Control and System Theory of Discrete-Time Stochastic Systems Jan H. van Schuppen Chapter 6 Stochastic Realization of Gaussian Systems The reader who first learns about the stochastic realization problem is advised to concentrate attention on Sects. 6.2 through 6.5. The study of this chapter may be complemented with the reading of the appendices 23 and 24 but this can be postponed till a study of the proof of Theorem 6.4.3 presented in Sect. 6.6. The problem formulation of stochastic realization is due to R.E. Kalman. The theory of weak Gaussian stochastic realization is primarily due to P. Faurre and his co-workers. The theory of strong Gaussian stochastic realization is due to A. Lindquist, G. Picci, and G. Ruckebusch with his advisor M. Metivier. 6.1 Introduction to Realization Theory Realization theory is a major component of control and system theory used in this book. In control and system theory, realization theory mostly refers to realization of deterministic systems. The term stochastic realization is used for realization of stochastic systems. There follow historical comments on realization theory. The reader is also referred to Sect. 6.13 in which many references are mentioned. The term realization originates in circuit theory, also called electric network the- ory. Consider engineers who have formulated mathematically an impedance matrix of an electric network, either with two or more entry points called poles. Their prob- Proceedings of Machine Learning Research vol 242:504–513, 2024 A Data-driven Riccati Equation Anders Rantzer
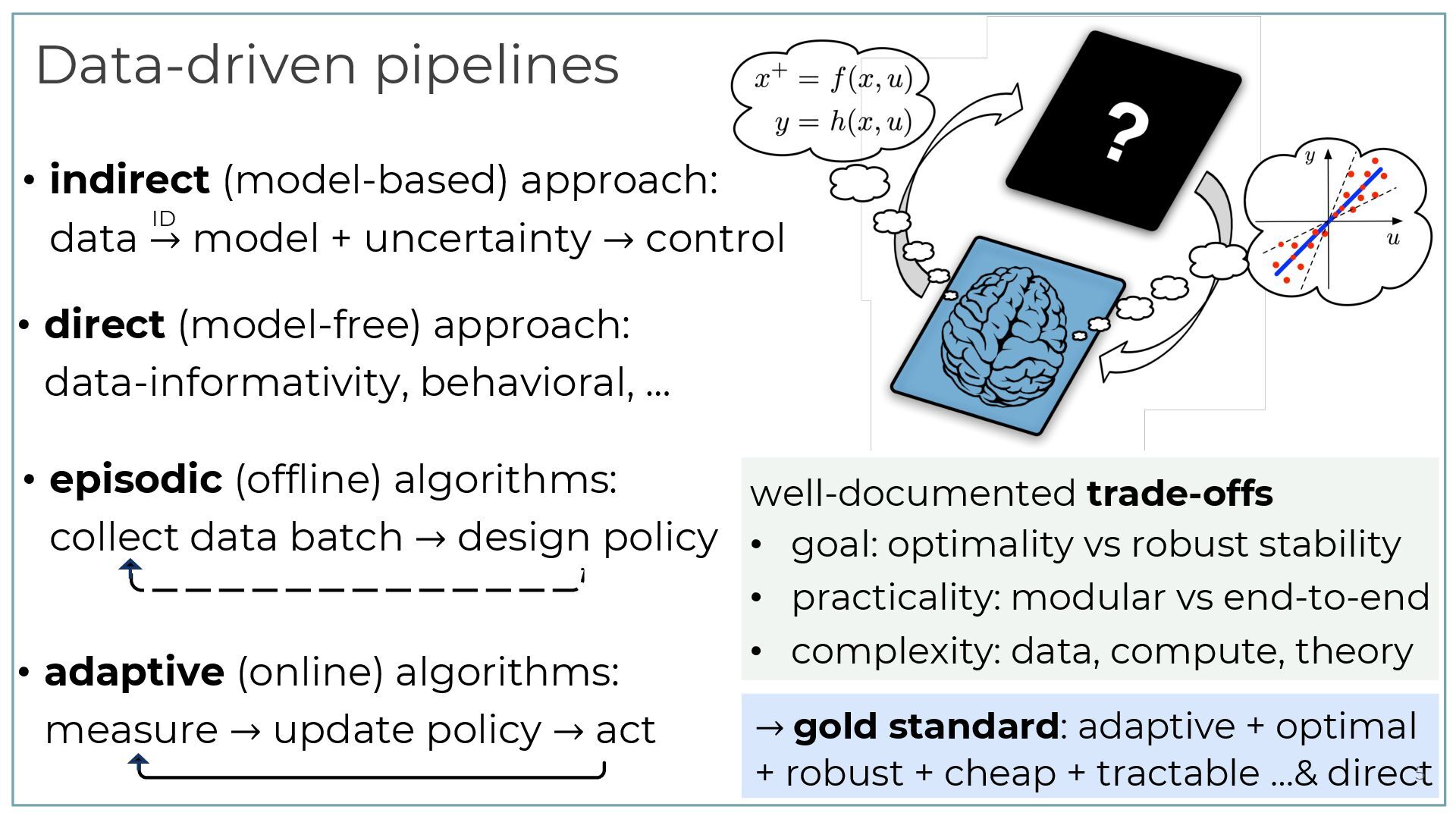
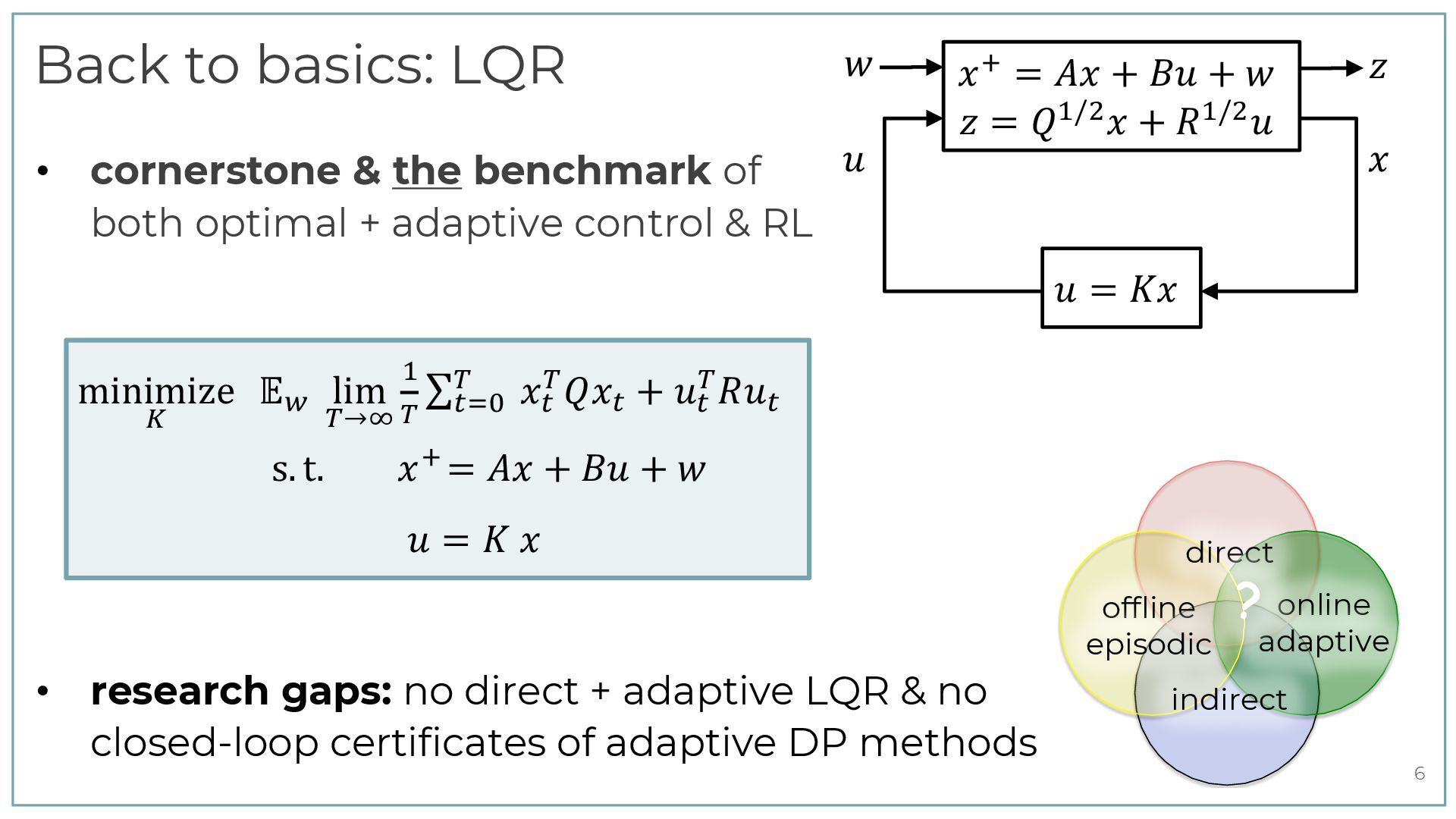
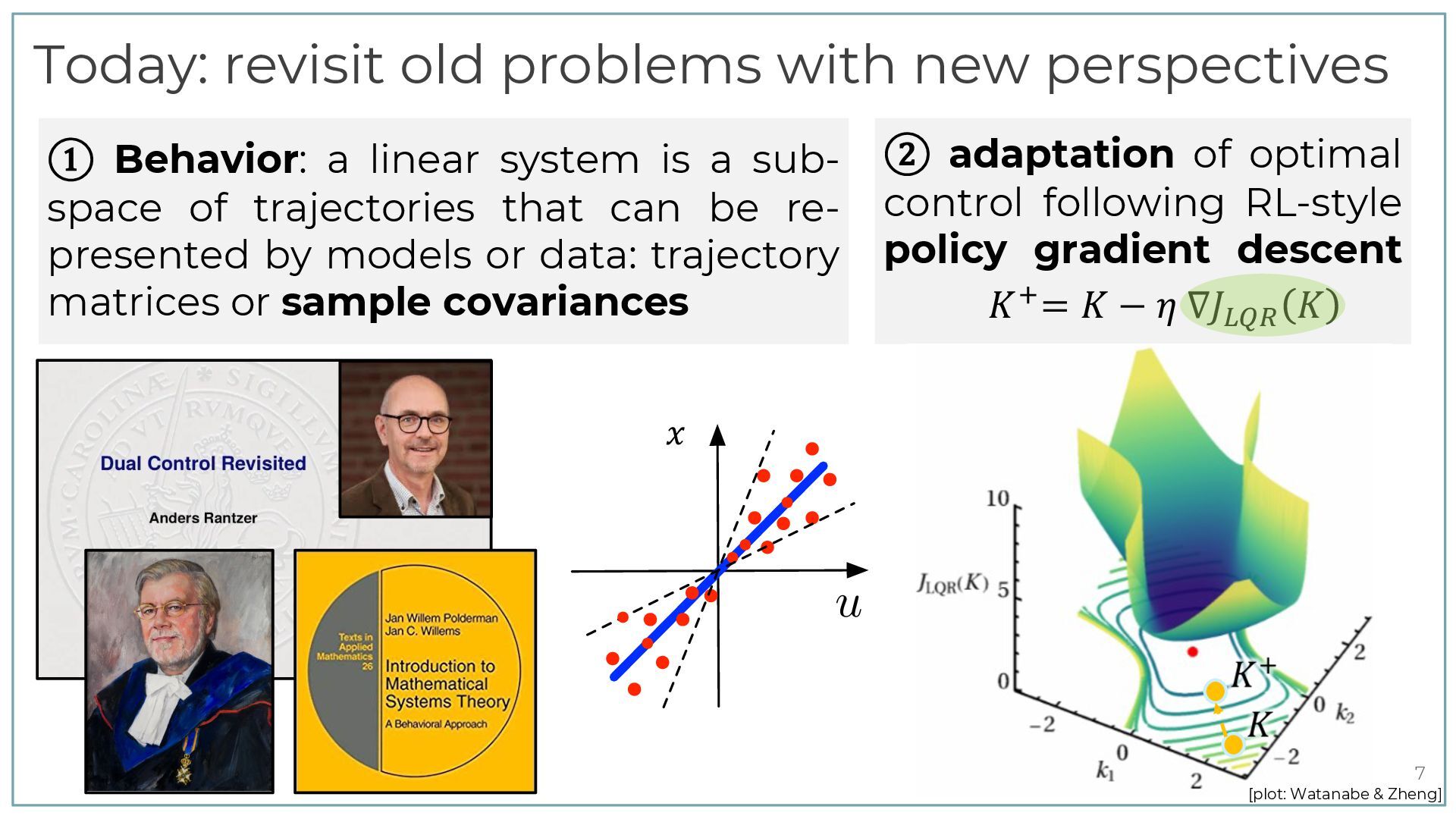
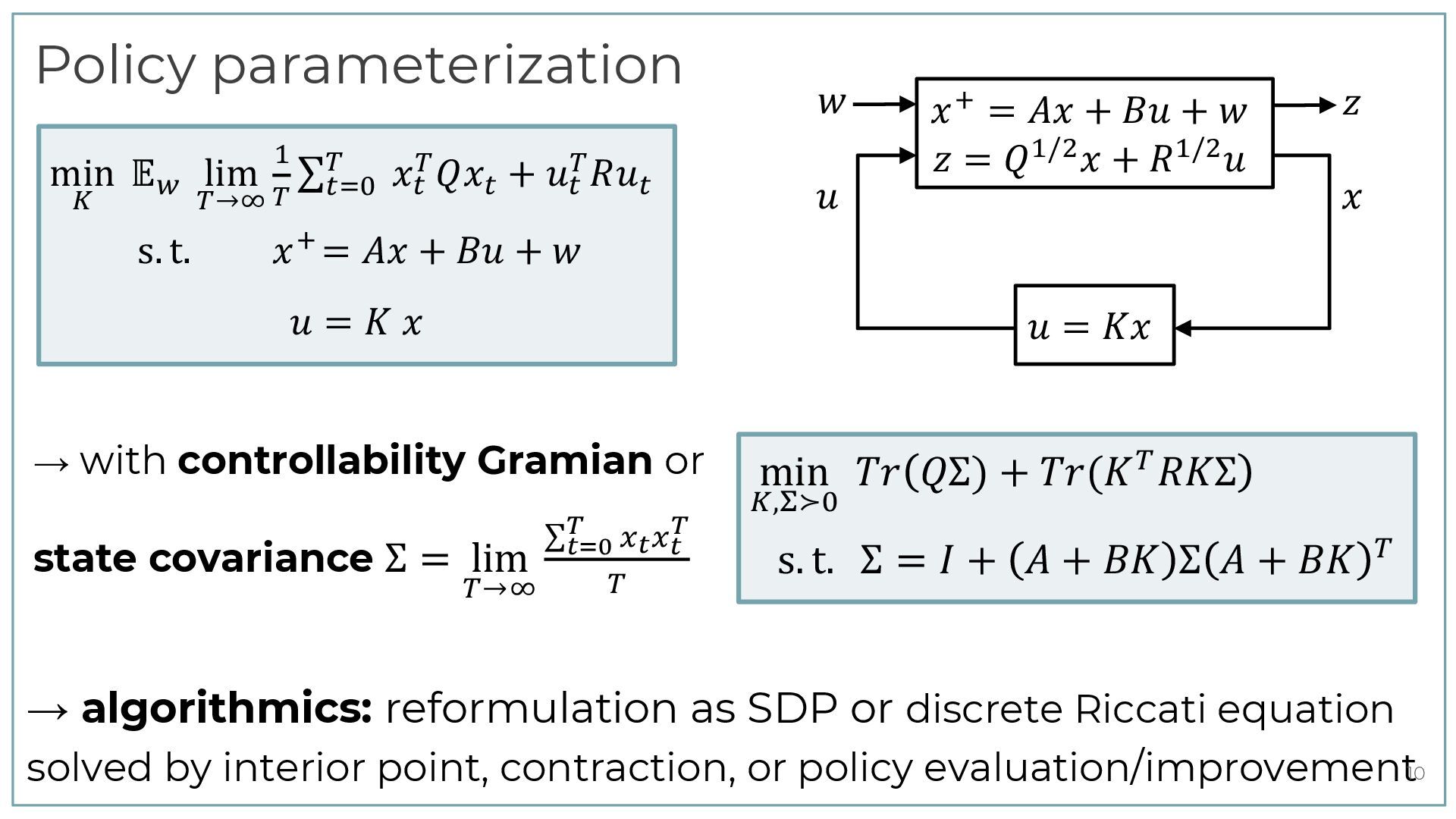
[email protected] Lund University, Sweden Abstract Certainty equivalence adaptive controllers are analysed using a “data-driven Riccati equation”, cor- responding to the model-free Bellman equation used in Q-learning. The equation depends quadrat- ically on data correlation matrices. This makes it possible to derive simple sufficient conditions for stability and robustness to unmodeled dynamics in adaptive systems. The paper is concluded by short remarks on how the bounds can be used to quantify the interplay between excitation levels and robustness to unmodeled dynamics. Keywords: dual control, adaptive control, online learning, linear quadratic control 1. Introduction The history of adaptive control dates back at least to aircraft autopilot development in the 1950s. Following the landmark paper ˚ Astr¨ om and Wittenmark (1973), a surge of research activity during the 1970s derived conditions for convergence, stability, robustness and performance under various assumptions. For example, Ljung (1977) analysed adaptive algorithms using averaging, Goodwin et al. (1981) derived an algorithm that gives mean square stability with probability one, while Guo (1995) gave conditions for the optimal asymptotic rate of convergence. On the other hand, condi- tions that may cause instability were studied in Egardt (1979), Ioannou and Kokotovic (1984) and Rohrs et al. (1985). Altogether, the subject has a rich history documented in numerous textbooks, such as ˚ Astr¨ om and Wittenmark (2013), Goodwin and Sin (2014), and Sastry and Bodson (2011). Recently, there has been a renewed interest in analysis of adaptive controllers, driven by progress in statistical machine learning. See Tsiamis et al. (2023) for a review. In parallel, there is also a rapidly developing literature on (off-line) data-driven control. De Persis and Tesi (2019); Markovsky and D¨ orfler (2021); Berberich et al. (2020). In this paper, the focus is on worst-case models for disturbances and uncertain parameters, as discussed in Cusumano and Poolla (1988); Sun and Ioannou (1987); Vinnicombe (2004); Megretski (2004) and more recently in Rantzer (2021); Cederberg et al. (2022); Kjellqvist and Rantzer (2022). However, the disturbances in this paper are assumend to be bounded in terms of past states and inputs. This causality constraint is different from above mentioned references. 