Reliable adaptive cubature using digital sequences, Monte Carlo and Quasi-Monte Carlo Methods: MCQMC, Leuven, Belgium, April 2014 (R. Cools and D. Nuyens, eds.), Springer Proceedings in Mathematics and Statistics, vol. 163, Springer-Verlag, Berlin, 2016, pp. 367–383. [HKS25] F. J. Hickernell, N. Kirk, and A. G. Sorokin, Quasi-Monte Carlo methods: What, why, and how?, submitted to MCQMC 2024 proceedings, https://doi.org/10.48550/arXiv.2502.03644, 2025+. [JH19] R. Jagadeeswaran and F. J. Hickernell, Fast automatic Bayesian cubature using lattice sampling, Stat. Comput. 29 (2019), 1215–1229. [JH22] R. Jagadeeswaran and F. J. Hickernell, Fast automatic Bayesian cubature using Sobol' sampling, Advances in Modeling and Simulation: Festschrift in Honour of Pierre L'Ecuyer (Z. Botev, A. Keller, C. Lemieux, and B. Tu ff i n, eds.), Springer, Cham, 2022, pp. 301–318. [JH16] Ll. A. Jiménez Rugama and F. J. Hickernell, Adaptive multidimensional integration based on rank-1 lattices, Monte Carlo and Quasi-Monte Carlo Methods: MCQMC, Leuven, Belgium, April 2014 (R. Cools and D. Nuyens, eds.), Springer Proceedings in Mathematics and Statistics, vol. 163, Springer-Verlag, Berlin, 2016, pp. 407–422.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
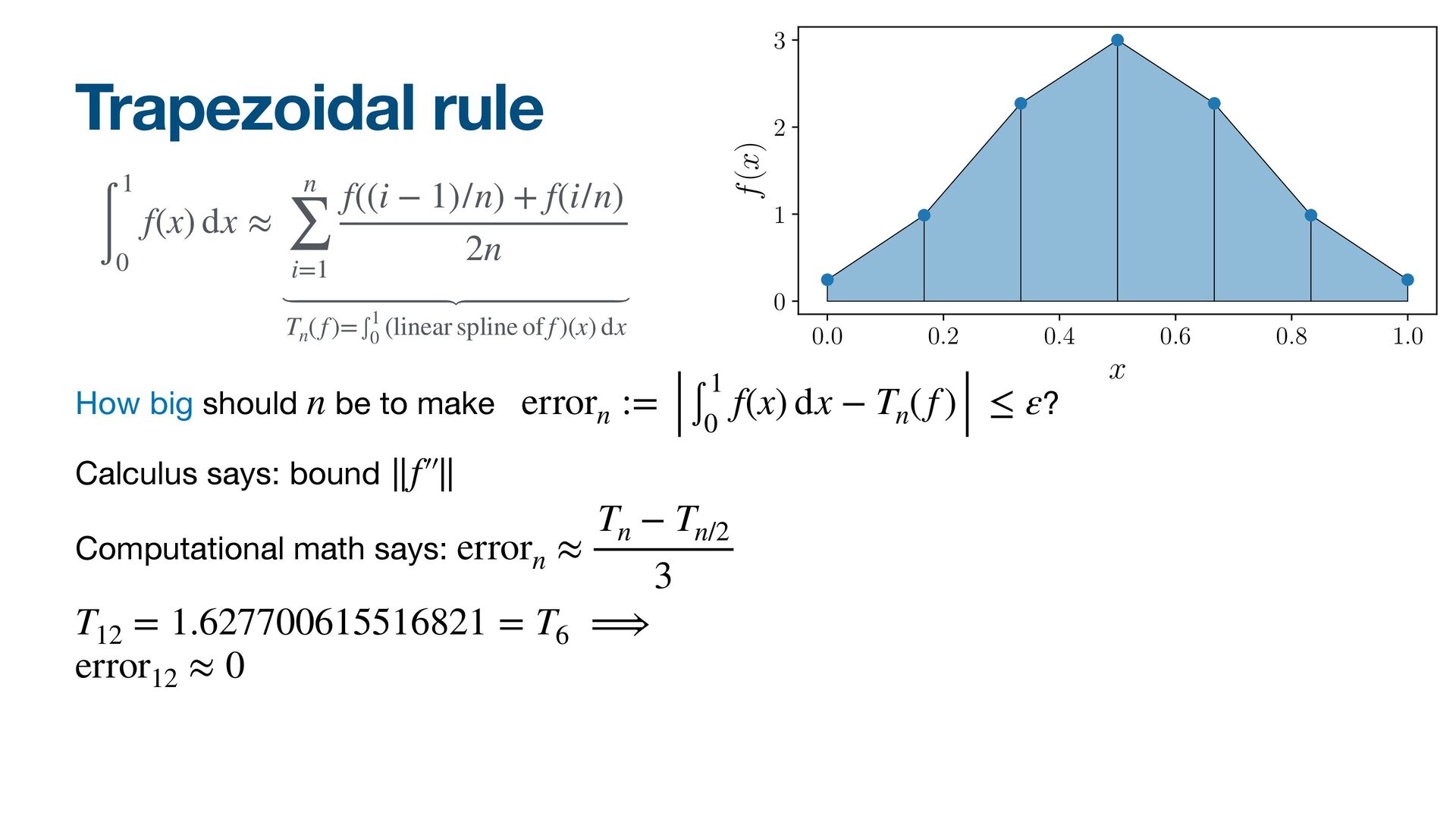{kind=link}
{kind=link}
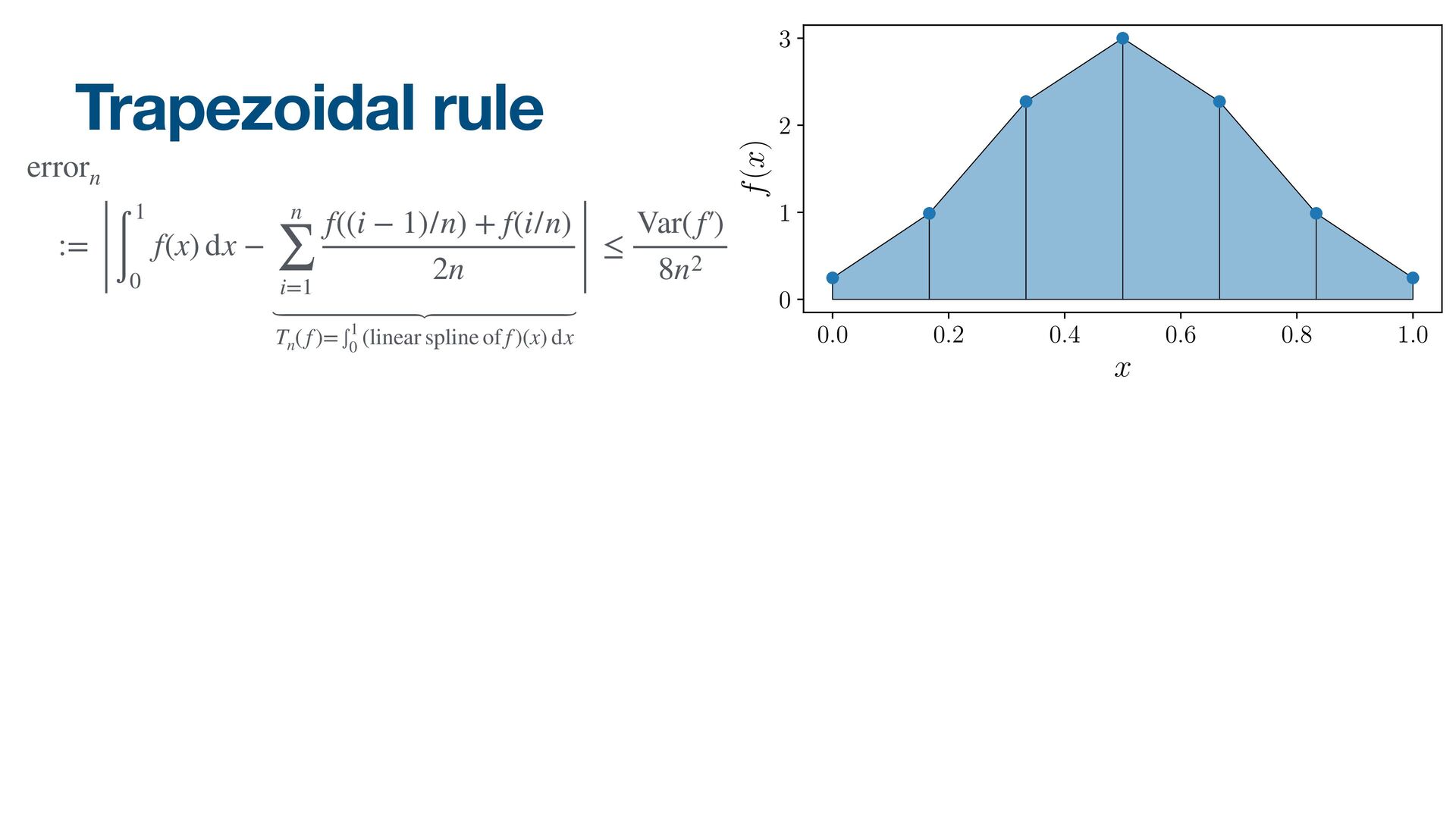{kind=link}
{kind=link}
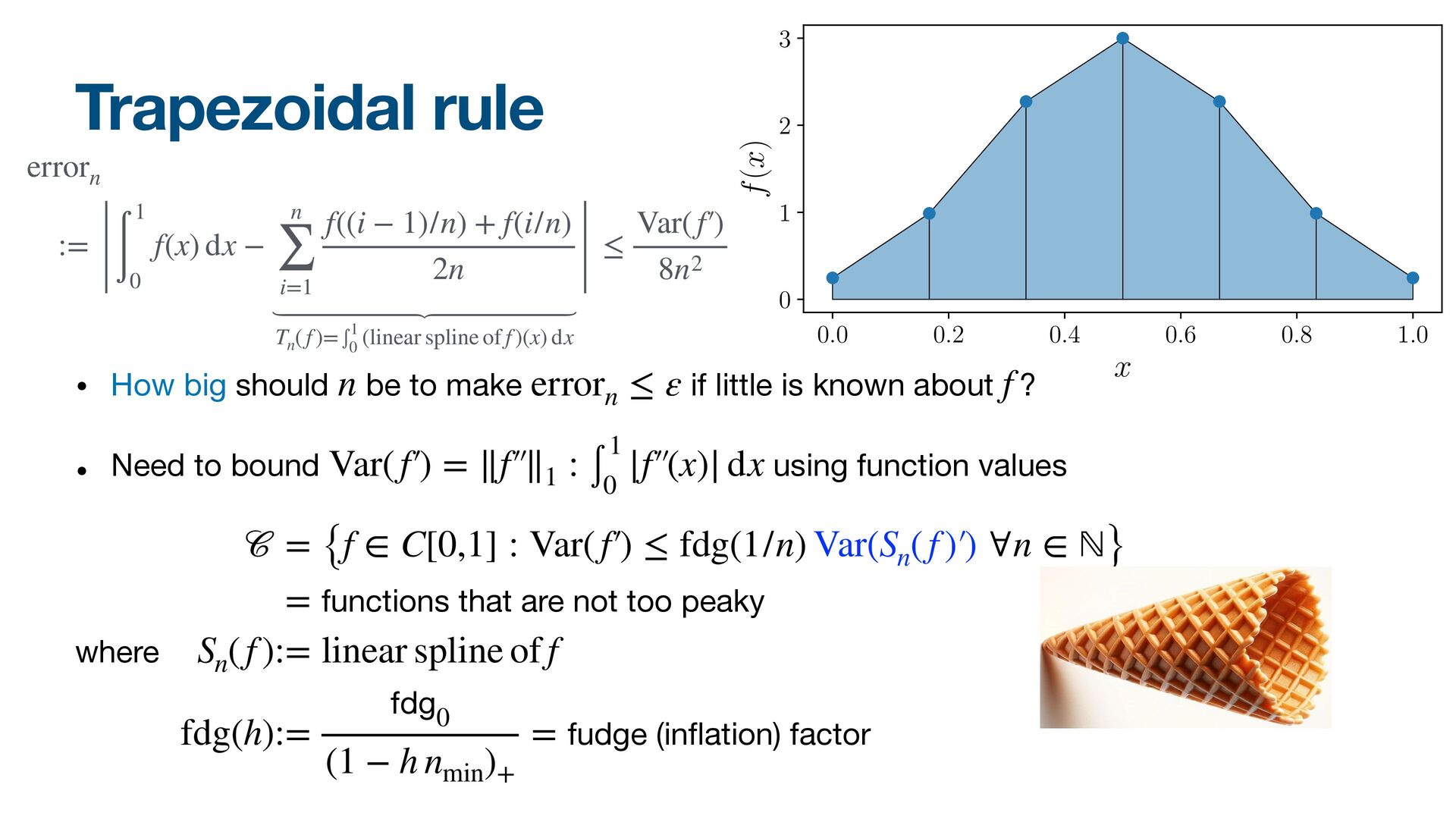{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![𝒞 := {f ∈ C[0,1] : Var(f′  , [β,](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
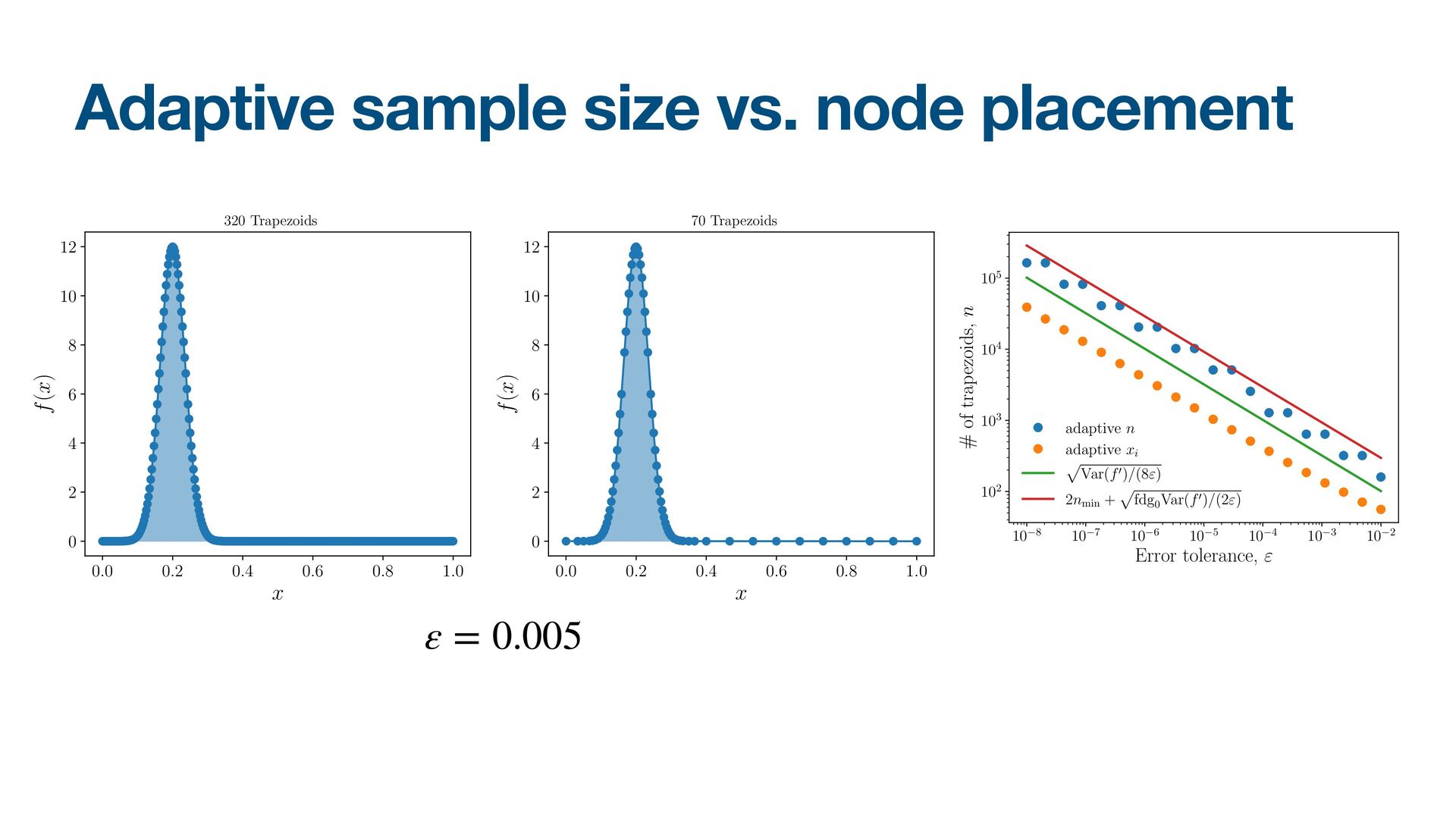{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
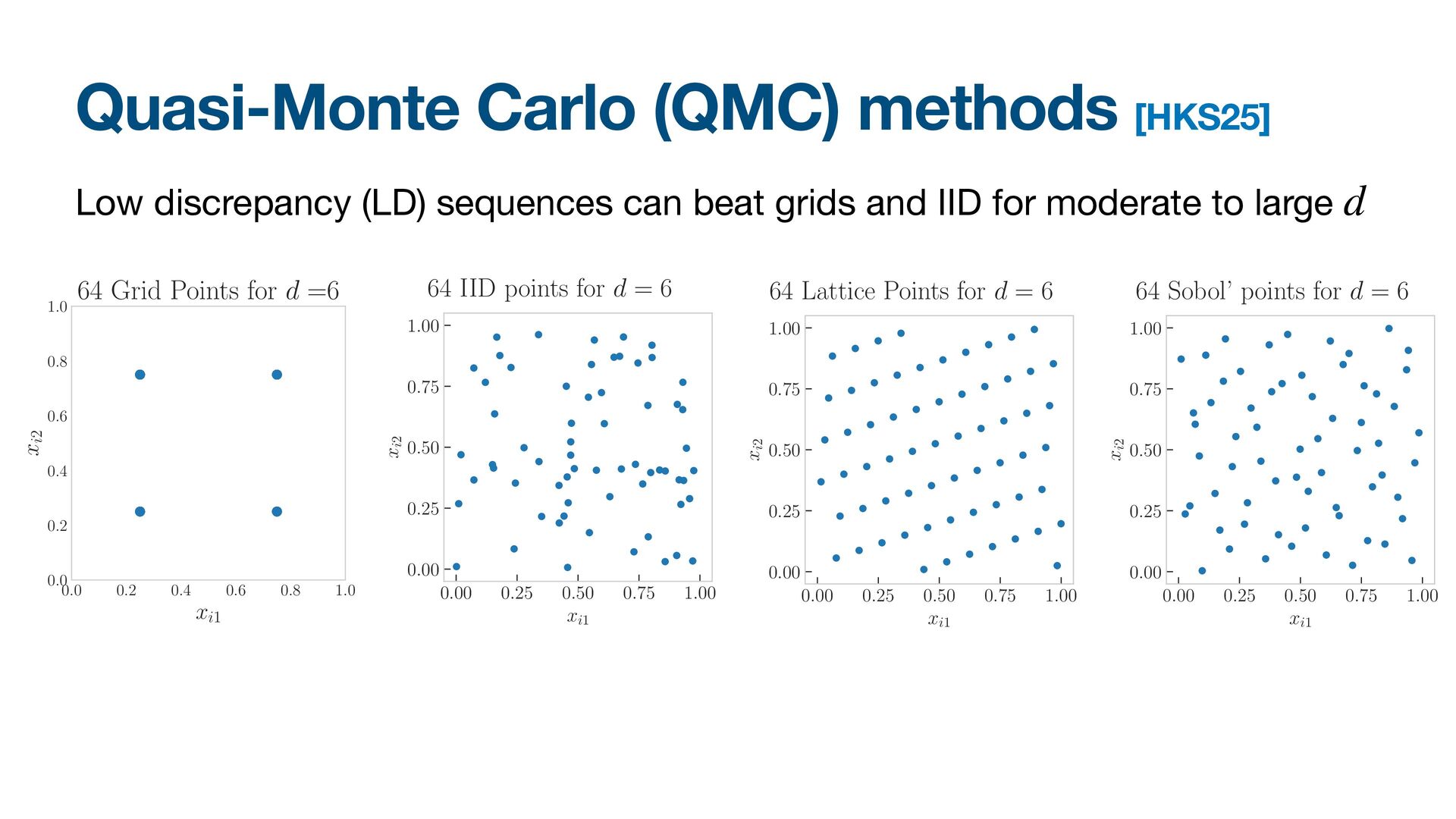{kind=link}
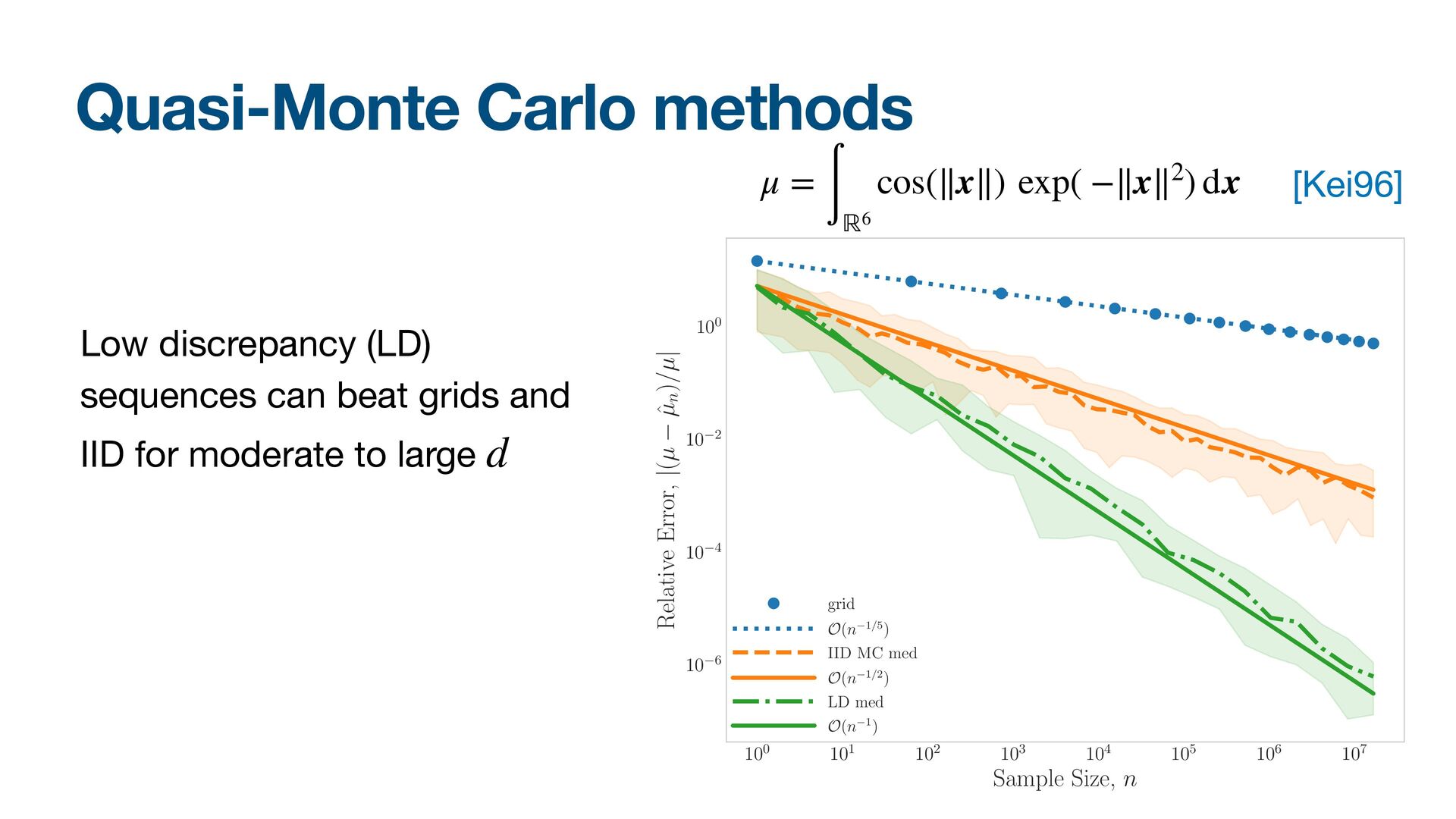{kind=link}
![Discrepancy measures the quality of [H00] x0 , x1 ,](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_45.jpg){kind=link}
![Discrepancy measures the quality of [H00] x0 , x1 ,](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_46.jpg){kind=link}
