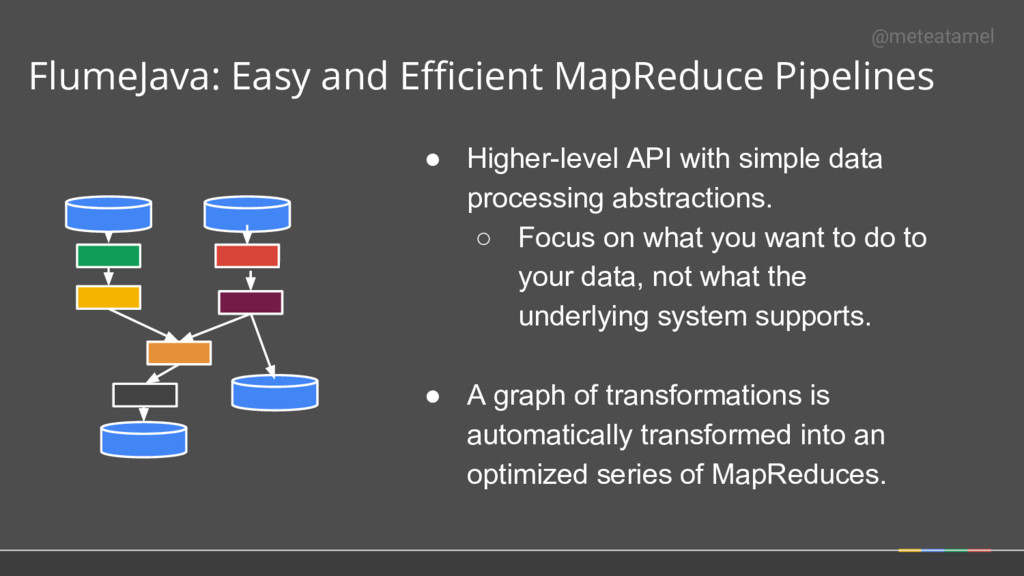
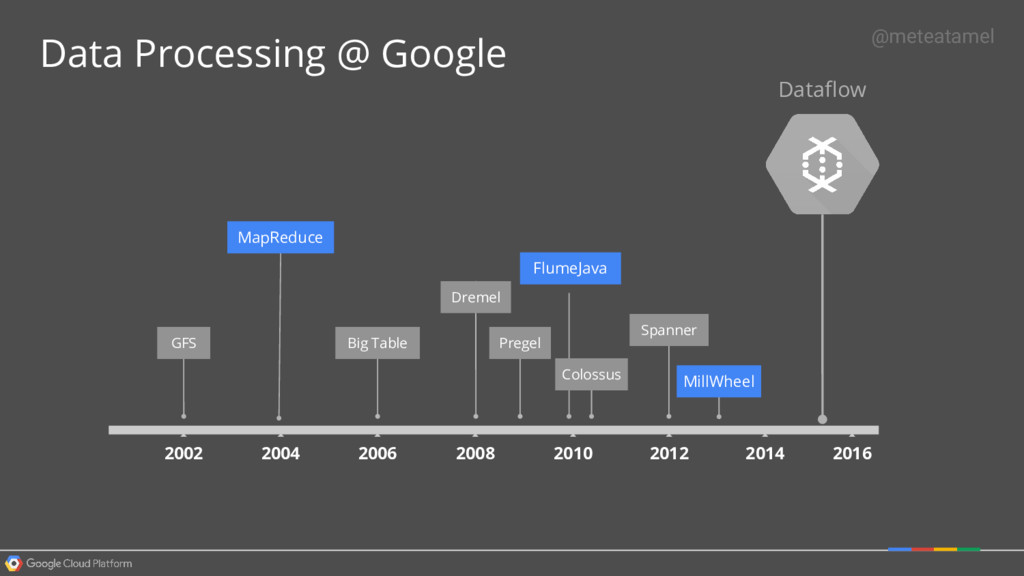
simple data processing abstractions. ◦ Focus on what you want to do to your data, not what the underlying system supports. • A graph of transformations is automatically transformed into an optimized series of MapReduces. @meteatamel
