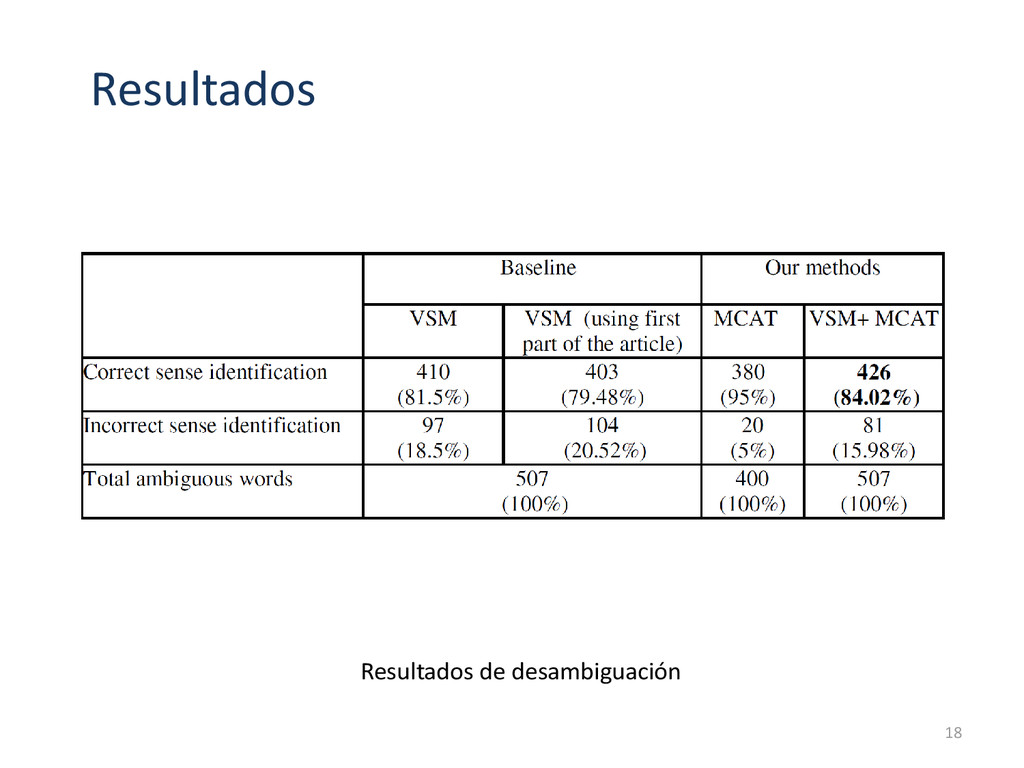
en español, ingles y japonés. Fueron extraídos en abril de 2006. La versión de WordNet utilizada es 2.1 Los datos de Wikipedia contienen un total de 377.621 artículos en japonés 2.749.310 en ingles y 194.708 en español. Se obtuvo un total de 25,379 palabras alineadas en los 3 idiomas. En WorNet hay 117,097 palabras y 141,274 sentidos. 78,247 tipos de palabras existen en WordNet, 14,614 corresponden a artículos polisémicos. El experimento se realizó usando 12,906 artículos de Wikipedia. Los resultados se muestran en la Tabla 1. 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}