- se scriptováním v LUA - serializuje se na disk - jednovláknový Redis umí datové struktury od jednoduchých key:value, přes seznamy a hashe po seřazené sety. Je možné mu poslat script v LUA který evalne přímo nad databázi, tedy si ušetříte hromadu komunikace. Další killer feature oproti memcache je i serializace na disk, což z něj dělá perfektního kanditáta pro session.
file storage je super, ale od určité návštěvnostni zvládá s přehledem zabíjet stránku. Journal v Nette je velice jednoduchá databáze, do které se ukládá jaké mají data v cachi tagy a priority pro mazání. Journal není tak úplně bottleneck pokud nepoužíváte tagy, ovšem pokud je používáte, tak narazíte na problémy při větší zátěži, nebo když do něj chce zapisovat hodně dat.
je to přece databáze! Redis se dá použít nejenom na cachování a sessions, ale je to i plnohodnotná databáze a tedy do ní můžete přešunout i jiné části aplikace a zefektivnit ji tím.
Největší dvě úzká hrdla jsou čištění starých session a limit počtu souborů na složku ve většine filesystémů. Obojí jde řešit, ale přoč tím ztrácet čas když máme možnost použít Redis.
se pomocí: redis: session: on Nativní storage využívá interního mechanismu v PHP na ukládání session a handleru který dodává phpredis (ten php extension). Důležité ovšem je, že tato forma ukládání session neblokuje a možná ani nikdy nebude, protože Redis sám o sobě nepodporuje zamykání.
off} Kdyby/Redis ale obsahuje i vlastní implementaci, která využívá jiný PHP mechanismus na ukládání sessions. Proč psát vlastní? Protože tato implementace dokáže session zamykat, jako standardní filesystemová. Díky tomu se nám nebudou přepisovat a ztrácet data. Obě implementace jsou kompatibilní a lze je libovolně přepínat bez strachu ze ztráty dat.
function read($key) { try { $time = microtime(TRUE); return $this->storage->read($key); } finally {$this->calls[]=microtime(TRUE)-$time;} } Večer před posobotou jsem se rozhodl změřit rozdíl rychlosti FS storage oproti Redisu abych mohl ohromit slečny v publiku a napsal jsem si vlastní storage dekorátor, kterým jsem plánoval měřit dobu strávenou v cachi.
opcache.verbosity_level=2 ; opcache.revalidate_freq=60 Opcache ve výsledku udělala brutální rozdíl pro filesytem i redis, takže pro úplnost - tohle nastavení jsem použil
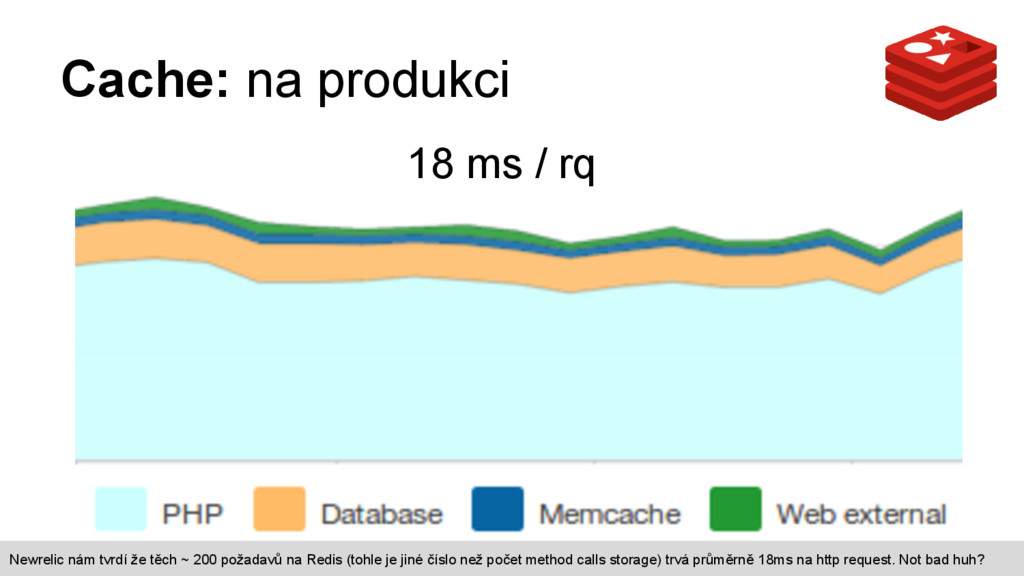
452.5 ms / 0.17 ms Obyčejný pageload 188 calls / 26.8 ms / 0.14 ms Redis První pageload 2607 calls / 776.9 ms / 0.30 ms Obyčejný pageload 188 calls / 44.4 ms / 0.23 ms První načtení stránky generovalo hromadu cache a tedy i hromadu požadavků na Redis. Ovšem toto nejsou požadavky na Redis, to jsou jednotlivá volání metod storage, celkový čas strávený jejich voláním a průměr na jeden method call.
