Presentation from GDG DevFest Ukraine 2018 - the biggest community-driven Google tech conference in the CEE.
Learn more at: https://devfest.gdg.org.ua
__
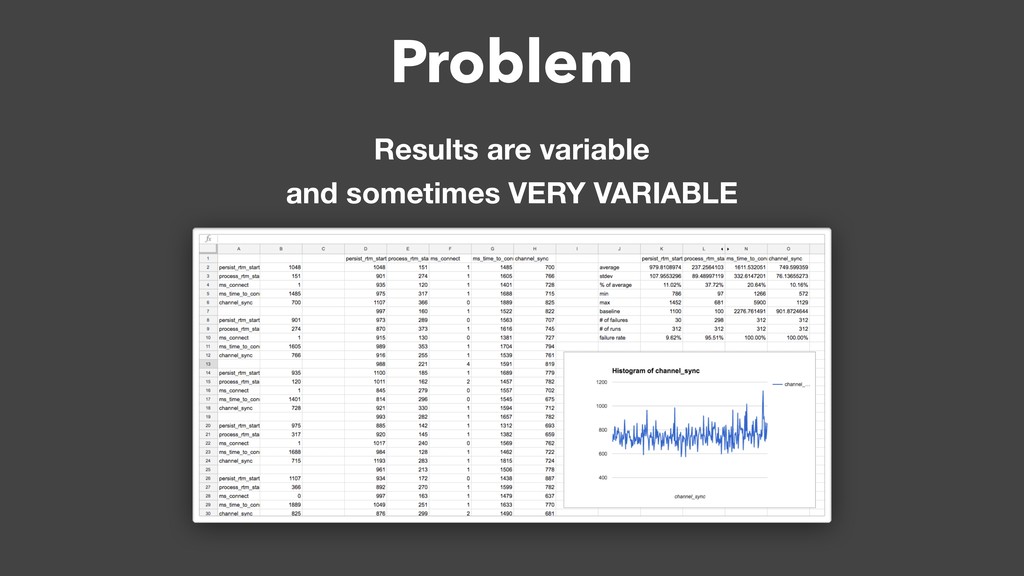
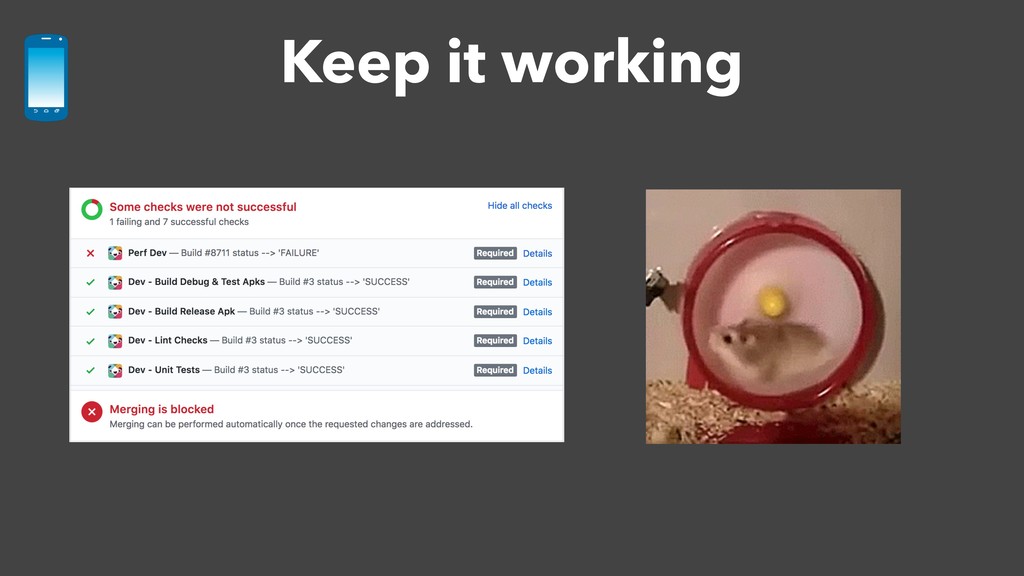
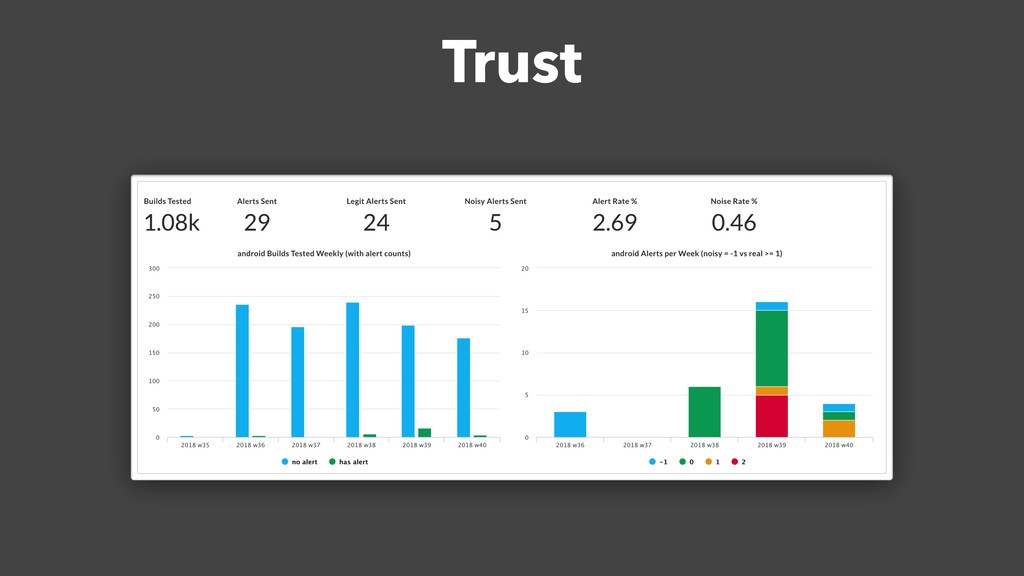
There comes a point in a company's evolution when the rush to build all the features as fast as possible subsides and the company realizes that performance should be prioritized too. The CEO publishes a document that says "a Slack client must be as fast as fuck" and the engineer team sets out to fix all the performance bottlenecks. But how does an engineer validate that their improvements actually work? More importantly, how does the team prevent future performance regressions?
