Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
俺のNETFLIX season2 AmazonPersonalize
Search
h-fkn
July 02, 2020
Technology
580
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
俺のNETFLIX season2 AmazonPersonalize
【オンライン】ゆるふわマシンラーニング vol.4 - connpass
https://enebular.connpass.com/event/178062/
h-fkn
July 02, 2020
More Decks by h-fkn
See All by h-fkn
The advantages and disadvantages of using machine learning with enebular
fkn0839
0
300
ラズパイで写真を撮った話_IoTLT_vol.66_2200812.pdf
fkn0839
0
440
俺のNETFLIX season1
fkn0839
0
300
ゆるふわマシーンラーニング#2_内容調整中()
fkn0839
0
340
ゆるふわマシーンラーニング「❝ Google AutoML Tablesでお手軽AI ❞ と題して話すつもりだったけど、実際に使ったら お手軽()だった件について5分以内で話す」
fkn0839
1
4.2k
データ分析プロセス/AIアプリケーションの基本設計
fkn0839
0
220
DataScienceBOOTCAMP5th_part1
fkn0839
0
2k
G'SACADEMY LAB5th DataScience
fkn0839
0
240
AIアプリ開発に「目的設定」が大切な理由
fkn0839
0
170
Other Decks in Technology
See All in Technology
どうして今サーバーサイドKotlinを選択したのか
nealle
0
190
アラート調査向けAIエージェントの本番導入とその後/AI Agents for Alert Investigation: Production Deployment and After
taddy_919
1
330
NDIAS CTF 2026 問題解説会資料
bata_24
0
170
『AIに負けない』より『AIと遊ぶ』」〜ワクワクが最強のテスト・QA学習戦略_公開用
odan611
1
370
はてなのサービス基盤を支える Kubernetes《足腰》
masayoshimaezawa
0
430
product engineering with qa
nealle
0
140
組織における AI-DLC 実践
askul
0
300
作る力から、見極める力へ — AI時代に広がるエンジニアの価値と役割
rince
0
410
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
190
ゼロをイチにする仕事が終わったあと
smasato
0
270
次世代ランサムウェア対策の考察 / 20260704 Mitsutoshi Matsuo
