Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MoAコンペで気づいたこと
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
fkubota
December 19, 2020
Programming
800
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MoAコンペで気づいたこと
fkubota
December 19, 2020
More Decks by fkubota
See All by fkubota
相対性理論の入門の入門
fkubota
0
130
データドリブンな組織の不正検知
fkubota
0
2.4k
JupyterNotebookでのdebug入門(サンプルは説明欄にあります)
fkubota
6
14k
ルールベース画像処理のススメ
fkubota
17
16k
Kaggle日記について
fkubota
2
2.8k
鳥コンペで惨敗した話とコンペの取り組み方
fkubota
1
7k
クロマベクトルって何?
fkubota
2
2.7k
生産性と戦った僕の1年の記録とツールたち
fkubota
6
6.8k
Other Decks in Programming
See All in Programming
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
910
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
850
Android CLI
fornewid
0
170
自作OSでスライド発表する
uyuki234
1
3.9k
Built Our Own Background Agent at LayerX #aidevex_findy
layerx
PRO
8
3.3k
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
280
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
190
FDEが実現するAI駆動経営の現在地
gonta
2
220
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
2.4k
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
130
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
150
PHP に部分適用が来るぞ!……ところで何それ?おいしいの? #phpcon / phpcon-2026
shogogg
0
350
Featured
See All Featured
A better future with KSS
kneath
240
18k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Odyssey Design
rkendrick25
PRO
2
730
Exploring anti-patterns in Rails
aemeredith
3
450
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
560
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
Google's AI Overviews - The New Search
badams
0
1.1k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
It's Worth the Effort
3n
188
29k
We Have a Design System, Now What?
morganepeng
55
8.2k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
Transcript
MoAコンペで気づいたこと fkubota https://www.kaggle.com/fkubota
さっそくですが モデルの性能をtarget_columnごとで評価したことありますか? 僕はあります。 今回のコンペのmetricを見てみましょう。 これを変形してみます。 https://www.kaggle.com/c/lish-moa/overview/evaluation
row方向 column方向 mのみに依存
各カラム毎にscoreを出力できた!
ターゲットカラム毎に評価はできました。 1つ1つ結果を確認するのもいいですが、 もう少しおもしろいことをしましょう。
1の数(n)を数えてみる 17 18 24 190 301 仮説: nが小さいほど(学習が困難になって)lossが大きいのでは? n =
n vs logloss でプロット nが小さいほどうまく学習ができていない? ---> nが小さいほどloglossは大きくなる? 右のグラフを見る限りそうでもない。 仮説は否定された。なんでこうなるの? あと、右上に単調増加する意味ありげな形
これはなにかあるぞ。。。
そもそも、nが1とかだったら、 モデルに予測させるのではなく、 全部0埋めすればいいのでは? こいつら学習させることで きるんですか?
0で埋めるのが最適かはわからない。 0に近い値で埋めたほうがいいのは確か。 どの程度の一定値で埋めればいい? n=1, 2, 3, 4, 5のときに、様々な一定値で埋めて score_colを計算した。 横軸は、埋めた一定値の値。
縦軸はscore_col の値。 最適な一定値はnによって変わる。
実はこの最適な一定値は解析的に計算できる。 簡単に紹介(自分で計算してみてね)。
score_colを最小とするようなCをC_0とする (記号の雑さ、数学的な厳密性の欠如は今は目を瞑ってください m(_ _)m) これを解くと... 美しい感じの解出た! 直感的!!
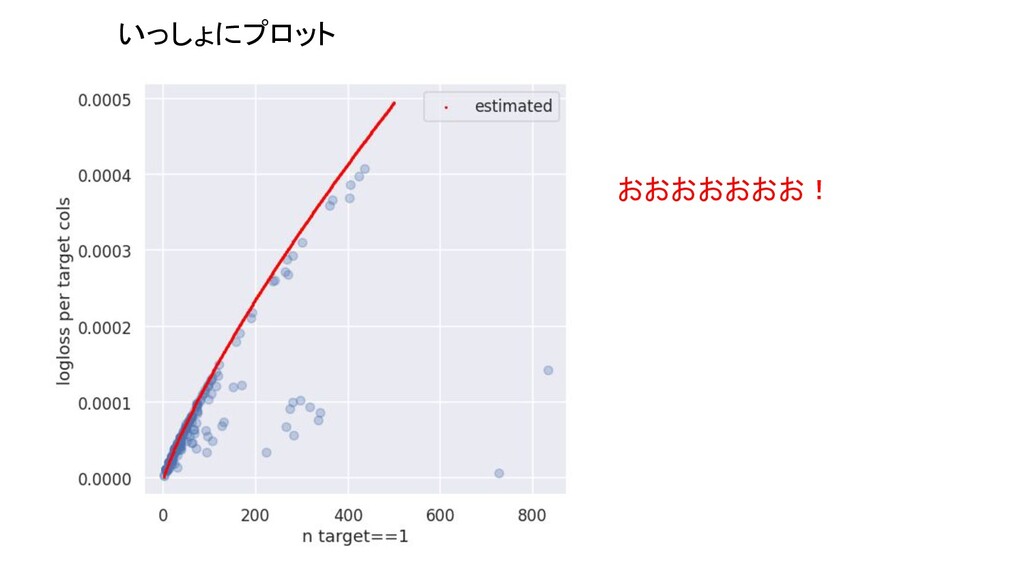
求めた解を使って、nごとにプロットしてみる おっ??
いっしょにプロット おおおおおおお!
つまり? 計算したloglossを赤色でプロットした。 見事に一致している部分が多くある。 赤色と重なっている青い部分はこう解釈できる。 「1は予測できないが、たまに1がtargetにある。すべて0 にpredictしてしまうとペナルティが大きくなってしまうの で、ちょうどいい感じの値を出しておこう」 モデルは、1を頑張って予測しようとしているのではな く、ペナルティが最小限になるような値を出力しているに 過ぎないと言える。
赤い線に近い値を取っているカラムは 全く学習していない!!!
シェイクの予感 - ほとんどの参加者は、この事に気づいていない - スコアに大きな影響があるのはnが大きいターゲット - おそらくほとんどのモデルはnが小さいターゲットはほとんど学習で きていない - モデルは、nが小さなターゲットではn(1が何個含まれているか?)し
か見ていない。 - testとtrainでnの数に大きな差があれば性能は極端に落ちる。 nが小さいtargetで性能を出せればシェイクアップはできる!!
コンペ後半は、n<200の部分だけの性能アップに注力 - focal loss - mixup - LabelSmoothing - etc….
mixupが一番効く!!
cool_rabbitさんによる実験 黄色: mixup なし 青色: mixupあり 良くなってる 悪くなってる アンサンブルの時、 このモデルはN<200
の部分だけを使うなどの工 夫をした
シェイクアップ!!!!
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}