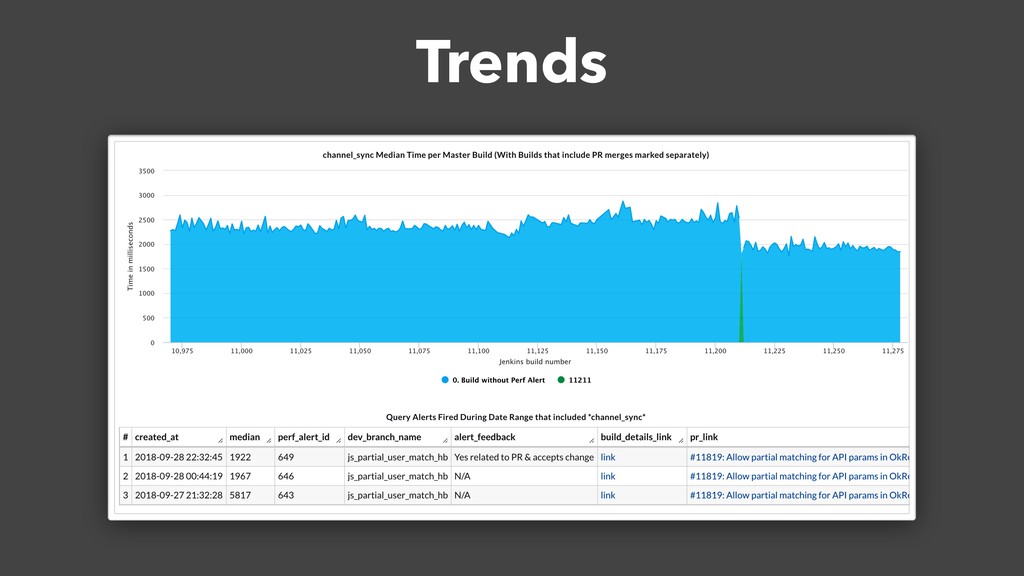
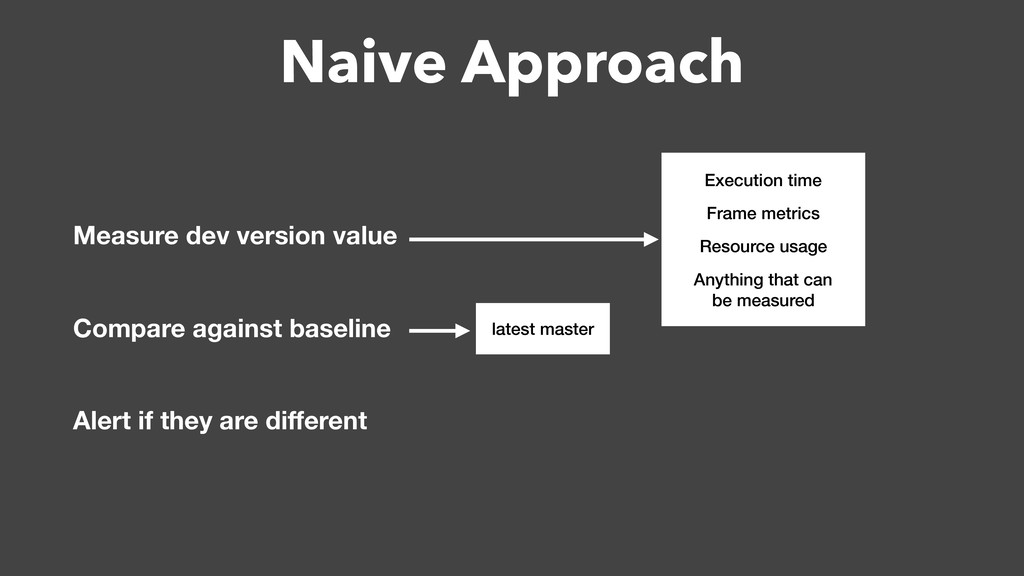
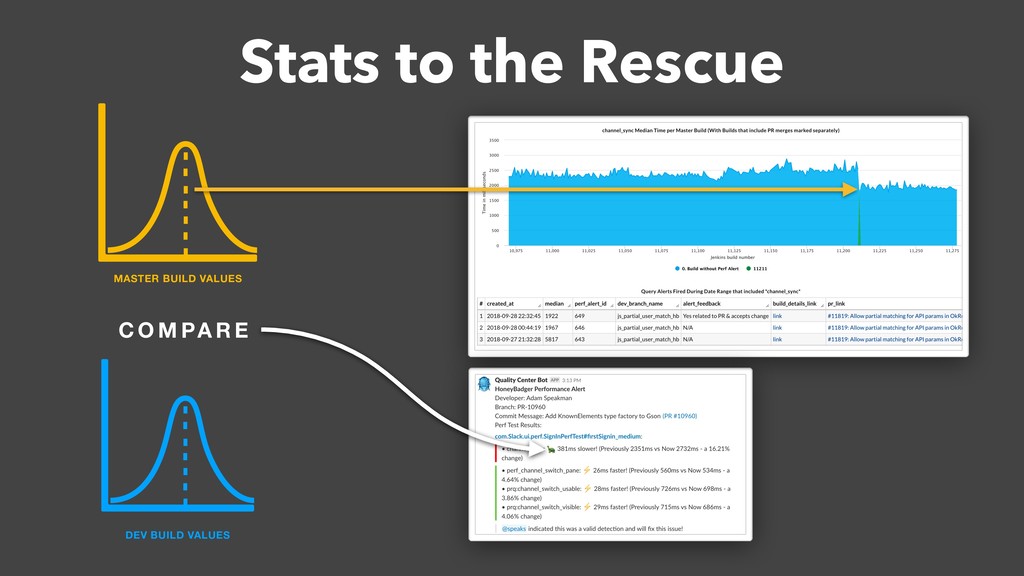
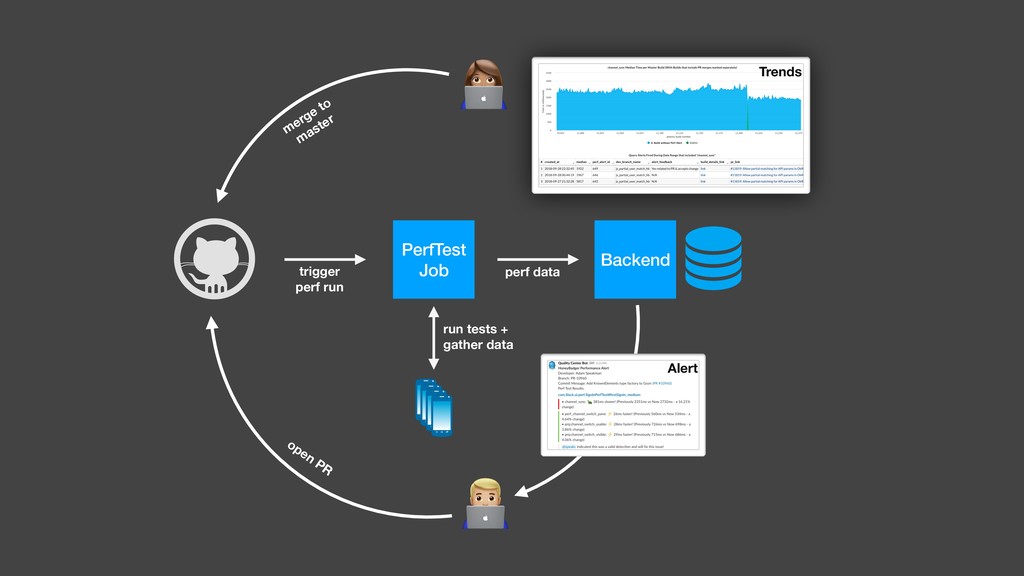
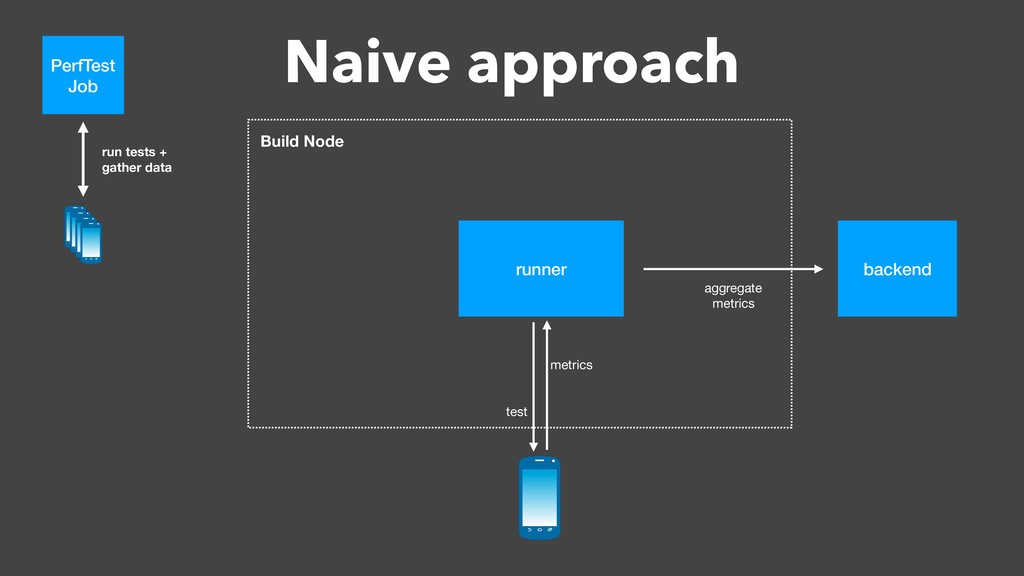