shift_evolve
PRO
5
1.7k
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
130
Featured
See All Featured
Mind Mapping
helmedeiros
PRO
1
270
ラッコキーワード サービス紹介資料
rakko
1
3.8M
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
How GitHub (no longer) Works
holman
316
150k
KATA
mclloyd
PRO
35
15k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
The Curious Case for Waylosing
cassininazir
1
420
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
160
Transcript
俺の ゆるふわマシーンラーニングとは 昨今、Google AutoMLやAzureML、AWS Sagemakerな ど、クラウド上のMLサービスが一般的になりつつありま す。 そういったクラウドMLサービスをゆるふわに学べる・ 共有できる勉強会です。
俺の 質問はTwitterで受付中! • 質問やコメントはTwitterで! YouTubeではないので注意 • ハッシュタグ は #yurufuwaml
俺の 本日の流れ 19:30〜19:35 オープニング 19:35〜20:50 LT(1名15分程度)* 5名 20:50〜21:00 パネルディスカッション 21:00〜21:10 アンケート&今後のご案内
俺の 発表者一覧 1. 俺のNETFLIX〜今度こそクラウドでレコメンド実装する〜 (hidefさん) 2. Web Speech APIとGoogle Cloud
Speech to Textを比較した話(仮) (masakazu_kawazuさん) 3. ラズパイは俺の嫁!GoogleAutoMLで作る音声アシスタント (ringoさん) 4. 映像を掛け合わせて新しい映像を生み出したい! (notitle420さん) 5. enebular x Teachable Machine x LINE Bot (仮) (がおまるさん)
俺の LT登壇者の皆さまへ • 【REC】に近い場所に移動してLT! • スライドはステージ側に大きく投影! • 上記の準備含めて15分だとちょうどいいかも • 音声ONで他の登壇者のLTにリアクションしてくれ
ると嬉しみが深い
俺の 2020-07-02 Thu ゆるふわマシーンラーニング#4 @hidefkn
俺の 自己紹介 • Twitter @hidefkn • Facebook hidefkn ▼おすすめのネトフリ視聴コンテンツ 『かぐや様は告らせたい』
いまいちって言っちゃったけど、きちんと見始めたら普通にハマった 『梨泰院クラス』もいいけど、『人間レッスン』 韓流ナメてた。ただし長いので、仕事をサボる覚悟が必要() 7
