penyimpanan data yang sederhana (key-value, document) dan mampu mendukung scaling. NoSQL June 5, 2015 5 Referensi: http://www.couchbase.com/binaries/content/gallery/website/figures/why-nosql- 5.png
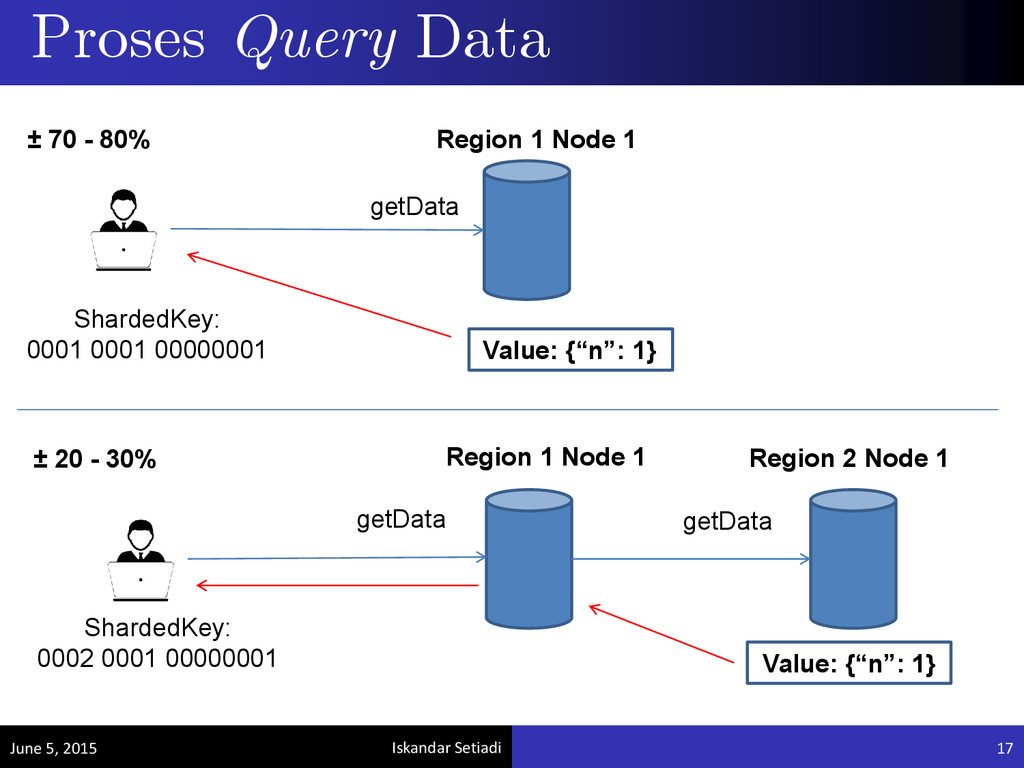
akhir ini bertujuan untuk meminimalkan jarak data yang disimpan dalam server dengan pengguna. Prototipe ini menggunakan asumsi probabilistik bahwa pengguna yang mengakses (read) data adalah pengguna yang terletak dekat dengan pengguna yang menulis data pertama kali. Prototipe: TippyDB June 5, 2015 7
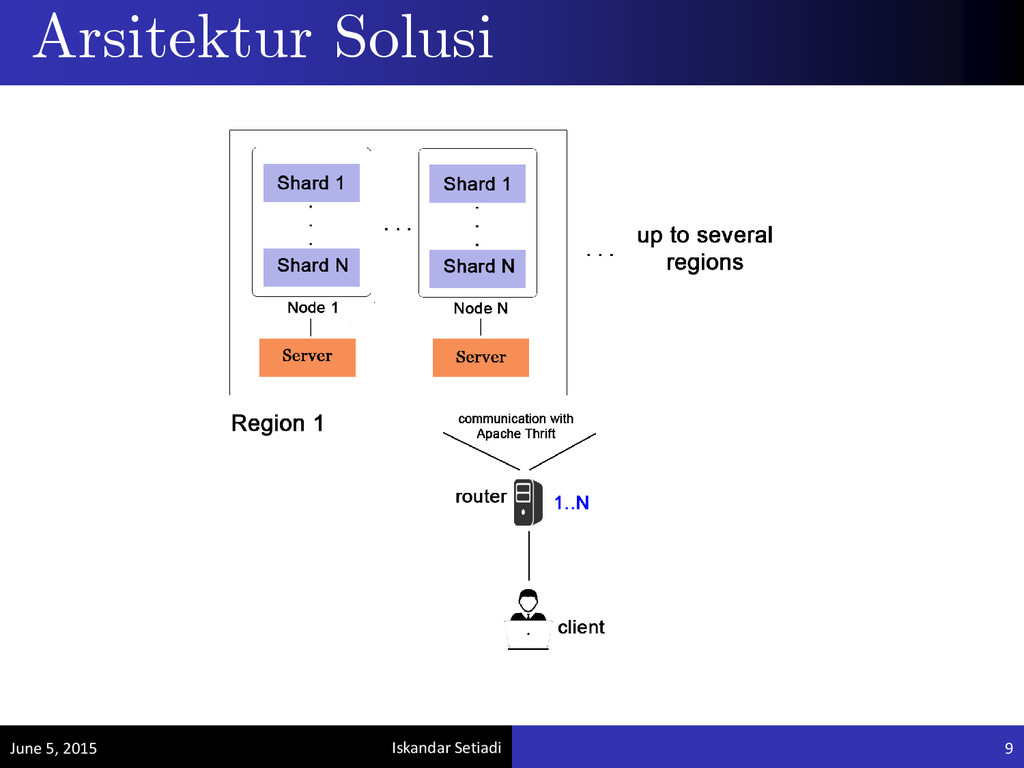
delete Partisi dengan ukuran shard statik yang terdefinisi Replikasi dalam beberapa region dengan konfigurasi