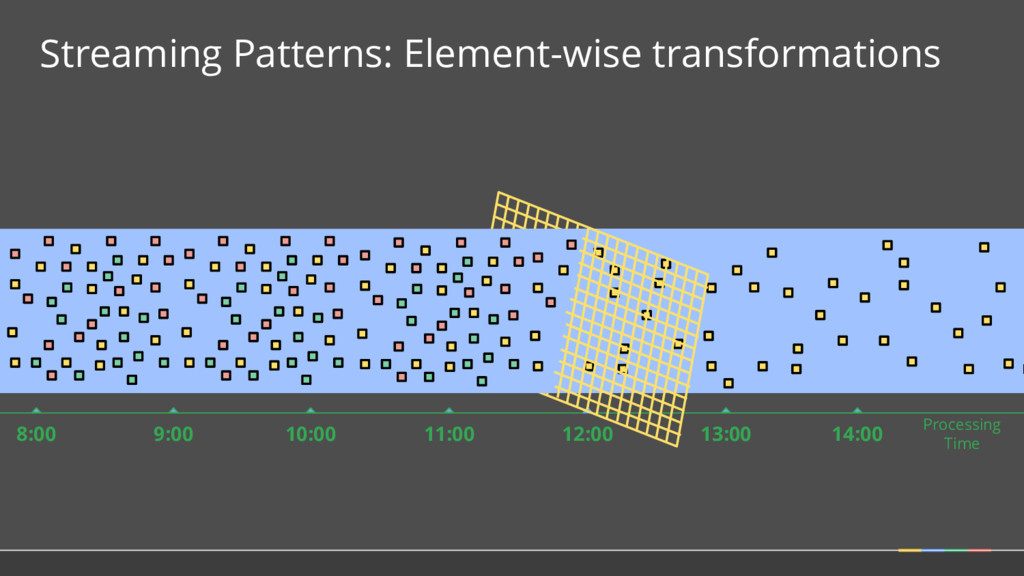
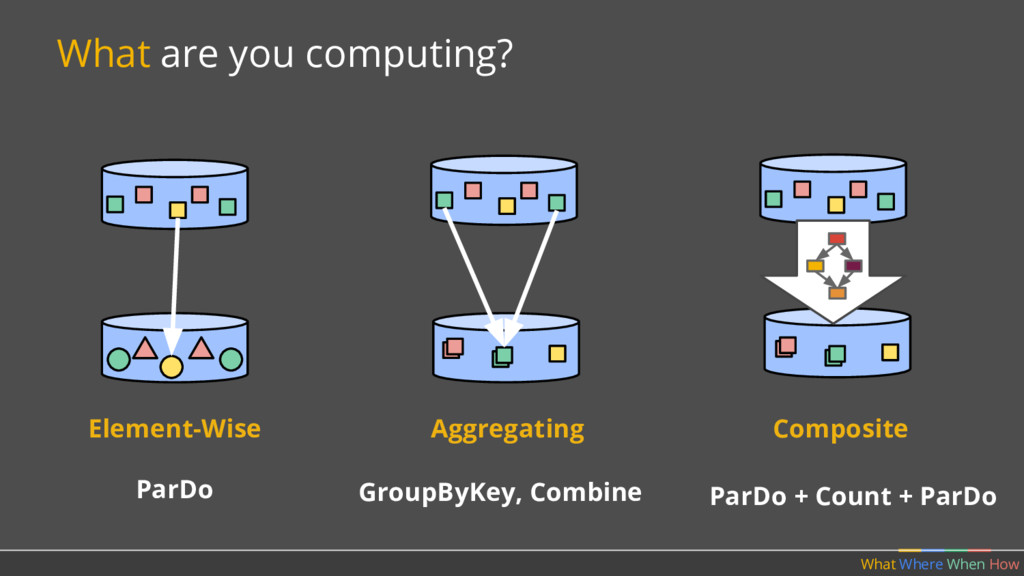
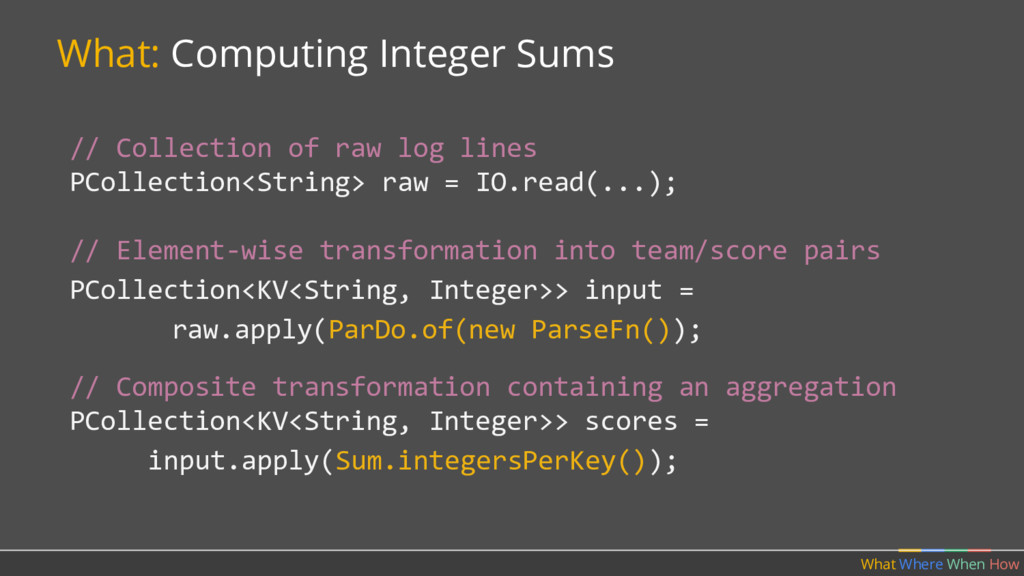
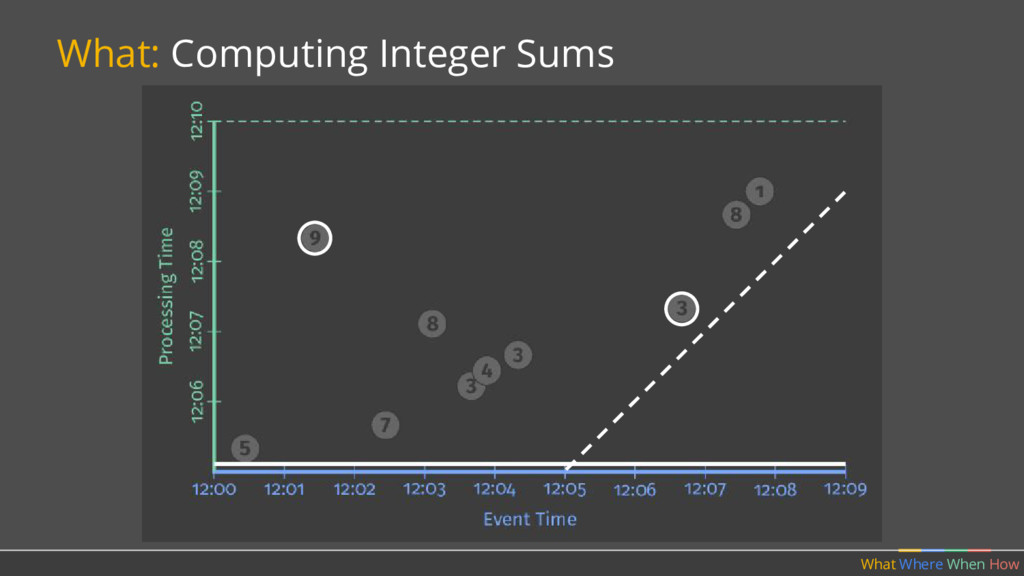
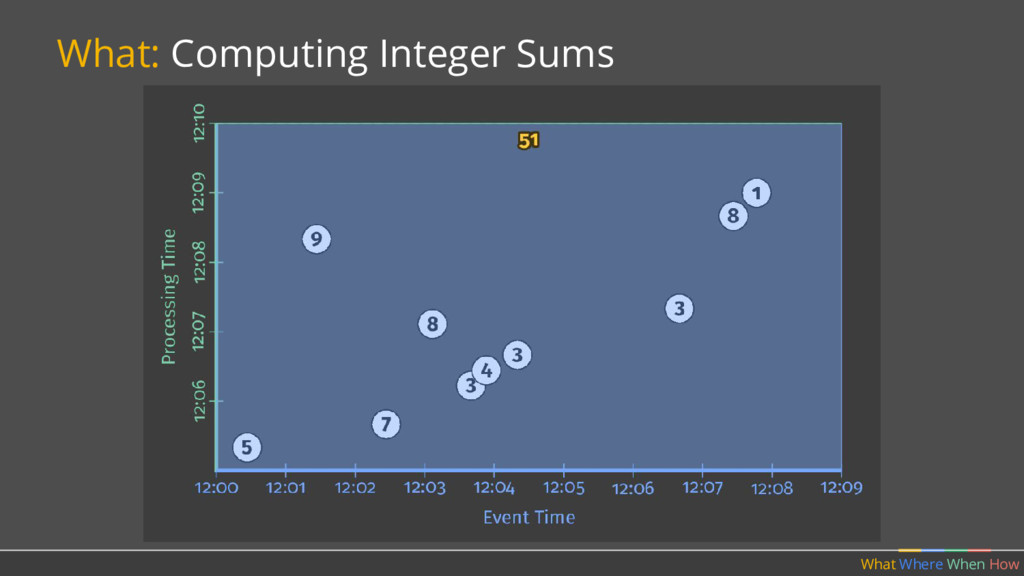
PCollection<String> raw = IO.read(...); What Where When How // Element-wise