俺の 2020 ?シーズン シーズン1-1を再生 他のエピソード 類似する作品 音声および字幕 マイリストに追加 俺の マッチ度:
96% ゆるふわマシーンラーニングの登壇することになった!しかし、 登壇テーマが決まらない。この機会に、ネットフリックスに使われ ている機械学習の技術をゆるふわに学んでいくが悪戦苦闘! 出演: 深野嗣 ゆるふわな機械学習、ティーン向け、パワポだけ無駄にこだわる 8
俺の ネトフリをつくるという壮大な趣味 • 映画視聴評価のオープンデータを使って レコメンドシステムをつくる • クラウドMLを使う • ゆるく開発する 9
俺の Google Recommendations AI(β)を 使いこなせなくてオワコンした Season1までの『俺のNETFLIX』 10
俺の Googleに別れを告げて、AWSに向き合った話 1. Amazon Personalize とは 2. Amazon Personalize を使ってレコメンドを作ってみた
3. Amazon Personalize で推薦結果を取得してみた Season2のあらすじ 11
ゆるふわマシーンラーニング #4 2020-07-02 Thu 俺の NETFLIXに使われてい る機械学習技術 (再掲)
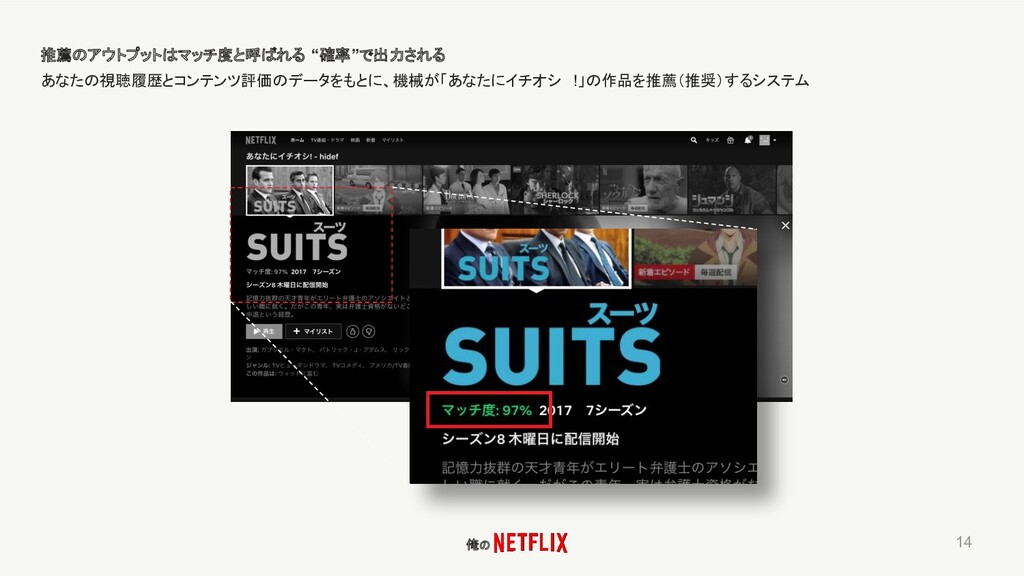
俺の NETFLIXには、推薦システムに機械学習が使われている あなたの視聴履歴とコンテンツ評価のデータをもとに、機械が「あなたにイチオシ !」の作品を推薦(推奨)するシステム 13 推薦システム
俺の 推薦のアウトプットはマッチ度と呼ばれる “確率”で出力される あなたの視聴履歴とコンテンツ評価のデータをもとに、機械が「あなたにイチオシ !」の作品を推薦(推奨)するシステム 14
俺の 推薦システムは一生かけても見きれない映画作品を絞込んでくれる Film Exhibition Yearbook |2018 から抜粋 15 • 年間1,200件の映画作品が公開されている
• 一方、日本人は年間1.4回しか映画を鑑賞しない • もしも、作品を全部鑑賞するのであれば、1日に3.3作品以上見る必要がある • 1作品2時間だと仮定すると、6時間以上も必要! • 絶対ムリ! 映画を全部見るのは絶対ムリ! • 「あなたにイチオシ!」とオススメしてくれる推薦システムは… • わざわざ、自分に合った作品を探さなくて済む! • つまり、ユーザーの貴重な時間を無駄にしない神テクノロジー!
ゆるふわマシーンラーニング #4 2020-07-02 Thu 俺の Amazon Personalize とは
俺の Amazon Personalizeとは 17 引用: Amazon Personalize
俺の Amazon Personalizeとは 18 機械学習の経験がほとんどない開発者が パーソナライゼーションとレコメンデーションを 作れるフルマネージドサービス つまり、非常にゆるくMLできる
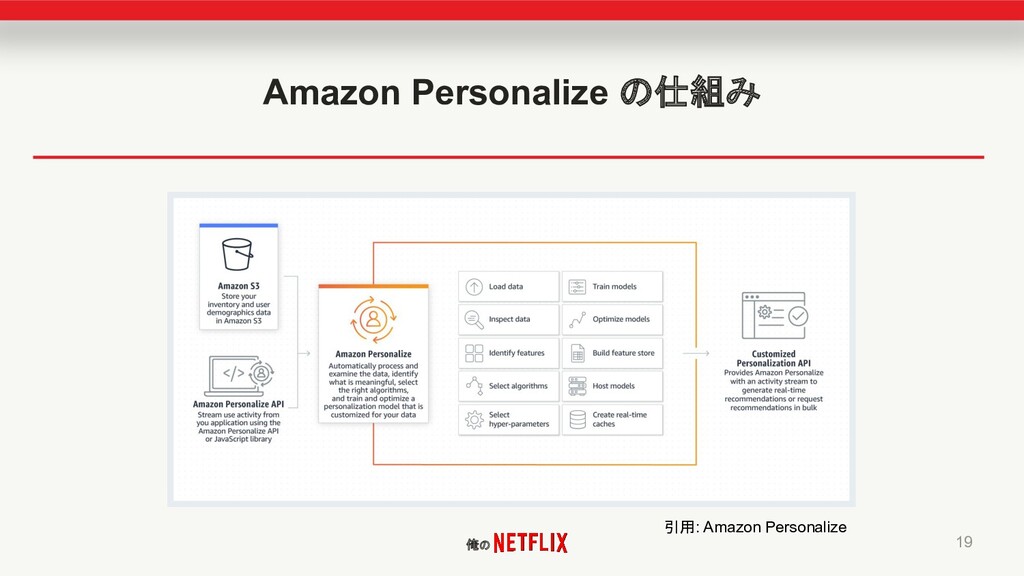
俺の Amazon Personalize の仕組み 19 引用: Amazon Personalize
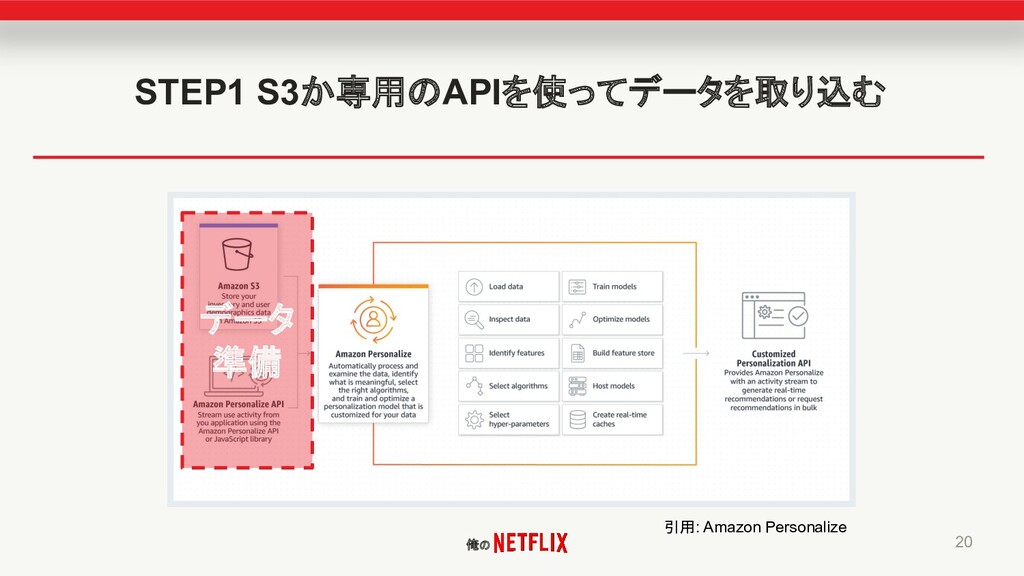
