Linux makes a great little NFS server, the emphasis being on "little". SGI's experience is that Linux' NFS server will scale to small machines with 4 or fewer processors, but not to larger machines. To make Linux scale to 8 processors and 8 Gigabit Ethernet network cards, an important market segment for SGI, we have had to perform a lot of performance and scaling work.
After protracted internal development, this work is now (July 2006) just starting to be pushed into the Linux mainstream, as a series of over 40 kernel and nfs-utils patches. See the Linux NFS mailing list at nfs.sourceforge.net.
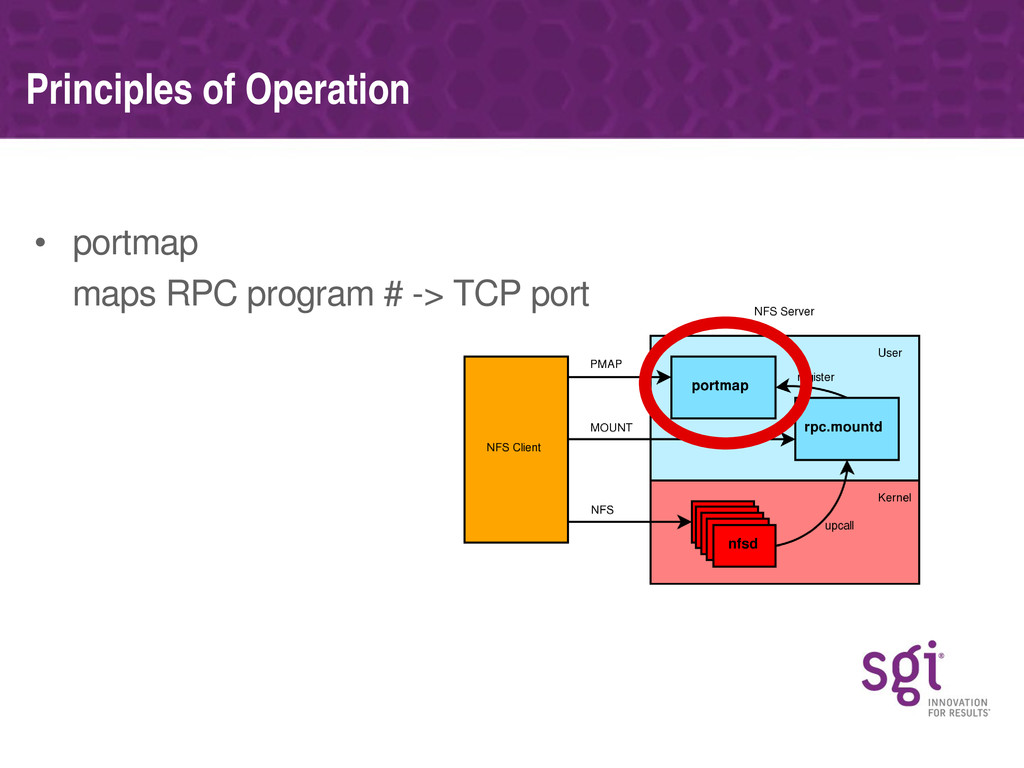
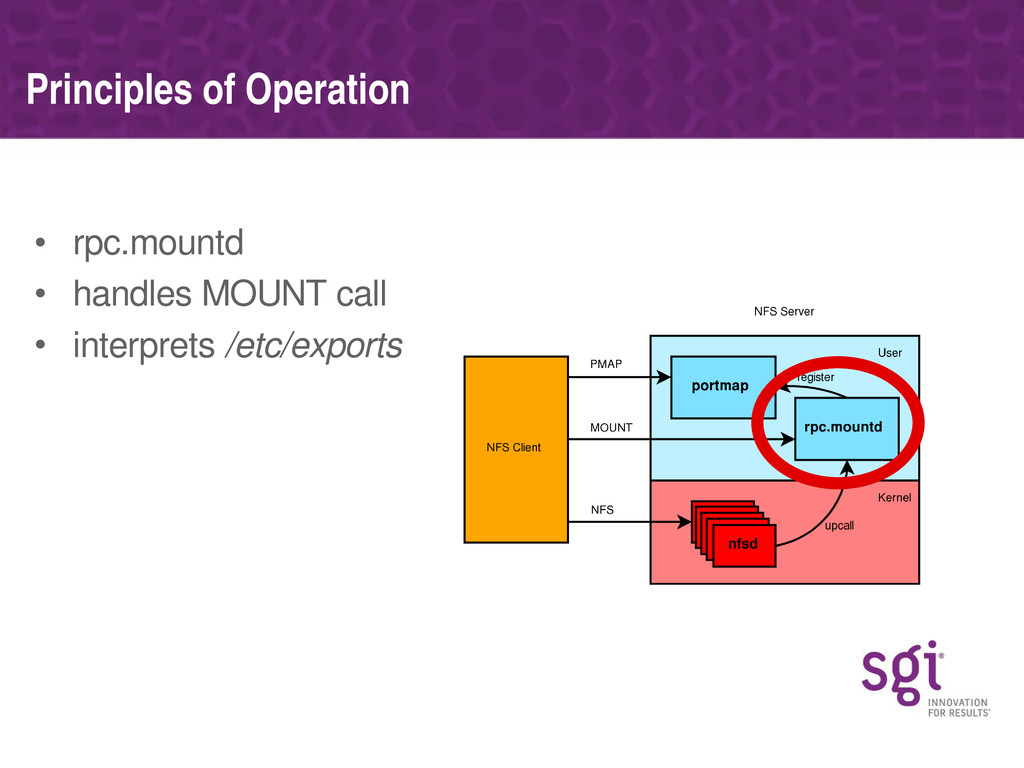
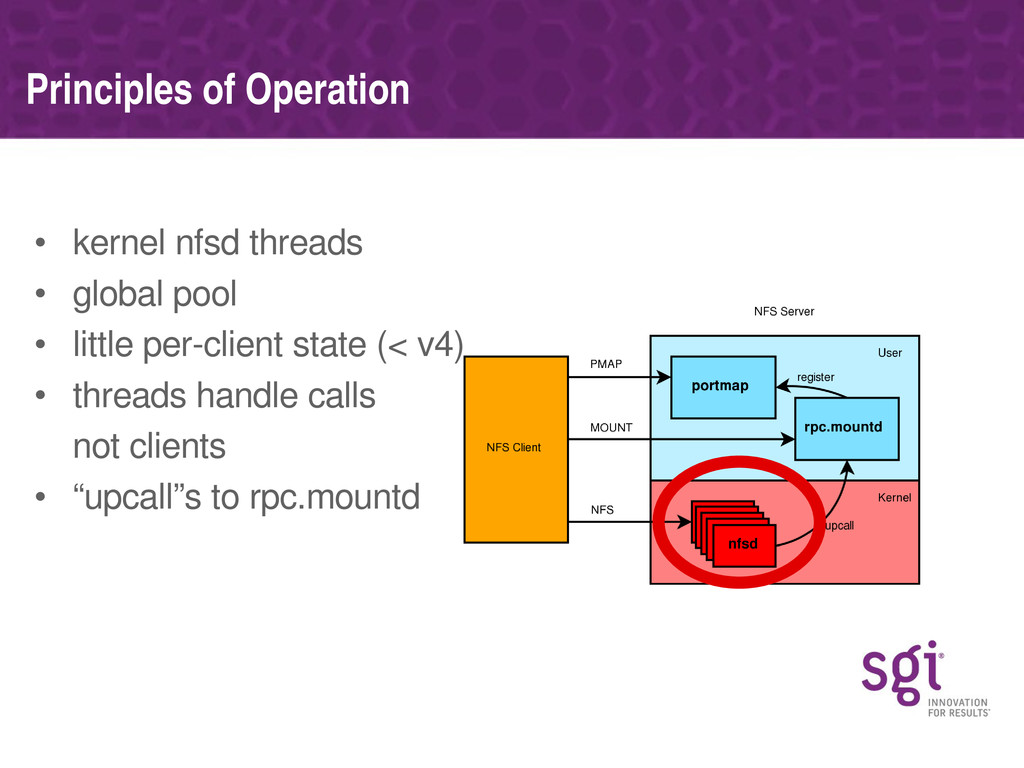
The talk will start with a brief introduction to the theory of operation of the Linux NFS server, explaining how the nfsd threads work and a brief sketch of the lifetime of an NFS call as seen by the server.