transformation into team/score pairs PCollection<KV<String, Integer>> input = raw.apply(ParDo.of(new ParseFn()); // Composite transformation containing an aggregation PCollection<KV<String, Integer>> scores = input.apply(Sum.integersPerKey());
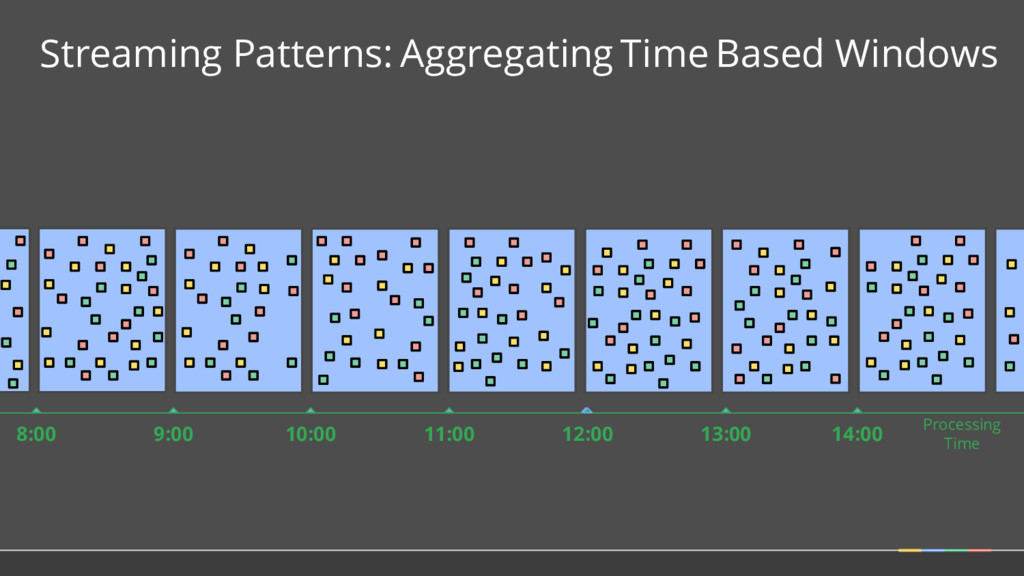