statik yang terdefinisi Pengembangan dilakukan dengan memanfaatkan levelDB (key-value library) dan Apache Thrift (RPC library) Fitur & Batasan June 5, 2015 8
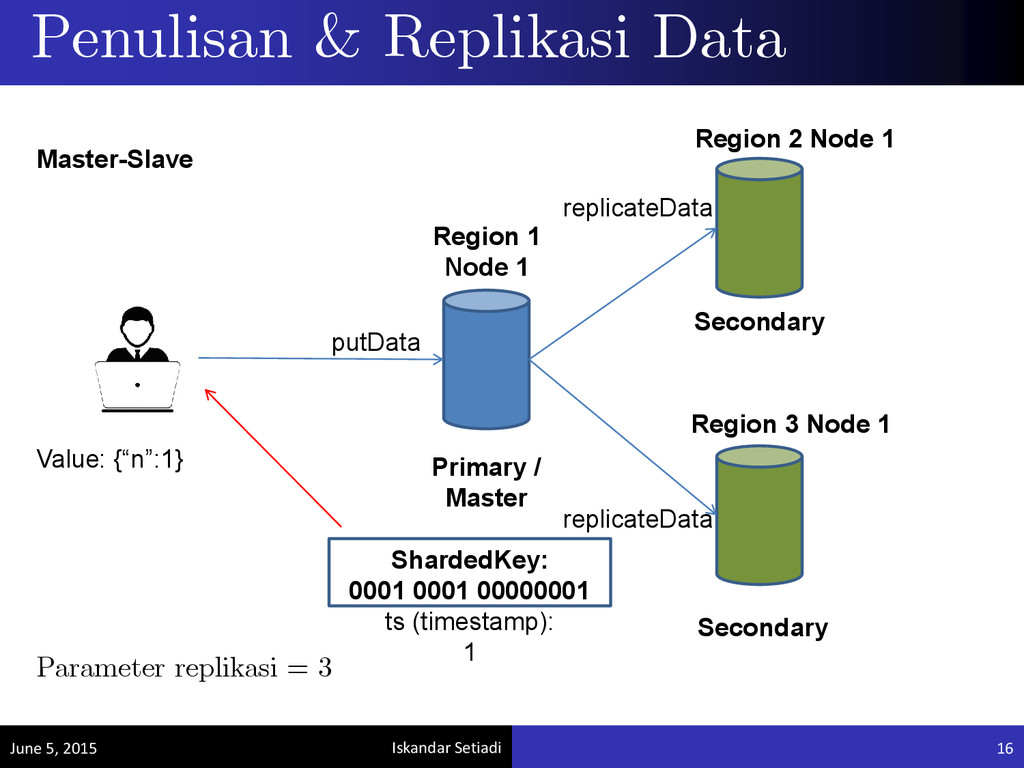
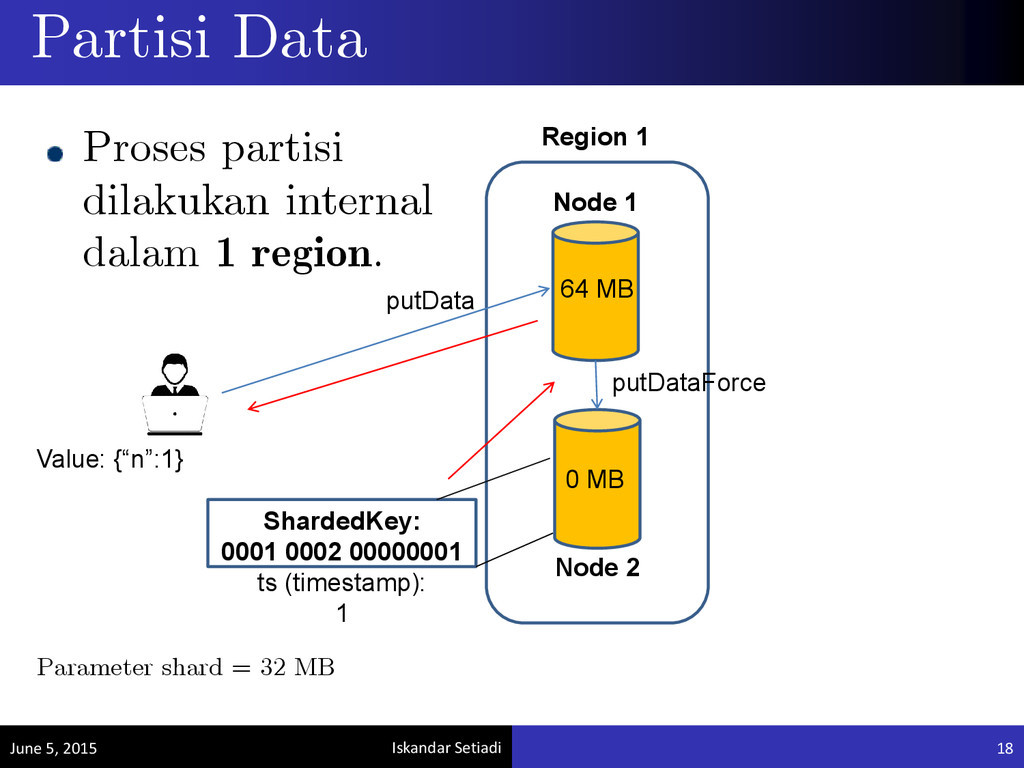
region tempat data tersebut ditulis 4 byte selanjutnya merepresentasikan node tempat data tersebut ditulis 8 byte terakhir merepresentasikan kunci unik yang dimiliki oleh data tersebut Penyimpanan Berbasis Key-Value June 5, 2015 10
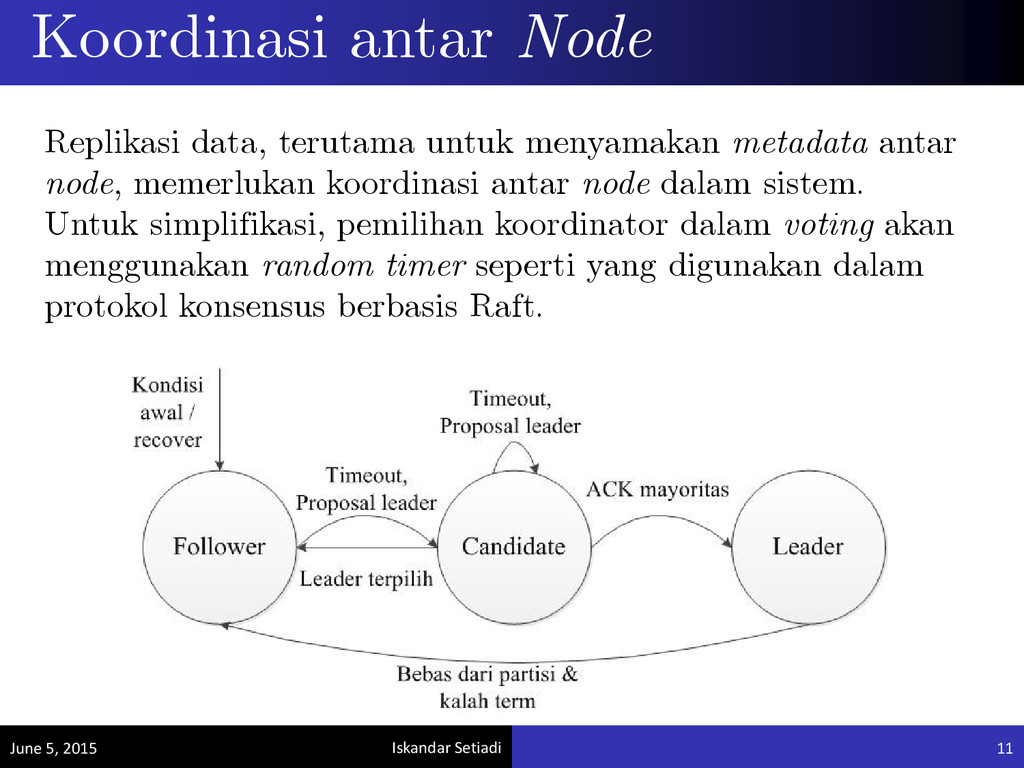
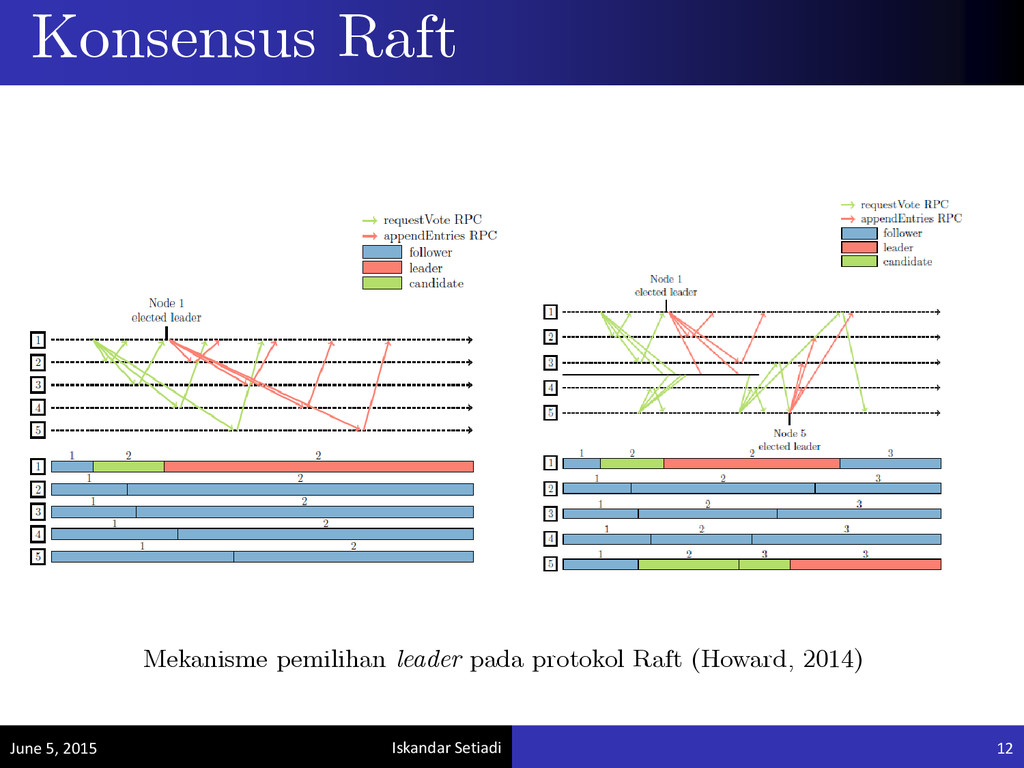
memerlukan koordinasi antar node dalam sistem. Untuk simplifikasi, pemilihan koordinator dalam voting akan menggunakan random timer seperti yang digunakan dalam protokol konsensus berbasis Raft. Koordinasi antar Node June 5, 2015 11
