2. Fast development 3. Lots of libraries for machine learning and neural networks: a. NumPy and SciPy (complex math) b. Scikit-Learn (machine learning) c. NLTK and TextBlob (natural languages processing) d. Theano (neural networks)
person? • What the document is about? • What is the opinion of the author to described problem? • Is the document is a spam? • Automatically correct mistakes in documents • Detect document language
This problem usually isn’t that hard You can easily split text by dots, question or exclamation marks etc Split sentences into words While the problem isn’t hard at the first look, it becomes more complicated as you dive deeper Examples: It’s, 20-year-old, U.S., New York
when you don’t really care about the endings, prefixes and suffixes of the words in the text, and you only need the root of the word. Generously -> generous Miles -> mile Traditional -> tradition
`bag-of-words` analysis: ◦ Sentimental analysis ◦ Authorship analysis DecisionTreeClassifier • Longer learning process, but can give better results • Good for `bag-of-collocations` analysis
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example common_suffixes = [suffix for (suffix, count) in suffix_fdist.most_common(100)] tagged_words](https://files.speakerdeck.com/presentations/b3f6917e392c4912962cf5d0bc6ccdb3/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
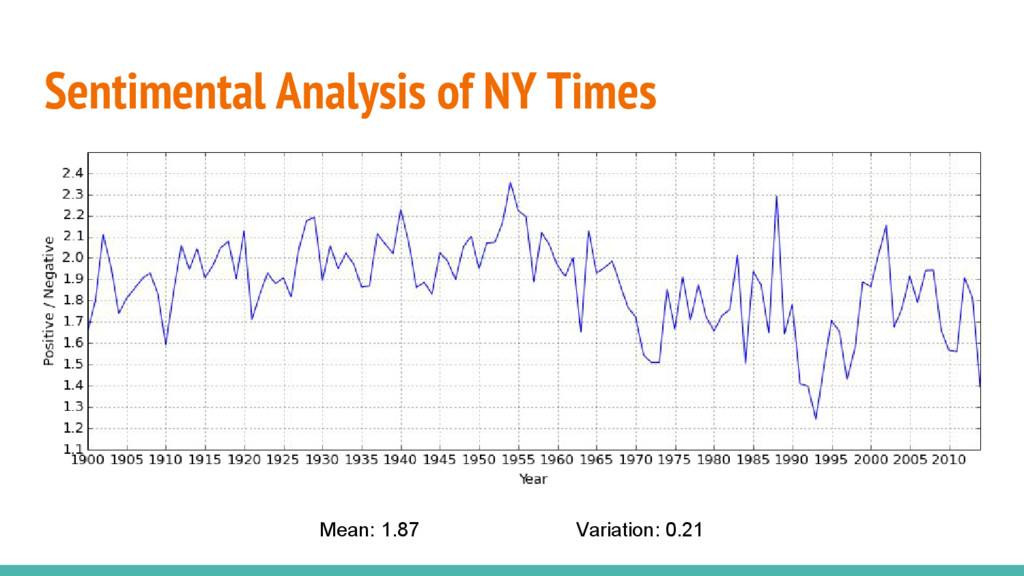{kind=link}