Tools and techniques for identifying and measuring software bottlenecks on large machines will be explored. These include profilers, statistics tools, network sniffers, and the relative merits of various kinds of load generators.
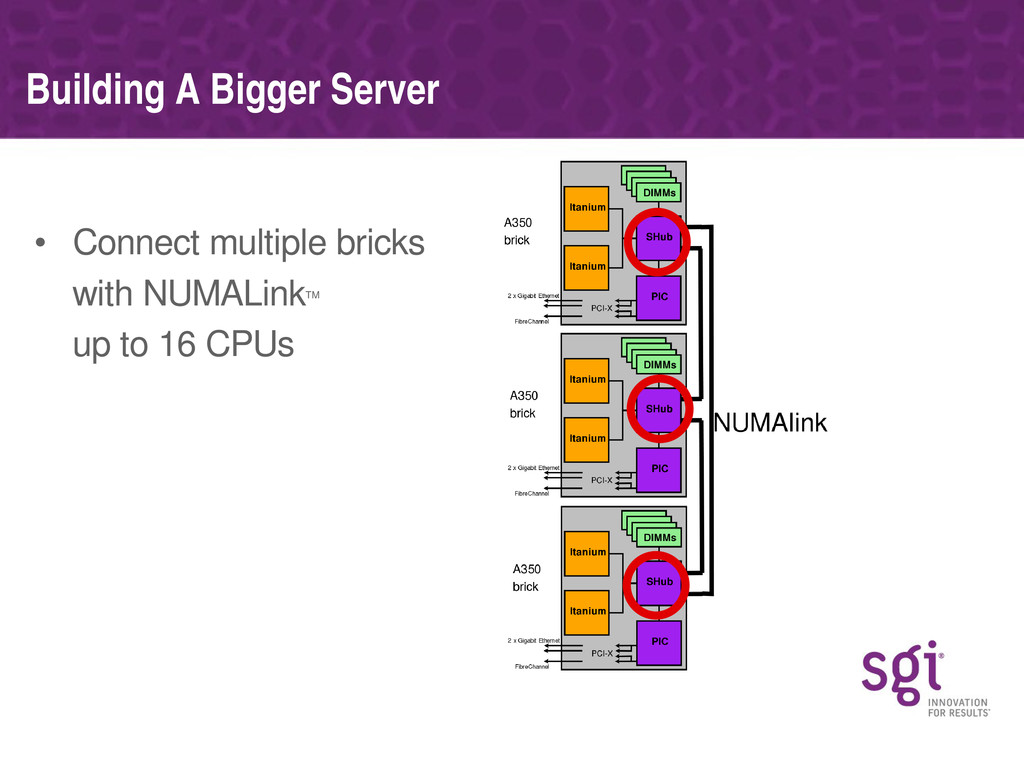