2. Notation Regularization for Covariance Parameterization of Direct Data-Driven LQR Control Feiran Zhao, Alessandro Chiuso, Florian D¨ orfler Abstract— As the benchmark of data-driven control methods, the linear quadratic regulator (LQR) problem has gained significant attention. A growing trend is direct LQR design, which finds the optimal LQR gain directly from raw data and bypassing system identification. To achieve this, our previous work develops a direct LQR formulation parameterized by sample covariance. In this paper, we propose a regulariza- tion method for the covariance-parameterized LQR. We show that the regularizer accounts for the uncertainty in both the steady-state covariance matrix corresponding to closed- loop stability, and the LQR cost function corresponding to averaged control performance. With a positive or negative coefficient, the regularizer can be interpreted as promoting either exploitation or exploration, which are well-known trade- offs in reinforcement learning. In simulations, we observe that our covariance-parameterized LQR with regularization can significantly outperform the certainty-equivalence LQR in terms of both the optimality gap and the robust closed-loop stability. I. INTRODUCTION As a cornerstone of modern control theory, the linear quadratic regulator (LQR) has become the benchmark prob- lem of validating and comparing different data-driven control methods [1]. Manifold approaches to data-driven LQR design can be broadly classified as indirect, i.e., based on system identification (SysID) followed by model-based control, ver- relations, the closed-loop matrix can be further expressed by raw data matrices. As such, the LQR problem can be reformulated as a data-based convex program parameterized and solved without involving any explicit SysID. In this direct LQR framework, regularization can be used to single out a solution with favorable properties [2], [12], [13]. By selecting proper regularization coefficients, the solution can flexibly interpolate between indirect certainty-equivalence LQR and robust closed-loop stable gains. While the parameterization and regularization in [2], [12], [13] sheds a light on direct LQR design, two limitations hinder their broader implication. First, the dimension of their direct LQR formulation scales linearly with the data length. Thus, this parameterization cannot be used to achieve adaptive control with online closed-loop data [14]. Second, their direct LQR solution without regularization is sensitive to noise [15]. Even using regularization, there is a trade- off between performance and robust closed-loop stability in their solution, i.e., one has to be sacrificed to gain the other [13]. Moreover, when the length of data tends to infinity, the regularized formulation may lead to trivial solutions [15]. To address the first limitation, our previous work [14] proposes a new parameterization for the direct data-driven LQR, which parameterizes the feedback gain as a linear 985v1 [eess.SY] 4 Mar 2025 Gaussian behaviors: representations and data-driven control Andr´ as Sasfi, Ivan Markovsky, Alberto Padoan, Florian D¨ orfler Abstract— We propose a modeling framework for stochastic systems based on Gaussian processes. Finite-length trajectories of the system are modeled as random vectors from a Gaussian distribution, which we call a Gaussian behavior. The proposed model naturally quantifies the uncertainty in the trajectories, yet it is simple enough to allow for tractable