Rychlé představení dalšího způsobu jak pracovat s daty, který vám umožňuje snadněji řešit invalidaci cache, která se velice snadno stane opravdu komplexní.
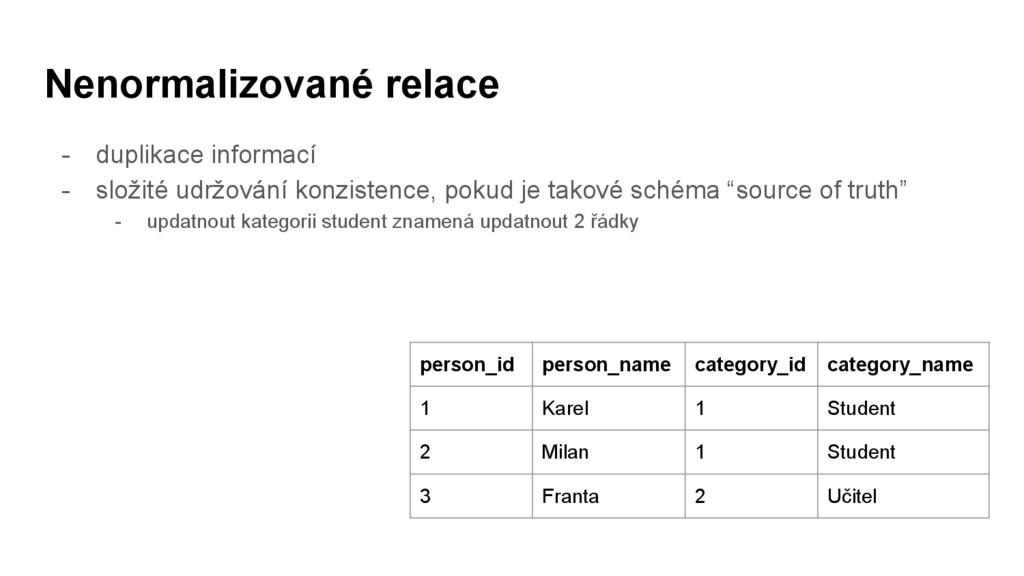
je takové schéma “source of truth” - updatnout kategorii student znamená updatnout 2 řádky person_id person_name category_id category_name 1 Karel 1 Student 2 Milan 1 Student 3 Franta 2 Učitel
- snadné editace/mazání a úpravy schématu - 3NF je perfektní na ukládání relačních dat Ale... - u složitých relací s hodně JOINy mají db problém - problém se zhoršuje s narůstajícím množstvím dat - nejde vyřešit výměnou db (MySQL vs PostgreSQL) - ORM lazy loading id name 1 Karel 2 Milan 3 Franta id name 1 Student 2 Učitel person_id category_id 1 1 2 1 3 2
triggery - plnění z modelu, při změně dat - cronjob / rabbitmq worker - materializovaný pohled - o synchronizaci se stará databáze - úplně jiná databáze - například ElasticSearch - plnění z modelu, při změně dat - cronjob / rabbitmq worker
~15 vteřin - personalizace => nemožnost použít cache - přenesením logiky filtrování jsme se dostali pod ~4 vteřiny - ES data vyfiltroval a vrátil list IDček - o hydrataci z MySQL se starala Doctrine - zahozením hydratace produktů jsme se dostali na ~1 vteřinu - z ES se získávaly celé dokumenty - ty se obalily do Value Objectů bez mapování properties - stejné rozhranní - bez nutnosti měnit šablony - stále otřesně pomalé, ale už né kvůli výpisu produktů
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}