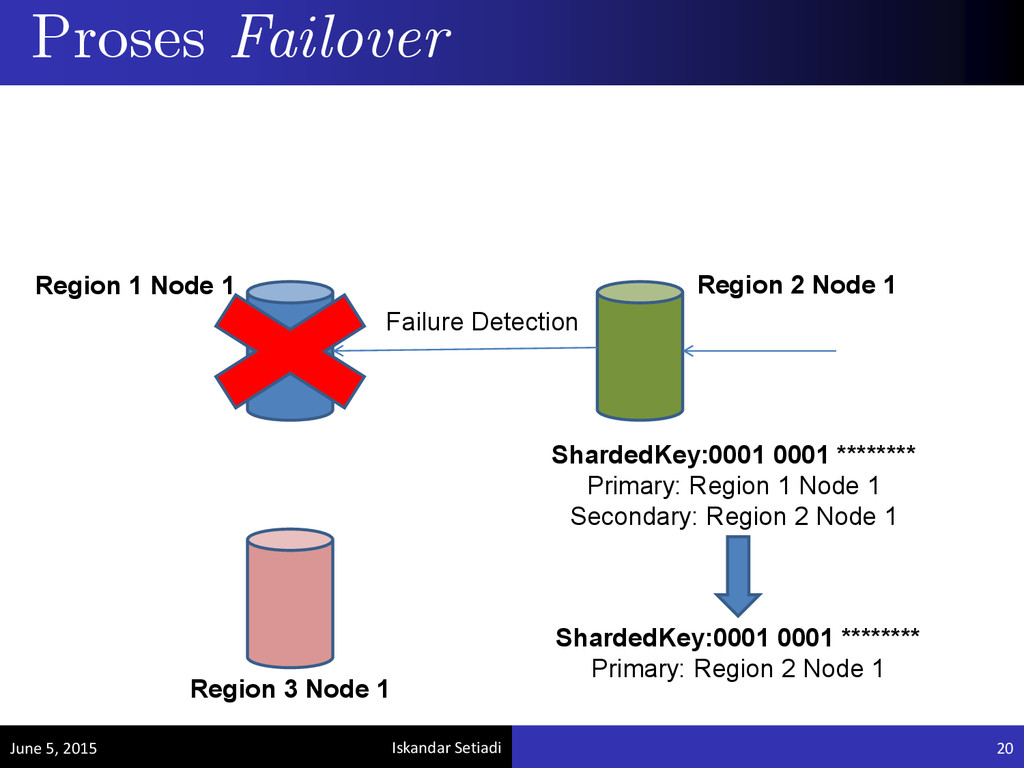
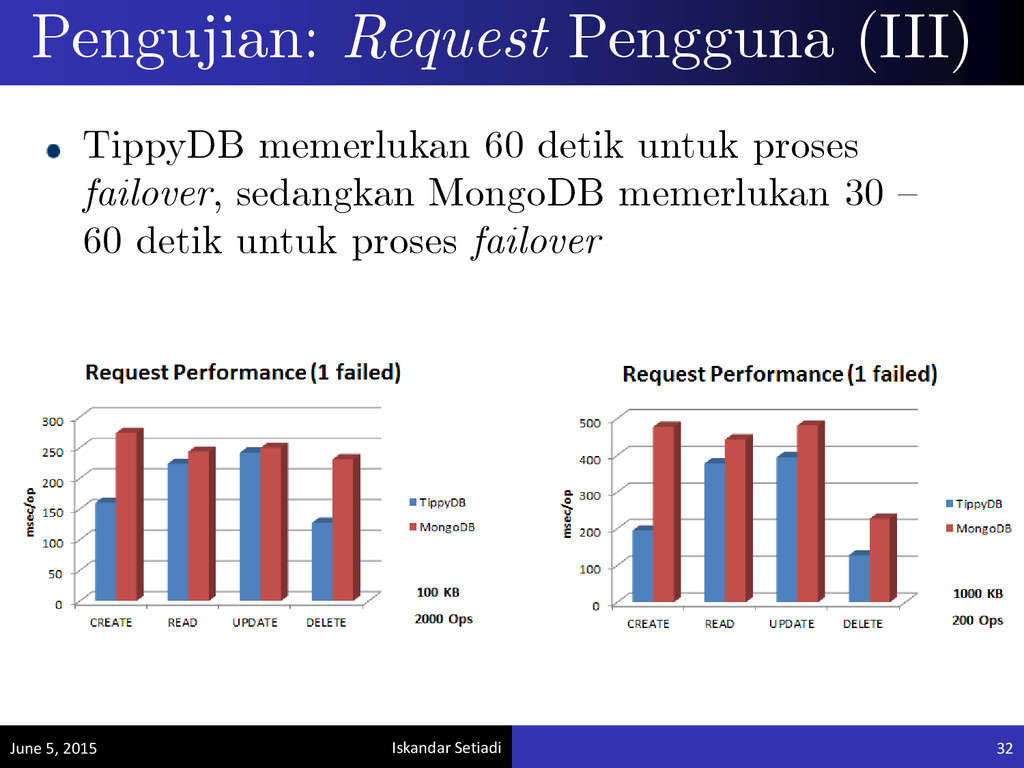
failover secara otomatis untuk penyimpanan data yang menggunakan faktor geografis. Permasalahan: Desain sistem yang tidak dapat mendukung proses failover secara otomatis. Permasalahan Failover June 5, 2015 19
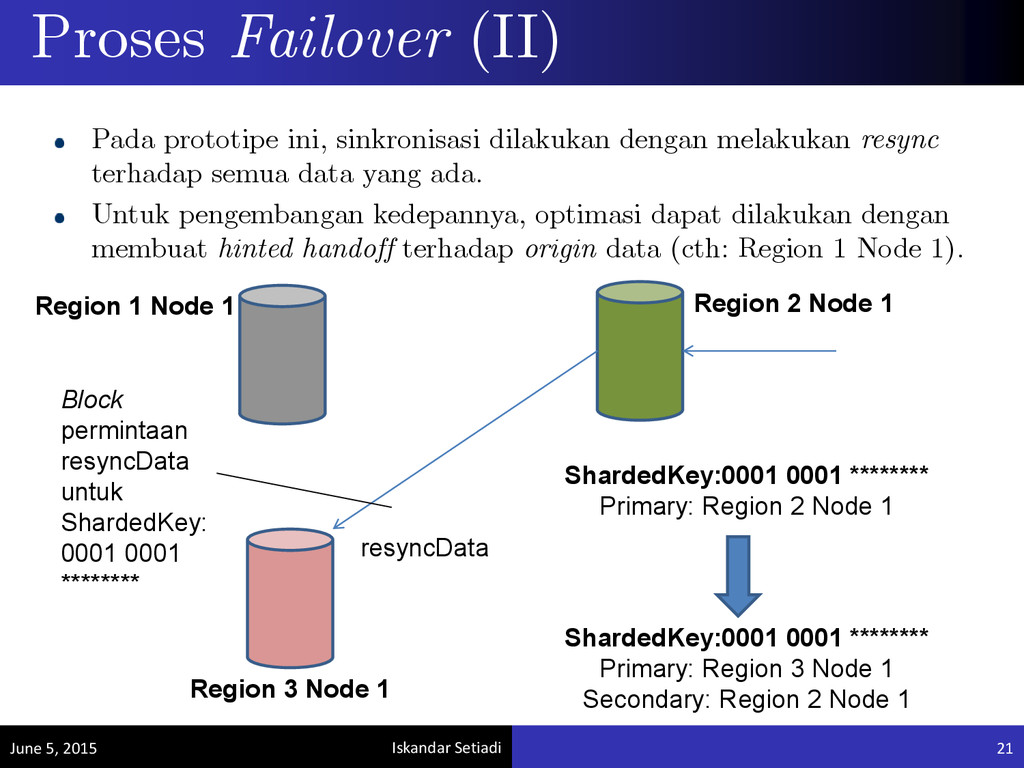
2 Node 1 Region 3 Node 1 ShardedKey:0001 0001 ******** Primary: Region 3 Node 1 Secondary: Region 2 Node 1 ShardedKey:0001 0001 ******** Primary: Region 2 Node 1 resyncData Pada prototipe ini, sinkronisasi dilakukan dengan melakukan resync terhadap semua