formulations. We relate the proposed model to existing descriptions of dynamical systems including deterministic and stochastic behaviors, and linear time-invariant (LTI) state-space models with Gaussian process and measurement noise. Gaussian behaviors can be estimated directly from observed data as the empirical sample covariance under the assumption that the measured trajectories are from independent experiments. The distribution of future outputs conditioned on inputs and past outputs provides a predictive model that can be incorporated in predictive control frameworks. We show that subspace predictive control (SPC) is a certainty-equivalence control formulation with the estimated Gaussian behavior. Furthermore, the regularized data-enabled predictive control (DeePC) method is shown to be a distribu- tionally optimistic formulation that optimistically accounts for uncertainty in the Gaussian behavior. To mitigate the excessive optimism of DeePC, we propose a novel distributionally ro- bust control formulation, and provide a convex reformulation allowing for efficient implementation. I. INTRODUCTION Recent data-driven control methods based on the be- havioral approach [1]–[7] have gained significant attention. These formulations rely on behavioral systems theory that treats systems as sets of trajectories, and allows to represent linear time-invariant (LTI) systems directly with data [8], [9]. The methods exploit this data representation and typically add regularization to the problem [10], [11] for a posteriori robustification. The resulting formulations can achieve com- parable or even superior performance compared to classical methods consisting of an identification and a control step, Stochastic extensions to behavioral systems theory have been defined bottom up in the literature [14], [15]. However, the existing works provide general and abstract (and thus also blunt) perspectives that hinder the practical applicability of the frameworks. Stochastic behaviors have also been mod- eled in the literature using polynomial chaos expansions [16], [17]. However, the complexity of the resulting methods grow with the order of the expansion, limiting scalability. Recently, a stochastic interpretation of data-driven control formula- tions was proposed in [18], highlighting that regularization accounts for the uncertainty in a linear model estimated from data. In this work, we take a different approach, and propose a new bottom-up stochastic modeling framework that admits a data representation and leads to tractable control formulations which can be solved efficiently. The contributions of this work are the following. First, in Section III, we propose a stochastic modeling framework based on Gaussian processes that enables us to model tra- jectories as normally distributed random vectors. We define the distribution of trajectories to be a Gaussian behavior, characterized by its mean and covariance, which inherently captures uncertainty. Gaussian behaviors give rise to pre- dictive models given by the conditional distribution, which can be calculated readily in the proposed framework. Fur- thermore, in a data-driven context, Gaussian behaviors can be estimated directly as the empirical sample covariance, which is also used as a system representation in [19]. We show that Gaussian behaviors are a special class of stochas- tic behaviors. Furthermore, the deterministic behavioral de- scription of LTI systems as subspaces is captured by the proposed definition with zero mean and singular covariance matrix. Finally, stochastic LTI systems given by state-space 1 Data-Enabled Policy Optimization for Direct Adaptive Learning of the LQR Feiran Zhao, Florian D¨ orfler, Alessandro Chiuso, Keyou You Abstract —Direct data-driven design methods for the