![Discrepancy measures the quality of [H00] x0 , x1 ,](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_47.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_48.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_49.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_50.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_51.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_52.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_53.jpg){kind=link}
![Deterministic stopping rules for QMC [HJ16, JH16, SJ24] μ :=](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_54.jpg){kind=link}
![Bayesian stopping rules for QMC [JH19, JH22] μ := expectation](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_55.jpg){kind=link}
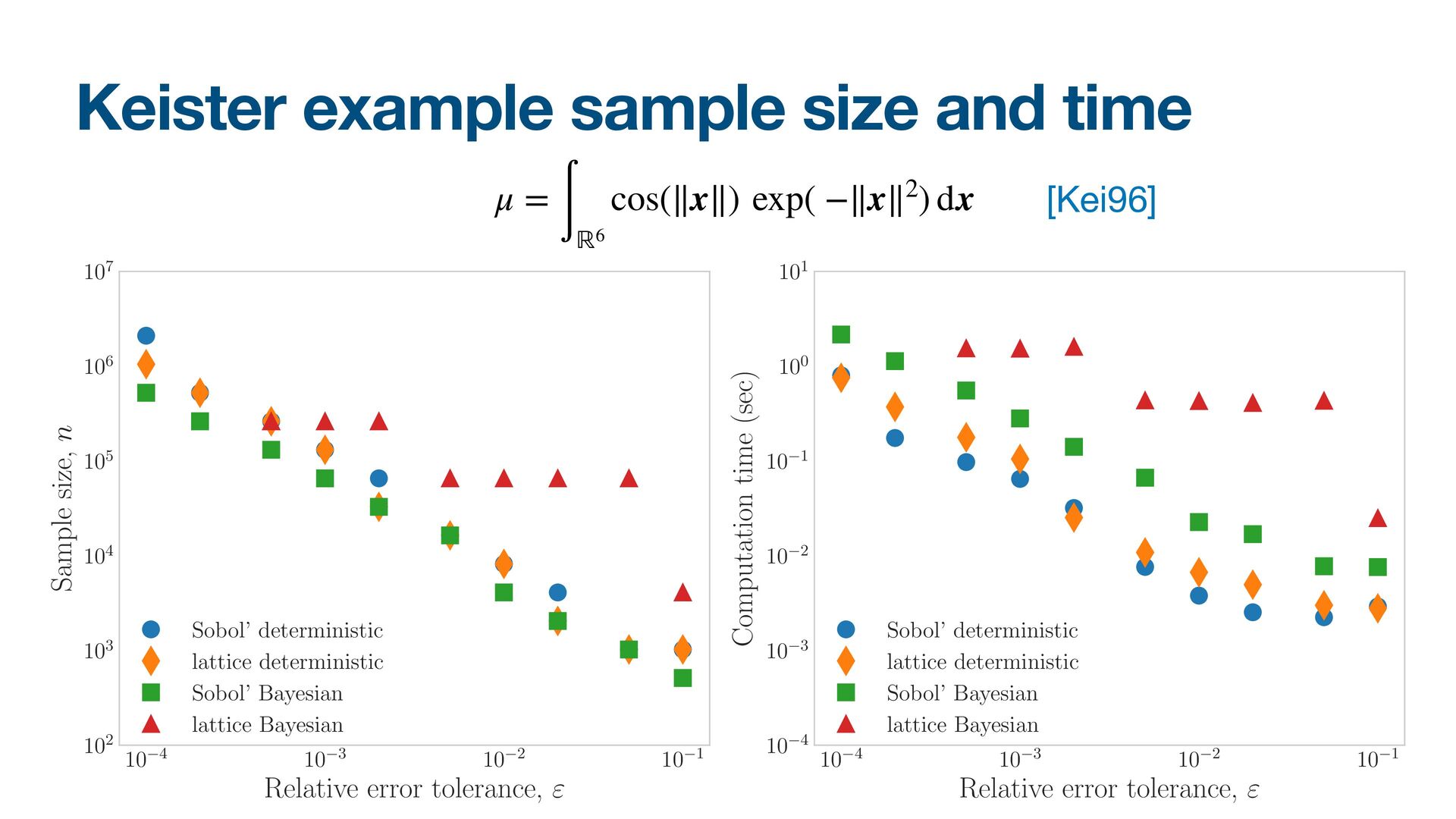{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [Bak70] N. S. Bakhvalov, On the optimality of linear](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_63.jpg){kind=link}
![References [HJ16] F. J. Hickernell and Ll. A. Jiménez Rugama,](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_64.jpg){kind=link}
![References [Kei96] B. D. Keister, Multidimensional quadrature algorithms, Computers in](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_65.jpg){kind=link}
![Multilevel methods reduce computational cost [Gil15] μ := expectation 𝔼](https://files.speakerdeck.com/presentations/7c399f480e7e4745b75cdd12889e8705/slide_66.jpg){kind=link}