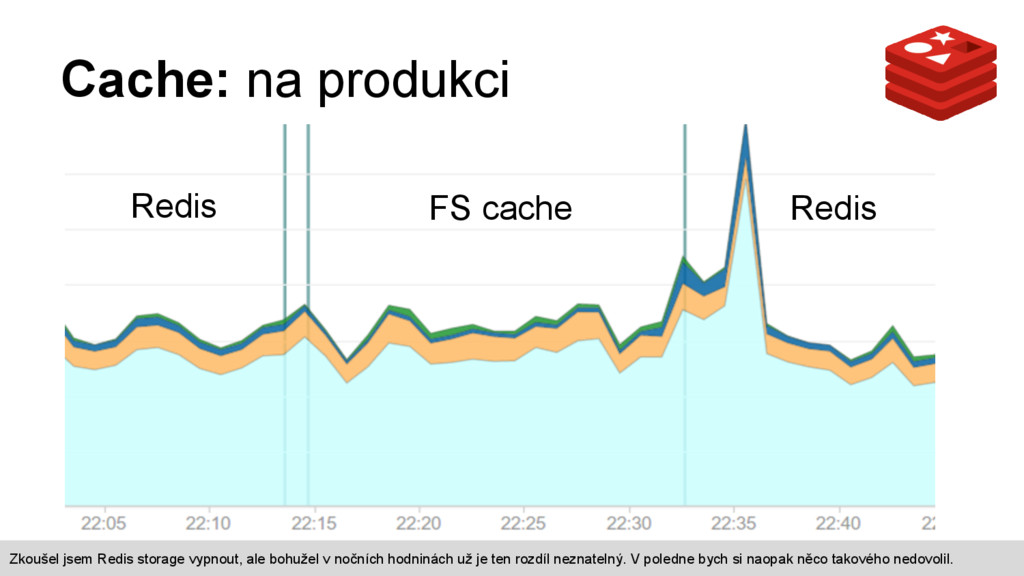
- zápis storage dělá více requestů - journál dělá více requestů Jsem stejně v šoku jako vy :) Jenže ono to není tak úplně jednoduché. Zaprvé, časy z předchozího slajdu jsou pro jeden jediný request na localhostu a tedy to není úplně vypovídající. Filesystem totiž neškáluje zdaleka tak dobře jako Redis a s nárůstem zátěže se rychlost strovná a Redis postupně získá náskok, protože ten s množstvím requestů téměř vůbec nezpomaluje a horní limit je někde kolem půl milionu GETů za vteřinu. Redis neumí zamykat a tedy musím zámky emulovat. Emulování zámků se dělá pomocí http://redis.io/commands/setnx a lepší řešení jsem ani po hodinách studia nenašel. Když se zapisuje do storage, musí se tedy nejdříve získat zámek, potom se zapíše a ještě když ukládáme nějaké tagy ke klíčům tak to dělá další requesty kvůli journalu. Strávili jsme s @matej_21 několik bezesných nocí optimalizací journalu i storage až na dřeň plošných obvodů a pokud si myslíte že to zvládnete lépe, budu strašně rád když se zapojíte.
zapíšu - uvolním zámek Zápis do cache funguje tak, že nejprve získám zámek cyklickým voláním SETNX na klíč se suffixem ‘:lock’ oproti klíči který chci zamknout. Platnost zámku jde samozřejmě nastavit na libovolný počet vteřin. Následně zapíšu data a zámek uvolním.