linear quadratic regulator (LQR) mainly use offline or episodic data batches, and their online adaptation remains unclear. In this paper, we propose a direct adaptive method to learn the LQR from online closed-loop data. First, we propose a new policy parameterization based on the sample covariance to formulate a direct data-driven LQR problem, which is shown to be equivalent to the certainty-equivalence LQR with optimal non-asymptotic guarantees. Second, we design a novel data-enabled policy opti- mization (DeePO) method to directly update the policy, where the gradient is explicitly computed using only a batch of persistently exciting (PE) data. Third, we establish its global convergence via a projected gradient dominance property. Importantly, we efficiently use DeePO to adaptively learn the LQR by performing only one-step projected gradient descent per sample of the closed- loop system, which also leads to an explicit recursive update of the policy. Under PE inputs and for bounded noise, we show that the average regret of the LQR cost is upper-bounded by two terms signifying a sublinear decrease in time O(1/ → T) plus a bias scaling inversely with signal-to-noise ratio (SNR), which are independent of the noise statistics. Finally, we perform simulations to validate the theoretical results and demonstrate the computational and sample efficiency of our method. Index Terms —Adaptive control, linear quadratic regulator, System (𝐴𝐴, 𝐵𝐵) ℎ𝑖𝑖 𝑥𝑥𝑡𝑡 Controller 𝐾𝐾𝑖𝑖 𝑢𝑢𝑡𝑡 𝑖𝑖: iteration Policy update Fig. 1. An illustration of episodic approaches, where hi = (x0, u0, . . . , xT i ) denotes the i-th episode of data, and the episodes can be consecutive. System (𝐴𝐴, 𝐵𝐵) 𝑥𝑥𝑡𝑡 𝐾𝐾𝑡𝑡 = 𝑓𝑓𝑡𝑡 (𝐾𝐾𝑡𝑡−1 ) 𝐾𝐾𝑡𝑡 = 𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆(𝐴𝐴𝑡𝑡 , 𝐵𝐵𝑡𝑡 ) SysID (𝐴𝐴𝑡𝑡 , 𝐵𝐵𝑡𝑡 ) 𝑢𝑢𝑡𝑡 Direct Indirect 𝑡𝑡: time step Controller Fig. 2. An illustration of indirect and direct adaptive approaches in a closed- loop system, where function ft has an explicit form. The indirect data-driven LQR design has a rich history with well-understood tools for identification and control. Repre- v4 [math.OC] 4 Oct 2024 Linear-Quadratic Problems in Systems and Controls via Covariance Representations and Linear-Conic Duality: Finite-Horizon Case Bassam Bamieh∗ Abstract Linear-Quadratic (LQ) problems that arise in systems and controls include the classical optimal control problems of the Linear Quadratic Regulator (LQR) in both its deterministic and stochastic forms, as well as H →-analysis (the Bounded Real Lemma), the Positive Real Lemma, and general Integral Quadratic Constraints (IQCs) tests. We present a unified treatment of all of these problems using an approach which converts linear-quadratic problems to matrix-valued linear-linear problems with a positivity constraint. This is done through a system representation where the joint state/input covariance (the outer product in the deterministic case) matrix is the fundamental object. LQ problems then become infinite-dimensional semidefinite programs, and the key tool used is that of linear-conic duality. Linear Matrix Inequalities (LMIs) emerge naturally as conal constraints on dual problems. Riccati equations characterize extrema of these special LMIs, and therefore provide solutions to the dual problems. The state-feedback structure of all optimal signals in these problems emerge out of alignment (complementary slackness) conditions between primal and dual problems. Perhaps the new insight gained from this approach is that first LMIs, and then second, Riccati equations arise naturally in dual, rather than primal problems. Furthermore, while traditional LQ problems are set up in L 2 spaces of signals, their equivalent covariance-representation problems are most naturally set up in L 1 spaces of matrix-valued signals. 