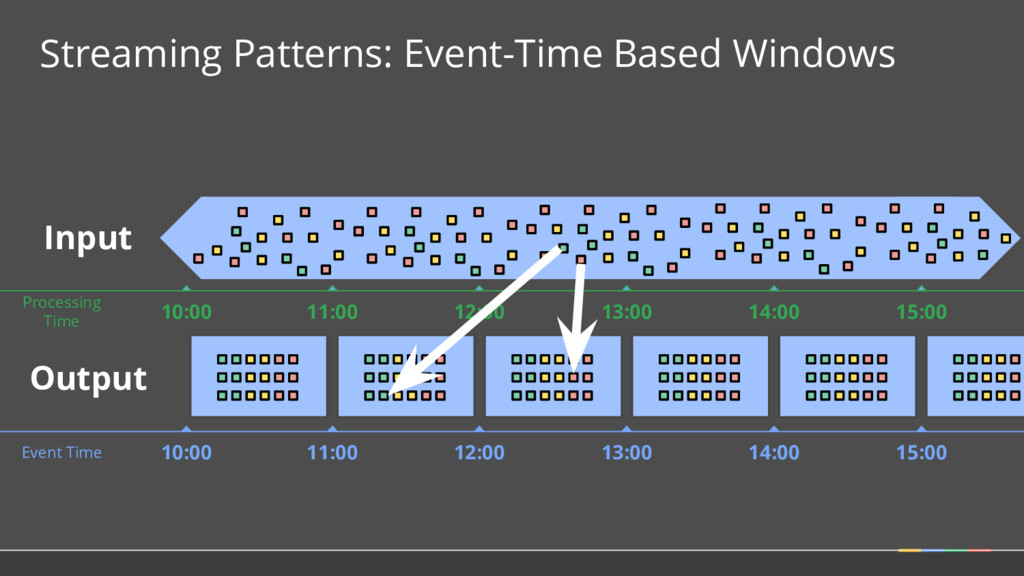
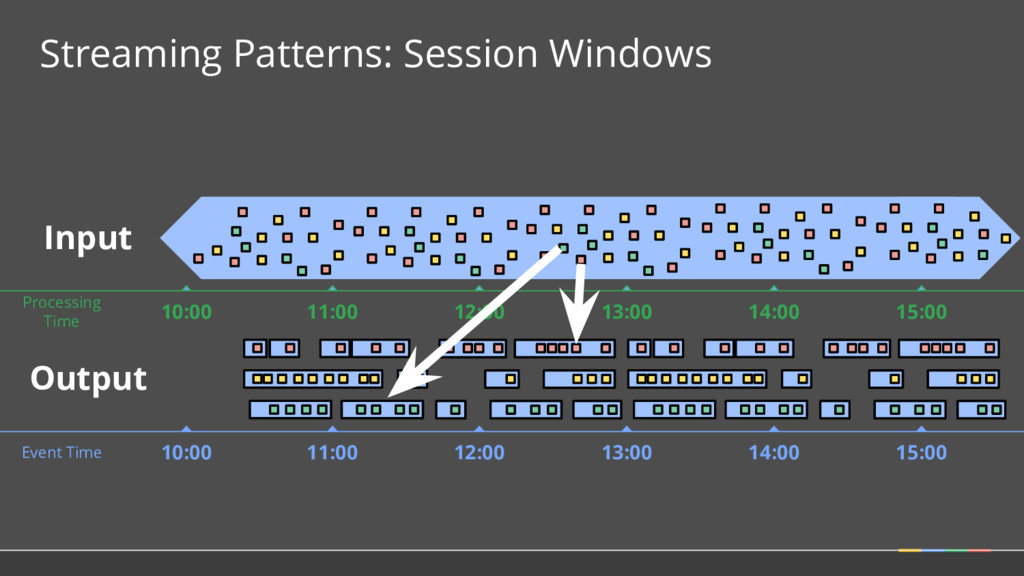
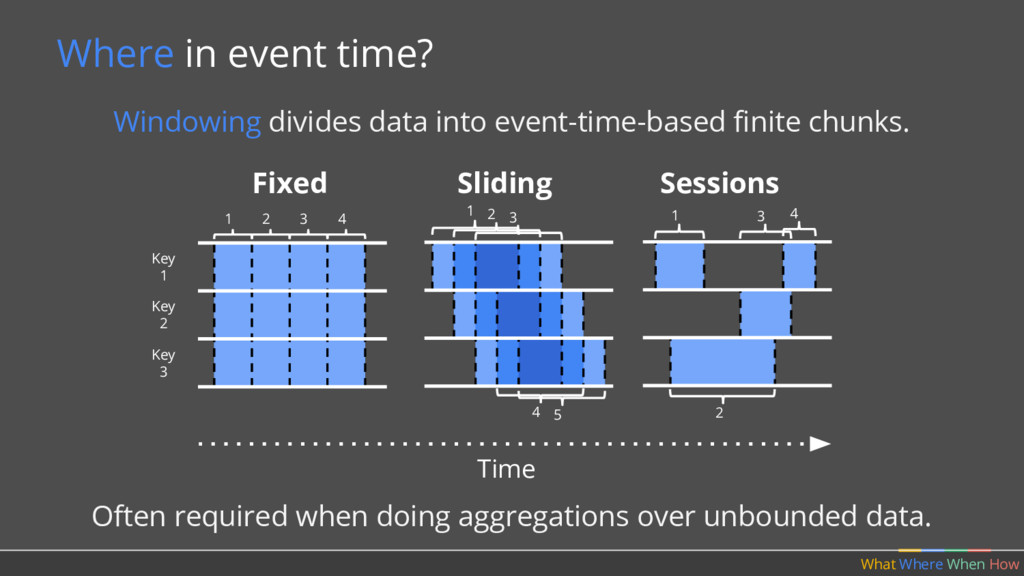
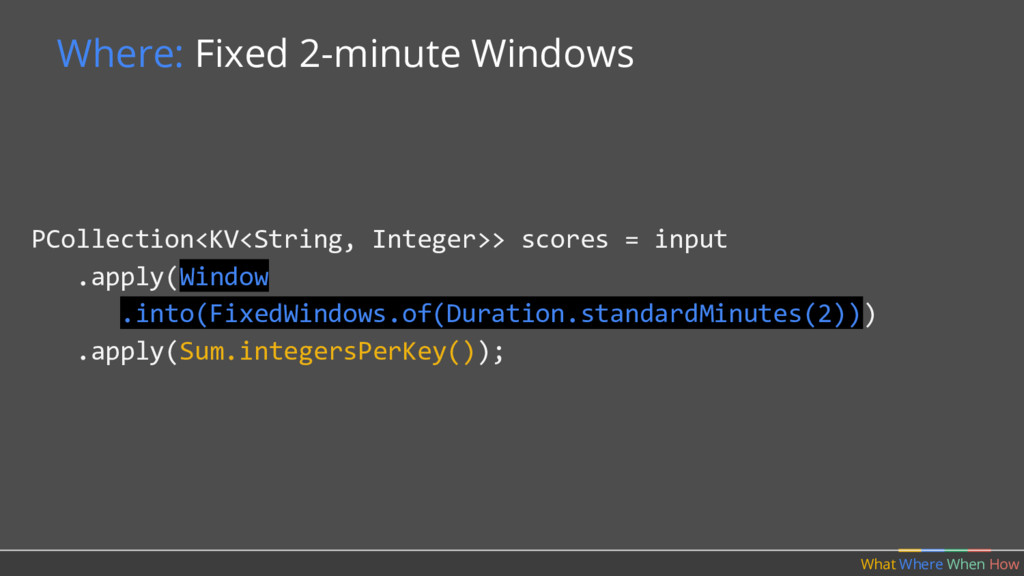
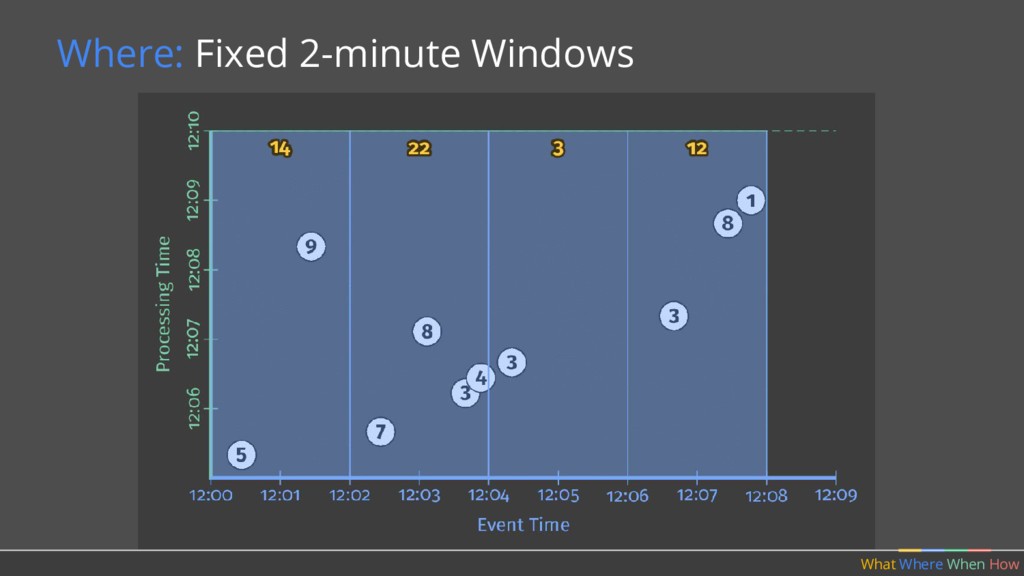
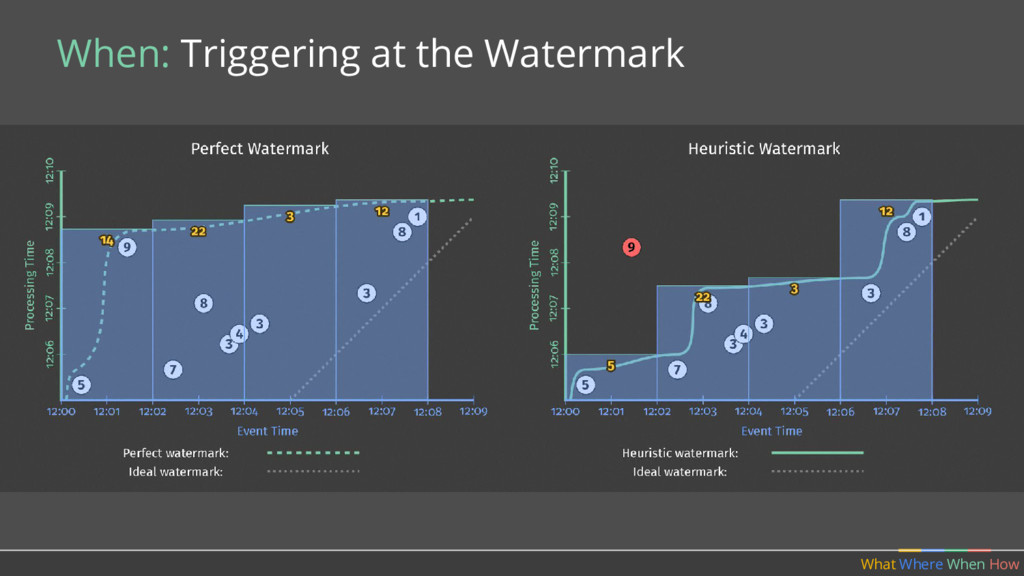
doing aggregations over unbounded data. Where in event