data yang ada. Untuk pengembangan kedepannya, optimasi dapat dilakukan dengan membuat hinted handoff terhadap origin data (cth: Region 1 Node 1). Region 1 Node 1 Block permintaan resyncData untuk ShardedKey: 0001 0001 ********
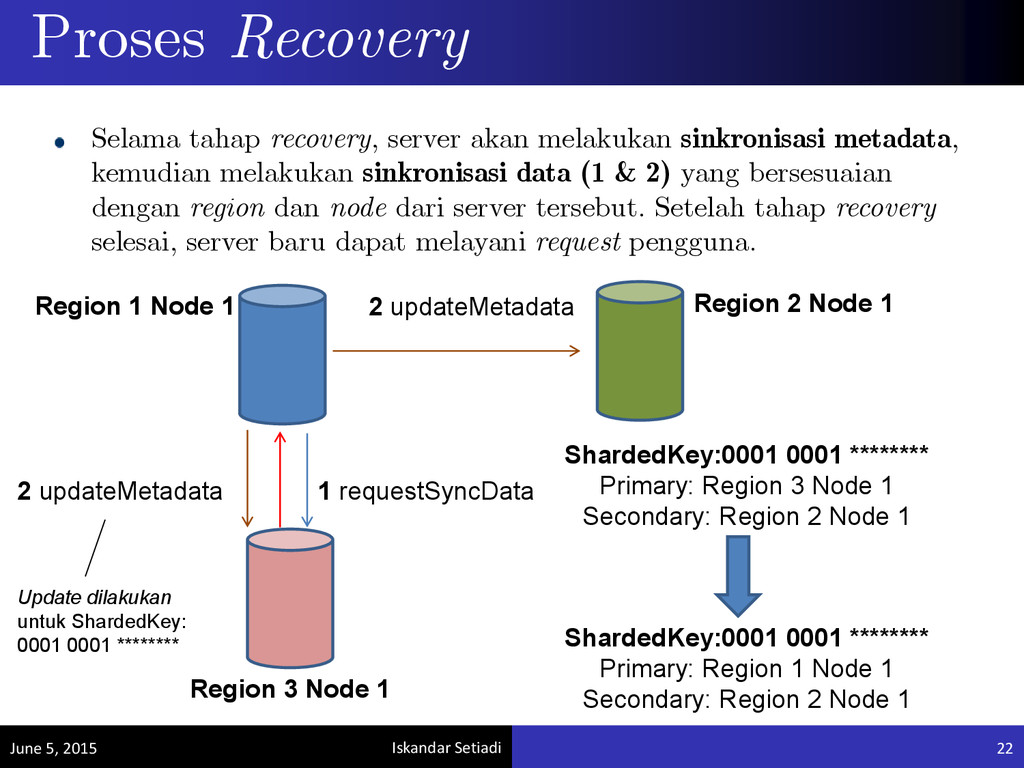
Node 1 Region 3 Node 1 ShardedKey:0001 0001 ******** Primary: Region 1 Node 1 Secondary: Region 2 Node 1 1 requestSyncData Region 1 Node 1 ShardedKey:0001 0001 ******** Primary: Region 3 Node 1 Secondary: Region 2 Node 1 Selama tahap recovery, server akan melakukan sinkronisasi metadata, kemudian melakukan sinkronisasi data (1 & 2) yang bersesuaian dengan region dan node dari server tersebut. Setelah tahap recovery selesai, server baru dapat melayani request pengguna. 