1 Introduction and Motivation Linear Quadratic (LQ) control problems in systems and controls first arose through the original Linear Quadratic Regulator (LQR) [1], which is an optimal control problem, as well as the celebrated Kalman- Yacubovic-Popov (KYP) Lemma [2, 3, 4]. The KYP Lemma can be considered as a test for an Integral Quadratic Constraint (IQC), which can be phrased as whether an LQ optimal control problem has finite or infinite infima as advocated in the influential paper of Willems [5]. Other IQC tests can be used to char- acterize robust stability of feedback systems subject to uncertainties that can be characterized by IQCs [6]. Those include the Bounded Real Lemma for testing a system’s H → (L2-induced) norm, as well as the Pos- itive Real Lemma for testing a system’s passivity. In the same manner as [5], by LQ problems we mean something more general than the LQR problem, namely any problem involving linear dynamics with inputs, and a quadratic form defined jointly on the state and input. The goal is to characterize the extrema of the quadratic form subject to the dynamics as a constraint. The literature on these problems is vast, and will not be summarized here. Notably, Linear Matrix Inequalities (LMIs) and Riccati equations appear frequently as central characters in these intertwined stories. Connections between LQ problems and LMIs were pointed out by Willems [5]. The books [7, 8] (see arXiv:2401.01422v1 [eess.SY] 2 Jan 2024 Efficient Optimistic Exploration in Linear-Quadratic Regulators via Lagrangian Relaxation Marc Abeille 1 Alessandro Lazaric 2 Abstract We study the exploration-exploitation dilemma in the linear quadratic regulator (LQR) setting. Inspired by the extended value iteration algorithm used in optimistic algorithms for finite MDPs, we propose to relax the optimistic optimization of OFU-LQ and cast it into a constrained extended LQR problem, where an additional control vari- able implicitly selects the system dynamics within a confidence interval. We then move to the corre- sponding Lagrangian formulation for which we prove strong duality. As a result, we show that an ✏-optimistic controller can be computed effi- ciently by solving at most O log(1/✏) Riccati equations. Finally, we prove that relaxing the orig- inal OFU problem does not impact the learning performance, thus recovering the e O( p T) regret of OFU-LQ. To the best of our knowledge, this is the first computationally efficient confidence- based algorithm for LQR with worst-case optimal regret guarantees. 1. Introduction Exploration-exploitation in Markov decision processes (MDPs) with continuous state-action spaces is a challenging problem: estimating the parameters of a generic MDP may require many samples, and computing the corresponding optimal policy may be computationally prohibitive. The lin- ear quadratic regulator (LQR) model formalizes continuous state-action problems, where the dynamics is linear and the cost is quadratic in state and action variables. Thanks to its specific structure, it is possible to efficiently estimate the parameters of the LQR by least-squares regression and the optimal policy can be computed by solving a Riccati equa- tion. As a result, several exploration strategies have been adapted to the LQR to obtain effective learning algorithms. 1Criteo AI Lab 2Facebook AI Research. Correspondence to: Marc Abeille <
