I'm often asked to rescue situations where NFS is working too slowly for people's liking. Sometimes the answer is pointing out that NFS is already running as fast as the hardware will allow it. Sometimes the answer involves undoing some clever "tuning improvements" that have been performed in the name of "increasing performance". Every now and again, there's an actual NFS bug that needs fixing.
This talk will distill that experience, and give guidance on the right way to tune Linux NFS servers and clients. I talked a little about this last year, in the context of tuning performed by SGI's NAS Server product. This year I'll expand on the subject and give direct practical advice.
I'll cover the fundamental hardware and software limits of NFS performance, so you can tell if there's any room for improvement. I'll mention some of the more dangerous or slow "improvements" you could make by tuning unwisely. I'll explain how some of the more obscure tuning options work, so you can see why and how they need to be tuned. I'll even cover some bugs which can cause performance problems.
After hearing this talk, you'll leave the room feeling rightfully confident in your ability to tune NFS in the field.
Plus, you'll have a warm fuzzy feeling about NFS and how simple and obvious it is. Sorry, just kidding about that last bit.
![Headline in Arial Bold 30pt Greg Banks <[email protected]> Senior Software](https://files.speakerdeck.com/presentations/50716afd60c4040002055606/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
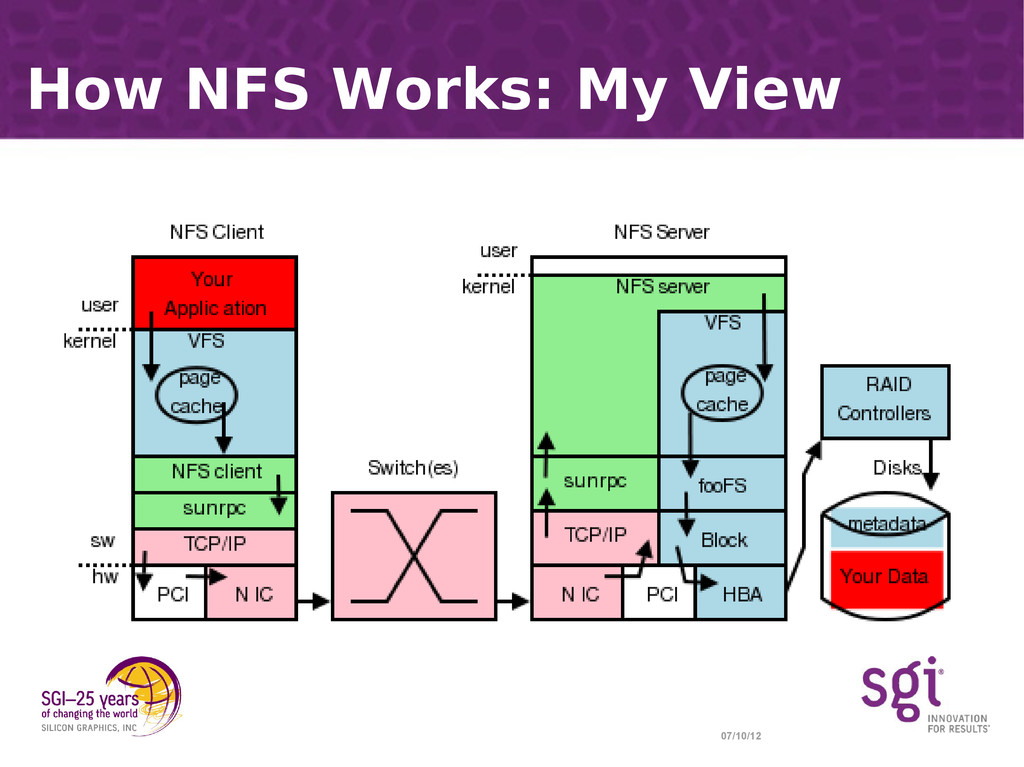{kind=link}
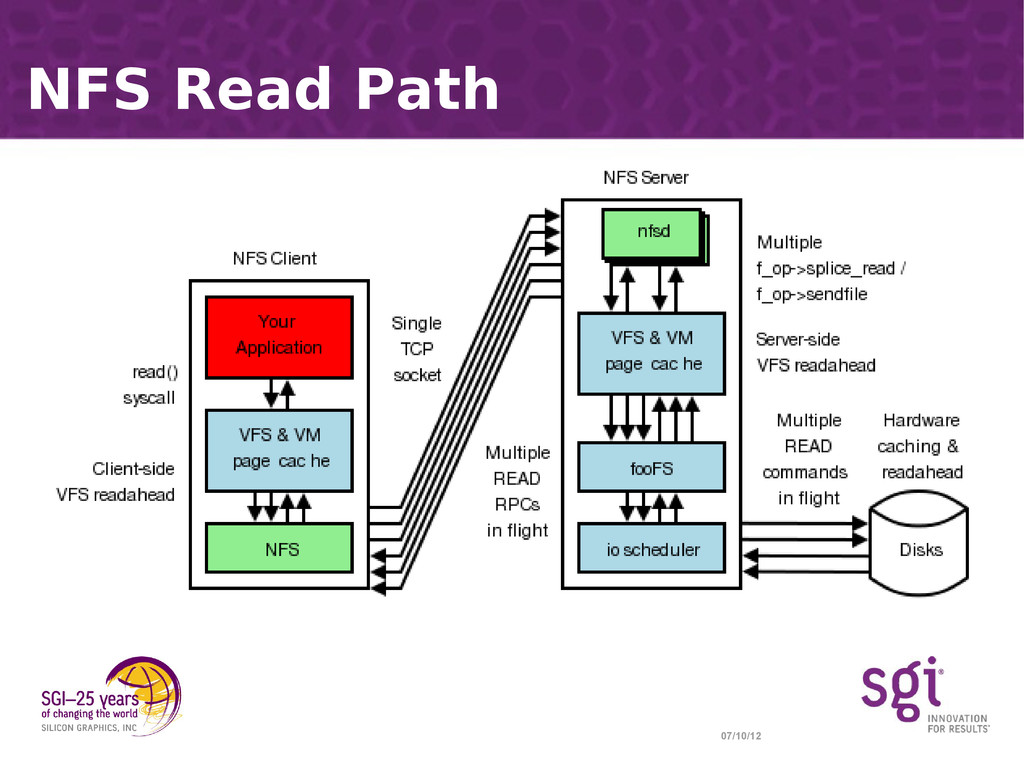{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}