Iria Gayo • Procedimientos del Taller de Investigación de Estudiantes asociados con RANLP-2011, págs. 73-78 Hissar, Bulgaria, 13 de Septiembre del 2011.
Sin embargo, al menos para el idioma inglés, esta opción trae algunas consecuencias. – La precisión disminuye significativamente con datos fuera del dominio. Particularmente para analísis de preguntas. • En Español no hay datos que comparen la precisión de los parsers generales con los parsers de de preguntas. – Se procede a comparar los estudios que miden el rendimiento de los parsers de preguntas con el rendimiento de los parsers generales.
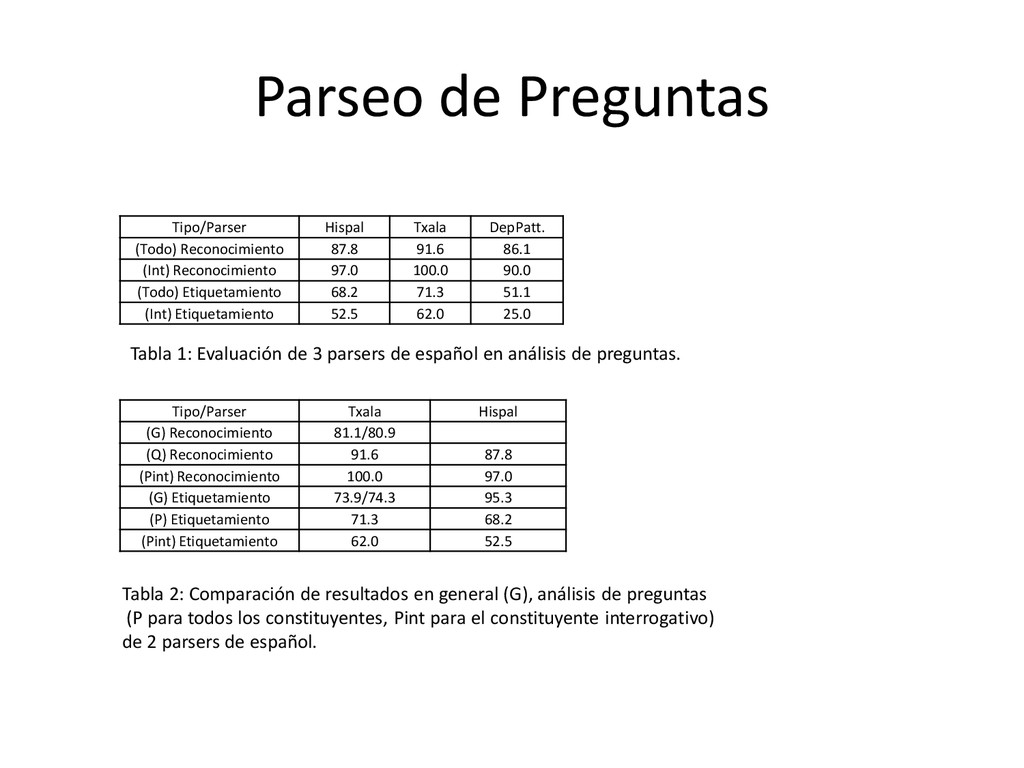
Reconocimiento 91.6 87.8 (Pint) Reconocimiento 100.0 97.0 (G) Etiquetamiento 73.9/74.3 95.3 (P) Etiquetamiento 71.3 68.2 (Pint) Etiquetamiento 62.0 52.5 Tipo/Parser Hispal Txala DepPatt. (Todo) Reconocimiento 87.8 91.6 86.1 (Int) Reconocimiento 97.0 100.0 90.0 (Todo) Etiquetamiento 68.2 71.3 51.1 (Int) Etiquetamiento 52.5 62.0 25.0 Tabla 1: Evaluación de 3 parsers de español en análisis de preguntas. Tabla 2: Comparación de resultados en general (G), análisis de preguntas (P para todos los constituyentes, Pint para el constituyente interrogativo) de 2 parsers de español.
en español bajo un contexto QA. • Su objetivo es obtener tanta información lingüística como sea posible de preguntas. – Interés en información sintáctica y semántica .
Vinci en 1492? • Reconoce y etiqueta todo los constituyentes sintácticos, y muestra las relaciones de dependencia entre ellas. • Identifica el objetivo sintáctico y semántico de la pregunta • Reconoce y especifica estructuras como fechas, cantidades y pronombres propios. [[PN3: Leonardo Da Vinci ] <SUBJ [ V:dibujar<qtOBJ [ENTITY] <DATEen 1492 ]] • Identifica seis diferentes objetivos semánticos: – Persona, Entidad, Cantidad, Tiempo, Lugar y Modo • Busca cubrir todos los tipos de estructuras interrogativas directas.