2 updateMetadata 2 updateMetadata Update dilakukan untuk ShardedKey: 0001 0001 ********
(EC2) yang telah dikonfigurasi pada dua instance t2.micro di dua access point berbeda, yaitu US East (N. Virginia): 1 replica dan Asia Pacific (Singapore): 2 replicas, dengan spesifikasi sebagai berikut: - Processor Intel® Xeon E5-2670 CPU @ 2.50 GHz (1 vCPU) - Memory 1 GiB RAM Implementasi June 5, 2015 23
g++ versi 4.7.2 (dengan dukungan C++11) Python versi 2.7 Boost library versi 1.54 Apache Thrift versi 0.9.2 LevelDB versi 1.15.0 MongoDB versi 3.0.1 & PyMongo versi 3.0 (untuk benchmark) Git versi 1.7.10.4 https://github.com/freedomofkeima/TippyDB Implementasi (II) June 5, 2015 24
dalam 3 bagian utama: - Pengujian dilakukan untuk menjamin safety dan liveness dari komunikasi antar server (T-SS-XXX) - Pengujian dilakukan untuk menjamin kebenaran dari komunikasi antara client dengan server (T- CS-XXX) - Pengujian dilakukan untuk menjamin kebenaran internal dari server, mencakup komunikasi antara Apache Thrift dengan LevelDB (T-IS-XXX) Pengujian: Correctness June 5, 2015 25
data di secondary node T-SS-004: Penghapusan data di secondary node T-SS-005: Pembaharuan metadata dalam sistem T-SS-006: Pemilihan koordinator baru T-SS-007: Proses failover untuk kegagalan node T-SS-008: Proses recovery untuk node yang gagal Pengujian T-SS-XXX June 5, 2015 26
