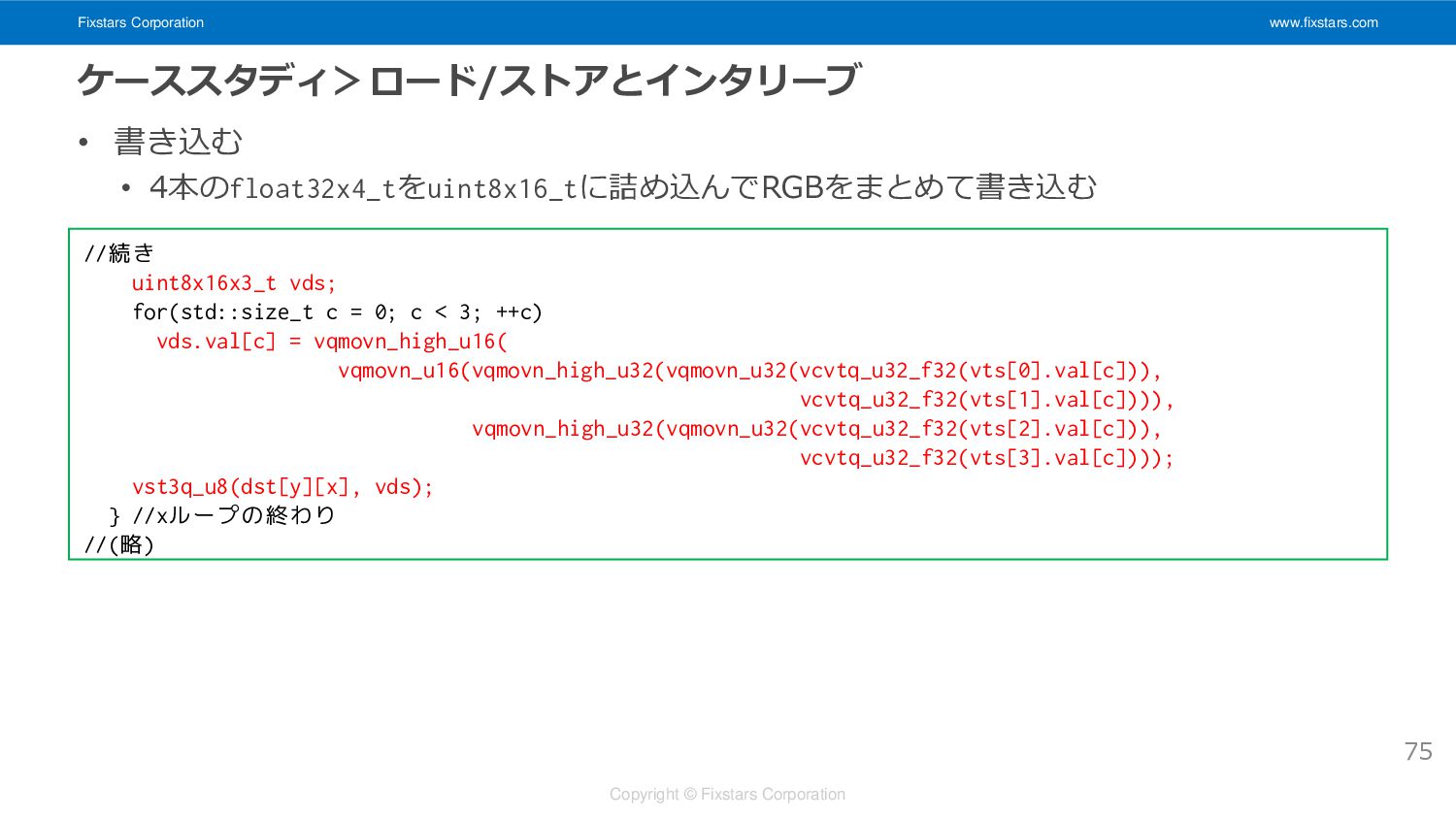
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 書き込む
• 4本のfloat32x4_tをuint8x16_tに詰め込んでRGBをまとめて書き込む 75 //続き uint8x16x3_t vds; for(std::size_t c = 0; c < 3; ++c) vds.val[c] = vqmovn_high_u16( vqmovn_u16(vqmovn_high_u32(vqmovn_u32(vcvtq_u32_f32(vts[0].val[c])), vcvtq_u32_f32(vts[1].val[c]))), vqmovn_high_u32(vqmovn_u32(vcvtq_u32_f32(vts[2].val[c])), vcvtq_u32_f32(vts[3].val[c]))); vst3q_u8(dst[y][x], vds); } //xループの終わり //(略)
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 書き込む
• 使ったintrinsic • vcvtq_u32_f32 • float32x4_t -> uint32x4_t • 型変換 • vqmovn_u32 • uint32x4_t -> uint16x4_t • movnはmovlとは逆にbit幅を狭める • qmovnはオーバーフロー時に最大値でクランプする • uintは最小値は全部0なので気にしなくて良い • vqmovn_high_u32 • (uint16x4_t, uint32x4_t) -> uint16x8_t • 第2引数のuint32x4_tをqmovnしてから第1引数とつなげてuint16x8_tにする • vqmovn_u16/vqmovn_high_u16 • uint16x8_tやuint8x8_tを受け取る 76