[email protected]>. Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, PMLR 119, 2020. Copyright 2020 by the author(s). Confidence-based exploration. Bittanti et al. (2006) intro- duced an adaptive control system based on the “bet on best” principle and proved asymptotic performance guarantees showing that their method would eventually converge to the optimal control. Abbasi-Yadkori & Szepesvári (2011) later proved a finite-time e O( p T) regret bound for OFU-LQ, later generalized to less restrictive stabilization and noise assumptions by Faradonbeh et al. (2017). Unfortunately, nei- ther exploration strategy comes with a computationally effi- cient algorithm to solve the optimistic LQR, and thus they cannot be directly implemented. On the TS side, Ouyang et al. (2017) proved a e O( p T) regret for the Bayesian regret, while Abeille & Lazaric (2018) showed that a similar bound holds in the frequentist case but restricted to 1-dimensional problems. While TS-based approaches require solving a single (random) LQR, the theoretical analysis of Abeille & Lazaric (2018) suggests that a new LQR instance should be solved at each time step, thus leading to a computational complexity growing linearly with the total number of steps. On the other hand, OFU-based methods allow for “lazy” updates, which require solving an optimistic LQR only a logarithmic number of times w.r.t. the total number of steps. A similar lazy-update scheme is used by Dean et al. (2018), who leveraged robust control theory to devise the first learn- ing algorithm with polynomial complexity and sublinear regret. Nonetheless, the resulting adaptive algorithm suffers from a e O(T2/3) regret, which is significantly worse than the e O( p T) achieved by OFU-LQ. To the best of our knowledge, the only efficient algorithm for confidence-based exploration with e O( p T) regret has been recently proposed by Cohen et al. (2019). Their method, called OSLO, leverages an SDP formulation of the LQ prob- lem, where an optimistic version of the constraints is used. As such, it translates the original non-convex OFU-LQ opti- mization problem into a convex SDP. While solving an SDP is known to have polynomial complexity, no explicit analysis is provided and it is said that the runtime may scale polyno- mially with LQ-specific parameters and the time horizon T (Cor. 5), suggesting that OSLO may become impractical for moderately large T. Furthermore, OSLO requires an initial system identification phase of length e O( p T) to properly initialize the method. This strong requirement effectively reduces OSLO to an explore-then-commit strategy, whose arXiv:2007.06482v1 [stat.ML] 13 Jul 2020 Harnessing Uncertainty for a Separation Principle in Direct Data-Driven Predictive Control ω Alessandro Chiuso a, Marco Fabris a, Valentina Breschi b, Simone Formentin c aDepartment of Information Engineering, University of Padova, Via Gradenigo 6/b, 35131 Padova, Italy. bDepartment of Electrical Engineering, Eindhoven University of Technology, 5600 MB Eindhoven, The Netherlands. cDipartimento di Elettronica, Informazione e Bioingegneria, Politecnico di Milano, P.za L. Da Vinci, 32, 20133 Milano, Italy. Abstract Model Predictive Control (MPC) is a powerful method for complex system regulation, but its reliance on an accurate model poses many limitations in real-world applications. Data-driven predictive control (DDPC) aims at overcoming this limitation, by relying on historical data to provide information on the plant to be controlled. In this work, we present a unified stochastic framework for direct DDPC, where control actions are obtained by optimizing the Final Control Error (FCE), which is directly computed from available data only and automatically weighs the impact of uncertainty on the control objective. Our framework allows us to establish a separation principle for Predictive Control, elucidating the role that predictive models and their uncertainty play in DDPC. Moreover, it generalizes existing DDPC methods, like regularized Data-enabled Predictive Control (DeePC) and ω-DDPC, providing a path toward noise-tolerant data-based control with rigorous optimality guarantees. The theoretical