Concluding Remarks References References I Bayer, C., H. Hoel, E. von Schwerin, and R. Tempone. 2014. On nonasymptotic optimal stopping criteria in Monte Carlo Simulations, SIAM J. Sci. Comput. 36, A869–A885. Bratley, P., B. L. Fox, and H. Niederreiter. 1992. Implementation and tests of low-discrepancy sequences, ACM Trans. Model. Comput. Simul. 2, 195–213. Choi, S.-C. T., Y. Ding, F. J. H., L. Jiang, Ll. A. Jiménez Rugama, D. Li, J. Rathinavel, X. Tong, K. Zhang, Y. Zhang, and X. Zhou. 2013–2017. GAIL: Guaranteed Automatic Integration Library (versions 1.0–2.2). Genz, A. 1993. Comparison of methods for the computation of multivariate normal probabilities, Computing Science and Statistics 25, 400–405. Giles, M. 2015. Multilevel Monte Carlo methods, Acta Numer. 24, 259–328. H., F. J. 2017+. The trio identity for quasi-Monte Carlo error analysis, Monte Carlo and quasi-Monte Carlo methods: MCQMC, Stanford, usa, August 2016. submitted for publication, arXiv:1702.01487. H., F. J., S.-C. T. Choi, L. Jiang, and Ll. A. Jiménez Rugama. 2017+. Monte Carlo simulation, automatic stopping criteria for, Wiley statsref-statistics reference online. to appear. H., F. J., L. Jiang, Y. Liu, and A. B. Owen. 2013. Guaranteed conservative fixed width confidence intervals via Monte Carlo sampling, Monte Carlo and quasi-Monte Carlo methods 2012, pp. 105–128. 20/21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
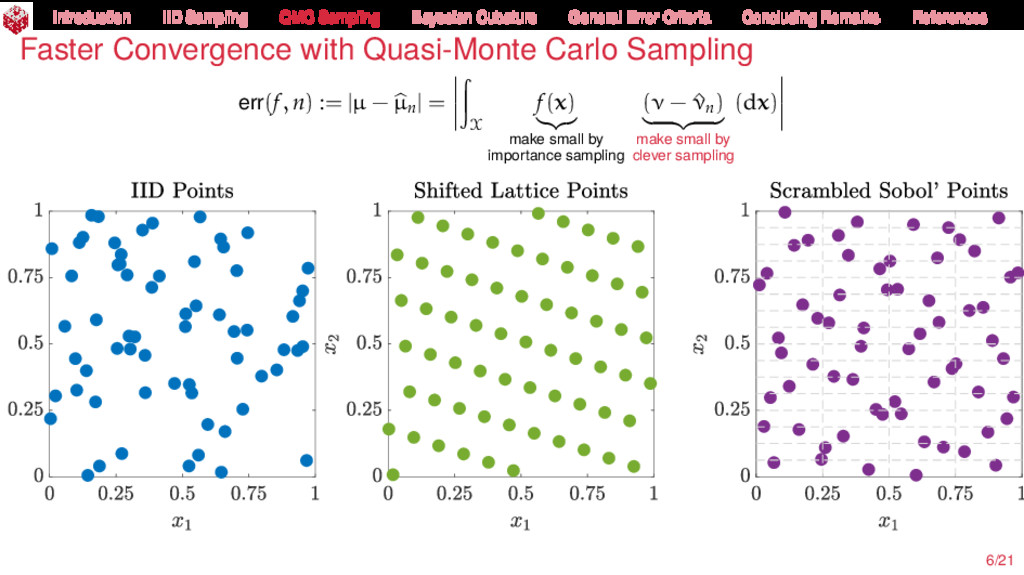{kind=link}
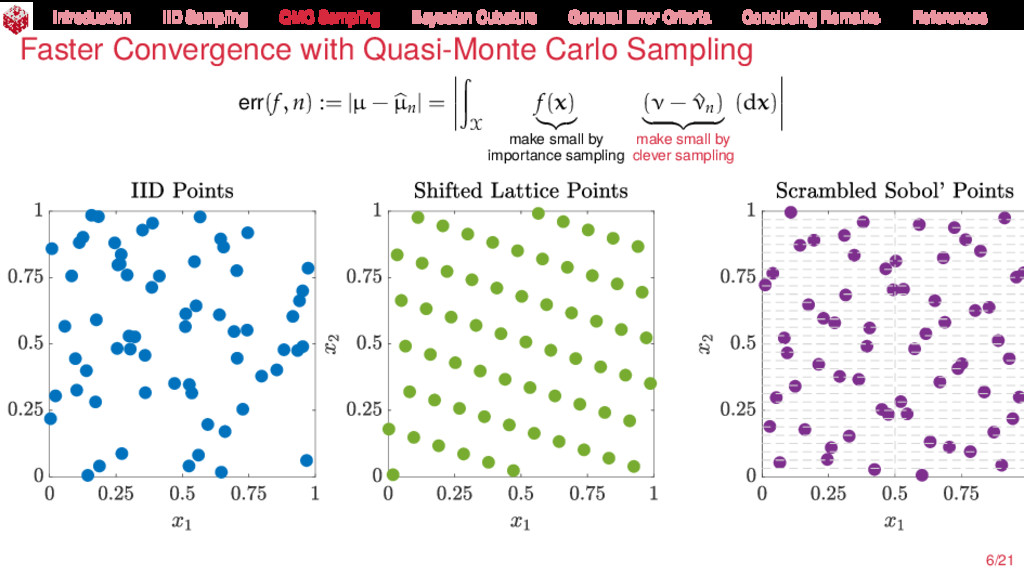{kind=link}
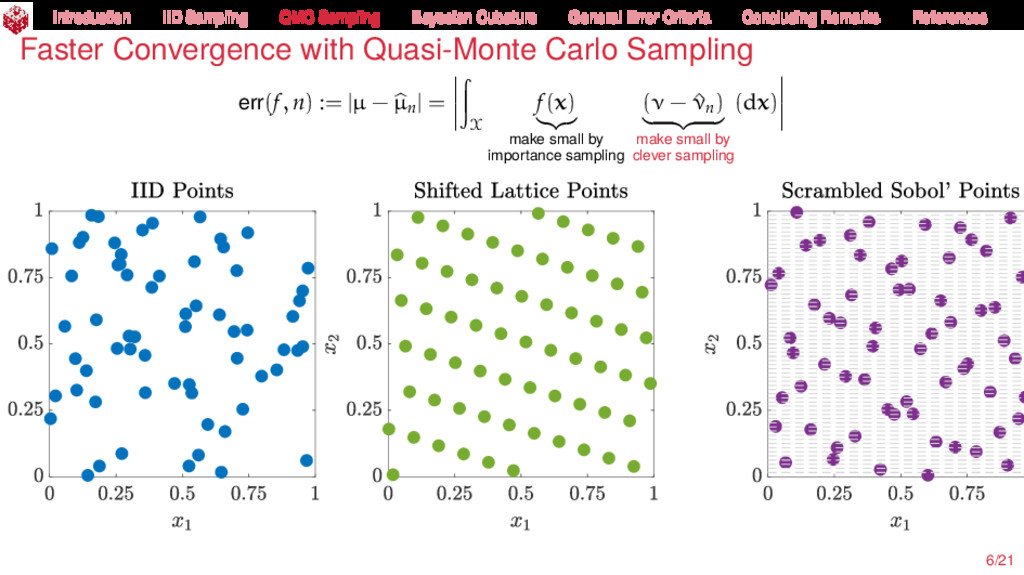{kind=link}
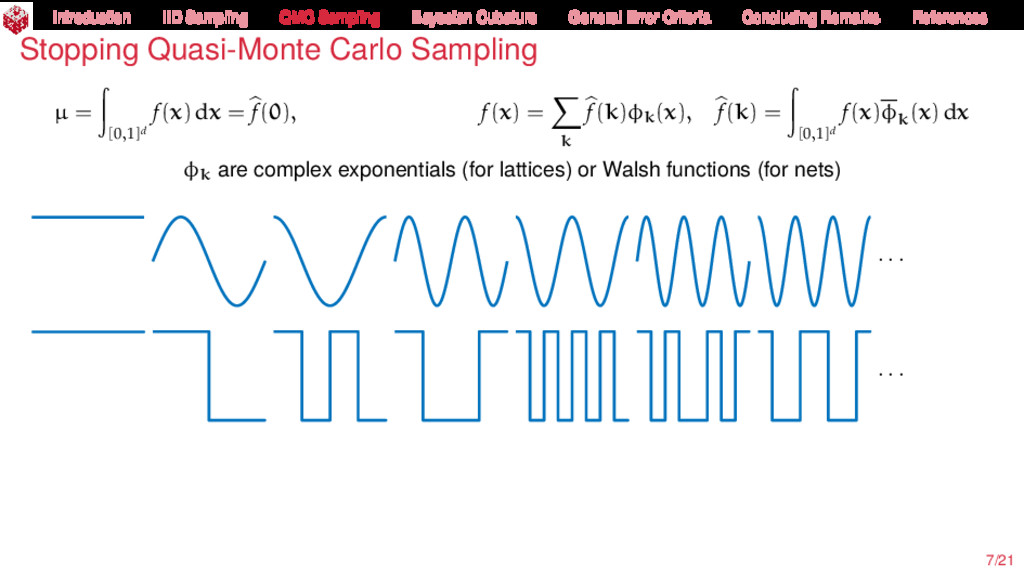{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}