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 書き込む
• 以下のようなことをやっている 77 R0 R1 R2 R3 R4 R5 R6 R7 SIMDレジスタ R8 R9 R10 R11 R12 R13 R14 R15 R0 R1 R2 R3 R4 R5 R6 R7 vqmovn_high_u32 vqmovn_u16 R0 R1 R2 R3 R0 R1 R2 R3 vqmovn_u32 R4 R5 R6 R7 R8 R9 R10 R11 R12 R13 R14 R15 R0 R1 R2 R3 R4 R5 R6 R7 vqmovn_high_u16
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • 書き込む
• 使ったintrinsic • vst3q_u8 • (uint8_t*, uint8x16x3_t) -> void • Rのuint8x16_t, Gのuint8x16_t, Bのuint8x16_tの3本をインタリーブして書き込む 78 R0 G0 B0 R1 G1 B1 R2 G2 B2 R3 G3 B3 R4 G4 B4 R5 G5 B5 R6 G6 B6 R7 G7 B7 R0 R1 R2 R3 R4 R5 R6 R7 G0 G1 G2 G3 G4 G5 G6 G7 B0 B1 B2 B3 B4 B5 B6 B7 vst3q_u8 メモリ SIMDレジスタ … R8 R9 R10 R11 R12 R13 R14 R15 G8 G9 G10 G11 G12 G13 G14 G15 B8 B9 B10 B11 B12 B13 B14 B15
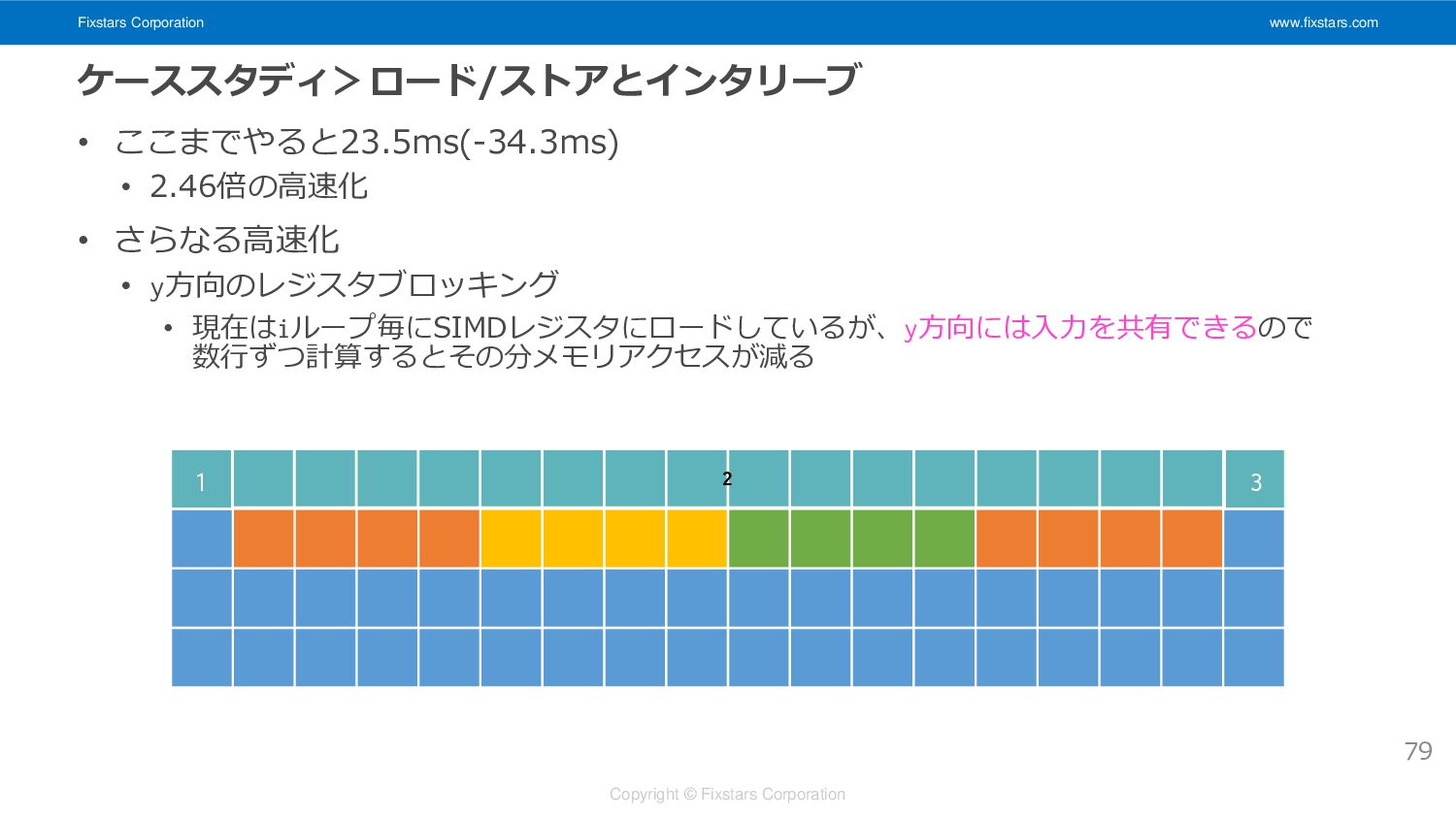