time? What Where When How Fixed Sliding 1 2 3 5 4 Sessions 2 4 3 1 Key 2 Key 1 Key 3 Time 1 2 3 4
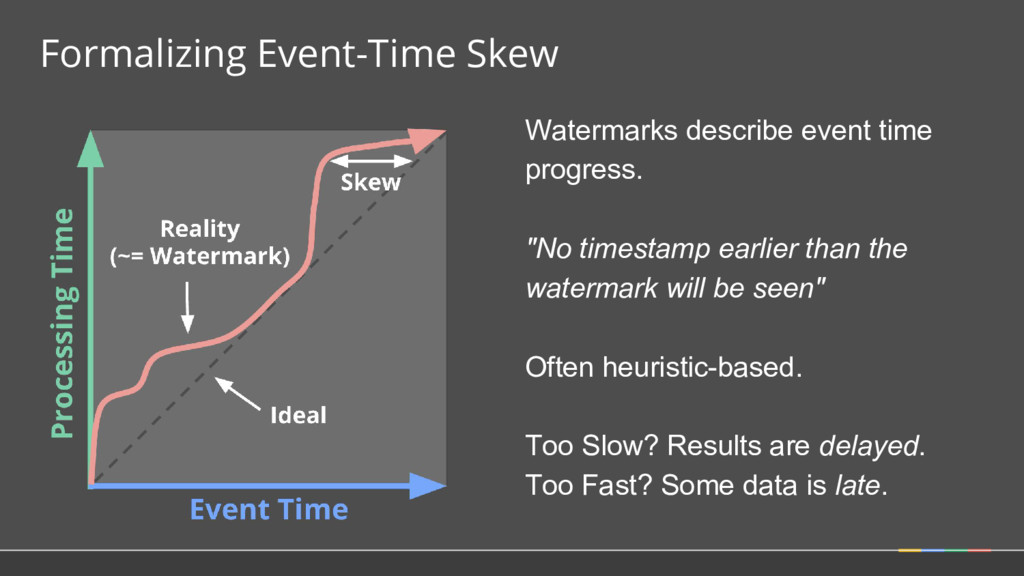
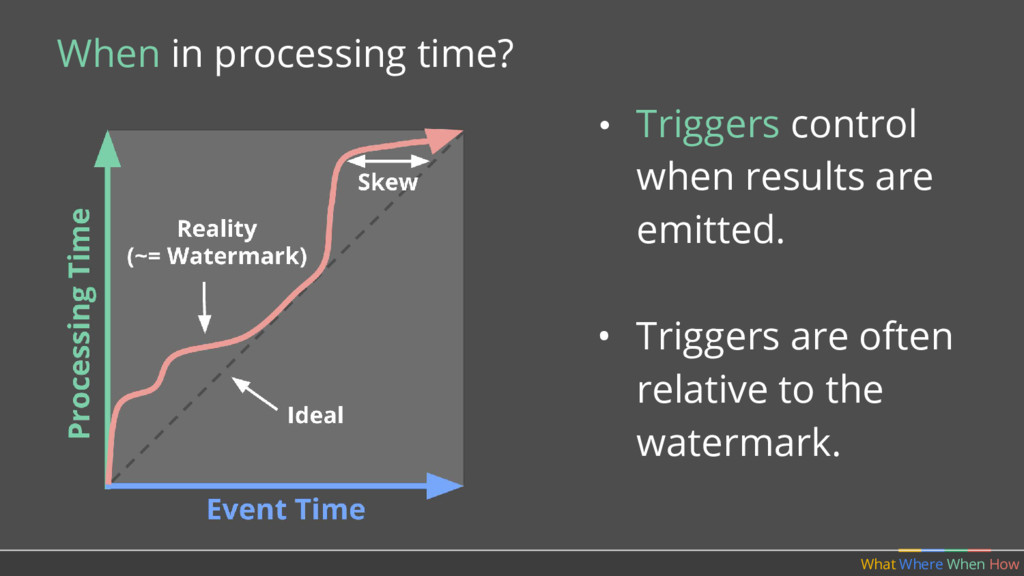
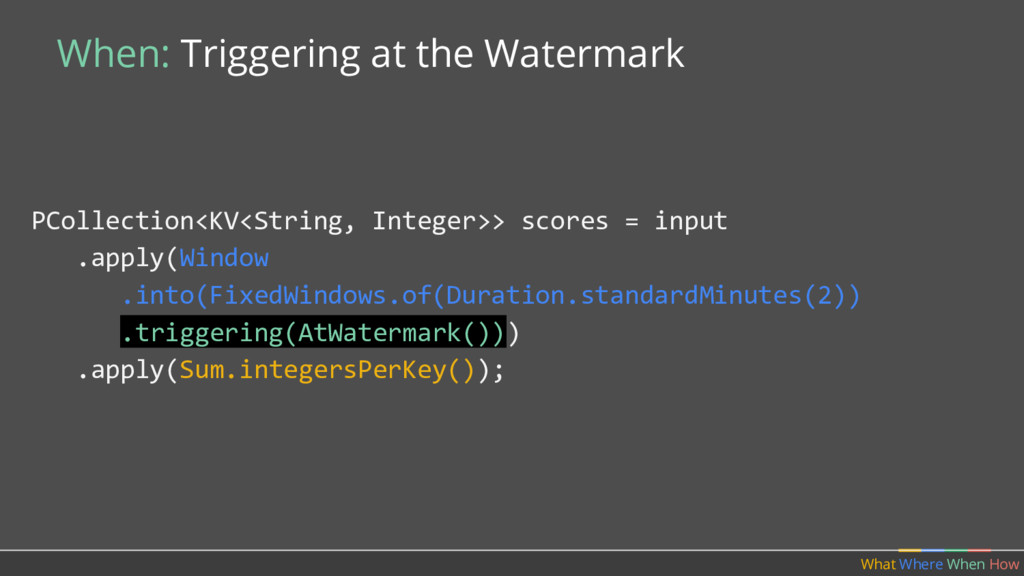
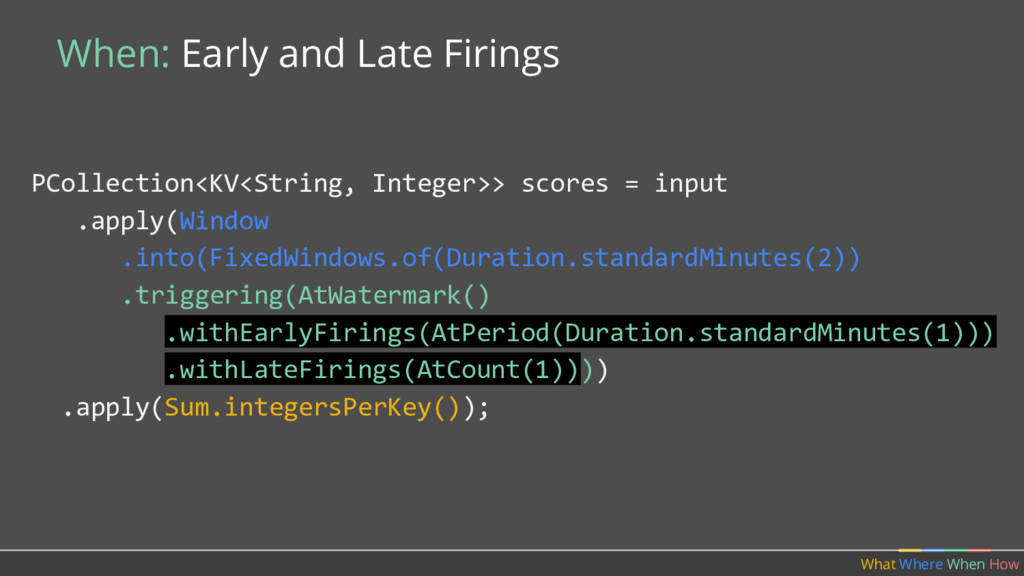
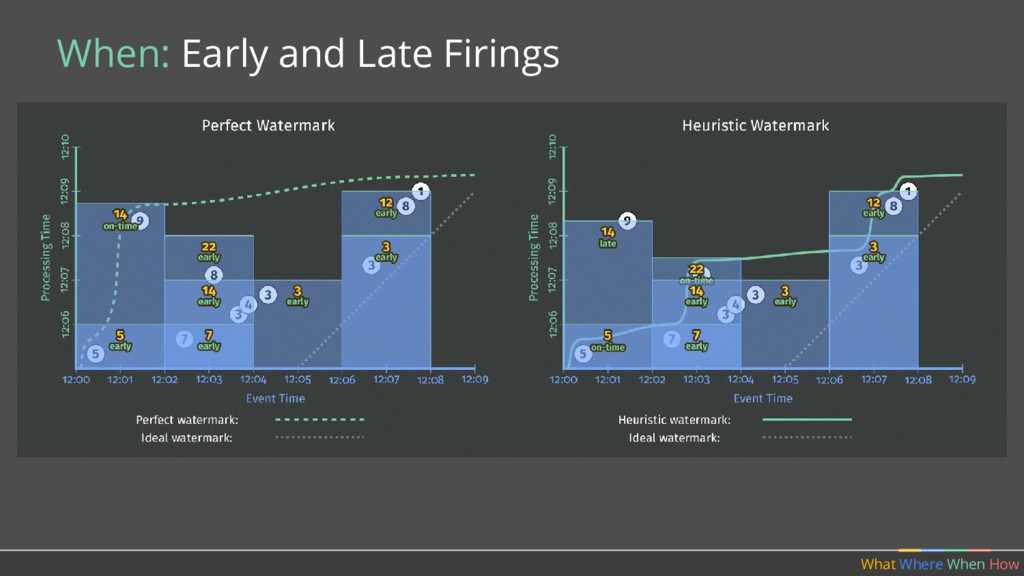