data T-CS-004: Penghapusan data T-IS-001: Pembaharuan informasi ukuran basis data T-IS-002: Pembaharuan counter logical clock Pengujian T-CS-XXX & T-IS-XXX June 5, 2015 27
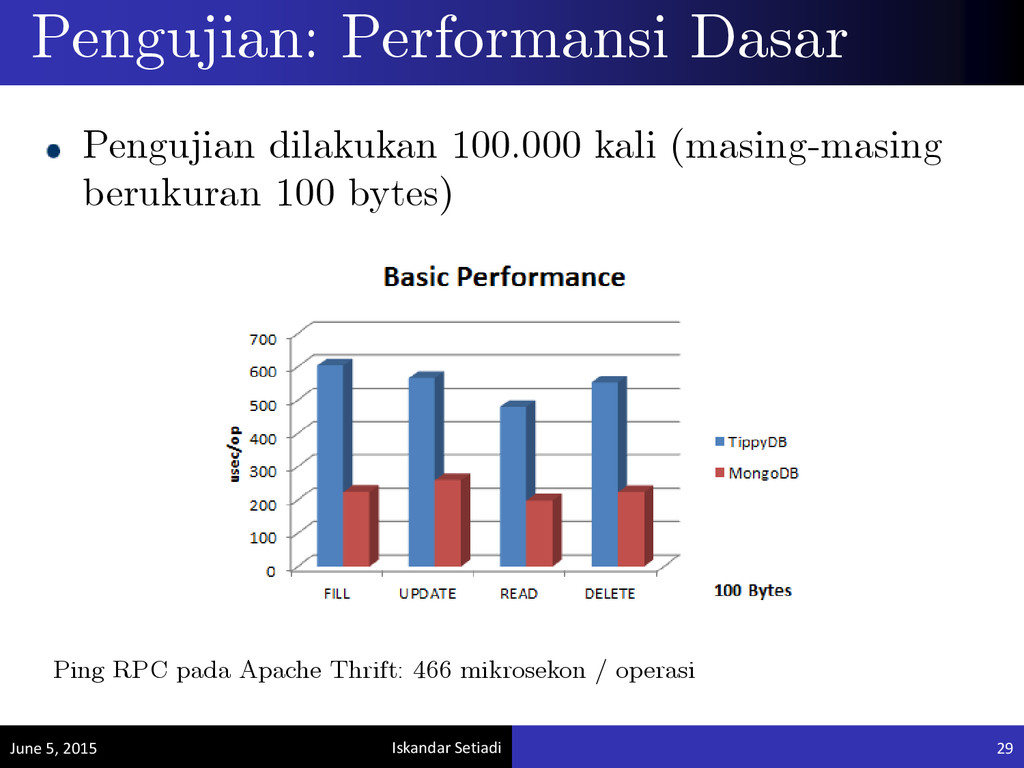
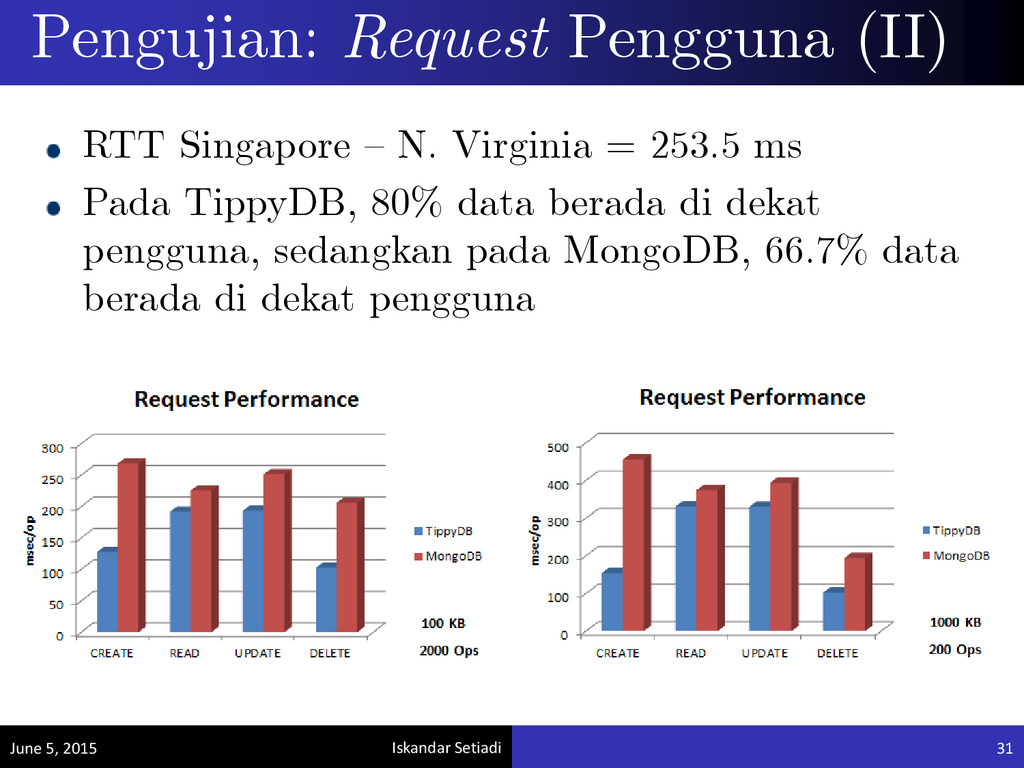
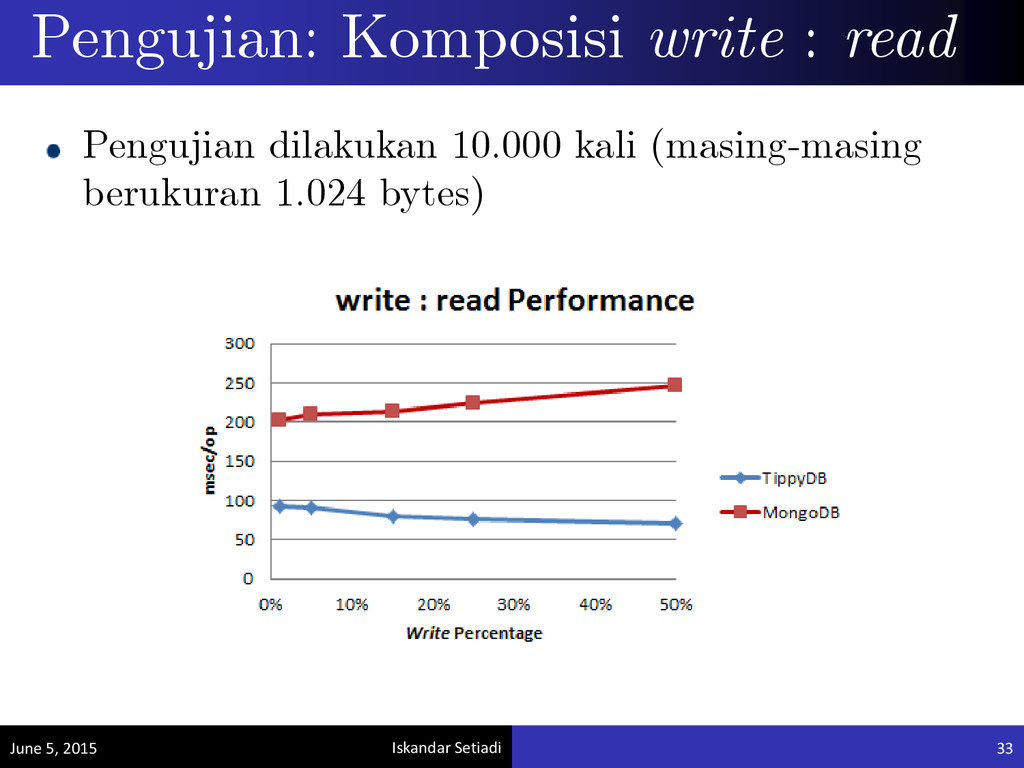
Eksperimen dilakukan 4 kali, dengan spesifikasi masing-masing eksperimen sebagai berikut: - 2.000 operasi (@ 100 KB), 3 replika - 200 operasi (@ 1.000 KB), 3 replika - 2.000 operasi (@ 100 KB), 2 replika: 1 replika di access point Singapore mengalami kegagalan - 200 operasi (@ 1.000 KB), 2 replika: 1 replika di access point Singapore mengalami kegagalan • 80% data ditulis di dekat lokasi pengguna