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • ここまでやると23.5ms(-34.3ms)
• 2.46倍の高速化 • さらなる高速化 • y方向のレジスタブロッキング • 現在はiループ毎にSIMDレジスタにロードしているが、y方向には入力を共有できるので 数行ずつ計算するとその分メモリアクセスが減る 79 1 3 2
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • ここまでやると23.5ms(-34.3ms)
• 2.46倍の高速化 • さらなる高速化 • y方向のレジスタブロッキング • 現在はiループ毎にSIMDレジスタにロードしているが、y方向には入力を共有できるので 数行ずつ計算するとその分メモリアクセスが減る 80 4 6 5
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • ここまでやると23.5ms(-34.3ms)
• 2.46倍の高速化 • さらなる高速化 • y方向のレジスタブロッキング • 現在はiループ毎にSIMDレジスタにロードしているが、y方向には入力を共有できるので 数行ずつ計算するとその分メモリアクセスが減る 81 7 9 8
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • ここまでやると23.5ms(-34.3ms)
• 2.46倍の高速化 • さらなる高速化 • y方向のレジスタブロッキング • 現在はiループ毎にSIMDレジスタにロードしているが、y方向には入力を共有できるので 数行ずつ計算するとその分メモリアクセスが減る 82 10 12 11
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • ここまでやると23.5ms(-34.3ms)