俺の STEP1 S3か専用のAPIを使ってデータを取り込む 20 引用: Amazon Personalize データ 準備
俺の STEP2 いい感じにモデル構築してくれる(AutoML) 21 引用: Amazon Personalize モデル構築
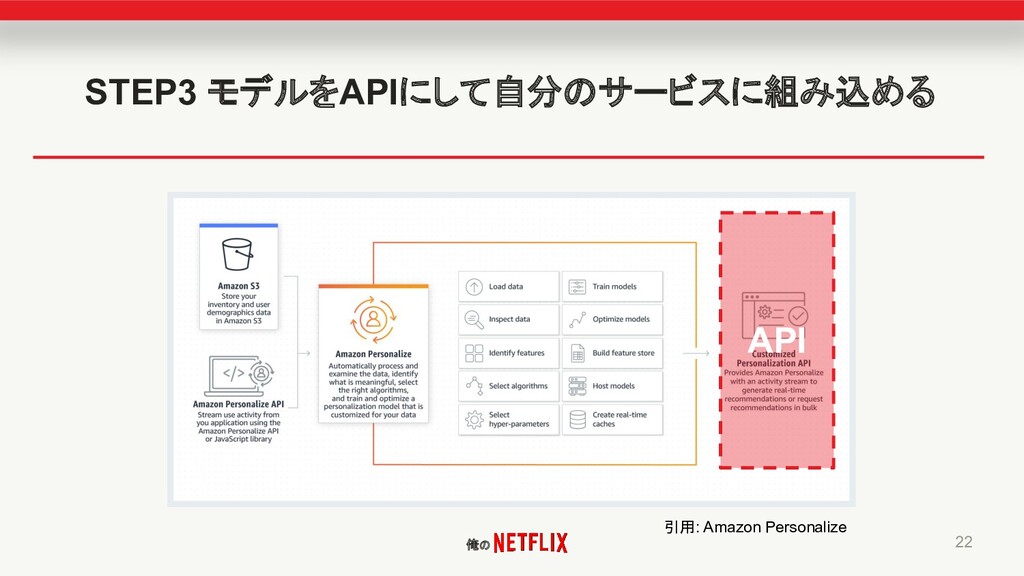
俺の STEP3 モデルをAPIにして自分のサービスに組み込める 22 引用: Amazon Personalize API
俺の ゆるく試す分には、無料でいけると思う 23 引用: Amazon Personalize • 期間 初回利用から2ヶ月間 •
データ処理およびストレージ 毎月最大 20GB • トレーニング 毎月最大 100 トレーニング時間 • レコメンデーション 最大 50 TPS 時間 即時推薦/月
ゆるふわマシーンラーニング #4 2020-07-02 Thu 俺の Amazon Personalize でレコメン ドシステムを作ってみた
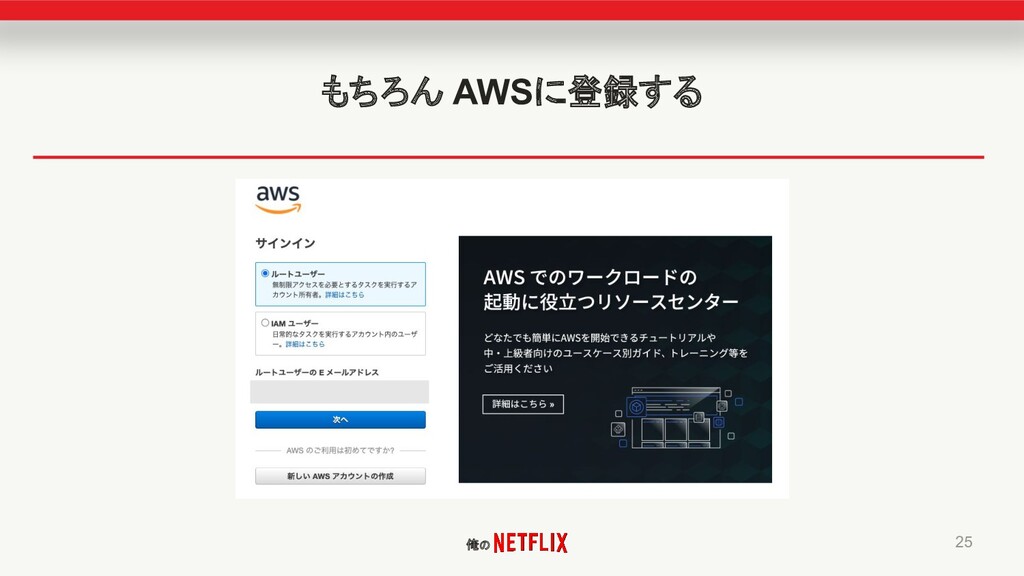
俺の もちろん AWSに登録する 25
俺の Amazon Personalize を使う方法は3つある 1. Amazon Personalize 専用コンソールから使う 2. AWS
CLI から使う 3. AWS SDK から使う 今回は、専用コンソール(1)でやってみた 26
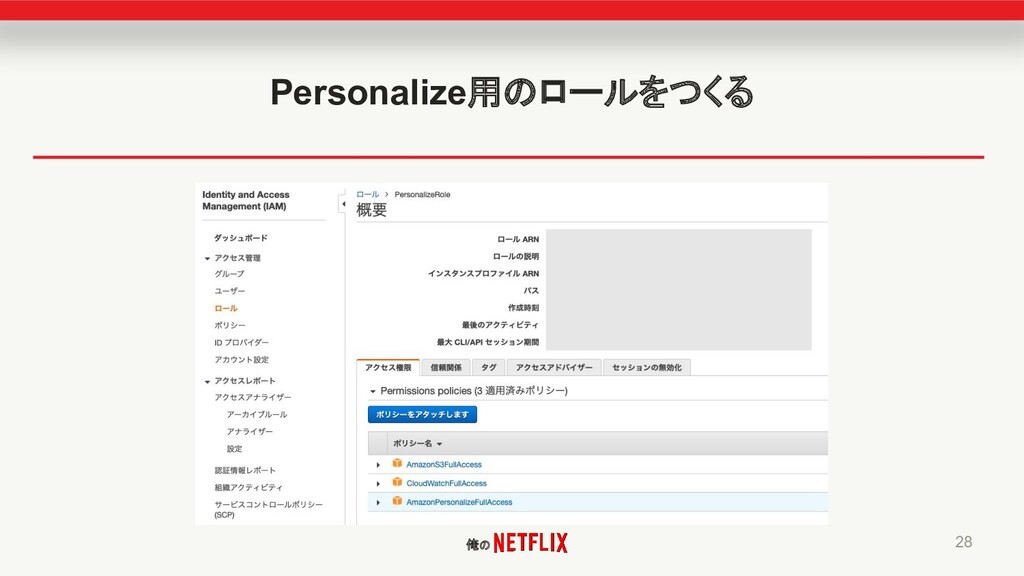
俺の 権限のセットアップ 27 • S3バケットにアップロードしたデータを使っ て、学習をおこなう • そのためS3やPersonalizeへのアクセスを許 可する設定作業が必要 •
クラウドいじったことある人なら難しくないけ ど、初学者ならちょっとだけハマるかも
俺の Personalize用のロールをつくる 28
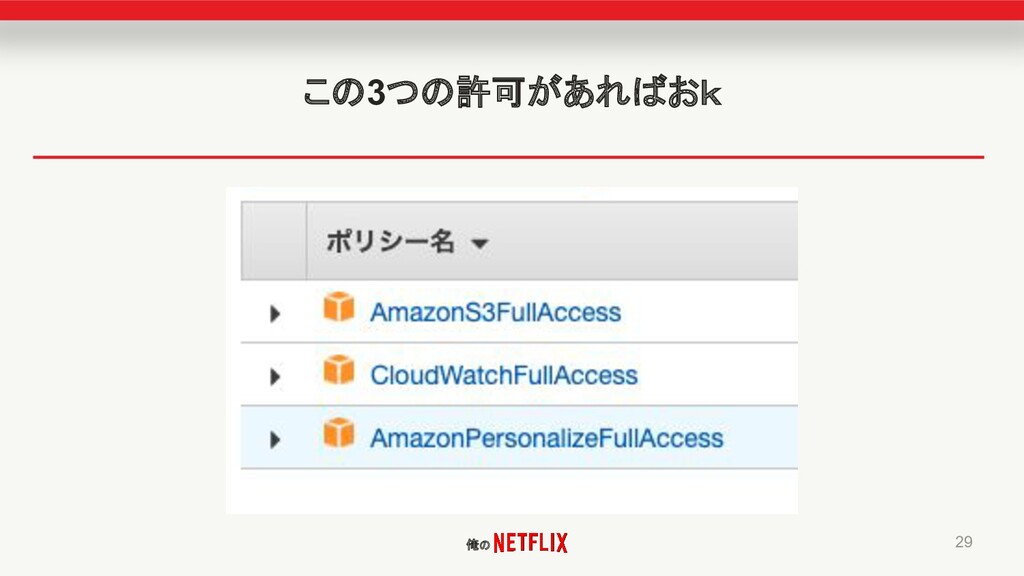
俺の この3つの許可があればおk 29
俺の データの準備 30 非常にゆるくMLできるサービスの罠 そのままインポートできるレベルの 高品質データじゃないと マジで使い始められない
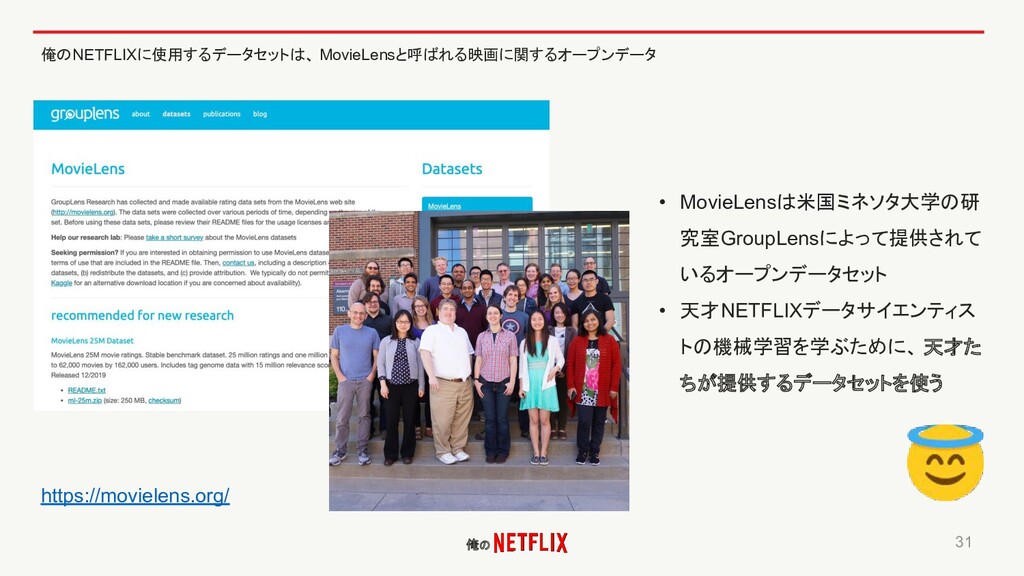
俺の 俺のNETFLIXに使用するデータセットは、 MovieLensと呼ばれる映画に関するオープンデータ 31 • MovieLensは米国ミネソタ大学の研 究室GroupLensによって提供されて いるオープンデータセット • 天才NETFLIXデータサイエンティス
トの機械学習を学ぶために、 天才た ちが提供するデータセットを使う https://movielens.org/
俺の 今回は2018年9月9日に更新された 1MBの一番軽いデータセットを使うことにした 32 ml-latest-small.zip ratings.csv movies.csv tags.csv links.csv •
600人のユーザーが • 9,000本の映画作品の中から • 視聴した作品を評価したデータ • 作品に対してハッシュタグもつけている • 評価件数は100,000件 ふ〜ん(?)
