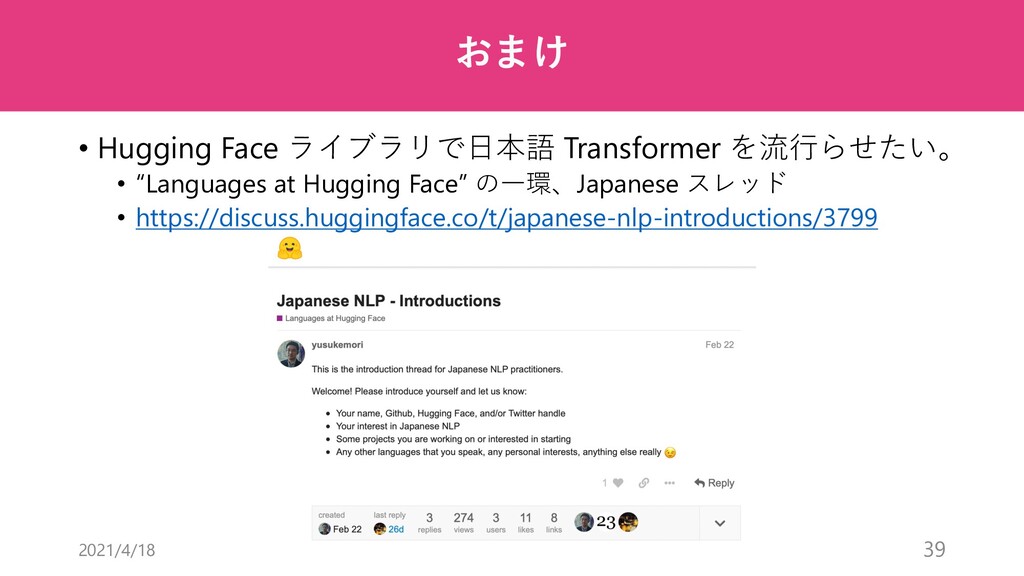
第六回 全日本コンピュータビジョン勉強会 Transformer論文読み会 にて、
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" [Dosovitskiy et al., ICLR 2021]
のご紹介をさせていただきました。
◆イベント詳細 URL:
https://kantocv.connpass.com/event/205271/
◆発表日:
2021/04/18
◆紹介論文の Open Review の URL:
https://openreview.net/forum?id=YicbFdNTTy
{kind=link}
{kind=link}
{kind=link}
![論⽂選定の理由(※主観を含みます) • Vision Transformer (ViT) を提案。Transformer [Vaswani+, 2017] を Computer](https://files.speakerdeck.com/presentations/7474ba5706bd4753a6e3dd73ee64f53d/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関連研究 (2) • ⼀番近いのは [Cordonnier+, 2020] • ⼊⼒画像を 2 x](https://files.speakerdeck.com/presentations/7474ba5706bd4753a6e3dd73ee64f53d/slide_12.jpg){kind=link}
{kind=link}
![関連研究 (4) • image GPT (iGPT) [Chen et al., 2020a]](https://files.speakerdeck.com/presentations/7474ba5706bd4753a6e3dd73ee64f53d/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}