investigation is complemented by a series of experiments (code available on GitHub), revealing that the proposed method consistently outperforms or, at worst, matches existing techniques without requiring tuning regularization parameters as other methods do. Key words: data-driven predictive control, control of constrained systems, regularization, identification for control 1 Introduction Model Predictive Control (MPC) has earned recognition as a powerful technology for optimizing the regulation of complex systems, owing to its flexible formulation and constraint-handling capabilities [26]. However, its e!ec- tiveness is contingent on the accuracy of the predictor based on which control actions are optimized [6]. This native to traditional MPC, see [5,8,12]. DDPC directly maps data collected o”ine onto the control sequence starting from the current measurements, without the need for an intermediate identification phase. In the lin- ear time-invariant setting, mathematical tools such as the “fundamental lemma” [33] and linear algebra-based subspace and projection methods [32] represent the en- abling technology for data-driven control [8,15] also pro- Xiv:2312.14788v3 [eess.SY] 7 Jan 2025 Related to trajectory matrices, but • matrices independent of data size • uniqueness & no regularization • recursive rank-1 updates 1 Formulas for Data-driven Control: Stabilization, Optimality and Robustness C. De Persis and P. Tesi Abstract—In a paper by Willems and coauthors it was shown control theory [6], iterative feedback tuning [7], and virtual On the Certainty-Equivalence Approach to Direct Data-Driven LQR Design Florian D¨ orfler, Pietro Tesi, and Claudio De Persis Abstract—The linear quadratic regulator (LQR) problem is a cor- nerstone of automatic control, and it has been widely studied in the data-driven setting. The various data-driven approaches can be classified as indirect (i.e., based on an identified model) versus direct or as robust (i.e., taking uncertainty into account) versus certainty-equivalence. Here we show how to bridge these different formulations and propose a novel, direct, and regularized formulation. We start from indirect certainty-equivalence LQR, i.e., least-square identification of state-space matrices followed by a nominal model-based design, formalized as a bi-level program. We show how to transform this problem into a single- Lemma [26] implies that the behavior of an LTI system characterized by the range space of a matrix containing ra series data. This perspective gave rise to data-enabled pr control formulations [24], [27], [28] as well as the design of feedback policies [14]–[17]. Both of these are direct dat control approaches and robustness plays a pivotal role. In this paper, we show how to transition between the dir indirect as well as the robust and certainty-equivalence pa for the LQR problem. We begin our investigations with an 2021 Online Linear Quadratic Control Alon Cohen 1 2 Avinatan Hassidim 1 3 Tomer Koren 4 Nevena Lazic 4 Yishay Mansour 1 5 Kunal Talwar 4 Abstract We study the problem of controlling linear time- invariant systems with known noisy dynamics and adversarially chosen quadratic losses. We present the first e cient online learning algorithms in this setting that guarantee O( p T) regret under mild assumptions, where T is the time horizon. Our algorithms rely on a novel SDP relaxation for the steady-state distribution of the system. Crucially, and in contrast to previously proposed relaxations, the feasible solutions of our SDP all correspond to “strongly stable” policies that mix exponentially fast to a steady state. 