俺の 評価ってこうやって保存しているのが雰囲気でわかってきた ratings.csv 33 このファイルだけで • 誰が(userId) • いつ(timestamp) •
どんな映画作品(movieId)を • どのように評価(rating)したのかがわかる!
俺の 何をレコメンドするの?を考える ユーザーが高評価しそうな作品をレコメンドしたい ↓ • 高評価って具体的にいくつよ? • 学習しすぎたら請求額やばいよ? • 評価された時期どうするの?
• データが規則正しすぎたら学習に支障でるよ? 34
俺の ゆるくMLするので、ご容赦ください ユーザーが高評価しそうな作品をレコメンドしたい ↓ • 高評価って具体的にいくつよ? 食べログパクる(rating<3.6〜 • 学習しすぎたら請求額やばいよ? 10,000行未満
• 評価された時期どうするの? 今回は考慮しない • データが規則正しすぎたら学習に支障でるよ? シャッフルする 35
俺の GogoleColabで前処理した(まずシャッフル) 36 • DeepLearningの学習でもよくつ かう、PythonのMLライブラリの Scikit-learnから • shuffleメソッドを拝借
俺の 3.6より大きい評価のデータだけを残す 37
俺の 10,000行までに抑えておく 38
俺の boto3(AWS SDK for python)使えるけど、csv出力した 39
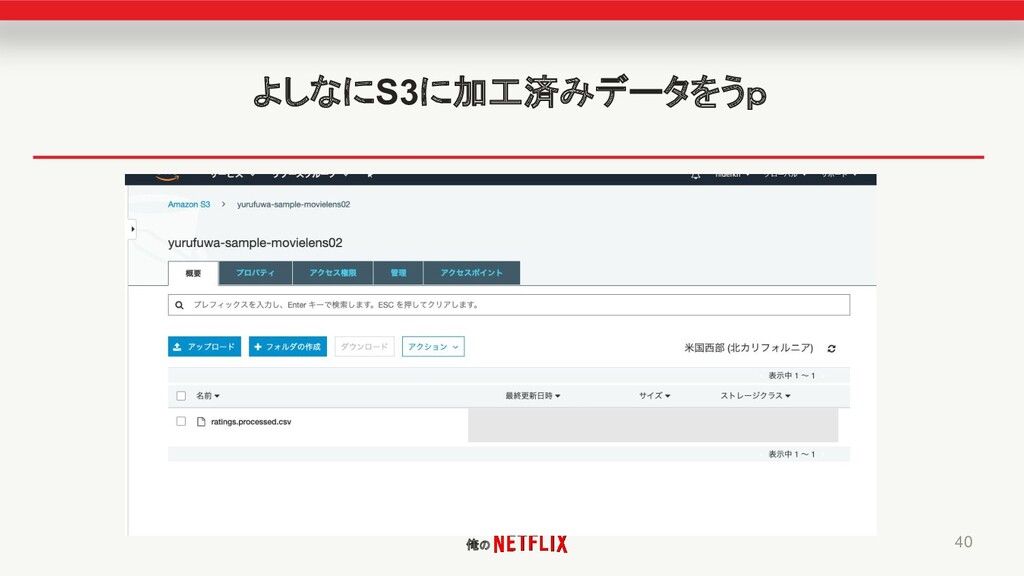
俺の よしなにS3に加工済みデータをうp 40
俺の 前準備完了 ここからやっとPersonalize
俺の Amazon Personalizeにもどる 42
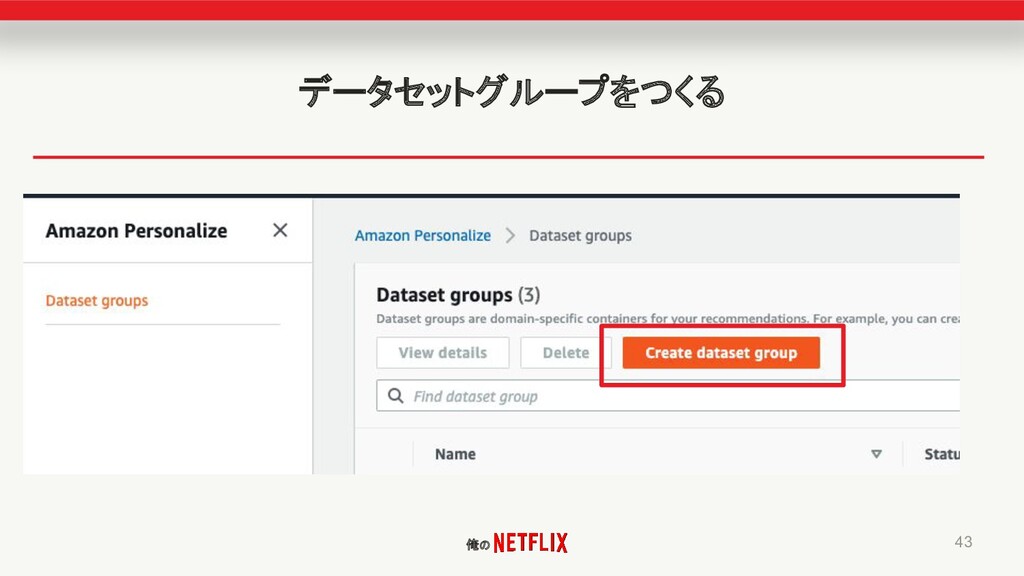
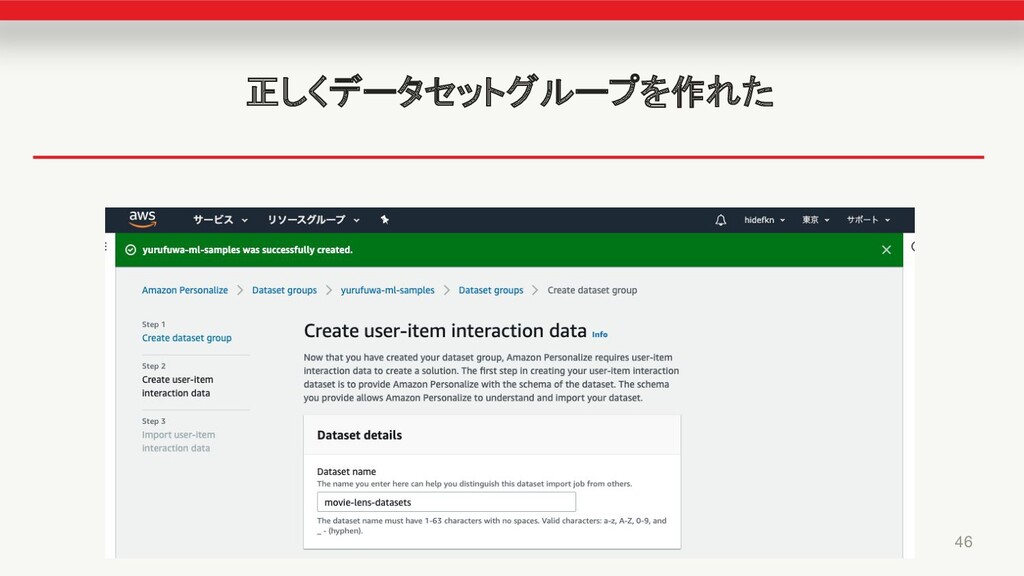
俺の データセットグループをつくる • 43
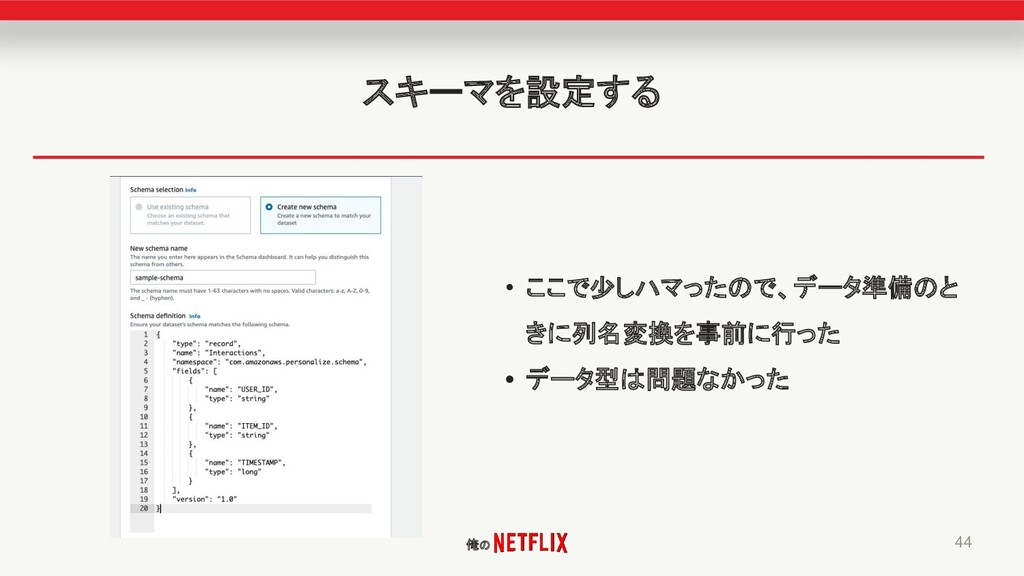
俺の スキーマを設定する 44 • ここで少しハマったので、データ準備のと きに列名変換を事前に行った • データ型は問題なかった
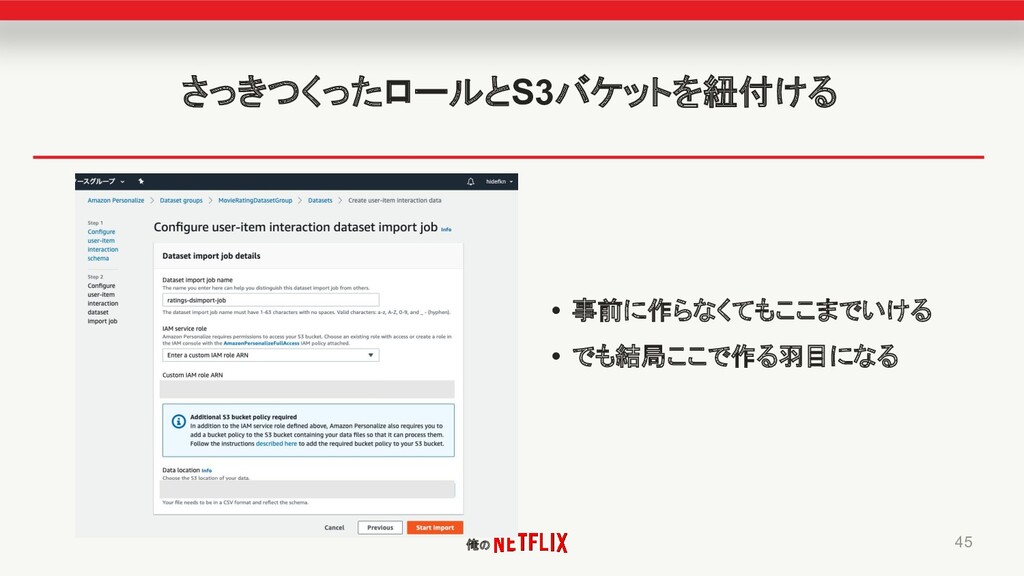
俺の さっきつくったロールとS3バケットを紐付ける 45 • 事前に作らなくてもここまでいける • でも結局ここで作る羽目になる
俺の 正しくデータセットグループを作れた 46
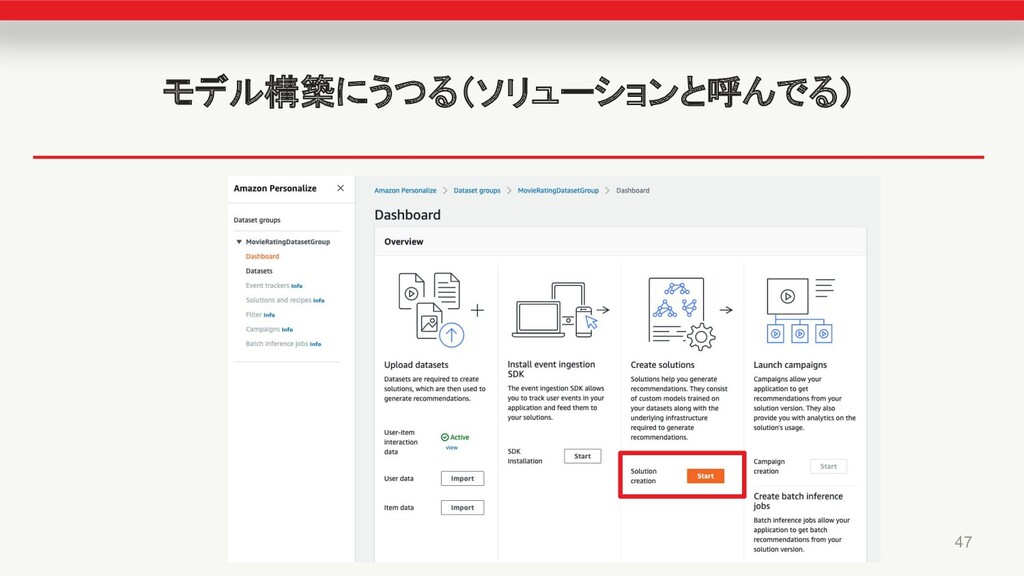
俺の モデル構築にうつる(ソリューションと呼んでる) 47