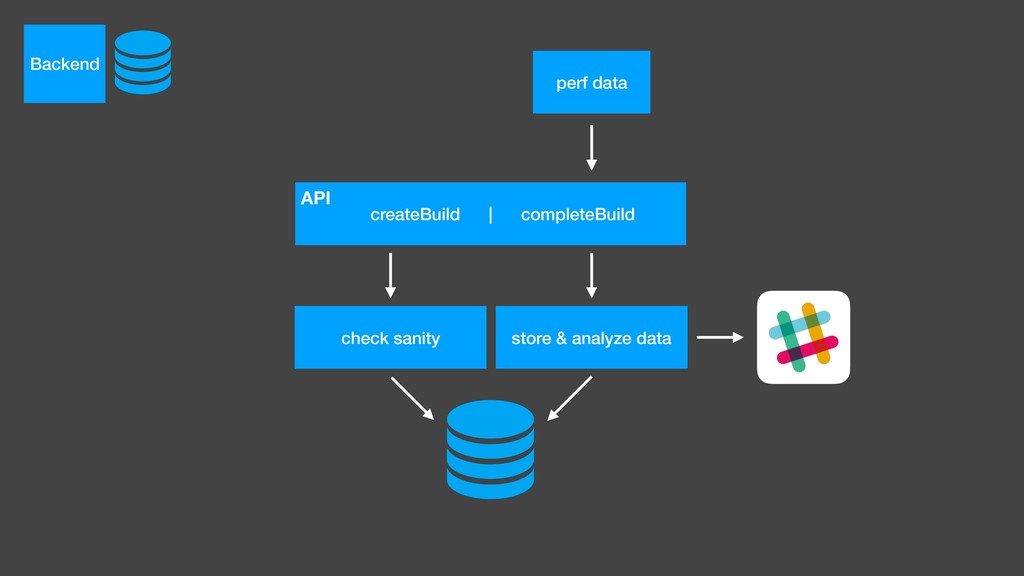
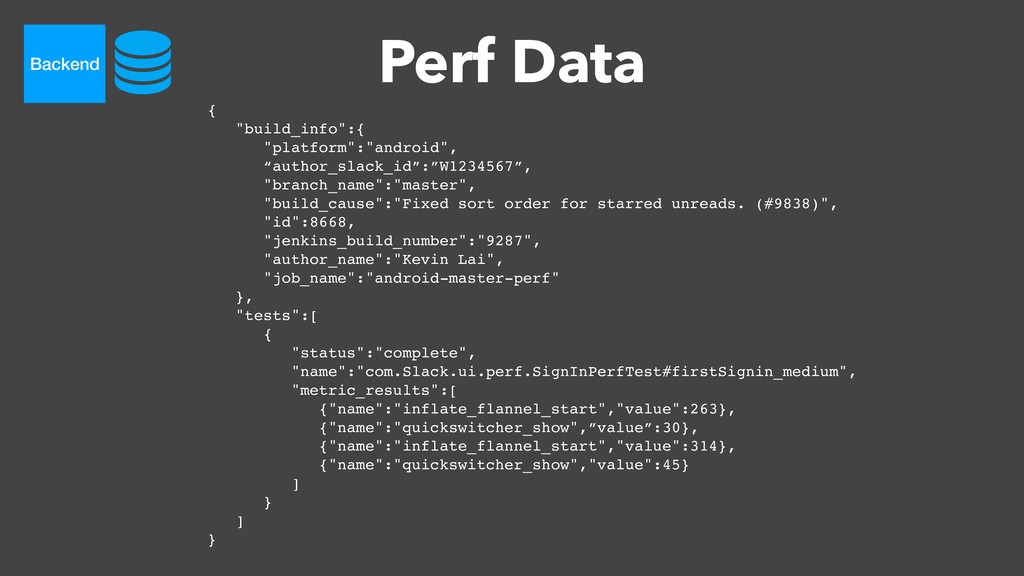
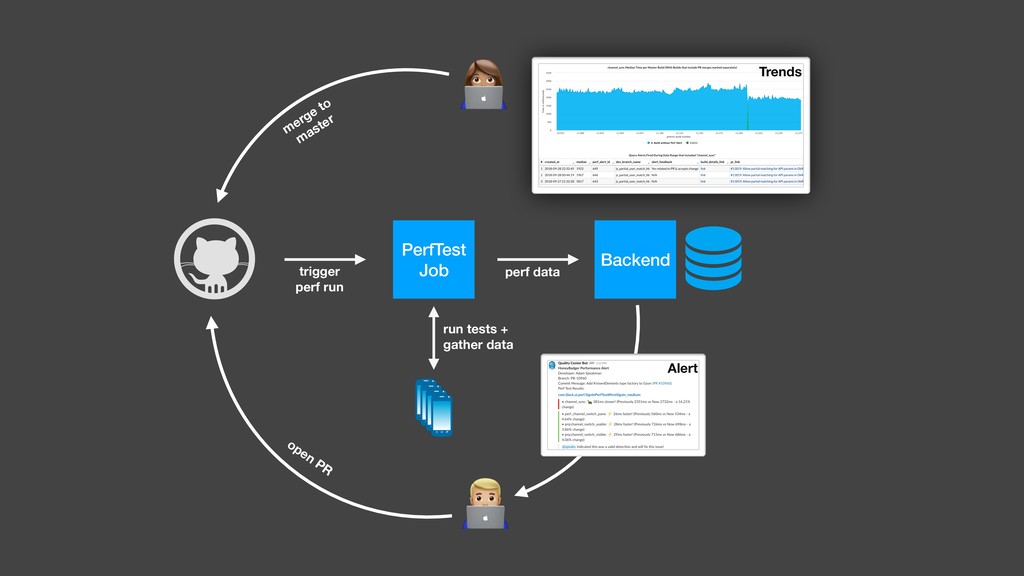
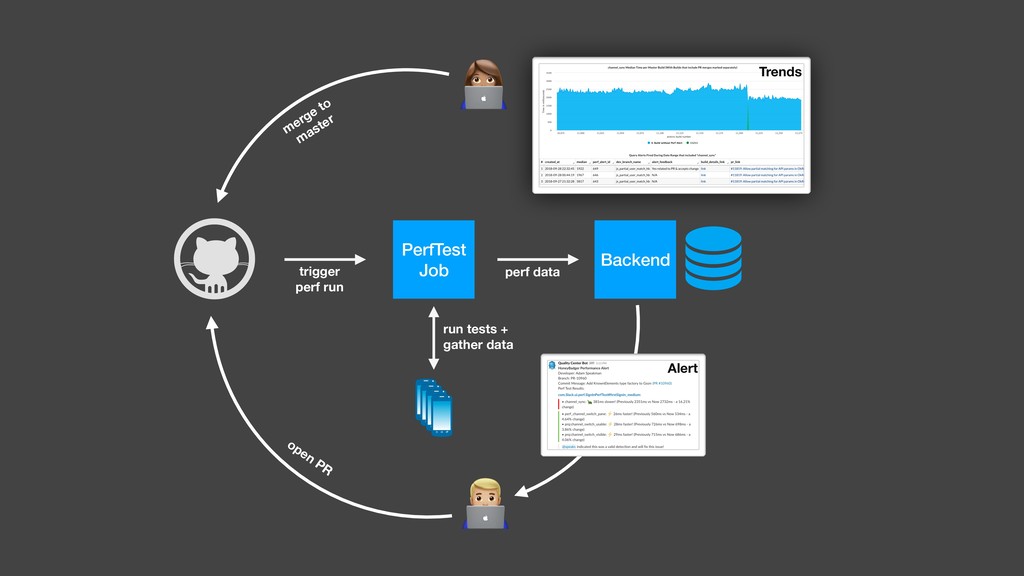
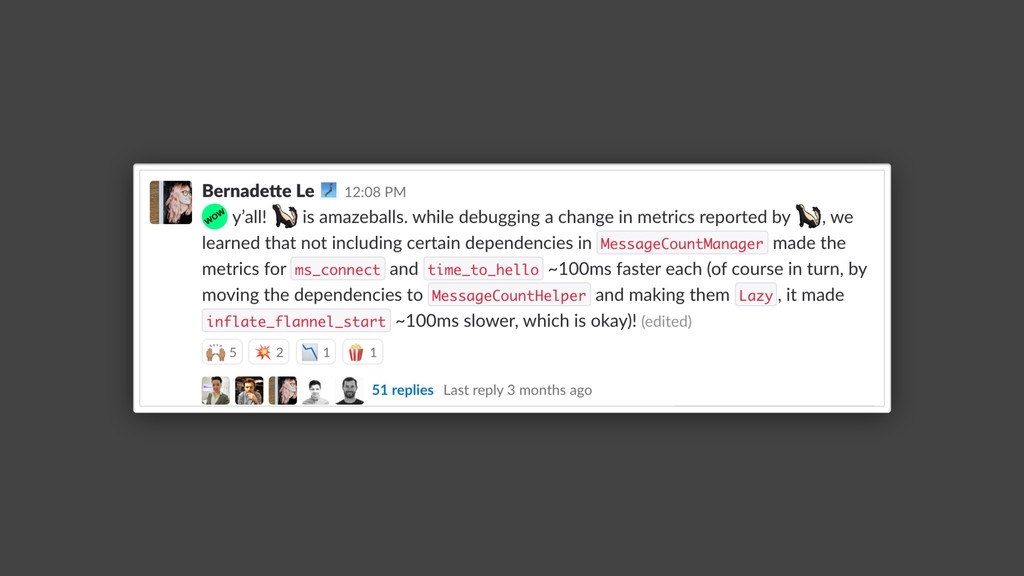