• 2.46倍の高速化 • さらなる高速化 • y方向のレジスタブロッキング • 現在はiループ毎にSIMDレジスタにロードしているが、y方向には入力を共有できるので 数行ずつ計算するとその分メモリアクセスが減る 83 13 15 14
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • ここまでやると23.5ms(-34.3ms)
• 2.46倍の高速化 • さらなる高速化 • y方向のレジスタブロッキング • 現在はiループ毎にSIMDレジスタにロードしているが、y方向には入力を共有できるので 数行ずつ計算するとその分メモリアクセスが減る 84
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • ここまでやると23.5ms(-34.3ms)
• 2.46倍の高速化 • さらなる高速化 • y方向のレジスタブロッキング • 現在はiループ毎にSIMDレジスタにロードしているが、y方向には入力を共有できるので 数行ずつ計算するとその分メモリアクセスが減る • 両端のメモリアクセスのキャッシング • 現在はvss[0]やvss[5]の算出に1要素のメモリアクセスとvdupq_n_f32を使っているが、 これらは「前のvss[4]」や「次のvss[1]」としてSIMDレジスタ上に置いておけるので 読みに行かなくて済む • 実際には上記のようなことをするにはSIMDレジスタが足りない • 先述のようにARMv8のNEONにはSIMDレジスタが32本しかない • 常にRGBの3本を扱うので各チャネルあたり10本程度しか使えない • 現状で結構ギリギリ 85
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation ケーススタディ>ロード/ストアとインタリーブ • その他の高速化:
