se realizo manualmente usando Yellow Bridge, un sitio web que sirve como guía de la cultura y lenguaje chino para hablantes del ingles. Posee una lista de palabras clasificadas por su categoría gramatical, tales como verbos, sustantivos, numerales, conjunciones, etc. Para cada categoría cada palabra tiene su traducción al ingles, información que fue añadida al diccionario. Con este proceso se agrego cientos de numerales, pronombres, conjunciones, adjetivos, 3000 sustantivos y 2000 verbos. 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
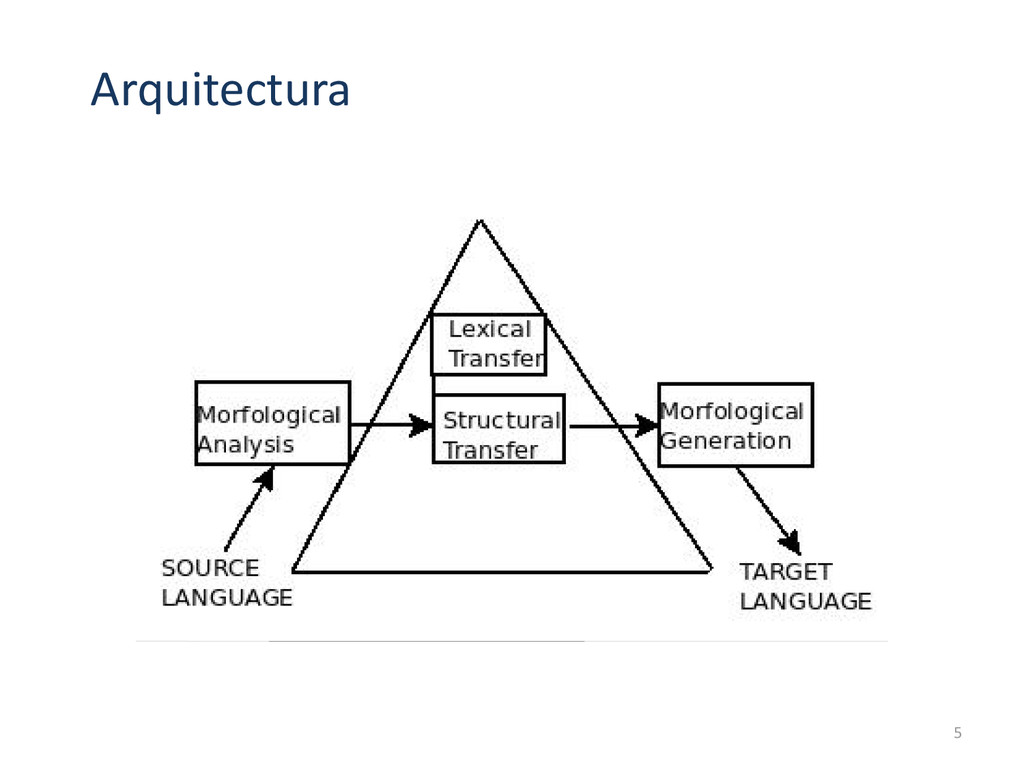{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
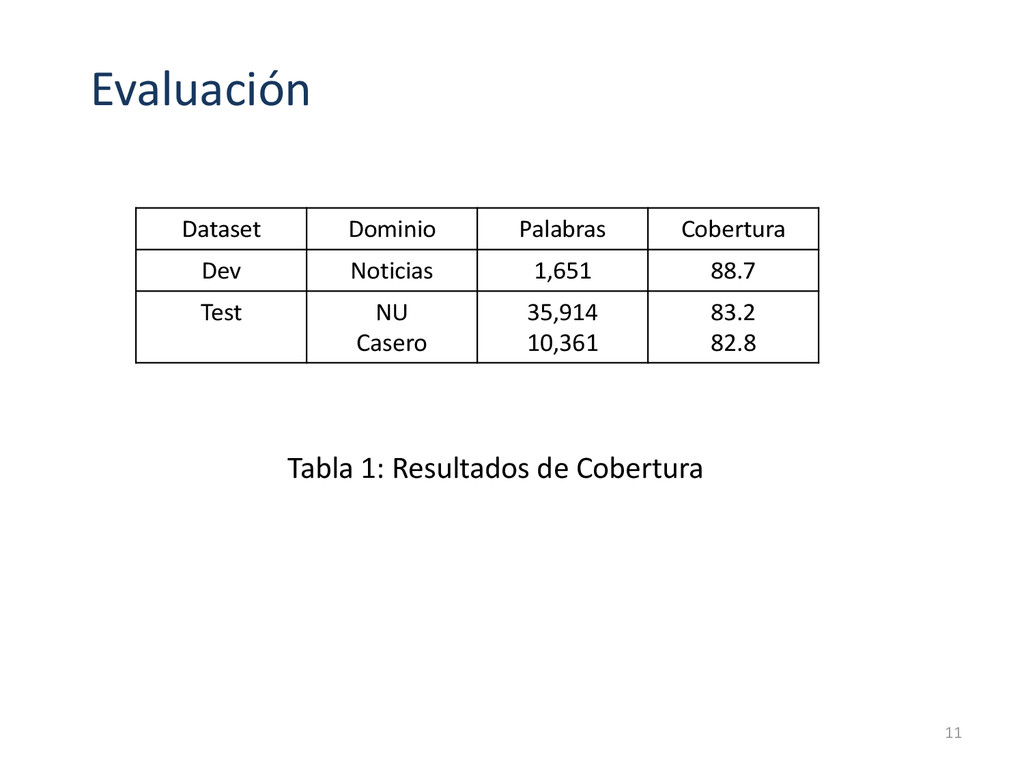{kind=link}
{kind=link}