Over a year ago, we asked these questions and decided to build a performance testing pipeline that would continuously validate every code change for performance impact. In this talk, I will introduce the basic building blocks of this pipeline and share the lessons learned from building and maintaining this infrastructure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
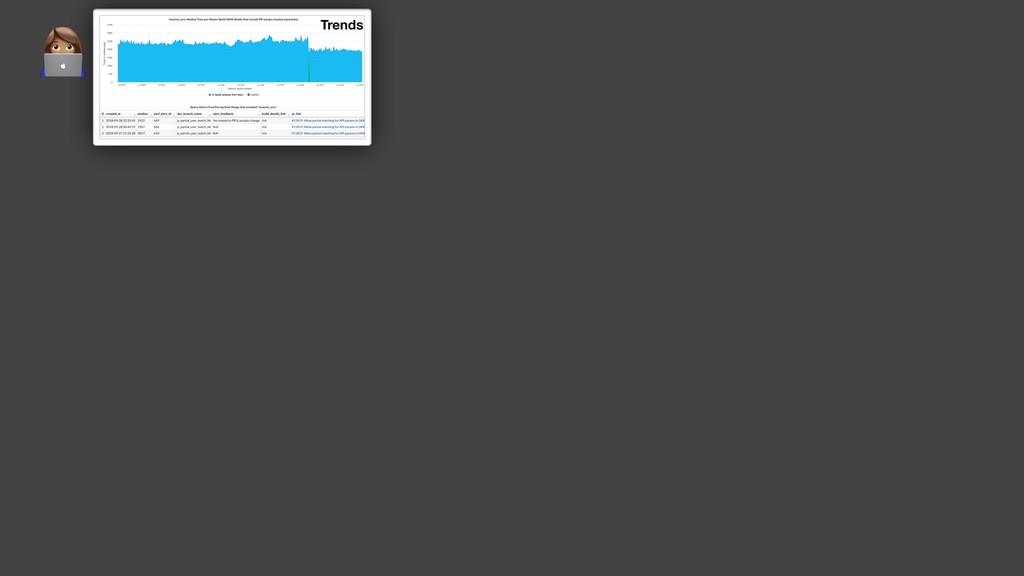{kind=link}