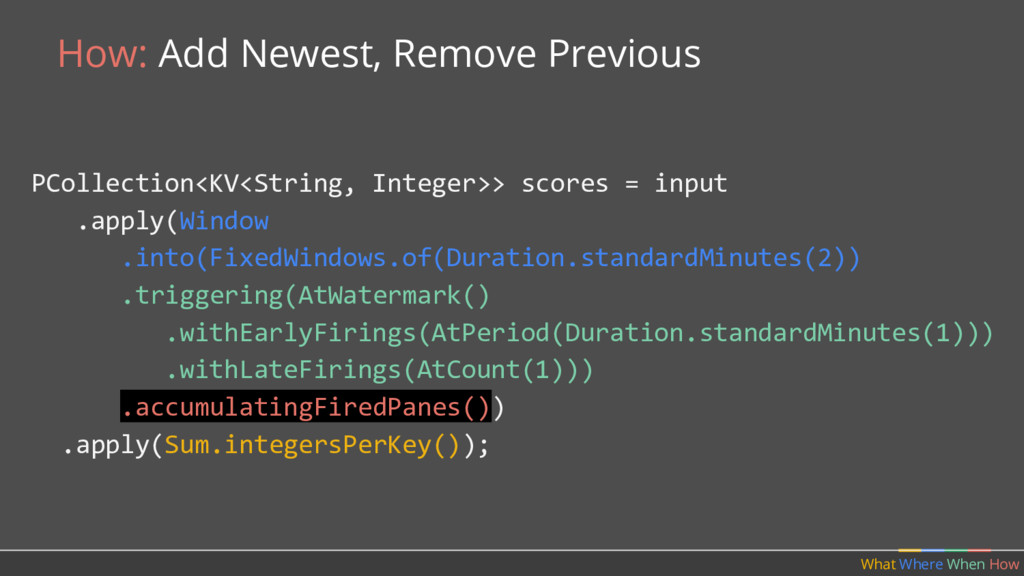
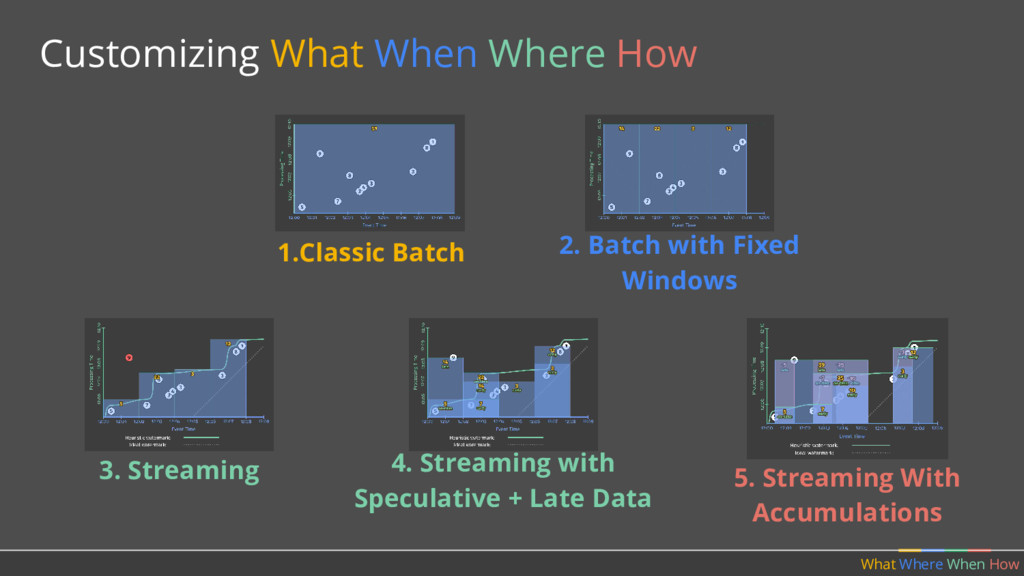
should multiple outputs per window accumulate? • Should we emit the running sum, or only the values that have come in since the last result? (Accumulating & Retracting not yet implemented in Apache Beam.)