y方向のマルチスレッド化 • 先述のように畳み込みは各ピクセルの各チャネル毎の依存がない • yループに対してもマルチスレッド化が容易に可能 • 「NEONの基礎」の範囲外なので今回は省略 86
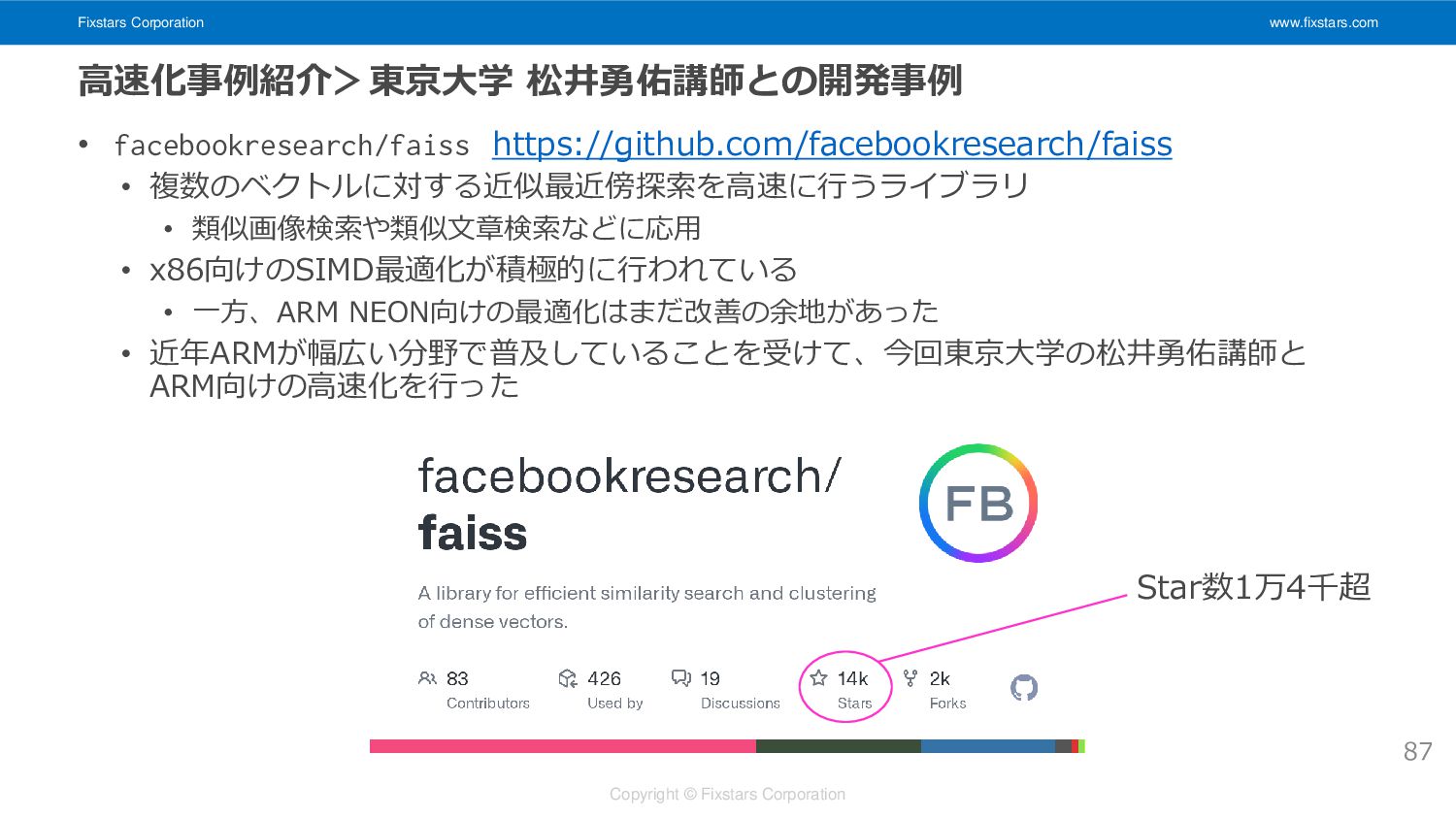
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 高速化事例紹介>東京大学 松井勇佑講師との開発事例 •
facebookresearch/faiss https://github.com/facebookresearch/faiss • 複数のベクトルに対する近似最近傍探索を高速に行うライブラリ • 類似画像検索や類似文章検索などに応用 • x86向けのSIMD最適化が積極的に行われている • 一方、ARM NEON向けの最適化はまだ改善の余地があった • 近年ARMが幅広い分野で普及していることを受けて、今回東京大学の松井勇佑講師と ARM向けの高速化を行った 87 Star数1万4千超
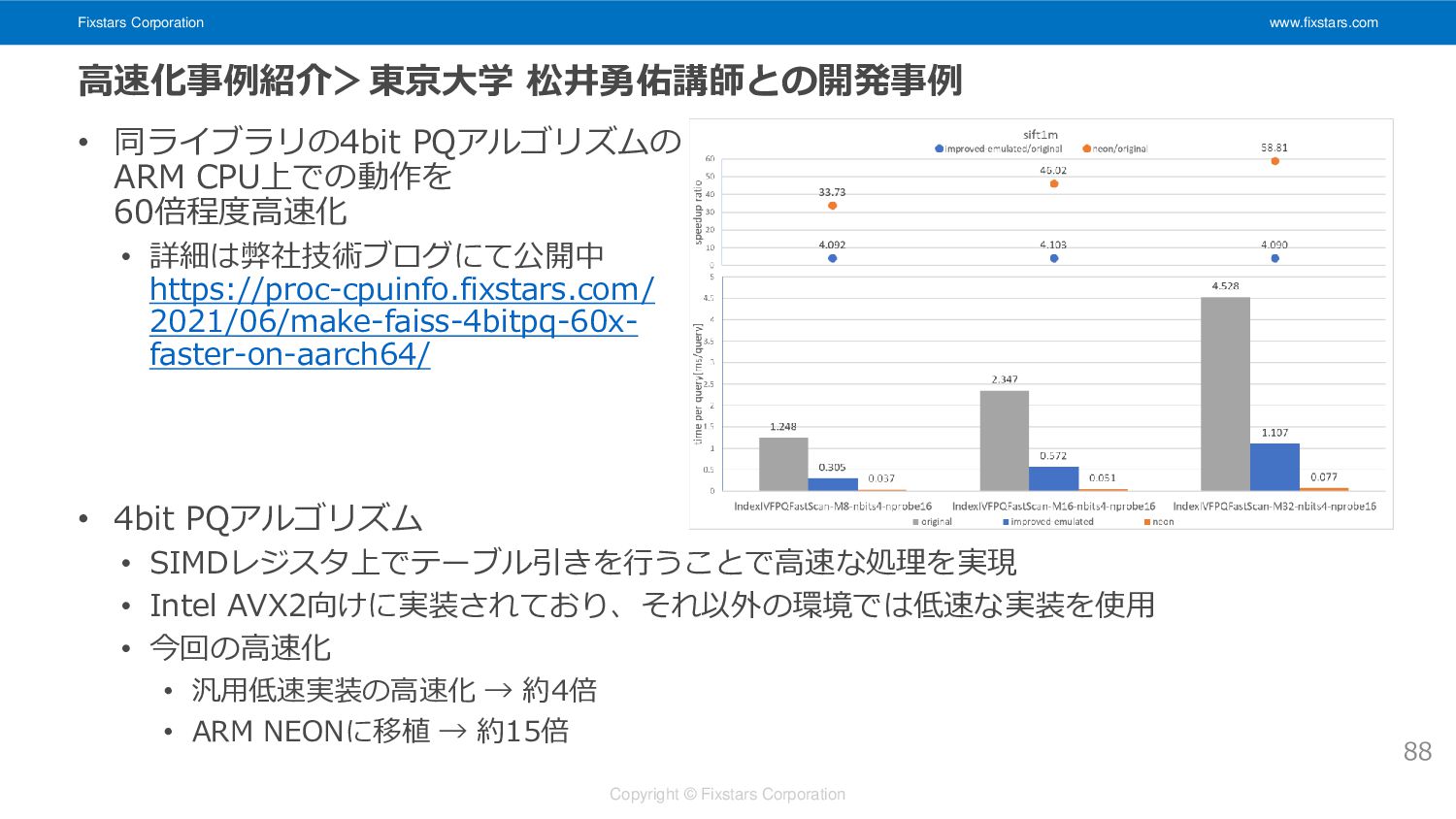
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation 高速化事例紹介>東京大学 松井勇佑講師との開発事例 •
同ライブラリの4bit PQアルゴリズムの ARM CPU上での動作を 60倍程度高速化 • 詳細は弊社技術ブログにて公開中 https://proc-cpuinfo.fixstars.com/ 2021/06/make-faiss-4bitpq-60x- faster-on-aarch64/ • 4bit PQアルゴリズム • SIMDレジスタ上でテーブル引きを行うことで高速な処理を実現 • Intel AVX2向けに実装されており、それ以外の環境では低速な実装を使用 • 今回の高速化 • 汎用低速実装の高速化 → 約4倍 • ARM NEONに移植 → 約15倍 88
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation まとめ • ARMのSIMD命令についての基礎を扱った
• ARMv8以降でも慣習的にNEONと呼ばれ(続け)ている • 64bit/128bit SIMD • デインタリーブロード/インタリーブストアが可能 • 画像処理に便利 • intrinsicを使った書き方を紹介した • 型がしっかりしていて読み書きしやすい • ケーススタディとして3チャンネル・カーネルサイズ3x3の畳み込み処理の高速化の流れを 追った • 2.5倍程度高速化できた • 高速化事例としてfaissの4bit PQアルゴリズムの高速化事例を紹介した • NEONによる高速化によって15倍程度、全体で60倍程度の高速化を行った 89
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation Q&A time
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Copyright © Fixstars
Corporation 告知
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation フィックスターズでは仲間を募集しています! さまざまな専門性を持つエンジニアを募集しています 詳細は
https://www.fixstars.com/ja/recruit/ まで 92
Fixstars Corporation www.fixstars.com Copyright © Fixstars Corporation Thank You お問い合わせ窓口
:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}