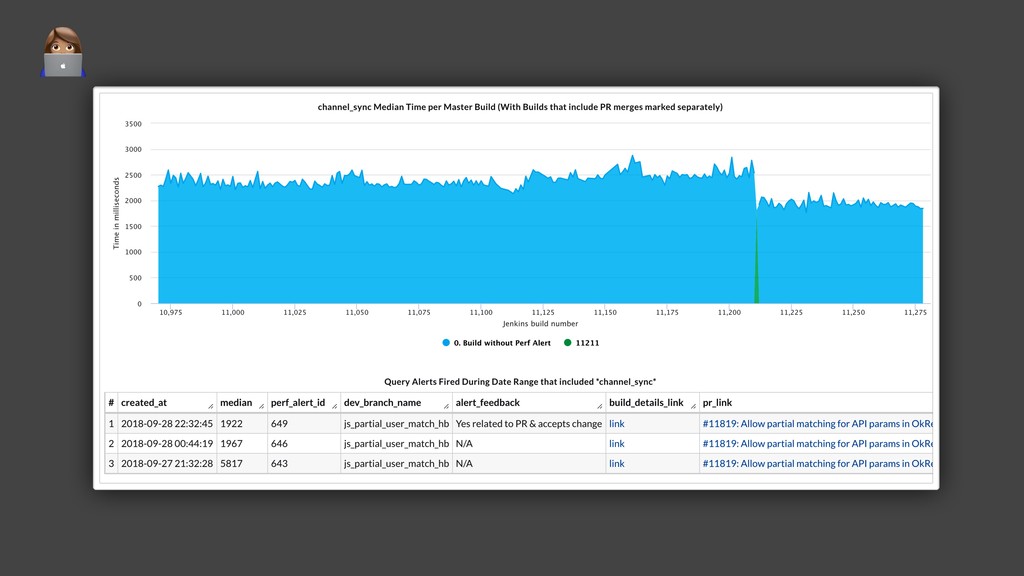{kind=link}
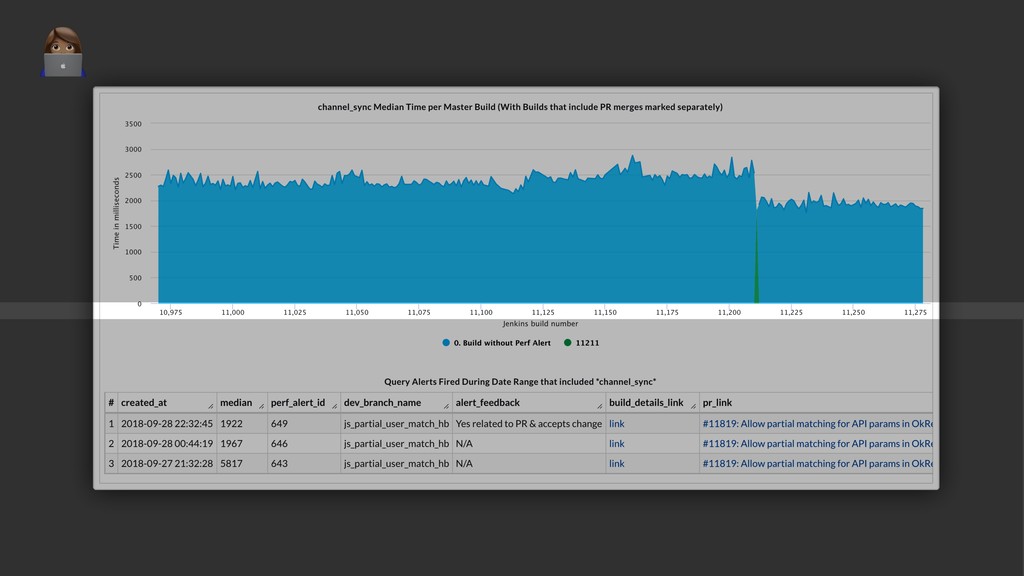{kind=link}
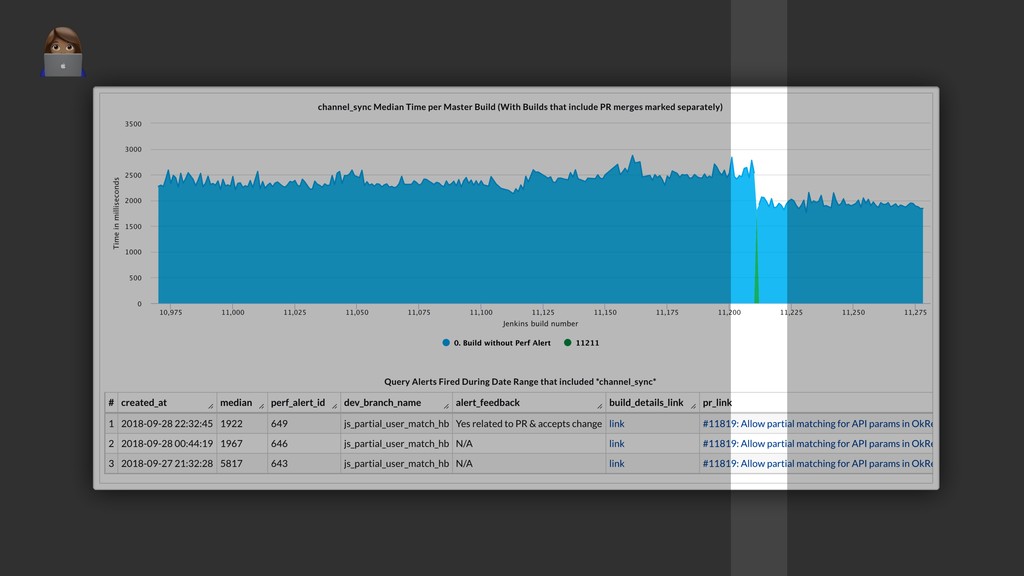{kind=link}
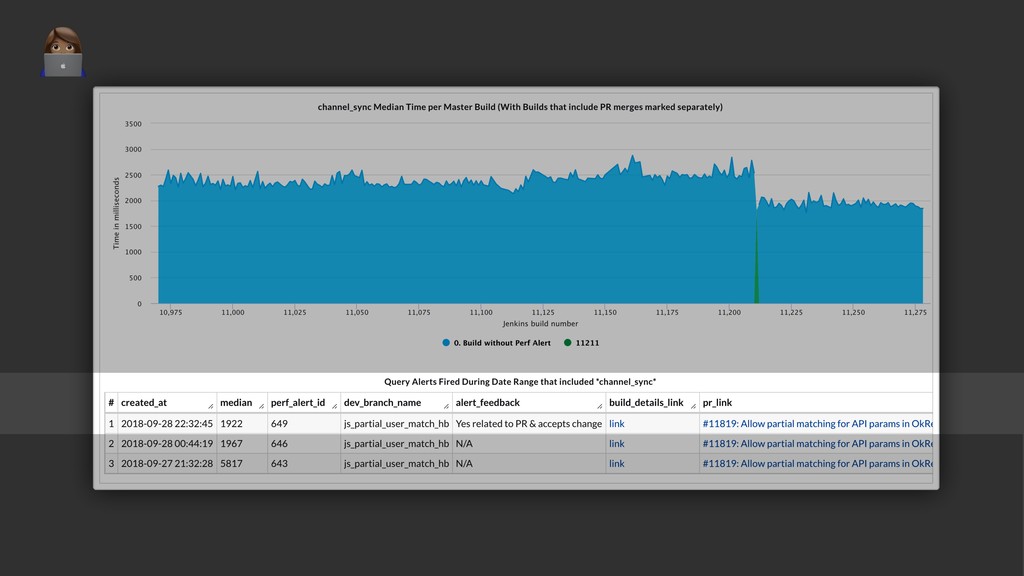{kind=link}
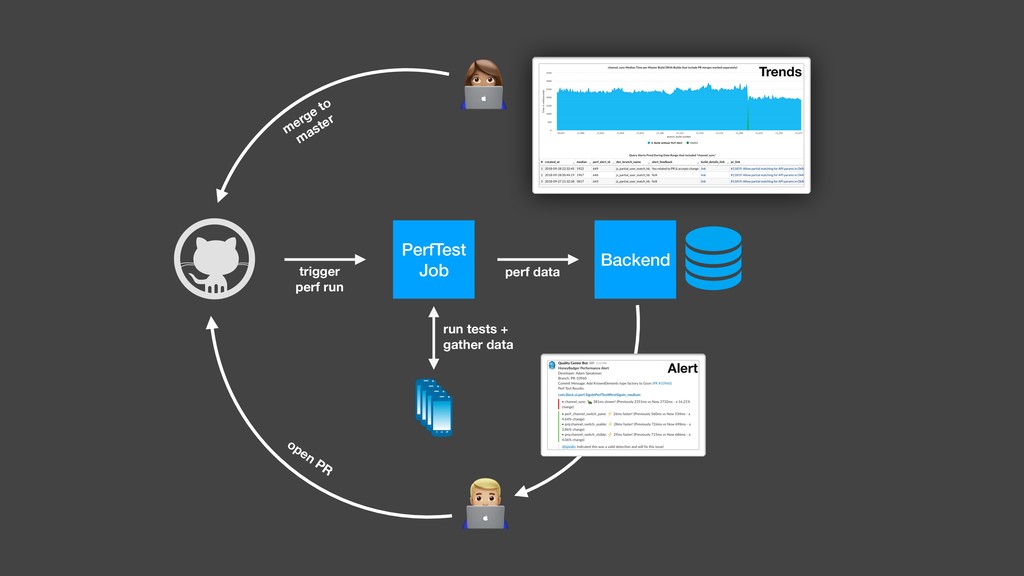{kind=link}