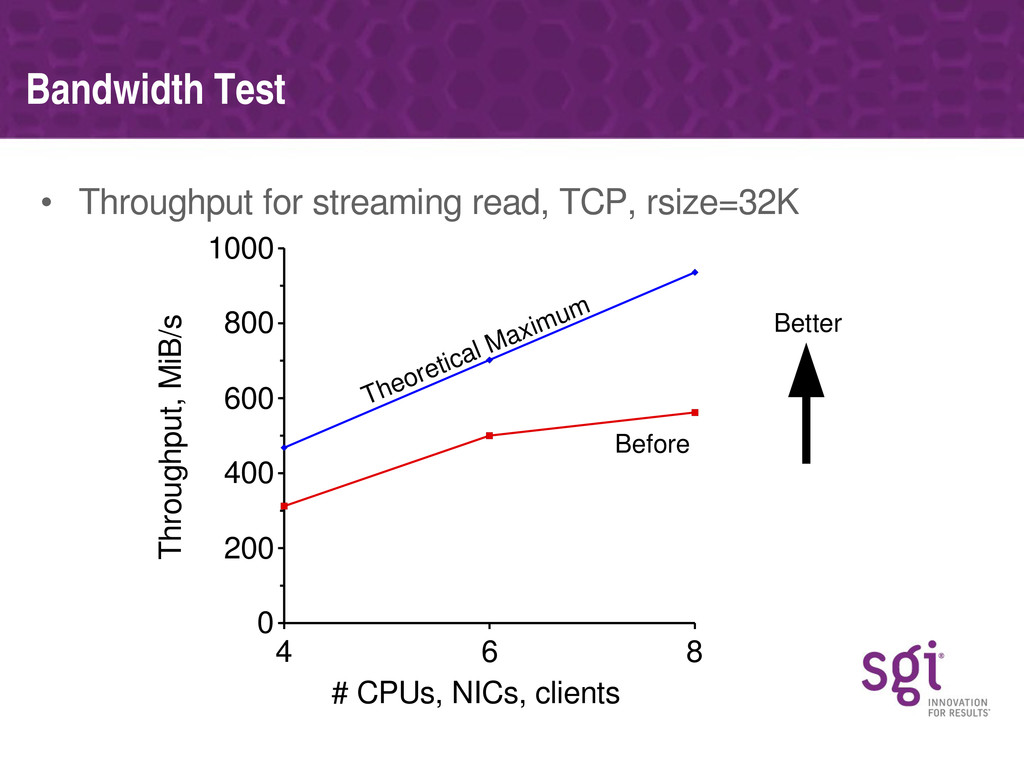
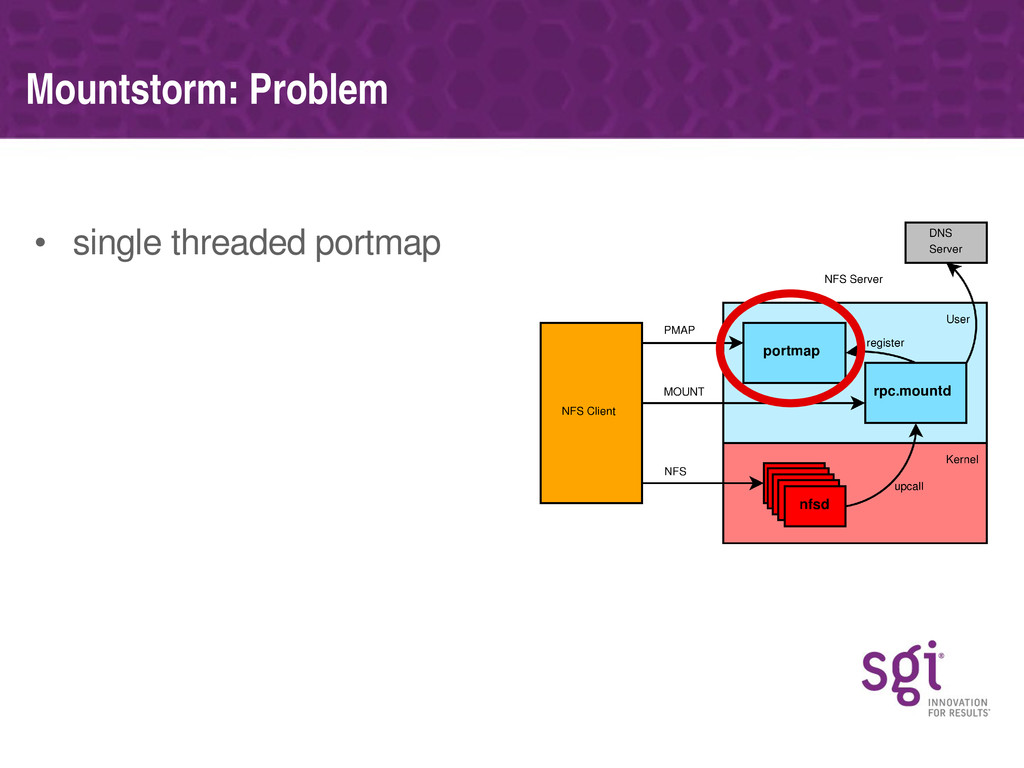
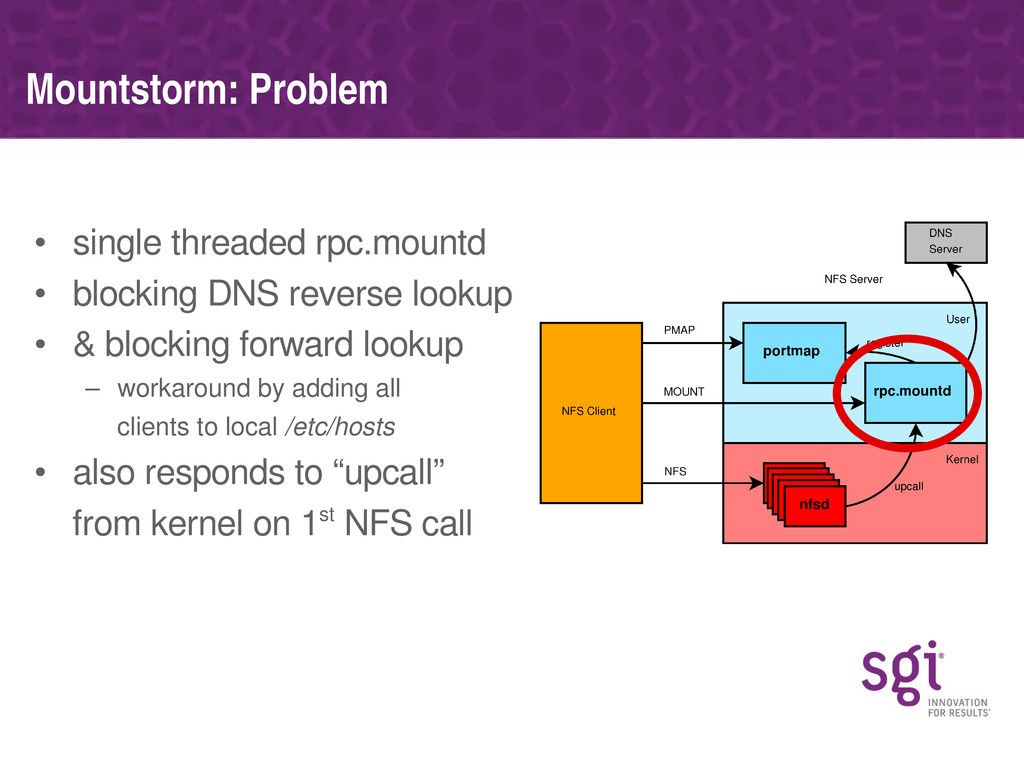
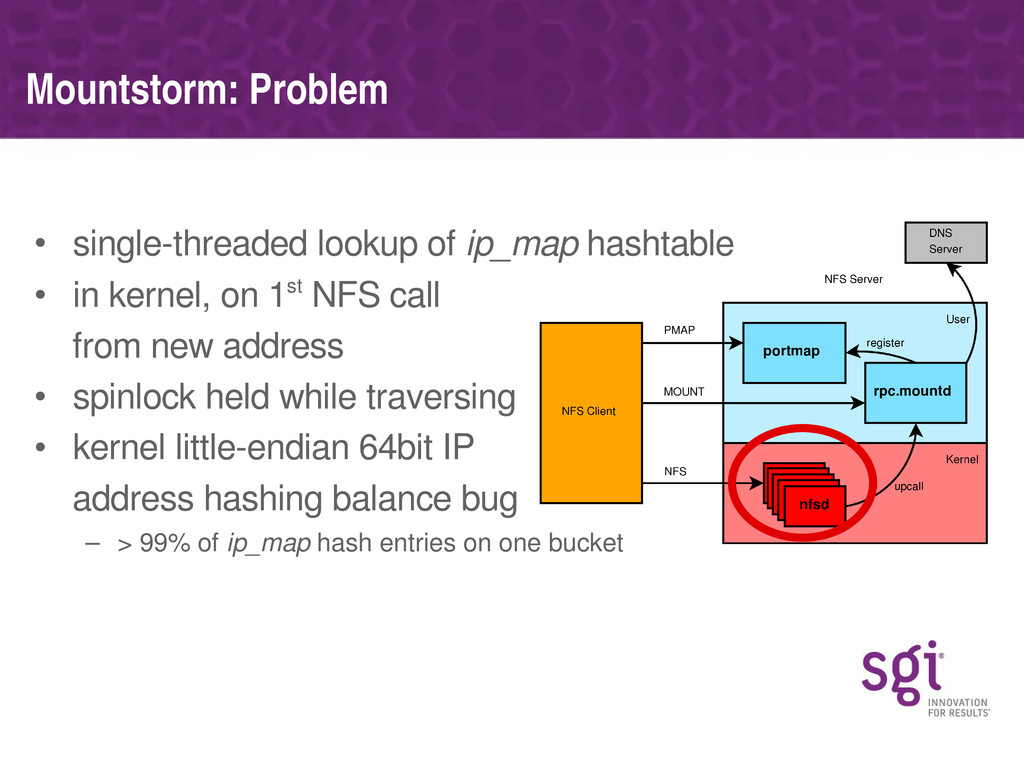
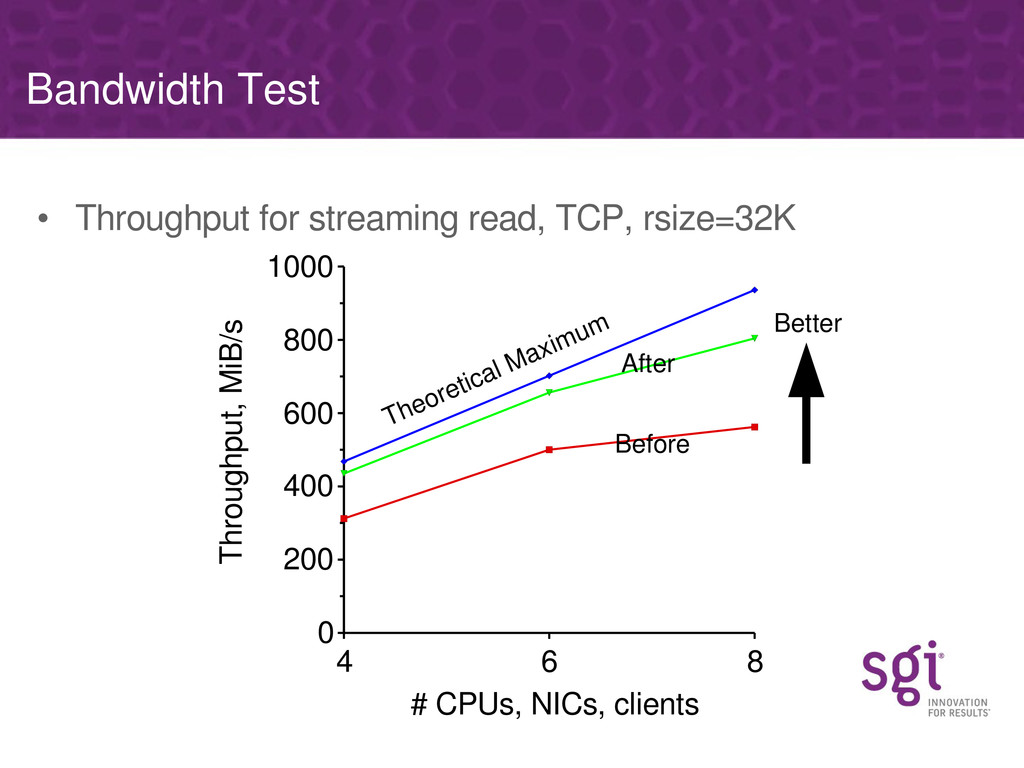
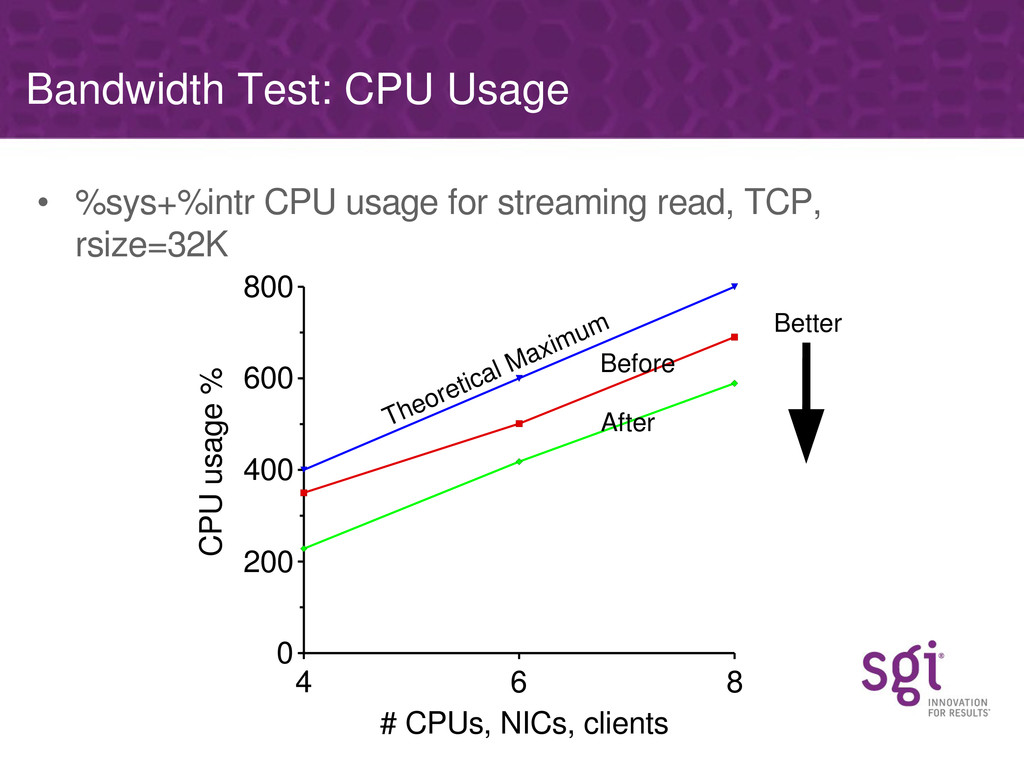