- zapíšu (rq ~= klíče*tagy + priorita) - uvolním zámek Do journalu se zapisuje trošku složitěji. Nejprve musíme smazat stará data pro daný klíč, tedy odmazat tagy a následně z tagů odmazat klíč, případně ještě další request na priority. Potom to samé udělám naopak, tedy spáruji jednotlivé tagy s klíčem a klíč s tagy, případně zapíšu prioritu.
journal načte do paměti - změní co potřebuje - zapíše journal Oproti tomu filejournal zamkne celý soubor ve kterém jsou všechna metadata, načte ho do paměti, pomění co potřebuje a opět zapíše. Jinak to totiž udělat ani nejde, pokud chceme mít atomický zápis. Tento způsob je samozřejmě skvělý, ale pouze do určitého počtu http požadavků.
mít pro jeden klíč víc než X tagů a pro jeden tag víc než X klíčů Bohužel tady narážíme na limity filejournalu, tedy že se skládá z jakýchsi datových bloků, do kterých se ukládají data a byť je rozumně naddimenzovaný, i tak se může stát že máte moc tagů pro nějaký klíč, nebo moc klíčů pro nějaký tag a zkrátka nebude možné data uložit. Redis journal je omezen pouze velikostí ramky.
smazat. V Redisu automaticky expiruje, jako by tam nikdy nebyl :) Další skvělá feature redis cache storage je automatická expirace klíčů na úrovni databáze. Filestorage je po sobě musí klízet když zjistí že data mají expirovat, v Redisu prostě zmizí.
(journal) - smazat tagy z klíčů (journal) - smazat klíče z tagů (journal) - vrátí seznam klíčů na smazání - smazat nalezené klíče (cache) Tohle je asi největší špek jaký jsme v celém journalu řešili. Normální filestorage a journal fungují tak, že storage dá journalu tag (případně jiné pravidlo jak cache mazat) a zeptá se jaké klíče ten tag mají a které teda má mazat. Journal to přechroustá a vrátí list klíčů. Cache následně maže data.
000 rq? 100 000 rq? 1 000 000 rq? Co byste řekli, kolik musí udělat requestů algoritmus popsaný na minulém slide? Pokud byste se nebáli tipnout i ta šílená čísla s hodně nulami nebyli byste daleko od pravdy, protože pokud máte u jednoho tagu tisíce klíčů cache, může to dát redisu pořádně pokouřit.
Ovšem s tím se odmítám spokojit! Jak jsme si řekli, Redis umí scriptovat v Lua a proto jsem napsal mazání pomocí tagů journalu jako Lua script, který se jednoduše pošle databázi s argumentem (jméno tagu, priorita), databáze evalne script a ten najde všechny klíče, promaže všechna metadata a pokud použiváte redis cache storage i journal zároveň, rovnou zkusí klíče z databáze smazat. Ušetří se tedy vracení seznamu klíčů a mazání “z venku”.
network is about 200 us, while the latency with a Unix domain socket can be as low as 30 us.” Lokální síť mezi dvěma VPS je samozřejmě brutálně rychlá a když posíláte jenom pár requestů tak ten rozdíl nejspíš nepocítíte, ale když sypete do Redisu na každý http request stovky příkazů tak už se vyplatí zamyslet se nad použitím lokálních instací redisu na cachování pro každý http server (myslím tím VPS, která je určená ke zpracování http requestů a běží na ní PHP).