{kind=link}
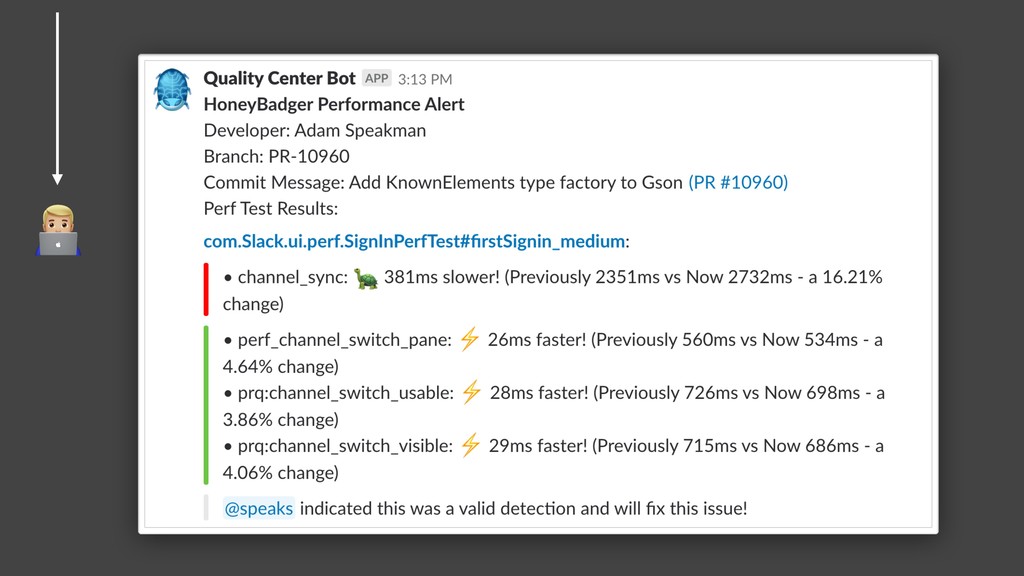{kind=link}
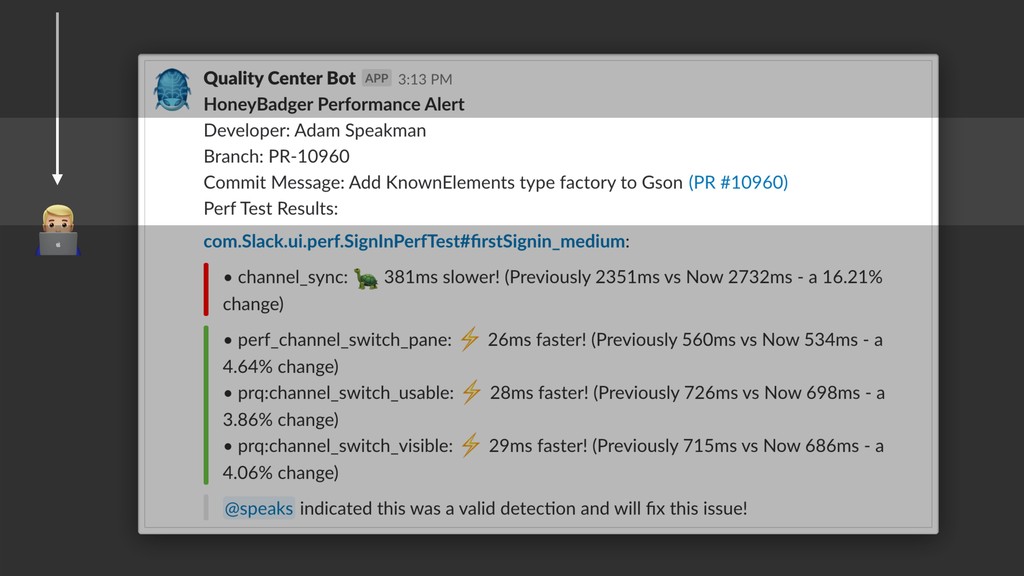{kind=link}
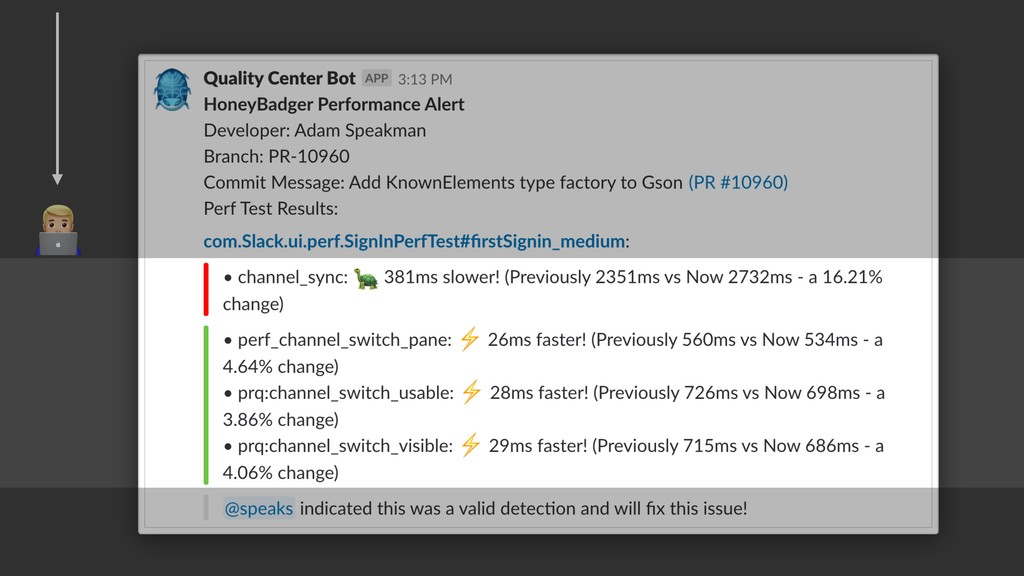{kind=link}
{kind=link}
