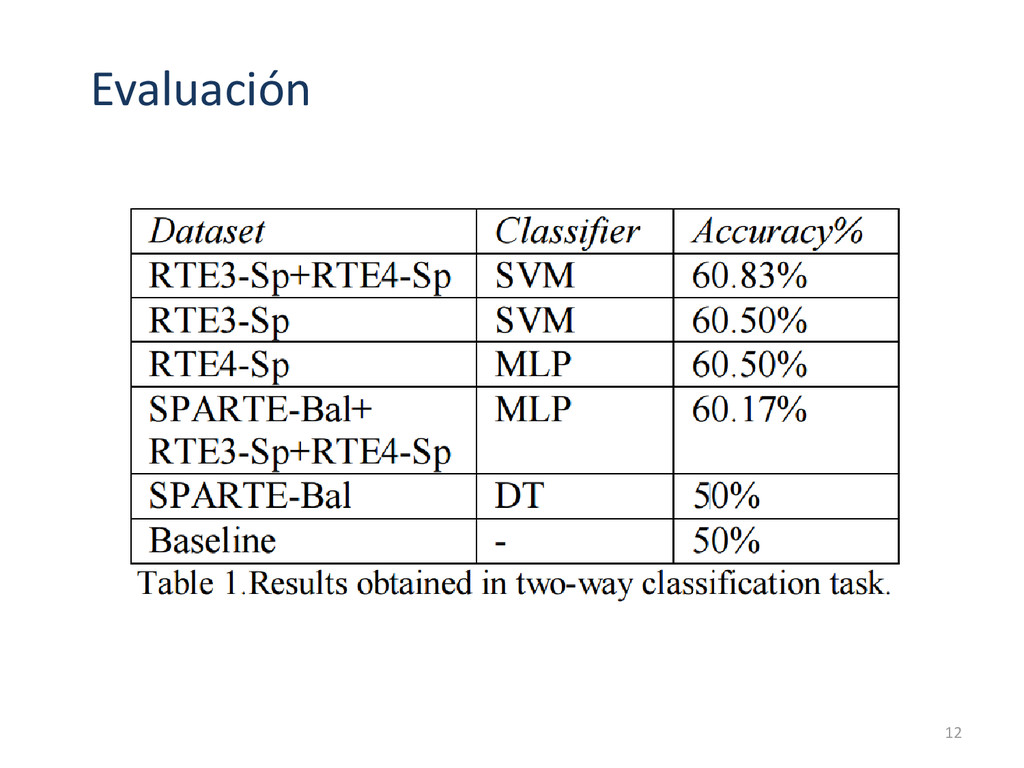
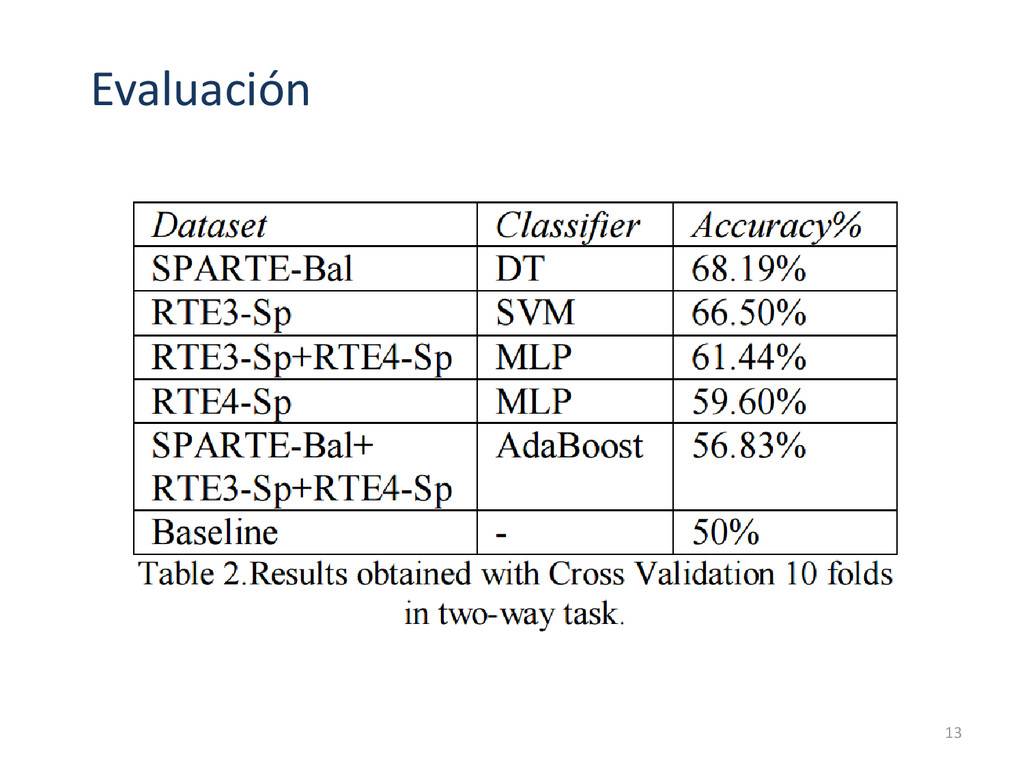
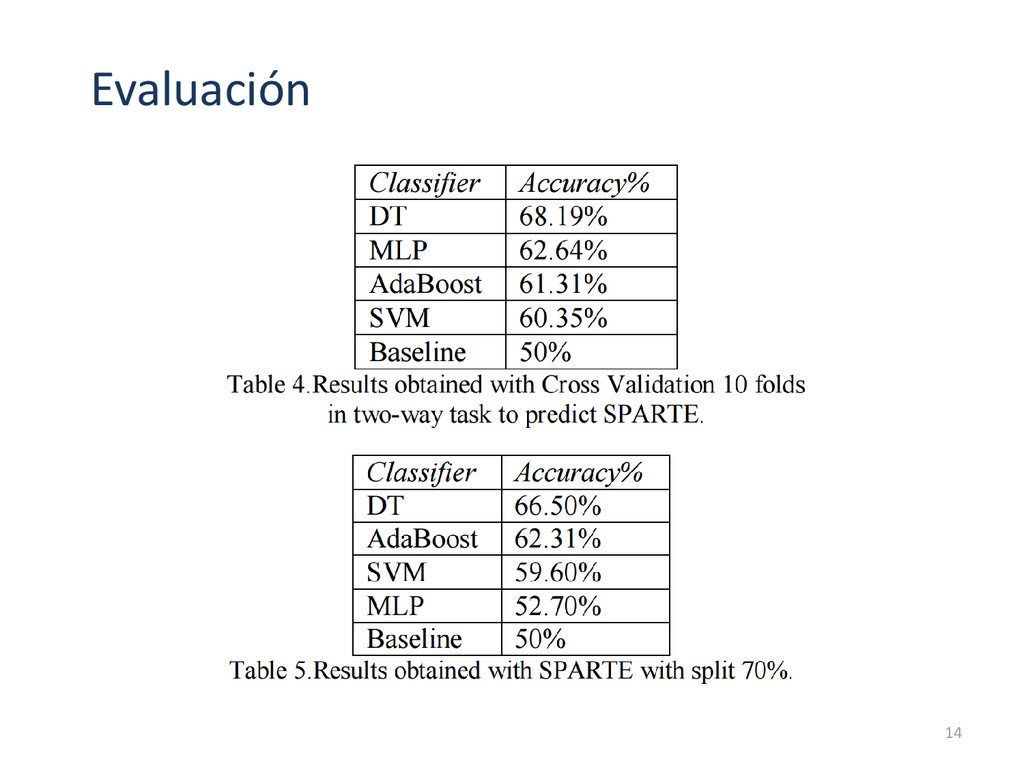
SPARTE. SPARTE fue construido durante los años 2003-2005 para evaluar los sistemas QA. RTE3, RTE4, RTE5 fueron traducidos al español mediante un traductor en línea. Se generan distintos conjuntos de datos: RTE3-Sp+RTE4-Sp SPARTE-Bal + RTE3-Sp+RTE4-Sp RTE5-Sp fue usado como conjunto de prueba. 4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}