vypnout serializaci cache na disk - vypnout zamykání cache pro zápis Kdyby/Redis je sice chytrý a cache i session prefixuje a tedy se nikdy nepomýchají, ale výborné je rozdělit je do dvou různých databází. Jak jsme si řekli, data v redisu se mohou dělit na databáze a tedy při deployi můžete jednoduše zavolat `redis-cli -n 0 flushdb` a smazat tak databázi s cachí a session zůstane nedotčena. Pokud to chcete povýšit, místo použití databází můžete nastartovat dvě různé instance redisu a jednu použít na session a jednu na cache. Díky tomu budete moci vypnout ukládání cache na disk a tedy zase trochu ulehčíte Redisu ve špičkách. Když jsme měli problémy s výkonem, protože jsme hodně experimentovali, zkoušeli jsme i vypnout zamykání cache pro write, ale výsledkem bylo jenom to, že se cache generovala klidně 100x dokud ji ten první request, co ji generovat začal, konečně nezapsal a tedy se výkon logicky zhoršil.
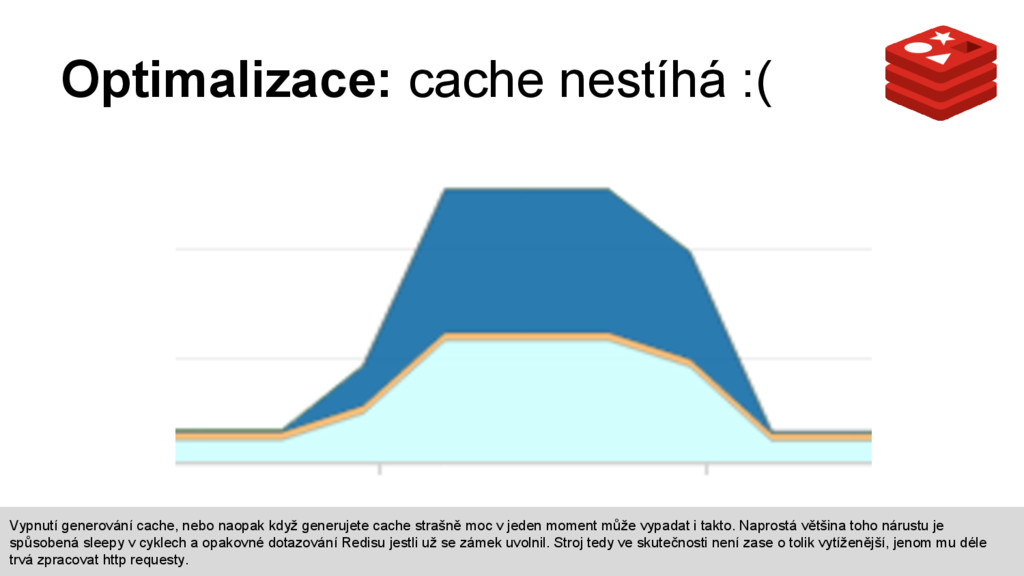
generujete cache strašně moc v jeden moment může vypadat i takto. Naprostá většina toho nárustu je spůsobená sleepy v cyklech a opakovné dotazování Redisu jestli už se zámek uvolnil. Stroj tedy ve skutečnosti není zase o tolik vytíženější, jenom mu déle trvá zpracovat http requesty.
No a když už vám návštěvnost naroste takovým způsobem že už nic nepomáhá a komunikace s Redisem se ukáže jako úzké hrdlo, je na řadě zvážit sharding. Protože jak jsme si řekli na začátku, Redis je jednovláknový a tedy tím že nastartujete více instancí (třeb 16, nebo klidně 64) získáte více vláken :)
na shardování Redisu je twemproxy od Twitteru, jenže ta je navržená tak, že by asi úplně dobře nefungovala při invalidaci cache pomocí našeho LUA scriptu, tedy tu bohužel nemůžu pro kombinaci s Kdyby/Redis doporučit. Ale nenechám vás na holičkách, mám napsané vlastní klientské shardování. Zatím ovšem není v masteru, ale v samostatné větvi a budu rád když ji se mnou zkusíte otestovat, ale opatrně! :)
byla klidně ještě o polovinu pomalejší, pořád se ve 100% případů vyplatí použít pro session. A pokud tagujete cache tak v ten moment se journal a cache vyplatí i vám.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}