Various specific bottlenecks in the NFS server (discovered using these tools) will be covered, along with how they affect performance on real workloads and the approach SGI have taken in fixing each. Some of the bottlenecks are specific to the NUMA nature of SGI's architecture, but most are generic to any multi-processor platform.
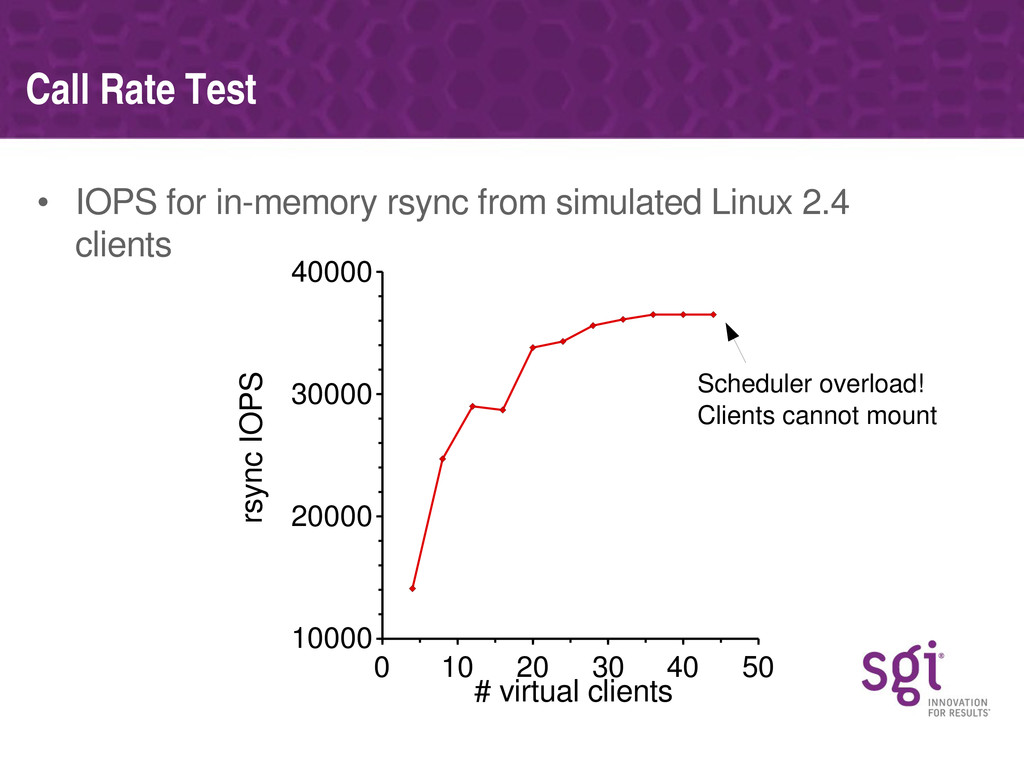
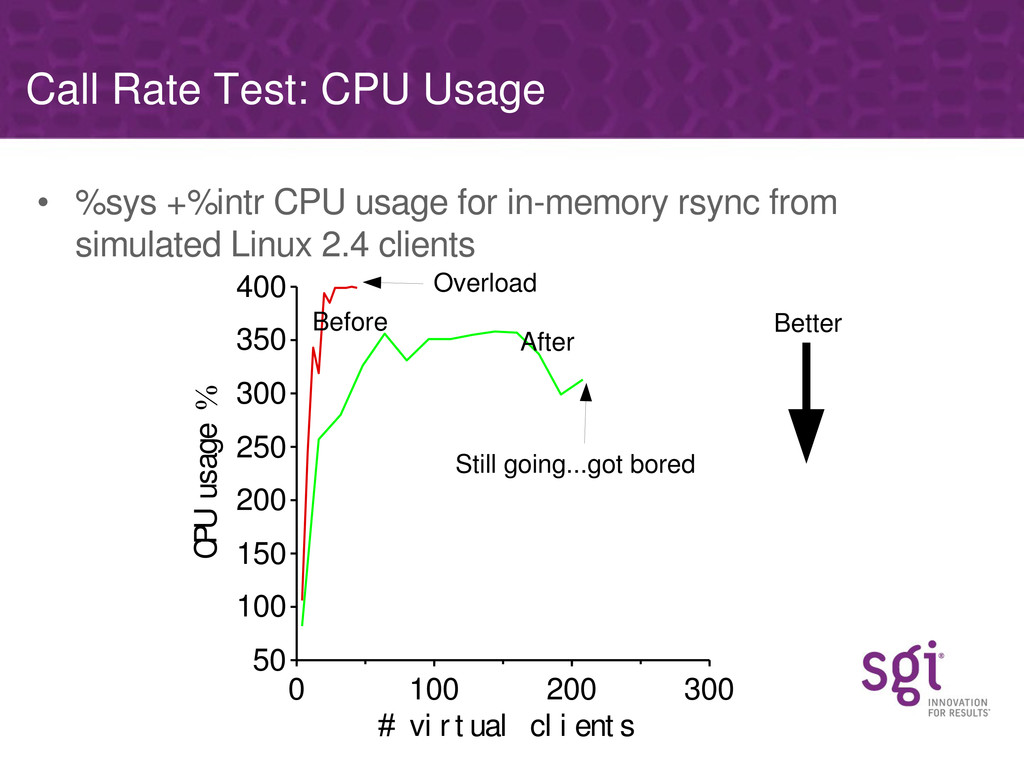
The problems associated with serving large numbers (thousands) of clients, rather than large amount of traffic from mere tens of clients, will be discussed, together with how SGI have solved those.
Finally, there will be a brief mention of work remaining for the future.
Some knowledge of Linux kernel internals and TCP/IP networking will be assumed, but not of NFS. The talk will appeal to kernel programmers, people interested in NFS and network performance, and to programmers interested in improving Linux kernel performance.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}