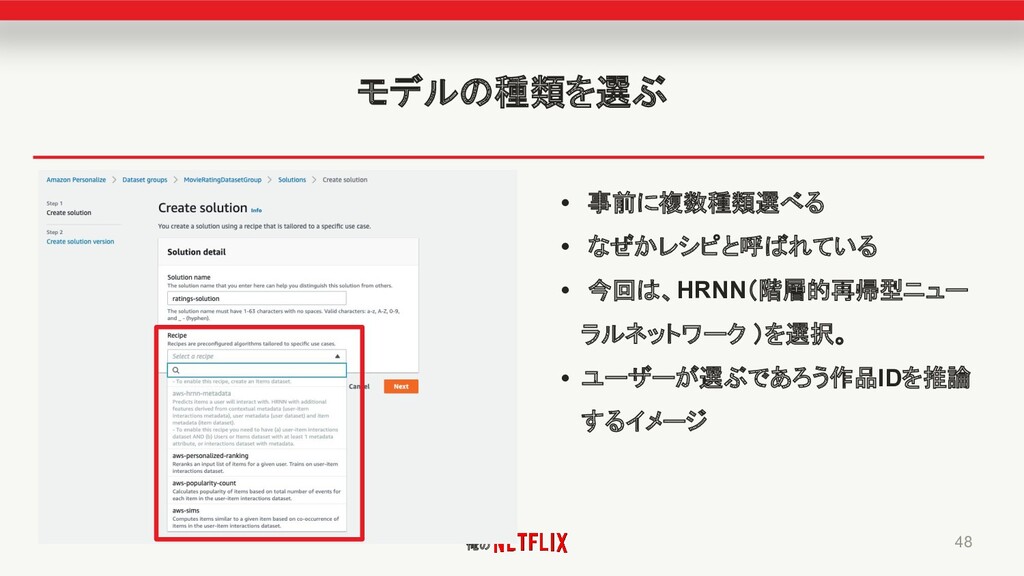
俺の モデルの種類を選ぶ • 事前に複数種類選べる • なぜかレシピと呼ばれている • 今回は、HRNN(階層的再帰型ニュー ラルネットワーク )を選択。
• ユーザーが選ぶであろう作品IDを推論 するイメージ 48
俺の 手動調整もできるけど、今回はおまかせモード • 作ってみて微調整したい なって思ったときに、再学習 させることができるのは便 利 49
俺の あつ森やってる間に、モデルできてた 50
ゆるふわマシーンラーニング #4 2020-07-02 Thu 俺の Amazon Personalize で 推薦結果を取得してみる
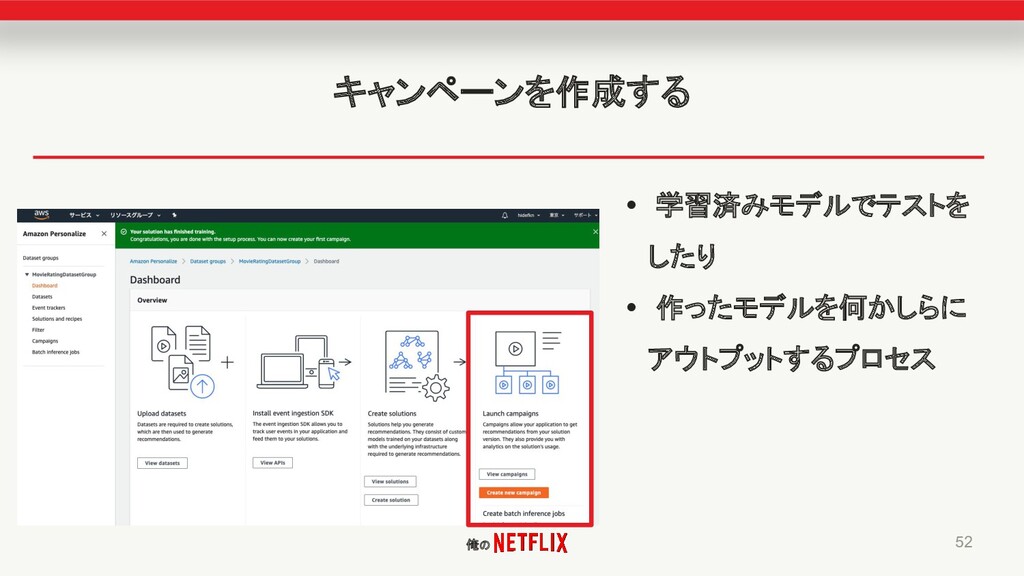
俺の キャンペーンを作成する • 学習済みモデルでテストを したり • 作ったモデルを何かしらに アウトプットするプロセス 52
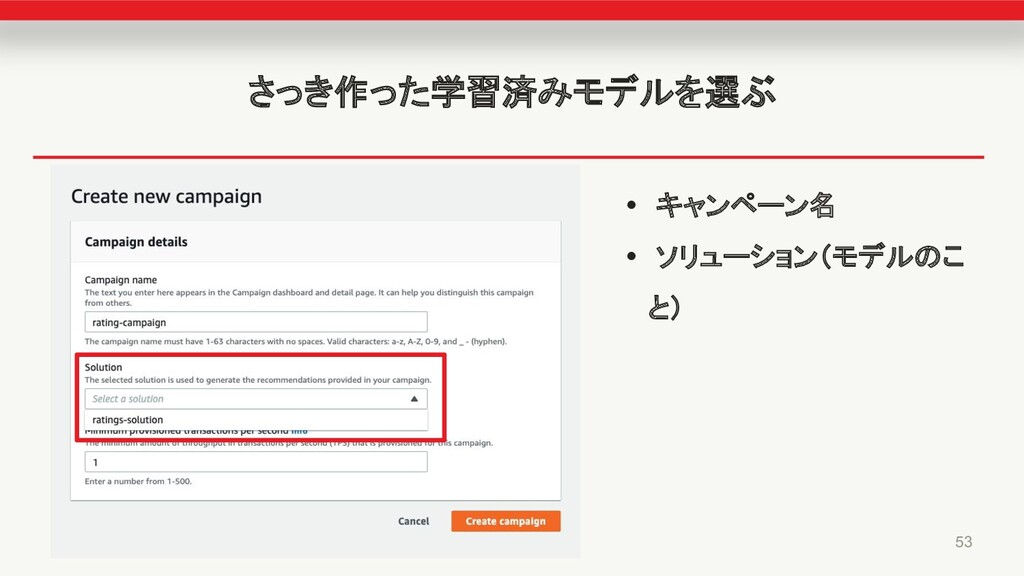
俺の さっき作った学習済みモデルを選ぶ • キャンペーン名 • ソリューション(モデルのこ と) 53
俺の キャンペーンできた 54
俺の 予測したいユーザーIDを入力して、レコメンド開始! 55
俺の movieIdがどんな映画作品を指しているのかも、わかってきた movies.csv 56