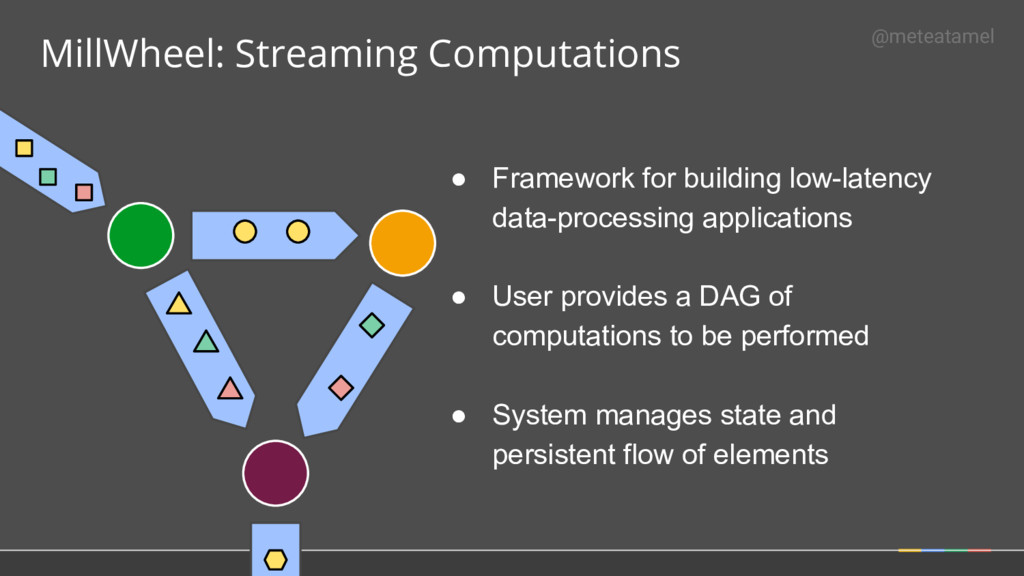
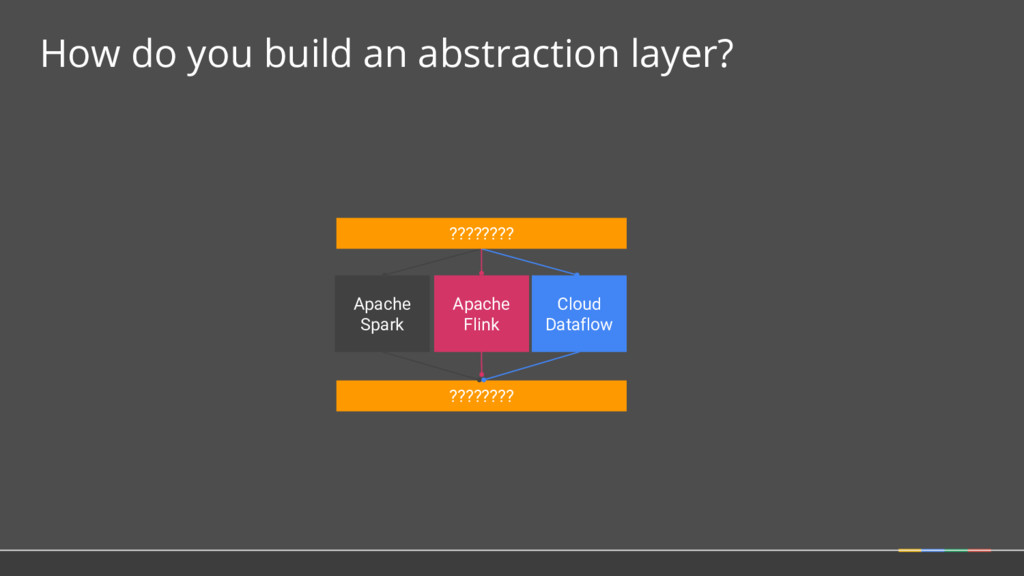
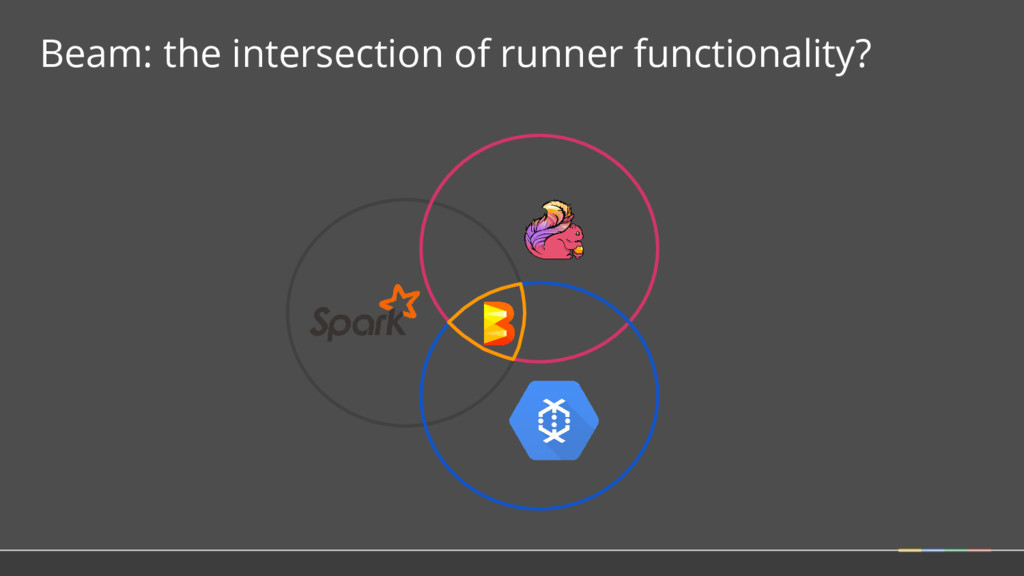
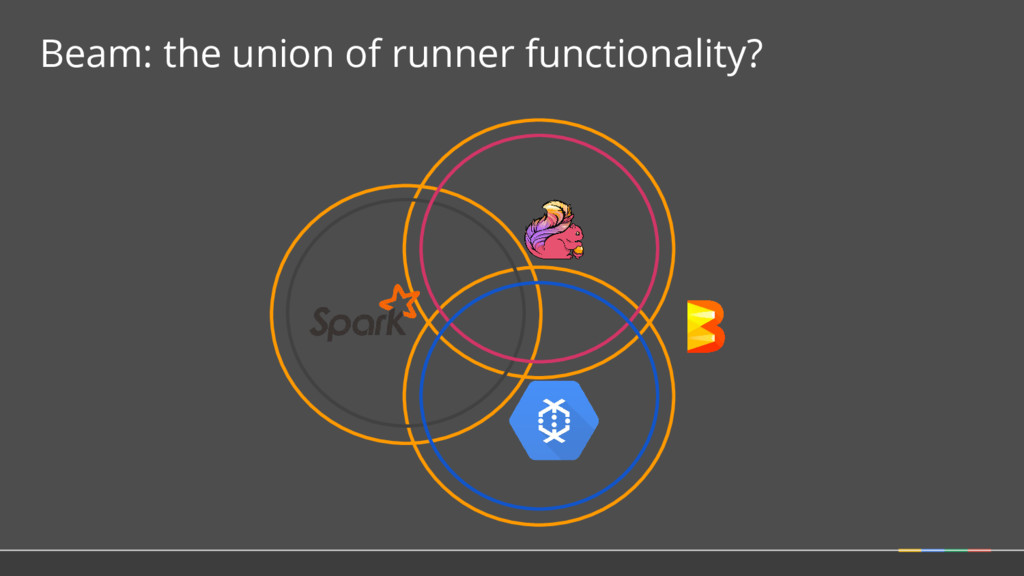
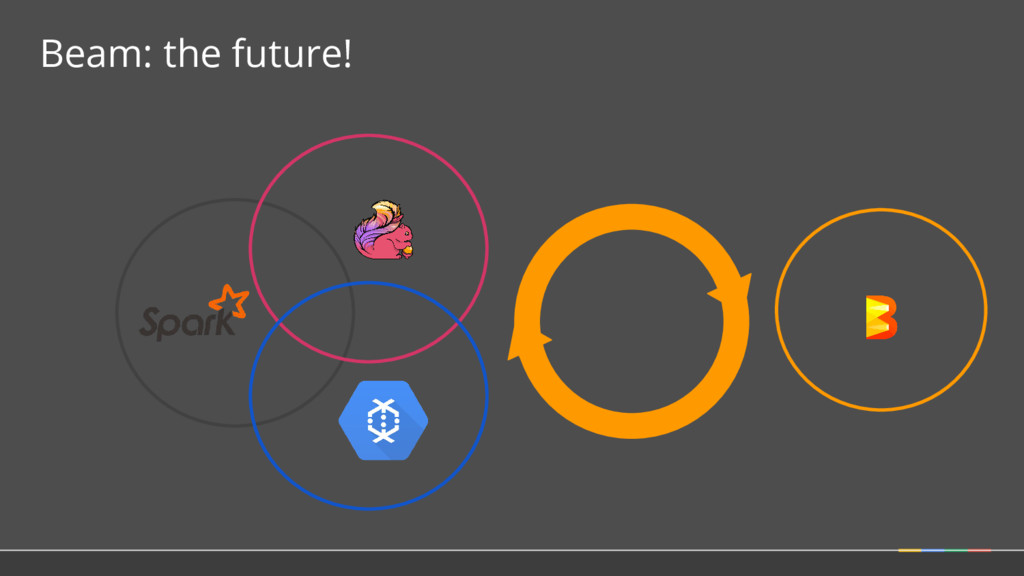
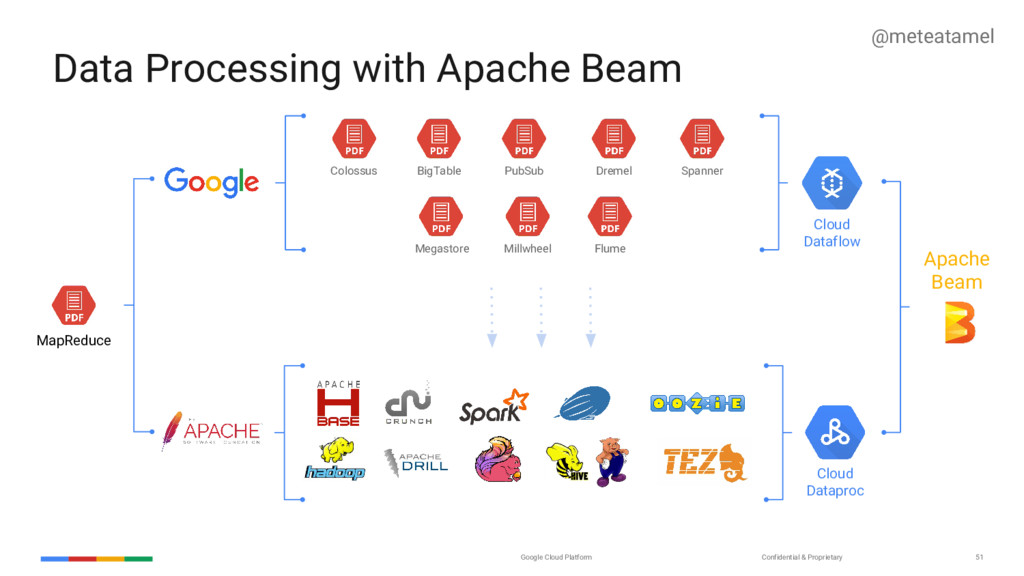
How 2. SDKs for writing Beam pipelines -- starting with Java 3. Runners for Existing Distributed Processing Backends • Apache Flink (thanks to data Artisans) • Apache Spark (thanks to Cloudera) • Google Cloud Dataflow (fully managed service) • Local (in-process) runner for testing What is Part of Apache Beam?
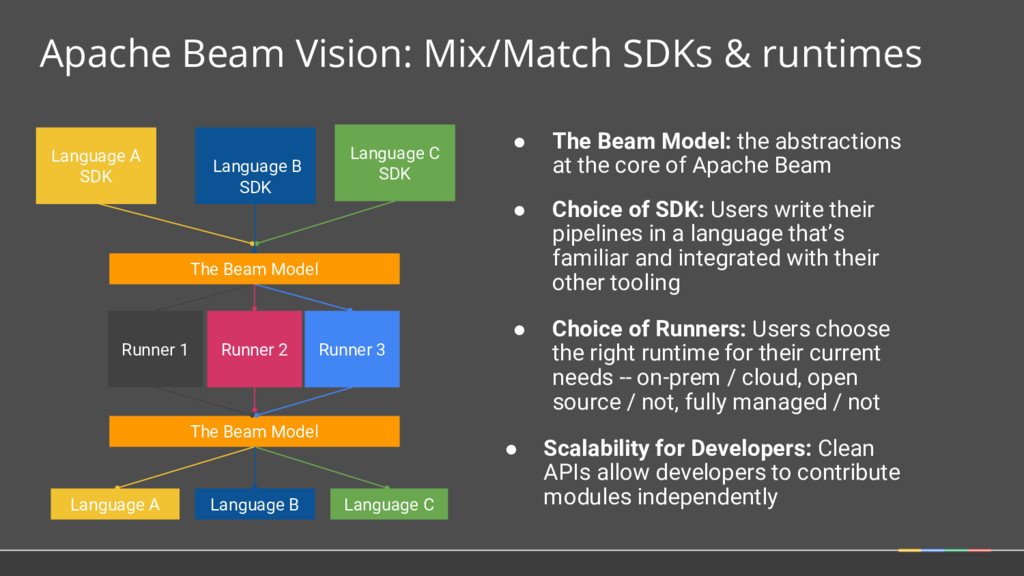
Model: the abstractions at the core of Apache Beam Language B SDK Language A SDK Language C SDK Runner 1 Runner 3 Runner 2 • Choice of SDK: Users write their pipelines in a language that’s familiar and integrated with their other tooling • Choice of Runners: Users choose the right runtime for their current needs -- on-prem / cloud, open source / not, fully managed / not • Scalability for Developers: Clean APIs allow developers to contribute modules independently The Beam Model Language A Language C Language B The Beam Model
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}