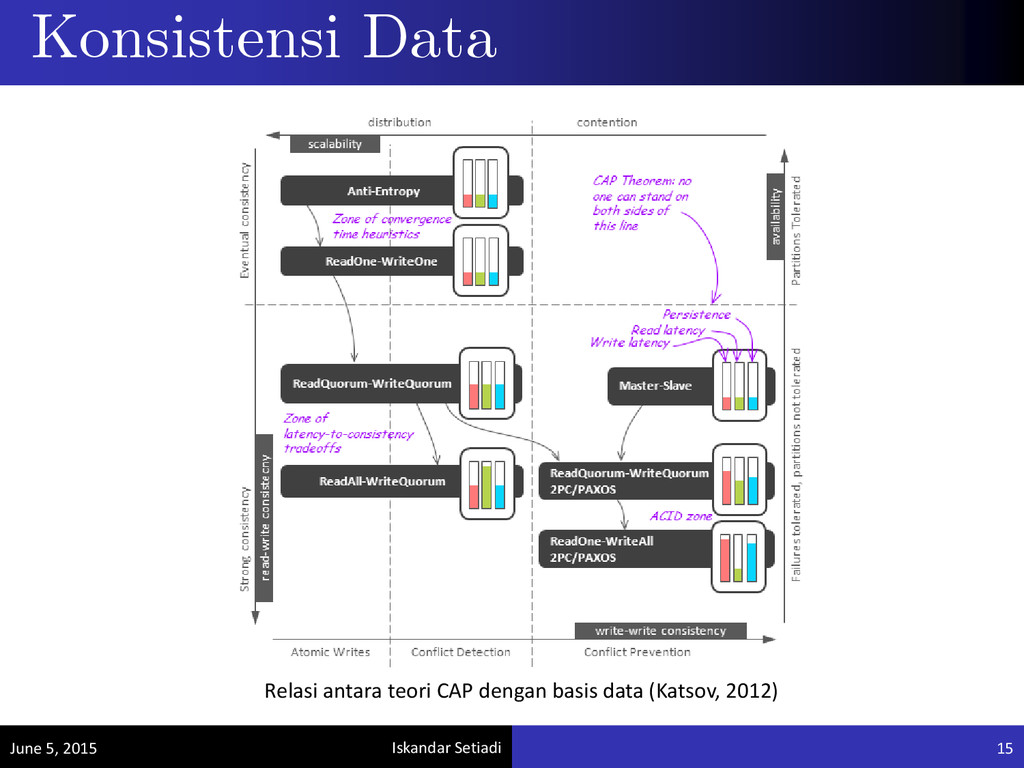
penyimpanan data yang terpartisi maupun tereplikasi. Basis data NoSQL yang membutuhkan cukup banyak operasi penulisan (write) dapat dikembangkan dengan memperhatikan aspek lokasi pengguna. Hal ini dapat mengurangi latensi RTT rata-rata dari pengguna 50 - 100 ms.
algoritma dan struktur data (Merkle Tree maupun B-tree) 2. Pengujian overhead maksimal disertai dengan pengembangan untuk metode balancing ke node kedua terdekat 3. Proses failover dengan scheduling terjadwal 4. Penambahan fitur seperti indexing, optimasi penyimpanan data, dan keamanan data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}