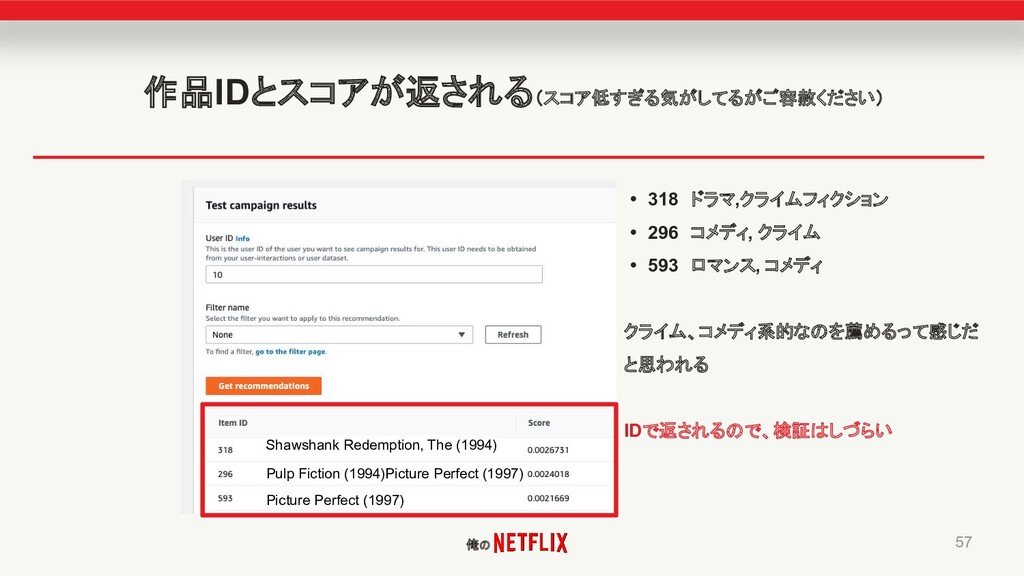
俺の 作品IDとスコアが返される(スコア低すぎる気がしてるがご容赦ください) 57 Shawshank Redemption, The (1994) Pulp Fiction (1994)Picture
Perfect (1997) Picture Perfect (1997) • 318 ドラマ,クライムフィクション • 296 コメディ, クライム • 593 ロマンス, コメディ クライム、コメディ系的なのを薦めるって感じだ と思われる IDで返されるので、検証はしづらい
ゆるふわマシーンラーニング #4 2020-07-02 Thu 俺の 使ってみて思ったこと
俺の やってみて思ったこと 59 • シーズン1の借りを返した • 権限周りの設定に少しハマった • レシピ(Recipe)がめちゃくちゃ便利 •
学習からモデル構築まで3時間もかからなかった • 検証環境は別で作ったほうが良いと思った • Google(GC)よりAmazon(AWS)派になったかも • なお実務ではMS(Azure)の模様
俺の Season2 完
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}