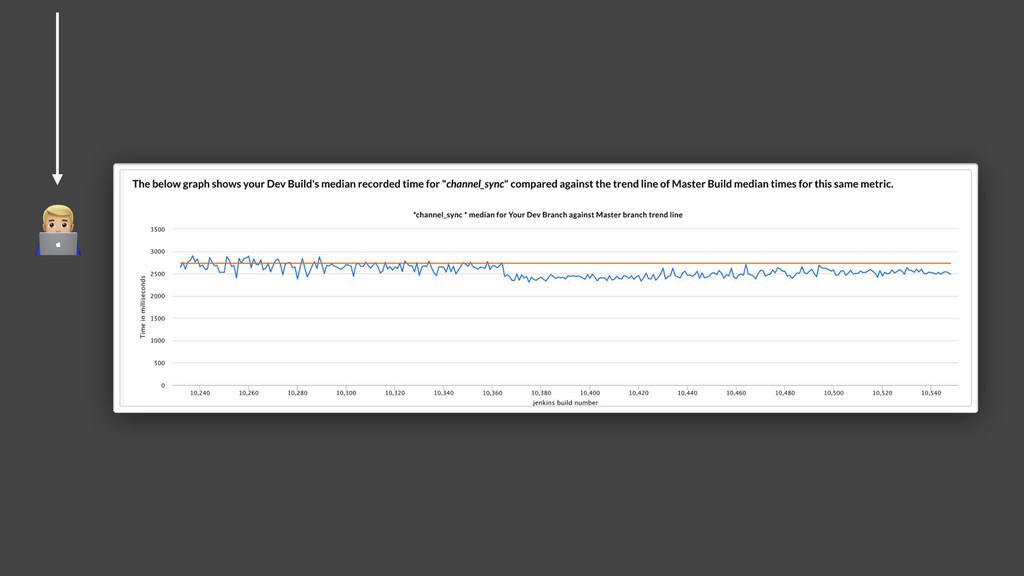{kind=link}
{kind=link}
{kind=link}
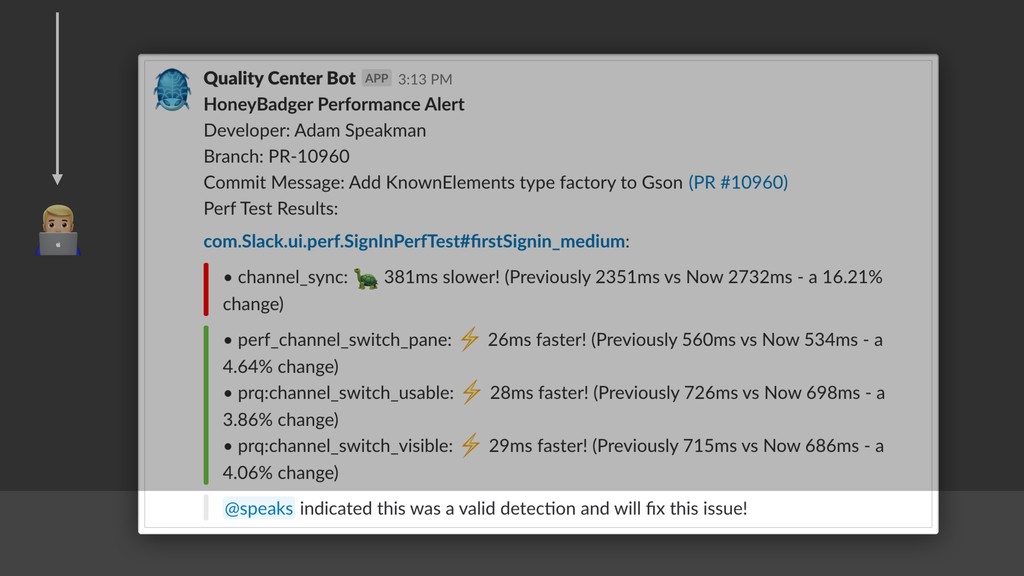{kind=link}
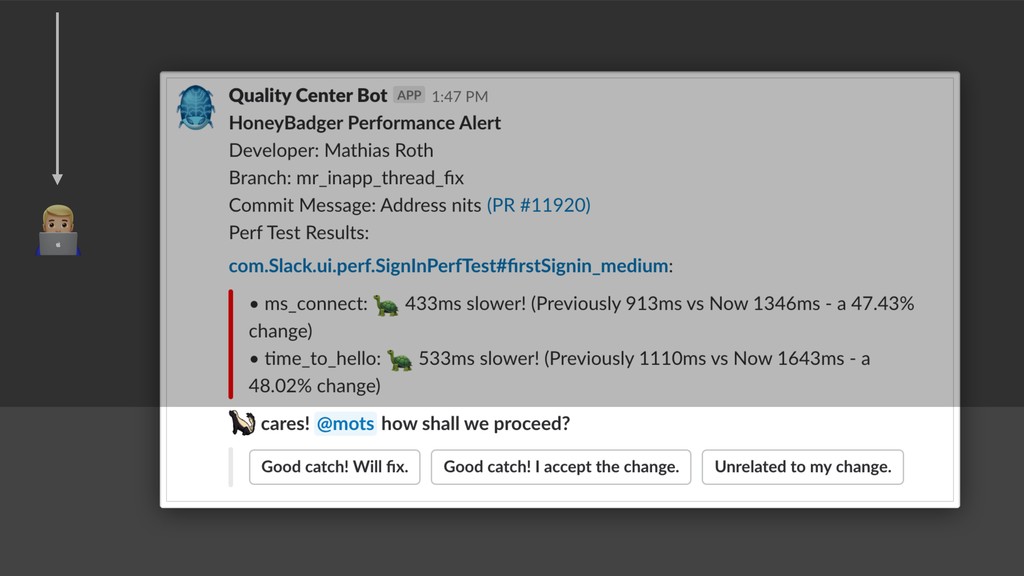{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}