1. Introduction Linear-quadratic (LQ) control is one of the most widely studied problems in control theory (Anderson et al., 1972; Bertsekas, 1995; Zhou et al., 1996). It has been applied successfully to problems in statistics, econometrics, robotics, social science and physics. In recent years, it has also re- ceived much attention from the machine learning community, as increasingly di cult control problems have led to demand for data-driven control systems (Abbeel et al., 2007; Levine et al., 2016; Sheckells et al., 2017). In LQ control, both the state and action are real-valued vectors. The dynamics of the environment are linear in the state and action, and are perturbed by Gaussian noise. The cost is quadratic in the state and control (action) vectors. The optimal control policy, which minimizes the cost, selects the control vector as a linear function of the state vector, and can be derived by solving the algebraic Ricatti equations. The main focus of this work is control of linear systems whose quadratic costs vary in an unpredictable way. This problem may arise in settings such as building climate control 1Google Research, Tel Aviv 2Technion—Israel Inst. of Tech- nology 3Bar Ilan University 4Google Brain, Mountain View 5Tel Aviv University. Correspondence to: Alon Cohen <alon-
[email protected]>, Tomer Koren <
[email protected]>. Proceedings of the 35 th International Conference on Machine Learning, Stockholm, Sweden, PMLR 80, 2018. Copyright 2018 by the author(s). in the presence of time-varying energy costs, due to energy auctions or unexpected demand fluctuations. To measure how well a control system adapts to time-varying costs, it is common to consider the notion of regret: the di erence between the total cost of the controller, one that is only aware of previously observed costs, and that of the best fixed control policy in hindsight. This notion has been thoroughly studied in the context of online learning, and particularly in that of online convex optimization (Cesa-Bianchi & Lugosi, 2006; Hazan, 2016; Shalev-Shwartz, 2012). LQ control was considered in the context of regret by Abbasi-Yadkori et al. (2014), who give a learning algorithm for the problem of tracking an adversarially changing target in a system with noiseless linear dynamics. In this paper we consider online learning with fixed, known, linear dynamics and adversarially chosen quadratic cost matrices. Our main results are two online algorithm that achieve O( p T) regret, when comparing to any fast mixing linear policy.1 One of our algorithms is based on Online Gradient Descent (Zinkevich, 2003). The other is based on Follow the Lazy Leader (Kalai & Vempala, 2005), a variant of Follow the Perturbed Leader with only O( p T) expected number of policy switches. Overall, our approach follows Even-Dar et al. (2009). We first show how to perform online learning in an “idealized setting”, a hypothetical setting in which the learner can immediately observe the steady-state cost of any chosen control policy. We proceed to bound the gap between the idealized costs and the actual costs. Our technique is conceptually di erent to most learning problems: instead of predicting a policy and observing its steady-state cost, the learner predicts a steady-state distri- bution and derives from it a corresponding policy. Impor- tantly, this view allows us to cast the idealized problem as a semidefinite program which minimizes the expected costs as a function of a steady state distribution (of both states and controls). As the problem is now convex, we apply OGD and FLL to the SDP and argue about fast-mixing properties of its feasible solutions. 1 Technically, we define the class of “strongly stable” policies that guarantee the desired fast mixing property. Conceptually, slowly mixing policies are less attractive for implementation, given their inherent gap between their long and short term cost. 25
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}