datos y método de evaluación presentados anteriormente. A su vez se comparan los resultados con los tres parsers mencionados anteriormente. • Como métrica se aplica PARSEVAL a dos variables en análisis de preguntas: reconocimiento y etiquetamiento de constituyente. • Para cada variable se miden: – Precisión – Exhaustividad – Puntaje F1
preguntas extraídas de CLEF 2004, 2005 y 2007. • Todas las preguntas son de tipo informativa (correspondiente a wh- en inglés) • Las preguntas seleccionadas fueron acorde a su estructura sintáctica. – Se busca obtener una gran variedad de estructuras sintácticas, como diferentes constituyentes interrogativos,.
corpus a evaluar analizado manualmente por una sola persona. • Su análisis consiste en identificar la estructura sintáctica principal: verbos y argumentos, etiquetados con su función sintáctica. ¿Qué robaba el oso Yogui? 3 constituyentes: Verbo: robaba Objeto directo interrogativo: Qué Sujeto: el oso Yogui • El análisis sintético es simplificado, – Solo se consideran seis etiquetas sintácticas: Sujeto (S), objeto directo (O), objeto indirecto (IO), predicativo (PR), complemente circunstancial (CC) y modificador (MOD) – Frases verbales son tratados como un solo constituyente: ha sido premiado
constituyentes de preguntas en general. • Posteriormente los resultados relacionados con los constituyentes interrogativos. (reconocimiento y etiquetamiento para ambos) • Su análisis consiste en identificar la estructura sintáctica principal: verbos y argumentos, etiquetados con su función sintáctica. ¿Qué robaba el oso Yogui? 3 constituyentes: Verbo: robaba Objeto directo interrogativo: Qué Sujeto: el oso Yogui • El análisis sintético es simplificado, – Solo se consideran seis etiquetas sintácticas: Sujeto (S), objeto directo (O), objeto indirecto (IO), predicativo (PR), complemente circunstancial (CC) y modificador (MOD) – Frases verbales son tratados como un solo constituyente: ha sido premiado
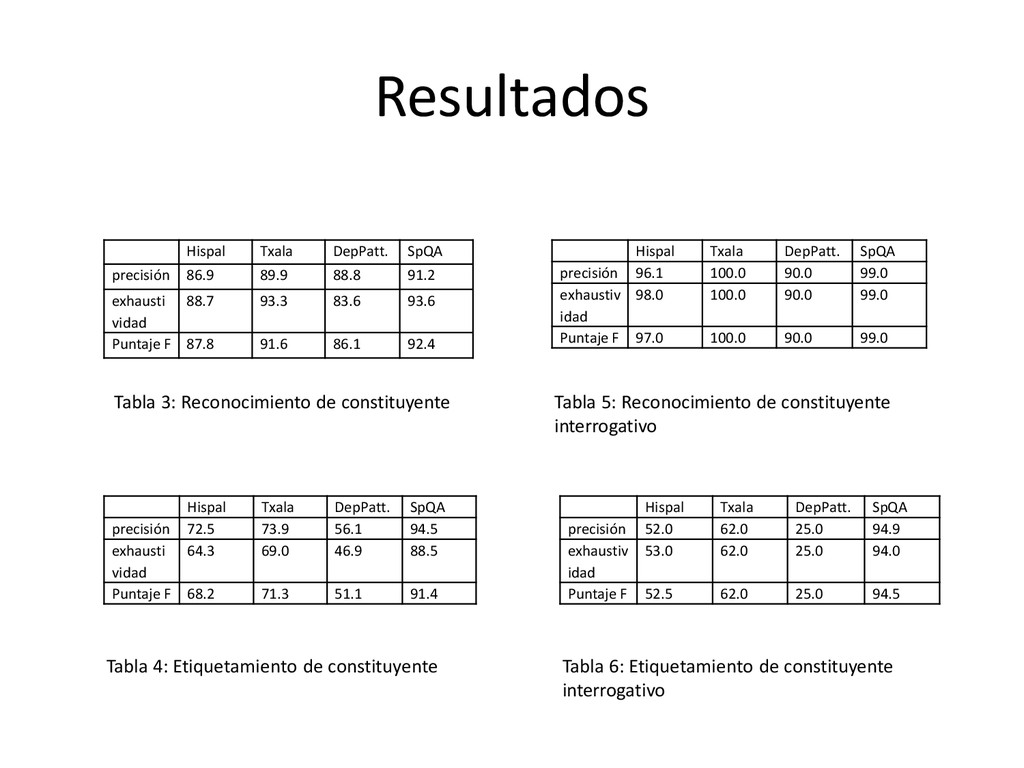
para los sistemas de QA. Para su procesamiento, el análisis sintáctico juega un papel importante. • Se presentó la herramienta SpQA, el cual actualmente reconoce y etiqueta todos los constituyentes de las preguntas. • Comparado con los otros parser disponibles gratuitamente: Hispal, Txala y DepPattern, SpQA muestra mejores resultados para reconocimiento y etiquetamiento de constituyentes y constituyentes interrogativos. • El trabajo futuro consiste en los aspectos semánticos y sintácticos de SpQA. Principalmente se debe ampliar la gramática de manera de cubrir todas las estructuras de las preguntas en español.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}